Qurro QIIME 2 "Moving Pictures" Tutorial¶
In this tutorial, we'll demonstrate the process of using Qurro to investigate a compositional biplot generated by DEICODE.
0. Introduction¶
0.1. What is Qurro?¶
Lots of tools for analyzing " 'omic" datasets can produce feature rankings. These rankings can be used as a guide to look at the log-ratios of certain features in a dataset. Qurro is a tool for visualizing both of these types of data.
0.1.1. ...What are feature rankings?¶
The term "feature rankings" includes differentials, which we define as the estimated log-fold changes for features' abundances across different sample types. You can get this sort of output from lots of "differential abundance" tools, including but definitely not limited to ALDEx2, Songbird, Corncob, DESeq2, edgeR, etc.
The term "feature rankings" also includes feature loadings in a biplot (see Aitchison and Greenacre 2002); you can get biplots from running DEICODE, which is a tool that works well with microbiome datasets, or from a variety of other methods. In this tutorial we'll show how to use Qurro with feature loadings, but if you'd like to try out Qurro with differentials we encourage checking out the Qurro transcriptomics tutorial (which demonstrates using Qurro with those).
In either case -- differentials or feature loadings -- both of these flavors of "feature rankings" can be interpreted as, well, rankings (i.e. you can just sort them numerically). Visualizing these rankings gives us a list of features in a dataset sorted based on their association with some sort of variation, in either a supervised (in the case of differentials) or unsupervised (in the case of feature loadings) way. We call this a rank plot.
 Example rank plot from Fig. 2 in Morton and Marotz et al. 2019.
Example rank plot from Fig. 2 in Morton and Marotz et al. 2019.
0.1.2. What can we do with feature rankings?¶
A common use of these rankings is examining the log-ratios of particularly high- or low-ranked features across the samples in your dataset, and seeing how these log-ratios relate to your sample metadata (e.g. "does this log-ratio differ between 'healthy' and 'sick' samples?").
Log-ratio analyses are needed because data obtained from a microbiome study (or from various other types of " 'omic" studies) is, in general, "compositional": we only have access to the relative abundances of features in each sample, instead of their absolute abundances. To quote Gloor et al. 2017:
The starting point for any compositional analyses [sic] is a ratio transformation of the data. Ratio transformations capture the relationships between the features in the dataset and these ratios are the same whether the data are counts or proportions. Taking the logarithm of these ratios, thus log-ratios, makes the data symmetric and linearly related, and places the data in a log-ratio coordinate space (Pawlowsky-Glahn et al., 2015). Thus, we can obtain information about the log-ratio abundances of features relative to other features in the dataset, and this information is directly relatable to the environment.
For more details about creating and interpreting feature rankings, check out Morton and Marotz et al. 2019.
0.1.3. What does Qurro do?¶
Qurro is an interactive web application for visualizing feature rankings and log-ratios. It does this using a two-plot interface: on the left of the screen, a "rank plot" shows how features are ranked for a selected ranking, and on the right of the screen a "sample plot" shows the log-ratios of selected features' abundances within samples. There are a variety of controls available for selecting features for a log-ratio, and changing the selected log-ratio updates both the rank plot (highlighting selected features) and the sample plot (changing the y-axis value of each sample to match the selected log-ratio).
0.2. What is this tutorial going to cover?¶
In this tutorial, we'll visualize feature loadings in a biplot produced by DEICODE for the "Moving Pictures" dataset. We'll discuss various ways of using these feature loadings as a starting point for investigating log-ratios in a Qurro visualization.
This tutorial will pick up from where the DEICODE moving pictures tutorial leaves off. Don't worry if you haven't followed that tutorial yet; we'll provide all the files needed here.
1. Installing Qurro¶
First off, activate your QIIME 2 conda environment. Next, install Qurro as outlined in its installation instructions here.
Once you've installed Qurro, let's make sure that it was installed properly. Run the following commands in a terminal:
!qiime dev refresh-cache
!qiime qurro --help
QIIME is caching your current deployment for improved performance. This may take a few moments and should only happen once per deployment. Usage: qiime qurro [OPTIONS] COMMAND [ARGS]... Description: This QIIME 2 plugin supports the interactive visualization of feature rankings (either differentials or feature loadings -- when sorted numerically these provide rankings) in tandem with feature log-ratios across samples. Plugin website: https://github.com/biocore/qurro Getting user support: Please post to the QIIME 2 forum for help with this plugin: https://forum.qiime2.org Options: --version Show the version and exit. --example-data PATH Write example data and exit. --citations Show citations and exit. --help Show this message and exit. Commands: differential-plot Generate a Qurro visualization from feature differentials loading-plot Generate a Qurro visualization from feature loadings qarcoal Compute feature log-ratios based on textual taxonomy searching.
If these commands succeed, you should see information about Qurro's QIIME 2 plugin.
2. Input files¶
If you've completed the DEICODE tutorial already, you should already have these files. If you haven't completed the DEICODE tutorial already, you can find these files in the data/ folder within this notebook's folder.
table.qzaview | downloadsample-metadata.tsvdownloadtaxonomy.qzaview | downloadordination.qzaview | downloadbiplot.qzvview | download
2.1. Looking at the biplot¶
DEICODE produces a biplot using Robust Aitchison PCA. As mentioned above, the "feature rankings" we're going to look at here are the feature loadings in this biplot.
(Just to be clear, the actual data describing the biplot -- the sample and feature
loadings -- are contained in the ordination.qza artifact that DEICODE produces;
a visualization of this data is contained in biplot.qzv, a visualization produced by Emperor.)
(If you'd like to learn about the math behind how DEICODE generates a biplot, check out Martino et al. 2019.)
When using Qurro to look at DEICODE output, it makes sense to look at both the biplot and at the Qurro visualization. If we see a pattern in the biplot (e.g. "most of the samples cluster by their body site", or "samples along axis 1 seem to be separated by this metadata field"), then we can use that insight when looking for differentially abundant features in Qurro. (And if we don't observe these sorts of patterns, that can still be interesting as well!)
So let's open up biplot.qzv on view.qiime2.org. (You can also just click here on this link.) We should see something a bit like the following:

With a few clicks (changing colors and making the plot 2D in the Axes tab; clicking the "settings" button and toggling label visibility; coloring samples by BodySite; coloring features by Taxon) we can get a more informative and slightly prettier-looking visualization:

2.2. Interpreting the biplot¶
As was mentioned in the DEICODE moving pictures tutorial, it looks like samples separate in this biplot by body site.1 What's cool about biplots is that we can go further than just describing how samples vary in the ordination space. We can visualize features alongside samples, and see how these features are also associated with variation in the dataset. (See section 4 of Aitchison and Greenacre (2002) for details about interpreting biplots of compositional data.)
Now that we've familiarized ourselves with the biplot a little bit, let's take a look at a Qurro visualization of the corresponding feature loadings.
1This isn't that surprising; it's known that the community of microorganisms living in someone's gut is generally pretty different from, say, the community of microorganisms living on the skin of that same person's hand (as a reference see, for example, this paper from the Human Microbiome Project).
3. Generating a Qurro visualization¶
Since the type of rankings we're using are feature loadings, we'll need to use the qiime qurro loading-plot command to generate a Qurro visualization.
!qiime qurro loading-plot \
--i-table data/table.qza \
--i-ranks data/ordination.qza \
--m-sample-metadata-file data/sample-metadata.tsv \
--m-feature-metadata-file data/taxonomy.qza \
--o-visualization data/qurro-plot.qzv
Saved Visualization to: data/qurro-plot.qzv
Output Artifacts¶
You just generated your first Qurro visualization! qurro-plot.qzv is a .qzv file -- in other words, a QIIME 2 visualization. As with other QIIME 2 visualizations (e.g. the biplot.qzv file we made above), you can view it either by running qiime tools view qurro-plot.qzv or by uploading it to view.qiime2.org. (You can also just click on the "view" link right above to see a precomputed version of this visualization.)
4. Interacting with a Qurro visualization¶
Let's view qurro-plot.qzv, as described above. You should see something like
this:

(The Qurro screenshots in this tutorial are zoomed out a bit so that we can show all the relevant parts of the display; depending on your screen resolution things might look slightly different.)
In any case, right away we see two things: on the left a plot of rankings (in this case, sorted loadings) for each feature, and on the right a plot of selected features' log ratios in samples. Throughout this tutorial these plots will be referred to as the rank plot and sample plot, respectively.
Since no features are currently selected to be part of a log-ratio, these plots look pretty empty. Let's select some features!
4.1. First steps: trying out autoselection¶
Autoselection is a quick way of selecting the log-ratio of the highest- to lowest- ranked features for a given ranking. It's useful if you have a suspicion that a given feature ranking field "separates" certain types of samples.
For example, let's take another look at the DEICODE biplot from before: notice how the gut samples (colored brown) seem to cluster to the left side of Axis 1? We should be able to find out about what features are driving this separation. To investigate this, enter in 5 in the autoselection field (located in the bottom-right quadrant of the screen), and click Apply:

Things are more busy now! The rank plot has been updated to show that a log-ratio of the top 5% of features and the bottom 5% of features ranked for the Axis 1 feature loadings is selected. The sample plot has been updated, also: each sample's log-ratio is shown on the y-axis.
Of course, the sample plot is currently set to have an x-axis of BarcodeSequence, which is kind of useless right now. Let's adjust the x-axis field and color field selectors (in the top-right quadrant of the screen) to say BodySite:

As we expected, this log-ratio clearly separates gut samples from most of the other samples in this dataset. There are two right palm samples that still cluster with these gut samples, though, which is interesting! As an exercise for the reader -- looking at the biplot, does these two right palm samples having such a low log-ratio here make sense to you? Try checking out sample IDs by hovering over points in the Qurro sample plot, or by double-clicking on a sample in Emperor.
4.2. Moving from autoselection to taxonomy-based filtering¶
Although having a log-ratio that kind of differentiates poop samples from skin/oral samples is somewhat interesting, we might want to know more about the specific features that influence this separation. For example, what are the assigned taxonomic classifications of the highest- and lowest- ranked features in the Axis 1 feature loadings?
To investigate this, let's look at the tables of selected numerator / denominator features in the bottom left quadrant of the screen. These are interactive tables showing all of the features present in the currently selected log-ratio: each row represents a selected feature. You can sort the rows of these tables by any of the columns in the table.
Let's use the Axis 1 column to sort the numerator and denominator tables:

(Notice how the arrow icon for the Numerator Features table is pointing down, indicating that it's sorted in descending order, and how the arrow icon for the Denominator Features table is pointing up -- indicating that it's sorted in ascending order.)
Once we've got things sorted, we can scroll over and check out the assigned taxonomic classifications (Taxon) for these features. As you scroll through the table, do you notice any patterns?

We can see that the highest-ranked feature for the Axis 1 loadings is classified in the genus Pseudomonas, and the lowest-ranked feature is classified as mitochondria. Let's try looking at the log-ratio between these features' families: so, between the features classified as being in f__Pseudomonadaceae and the features classified as being in f__mitochondria. (Note: in practice, you may want to filter mitochondria out of your datasets entirely -- see this discussion. Feel free to try out the second lowest-ranked feature, classified as g__Bacteroides, as the denominator here instead!)
To investigate this, we'll need to use the Selecting Features by Filtering controls, located in the bottom-right quadrant of the screen. Enter f__Pseudomonadaceae in the top filtering text box, and enter f__mitochondria in the bottom filtering text box. Next, change the first selectors (that currently say Feature ID) to say Taxon. Finally, hit Apply Filtering! You should see the following:

Wow, the sample plot looks empty! The filtering worked, but what happened?
4.3. Dealing with missing samples¶
As we can see from looking at the sample plot, only palm samples are shown right now -- all of the gut and tongue samples are missing. The text underneath the sample plot controls confirms this -- right now, it says that only 10 / 34 samples (29.41%) are shown in the sample plot. What gives?
As the text underneath the sample plot explains, it's because the missing samples have invalid log-ratios. These samples either don't have any f__Pseudomonadaceae features observed, don't have any f__mitochondria features observed, or didn't have either of these types of features observed.
Zeroes in either the top or bottom of a log-ratio mess things up. The logarithm of 0 / x (i.e the logarithm of 0) is undefined, as is the logarithm of x / 0 (since you straight-up can't divide by 0 in the first place).
Methods like autoselection are a way to try get around this problem -- by having a group of features in a side of a log-ratio, not just a single feature, you're more likely to "pick up" samples. We can also try to circumvent this problem by "going up" a taxonomic ranking -- for example, looking at the order level instead of the family level.
Of course, both of these methods (usually) introduce more features into your log-ratio -- and the more crowded your log-ratio gets, the less specificity you have in the conclusions you can draw. There's a tradeoff, and unfortunately no "easy" way to get around this (aside from things like pseudocounts, which aren't officially supported in Qurro yet).
Of course, it's totally possible to identify more robust (i.e. present in more than 10 samples :) log-ratios from investigating these tables -- check out the Qurro transcriptomics tutorial for a nice example of this. However, we're going to move on for right now.
5. Using Emperor alongside Qurro to try out log-ratios directly from a biplot¶
Let's say you see a feature in the biplot that you want to investigate in more detail. Here, we'll use the biplot from before as a way to "select features" in Qurro.
5.1. Selecting features from Emperor¶
First, make sure you've still got the biplot open in another browser tab or window.
Here's a screenshot of the biplot from before. Samples (spheres) are colored by their BodySite and features (arrows) are colored by their Taxon.
Let's try to select a log-ratio that differentiates samples along Axis 1. Here, we'll try this by looking at the log-ratio of the purple arrow to the smaller dark-blue arrow, but feel free to try out any features you like.
In order to select a feature from the Emperor visualization, you'll need to double-click on the head of an arrow in the visualization. You should see a message pop up in the bottom left of your screen that says (copied to clipboard), followed by a long sequence of characters. This indicates that you just copied the Feature ID of this feature to your clipboard.
Move back to the tab or window where you have the Qurro plot open. You can paste (using something like ctrl-V or ⌘-V) the feature ID you just copied directly into the numerator or denominator search box, in the bottom right corner of Qurro's interface. You can do this twice (once for the numerator and once for the denominator) to create log-ratios of features directly from the biplot. (Make sure to change the feature field selector back to Feature ID, since we're searching using these feature IDs directly.)
Now press the Apply Filtering button to select these two features, applying their log-ratio to the rank and sample plots.
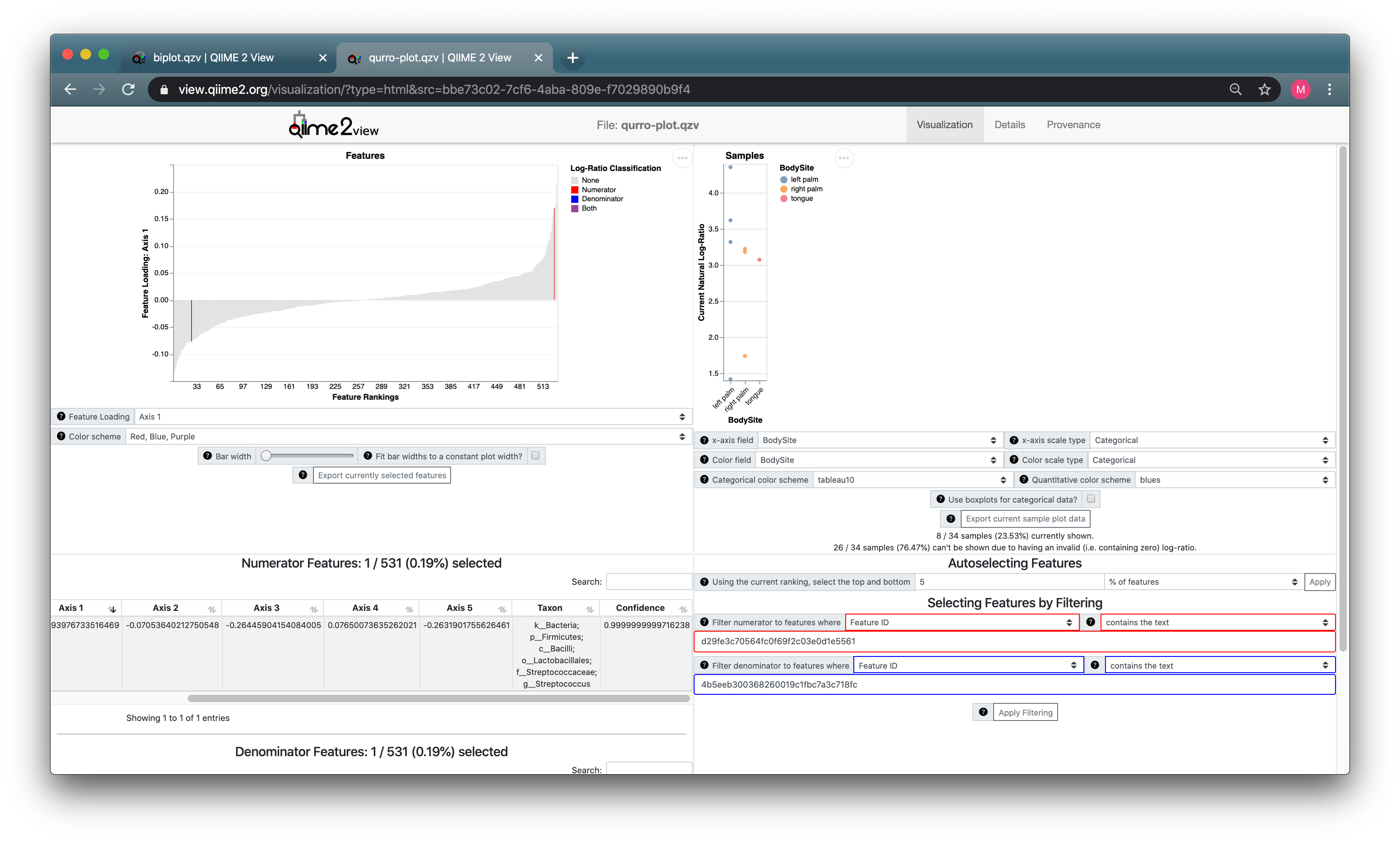
The sample plot looks pretty empty, again -- now only 8 / 34 samples are shown. It's clear that a lot of samples have a 0 in one or both sides of this log-ratio.
5.2. Moving "up" taxonomic ranks¶
Since microbiome datasets are so sparse, we're probably going to face this sort of problem no matter what combinations of features we try. Let's try getting around this, then.
Rather than select a log-ratio of one feature to another, let's try selecting a log-ratio based on these features' taxonomic classifications. The feature represented by the purple arrow in the biplot was annotated as k__Bacteria; p__Firmicutes; c__Bacilli; o__Lactobacillales; f__Streptococcaceae; g__Streptococcus, and the feature represented by the small blue arrow was annotated as k__Bacteria; p__Bacteroidetes; c__Bacteroidia; o__Bacteroidales; f__Bacteroidaceae; g__Bacteroides; s__. So let's try taking the log-ratio of g__Streptococcus features to g__Bacteroides features:

Now things are more populated! The sample plot has at least a few samples from each of the four body sites -- and we've managed to recapitulate the general pattern of sample separation we saw with the autoselection, but with a more targeted log-ratio between two genera.
Sidenote: using multiple features from Emperor in the same side of a log-ratio¶
If you'd like, you can specify arbitrary amounts of feature IDs on one side of a log-ratio. This can be done by separating the IDs by | characters and using the contains text separated by | (pipe) searching option; see the Selection tutorial for details.
5.3. Hey, wait a second! There are only eight arrows in the biplot, but there are over five hundred features in the rank plot. What gives?¶
This is just a result of how the biplot visualization was created in the DEICODE tutorial. In the qiime emperor biplot command, the --p-number-of-features parameter was set to 8, so only 8 arrows (i.e. features) are shown in the Emperor visualization of the biplot. Feel free to try rerunning this command with a different number of features to show more features in the biplot.
(Emperor's choice of which features to show is based on features' "magnitude based on all ... dimensions" -- see this comment and the surrounding QIIME 2 forum thread for context.)
6. Epilogue: Staving off p-hacking¶
So, I know what you might be thinking. Isn't the problem of selecting features intractable? For a dataset with n features, there are on the order of 2n ways to select a group of features to include in the numerator or denominator of a log-ratio -- what does this mean in practice? Are all analyses that use Qurro doomed to be p-hacked to oblivion, since there are just so many things you can try?
Hopefully not! The idea with feature rankings is that these provide an intuitive way to select features -- Qurro was not designed to enable brute-forcing the selection of log-ratios. If you find yourself trying lots of log-ratios over and over again in order to manipulate the sample plot to look "how you want it to," you should take a few steps back and ask yourself what question you're trying to answer.
...However, yes, in practice there's nothing stopping you from spending hours trying over and over to manipulate things to find something interesting. This is a problem I've been thinking about for some time. A good way to account for this, which QIIME 2 and Qurro work well with, is sharing your Qurro visualizations along with the rest of your data. You can just upload the corresponding QZV file to GitHub, or to another data-hosting site, and other researchers can try out the visualization for themselves. If your conclusions don't hold up under scrutiny -- for example, your paper has a figure of the sample plot represented as a boxplot, but only a few samples are actually present in the boxplot because the rest were dropped and you didn't mention that in your paper -- then this should be apparent to other people recreating your work in Qurro.
7. Other work on selecting features¶
Selecting features for log-ratios "optimally" (where "optimally" might mean distinguishing two groups of samples, etc.) is still an area of ongoing research, although some heuristics have been proposed. Our hope is that Qurro makes the process of established compositional data analysis methods -- in this tutorial, biplots and log-ratios -- easier; in the end, how you use it is up to you.
In terms of heuristics that have been proposed for selecting log-ratios automatically, one cool method is selbal, described in Rivera-Pinto et al. 2018. In theory, you could use the output of selbal as a starting point for playing around with feature selection in a Qurro visualization, but I haven't tried this as of writing; if you try this, let me know how it goes!
Morton and Marotz et al. 2019 also offers a good review of log-ratio analyses, and how to interpret rank plots (see the section on "Interpreting ranks" for details). Of course, some of the authors of this paper are also authors of Qurro, so this might not be the most unbiased advice :)
Lastly, any discussion of interpreting compositional biplots (like those DEICODE generates) wouldn't be complete without mentioning Aitchison and Greenacre 2002. We actually have a tutorial showing off using Qurro with the color composition data shown in that paper!
8. Acknowledgements¶
This tutorial was based on the DEICODE and QIIME 2 moving pictures tutorials.