Word-level entailment with neural networks¶
__author__ = "Christopher Potts"
__version__ = "CS224u, Stanford, Spring 2016"
Overview¶
Problem: For two words $w_{1}$ and $w_{2}$, predict $w_{1} \subset w_{2}$ or $w_{1} \supset w_{2}$. This is a basic, word-level version of the task of Natural Language Inference (NLI).
Approach: Shallow feed-forward neural networks. Here's a broad overview of the model structure and task:
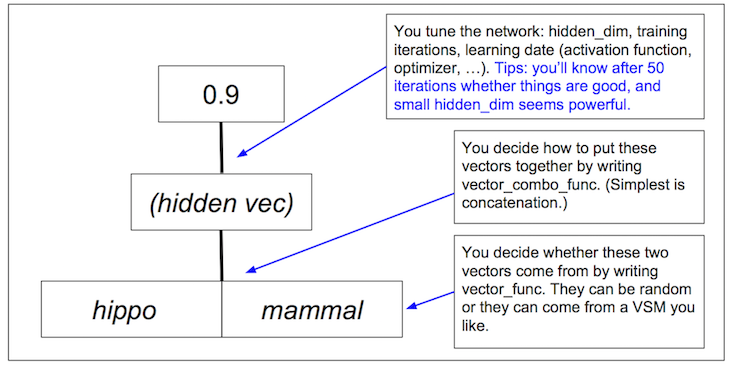
Set-up¶
- Make sure your environment includes all the requirements for the cs224u repository, especially TensorFlow, which isn't included in the standard Anaconda distribution (but is easily installed).
- Make sure you have the the Wikipedia 2014 + Gigaword 5 distribution of pretrained GloVe vectors downloaded and unzipped, and that
glove_homebelow is pointing to it. - Make sure
wordentail_data_filenamebelow is pointing to the full path forwordentail_data.pickle, which is included in the cs224u repository.
wordentail_data_filename = 'wordentail_data.pickle'
glove_home = "glove.6B"
import os
import sys
import pickle
import random
from collections import defaultdict
import numpy as np
from sklearn.metrics import classification_report
import utils
from shallow_neural_networks import ShallowNeuralNetwork
Data¶
As suggested by the task decription, the dataset consists of word pairs with a label indicating that the first entails the second or the second entails the first.
The pickled data distribution is a tuple in which the first member is the vocabulary for the entire dataset and the second is a dictionary establishing train/test splits:
wordentail_data = pickle.load(open(wordentail_data_filename, 'rb'))
vocab, splits = wordentail_data
The structure of splits creates a single training set and two different test sets:
splits.keys()
dict_keys(['disjoint_vocab_test', 'train', 'test'])
All three sets are disjoint in terms of word pairs.
The
testvocab is a subset of thetrainvocab. So every word seen at test time was seen in training.The
disjoint_vocab_testsplit has a vocabulary that is totally disjoint fromtrain. So none of the words are seen in training.All the words are in the GloVe vocabulary.
Each split is itself a dict mapping class names to lists of word pairs. For example:
splits['train'].keys()
dict_keys([1.0, -1.0])
splits['train'][1.0][: 5]
[['polynesian', 'inhabitant'], ['wiper', 'worker'], ['argonaut', 'adventurer'], ['bride', 'relative'], ['aramean', 'semite']]
The class labels are 1.0 if the first word entails the second, and -1.0 if the second entails the first. These labels are scaled to the particular neural models we'll be using, in particular, to the tanh activation functions they use by default. It's also worth noting that we'll be treating these labels using a one-dimensional output space, since they are completely complementary.
SUBSET = 1.0 # Left word entails right, as in (hippo, mammal)
SUPERSET = -1.0 # Right word entails left, as in (mammal, hippo)
Neural network architecture¶
For this notebook, we'll use a simple shallow neural network parameterized as follows:
- A weight matrix $W^{1}$ of dimension $m \times n$, where $m$ is the dimensionality of the input vector representations and $n$ is the dimensionality of the hidden layer.
- A bias term $b^{1}$ of dimension $n$.
- A weight matrix $W^{2}$ of dimension $n \times p$, where $p$ is the dimensionality of the output vector.
- A bias term $b^{2}$ of dimension $p$.
The network is then defined as follows, with $x$ the input layer, $h$ the hidden layer of dimension $n$, and $y$ the output of dimension $1 \times p$:
$$h = \tanh\left(xW^{1} + b^{1}\right)$$$$y = \tanh\left(hW^{2} + b^{2}\right)$$We'll first implement this from scratch and then reimplement it in TensorFlow. Our hope is that this will provide a firm foundation for your own exploration of neural models for NLI.
Shallow neural networks from scratch¶
Before moving to TensorFlow, it's worth building up our simple shallow architecture from scratch, as a way to explore the concepts and avoid the dangers of black-box machine learning.
The full implementation is in shallow_neural_networks.py, as ShallowNeuralNetwork, so that we can use it as a free-standing module. Check it out — it's just a few dozen lines of code.
Input feature representation¶
Even in deep learning, feature representation is the most important thing and requires care! For our task, feature representation has two parts: representing the individual words and combining those representations into a single network input.
Representing words¶
Our baseline word representations will be random vectors. This works well for the test task but is of course hopeless for the disjoint_vocab_test one.
def randvec(w, n=50, lower=-0.5, upper=0.5):
"""Returns a random vector of length `n`. `w` is ignored."""
return np.array([random.uniform(lower, upper) for i in range(n)])
Whereas random inputs are hopeless for disjoint_vocab_test, GloVe vectors might not be ...
# Any of the files in glove.6B will work here:
glove50_src = os.path.join(glove_home, 'glove.6B.50d.txt')
# Creates a dict mapping strings (words) to GloVe vectors:
GLOVE50 = utils.glove2dict(glove50_src)
def glove50vec(w):
"""Return `w`'s GloVe representation if available, else return
a random vector."""
return GLOVE50.get(w, randvec(w, n=50))
Combining words into inputs¶
Here we decide how to combine the two word vectors into a single representation. In more detail, where $x_{l}$ is a vector representation of the left word and $x_{r}$ is a vector representation of the right word, we need a function $\textbf{combine}$ such that $\textbf{combine}(x_{l}, x_{r})$ returns a new input vector $x$ of dimension $m$.
def vec_concatenate(u, v):
"""Concatenate np.array instances `u` and `v` into a new np.array"""
return np.concatenate((u, v))
$\textbf{combine}$ could be concatenation as in vec_concatenate, or vector average, vector difference, etc. (even combinations of those) — there's lots of space for experimentation here.
Building datasets for experiments¶
As usual, we define a function that featurizes the data (here, according to vector_func and vector_combo_func) and puts it into the right format for optimization.
def build_dataset(
wordentail_data,
vector_func=randvec,
vector_combo_func=vec_concatenate):
"""
Parameters
----------
wordentail_data
The pickled dataset at `wordentail_data_filename`.
vector_func : (default: `randvec`)
Any function mapping words in the vocab for `wordentail_data`
to vector representations
vector_combo_func : (default: `vec_concatenate`)
Any function for combining two vectors into a new vector
of fixed dimensionality.
Returns
-------
dataset : defaultdict
A map from split names ("train", "test", "disjoint_vocab_test")
into data instances:
{'train': [(vec, [cls]), (vec, [cls]), ...],
'test': [(vec, [cls]), (vec, [cls]), ...],
'disjoint_vocab_test': [(vec, [cls]), (vec, [cls]), ...]}
"""
# Load in the dataset:
vocab, splits = wordentail_data
# A mapping from words (as strings) to their vector
# representations, as determined by vector_func:
vectors = {w: vector_func(w) for w in vocab}
# Dataset in the format required by the neural network:
dataset = defaultdict(list)
for split, data in splits.items():
for clsname, word_pairs in data.items():
for w1, w2 in word_pairs:
# Use vector_combo_func to combine the word vectors for
# w1 and w2, as given by the vectors dictionary above,
# and pair it with the singleton array containing clsname:
item = [vector_combo_func(vectors[w1], vectors[w2]),
np.array([clsname])]
dataset[split].append(item)
return dataset
Running experiments¶
The function experiment trains its network parameters on dataset['train'] and then evaluates its performance on all three splits:
def experiment(dataset, network):
"""Train and evaluation code for the word-level entailment task.
Parameters
----------
dataset : dict
With keys 'train', 'test', and 'disjoint_vocab_test', each with
values that are lists of vector pairs, the first giving the
example representation and the second giving its 1d output vector.
The expectation is that this was created by `build_dataset`.
network
This will be `ShallowNeuralNetwork` or `TfShallowNeuralNetwork`
below, but it could be any function that can train and
evaluate on `dataset`. The needed methods are `fit` and
`predict`.
Prints
------
To standard ouput
An sklearn classification report for all three splits.
"""
# Train the network:
network.fit(dataset['train'])
# The following is evaluation code. You won't have to alter it
# unless you did something unexpected like transform the output
# variables before training.
for typ in ('train', 'test', 'disjoint_vocab_test'):
data = dataset[typ]
predictions = []
cats = []
for ex, cat in data:
# The raw prediction is a singleton list containing a float,
# either -1 or 1. We want only its contents:
prediction = network.predict(ex)[0]
# Categorize the prediction for accuracy comparison:
prediction = SUPERSET if prediction <= 0.0 else SUBSET
predictions.append(prediction)
# Store the gold label for the classification report:
cats.append(cat[0])
# Report:
print("="*70)
print(typ)
print(classification_report(cats, predictions, target_names=['SUPERSET', 'SUBSET']))
Here's a baseline experiment run:
baseline_dataset = build_dataset(
wordentail_data,
vector_func=randvec,
vector_combo_func=vec_concatenate)
baseline_network = ShallowNeuralNetwork()
experiment(baseline_dataset, baseline_network)
completed iteration 100; error is 70.0256787791
======================================================================
train
precision recall f1-score support
SUPERSET 0.99 0.99 0.99 2000
SUBSET 0.99 0.99 0.99 2000
avg / total 0.99 0.99 0.99 4000
======================================================================
test
precision recall f1-score support
SUPERSET 0.89 0.85 0.87 200
SUBSET 0.86 0.89 0.87 200
avg / total 0.87 0.87 0.87 400
======================================================================
disjoint_vocab_test
precision recall f1-score support
SUPERSET 0.51 0.55 0.53 49
SUBSET 0.51 0.47 0.49 49
avg / total 0.51 0.51 0.51 98
Shallow neural networks in TensorFlow¶
Let's now translate ShallowNeuralNetwork into TensorFlow. TensorFlow is a powerful library for building deep learning models. In essence, you define the model architecture and it handles the details of optimization. In addition, it is very high-performance, so it will scale to large datasets and complicated model designs. The full implementation is in shallow_neural_networks.py, as TfShallowNeuralNetwork. It's even less code than our ShallowNeuralNetwork!
Here's a baseline run with this new network, using baseline_dataset as created above for our other baseline experiment.
try:
import tensorflow
except:
print("Warning: TensorFlow is not installed, so you won't be able to use `TfShallowNeuralNetwork`.")
# Let's not try to run this if `tensorflow` isn't available:
if 'tensorflow' in sys.modules:
from shallow_neural_networks import TfShallowNeuralNetwork
baseline_tfnetwork = TfShallowNeuralNetwork()
experiment(baseline_dataset, baseline_tfnetwork)
======================================================================
train
precision recall f1-score support
SUPERSET 0.95 0.95 0.95 2000
SUBSET 0.95 0.95 0.95 2000
avg / total 0.95 0.95 0.95 4000
======================================================================
test
precision recall f1-score support
SUPERSET 0.86 0.84 0.85 200
SUBSET 0.85 0.86 0.85 200
avg / total 0.85 0.85 0.85 400
======================================================================
disjoint_vocab_test
precision recall f1-score support
SUPERSET 0.54 0.59 0.56 49
SUBSET 0.55 0.49 0.52 49
avg / total 0.54 0.54 0.54 98
In-class bake-off¶
The goal: achieve the highest average F1 score on disjoint_vocab_test.
Notes
You must train only on the
trainsplit. No outside training instances can be brought in. You can, though, bring in outside information via your input vectors, as long as this information is not fromtestordisjoint_vocab_test.Since the evaluation is for
disjoint_vocab_test, you're not going to get very far with random input vectors! A GloVe featurizer is defined above (glove50vec). Feel free to look around for new word vectors on the Web, or even train your own using ourvsmnotebook.You're not required to stick to the network structures defined above. For instance, you could create deeper versions of them. As long as you have
fitandpredictmethods with the same input and output types as our networks, you should be able to useexperiment. Usingexperimentis not a requirement, though.
At the end of class, bring your score to one of the teaching team. We'll report the results in the class discussion forum.