Introduction and Definitions¶
import addutils.toc ; addutils.toc.js(ipy_notebook=True)
from addutils import css_notebook
css_notebook()
1 Introduction¶
Today we see an explosion of applications that are wide and connected with an emphasis on storage and processing. Most companies are storing a lot of data but not solving the problem of what to do with it. Yet most of the information is stored in raw form: There a huge amound of information locked-up in databases: information that is potentially important but has not yet been discovered. The objective of these tutorials is to show the foundamental techniques to Discover Meaningful Information in Data and use state of the art algorithms for Building Models from Data.
Machine Learning is a technology that is currently having a huge impact on business and society. Many big tech companies such as Google, Facebook, Twitter, Amazon and others have employed Machine Learning algorithms to ranking web pages, photo tagging, spam filters, product recomendation systems and many more use cases.
2 What is Machine Learning?¶
Traditionally computers can be programmed with specific algorithms to perform defined tasks, for example how to find the shortest path from A to B, but for the most important tasks, for example how to drive a car, we are not able to program a machine to do that. The only way is to program the machine to learn by itself.
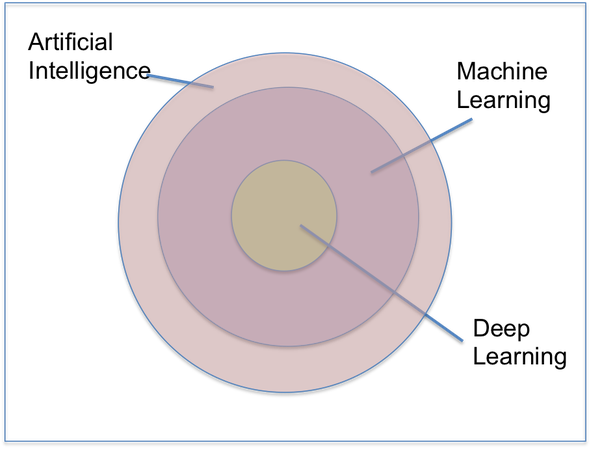
In order to do so, scientist developed in the early fifties the field of Artificial Intellingence (AI). The field growed rapidly and now encompasses many subfields, that ranges from general, like for example learning, to specific, like for example playing GO. AI has many approaches, but historically its main goals were to act and behave like humans, and think rationally.
In recent years, Machine Learning (ML) and Deep Learning (DL) emerged as a subfield of AI. In contrast with the general principles of AI (namely building sentients machines) ML goals is to learn, that is programming computer to improve automatically with experience.
ML is about building programs with tunable parameters (typically an array of floating point values) that are adjusted automatically so as to improve their behavior by adapting to previously seen data. DL is about modeling high-level abstractions in data by using model architectures composed of multiple non-linear transformations.
Other field of computer science deals with information and data, for example Data Mining is the extraction of implicit, previously unknown and potentially useful information from unstructured data.
In recent year the boundaries between all these disciplines and fields has become blurred as all of them borrow techniques from one another. A simple diagram of the interrelation of this fields can be seen in the picture below.
Examples:
- Database mining, Large datasets from growth of automation/web:
- E.g., Web click data, medical records, biology, engineering
- Applications that cannot be programmed by hand:
- E.g., Autonomous helicopter, handwriting recognition, most of Natural Language Processing (NLP), Computer Vision.
- Self-customizing programs:
- E.g., Amazon, Netflix product recommendations
- Understanding human learning (brain, real AI).
2.1 Definitions¶
- Arthur Samuel (1959). Machine Learning: Field of study that gives computers the ability to learn without being explicitly programmed.
- Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
Suppose your email program watches which emails you do or do not mark as spam, and based on that learns how to better filter spam. What is the task T in this setting?
- Classifying emails as spam or not spam.
- Watching you label emails as spam or not spam.
- The number (or fraction) of emails correctly classified as spam/not spam.
Machine learning algorithms:
- SUPERVISED LEARNING
- UNSUPERVISED LEARNING
Others:
- Reinforcement Learning
- Recommendetion Systems.
3 Supervised Learning¶
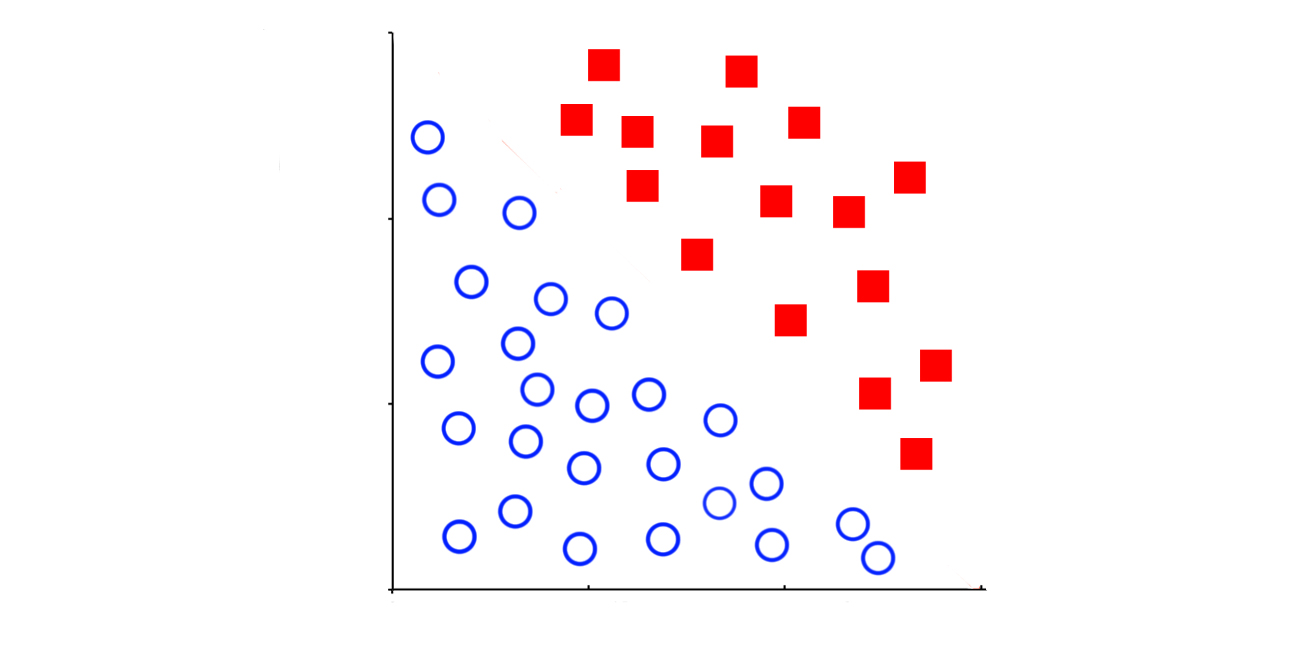
In SUPERVISED LEARNING, we have a dataset consisting of both features and labels. The task is to construct an estimator which is able to predict the label of an object given the set of features.
In general, a learning problem uses a set of n data samples to predict properties of unknown data. Usually data are organized in tables where rows (first axis) represent the samples (or instances) and colums represent attributes (or features), for Supervised Learning, another array of classes or target variables (the "right answers") is provided.
We can separate learning problems in a few large categories:
- Regression
- Classification
- We have a REGRESSION task when the target variable is continuous
- examples:
- predict the future price of stock market
- given a set of attributes, determine the selling price of an house

- We have a CLASSIFICATION task when the target variable is nominal (discrete)
- examples:
- predicting the species of iris given a set of measurements of its flower
- given a multicolor image of an object through a telescope, determine whether that object is a star, a quasar, or a galaxy.
- predict if a patient has brest cancer based on her medical records
4 Unsupervised Learning¶
In UNSUPERVISED LEARNING the data has no labels, and we are interested in finding similarities between the samples.
Unsupervised learning comprises tasks such as dimensionality reduction, clustering, and density estimation. Some unsupervised learning problems are:
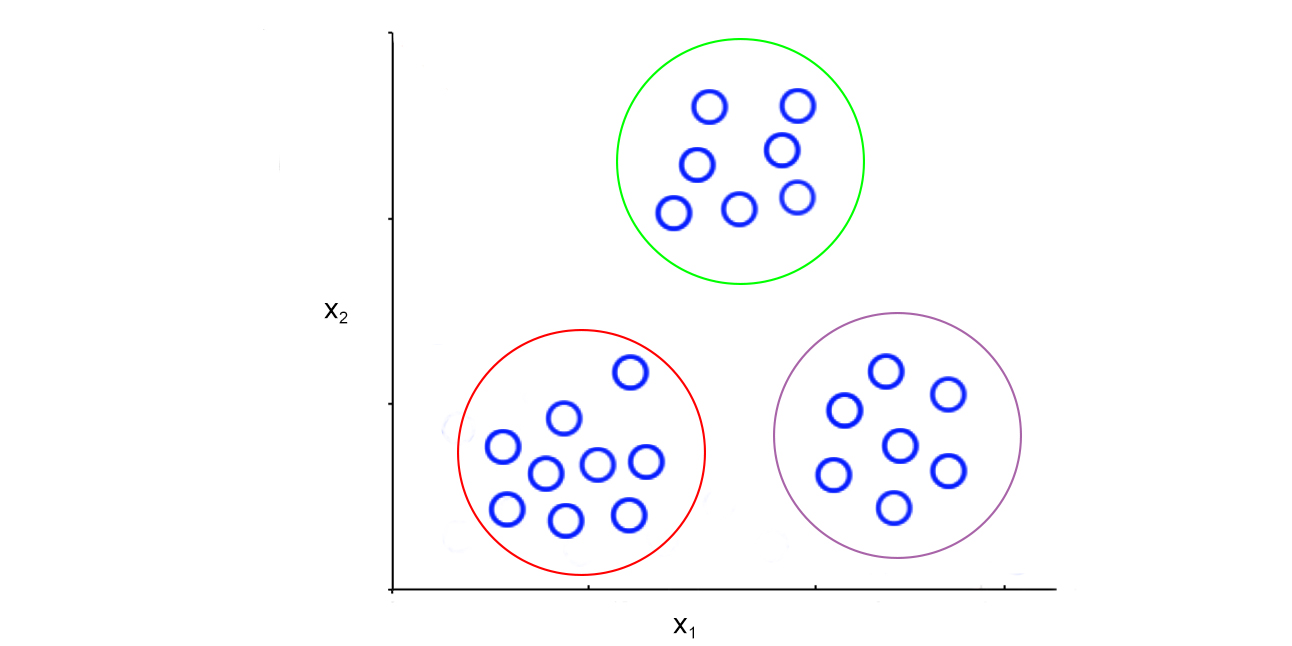
- CLUSTERING is the task that group similar items together
examples:
- market segmentation: find groups of customers in a database that have simliear behavior
- social network analysis: find groups of friends among friends
- given observations of distant galaxies, determine which features are most important in distinguishing between them.
DENSITY ESTIMATION is a task were we want to find statistical values that describe the data
DIMENSIONALITY REDUCTION is for reduce the number of the features while keeping most of the information
UNSUPERVISED / SUPERVISED LEARNING in DL usally the two approach are combined, in fact the DL layers (Restricted Boltzmann Machines, Autoencoders, Convolutional Neural Networks) are used to learn the most significative features of the data. Those features are then used with standard ML regressors or classificators.
5 The Machine Learning Process¶
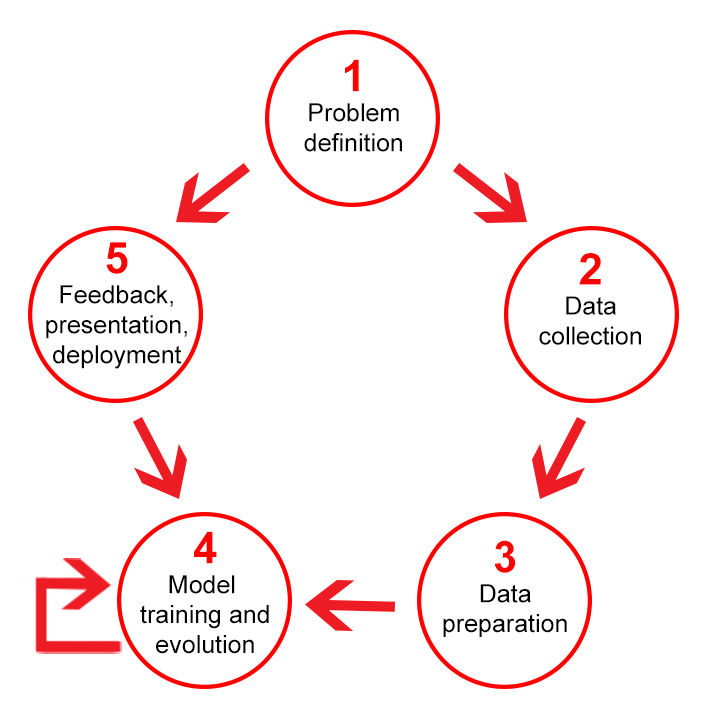
- Problem Definition
- What is the problem? Describe the problem informally and formally and list assumptions and similar problems.
- Why does the problem need to be solved? List your motivation for solving the problem, the benefits a solution provides and how the solution will be used.
- How would I solve the problem? Describe how the problem would be solved manually to flush domain knowledge.
- Data Collection
Data collection may require the use of specialized hardware such as a
sensor network, manual labor such as the collection of user surveys, or software tools such as a Web document crawling engine to collect documents. This stage is highly application-specific and it is critically important because good choices at this stage may significantly impact future stages of the process. After the collection phase, the data are often stored in a database or in a variety of file formats, for later processing.
- Data Preparation
The data is often not in a form that is suitable for processing. For example, the data may be encoded in complex logs or documents without a structure. In many cases, different types of data may be arbitrarily mixed together. To make the data suitable for processing, it is essential to transform them into a format that is friendly to ML algorithms, such as multidimensional, time series, or semistructured format.
The multidimensional format is the most common one, in which different fields of the data correspond to the different measured properties that are referred to as features, attributes, or dimensions. It is crucial to extract relevant features.
The feature extraction phase is often performed in parallel with data cleaning, where missing and erroneous parts of the data are either estimated or corrected. In many cases, the data may be extracted from multiple sources and need to be integrated into a unified format for processing. The final result of this procedure is a tidy data set, which can be effectively used by a computer program.
- Model Training and Evaluation
The goal of Model Training and Evaluation is to test the types of algorithms and dataset combinations that are good at picking out the structure of the problem so that they can be studied in more detail with focused experiments.
More focused experiments with well-performing families of algorithms may be performed in this step, but algorithm tuning is left for the next step.
In this phase we must answer the question:
- What algorithms exist for learning a target functions from training examples? In what settings will particular algorithms converge to the function, given sufficient training data? Which algorithms perform best for which types of problems and representations?
- How much data do I need based on how much is available and what kind of algorithm I would like to use
- How can I improve the solution? More data (if possible!)? Less features? More features? Simpler learning algorithm? More complex learning algorithm?
This is known as Model Selection: any modeling technique can be used to construct of a continuum of models, from simple to complex. One of the key issues in modeling is model selection, which involves picking the appropriate level of complexity for a model given a data set. Although model selection methods can be automated to some degree, model selection cannot be avoided. If someone claims otherwise, or does not emphasize their expertise in model selection, one should be suspicious of his abilities.
- Feedback/Presentation/Deployment
- Start again from the beginning with improved knowledge and refine the model
- Present your results
- Deploy to production
5.1 Few useful things to know about ML¶
Here is a list of things to take in great consideration while developing ML systems:
- No Free Lunch: A wide variety of techniques exist for modeling. An important theorem in statistical machine learning essentially states that no one technique will outperform all other techniques on all problems (Wolpert & MacReady, 1997). This theorem is sometimes referred to as No Free Lunch. Often, a modeling group will specialize in one particular technique, and will tout that technique as the being intrinsically superior to others. Such a claim should be regarded with extreme suspicion. Furthermore, the field of statistical machine learning is evolving rapidly, and new algorithms are developed at a regular pace, this determines a very fast aging for ML approaches. This is the reason why in Addfor we rely on Open Source, Lean and Data-Driven Development and Combinatorial Innovation.
- Curse of Dimensionality: The problems is that when the dimensionality increases, the volume of the space increases so fast that the available data become sparse. This sparsity is problematic for any method that requires statistical significance. In order to obtain a statistically sound and reliable result, the amount of data needed to support the result often grows exponentially with the dimensionality. Also organizing and searching data often relies on detecting areas where objects form groups with similar properties; in high dimensional data however all objects appear to be sparse and dissimilar in many ways which prevents common data organization strategies from being efficient.
- Beware of False Predictors: In selecting input variables for a model, one must be careful not to include false predictors. A false predictor is a variable that is strongly correlated with the output class, but that is not available in a realistic prediction scenario. This step is stricktly data-dependent and can be accomplished by paying attention to the choice of the validation dataset. Correlation does not imply causation: ice-cream sales is a strong predictor for drowning deaths.
- Mind Data Balancing: Always check if your algorithm is suitable to handle Data Asymmetricity.
- Correctly Define Output Classes: If the model's task is to predict a system failure, it seems natural for the output classes to be "fail" and "not fail". However, characterizing the exact conditions under which failure occurs is not straightforward. For example two failures for different reasons could represent very different classes.
- Segmentation: Often, a data set can be broken into several smaller, more homogenous data sets, which is referred to as segmentation. For example, a customer data base might be split into business and residential customers. Although domain experts can readily propose segmentations, enforcing a segmentation suggested by domain experts is generally not the most prudent approach to modeling, because the data itself provides clues to how the segmentation should be performed. Consequently, one should be concerned if a modeler claims to utilize a priori segmentation.
Model Evaluation: Once a model has been built, the natural question to ask is how accurate it is. Here we describe common sorts of deception that can occur in assessing and evaluating a model:
Failing to use an independent test set: To obtain a fair estimate of performance, the model must be evaluated on examples that were not contained in the training set. The available data must be split into nonoverlapping subsets, with the test set reserved only for evaluation.
Assuming stationarity of the test environment: For many difficult problems, a model built based on historical data will become a poorer and poorer predictor as time goes on, because the environment is nonstationary--the rules and behaviors of individuals change over time. Consequently, the best measure of a model's true performance will be obtained if it is tested on data from a different point in time relative to the training data.
Incomplete reports of results: An accurate model will correctly discriminate examples of one output class from examples of another output class. Discrimination performance is best reported with an ROC curve, a lift curve, or a precision-recall curve. Any report of accuracy using only a single number is suspect.
Filtering data to bias results: In a large data set, one segment of the population may be easier to predict than another. If a model is trained and tested just on this segment of the population, it will be more accurate than a model that must handle the entire population. Selective filtering can turn a hard problem into an easier problem.
Selective sampling of test cases: A fair evaluation of a model will utilize a test set that is drawn from the same population as the model will eventually encounter in actual usage.
Failing to assess statistical reliability: When comparing the accuracy of two models, it is not sufficient to report that one model performed better than the other, because the difference might not be statistically reliable. "Statistical reliability" means, among other things, that if the comparison were repeated using a different sample of the population, the same result would be achieved.
6 Resources and Courses¶
Visit www.add-for.com for more tutorials and updates.
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.