Week 5: Introduction to neural Networks
CSCI-UA 9473 - Introduction to Machine Learning

Perceptron learning rule¶
This week, we will start working with neural networks. For each of the exercises below you can use the method of your choice but you should display the final boundary of your classifier.
Exercise 1.¶
As a first exercise, load the binary dataset below and code a few steps of the perceptron learning rule.
import scipy.io as sio
data1 = sio.loadmat('perceptron_data_class1.mat')
data2 = sio.loadmat('perceptron_data_class2.mat')
data1 = data1['perceptron_data_class1']
data2 = data2['perceptron_data_class2']
# put your code here
Exercise 2.¶
2a. Load the data below. Using the neural_network module from scikit-learn and its MLPClassifier model, learn a classifier, for the dataset below using
One hidden layer with a linear activation function and
- One neuron
- Two neurons
One hidden layer with a non linear activation function (take Relu for example or a binary step)
- One neuron
- Two neurons
How many neurons, hidden layers do you need to learn the distribution of the data? Do you have an idea why?
Try increasing the number of neurons and hidden layers. Then try different values of the learning rate.
import scipy.io as sio
import numpy as np
data1 = sio.loadmat('data_Week6_class1_XOR.mat')
data2 = sio.loadmat('data_Week6_class2_XOR.mat')
data1 = data1['data_Week6_class1_XOR']
data2 = data2['data_Week6_class2_XOR']
from sklearn.neural_network import MLPClassifier
import matplotlib.pyplot as plt
plt.scatter(data1[:,0], data1[:,1], c= 'r')
plt.scatter(data2[:,0], data2[:,1], c= 'b')
plt.show()

# put your code here
2b. Keep the dataset from above. try to change the intialization of the training algorithm. Plot the resulting classifier for a couple of different initializations. What do you see?
Do it for a small network first. Then repeat those experiments for larger architectures. I.e. increase the number of neurons and the number of layers. What do you see when you change the initialization?
from sklearn.neural_network import MLPClassifier
# put your code here
Exercise 3.¶
__3a.__Load the data below. Try to build the best neural network you can for this dataset. Split the data between a training and a test set and evaluate the models you built. What is the best validation error you can get?
import scipy.io as sio
data1 = sio.loadmat('neural_net_ex2_class1.mat')
data2 = sio.loadmat('neural_net_ex2_class2.mat')
data1 = data1['neural_net_ex2_class1']
data2 = data2['neural_net_ex2_class2']
plt.scatter(data1[:,0], data1[:,1], c= 'r')
plt.scatter(data2[:,0], data2[:,1], c= 'b')
plt.show()

# put your answer here
3b. With the same dataset, add additional features to your model, e.g. $\sin(x), \sin(y)$ or other monomials. Can you improve your classifier ?
Exercise 4.¶
Let us go back briefly to a simple dataset to make sure we understand how things work. As a first exercise, we will code a one hidden layer neural network that outputs a binary 0/1 variable indicating the class of our data. Throughout this exercise, we will use the notation $z^{\ell+1} = \sigma(a^{\ell+1})$ to denote the output of any neuron from the $(\ell+1)^{th}$ layer and where $a^{\ell+1} = \sum_{k} w_{\ell+1,k} z_k$ is the combination from the previous layer that is fed to the neuron.
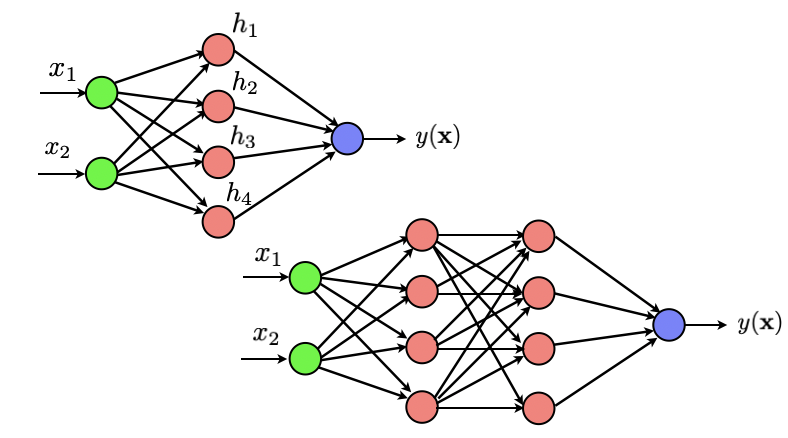
We will use the function 'minimize' from scipy. Check the documentation of that function. We will set the 'jac' parameter of the optimizer to 'True', which implies that the (objective) function that we provide as an input should return both the value of the loss and the value of its gradient.
For this first exercise, you are asked to write a function $f(W)$ wich takes as arguments a vector $W$ containing all the parameters of your network (as a first step consider building a network with only a few hidden units, in order to make sure the model is working). As indicated above, the function should return (1) the value of the binary cross entropy for the given set of weights and (2) the value of the gradient derived through Backpropagation (as we set the value of 'jac' to True).
We will split the writing of your function into several steps. Once you have coded each step, you should gather them together in a single $fun(W)$ body that you will then pass as input to the minimize function.
Exercise 4.a.¶
Start Load the data using the lines below and plot it using scatter()
from scipy.optimize import minimize
import scipy.io as sio
data1 = sio.loadmat('pointsClass1Week6.mat')
data2 = sio.loadmat('pointsClass2Week6.mat')
from numpy import linalg as LA
data1 = data1['pointsClass1Week6']
data2 = data2['pointsClass2Week6']
# put your code here
Exercise 4.b¶
As indicated above, we want to apply the network to the simple binary dataset that you loaded above. We want to build an architecture similar to the one shown above, except that, since we only consider a 2D dataset, we only need 2 inputs. we want our activation function to be all sigmoid. Start by defining the function sigmoid and the gradient of this function. Once you are done, check your derivative. Also make sure you can compute the entrywise sigmoid on any numpy array if the input to your function is a numpy array.
Exercise 4.c¶
Now that we have the sigmoid and its gradient, we will code the loss. As you might remember from previous labs, the MLPClassifier from scikit-learn optimizes the 'log-loss function' (a.k.a Binary cross entropy) which reads for a set of $N$ prototypes $x_i$ with binary $0/1$ targets,
$$−\frac{1}{N}\sum_{i=1}^N (y_i \log(p_{W}(x_i))+(1−y_i)\log(1−p_{W}(x_i))) $$Here the probability $p_{W}(x_i)$ is the output of your network. Instead of minimizing this function directly, we will consider its $\ell_2$ regularized version
$$−\frac{1}{N}\sum_{i=1}^N (y_i \log(p_{W}(x_i))+(1−y_i)\log(1−p_{W}(x_i))) + \lambda \sum_{j\in\text{weights}\setminus \text{bias}} W^2_j$$Where the $W_j$ encode the weights. Code that function for a given labeled dataset $X,t$ such as given above, a set of weights stored in the vector $W$ (you can use a list or a dictionnary if you want but ultimately, you will need to store them in a numpy vector for use with the optimization routine). Note that one typically does not regularize the bias terms.
Exercise 4.d.¶
Towards Backpropagation. The example above is relatively simple so that backpropagation is not really needed. Compute the gradient of the Binary cross entropy loss with respect to the weights.
Exercise 4.e.¶
Combine all your previous steps into a single function and pass this function to the 'minimize' routine. To choose the initial value for the weights, a common heuristic is for the n^th layer to be initialized unformly at random in the interval $[-\varepsilon_n, \varepsilon_n]$ with $\epsilon_n$ defined as $\sqrt{\frac{2}{\text{size layer}_{\ell-1} + \text{size layer}_{\ell} }}$
Bonus 1¶
Change the activation to the Relu and reapeat the steps above. How do you compute the gradient in this case?
Exercise 5.¶
Coding a One hidden layer neural network is good to warm up but to really understand backpropagation, we will not add a few hidden layers. Still relying on the code that you developed above and using backpropagation, train a depth 4 neural network with 10 neurons in each layer on the binary dataset.
Exercise 5a.¶
In this exercise, because of the multiple layers of the network, you will get to really code backpropagation. To do this, follow the steps below
(see Bishop Pattern Recognition and Machine Learning) for more details.
Take any of the sample (Once you have completed one step of backprop, you should re-apply it to the next sample to get the gradient contribution for that next sample and so on). Forward propagate that sample through the network and compute all the activations $z = \sigma(a_i)$ and input $a_i$ for each unit.
Evaluate the $\delta_k = y_k(x_n) - t_{n,k}$ for all the output units.
Backpropagate the $\delta_k$ using the formula
- Finally, compute the derivatives as
Note that when coding the backpropagation algorithm, you don't need to account for the regularization part of the loss as you can just add the gradient of the regularization to the result of the backpropagation algorithm.
from scipy.optimize import minimize
# put your code here
Exercise 6.¶
Extending to multiple classes. Load the data using the lines given below, visualize it with scatter. How can you extend the Binary cross entropy function to the multiclass problem?
import scipy.io as sio
data1 = sio.loadmat('xWeek6Ex3PointsClass1.mat')
data2 = sio.loadmat('xWeek6Ex3PointsClass2.mat')
data3 = sio.loadmat('xWeek6Ex3PointsClass3.mat')
from numpy import linalg as LA
data1 = data1['xWeek6Ex3PointsClass1']
data2 = data2['xWeek6Ex3PointsClass2']
data3 = data3['xWeek6Ex3PointsClass3']
# put your code here