Creative Commons CC-BY 4.0, code under MIT license (c) 2016 Pi-Yueh Chuang, L. A. Barba¶
Using AmgX to Accelerate PETSc-Based CFD Codes¶
Pi-Yueh Chuang & Lorena A. Barba, George Washington University.
This technical report supplements the presentation by Pi-Yueh Chuang at the 2016 GPU Technology Conference, on Thu. April 7th: see session S6355.
Introduction¶
PetIBM is a parallel code to study flow around immersed bodies, solving the Navier-Stokes equations on a Cartesian mesh. The body can be embedded in the fluid mesh via the so-called immersed boundary method (IBM), which brings many advantages in regards to mesh generation. The equations are discretized with a finite-difference scheme, via a pressure-projection method, resulting in a Poisson-like linear system. PetIBM uses the PETSc library to solve the linear system of equations in parallel on CPU hardware, and now we want to accelerate it with the help of GPU computing.
Our group previously developed another code, cuIBM, which implements the same methods as PetIBM, except that it runs on a sigle CPU and a single GPU, using the CUSP library to solve the linear system. The limited memory on a single GPU restricts the size of CFD problems that we can solve using cuIBM to about 4 million mesh points. In three dimensions, we often need to solve larger problems, which led us to develop PetIBM. Our next step was to add the capability of exploiting multi-GPU systems.
In this work, we set out to accelerate PetIBM using the NVIDIA AmgX library on multi-GPUs. We wrote a wrapper code to couple AmgX and PETSc, so that we require few modifications in PetIBM. Our AmgX wrapper is able to handle the situation where the PETSc-based code launches more MPI processes than the number of GPUs available, achieving heterogeneous speed-up. It is open source and we hope others may find it useful to accelerate their PETSc-based parallel programs with multiple GPUs.
Warning!¶
In some of the results presented here, we talk about a "speed-up" obtained when using GPU computing. Please note, this refers to application speed-up from using the solution methods of the AmgX library on GPUs, compared to obtaining the same solution with the PETSc library on CPUs.
The present work is not a code port and therefore you should not be looking at those speed-ups and wondering how they are compatible with the peak-to-peak bandwidth specifications of the hardware.
To be clear: we are not comparing the same code on CPU and GPU. We make no claims of an "apples to apples" comparison. The point of this work is not to show our coding prowess in moving an algorithm to GPU hardware. The point is to assess the reductions in runtime that a user may experience in using the NVIDIA AmgX GPU library from an application code written with PETSc.
Bear in mind that PETSc is a two-decades old, actively developed library, and it is used in hundreds of research codes around the world.
Brief overview of PetIBM¶
We all know that solving Poisson problems is computationally demanding. It is particularly challenging in unsteady computational fluid dynamics (CFD), where we need to solve the Poisson system over and over again during a time-marching iteration. The situation in PetIBM is tougher than typical unsteady CFD problems because the coefficient matrix is not a standard discrete Laplace operator: it is augmented by terms derived from the presence of the body. We are in fact solving modified Poisson equation at every time step, and this is responsible for about 90% of the run time.
The particular immersed-boundary formulation in PetIBM is due to Taira and Colonius [1]. The governing equations for the fluid velocity, $\bf{u}$, and pressure, $p$, are the following:
In the first equation, Navier-Stokes is augmented by a source term that represents the effect of the body on the fluid, via the no-slip boundary condition. Here, $\bf{f}$ is a singular force distribution along the solid boundary. The second equation enforces the conservation of mass in an incompressible fluid, and the third equation states that the fluid velocity is the same as the body velocity, $\bf{u}_\it{B}$ at the boundary (no slip). After discretization, we can write the above equations as a block system of linear equations, in which each submatrix represents an operator or a term in the PDE:
Here, $q^{n+1}$ are the momentum fluxes at cell boundaries on the next time step, $n+1$, while $r^n$ are the convective terms on the previous time step; $\phi$ is a vector of pressure values and $\tilde{f}$ is a vector of force values at the boundary points. We can further define some larger submatrices and perform a block-LU decomposition:
The above matrix system corresponds to solving three algebraic equations:
Here, $q^{*}$ is the intermediate solution for the fluxes, used in the pressure projection step. The second equation is a modified Poisson equation, corresponding to a Poisson equation plus terms that are due to the presence of the body. The coefficient matrix in the modified Poisson eqauation, $Q^TB^NQ$, has a non-zero pattern like that shown in Figure 1, which corresponds to the situation where a circular cylinder is immersed in a fluid.

Figure 1. Non-zero pattern of the modified Poisson coefficient matrix.¶
The upper-left block in the coefficient matrix corresponds to the typical Poisson system, i.e., the discrete Laplace operator. The bottom, bottom-right corner and the right side of the matrix in Figure 1 are the modification terms due to the presence of the body.
In PetIBM, solving this modified Poisson equation takes over 90% of the total run time. We will introduce GPU computing to accelerate only this part of the overall calculation.
NVIDIA AmgX library¶
AmgX is a library that provides linear solvers and preconditioners with capability of using multiple GPUs. It is developed and supported by NVIDIA, having entered beta production in January 2014. A tutorial, user's manual and license information are available on the NVIDIA Developer website.
Here we list some of the features of AmgX:
- Krylov methods:
- CG, GMRES, BiCGStab, ... etc
- Multigrid (MG) preconditioners:
- Classical algebraic multigrid (AMG)
- Unsmoothed aggregation AMG
- Smoothers:
- Block-Jacobi, Gauss-Seidel, incomplete LU, dense LU, ... etc
- Cycles:
- V, W, F, FG, CGF
- Multiple GPUs on single node / multiple nodes
- MPI (OpenMPI) / MPI Direct
- Single MPI rank <=> single GPU
- Multiple MPI ranks <=> single GPU
- C API
- Unified Virtual Addressing
The various combinations of Krylov methods and multigrid preconditioners are very popular in CFD applications. In fact, the AmgX library was developed specifically aimed for CFD and similar computational physics applications, in a partnership between NVIDIA and ANSYS, a major provider of commercial CFD software.
Benchmarks published by NVIDIA in the Developer Blog (May 15, 2014) compared against the "gold standard" classical AMG implementation: BoomerAMG in the HYPRE package. They showed speedups of 2x in the setup phase and 4–6x in the solve phase, when comparing a single K40 GPU versus 2x10-core Intel Ivy Bridge CPUs, on problems of size 5 million and 10 million. But results on multi-GPUs were still unclear.
Our AmgX wrapper for PETSc¶
Why did we need to write an AmgX "wrapper" code?
AmgX requires the application code to provide it with the coefficient matrix, and the right-hand-side vector of the linear system. The application can create these data structures in the host CPU (then copy them to the device), or in-place in the GPU.
But our application code uses the PETSc library. Both AmgX and PETSc have their own data structures for parallel linear algebra. PetIBM is also written in C++ with some object-oriented design, while AmgX offers a pure-C API. Thus, to use AmgX directly in PetIBM, we would need to add or modify a lot of code, which we would rather avoid.
Also, we may later on want to develop some other software using PETSc, and we may also want to use AmgX with it. So a wrapper to couple AmgX and PETSc could help us or others in the future.
The philosophy of our wrapper is simple: except when initializing and finalizing, users should only need to call setA and solve in most cases. In unsteady CFD applications, with time-marching iterations, users would simply call solve repeatedly. But there should be no need to be concerned about data conversion: A, x, and rhs are all PETSc data structures, and remain so, on the application side. We also would like configuration to be done simply through an input script during runtime.
The wrapper code equips the PETSc application software with access to AmgX, without the burden of unpacking data structures from one into the other. Without it, to use AmgX from PETSc one would have to access the raw data from the sparse matrix in PETSc, then redistribute as needed across MPI processes to consolidate the data in a way that can be sent to the GPU device. Next, the application would need to initialize AmgX and allocate memory on the GPU—using the API only, users would need about 10 different AmgX functions for just this part. Users would need more code to set up the matrix and vectors and send from host to device, then set up the solver, solve and finalize. With our wrapper, users only need to declare an instance of the solver with AmgXWrapper solver and then call solver.initialize(...). The diagram in Figure 2 shows the simple work flow provided by our wrapper.
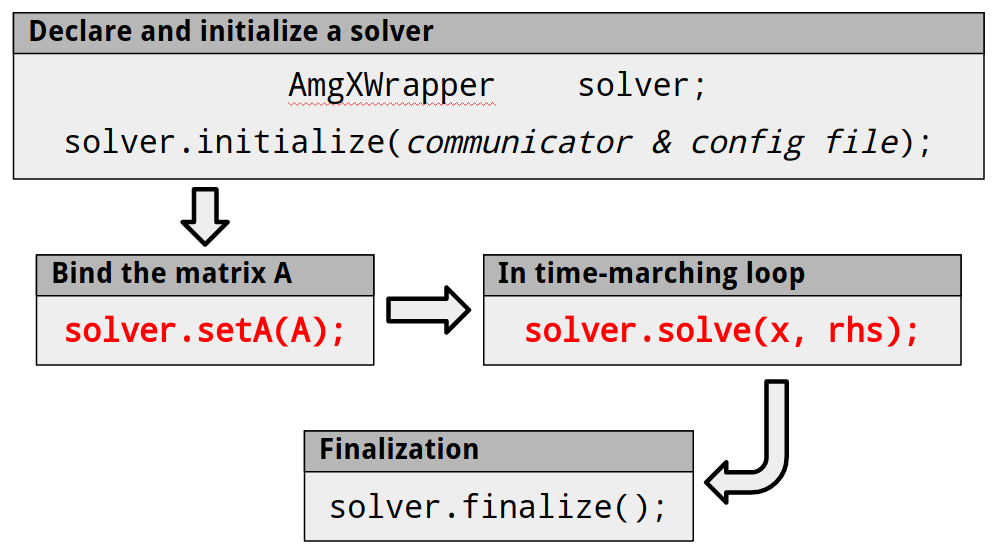
Figure 2. Diagram of our AmgX wrapper work flow.¶
Numerical tests¶
First test: 2D cylinder flow, Re=40¶
With our AmgX wrapper code, we have access to the linear solvers on GPU provided by AmgX, from our PETSc application, PetIBM. As a first test, we used PetIBM to solve flow around a 2D cylinder at Reynolds number Re=40, on 2.25M mesh points, for 300 time steps. The detailed simulation settings can be found in the directory data/cylinder2d_Re40—the interested reader can repeat all of our tests (after installing PetIBM, AmgX and dependencies) using the corresponding data files for each run.
The hardware used here was a workstation with a 6-core CPU (Intel i7-5930K) and up to 2 GPUs (NVIDIA K40c). First, we ran our original PetIBM code on the 6 CPU cores, then repeated the simulation using 1 CPU core and 1 GPU, and finally ran on all 6 CPU cores plus the GPU. The results in Figure 3 show the run time of each stage in the computation, for each system configuration.
On the pure-CPU runs, both linear systems (velocity and pressure) are being solved with PETSc. In that case, we use a CG solver with block-Jacobi preconditioner for the velocity system, and a CG solver with GAMG preconditioner for the pressure system. With GPUs, only the pressure system is solved with AmgX; we use a CG solver with aggregation preconditioner in that case.

Figure 3. Run time of PetIBM for flow around a 2D cylinder.¶
On Figure 3, the left bar shows the timings when using our original CPU-version of PetIBM on 6 CPU cores. We can see that solving modified Poisson equation, the blue portion, takes over 90% of total time in this case.
The middle bar is the result from using the AmgX-version of PetIBM with 1 GPU and 1 CPU core. We get 4x speed-up on solving the modified Poisson equation and 3x speed-up on the total time. We think it looks great, but not great enough. It now takes more time to compute the parts that remained on the CPU (the portions with colors other than blue). The reason is obvious: in this case we only used 1 CPU core to compute these parts, while 6 CPU cores were used before. What happens if we use 6 CPU cores to compute the CPU-based parts and 1 GPU to solve the modified Poisson system?
The right-most bar is the result when we use all available CPU cores. We regain the same performance on the CPU-based parts, but the speed-up of the GPU-accelerated modified-Poisson solve is all but wiped out. What just happened?
Recall that AmgX only provides linear solvers, it does not provide other linear-algebra operations. That means we need to prepare the linear systems using PETSc on the CPU side. When launching PetIBM using 6 CPU cores, the modified Poisson system is partitioned into 6 subdomains via the partitioning methods in PETSc. And when calling AmgX to solve the modified Poisson system, each CPU core creates an AmgX solver to solve the subdomain it holds. In our case, there are 6 subdomain-solvers but only one GPU. This means the 6 subdomain-solvers are competing for GPU resources. We are using domain-decomposition methods, so data exchanges occur between these 6 subdomain-solvers and on one single GPU. This leads to the degradation of performance we in the right-most bar of Figure 3.
More examples revealing this issue¶
In Figure 4 below, we show the results of computational experiments on a 3D Poisson equation with 6 million unknowns, using 1 or 2 GPUs and increasing number of MPI processes. This case used a CG solver with classical AMG preconditioner. Figure 5 shows results with a modified Poisson equation corresponding to flow around a cylinder, under similar system configurations as Fig. 4. This case used a CG solver and an aggregation AMG preconditioner. Both cases show degradation of performance when we prepare the linear systems with PETSc using more MPI processes than the number of GPUs.


Improved AmgX wrapper for PETSc¶
The performance degradation seen above is of course not acceptable, but the solution is straightforward: we can prepare the linear system so that it has only one subdomain-solver per available GPU device. We could modify our application code, PetIBM, to accomplish this. But our strategy is to avoid modifications of the application and instead build this functionality into our wrapper code.
The goal of the wrapper is to ease the use of AmgX in PETSc-based applications.
We'd like to provide full access to the AmgX solvers with just four functions:
solver.initialize(...), solver.setA(A), solver.solve(x, rhs), and solver.finalize().
To achieve this goal, we built into the AmgX wrapper the capacity to manage the parallel distribution of the linear system via communicator splitting. As shown on the diagram in Figure 6, the idea is to merge the sub-systems on the CPU-side, before calling AmgX with one sub-system per GPU device. The text and diagrams below illustrate the process step-by-step.

Figure 6. Merge sub-systems to match number of GPU devices.¶
Step 1 — Split the global communicator into per-node communicators¶
The first step is to split the global communicator, typically MPI_COMM_WORLD, into local communicators corresponding to each computing node. See Figure 7.

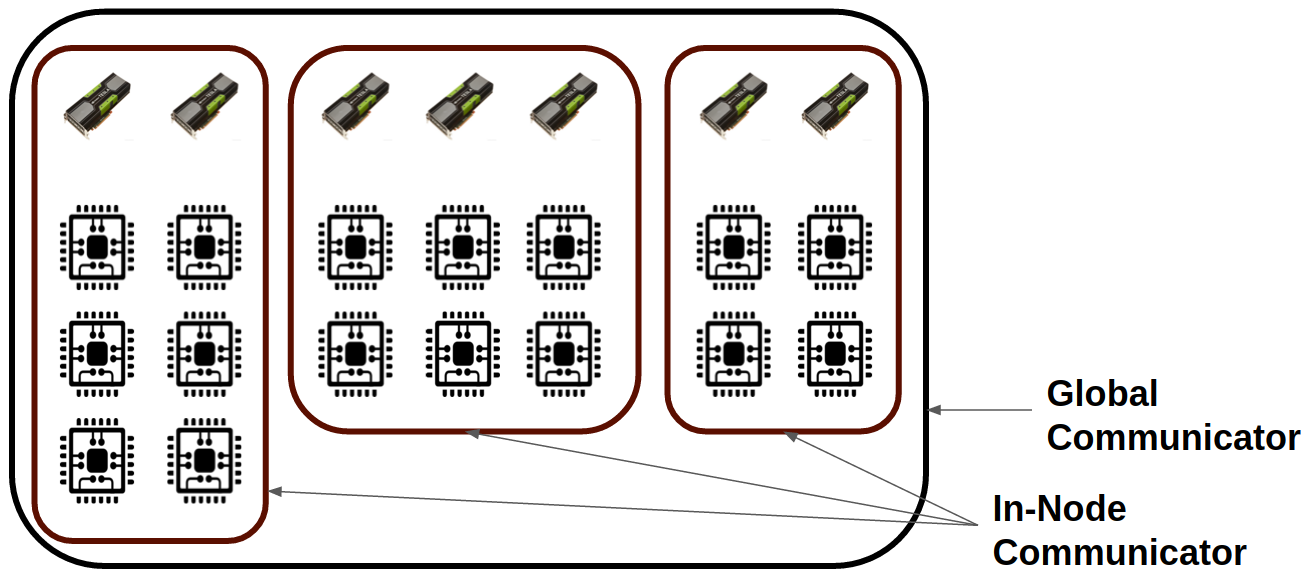
Figure 7. Split the global communicator into per-node communicators.¶
Step 2 — Divide the in-node communicators by the number of GPUs¶
In each compute node, the local MPI processes are now grouped into one communicator per GPU device, via communicator splitting (again). We call these subdomain gather/scatter communicators. They each include MPI processes that share the same GPU device, whose data for their local subdomain will be gathered before being transferred to their shared GPU. The communicators will also scatter the solution coming back from AmgX on the GPU to the corresponding MPI processes. See Figure 8.

Figure 8. Split in-node communicators by number of GPUs.¶
Step 3 — Assign one MPI process to launch AmgX on a GPU device¶
Only one MPI process will be in charge of launching AmgX for the merged sub-system corresponding to the matrix-consolidation communicator (normally, rank zero in that communicator). These "master" MPI processes will be the only ones to interact with the GPUs. See Figure 9.

Figure 9. Assign one MPI process to interact with each GPU device.¶
Step 4 — Create a new communicator with all "master" MPI processes¶
We are solving linear systems of equations in parallel via domain-decomposition, which means that the AmgX subdomain-solvers on GPUs need to communicate. Since GPUs cannot communicate directly (for now!), we need to create a communicator with all the "master" MPI processes to accomplish that. See Figure 10.

Figure 10. One communicator with all "master" MPI processes.¶
Tests with the improved AmgX wrapper¶
The process described above—using communicator splitting to organize the launch of one AmgX instance per GPU—introduces extra communication. The overhead of this additional communication may affect overall performance, and we need to run some tests to find out if all of this is worthwhile. Below, we show the results of repeating the previous tests with the improved AmgX wrapper.
New tests with Poisson systems¶
As before, we ran a solution of the 3D Poisson equation (Figure 11) and the modified Poisson equation (Figure 12) using 1 or 2 GPUs, with increasing number of MPI processes. The test conditions were the same as for the cases shown on Figures 4 and 5. But now, the time to solution is almost the same, regardless of the number of MPI processes.


New tests with PetIBM on 2D cylinder flow¶
Figure 13 shows the result of running PetIBM with AmgX and host-side consolidation enabled in the wrapper (right-most bar). Compare with Figure 3. The time to solve the modified Poisson equation (the blue portion) is now the same as in the middle bar. And the portions that remained on CPUs (colors other than blue) now are able to utilize all the available CPU cores.
This means that our AmgX wrapper for PETSc lets users exploit all available CPU and GPU resources, achieving good performance.
All they have to do on the PETSc application code is to call setA and solve.

Figure 13. Runtime for 2D cylinder flow with PetIBM and AmgX.¶
CFD benchmarks¶
With our wrapper ready for real work now, we can run some benchmarks to evaluate the performance of AmgX for CFD problems. We focus on two benchmarks. The first is solving Poisson equations, which represents the situation when computing flows without an immersed solid body, like lid-driven flows. The second is solving modified Poisson equations. In this case, we use PetIBM to run a real application and see how much speed-up we can get.
1. Poisson equation¶
a. Small-size problem¶
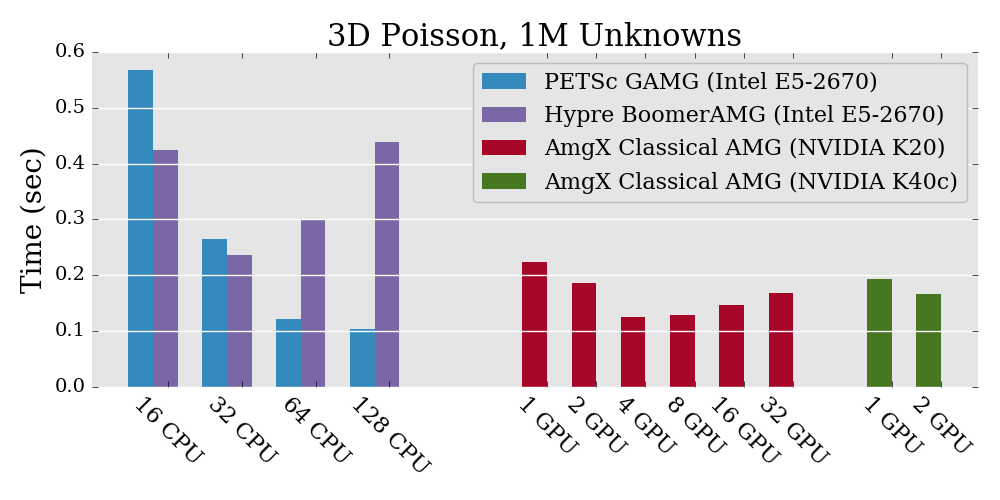
Our first tests solved a Poisson problem with 1M unknowns, both in 2D and 3D. See Figure 14.
On the left side of the plots, we show the results of running a CPU-based solution. The blue bars are the runtimes using PETSc KSP solvers and PETSc GAMG preconditioners, while the purple bars are the runtimes using Hypre preconditioners but still with PETSc KSP solvers.
The results on GPUs with AmgX are shown on the right side of the plots. The red bars are the runtimes on the GPU cluster of our university HPC center (Colonial One), and the green bars are the runtimes on a workstation in our lab.
We include tests on our GPU workstations because we are always curious to see if it is possible that, with GPU computing, even a workstation can be competitive to traditional CPU clusters.
In this case, with a small-size problem, it looks like we're getting humble acceleration on one GPU (the runtime is slightly longer than when using 64 CPU cores, or a 4x speed-up compared with one 16-core compute node), but no benefit from adding more GPUs. We suspect the problem size is too small to scale.

b. Medium-size problem¶
Next, we solved Poisson problems with 25 million unknowns—a size that might be routine in various aerodynamics or hydrodynamics applications.
For our CPU-based runs, we now omit the results when using GAMG preconditioners, because they were much slower than Hypre in this case. On GPUs, we need at least four or eight K20s in 2D and 3D problems, respectively, because of the limited memory on a single K20. Also, since we only have two K40s in our workstation, this machine cannot handle the 3D case.
See Figure 15. What do you think? We think these results are not bad at all.
In the 2D case, given that the CPU results scale well in this range, we estimate that we would probably need about 100 CPU cores to achieve 5x speed-up. (See the blue bars with 64 and 128 CPU cores.) Using AmgX, we obtain a 5x speed-up on four K20s, compared to one 16-core CPU node. (Recall that we need four GPUs to have enough memory for this problem size.)
We think that four K20s are better than 100 CPU cores, because we can actually have four K20s in our personal workstation: no need for compute clusters! Also, bear in mind that the K20 is not a new model. You can probably find a new one on Amazon for 2500 dollars. Four K20s could cost around $10k, but it's unlikely that 10 grand could get you a CPU cluster with 100 CPU cores!
In the 3D case, similarly, we get a 13.2x speedup with eight K20s using AmgX (compared to one 16-core CPU node), yet if we wanted to achieve that with CPU hardware only, we would need about 256 CPU cores. We also think that eight K20s are better than 256 CPU cores, for the same reason explained above. Though it may not be possible to host eight K20s in a personal workstation, it is possible to install eight K20s in one node of an HPC cluster. (That means that the cost of fast interconnect could be avoided.) Again, the K20 is an older GPU model; if we used K40s, we may be able to still use a lab workstation to compete against a 256-core CPU cluster.


c. Large-size problem¶
Our final test solves the Poisson problem with 100 million unknowns in 2D and 50 million unknowns in 3D. (We were limited to 50 million points in the 3D case due to the memory requirements.) See Figure 16 for the runtimes we obtained.
Extrapolating with For the 2D case, we estimate that we would need nearly 400 CPU cores to achieve a similar speed-up as the 17.6x we achieve with 32 GPUs.
For the 3D case, we again estimate that we'd need about 400 CPU cores to achieve a similar speed-up as the 20.8x we see in this case with 32 GPUs.
But again, K20 is not the newest model. With a newer model that has larger memory, like the K80, we may need only a few of them to achieve similar performance.


2. Flying snake simulations¶
The standard Poisson equation corresponds to the situation when we solve for flows without an immersed solid body in the fluid. Most applications we're interested in have an immersed body, resulting in a modified Poisson equation in PetIBM.
In this final test, we used PetIBM to solve a real flow application: the aerodynamics of a flying-snake cross section. Our group studied the aerodynamics of flying snakes with the single-GPU code cuIBM, and published the paper "Lift and wakes of flying snakes" in 2014 [2].
Figure 17 shows a typical flow visualization for an anatomically correct cross-section of the snake's body mid-flight: the red and blue colors show positive and negative vorticity in the flow (corresponding to swirling flow). The snake's body produces a typical vortex street pattern in the wake, accompanied by large aerodynamic forces.

Figure 17. Vorticity field due to flow around a flying snake cross-section.¶
Figure 18 shows the runtimes for the simulations of flow around a flying snake, using PetIBM and AmgX. We re-run one of the simulations from Reference [2], corresponding to a mesh size of 1704x1704 points in 2D. The number of unknowns in the velocity system is 5.8M, and the number of unknowns in the modified Poisson system is 2.9M.
We used a CPU cluster, a GPU cluster with K20s, and a personal workstation with two K40 GPUs. Here are short specs of the hardware:
- 1 node in the CPU cluster = 12 CPU cores (2 Intel E5-2620)
- 1 node in the GPU cluster = 1 CPU node (i.e., 12 CPU cores) + 2 K20 GPUs
- personal workstation = 6 CPU cores (1 Intel i7-5930K) + 2 K40c GPUs
The GPU compute nodes are actually nodes in the same HPC cluster with two added K20 GPUs. This setting can help us determine whether using AmgX and GPU computing is beneficial from the viewpoint of monetary cost of hardware.
Using the result of one CPU node as our baseline, the speed-up from using 1 GPU node is almost 21x. Again, based on the scalability of CPU results, we can predict that we may need 20 CPU nodes in order to achieve 21 times speed-up if we are using pure CPU code. Recall one GPU node is actually 1 CPU node plus 2 K20. I think it's obvious that adding 2 K20 to an existing computing node is cheaper than adding 19 extra computing nodes.
Next let's move on to the results of using the workstation. I think the result here is much more exciting. When we use our personal workstation and one K40 GPU, we can get about 15 times speed-up, which can also be achieved with 16 CPU nodes in the CPU cluster. This means, at least for our applications, if the GPU memory on our workstation is large enough, we don't need to run our simulations on clusters. Our personal workstation can handle it.
So from these results, the benefit of AmgX and GPU computing for our CFD code, PetIBM, is very obvious.
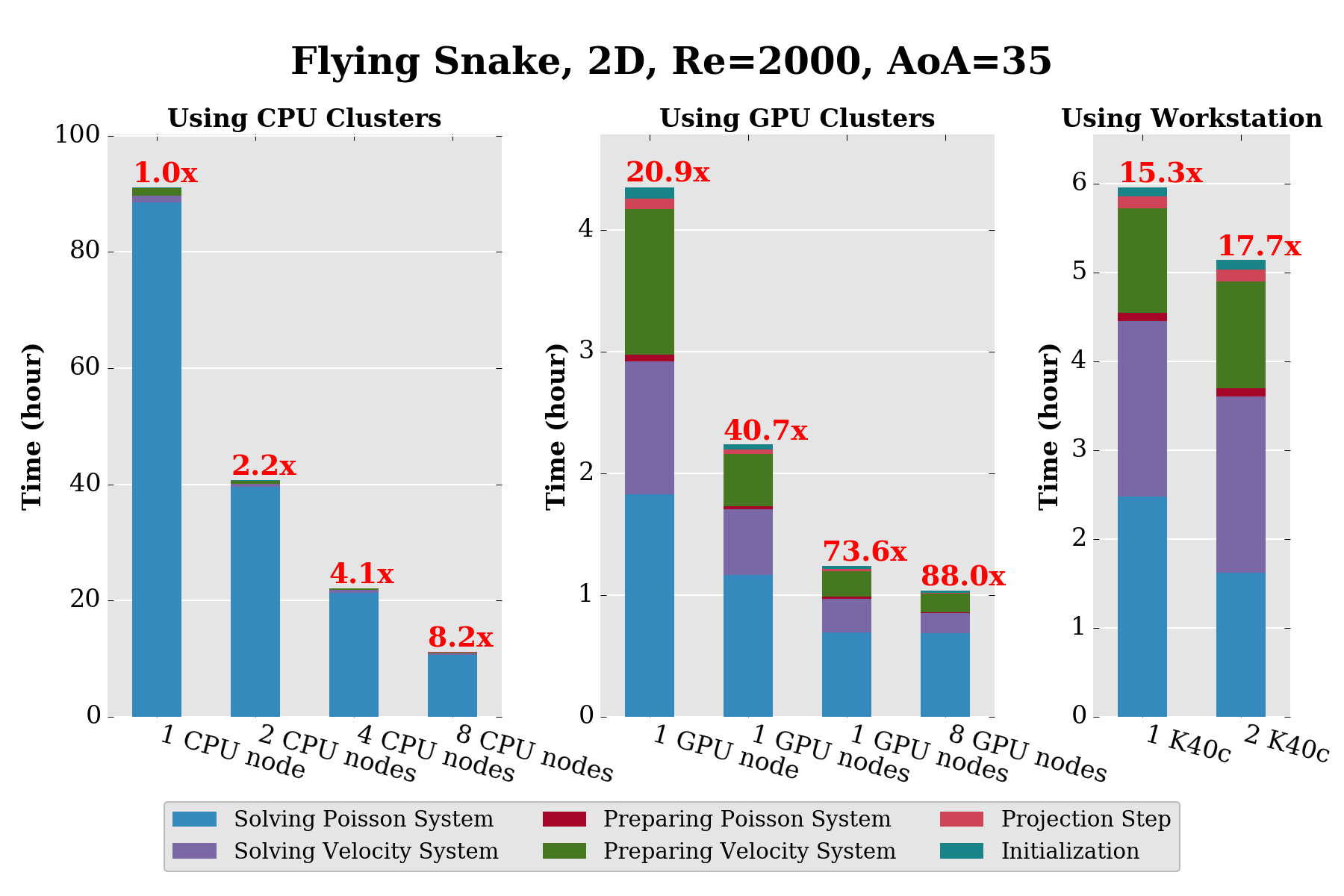
Figure 18. Runtimes for the flying-snake case, using PetIBM and AmgX.¶
Computational cost: time is money¶
In the previous sections, we focused on the speed-ups that we can get from using GPU computing with the AmgX library. Is that all? What else do those benchmarks imply?
As we know, time is money. When AmgX saves us time, it also saves us money. Let's try to quantify that.
1. Potential savings on hardware¶
The flying snake simulations convey that using AmgX on a workstation with one K40 GPU could be competitive with running standard libraries on a 16-node CPU cluster. There are several advantages to using workstation, in this scenario. Building a typical HPC cluster involves costly hardware like network switches, cooling systems and so on, while operating costs are inflated by power requirements and system administration. If we can get our science done on a workstation with one or two GPUs, simply plugged-in via PCI-E, we will certainly save some money. We'll also save time and irritation, not having to deal with shared-computing job queues or having to negotiate with system administrators to get libraries installed, etc.
Of course we may still need clusters sometimes because of the limited memory on GPUs and limited PCI-E slots on a single motherboard. But from our benchmark results, we can say that with AmgX, even when we need clusters, we will require fewer computing nodes. This comes with several benefits: less socket-to-socket communication; fewer potential runtime crashes due to single-node failure or network failiure; or you can get higher priority in the job queue when using HPC centers, because now you need less time and fewer nodes.
2. Potential savings on cloud HPC service¶
Here's another perspective on the advantates of using AmgX on GPUs, versus traditional libraries on CPU clusters: running on cloud HPC services, such as Amazon EC2.
We ran benchmarks on Amazon EC2, with the machine specs listed below for GPU- and CPU-based nodes:
Figure 19 shows the runtimes for our flying-snake simulations on these EC2 machines. The left bar corresponds to the CPU-based architecture, using 8 nodes. The right bar corresponds to a GPU node. Surprising! Even when using 8 CPU nodes, we still see a 3x speedup when moving to a single GPU node. That is surprising, becasue the eight CPU nodes have a collective 288 CPU cores. On the other hand, those CPU "nodes" are virtual machines, not physical machines. We don't really know what is inside the EC2 "black box."

Figure 19. Runtimes for flying-snake simulations on Amazon EC2.¶
One thing we do know is how much money we can save. First, let's calculate the actual fee we paid for these benchmarks. We used spot instances, and the real amounts we paid for nodes are as follows:
CPU nodes: 12.5hr x $0.5/hr x 8 nodes $=$ $50.0
GPU nodes: 4hr x $0.5/hr x 1 node $=$ $2.0
That's a 25x savings on real cost of cloud usage!
Sometimes it's hard to get spot instances or we may not be willing to use them. In that case, how much can we save if we rent the instances at the official price?
CPU nodes: 12.5hr x $1.675/hr x 8 nodes $=$ $167.5
GPU nodes: 4hr \times $2.6/hr x 1 node $=$ $10.4
We still get about 16x real money savings on cloud usage. Not bad.
Conclusion¶
In this work, we used AmgX to accelerate our CFD code, PetIBM, with GPU computing. We found it necessary to write a wrapper to couple AmgX and PETSc, which we release openly in case others find it useful. Our wrapper efficiently manages the situation when we want to launch the PETSc-based program with more MPI processes than the number of available GPUs. We can thus utilize as many CPU cores as available to run the parts that still remain on the CPU-side of the application code, and use as many GPUs as available to accelerate the linear solvers on AmgX.
On our benchmarks solving standard Poisson problems with 25M unknowns, we obtained a 5x speed-up on four K20s, compared to one 16-core CPU node, in the 2D case. In the 3D case, we obtained a 13.2x speedup with eight K20s using AmgX, compared to one 16-core CPU node. The minimum number of GPUs, in this case, is dictated by our memory needs.
On larger Poisson benchmarks, with 100M unknowns in 2D and 50M unknowns in 3D, we prefer to look at the equivalent size of a CPU cluster that would give the same speedup as a GPU cluster. We get that about 400 CPU cores would be needed to give similar speed-ups to a 32-GPU cluster (with speedups of 17.6x and 20.8x, respectively). On a real application (flying snake simulations), with almost 3M mesh points, we obtained a 21x speedup on one K20 GPU, compared to one 12-core CPU node.
You can download AmgX, our wrapper, and PetIBM with multi-GPU computing enabled from the following sites:
Acknowledgements¶
We are grateful for hardware donations from NVIDIA Corp., via the CUDA Research Center program and the CUDA Fellows Program. Our lab workstations have been fitted with donated GPUs, enabling this research. (We share the parts list for a recent workstation build on our group website.) Special thanks to Dr. Joe Eaton from NVIDIA for support on AmgX during this project.
Prof. Lorena Barba was named CUDA Fellow in 2012.
References¶
[1] K. Taira and T. Colonius, "The immersed boundary method: A projection approach", Journal of Computational Physics, vol. 225, no. 2, pp. 2118-2137, 2007
[2] A. Krishnan, J. Socha, P. Vlachos and L. Barba, "Lift and wakes of flying snakes", Physics of Fluids, vol. 26, no. 3, p. 031901, 2014
# Execute this cell to load the notebook's style sheet, then ignore it
from IPython.core.display import HTML
css_file = '../styles/GTC16style.css'
HTML(open(css_file, "r").read())