KDD2024 Tutorial / A Hands-On Introduction to Time Series Classification and Regression
Feature-based Time Series Machine Learning in aeon¶
Feature-based classifiers and regressors are a popular theme in time series classification (TSC) and regression (TSER). The feature-based learners we provide are simply pipelines of transform and classifier/regressor. They extract descriptive statistics as features from time series to be used in a base estimator. Several toolkits exist for extracting features from time series data, in the first half of this notebook we will introduce a few available in aeon and explore them using our EEG example dataset.
In the second half of the notebook, we will introduce the pipelining utilities available in aeon and demonstrate how to build a learner using your own selection of feature extraction transformation algorithm and estimator. Being a scikit-learn compatible library, we will also show how the utilities present there can also be used as a substitution for the aeon ones.
!pip install aeon==0.11.0 tsfresh
!mkdir -p data
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_MTSC_TRAIN.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_MTSC_TEST.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_UTSC_TRAIN.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_UTSC_TEST.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_MTSER_TRAIN.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_MTSER_TEST.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_UTSER_TRAIN.ts -P data/
!wget -nc https://raw.githubusercontent.com/aeon-tutorials/KDD-2024/main/Notebooks/data/KDD_UTSER_TEST.ts -P data/
# There are some deprecation warnings present in the notebook, we will ignore them.
# Remove this cell if you are interested in finding out what is changing soon, for
# aeon there will be big changes in out v1.0.0 release!
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
from aeon.registry import all_estimators
all_estimators(
"classifier", filter_tags={"algorithm_type": "feature"}, as_dataframe=True
)
| name | estimator | |
|---|---|---|
| 0 | Catch22Classifier | <class 'aeon.classification.feature_based._cat... |
| 1 | FreshPRINCEClassifier | <class 'aeon.classification.feature_based._fre... |
| 2 | SignatureClassifier | <class 'aeon.classification.feature_based._sig... |
| 3 | SummaryClassifier | <class 'aeon.classification.feature_based._sum... |
| 4 | TSFreshClassifier | <class 'aeon.classification.feature_based._tsf... |
all_estimators(
"regressor", filter_tags={"algorithm_type": "feature"}, as_dataframe=True
)
| name | estimator | |
|---|---|---|
| 0 | Catch22Regressor | <class 'aeon.regression.feature_based._catch22... |
| 1 | FreshPRINCERegressor | <class 'aeon.regression.feature_based._fresh_p... |
| 2 | SummaryRegressor | <class 'aeon.regression.feature_based._summary... |
| 3 | TSFreshRegressor | <class 'aeon.regression.feature_based._tsfresh... |
Load example data ¶
from aeon.datasets import load_from_tsfile
X_train_c, y_train_c = load_from_tsfile("./data/KDD_MTSC_TRAIN.ts")
X_test_c, y_test_c = load_from_tsfile("./data/KDD_MTSC_TEST.ts")
print("Train shape:", X_train_c.shape)
print("Test shape:", X_test_c.shape)
Train shape: (40, 4, 100) Test shape: (40, 4, 100)
from aeon.visualisation import plot_collection_by_class
plot_collection_by_class(X_train_c[:,2,:], y_train_c)
(<Figure size 1200x600 with 2 Axes>, array([<Axes: >, <Axes: >], dtype=object))

X_train_r, y_train_r = load_from_tsfile("./data/KDD_MTSER_TRAIN.ts")
X_test_r, y_test_r = load_from_tsfile("./data/KDD_MTSER_TEST.ts")
print("Train shape:", X_train_r.shape)
print("Test shape:", X_test_r.shape)
Train shape: (72, 4, 100) Test shape: (72, 4, 100)
from matplotlib import pyplot as plt
plt.plot(X_train_r[0].T)
plt.legend(["Dim 0", "Dim 1", "Dim 2", "Dim 3"])
<matplotlib.legend.Legend at 0x116ec2ed840>

Simple summary statistics ¶
One of the simplest ways to transform time series data is to calculate simple summary statistics such as the mean, median, minimum and maximum. While unlikely to be the most effective method for classification or regression, simple statistics can be an efficient approach if it is all that is required to solve a problem. It also serves as a useful baseline to compare more complex methods against.
Transforming summary statistics ¶
There are a myriad of simple summary statistics to extract. aeon provides the SevenNumberSummaryTransformer to extract some common sets of simple summary statistics. By default, this will extract the mean, standard deviation, minimum and maximum as well as the 25%, 50% and 75% percentiles of the series.
from aeon.transformations.collection.feature_based import SevenNumberSummaryTransformer
sns = SevenNumberSummaryTransformer()
sns.fit_transform(X_train_c)[:5]
array([[-4.84662295e-06, 4.07268745e-07, -2.73869572e-06,
-3.51260400e-06, 1.63624369e-05, 1.16629572e-05,
1.30628441e-05, 8.11090668e-06, -4.45090224e-05,
-3.11305575e-05, -4.75946408e-05, -2.61954642e-05,
3.46203603e-05, 3.47668727e-05, 3.39561285e-05,
1.76228755e-05, -1.64710485e-05, -6.62102019e-06,
-9.29125055e-06, -9.18664189e-06, -4.16492472e-06,
5.05660282e-07, -3.59126774e-06, -3.57970993e-06,
6.21564018e-06, 8.52922486e-06, 3.78158546e-06,
1.46693222e-06],
[ 1.43118551e-06, 4.93131265e-06, -3.01206374e-06,
-2.96546855e-06, 1.57514418e-05, 1.18989896e-05,
1.42330289e-05, 8.23176010e-06, -3.96678721e-05,
-3.20327392e-05, -4.97710490e-05, -2.27389254e-05,
3.86811780e-05, 3.41553068e-05, 3.07966661e-05,
1.69591315e-05, -1.00173490e-05, -1.38364793e-06,
-1.12537694e-05, -7.63621645e-06, 1.71570094e-07,
6.00613380e-06, -4.99488676e-06, -4.33762891e-06,
1.21498805e-05, 1.26801341e-05, 7.58307639e-06,
1.90720899e-06],
[-6.06350354e-07, 3.79695308e-06, 3.37033758e-06,
8.40880283e-07, 1.33059491e-05, 1.00766877e-05,
1.24823971e-05, 8.31148145e-06, -2.46474158e-05,
-3.52807268e-05, -2.07430038e-05, -1.40873679e-05,
3.50846795e-05, 3.23808257e-05, 4.22996921e-05,
2.04928310e-05, -1.05036740e-05, -1.90196079e-06,
-5.74253879e-06, -5.54778688e-06, -1.00610183e-06,
3.66990513e-06, 2.48374584e-06, -3.05285469e-07,
7.54937899e-06, 1.03798062e-05, 1.08999518e-05,
6.52059787e-06],
[-2.17892949e-07, -2.02235649e-06, -2.30261793e-06,
-2.96036604e-06, 1.41719989e-05, 1.04135837e-05,
1.08641355e-05, 7.47429838e-06, -3.88787165e-05,
-2.79391997e-05, -2.89298783e-05, -2.16766752e-05,
4.10128682e-05, 2.54540561e-05, 2.02451413e-05,
1.45322196e-05, -9.32112423e-06, -8.51916609e-06,
-9.36117398e-06, -7.86137111e-06, 1.00891793e-06,
-1.31757362e-06, -3.07652146e-06, -3.33946583e-06,
9.17556384e-06, 4.04165912e-06, 5.28668617e-06,
1.72718528e-06],
[ 3.07705341e-06, 8.81621473e-09, 2.83706608e-06,
-8.22774051e-07, 1.41351503e-05, 1.01270483e-05,
1.17155555e-05, 7.29112178e-06, -2.82107673e-05,
-3.41915997e-05, -2.67467147e-05, -1.66092656e-05,
3.90449654e-05, 3.29991224e-05, 3.82125421e-05,
1.62320250e-05, -5.53341704e-06, -3.66923844e-06,
-3.28692074e-06, -6.70620737e-06, 2.78593407e-06,
1.00783371e-06, 2.62830476e-06, -2.21012831e-08,
1.26472925e-05, 3.66738837e-06, 1.06877853e-05,
5.16018061e-06]])
Classification and regression with summary statistics ¶
The SummaryClassifier and SummaryRegressor aeon classes are wrappers for a pipeline of a SevenNumberSummaryTransformer transformation and a scikit-learn Random Forest by default.
from aeon.classification.feature_based import SummaryClassifier
from sklearn.metrics import accuracy_score
sns_cls = SummaryClassifier(random_state=42)
sns_cls.fit(X_train_c, y_train_c)
sns_preds_c = sns_cls.predict(X_test_c)
accuracy_score(y_test_c, sns_preds_c)
0.8
The summary feature set and the scikit-learn estimator are configurable.
from sklearn.linear_model import RidgeClassifierCV
sns_cls = SummaryClassifier(
summary_stats="bowley",
estimator=RidgeClassifierCV(),
random_state=42,
)
sns_cls.fit(X_train_c, y_train_c)
sns_preds_c = sns_cls.predict(X_test_c)
accuracy_score(y_test_c, sns_preds_c)
0.65
Regression is run similarly to classification.
from aeon.regression.feature_based import SummaryRegressor
from sklearn.metrics import mean_squared_error
sns_reg = SummaryRegressor(random_state=42)
sns_reg.fit(X_train_r, y_train_r)
sns_preds_r = sns_reg.predict(X_test_r)
mean_squared_error(y_test_r, sns_preds_r)
0.5982165183583272
from aeon.visualisation import plot_scatter_predictions
plot_scatter_predictions(y_test_r, sns_preds_r)
(<Figure size 600x600 with 1 Axes>, <Axes: xlabel='Actual values', ylabel='Predicted values'>)

Catch22 ¶
The highly comparative time-series analysis (hctsa) [1,2] toolbox can create over 7700 features for exploratory time series analysis. Unfortunetly there is not a complete set of these features available in Python currently, interested users can check out the relevant publication and the original MATLAB toolbox.
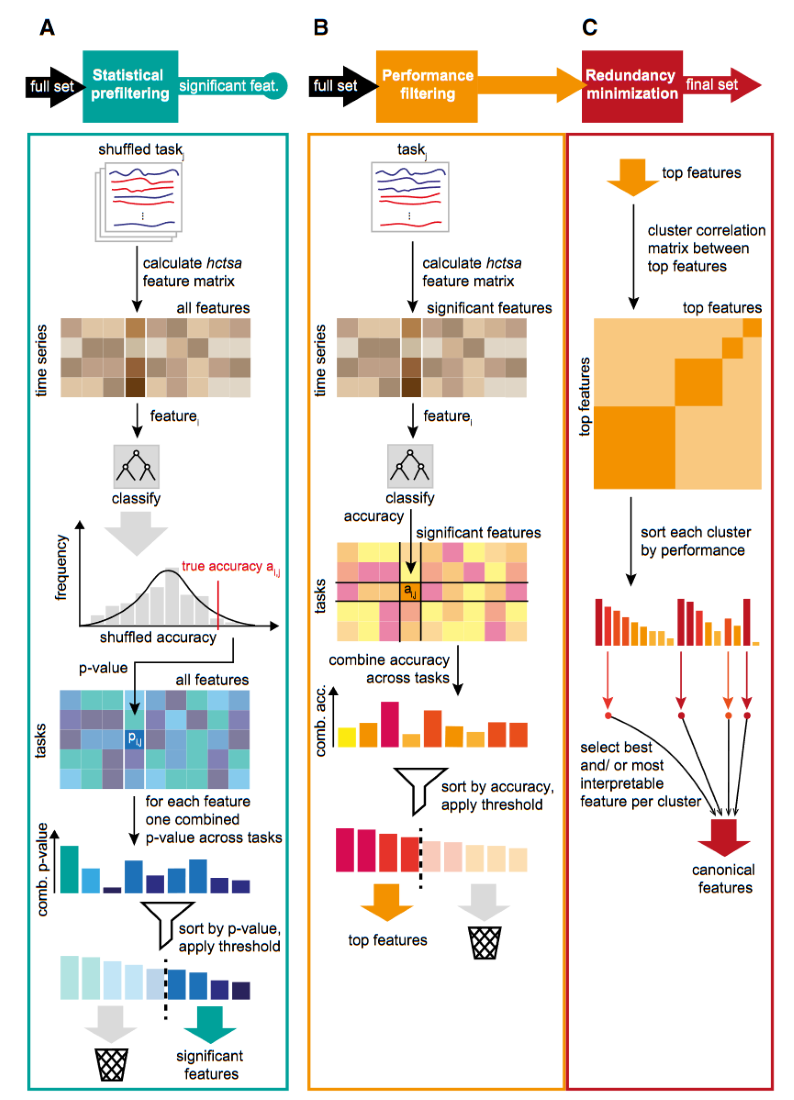
The canonical time series characteristics (Catch22) [3] are 22 hctsa features determined to be the most discriminatory of the full set.
The Catch22 features were chosen by an evaluation on the UCR datasets [4]. The hctsa features were initially pruned, removing those which are sensitive to mean and variance and any which could not be calculated on over 80% of the UCR datasets. A feature evaluation was then performed based on predictive performance. Any features which performed below a threshold were removed. For the remaining features, a hierarchical clustering was performed on the correlation matrix to remove redundancy. From each of the 22 clusters formed, a single feature was selected, taking into account balanced accuracy, computational efficiency and interpretability. The Catch22 features cover a wide range of concepts such as basic statistics of data series values, linear correlations, and entropy.
Transforming Catch22 ¶
The Catch22 class transforms time series into the 22 features.
from aeon.transformations.collection.feature_based import Catch22
c22 = Catch22()
c22.fit_transform(X_train_c)[:5]
array([[-4.94433107e-06, 6.92507633e-06, 2.98422388e+00,
4.00000000e+00, -8.88178420e-16, -1.01000518e-15,
0.00000000e+00, 1.60000000e+01, 1.11111111e-01,
0.00000000e+00, 0.00000000e+00, 3.00000000e+00,
3.84615385e-02, 0.00000000e+00, 0.00000000e+00,
1.57359203e-10, 5.00000000e+00, 2.00785293e+00,
8.28571429e-01, 6.00000000e-01, 4.90873852e-01,
1.40193684e-05, 1.81815758e-06, -1.47671393e-06,
3.71562980e+00, 4.00000000e+00, -8.88178420e-16,
-5.87837340e-16, 0.00000000e+00, 1.70000000e+01,
6.25000000e-02, 0.00000000e+00, 0.00000000e+00,
3.00000000e+00, 4.54545455e-02, 0.00000000e+00,
0.00000000e+00, 7.77998115e-11, 7.00000000e+00,
2.00199666e+00, 8.28571429e-01, 8.28571429e-01,
2.94524311e-01, 1.02667064e-05, -6.81925616e-06,
-2.74171769e-06, 2.54465362e+00, 5.00000000e+00,
-8.88178420e-16, -4.07928862e-16, 0.00000000e+00,
1.20000000e+01, 4.00000000e-02, 0.00000000e+00,
0.00000000e+00, 4.00000000e+00, 5.26315789e-02,
0.00000000e+00, 0.00000000e+00, 1.04053400e-10,
8.00000000e+00, 1.84997494e+00, 8.28571429e-01,
8.28571429e-01, 4.41786467e-01, 1.08579400e-05,
-4.28629432e-06, -2.09537733e-06, 2.25468230e+00,
5.00000000e+00, -8.88178420e-16, -1.96296224e-17,
0.00000000e+00, 1.30000000e+01, 6.36574074e-03,
0.00000000e+00, 0.00000000e+00, 3.00000000e+00,
2.50000000e-01, 0.00000000e+00, 0.00000000e+00,
3.78824191e-11, 5.00000000e+00, 1.94369228e+00,
1.71428571e-01, 8.00000000e-01, 5.39961237e-01,
7.16263022e-06],
[-4.93347026e-07, -4.41079953e-06, 9.76550866e-01,
5.00000000e+00, -8.88178420e-16, -1.93131216e-15,
0.00000000e+00, 1.00000000e+01, 1.47737765e-02,
0.00000000e+00, 0.00000000e+00, 3.00000000e+00,
2.00000000e-01, 0.00000000e+00, 0.00000000e+00,
1.02981595e-10, 6.00000000e+00, 2.08655852e+00,
1.71428571e-01, 8.28571429e-01, 7.36310778e-01,
1.60656562e-05, 1.06128379e-06, 4.37068609e-06,
2.99539703e+00, 1.00000000e+00, -8.88178420e-16,
2.19729828e-16, 0.00000000e+00, 1.50000000e+01,
2.08333333e-02, 0.00000000e+00, 0.00000000e+00,
2.00000000e+00, 8.33333333e-02, 0.00000000e+00,
0.00000000e+00, 8.84485984e-11, 5.00000000e+00,
2.05946536e+00, 6.00000000e-01, 3.14285714e-01,
2.94524311e-01, 9.62091285e-06, -9.48719145e-06,
-5.45880569e-06, 1.78980033e+00, 5.00000000e+00,
-8.88178420e-16, 5.16491517e-17, 0.00000000e+00,
1.20000000e+01, 6.12182430e-03, 0.00000000e+00,
0.00000000e+00, 2.00000000e+00, 6.66666667e-01,
0.00000000e+00, 0.00000000e+00, 7.71939551e-11,
6.00000000e+00, 1.96831980e+00, 1.71428571e-01,
7.14285714e-01, 6.87223393e-01, 1.48956808e-05,
-2.88989693e-06, -4.87479978e-06, 2.21747187e+00,
5.00000000e+00, -8.88178420e-16, 7.57005863e-17,
0.00000000e+00, 1.20000000e+01, 9.23361034e-03,
0.00000000e+00, 0.00000000e+00, 3.00000000e+00,
2.00000000e-01, 0.00000000e+00, 0.00000000e+00,
3.72808238e-11, 4.00000000e+00, 2.04733206e+00,
1.71428571e-01, 6.85714286e-01, 4.41786467e-01,
7.52540169e-06],
[-6.72778723e-06, 2.23202708e-06, 8.30813700e-01,
1.00000000e+00, -8.88178420e-16, 1.16234122e-15,
0.00000000e+00, 1.10000000e+01, 1.73611111e-02,
0.00000000e+00, 0.00000000e+00, 2.00000000e+00,
2.50000000e-01, 0.00000000e+00, 0.00000000e+00,
6.56303902e-11, 7.00000000e+00, 2.17460531e+00,
7.14285714e-01, 1.71428571e-01, 8.34485549e-01,
1.45365247e-05, -1.44995057e-06, 1.93312705e-06,
7.17005807e-01, 1.00000000e+00, -8.88178420e-16,
-8.69151397e-16, 0.00000000e+00, 1.20000000e+01,
4.62962963e-03, 0.00000000e+00, 0.00000000e+00,
2.00000000e+00, 1.25000000e-01, 0.00000000e+00,
0.00000000e+00, 3.23868358e-11, 4.00000000e+00,
2.16552480e+00, 8.00000000e-01, 8.00000000e-01,
1.32535940e+00, 1.07278852e-05, -1.83019499e-06,
7.62620939e-06, 2.41674894e+00, 5.00000000e+00,
-8.88178420e-16, 2.01394617e-16, 0.00000000e+00,
2.50000000e+01, 9.23361034e-03, 0.00000000e+00,
0.00000000e+00, 5.00000000e+00, 4.00000000e-01,
0.00000000e+00, 0.00000000e+00, 9.72031604e-11,
6.00000000e+00, 1.94369228e+00, 8.00000000e-01,
7.42857143e-01, 4.41786467e-01, 1.12686720e-05,
-3.71330823e-06, -1.98429828e-06, 2.58492491e+00,
5.00000000e+00, -8.88178420e-16, 5.66426479e-17,
0.00000000e+00, 2.30000000e+01, 8.00000000e-02,
0.00000000e+00, 0.00000000e+00, 4.00000000e+00,
5.55555556e-02, 0.00000000e+00, 0.00000000e+00,
4.52016486e-11, 5.00000000e+00, 1.97770999e+00,
7.14285714e-01, 8.28571429e-01, 4.41786467e-01,
7.43561030e-06],
[ 1.06707589e-06, 5.06165512e-06, 9.40987016e-01,
4.00000000e+00, -8.88178420e-16, -1.18293308e-15,
0.00000000e+00, 1.20000000e+01, 1.23456790e-02,
0.00000000e+00, 0.00000000e+00, 3.00000000e+00,
1.00000000e-01, 0.00000000e+00, 0.00000000e+00,
8.22614633e-11, 6.00000000e+00, 2.16264604e+00,
8.28571429e-01, 3.42857143e-01, 7.36310778e-01,
1.43699941e-05, -1.24257183e-06, 1.42709096e-06,
2.94247757e+00, 3.00000000e+00, -8.88178420e-16,
-2.50000611e-16, 0.00000000e+00, 1.50000000e+01,
4.62962963e-03, 0.00000000e+00, 0.00000000e+00,
2.00000000e+00, 1.25000000e-01, 0.00000000e+00,
0.00000000e+00, 6.93500440e-11, 5.00000000e+00,
1.92542785e+00, 8.28571429e-01, 8.28571429e-01,
2.94524311e-01, 8.91888264e-06, -4.34236854e-06,
-1.88361756e-06, 2.63896118e+00, 4.00000000e+00,
-8.88178420e-16, -5.92485890e-16, 0.00000000e+00,
1.50000000e+01, 2.20385675e-02, 0.00000000e+00,
0.00000000e+00, 3.00000000e+00, 1.11111111e-01,
0.00000000e+00, 0.00000000e+00, 6.96738164e-11,
6.00000000e+00, 2.00650422e+00, 8.28571429e-01,
8.28571429e-01, 3.43611696e-01, 9.74783003e-06,
-3.57222777e-06, -5.38267251e-06, 3.04652712e+00,
1.10000000e+01, -8.88178420e-16, 4.38125672e-17,
0.00000000e+00, 1.40000000e+01, 5.10204082e-03,
0.00000000e+00, 0.00000000e+00, 5.00000000e+00,
1.42857143e-01, 0.00000000e+00, 0.00000000e+00,
4.00538711e-11, 7.00000000e+00, 2.04099986e+00,
7.71428571e-01, 2.00000000e-01, 3.43611696e-01,
6.30681363e-06],
[ 5.41709902e-06, 2.05431239e-06, 8.54785389e-01,
3.00000000e+00, -8.88178420e-16, -1.76750953e-15,
0.00000000e+00, 1.00000000e+01, 3.67309458e-03,
0.00000000e+00, 0.00000000e+00, 3.00000000e+00,
3.33333333e-01, 0.00000000e+00, 0.00000000e+00,
5.81324313e-11, 5.00000000e+00, 2.15525567e+00,
7.71428571e-01, 3.71428571e-01, 1.07992247e+00,
1.58005635e-05, -5.96238663e-07, 2.76329744e-06,
7.96695469e-01, 2.00000000e+00, -8.88178420e-16,
-5.99472331e-16, 0.00000000e+00, 9.00000000e+00,
1.93905817e-02, 0.00000000e+00, 0.00000000e+00,
1.00000000e+00, 2.00000000e-01, 0.00000000e+00,
0.00000000e+00, 3.29836877e-11, 5.00000000e+00,
2.14756047e+00, 8.00000000e-01, 8.28571429e-01,
1.27627202e+00, 1.12504263e-05, 5.73291371e-06,
2.48495087e-06, 1.59802527e+00, 4.00000000e+00,
-8.88178420e-16, -5.00682720e-16, 0.00000000e+00,
8.00000000e+00, 3.36700337e-03, 0.00000000e+00,
0.00000000e+00, 2.00000000e+00, 3.33333333e-01,
0.00000000e+00, 0.00000000e+00, 4.75743565e-11,
6.00000000e+00, 2.11236435e+00, 1.71428571e-01,
8.28571429e-01, 6.38136008e-01, 1.26219064e-05,
-1.88620306e-07, 1.45344422e-06, 1.46937513e+00,
5.00000000e+00, -8.88178420e-16, -3.32636878e-17,
0.00000000e+00, 1.70000000e+01, 5.20355066e-03,
0.00000000e+00, 0.00000000e+00, 2.00000000e+00,
3.33333333e-01, 0.00000000e+00, 0.00000000e+00,
2.18684364e-11, 5.00000000e+00, 2.03344937e+00,
1.71428571e-01, 8.28571429e-01, 6.38136008e-01,
7.81002358e-06]])
The order of the columns matches the feature_names list below for each channel.
from aeon.transformations.collection.feature_based._catch22 import feature_names
feature_names
['DN_HistogramMode_5', 'DN_HistogramMode_10', 'CO_f1ecac', 'CO_FirstMin_ac', 'CO_HistogramAMI_even_2_5', 'CO_trev_1_num', 'MD_hrv_classic_pnn40', 'SB_BinaryStats_mean_longstretch1', 'SB_TransitionMatrix_3ac_sumdiagcov', 'PD_PeriodicityWang_th0_01', 'CO_Embed2_Dist_tau_d_expfit_meandiff', 'IN_AutoMutualInfoStats_40_gaussian_fmmi', 'FC_LocalSimple_mean1_tauresrat', 'DN_OutlierInclude_p_001_mdrmd', 'DN_OutlierInclude_n_001_mdrmd', 'SP_Summaries_welch_rect_area_5_1', 'SB_BinaryStats_diff_longstretch0', 'SB_MotifThree_quantile_hh', 'SC_FluctAnal_2_rsrangefit_50_1_logi_prop_r1', 'SC_FluctAnal_2_dfa_50_1_2_logi_prop_r1', 'SP_Summaries_welch_rect_centroid', 'FC_LocalSimple_mean3_stderr']
The transform is configurable, and you can select a subset of the features to extract. The catch24 parameter will include the mean and standard deviation as well as the original 22 features.
use_pycatch22 will use the pycatch22 C-wrapped library by the original authors [5] to extract features if it is installed.
c22 = Catch22(
features=["DN_HistogramMode_5", "CO_f1ecac", "SB_MotifThree_quantile_hh", "Mean", "StandardDeviation"],
catch24=True,
)
c22.fit_transform(X_train_c)[:5]
array([[-4.94433107e-06, 2.98422388e+00, 2.00785293e+00,
-4.84662295e-06, 1.63624369e-05, 1.81815758e-06,
3.71562980e+00, 2.00199666e+00, 4.07268745e-07,
1.16629572e-05, -6.81925616e-06, 2.54465362e+00,
1.84997494e+00, -2.73869572e-06, 1.30628441e-05,
-4.28629432e-06, 2.25468230e+00, 1.94369228e+00,
-3.51260400e-06, 8.11090668e-06],
[-4.93347026e-07, 9.76550866e-01, 2.08655852e+00,
1.43118551e-06, 1.57514418e-05, 1.06128379e-06,
2.99539703e+00, 2.05946536e+00, 4.93131265e-06,
1.18989896e-05, -9.48719145e-06, 1.78980033e+00,
1.96831980e+00, -3.01206374e-06, 1.42330289e-05,
-2.88989693e-06, 2.21747187e+00, 2.04733206e+00,
-2.96546855e-06, 8.23176010e-06],
[-6.72778723e-06, 8.30813700e-01, 2.17460531e+00,
-6.06350354e-07, 1.33059491e-05, -1.44995057e-06,
7.17005807e-01, 2.16552480e+00, 3.79695308e-06,
1.00766877e-05, -1.83019499e-06, 2.41674894e+00,
1.94369228e+00, 3.37033758e-06, 1.24823971e-05,
-3.71330823e-06, 2.58492491e+00, 1.97770999e+00,
8.40880283e-07, 8.31148145e-06],
[ 1.06707589e-06, 9.40987016e-01, 2.16264604e+00,
-2.17892949e-07, 1.41719989e-05, -1.24257183e-06,
2.94247757e+00, 1.92542785e+00, -2.02235649e-06,
1.04135837e-05, -4.34236854e-06, 2.63896118e+00,
2.00650422e+00, -2.30261793e-06, 1.08641355e-05,
-3.57222777e-06, 3.04652712e+00, 2.04099986e+00,
-2.96036604e-06, 7.47429838e-06],
[ 5.41709902e-06, 8.54785389e-01, 2.15525567e+00,
3.07705341e-06, 1.41351503e-05, -5.96238663e-07,
7.96695469e-01, 2.14756047e+00, 8.81621473e-09,
1.01270483e-05, 5.73291371e-06, 1.59802527e+00,
2.11236435e+00, 2.83706608e-06, 1.17155555e-05,
-1.88620306e-07, 1.46937513e+00, 2.03344937e+00,
-8.22774051e-07, 7.29112178e-06]])
Classification and regression with Catch22 ¶
The Catch22Classifier and Catch22Regressor classes in aeon are simply convenient wrappers for a pipeline of a Catch22 transformation and a scikit-learn Random Forest by default.
from aeon.classification.feature_based import Catch22Classifier
from sklearn.metrics import accuracy_score
c22_cls = Catch22Classifier(random_state=42)
c22_cls.fit(X_train_c, y_train_c)
c22_preds_c = c22_cls.predict(X_test_c)
accuracy_score(y_test_c, c22_preds_c)
0.875
The estimators are also configurable like the Catch22 transformation. The estimator parameter is the estimator to use after transforming the features.
from aeon.classification.sklearn import RotationForestClassifier
c22_cls = Catch22Classifier(
features=["DN_HistogramMode_5", "CO_f1ecac", "SB_MotifThree_quantile_hh", "Mean", "StandardDeviation"],
estimator=RotationForestClassifier(),
random_state=42,
)
c22_cls.fit(X_train_c, y_train_c)
c22_preds_c = c22_cls.predict(X_test_c)
accuracy_score(y_test_c, c22_preds_c)
0.9
Regression is run similarly to classification.
from aeon.regression.feature_based import Catch22Regressor
from sklearn.metrics import mean_squared_error
c22_reg = Catch22Regressor(random_state=42)
c22_reg.fit(X_train_r, y_train_r)
c22_preds_r = c22_reg.predict(X_test_r)
mean_squared_error(y_test_r, c22_preds_r)
0.8063179977398083
from aeon.visualisation import plot_scatter_predictions
plot_scatter_predictions(y_test_r, c22_preds_r)
(<Figure size 600x600 with 1 Axes>, <Axes: xlabel='Actual values', ylabel='Predicted values'>)

TSFresh ¶
Time series feature extraction based on scalable hypothesis tests (TSFresh) [6] is a collection of just under 800 features extracted from time series. The aeon implementation is a wrapper of the tsfresh package, and we recommend exploring the original packages documentation for more information on the feature extraction process [7].
Note: You will need to pip install tsfresh to run this code.

Transforming TSFresh ¶
There are two aeon transformation classes for TSFresh. TSFreshFeatureExtractor extracts all features, while TSFreshRelevantFeatureExtractor extracts only the features that are relevant to the target class using the FRESH algorithm for selection.
from aeon.transformations.collection.feature_based import TSFreshFeatureExtractor
tsf = TSFreshFeatureExtractor()
t = tsf.fit_transform(X_train_c)
t.shape
(40, 3108)
t[:5]
| dim_0__variance_larger_than_standard_deviation | dim_0__has_duplicate_max | dim_0__has_duplicate_min | dim_0__has_duplicate | dim_0__sum_values | dim_0__abs_energy | dim_0__mean_abs_change | dim_0__mean_change | dim_0__mean_second_derivative_central | dim_0__median | ... | dim_3__fourier_entropy__bins_5 | dim_3__fourier_entropy__bins_10 | dim_3__fourier_entropy__bins_100 | dim_3__permutation_entropy__dimension_3__tau_1 | dim_3__permutation_entropy__dimension_4__tau_1 | dim_3__permutation_entropy__dimension_5__tau_1 | dim_3__permutation_entropy__dimension_6__tau_1 | dim_3__permutation_entropy__dimension_7__tau_1 | dim_3__query_similarity_count__query_None__threshold_0.0 | dim_3__mean_n_absolute_max__number_of_maxima_7 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | -0.000485 | 2.912191e-08 | 0.000011 | -4.244711e-07 | -1.451001e-07 | -4.164925e-06 | ... | 0.604187 | 1.009315 | 2.606830 | 1.755124 | 2.994032 | 3.931499 | 4.382343 | 4.513799 | 0.0 | 0.000021 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000143 | 2.501562e-08 | 0.000014 | 2.639171e-07 | 1.753673e-07 | 1.715701e-07 | ... | 0.585488 | 0.918126 | 2.513214 | 1.741437 | 2.937030 | 3.844856 | 4.367750 | 4.513799 | 0.0 | 0.000019 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | -0.000061 | 1.774159e-08 | 0.000013 | 1.566731e-07 | 1.023780e-07 | -1.006102e-06 | ... | 0.668774 | 0.973848 | 2.045156 | 1.763806 | 2.976764 | 3.956539 | 4.301941 | 4.499051 | 0.0 | 0.000017 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | -0.000022 | 2.008930e-08 | 0.000013 | 1.000790e-07 | 5.408120e-08 | 1.008918e-06 | ... | 0.451359 | 0.668811 | 1.980581 | 1.753098 | 2.969286 | 3.878165 | 4.323973 | 4.528547 | 0.0 | 0.000017 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000308 | 2.092707e-08 | 0.000013 | -1.980526e-08 | -3.690645e-08 | 2.785934e-06 | ... | 0.719063 | 1.125483 | 2.868121 | 1.728968 | 2.984151 | 3.981462 | 4.353158 | 4.463989 | 0.0 | 0.000015 |
5 rows × 3108 columns
There are multiple feature sets to extract, and functionality to extract specific features from them. The available feature sets are:"minimal". "efficient" and "comprehensive".
from aeon.transformations.collection.feature_based import TSFreshFeatureExtractor
tsf = TSFreshFeatureExtractor(default_fc_parameters="minimal")
t = tsf.fit_transform(X_train_c)
t.shape
(40, 40)
t[:5]
| dim_0__sum_values | dim_0__median | dim_0__mean | dim_0__length | dim_0__standard_deviation | dim_0__variance | dim_0__root_mean_square | dim_0__maximum | dim_0__absolute_maximum | dim_0__minimum | ... | dim_3__sum_values | dim_3__median | dim_3__mean | dim_3__length | dim_3__standard_deviation | dim_3__variance | dim_3__root_mean_square | dim_3__maximum | dim_3__absolute_maximum | dim_3__minimum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.000485 | -4.164925e-06 | -4.846623e-06 | 100.0 | 0.000016 | 2.677293e-10 | 0.000017 | 0.000035 | 0.000045 | -0.000045 | ... | -0.000351 | -3.579710e-06 | -3.512604e-06 | 100.0 | 0.000008 | 6.578681e-11 | 0.000009 | 0.000018 | 0.000026 | -0.000026 |
| 1 | 0.000143 | 1.715701e-07 | 1.431186e-06 | 100.0 | 0.000016 | 2.481079e-10 | 0.000016 | 0.000039 | 0.000040 | -0.000040 | ... | -0.000297 | -4.337629e-06 | -2.965469e-06 | 100.0 | 0.000008 | 6.776187e-11 | 0.000009 | 0.000017 | 0.000023 | -0.000023 |
| 2 | -0.000061 | -1.006102e-06 | -6.063504e-07 | 100.0 | 0.000013 | 1.770483e-10 | 0.000013 | 0.000035 | 0.000035 | -0.000025 | ... | 0.000084 | -3.052855e-07 | 8.408803e-07 | 100.0 | 0.000008 | 6.908072e-11 | 0.000008 | 0.000020 | 0.000020 | -0.000014 |
| 3 | -0.000022 | 1.008918e-06 | -2.178929e-07 | 100.0 | 0.000014 | 2.008456e-10 | 0.000014 | 0.000041 | 0.000041 | -0.000039 | ... | -0.000296 | -3.339466e-06 | -2.960366e-06 | 100.0 | 0.000007 | 5.586514e-11 | 0.000008 | 0.000015 | 0.000022 | -0.000022 |
| 4 | 0.000308 | 2.785934e-06 | 3.077053e-06 | 100.0 | 0.000014 | 1.998025e-10 | 0.000014 | 0.000039 | 0.000039 | -0.000028 | ... | -0.000082 | -2.210128e-08 | -8.227741e-07 | 100.0 | 0.000007 | 5.316046e-11 | 0.000007 | 0.000016 | 0.000017 | -0.000017 |
5 rows × 40 columns
The FRESH algorithm can be used for feature extraction with TSFreshRelevantFeatureExtractor.
from aeon.transformations.collection.feature_based import TSFreshRelevantFeatureExtractor
tsf = TSFreshRelevantFeatureExtractor()
t = tsf.fit_transform(X_train_c, y_train_c)
t.shape
(40, 266)
t[:5]
| dim_1__change_quantiles__f_agg_"var"__isabs_True__qh_1.0__ql_0.0 | dim_0__change_quantiles__f_agg_"var"__isabs_False__qh_1.0__ql_0.6 | dim_3__absolute_sum_of_changes | dim_0__change_quantiles__f_agg_"mean"__isabs_True__qh_0.8__ql_0.0 | dim_0__cid_ce__normalize_False | dim_0__change_quantiles__f_agg_"mean"__isabs_True__qh_1.0__ql_0.4 | dim_0__change_quantiles__f_agg_"var"__isabs_False__qh_1.0__ql_0.4 | dim_2__change_quantiles__f_agg_"var"__isabs_False__qh_1.0__ql_0.2 | dim_2__change_quantiles__f_agg_"mean"__isabs_True__qh_1.0__ql_0.2 | dim_2__change_quantiles__f_agg_"var"__isabs_True__qh_1.0__ql_0.2 | ... | dim_2__cwt_coefficients__coeff_5__w_20__widths_(2, 5, 10, 20) | dim_0__agg_linear_trend__attr_"intercept"__chunk_len_50__f_agg_"max" | dim_2__cwt_coefficients__coeff_6__w_20__widths_(2, 5, 10, 20) | dim_3__friedrich_coefficients__coeff_2__m_3__r_30 | dim_2__cwt_coefficients__coeff_4__w_20__widths_(2, 5, 10, 20) | dim_1__fft_coefficient__attr_"real"__coeff_4 | dim_2__cwt_coefficients__coeff_3__w_20__widths_(2, 5, 10, 20) | dim_1__time_reversal_asymmetry_statistic__lag_1 | dim_1__ratio_beyond_r_sigma__r_3 | dim_3__fft_coefficient__attr_"real"__coeff_6 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.239400e-11 | 1.110965e-10 | 0.000490 | 0.000010 | 0.000143 | 0.000009 | 1.296300e-10 | 7.058283e-11 | 0.000006 | 3.284806e-11 | ... | -0.000020 | 0.000035 | -0.000021 | -0.321405 | -0.000019 | -0.000014 | -0.000018 | 1.758128e-16 | 0.00 | 0.000144 |
| 1 | 5.052751e-11 | 1.402973e-10 | 0.000511 | 0.000011 | 0.000178 | 0.000011 | 2.038325e-10 | 8.934084e-11 | 0.000008 | 2.847982e-11 | ... | -0.000034 | 0.000033 | -0.000034 | -0.282894 | -0.000034 | -0.000021 | -0.000033 | -2.386514e-17 | 0.01 | 0.000118 |
| 2 | 8.231264e-11 | 1.749121e-10 | 0.000523 | 0.000010 | 0.000163 | 0.000011 | 1.738075e-10 | 7.956791e-11 | 0.000007 | 3.095846e-11 | ... | -0.000031 | 0.000035 | -0.000033 | -0.377012 | -0.000029 | -0.000013 | -0.000027 | 2.905208e-16 | 0.01 | 0.000119 |
| 3 | 2.427724e-11 | 1.638219e-10 | 0.000433 | 0.000011 | 0.000164 | 0.000009 | 1.443568e-10 | 5.867686e-11 | 0.000006 | 2.568302e-11 | ... | -0.000032 | 0.000041 | -0.000033 | -0.327350 | -0.000031 | 0.000119 | -0.000029 | 5.227201e-17 | 0.00 | 0.000079 |
| 4 | 7.710235e-11 | 1.095492e-10 | 0.000544 | 0.000011 | 0.000172 | 0.000010 | 1.649341e-10 | 9.028433e-11 | 0.000008 | 3.073530e-11 | ... | -0.000012 | 0.000039 | -0.000011 | -0.415386 | -0.000013 | 0.000095 | -0.000013 | 1.648984e-16 | 0.02 | 0.000071 |
5 rows × 266 columns
Classification and regression with TSFresh ¶
Like the previous feature transforms, the TSFreshClassifier and TSFreshRegressor classes in aeon are wrappers for a pipeline of a TSFreshFeatureExtractor transformation and a scikit-learn Random Forest by default. The default setting is to use the "efficient" feature set with feature selection.
from aeon.classification.feature_based import TSFreshClassifier
from sklearn.metrics import accuracy_score
tsf_cls = TSFreshClassifier(random_state=42)
tsf_cls.fit(X_train_c, y_train_c)
tsf_preds_c = tsf_cls.predict(X_test_c)
accuracy_score(y_test_c, tsf_preds_c)
0.875
Feature selection and feature sets to extract can be configured for the TSFresh transformer.
tsf_cls = TSFreshClassifier(
default_fc_parameters="minimal",
relevant_feature_extractor=False,
random_state=42
)
tsf_cls.fit(X_train_c, y_train_c)
tsf_preds_c = tsf_cls.predict(X_test_c)
accuracy_score(y_test_c, tsf_preds_c)
0.775
Regression is run similarly to classification, with feature selection available for both learning tasks.
from aeon.regression.feature_based import TSFreshRegressor
tsf_reg = TSFreshRegressor(random_state=42)
tsf_reg.fit(X_train_r, y_train_r)
tsf_preds_r = tsf_reg.predict(X_test_r)
mean_squared_error(y_test_r, tsf_preds_r)
0.6645977964288085
from aeon.visualisation import plot_scatter_predictions
plot_scatter_predictions(y_test_r, tsf_preds_r)
(<Figure size 600x600 with 1 Axes>, <Axes: xlabel='Actual values', ylabel='Predicted values'>)

from aeon.classification.feature_based import FreshPRINCEClassifier
from sklearn.metrics import accuracy_score
fp = FreshPRINCEClassifier(n_estimators=100, random_state=42)
fp.fit(X_train_c, y_train_c)
fp_preds = fp.predict(X_test_c)
accuracy_score(y_test_c, fp_preds)
0.925
Performance on the UCR univariate classification datasets ¶
Below we show the performance of the Catch22Classifier, TSFreshClassifier and FreshPRINCEClassifier pipelines on the UCR TSC archive datasets [4] using results from a large scale comparison of TSC algorithms [10]. The results files are stored on timeseriesclassification.com.
from aeon.benchmarking import get_estimator_results_as_array
from aeon.datasets.tsc_datasets import univariate
names = ["Catch22", "TSFresh", "FreshPRINCE", "1NN-DTW"]
results, present_names = get_estimator_results_as_array(
names, univariate, include_missing=False
)
results.shape
(112, 4)
import numpy as np
np.mean(results, axis=0)
array([0.78136831, 0.78275687, 0.84159997, 0.74206624])
from aeon.visualisation import plot_critical_difference
plot_critical_difference(results, names)
(<Figure size 600x230 with 1 Axes>, <Axes: >)

from aeon.visualisation import plot_boxplot_median
plot_boxplot_median(results, names, plot_type="boxplot")
(<Figure size 1000x600 with 1 Axes>, <Axes: >)

Composable pipelines ¶
The majority of feature-based approaches (and all the ones demonstrated here) take the form of a simple pipeline estimator. Both aeon and scikit-learn provide composable utilities for building these pipelines using selected transformations and learners.
aeon pipelines ¶
aeon pipelines are built using the make_pipeline function, the same as scikit-learn. This function takes a list of transformations and a final estimator. The transformations are applied in order to the input data, and the final estimator is trained on the transformed data.
The follow example z-normalises the time series, extracts Catch22 features and trains a Random Forest classifier.
from aeon.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from aeon.transformations.collection.feature_based import Catch22
from aeon.transformations.collection.scaler import TimeSeriesScaler
from sklearn.metrics import accuracy_score
pipe = make_pipeline(
TimeSeriesScaler(),
Catch22(replace_nans=True),
RandomForestClassifier(random_state=42)
)
pipe.fit(X_train_c, y_train_c)
pipe_preds = pipe.predict(X_test_c)
accuracy_score(y_test_c, pipe_preds)
0.7
The same function applied for regression.
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
pipe = make_pipeline(
TimeSeriesScaler(),
Catch22(replace_nans=True),
RandomForestRegressor(random_state=42)
)
pipe.fit(X_train_r, y_train_r)
pipe_preds = pipe.predict(X_test_r)
mean_squared_error(y_test_r, pipe_preds)
1.0100860998604486
scikit-learn pipelines ¶
The scikit-learn make_pipeline function can also be used. The following example extracts both the Catch22 features simple summary statistics then trains a Random Forest classifier.
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier
from aeon.transformations.collection.feature_based import Catch22
from aeon.transformations.collection.feature_based import SevenNumberSummaryTransformer
from sklearn.pipeline import FeatureUnion
pipe = make_pipeline(
FeatureUnion([("C22", Catch22(replace_nans=True)), ("SNS", SevenNumberSummaryTransformer())]),
RandomForestClassifier(random_state=42)
)
pipe.fit(X_train_c, y_train_c)
pipe_preds = pipe.predict(X_test_c)
accuracy_score(y_test_c, pipe_preds)
0.9
References ¶
[1] Fulcher, Ben D., and Nick S. Jones. "hctsa: A computational framework for automated time-series phenotyping using massive feature extraction." Cell systems 5.5 (2017): 527-531.
[2] https://github.com/benfulcher/hctsa
[3] Lubba, Carl H., et al. "catch22: CAnonical Time-series CHaracteristics: Selected through highly comparative time-series analysis." Data Mining and Knowledge Discovery 33.6 (2019): 1821-1852.
[4] Dau, Hoang Anh, et al. "The UCR time series archive." IEEE/CAA Journal of Automatica Sinica 6.6 (2019): 1293-1305.
[5] https://github.com/DynamicsAndNeuralSystems/pycatch22
[6] Christ, Maximilian, et al. "Time series feature extraction on basis of scalable hypothesis tests (tsfresh–a python package)." Neurocomputing 307 (2018): 72-77.
[7] https://github.com/blue-yonder/tsfresh
[8] Middlehurst, Matthew, and Anthony Bagnall. "The freshprince: A simple transformation based pipeline time series classifier." International Conference on Pattern Recognition and Artificial Intelligence. Cham: Springer International Publishing, 2022.
[9] Rodriguez, Juan José, Ludmila I. Kuncheva, and Carlos J. Alonso. "Rotation forest: A new classifier ensemble method." IEEE transactions on pattern analysis and machine intelligence 28.10 (2006): 1619-1630.
[10] Middlehurst, Matthew, Patrick Schäfer, and Anthony Bagnall. "Bake off redux: a review and experimental evaluation of recent time series classification algorithms." Data Mining and Knowledge Discovery (2024): 1-74.