In [ ]:
%pip install llama-index
设置¶
In [ ]:
import os
os.environ["OPENAI_API_KEY"] = "sk-proj-..."
In [ ]:
!mkdir -p 'data/paul_graham/'
!wget 'https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt' -O 'data/paul_graham/paul_graham_essay.txt'
In [ ]:
import nest_asyncio
nest_asyncio.apply()
In [ ]:
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data/paul_graham/").load_data()
构造¶
In [ ]:
from llama_index.core import PropertyGraphIndex
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
index = PropertyGraphIndex.from_documents(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
show_progress=True,
)
/Users/loganmarkewich/Library/Caches/pypoetry/virtualenvs/llama-index-bXUwlEfH-py3.11/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html from .autonotebook import tqdm as notebook_tqdm Parsing nodes: 100%|██████████| 1/1 [00:00<00:00, 25.46it/s] Extracting paths from text: 100%|██████████| 22/22 [00:12<00:00, 1.72it/s] Extracting implicit paths: 100%|██████████| 22/22 [00:00<00:00, 36186.15it/s] Generating embeddings: 100%|██████████| 1/1 [00:00<00:00, 1.14it/s] Generating embeddings: 100%|██████████| 5/5 [00:00<00:00, 5.43it/s]
让我们回顾一下刚刚发生了什么
PropertyGraphIndex.from_documents()- 我们将文档加载到了索引中Parsing nodes- 索引将文档解析为节点Extracting paths from text- 节点被传递给LLM,LLM被提示生成知识图三元组(即路径)Extracting implicit paths- 每个node.relationships属性被用来推断隐含路径Generating embeddings- 为每个文本节点和图节点生成了嵌入(因此这个过程发生了两次)
让我们来探索一下我们创建的内容!为了调试目的,默认的SimplePropertyGraphStore包括一个辅助功能,可以将图的networkx表示保存到一个html文件中。
In [ ]:
index.property_graph_store.save_networkx_graph(name="./kg.html")
在浏览器中打开这个html文件,我们就可以看到我们的图表了!
如果你放大图表,你会发现每个连接密集的节点实际上是源块,从那里分支出提取的实体和关系。
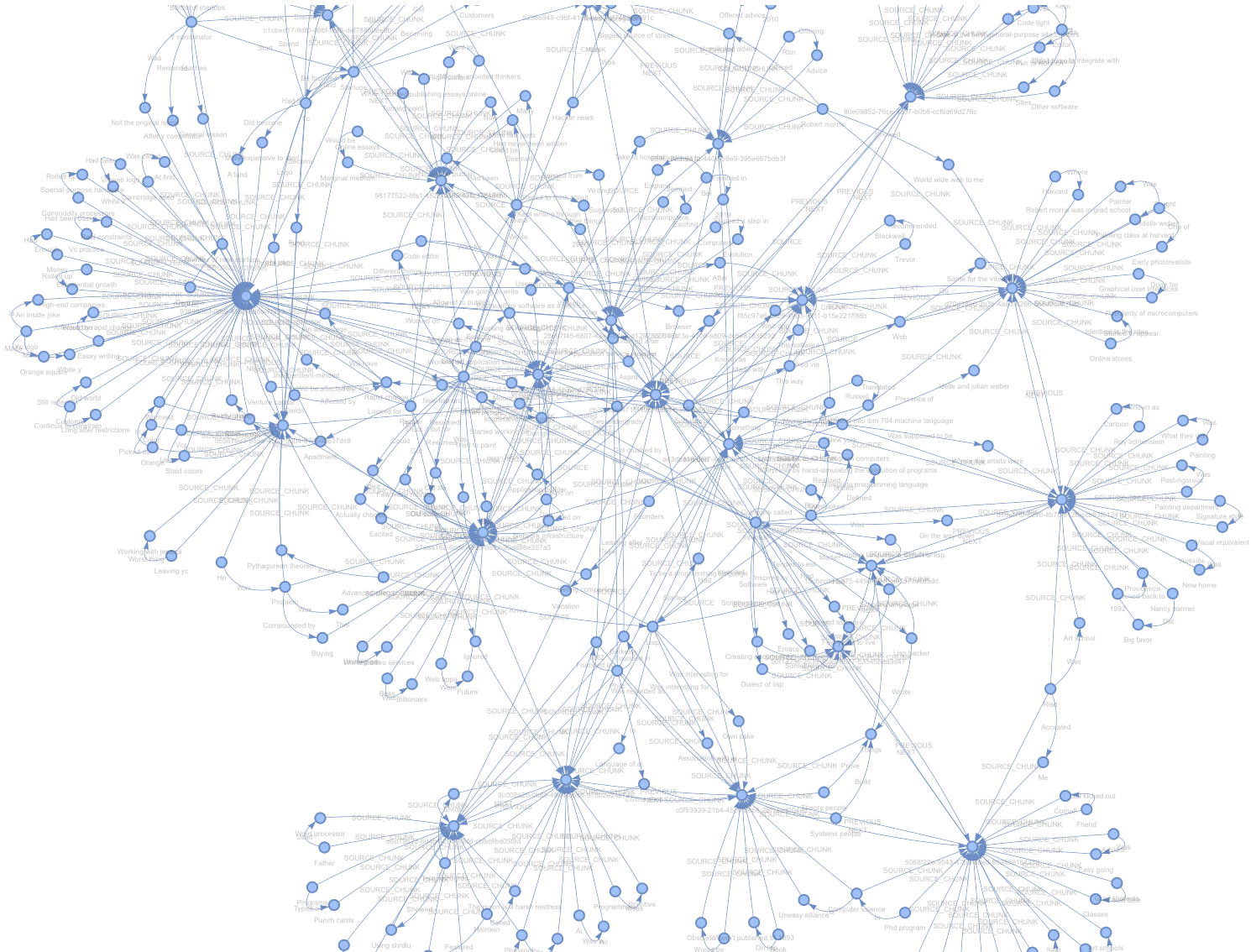
自定义低级构建¶
如果我们愿意,我们可以使用低级API来进行相同的摄取,利用kg_extractors。
In [ ]:
from llama_index.core.indices.property_graph import (
ImplicitPathExtractor,
SimpleLLMPathExtractor,
)
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
kg_extractors=[
ImplicitPathExtractor(),
SimpleLLMPathExtractor(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
num_workers=4,
max_paths_per_chunk=10,
),
],
show_progress=True,
)
有关所有提取器的完整指南,请参阅详细使用页面。
查询¶
查询属性图索引通常包括使用一个或多个子检索器并组合结果。
图检索可以被认为是
- 选择节点
- 从这些节点遍历
默认情况下,联合使用两种类型的检索
- 同义词/关键词扩展 - 使用LLM生成查询的同义词和关键词
- 向量检索 - 使用嵌入来在图中查找节点
一旦找到节点,您可以选择
- 返回与所选节点相邻的路径(即三元组)
- 返回路径+块的原始源文本(如果可用)
In [ ]:
# 创建一个索引检索器,不包括文本,默认为Trueretriever = index.as_retriever( include_text=False, )# 检索“What happened at Interleaf and Viaweb?”nodes = retriever.retrieve("What happened at Interleaf and Viaweb?")# 遍历检索结果并打印文本for node in nodes: print(node.text)
Interleaf -> Was -> On the way down Viaweb -> Had -> Code editor Interleaf -> Built -> Impressive technology Interleaf -> Added -> Scripting language Interleaf -> Made -> Scripting language Viaweb -> Suggested -> Take to hospital Interleaf -> Had done -> Something bold Viaweb -> Called -> After Interleaf -> Made -> Dialect of lisp Interleaf -> Got crushed by -> Moore's law Dan giffin -> Worked for -> Viaweb Interleaf -> Had -> Smart people Interleaf -> Had -> Few years to live Interleaf -> Made -> Software Interleaf -> Made -> Software for creating documents Paul graham -> Started -> Viaweb Scripting language -> Was -> Dialect of lisp Scripting language -> Is -> Dialect of lisp Software -> Will be affected by -> Rapid change Code editor -> Was -> In viaweb Software -> Worked via -> Web Programs -> Typed on -> Punch cards Computers -> Skipped -> Step Idea -> Was clear from -> Experience Apartment -> Wasn't -> Rent-controlled
In [ ]:
query_engine = index.as_query_engine(
include_text=True,
)
response = query_engine.query("What happened at Interleaf and Viaweb?")
print(str(response))
Interleaf had smart people and built impressive technology, including adding a scripting language that was a dialect of Lisp. However, despite their efforts, they were eventually impacted by Moore's Law and faced challenges. Viaweb, on the other hand, was started by Paul Graham and had a code editor where users could define their own page styles using Lisp expressions. Viaweb also suggested taking someone to the hospital and called something "After."
有关自定义检索和查询的详细信息,请参阅文档页面。
存储¶
默认情况下,使用我们简单的内存抽象进行存储 - SimpleVectorStore 用于嵌入,SimplePropertyGraphStore 用于属性图。
我们可以将这些存储到磁盘并从磁盘加载。
In [ ]:
index.storage_context.persist(persist_dir="./storage")
from llama_index.core import StorageContext, load_index_from_storage
index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./storage")
)
向量存储¶
虽然一些图数据库支持向量(比如Neo4j),但在一些不支持向量的情况下,或者你想要覆盖默认设置时,你仍然可以指定要在图上使用的向量存储。
下面我们将把 ChromaVectorStore 与默认的 SimplePropertyGraphStore 结合起来使用。
In [ ]:
%pip install llama-index-vector-stores-chroma
In [ ]:
from llama_index.core.graph_stores import SimplePropertyGraphStore
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
client = chromadb.PersistentClient("./chroma_db")
collection = client.get_or_create_collection("my_graph_vector_db")
index = PropertyGraphIndex.from_documents(
documents,
embed_model=OpenAIEmbedding(model_name="text-embedding-3-small"),
graph_store=SimplePropertyGraphStore(),
vector_store=ChromaVectorStore(collection=collection),
show_progress=True,
)
index.storage_context.persist(persist_dir="./storage")
然后进行加载:
In [ ]:
index = PropertyGraphIndex.from_existing(
SimplePropertyGraphStore.from_persist_dir("./storage"),
vector_store=ChromaVectorStore(collection=collection),
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3),
)
这看起来与纯粹使用存储上下文略有不同,但现在语法更加简洁,因为我们开始混合使用各种功能。