From Maps to Models - Tutorials for structural geological modeling using GemPy and GemGIS ¶
Model 1 - Horizontal Layers¶
This first notebook illustrates how to create a simple sample model of horizontal layers in GemPy. The model consists of four parallel layers plus basement layers and has an extent of 1000 m by 1000 m with a vertical extent of 600 m. No folded, faulted or truncated layers are present in this model.
If you have not gone through the introduction notebook for the course, please check it out: Introduction Notebook (notebook on Github)
- How to import input data into GemPy via CSV-Files (comma-separated-values) and what the files have to look like
- How to build a simple model consisting of horizontal layers belonging to one Series
- How to visualize the resulting model with cross sections in 2D and the entire model in 3D
Contents¶
- Installing GemPy
- Importing Libraries
- Data Preparation
- GemPy Model Calculation
- Model Visualization and Post-Processing
- Conclusions
- Outlook
- Licensing

The input data is provided as already prepared CSV-files (comma-separated-values) and will be loaded as Pandas DataFrames (see Figure below, DataFrame). The first file contains the interface points, the boundaries between the four stratigraphic units. It should consist of four columns with the headers X, Y, Z for the location of the interface points in meter and formation for name of the layer the interface belongs to (see Figure below). The second file contains the orientation of the layers with the same columns as before plus three more columns, dip, azimuth, and polarity indicating the dip the layer and the dip direction (azimuth, see Figure below) in degrees. The dip varies from 0° for horizontal layers to 90° for vertical layers. The azimuth varies from 0° (N) via 180° (S) to 360° (N). Here, we only provide the orientations for one layer. This will be explained later on in more detail. The polarity value is mostly set to 1.

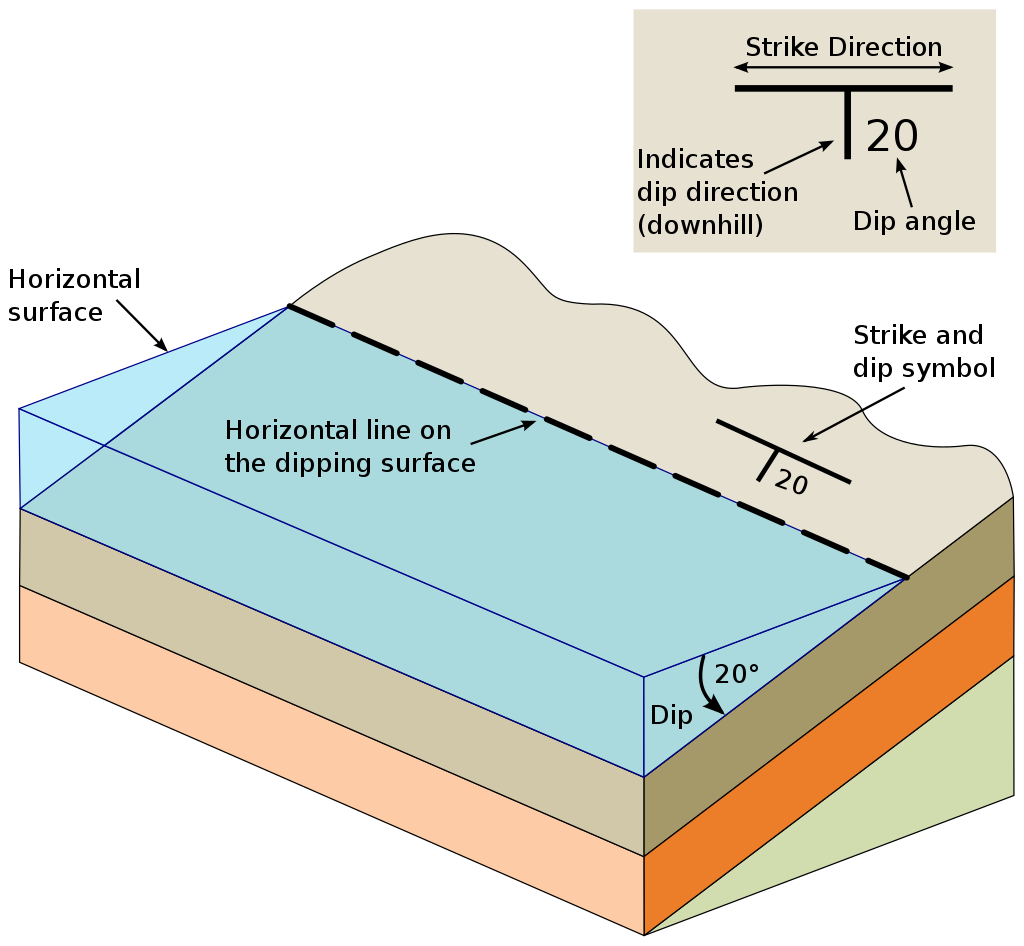
By CrunchyRocks, after Karla Panchuck - https://openpress.usask.ca/physicalgeology/chapter/13-5-measuring-geological-structures/, CC BY 4.0, https://commons.wikimedia.org/w/index.php?curid=113554289
Installing GemPy¶
If you have not installed GemPy yet, please follow the installation instructions. If you encounter any issues, feel free to open a new discussion at GemPy Discussions. If you encounter an error in the installation process, feel free to also open an issue at GemPy Issues. There, the GemPy development team will help you out.
Importing Libraries¶
For this notebook, we need the pandas library for the data preparation, matplotlib for plotting and of course the gempy library. Any warnings that may appear can be ignored for now.
import pandas as pd
import gempy as gp
import matplotlib.pyplot as plt
WARNING (theano.configdefaults): g++ not available, if using conda: `conda install m2w64-toolchain`
C:\Users\ale93371\Anaconda3\envs\gempy_new8\lib\site-packages\theano\configdefaults.py:560: UserWarning: DeprecationWarning: there is no c++ compiler.This is deprecated and with Theano 0.11 a c++ compiler will be mandatory
warnings.warn("DeprecationWarning: there is no c++ compiler."
WARNING (theano.configdefaults): g++ not detected ! Theano will be unable to execute optimized C-implementations (for both CPU and GPU) and will default to Python implementations. Performance will be severely degraded. To remove this warning, set Theano flags cxx to an empty string.
WARNING (theano.configdefaults): install mkl with `conda install mkl-service`: No module named 'mkl'
WARNING (theano.tensor.blas): Using NumPy C-API based implementation for BLAS functions.
Data Preparation¶
For this model, the only thing that needs to be done is loading the already created interface points and orientations. In the next tutorials, you will create the data yourself and process it further to make it usable for GemPy.
Importing Interface Points¶
We are using the pandas library (Pandas) to load the interface points that were prepared beforehand and stored as CSV-file (comma-separated-file). The only information that is needed are the location of the interface point (X, Y, Z) and the formation it belongs to. You may have to adjust the delimiter when loading the file.
interfaces = pd.read_csv('../../data/model1/model1_interfaces.csv',
delimiter = '\t')
interfaces.head()
| X | Y | Z | formation | |
|---|---|---|---|---|
| 0 | 200 | 250 | -150 | Layer1 |
| 1 | 200 | 500 | -150 | Layer1 |
| 2 | 200 | 750 | -150 | Layer1 |
| 3 | 200 | 250 | -250 | Layer2 |
| 4 | 200 | 500 | -250 | Layer2 |
Importing Orientations¶
The orientations will also be loaded using pandas. In addition to the location and the formation the orientation belongs to, the dip value, azimuth value (dip direction) and a polarity value (mostly set to 1 by default) needs to be provided. As the model will feature horizontal layers, the dip is equal to 0. These three provided orientations belonging to Layer1 are all the orientations that are needed to compute the model. There are no other orientations needed as the potential field approach implemented in GemPy allows to combine subparallel layers in on so-called Series where only at least one orientation is needed for the entire series.
orientations = pd.read_csv('../../data/model1/model1_orientations.csv',
delimiter='\t')
orientations.head()
GemPy Model Calculation¶
The following part introduces the main steps of creating a model in GemPy.
The creation of a GemPy Model follows particular steps which will be performed in the following:
- Create new model:
gp.create_model() - Data Initiation:
gp.init_data() - Map Stack to Surfaces:
gp.map_stack_to_surfaces() - [...]
- Set the Interpolator:
gp.set_interpolator() - Computing the Model:
gp.compute_model()
Creating the GemPy Model¶
The first step is to create a new empty GemPy model by providing a name for it.
geo_model = gp.create_model('Model1_Horizontal_Layers')
geo_model
It is possible to check out the different attributes of the GemPy model object using vars(). It is mostly empty for now but will be filled in the following steps. The most important attributes/objects of the GemPy model are:
surface_pointsorientationsgridsurfacesseriesadditional_datafaultsstack
vars(geo_model)
The attributes can easily be accessed via the geo_model.
geo_model.surface_points
geo_model.orientations
geo_model.grid
geo_model.surfaces
geo_model.series
geo_model.additional_data
geo_model.faults
geo_model.stack
Data Initiation¶
During this step, the extent of the model (xmin, xmax, ymin, ymax, zmin, zmax) and the resolution in X, Yand Z direction (res_x, res_y, res_z, equal to the number of cells in each direction) will be set using lists of values. If you want to provide cells with a certain size, you would have to calculate the following. It is important to convert the resulting number of cells into an int as only integer values for the number of cells are valid.
res_x = int((xmax-xmin)/cell_size_x)
res_y = int((ymax-ymin)/cell_size_y)
res_z = int((zmax-zmin)/cell_size_z)
The interface points (surface_points_df) and orientations (orientations_df) will be passed as pandas DataFrames.
gp.init_data(geo_model=geo_model,
extent=[0, 1000, 0, 1000, -600, 0],
resolution=[100, 100, 100],
surface_points_df=interfaces,
orientations_df=orientations,
default_values=True)
Inspecting the Surfaces¶
The model consists of four different layers or surfaces now which all belong to the Default series. During the next step, the proper Series will be assigned to the surfaces. Using the surfaces-attribute again, we can check which layers were loaded.
geo_model.surfaces
Inspecting the Input Data¶
The loaded interface points and orientations can again be inspected using the surface_points- and orientations-attributes. Using the df-attribute of this object will convert the displayed table in a pandas DataFrame.
geo_model.surface_points.df.head()
geo_model.orientations.df.head()
A second way of inspecting the data is the following. You can pass the following strings to the function to get the respective datasets: 'all', 'surface_points', 'orientations', 'surfaces', 'series', 'faults', 'faults_relations','additional data'.
gp.get_data(geo_model, 'surface_points').head()
gp.get_data(geo_model, 'orientations').head()
Map Stack to Surfaces¶
We want our geological units to appear in the correct order relative to age. Such order might for example be given by a depositional sequence of stratigraphy, unconformities due to erosion or other lithological genesis events such as igneous intrusions. Defining the correct order of series is vital to the construction of the model!
During this step, all four layers of the model are assigned to the Strata1 series. Per definition, only orientations for one layer are necessary to compute the model. However, it is of course possible to provide orientation measurements for the other layers as well. If the layers were not parallel as shown in the next models, multiple series would be defined. We will also add a Basement here (geo_model.add_surfaces('Basement')). The order within one series also defines the age relations within this series and has to be according to the depositional events of the layers.
gp.map_stack_to_surfaces(geo_model,
{
'Strata1': ('Layer1', 'Layer2', 'Layer3', 'Layer4'),
},
remove_unused_series=True)
geo_model.add_surfaces('Basement')
geo_model.surfaces
geo_model.stack
Plotting the input data in 2D using Matplotlib¶
The input data can now be visualized in 2D using matplotlib. This might for example be useful to check if all points and measurements are defined the way we want them to. Using the function plot_2d(), we attain a 2D projection of our data points onto a plane of chosen direction (we can choose this attribute to be either 'x', 'y', or 'z').
gp.plot_2d(geo_model,
direction='z',
show_lith=False,
show_boundaries=False)
plt.grid()
Plotting the input data in 3D using PyVista¶
The input data can also be viszualized using the pyvista package. In this view, the interface points are visible as well as the orientations (marked as arrows) which indicate the normals of each orientation value.
The pyvista package requires the Visualization Toolkit (VTK) to be installed.
gp.plot_3d(geo_model,
image=False,
plotter_type='basic',
notebook=True)
Setting the interpolator¶
Once we have made sure that we have defined all our primary information, we can continue with the next step towards creating our geological model: preparing the input data for interpolation.
Setting the interpolator is necessary before computing the actual model. Here, the most important kriging parameters can be defined.
gp.set_interpolator(geo_model,
compile_theano=True,
theano_optimizer='fast_compile',
verbose=[],
update_kriging=False
)
Computing the model¶
At this point, we have all we need to compute our full model via gp.compute_model(). By default, this will return two separate solutions in the form of arrays. The first provides information on the lithological formations, the second on the fault network in the model, which is not present in this example.
sol = gp.compute_model(geo_model,
compute_mesh=True)
sol
geo_model.solutions
gp.plot_2d(geo_model,
direction=['x', 'x', 'y', 'y'],
cell_number=[25, 50, 25, 75],
show_topography=False,
show_data=True)
Next to the lithology data, we can also plot the calculated scalar field.
gp.plot_2d(geo_model, show_data=False, show_scalar=True, show_lith=False)
Visualizing the computed model in 3D¶
The computed model can be visualized in 3D using the pyvista library. Setting notebook=False will open an interactive windows and the model can be rotated and zooming is possible.
gpv = gp.plot_3d(geo_model,
image=False,
show_topography=True,
plotter_type='basic',
notebook=True,
show_lith=True)
Conclusions¶
- How to import input data into GemPy via CSV-Files (comma-separated-values) and what the files have to look like
- How to build a simple model consisting of horizontal layers belonging to one Series
- How to visualize the resulting model with cross sections in 2D and the entire model in 3D
Outlook¶
- Get a better undestanding of what orientations mean in GemPy and how to plot them using mplstereonet
- How to build a simple model consisting of folded layers belonging to one Series
Take me to the next notebook on Github
Take me to the next notebook locally

Licensing¶
Institute for Computational Geoscience, Geothermics and Reservoir Geophysics, RWTH Aachen University & Fraunhofer IEG, Fraunhofer Research Institution for Energy Infrastructures and Geothermal Systems IEG, Authors: Alexander Juestel. For more information contact: alexander.juestel(at)ieg.fraunhofer.de
All notebooks are licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0, http://creativecommons.org/licenses/by/4.0/). References for each displayed map are provided. Most of the maps originate from the books of Powell (1992) and Bennison (1990). References for maps with unknown origin will gladly be added.