Exercise 10- CostSensitive Churn¶
Customer churn predictive modeling deals with predicting the probability of a customer defecting using historical, behavioral and socio-economical information. This tool is of great benefit to subscription based companies allowing them to maximize the results of retention campaigns. The problem of churn predictive modeling has been widely studied by the data mining and machine learning communities. It is usually tackled by using classification algorithms in order to learn the different patterns of both the churners and non-churners. Nevertheless, current state-of-the-art classification algorithms are not well aligned with commercial goals, in the sense that, the models miss to include the real financial costs and benefits during the training and evaluation phases. In the case of churn, evaluating a model based on a traditional measure such as accuracy or predictive power, does not yield to the best results when measured by the actual financial cost, i.e., investment per subscriber on a loyalty campaign and the financial impact of failing to detect a real churner versus wrongly predicting a non-churner as a churner.
The two main objectives of subscription-based companies are to acquire new subscribers and retain those they already have, mainly because profits are directly linked with the number of subscribers. In order to maximize the profit, companies must increase the customer base by incrementing sales while decreasing the number of churners. Furthermore, it is common knowledge that retaining a customer is about five times less expensive than acquiring a new one , this creates pressure to have better and more effective churn campaigns.
A typical churn campaign consists in identifying from the current customer base which ones are more likely to leave the company, and make an offer in order to avoid that behavior. With this in mind the companies use intelligence to create and improve retention and collection strategies. In the first case, this usually implies an offer that can be either a discount or a free upgrade during certain span of time. In both cases the company has to assume a cost for that offer, therefore, accurate prediction of the churners becomes important. The logic of this flow is shown in the following figure.
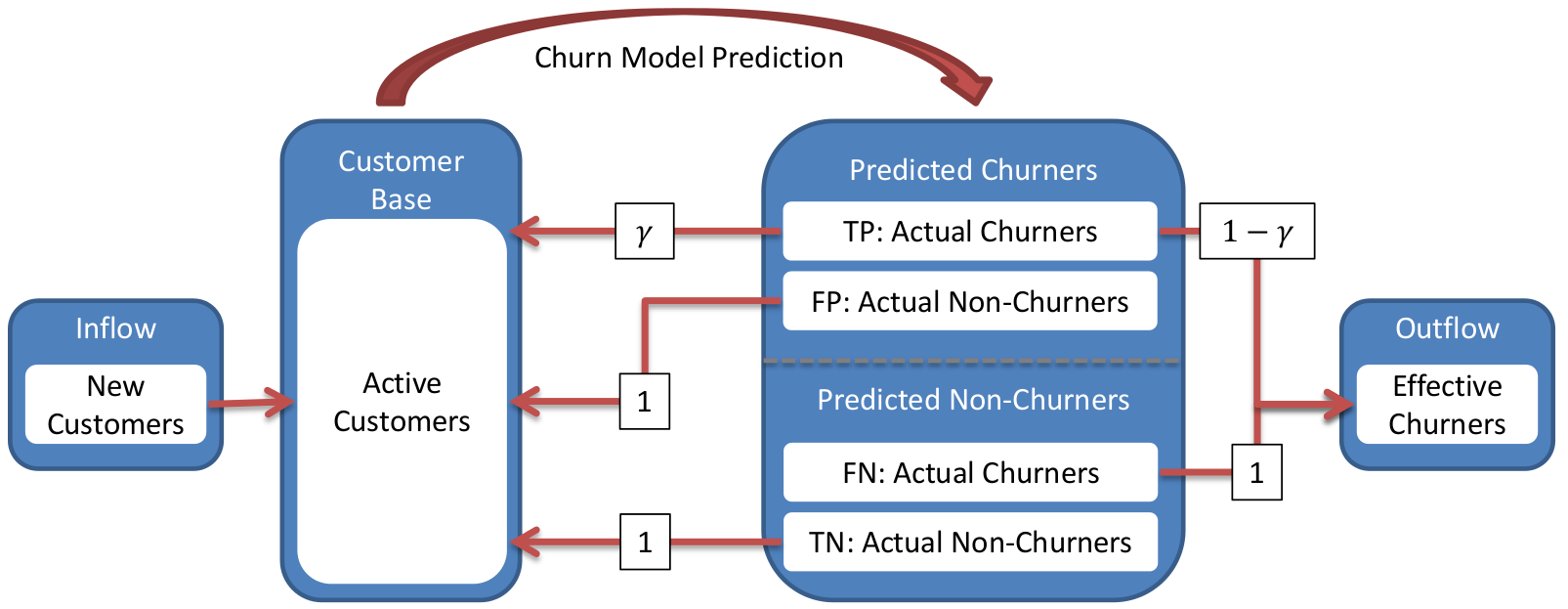
The churn campaign process starts with the sales that every month increase the customer base, however, monthly there is a group of customers that decide to leave the company for many reasons. Then the objective of a churn model is to identify those customers before they take the decision of defecting.
Using a churn model, those customers more likely to leave are predicted as churners and an offer is made in order to retain them. However, it is known that not all customers will accept the offer, in the case when a customer is planning to defect, it is possible that the offer is not good enough to retain him or that the reason for defecting can not be influenced by an offer. Using historical information, it is estimated that a customer will accept the offer with probability $\gamma$. On the other hand, there is the case in which the churn model misclassified a non-churner as churner, also known as false positives, in that case the customer will always accept the offer that means and additional cost to the company since those misclassified customers do not have the intentions of leaving.
In the case were the churn model predicts customers as non-churners, there is also the possibility of a misclassification, in this case an actual churner is predicted as non-churner, since these customers do not receive an offer and they will leave the company, these cases are known as false negatives. Lastly, there is the case were the customers are actually non-churners, then there is no need to make a retention offer to these customers since they will continue to be part of the customer base.
It can be seen that a churn campaign (or churn model) has three main points. First, avoid false positives since there is a financial cost of making an offer where it is not needed. Second, find the right offer to give to those customers identified as churners. And lastly, to decrease the number of false negatives.
In the following figure, the financial impact of a churn model is shown.
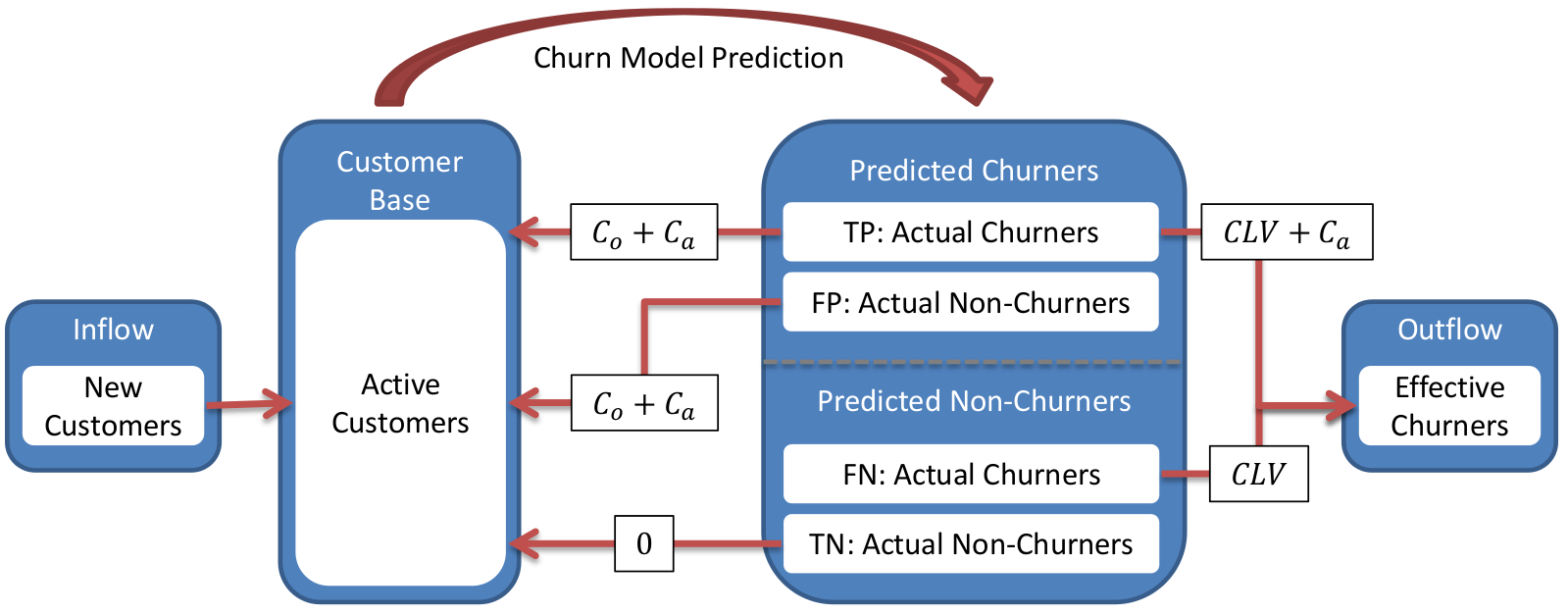
Note than we take
into account the costs and not the profit in each case.
When a customer is predicted to be a churner, an offer is made with the objective of avoiding
the customer defecting. However, if a customer is actually a churner, he may or not accept the
offer with a probability $\gamma_i$. If the customer accepts the offer, the financial impact is
equal to the cost of the offer ($C_{o_i}$) plus the administrative cost of contacting the
customer ($C_a$). On the other hand, if the customer declines the offer, the cost is the
expected income that the clients would otherwise generate, also called customer lifetime value
($CLV_i$), plus $C_a$. Lastly, if the customer is not actually a churner, he will be happy to
accept the offer and the cost will be $C_{o_i}$ plus $C_a$.
In the case that the customer is predicted as non-churner, there are two possible outcomes.
Either the customer is not a churner, then the cost is zero, or the customer is a churner and the
cost is $CLV_i$.
| | Actual Positive ($y_i=1$) | Actual Negative ($y_i=0$)| |--- |:-: |:-: | | Predicted Positive ($c_i=1$) | $C_{TP_i}=\gamma_iC_{o_i}+(1-\gamma_i)(CLV_i+C_a)$ | $C_{FP_i}=C_{o_i}+C_a$ | | Predicted Negative ($c_i=0$) | $C_{FN_i}=CLV_i$ | $C_{TN_i}=0$ |
import pandas as pd
import numpy as np
import zipfile
with zipfile.ZipFile('../datasets/cost_sensitive_classification_churn.csv.zip', 'r') as z:
f = z.open('cost_sensitive_classification_churn.csv')
data = pd.read_csv(f, index_col=0)
data.head()
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | x10 | ... | x42 | x43 | x44 | x45 | x46 | C_FP | C_FN | C_TP | C_TN | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| 0 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | ... | 1.0 | 1.0 | 5.0 | 2.0 | 2.0 | 74.000000 | 1028.571429 | 121.828571 | 0.0 | 0.0 |
| 1 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | ... | 3.0 | 1.0 | 5.0 | 2.0 | 4.0 | 53.428571 | 1028.571429 | 82.742857 | 0.0 | 0.0 |
| 2 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | ... | 1.0 | 8.0 | 3.0 | 1.0 | 4.0 | 66.285714 | 1285.714286 | 102.928571 | 0.0 | 0.0 |
| 3 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | ... | 1.0 | 8.0 | 4.0 | 3.0 | 2.0 | 92.000000 | 1285.714286 | 151.785714 | 0.0 | 0.0 |
| 4 | 0.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 1.0 | ... | 1.0 | 7.0 | 5.0 | 2.0 | 4.0 | 53.428571 | 1028.571429 | 82.742857 | 0.0 | 0.0 |
5 rows × 51 columns
data.target.value_counts(normalize=True)
0.0 0.952127 1.0 0.047873 Name: target, dtype: float64
X =data[['x'+str(i) for i in range(1, 47)]]
y = data.target
cost_mat = data[['C_FP','C_FN','C_TP','C_TN']].values
from sklearn.cross_validation import train_test_split
temp = train_test_split(X, y, cost_mat, test_size=0.33, random_state=42)
X_train, X_test, y_train, y_test, cost_mat_train, cost_mat_test = temp
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20. "This module will be removed in 0.20.", DeprecationWarning)
Exercice 10.1¶
- Train 4 different models to predict target (Churn) using x1-x46 as features
- Logistic Regression
- Ensemble
- Under-sampling LR
- Under-sampling Ensemble
Exercice 10.2¶
- Calculate the savings of the different models
- Compare F1Score and Savings
Exercice 10.3¶
Using the probabilities of each model estimate a BMR classifier
Compare the savings and F1Score
Exercice 10.4¶
Estimate a CostSensitiveDecisionTreeClassifier