Intelligent Agents and Active Inference¶
Preliminaries¶
- Goal
- Introduction to Active Inference and application to the design of synthetic intelligent agents
- Materials
- Mandatory
- These lecture notes
- Bert de Vries - 2021 - Presentation on Beyond deep learning: natural AI systems (video)
- Optional
- Bert de Vries, Tim Scarfe and Keith Duggar - 2023 - Podcast on Active Inference. Machine Learning Street Talk podcast
- Quite extensive discussion on many aspect regarding the Free Energy Principle and Active Inference, in particular relating to its implementation.
- Raviv (2018), The Genius Neuroscientist Who Might Hold the Key to True AI.
- Interesting article on Karl Friston, who is a leading theoretical neuroscientist working on a theory that relates life and intelligent behavior to physics (and Free Energy minimization). (highly recommended)
- Friston et al. (2022), Designing Ecosystems of Intelligence from First Principles
- Friston's vision on the future of AI.
- Van de Laar and De Vries (2019), Simulating Active Inference Processes by Message Passing
- How to implement active inference by message passing in a Forney-style factor graph.
- Bert de Vries, Tim Scarfe and Keith Duggar - 2023 - Podcast on Active Inference. Machine Learning Street Talk podcast
- Mandatory
Agents¶
- In the previous lessons we assumed that a data set was given.
- In this lesson we consider agents. An agent is a system that interacts with its environment through both sensors and actuators.
- Crucially, by acting onto the environment, the agent is able to affect the data that it will sense in the future.
- As an example, by changing the direction where I look, I can affect the (visual) data that will be sensed by my retina.
- With this definition of an agent, (biological) organisms are agents, and so are robots, self-driving cars, etc.
- In an engineering context, we are particularly interesting in agents that behave with a purpose (with a goal in mind), e.g., to drive a car or to design a speech recognition algorithm.
- In this lesson, we will describe how goal-directed behavior by biological (and synthetic) agents can also be interpreted as minimization of a free energy functional.
Illustrative Example: the Mountain Car Problem¶
- In this example, we consider the mountain car problem which is a classical benchmark problem in the reinforcement learning literature.
- The car aims to drive up a steep hill and park at a designated location. However, its engine is too weak to climb the hill directly. Therefore, a successful agent should first climb a neighboring hill, and subsequently use its momentum to overcome the steep incline towards the goal position.
- We will assume that the agent's knowledge about the car's process dynamics (i.e., its equations of motion) are known up to some additive Gaussian noise.
- Your challenge is to design an agent that guides the car to the goal position. (The agent should be specified as a probabilistic model and the control signal should be formulated as a Bayesian inference task).

- Solution at the end of this lesson.
Karl Friston and the Free Energy Principle¶
We begin with a motivating example that requires "intelligent" goal-directed decision making: assume that you are an owl and that you're hungry. What are you going to do?
Have a look at Prof. Karl Friston's answer in this video segment on the cost function for intelligent behavior. (Do watch the video!)
Friston argues that intelligent decision making (behavior, action making) by an agent requires minimization of a functional of beliefs.
Friston further argues (later in the lecture and his papers) that this functional is a (variational) free energy (to be defined below), thus linking decision-making and acting to Bayesian inference.
In fact, Friston's Free Energy Principle (FEP) claims that all biological self-organizing processes (including brain processes) can be described as Free Energy minimization in a probabilistic model.
- This includes perception, learning, attention mechanisms, recall, acting and decision making, etc.
Taking inspiration from FEP, if we want to develop synthetic "intelligent" agents, we have (only) two issues to consider:
- Specification of the FE functional.
- How to minimize the FE functional (often in real-time under situated conditions).
Agents that follow the FEP are said to be involved in Active Inference (AIF). An AIF agent updates its states and parameters (and ultimately its model structure) solely by FE minimization, and selects its actions through (expected) FE minimization (to be explained below).
Execution of an AIF Agent¶
- Consider an AIF agent with observations (sensory states) $x_t$, latent internal states $s_t$ and latent control states $u_t$ for $t=1,2,\ldots$.

The agent is embedded in an environment with "external states" $\tilde{s}_t$. The dynamics of the environment are driven by actions.
Actions $a_t$ are selected by the agent. Actions affect the environment and consequently affect future observations.
In pseudo-code, an AIF agent executes the following algorithm:
ACTIVE INFERENCE (AIF) AGENT ALGORITHM
SPECIFY generative model $p(x,s,u)$
ASSUME/SPECIFY environmental process $R$FORALL t DO
- $(x_t, \tilde{s}_t) = R(a_t, \tilde{s}_{t-1})$ % environment generates new observation
- $q(s_t) = \arg\min_q F[q]$ % update agent's internal states ("perception")
- $q(u_{t+1}) = \arg\min_q F_>[q]$ % update agent's control states ("actions")
- $a_{t+1} \sim q(u_{t+1})$ % sample next action and push to environment
END
- In the above algorithm, $F[q]$ and $F_>[q]$ are appropriately defined Free Energy functionals, to be discussed below. Next, we discuss these steps in more details.
The Generative Model in an AIF agent¶
What should the agent's model $p(x,s,u)$ be modeling? This question was (already) answered by Conant and Ashby (1970) as the good regulator theorem: every good regulator of a system must be a model of that system. See the OPTIONAL SLIDE for more information.
Conant and Ashley state: "The theorem has the interesting corollary that the living brain, so far as it is to be successful and efficient as a regulator for survival, must proceed, in learning, by the formation of a model (or models) of its environment."
Indeed, perception in brains is clearly affected by predictions about sensory inputs by the brain's own generative model.

- In the above picture (The Gardener, by Giuseppe Arcimboldo, ca 1590
), on the left you will likely see a bowl of vegetables, while the same picture upside down elicits with most people the perception of a gardener's face rather than an upside-down vegetable bowl.
Specification of AIF Agent's model and Environmental Dynamics¶
- In this notebook, for illustrative purposes, we specify the generative model at time step $t$ of an AIF agent as
- We will assume that the agent interacts with an environment, which we represent by a dynamic model $R$ as
where $a_t$ are actions (by the agent), $x_t$ are outcomes (the agent's observations) and $\tilde{s}_t$ holds the environmental latent states.
Note that $R$ only needs to be specified for simulated environments. If we were to deploy the agent in a real-world environment, we would not need to specify $R$.
The agent's knowledge about environmental process $R$ is expressed by its generative model $p(x_t,s_t,u_t|s_{t-1})$.
Note that we distinguish between control states and actions. Control states $u_t$ are latent variables in the agent's generative model. An action $a_t$ is a realization of a control state as observed by the environment.
Observations $x_t$ are generated by the environment and observed by the agent. Vice versa, actions $a_t$ are generated by the agent and observed by the environment.
State Updating in the AIF Agent¶
After the agent makes a new observation $x_t$, it will update beliefs over its latent variables. First the internal state variables $s$.
Assume the following at time step $t$:
- the state of the agent's model has already been updated to $q(s_{t-1}| x_{1:t-1})$.
- the agent has selected a new action $a_t$.
- the agent has recorded a new observation $x_t$.
The state updating task is to infer $q(s_{t}|x_{1:t})$, based on the previous estimate $q(s_{t-1}| x_{1:t-1})$, the new data $\{a_t,x_t\}$, and the agent's generative model.
Technically, this is a Bayesian filtering task. In a real brain, this process is called perception.
We specify the following FE functional
- The state updating task can be formulated as minimization of the above FE (see also AIF Algorithm, step 2):
In case the generative model is a Linear Gaussian Dynamical System, minimization of the FE can be solved analytically in closed-form and leads to the standard Kalman filter.
In case these (linear Gaussian) conditions are not met, we can still minimize the FE by other means and arrive at some approximation of the Kalman filter, see for example Baltieri and Isomura (2021) for a Laplace approximation to variational Kalman filtering.
Our toolbox RxInfer specializes in automated execution of this minimization task.
Policy Updating in an AIF Agent¶
Once the agent has updated its internal states, it will turn to inferring the next action.
In order to select a good next action, we need to investigate and compare consequences of a sequence of future actions.
A sequence of future actions $a= (a_{t+1}, a_{t+2}, \ldots, a_{t+T})$ is called a policy. Since relevant consequences are usually the result of an future action sequence rather than a single action, we will be interested in updating beliefs over policies.
In order to assess the consequences of a selected policy, we will, as a function of that policy, run the generative model forward-in-time to make predictions about future observations $x_{t+1:t+T}$.
Note that perception (state updating) preceeds policy updating. In order to accurately predict the future, the agent first needs to understand the current state of the world.
Consider an AIF agent at time step $t$ with (future) observations $x = (x_{t+1}, x_{t+2}, \ldots, x_{t+T})$, latent future internal states $s= (s_t, s_{t+1}, \ldots, s_{t+T})$, and latent future control variables $u= (u_{t+1}, u_{t+2}, \ldots, u_{t+T})$.
From the agent's viewpoint, the evolution of these future variables are constrained by its generative model, rolled out into the future:
- Consider the Free Energy functional for estimating posterior beliefs $q(s,u)$ over latent future states and latent future control signals:
In principle, this is a regular FE functional, with one difference to previous versions: since future observations $x$ have not yet occurred, $F_>[q]$ marginalizes not only over latent states $s$ and policies $u$, but also over future observations $x$.
We will update the beliefs over policies by minimization of Free Energy functional $F_>[q]$. In the optional slides below, we prove that the solution to this optimization task is given by (see AIF Algorithm, step 3, above)
where the factor $p(u)$ is a prior over admissible policies, and the factor $\exp(-G(u))$ updates the prior with information about future consequences of a selected policy $u$.
- The function
is called the Expected Free Energy (EFE) for policy $u$.
The FEP takes the following stance: if FE minimization is all that an agent does, then the only consistent and appropriate behavior for an agent is to select actions that minimize the expected Free Energy in the future (where expectation is taken over current beliefs about future observations).
Note that, since $q^*(u) \propto p(u)\exp(-G(u))$, the probability $q^*(u)$ for selecting a policy $u$ increases when EFE $G(u)$ gets smaller.
Once the policy (control) variables have been updated, in simulated environments, it is common to assume that the next action $a_{t+1}$ (an action is the observed control variable by the environment) gets selected in proportion to the probability of the related control variable (see AIF Agent Algorithm, step 4, above), i.e., the environment samples the action from the control posterior:
- Next, we analyze some properties of the EFE.
Active Inference Analysis: exploitation-exploration dilemma¶
- Consider the following decomposition of EFE:
Apparently, minimization of EFE leads to selection of policies that balances the following two imperatives:
minimization of the first term of $G(u)$, i.e. minimizing $\sum_x q(x|u) \log \frac{1}{p(x)}$, leads to policies ($u$) that align the inferred observations $q(x|u)$ under policy $u$ (i.e., predicted future observations under policy $u$) with a prior $p(x)$ on future observations. We are in control to choose any prior $p(x)$ and usually we choose a prior that aligns with desired (goal) observations. Hence, policies with low EFE leads to goal-seeking behavior (a.k.a. pragmatic behavior or exploitation). In the OPTIONAL SLIDES, we derive an alternative (perhaps clearer) expression to support this interpretation].
minimization of $G(u)$ maximizes the second term
which is the (conditional) mutual information between (posteriors on) future observations and states, for a given policy $u$. Thus, maximizing this term leads to actions that maximize statistical dependency between future observations and states. In other words, a policy with low EFE also leads to information-seeking behavior (a.k.a. epistemic behavior or exploration).
(The third term $\sum_{x,s} q(x,s|u) \log \frac{q(s|x)}{p(s|x)}$ is an (expected) KL divergence between posterior and prior on the states. This can be interpreted as a complexity/regularization term and $G(u)$ minimization will drive this term to zero.)
Seeking actions that balance goal-seeking behavior (exploitation) and information-seeking behavior (exploration) is a fundamental problem in the Reinforcement Learning literature.
Active Inference solves the exploration-exploitation dilemma. Both objectives are served by EFE minimization without any need for tuning parameters.
AIF Agents learn both the Problem and Solution¶
We highlight another great feature of FE minimizing agents. Consider an AIF agent ($m$) with generative model $p(x,s,u|m)$.
Consider the Divergence-Evidence decomposition of the FE again:
The first term, $-\log p(x|m)$, is the (negative log-) evidence for model $m$, given recorded data $x$.
Minimization of FE maximizes the evidence for the given model. The model captures the problem representation. A model with high evidence predicts the data well and therefore "understands the world".
The second term scores the cost of inference. In almost all cases, the solution to a problem can be phrased as an inference task on the generative model. Hence, the second term scores the accuracy of the inferred solution, for the given model.
FE minimization optimizes a balanced trade-off between a good-enough problem representation and a good-enough solution proposal for that model. Since FE comprises both a cost for solution and problem representation, it is a neutral criterion that applies across a very wide set of problems.
A good solution to the wrong problem is not good enough. A poor solution to a great problem statement is not sufficient either. In order to solve a problem well, we need both to represent the problem correctly (high model evidence) and we need to solve it well (low inference costs).
The Brain's Action-Perception Loop by FE Minimization¶
The above derivations are not trivial, but we have just shown that FE-minimizing agents accomplish variational Bayesian perception (a la Kalman filtering), and a balanced exploration-exploitation trade-off for policy selection.
Moreover, the FE by itself serves as a proper objective across a very wide range of problems, since it scores both the cost of the problem statement and the cost of inferring the solution.
The current FEP theory claims that minimization of FE (and EFE) is all that brains do, i.e., FE minimization leads to perception, policy selection, learning, structure adaptation, attention, learning of problems and solutions, etc.

The Engineering Challenge: Synthetic AIF Agents¶
We have here a framework (the FEP) for emergent intelligent behavior in self-organizing biological systems that
- leads to optimal (Bayesian) information processing, including balancing accuracy vs complexity.
- leads to balanced and continual learning of both problem representation and solution proposal
- actively selects data in-the-field under situated conditions (no dependency on large data base)
- pursues a optimal trade-off between exploration (information-seeking) and exploitation (goal-seeking) behavior
- needs no external tuning parameters (such as step sizes, thresholds, etc.)
Clearly, the FEP, and synthetic AIF agents as a realization of FEP, comprise a very attractive framework for all things relating to AI and AI agents.
A current big AI challenge is to design synthetic AIF agents based solely on FE/EFE minimization.
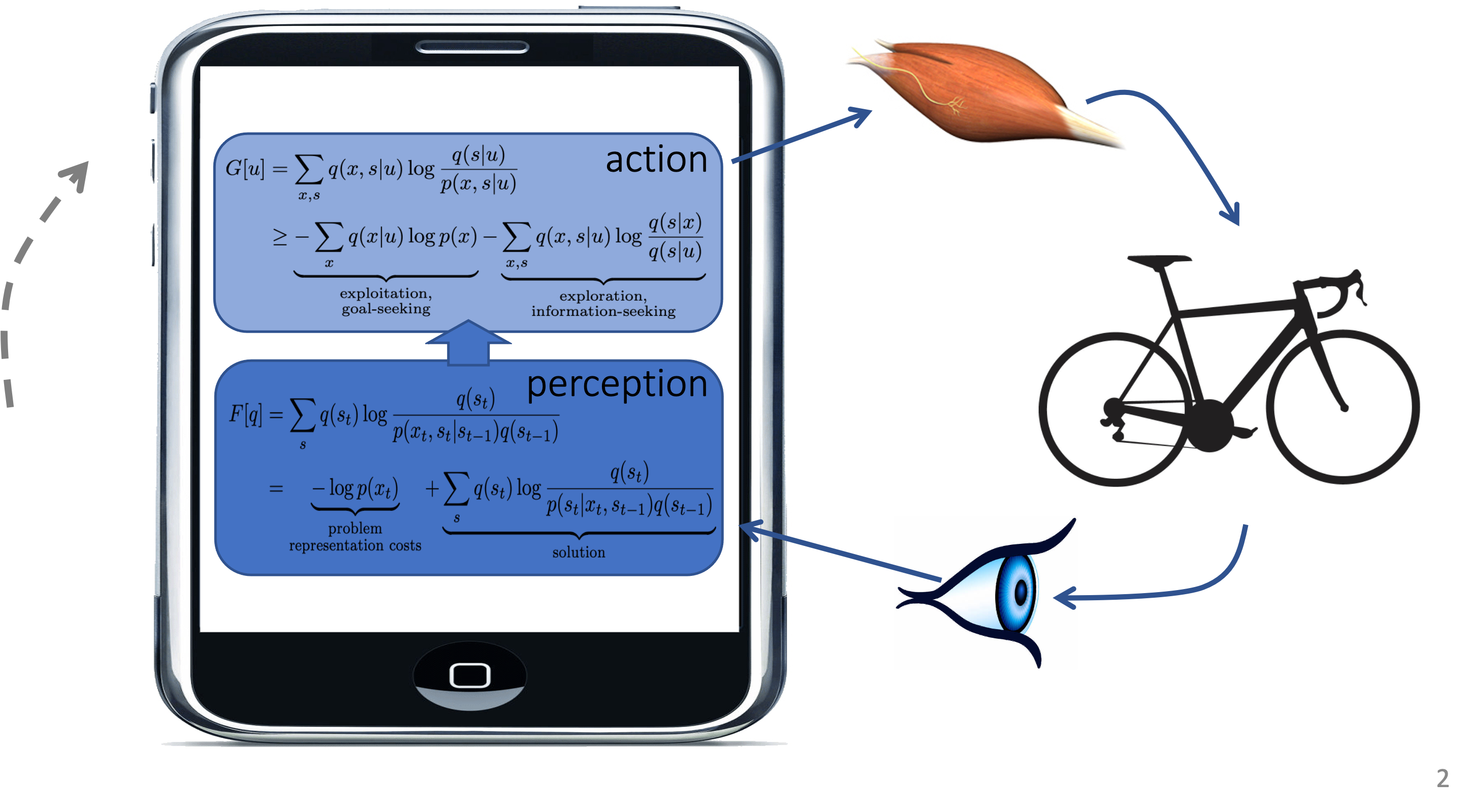
Executing a synthetic AIF agent often poses a large computational problem because of the following reasons:
- For interesting problems (e.g. speech recognition, scene analysis), generative models may contain thousands of latent variables.
- The FE function is a time-varying function, since it is also a function of observable variables.
- An AIF agent must execute inference in real-time if it is engaged and embedded in a real world environment.
So, in practice, executing a synthetic AIF agent may lead to a task of minimizing a time-varying FE function of thousands of variables in real-time!!
Factor Graph Approach to Modeling of an Active Inference Agent¶
How to specify and execute a synthetic AIF agent is an active area of research.
There is no definitive solution approach to AIF agent modeling yet; we (BIASlab) think that (reactive) message passing in a factor graph representation provides a promising path.
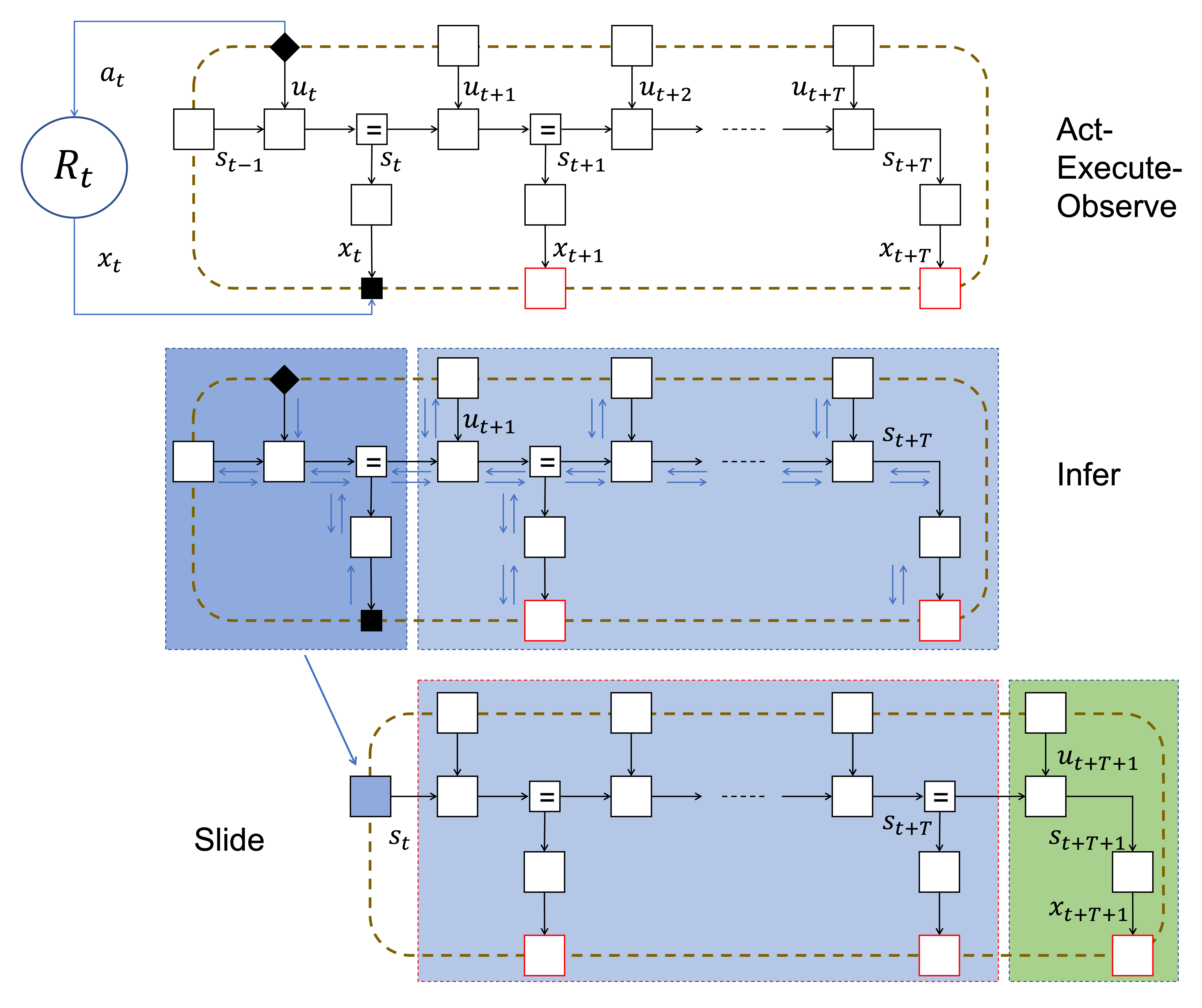
After selecting an action $a_t$ and making an observation $x_t$, the FFG for the rolled-out generative model is given by the following FFG:

The open red nodes for $p(x_{t+k})$ specify desired future observations, whereas the open black boxes for $p(s_k|s_{k-1},u_k)$ and $p(x_k|s_k)$ reflect the agent's beliefs about how the world actually evolves (ie, the veridical model).
The (brown) dashed box is the agent's Markov blanket. Given the states on the Markov blanket, the internal states of the agent are independent of the state of the world.
How to minimize FE: Online Active Inference¶
- Online active inference proceeds by iteratively executing three stages:
- act-execute-observe
- infer: update the latent variables and select an action
- slide forward
The Mountain car Problem Revisited¶
Here we solve the mountain car problem as stated at the beginning of this lesson. Before implementing the active inference agent, let's first perform a naive approach that executes the engine's maximum power to reach the goal. As can be seen in the results, this approach fails since the car's engine is not strong enough to reach the goal directly.
using Pkg; Pkg.activate("../."); Pkg.instantiate();
using IJulia; try IJulia.clear_output(); catch _ end
using LinearAlgebra, Plots, RxInfer
import .ReactiveMP: getrecent, messageout
include("./scripts/mountaincar_helper.jl")
# Environment variables
initial_position = -0.5
initial_velocity = 0.0
engine_force_limit = 0.04
friction_coefficient = 0.1
Fa, Ff, Fg, height = create_physics(
engine_force_limit = engine_force_limit,
friction_coefficient = friction_coefficient
)
# Target position and velocity
target = [0.5, 0.0];
# Simulation of a naive policy, going full power toward the parking place
# Let there be a world
(execute, observe) = create_world(
Fg = Fg, Ff = Ff, Fa = Fa,
initial_position = initial_position,
initial_velocity = initial_velocity
)
# Total simulation time
N = 40
y = Vector{Vector{Float64}}(undef, N)
for n in 1:N
execute(100.0) # Act with the maximum power
y[n] = observe() # Observe the current environmental outcome
end
plot_car(y, target, title_plot="Mountain Car Problem: naive policy", fps=5)

# Let's also plot the goal and car positions over time
trajectories = reduce(hcat,y)'
plot(trajectories[:,1], label="car: naive policy", title = "Car and Goal Positions", color = "orange")
plot!(0.5 * ones(N), color = "black", linestyle=:dash, label = "goal")
Next, we try a more sophisticated active inference agent. Above, we specified a probabilistic generative model for the agent's environment and then constrained future observations by a prior distribution that is located on the goal position. We then execute the (1) Act-execute-observe --> (2) infer --> (3) slide procedures as discussed above to infer future actions.
@model function mountain_car(m_u, V_u, m_x, V_x, m_s_t_min, V_s_t_min, T, Fg, Fa, Ff, engine_force_limit)
# Transition function modeling transition due to gravity and friction
g = (s_t_min::AbstractVector) -> begin
s_t = similar(s_t_min) # Next state
s_t[2] = s_t_min[2] + Fg(s_t_min[1]) + Ff(s_t_min[2]) # Update velocity
s_t[1] = s_t_min[1] + s_t[2] # Update position
return s_t
end
# Function for modeling engine control
h = (u::AbstractVector) -> [0.0, Fa(u[1])]
# Inverse engine force, from change in state to corresponding engine force
h_inv = (delta_s_dot::AbstractVector) -> [atanh(clamp(delta_s_dot[2], -engine_force_limit+1e-3, engine_force_limit-1e-3)/engine_force_limit)]
# Internal model perameters
Gamma = 1e4*diageye(2) # Transition precision
Theta = 1e-4*diageye(2) # Observation variance
s_t_min ~ MvNormal(mean = m_s_t_min, cov = V_s_t_min)
s_k_min = s_t_min
local s
for k in 1:T
u[k] ~ MvNormal(mean = m_u[k], cov = V_u[k])
u_h_k[k] ~ h(u[k]) where { meta = DeltaMeta(method = Linearization(), inverse = h_inv) }
s_g_k[k] ~ g(s_k_min) where { meta = DeltaMeta(method = Linearization()) }
u_s_sum[k] ~ s_g_k[k] + u_h_k[k]
s[k] ~ MvNormal(mean = u_s_sum[k], precision = Gamma)
x[k] ~ MvNormal(mean = s[k], cov = Theta)
x[k] ~ MvNormal(mean = m_x[k], cov = V_x[k]) # goal
s_k_min = s[k]
end
return (s, )
end
@meta function car_meta()
dzdt() -> DeltaMeta(method = Linearization())
end
function create_agent(;T = 20, Fg, Fa, Ff, engine_force_limit, target, initial_position, initial_velocity)
Epsilon = fill(huge, 1, 1) # Control prior variance
m_u = Vector{Float64}[ [ 0.0] for k=1:T ] # Set control priors
V_u = Matrix{Float64}[ Epsilon for k=1:T ]
Sigma = 1e-4*diageye(2) # Goal prior variance
m_x = [zeros(2) for k=1:T]
V_x = [huge*diageye(2) for k=1:T]
V_x[end] = Sigma # Set prior to reach goal at t=T
# Set initial brain state prior
m_s_t_min = [initial_position, initial_velocity]
V_s_t_min = tiny * diageye(2)
# Set current inference results
result = nothing
# The `compute` function performs Bayesian inference by message passing
compute = (upsilon_t::Float64, y_hat_t::Vector{Float64}) -> begin
m_u[1] = [ upsilon_t ] # Register action with the generative model
V_u[1] = fill(tiny, 1, 1) # Clamp control prior to performed action
m_x[1] = y_hat_t # Register observation with the generative model
V_x[1] = tiny*diageye(2) # Clamp goal prior to observation
data = Dict(:m_u => m_u,
:V_u => V_u,
:m_x => m_x,
:V_x => V_x,
:m_s_t_min => m_s_t_min,
:V_s_t_min => V_s_t_min)
model = mountain_car(T=T, Fg=Fg, Fa=Fa, Ff=Ff, engine_force_limit=engine_force_limit)
result = infer(model = model, data = data)
end
# The `act` function returns the inferred best possible action
act = () -> begin
if result !== nothing
return mode(result.posteriors[:u][2])[1]
else
# Without inference result we return some 'random' action
return 0.0
end
end
# The `future` function returns the inferred future states
future = () -> begin
if result !== nothing
return getindex.(mode.(result.posteriors[:s]), 1)
else
return zeros(T)
end
end
# The `slide` function modifies the `(m_s_t_min, V_s_t_min)` for the next step
# and shifts (or slides) the array of future goals `(m_x, V_x)` and inferred actions `(m_u, V_u)`
slide = () -> begin
model = RxInfer.getmodel(result.model)
(s, ) = RxInfer.getreturnval(model)
varref = RxInfer.getvarref(model, s)
var = RxInfer.getvariable(varref)
slide_msg_idx = 3 # This index is model dependent
(m_s_t_min, V_s_t_min) = mean_cov(getrecent(messageout(var[2], slide_msg_idx)))
m_u = circshift(m_u, -1)
m_u[end] = [0.0]
V_u = circshift(V_u, -1)
V_u[end] = Epsilon
m_x = circshift(m_x, -1)
m_x[end] = target
V_x = circshift(V_x, -1)
V_x[end] = Sigma
end
return (compute, act, slide, future)
end
create_agent (generic function with 1 method)
# Create another world
(execute_ai, observe_ai) = create_world(
Fg = Fg,
Ff = Ff,
Fa = Fa,
initial_position = initial_position,
initial_velocity = initial_velocity
)
# Planning horizon
T_ai = 50
# Let there be an agent
(compute_ai, act_ai, slide_ai, future_ai) = create_agent(;
T = T_ai,
Fa = Fa,
Fg = Fg,
Ff = Ff,
engine_force_limit = engine_force_limit,
target = target,
initial_position = initial_position,
initial_velocity = initial_velocity
)
# Length of trial
N_ai = 100
# Step through experimental protocol
agent_a = Vector{Float64}(undef, N_ai) # Actions
agent_f = Vector{Vector{Float64}}(undef, N_ai) # Predicted future
agent_x = Vector{Vector{Float64}}(undef, N_ai) # Observations
for t=1:N_ai
agent_a[t] = act_ai() # Invoke an action from the agent
agent_f[t] = future_ai() # Fetch the predicted future states
execute_ai(agent_a[t]) # The action influences hidden external states
agent_x[t] = observe_ai() # Observe the current environmental outcome (update p)
compute_ai(agent_a[t], agent_x[t]) # Infer beliefs from current model state (update q)
slide_ai() # Prepare for next iteration
end
plot_car(agent_x, target, title_plot="Mountain Car Problem: active inference agent", fps=5)

# Again, let's plot the goal and car positions over time
trajectories = reduce(hcat, agent_x)'
p1 = plot(trajectories[:,1], label="car: AIF agent", title = "Car and Goal Positions", color = "orange")
plot!(0.5 * ones(N_ai), color = "black", linestyle=:dash, label = "goal")
p2 = plot(agent_a, title = "Actions", color = "orange")
plot(p1,p2, layout = @layout [a ; b])
Note that the AIF agent explores other options, like going first in the opposite direction of the goal prior, to reach its goals. This agent is able to mix exploration (information-seeking behavior) with exploitation (goal-seeking behavior).
Extensions and Comments¶
Just to be sure, you don't need to memorize all FE/EFE decompositions nor are you expected to derive them on-the-spot. We present these decompositions only to provide insight into the multitude of forces that underlie FEM-based action selection.
In a sense, the FEP is an umbrella for describing the mechanics and self-organization of intelligent behavior, in man and machines. Lots of sub-fields in AI, such as reinforcement learning, can be interpreted as a special case of active inference under the FEP, see e.g., Friston et al., 2009.
Is EFE minimization really different from "regular" FE minimization? Not really, it appears that EFE minimization can be reformulated as a special case of FE minimization. In other words, FE minimization is still the only game in town.
Active inference also completes the "scientific loop" picture. Under the FEP, experimental/trial design is driven by EFE minimization. Bayesian probability theory (and FEP) contains all the equations for running scientific inquiry.
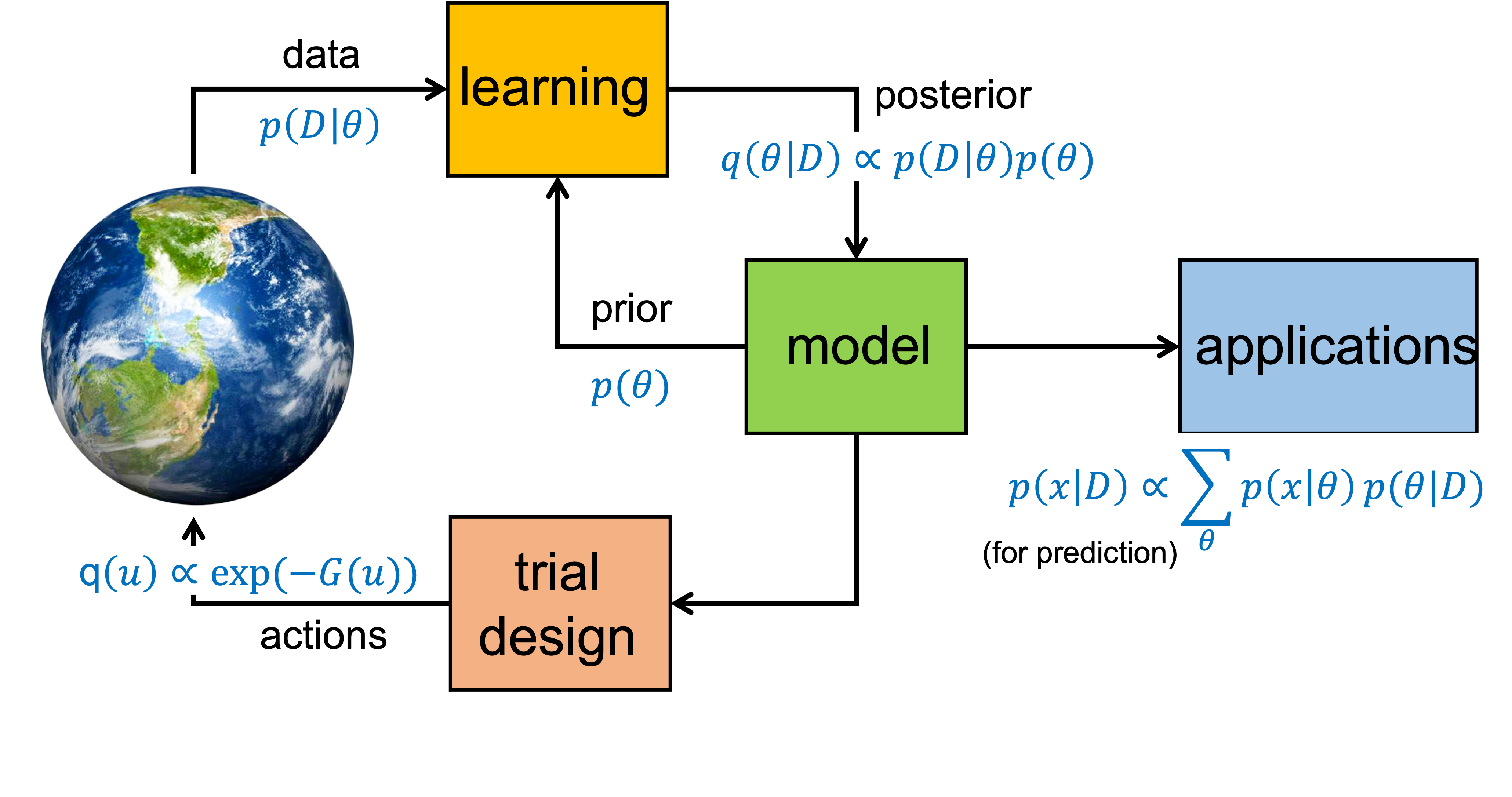
Essentially, AIF is an automated Scientific Inquiry Loop with an engineering twist. If there would be no goal prior, AIF would just lead to learning of a veridical ("true") generative model of the environment. This is what science is about. However, since we have goal prior constraints in the generative model, AIF leads to generating behavior (actions) with a purpose! For instance, when you want to cross a road, the goal prior "I am not going to get hit by a car", leads to inference of behavior that fulfills that prior. Similarly, through appropriate goal priors, the brain is able to design algorithms for object recognition, locomotion, speech generation, etc. In short, AIF is an automated Bayes-optimal engineering design loop!!
The big engineering challenge remains the computational load of AIF. The human brain consumes about 20 Watt and the neocortex only about 4 Watt (which is about the power consumption of a bicycle light). This is multiple orders of magnitude (at least 1 million times) cheaper than what we can engineer on silicon for similar tasks.
Final Thoughts¶
In the end, all the state inference, parameter estimation, etc., in this lecture series could have been implemented by FE minimization in an appropriately specified generative probabilistic model. However, the Free Energy Principle extends beyond state and parameter estimation. Driven by FE minimization, brains change their structure as well over time. In fact, the FEP extends beyond brains to a general theory for biological self-organization, e.g., Darwin's natural selection process may be interpreted as a FE minimization-driven model optimization process, and here's an article on FEP for predictive processing in plants. Moreover, Constrained-FE minimization (rephrased as the Principle of Maximum Relative Entropy) provides an elegant framework to derive most (if not all) physical laws, as Caticha exposes in his brilliant monograph on Entropic Physics. Indeed, the framework of FE minimization is known in the physics community as the very fundamental Principle of Least Action that governs the equations-of-motion in nature.
So, the FEP is very fundamental and extends way beyond applications to machine learning. At our research lab at TU/e, we work on developing FEP-based intelligent agents that go out into the world and autonomously learn to accomplish a pre-determined task, such as learning-to-walk or learning-to-process-noisy-speech-signals. Free free to approach us if you want to know more about that effort.
OPTIONAL SLIDES ¶
In an AIF Agent, Actions fulfill Desired Expectations about the Future¶
In the derivations above, we decomposed the EFE into an upperbound on the sum of a goal-seeking and information-seeking term. Here, we derive an alternative (exact) decomposition that more clearly reveals the goal-seeking objective.
We consider again the EFE and factorize the generative model $p(x,s|u) = p^\prime(x) p(s|x,u)$ as a product of a goal prior $p^\prime(x)$ on observations and a veridical state model $p(s|x,u)$.
Through the goal prior $p^\prime(x)$, the agent declares which observations it wants to observe in the future. (The prime is just to distinguish the semantics of a desired future from the model for the actual future).
Through the veridical state model $p(s|x,u)$ , the agent implicitly declares its beliefs about how the world will actually generate observations.
- In particular, note that through the equality (by Bayes rule)
it follows that in practice the agent may specify $p(s|x,u)$ implicitly by explicitly specifying a state transition model $p(s|u)$ and observation model $p(x|s)$.
Hence, an AIF agent holds both a model for its beliefs about how the world will actually evolve AND a model for its beliefs about how it desires the world to evolve!!
To highlight the role of these two models in the EFE, consider the following alternative EFE decomposition:
In this derivation, we have assumed that we can use the generative model to make inferences in the "forward" direction. Hence, $q(s|u)=p(s|u)$ and $q(x|s)=p(x|s)$.
The terms "ambiguity" and "risk" have their origin in utility theory for behavioral ecocomics. Minimization of EFE leads to minimizing both ambiguity and risk.
Ambiguous (future) states are states that map to large uncertainties about (future) observations. We want to avoid those ambiguous states since it implies that the model is not capable to predict how the world evolves. Ambiguity can be resolved by selecting information-seeking (epistemic) actions.
Minimization of the second term (risk) leads to choosing actions ($u$) that align predicted future observations (represented by $p(x|u)$) with desired future observations (represented by $p^\prime(x)$). Agents minimize risk by selecting pragmatic (goal-seeking) actions.
$\Rightarrow$ Actions fulfill desired expectations about the future!
Proof $q^*(u) = \arg\min_q F_>[q] \propto p(u)\exp(-G(u))$¶
$$\begin{aligned} F_>[q] &= \sum_{x,s,u} q(x,s,u) \log \frac{q(s,u)}{p(x,s,u)} \\ &= \sum_{x,s,u} q(x,s|u) q(u) \log \frac{q(s|u) q(u)}{p(x,s|u) p(u)} \\ &= \sum_{u} q(u) \bigg(\sum_{x,s} q(x,s|u) \log \frac{q(s|u) q(u)}{p(x,s|u) p(u)}\bigg) \\ &= \sum_{u} q(u) \bigg( \log q(u) + \log \frac{1}{p(u)}+ \underbrace{\sum_{x,s} q(x,s|u) \log \frac{q(s|u)}{p(x,s|u)}}_{G(u)}\bigg) \\ &= \sum_{u} q(u) \log \frac{q(u)}{p(u)\exp\left(- G(u)\right) } \end{aligned}$$- This is a KL-divergence. Minimization of $F_>[q]$ leads to the following posterior for the policy:
What Makes a Good Agent? The Good Regulator Theorem¶
According to Friston, an ``intelligent'' agent like a brain minimizes a variational free energy functional, which, in general, is a functional of a probability distribution $p$ and a variational posterior $q$.
What should the agent's model $p$ be modeling? This question was (already) answered by Conant and Ashby (1970) as the Good Regulator Theorem: every good regulator of a system must be a model of that system.
A Quote from Conant and Ashby's paper (this statement was later finessed by Friston (2013)):
"The theory has the interesting corollary that the living brain, insofar as it is successful and efficient as a regulator for survival, must proceed, in learning, by the formation of a model (or models) of its environment."

open("../../styles/aipstyle.html") do f
display("text/html", read(f,String))
end