情感分析(sentiment analysis)和意见挖掘(opinion mining)虽然相关,但是从社会科学的角度而言,二者截然不同。这里主要是讲情感分析(sentiment or emotion),而非意见挖掘(opinion, 后者通过机器学习效果更可信)。

classify emotion¶
Different types of emotion: anger, disgust, fear, joy, sadness, and surprise. The classification can be performed using different algorithms: e.g., naive Bayes classifier trained on Carlo Strapparava and Alessandro Valitutti’s emotions lexicon.
classify polarity¶
To classify some text as positive or negative. In this case, the classification can be done by using a naive Bayes algorithm trained on Janyce Wiebe’s subjectivity lexicon.
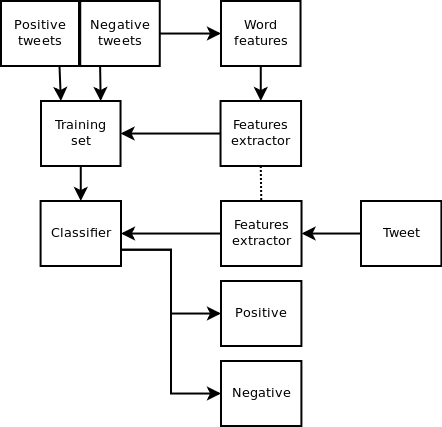
LIWC & TextMind¶
http://ccpl.psych.ac.cn/textmind/
“文心(TextMind)”中文心理分析系统是由中科院心理所计算网络心理实验室研发的,针对中文文本进行语言分析的软件系统,通过“文心”,您可以便捷地分析文本中使用的不同类别语言的程度、偏好等特点。针对中国大陆地区简体环境下的语言特点,参照LIWC2007和正體中文C-LIWC词库,我们开发了“文心(TextMind)”中文心理分析系统。“文心”为用户提供从简体中文自动分词,到语言心理分析的一揽子分析解决方案,其词库、文字和符号等处理方法专门针对简体中文语境,词库分类体系也与LIWC兼容一致。
Preparing the data¶
NLTK¶
Anaconda自带的(默认安装的)第三方包。http://www.nltk.org/
NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.
import nltk
pos_tweets = [('I love this car', 'positive'),
('This view is amazing', 'positive'),
('I feel great this morning', 'positive'),
('I am so excited about the concert', 'positive'),
('He is my best friend', 'positive')]
neg_tweets = [('I do not like this car', 'negative'),
('This view is horrible', 'negative'),
('I feel tired this morning', 'negative'),
('I am not looking forward to the concert', 'negative'),
('He is my enemy', 'negative')]
tweets = []
for (words, sentiment) in pos_tweets + neg_tweets:
words_filtered = [e.lower() for e in words.split() if len(e) >= 3]
tweets.append((words_filtered, sentiment))
tweets[:2]
test_tweets = [
(['feel', 'happy', 'this', 'morning'], 'positive'),
(['larry', 'friend'], 'positive'),
(['not', 'like', 'that', 'man'], 'negative'),
(['house', 'not', 'great'], 'negative'),
(['your', 'song', 'annoying'], 'negative')]
Extracting Features¶
Then we need to get the unique word list as the features for classification.
# get the word lists of tweets
def get_words_in_tweets(tweets):
all_words = []
for (words, sentiment) in tweets:
all_words.extend(words)
return all_words
# get the unique word from the word list
def get_word_features(wordlist):
wordlist = nltk.FreqDist(wordlist)
word_features = wordlist.keys()
return word_features
word_features = get_word_features(get_words_in_tweets(tweets))
' '.join(word_features)
To create a classifier, we need to decide what features are relevant. To do that, we first need a feature extractor.
def extract_features(document):
document_words = set(document)
features = {}
for word in word_features:
features['contains(%s)' % word] = (word in document_words)
return features
help(nltk.classify.util.apply_features)
training_set[0]
training_set = nltk.classify.util.apply_features(extract_features,\
tweets)
classifier = nltk.NaiveBayesClassifier.train(training_set)
# You may want to know how to define the ‘train’ method in NLTK here:
def train(labeled_featuresets, estimator=nltk.probability.ELEProbDist):
# Create the P(label) distribution
label_probdist = estimator(label_freqdist)
# Create the P(fval|label, fname) distribution
feature_probdist = {}
model = NaiveBayesClassifier(label_probdist, feature_probdist)
return model
tweet_positive = 'Harry is my friend'
classifier.classify(extract_features(tweet_positive.split()))
tweet_negative = 'Larry is not my friend'
classifier.classify(extract_features(tweet_negative.split()))
# Don’t be too positive, let’s try another example:
tweet_negative2 = 'Your song is annoying'
classifier.classify(extract_features(tweet_negative2.split()))
def classify_tweet(tweet):
return classifier.classify(extract_features(tweet))
# nltk.word_tokenize(tweet)
total = accuracy = float(len(test_tweets))
for tweet in test_tweets:
if classify_tweet(tweet[0]) != tweet[1]:
accuracy -= 1
print('Total accuracy: %f%% (%d/20).' % (accuracy / total * 100, accuracy))
使用sklearn的分类器¶
# nltk有哪些分类器呢?
nltk_classifiers = dir(nltk)
for i in nltk_classifiers:
if 'Classifier' in i:
print(i)
from sklearn.svm import LinearSVC
from nltk.classify.scikitlearn import SklearnClassifier
classif = SklearnClassifier(LinearSVC())
svm_classifier = classif.train(training_set)
# Don’t be too positive, let’s try another example:
tweet_negative2 = 'Your song is annoying'
svm_classifier.classify(extract_features(tweet_negative2.split()))
作业1:¶
使用另外一种sklearn的分类器来对tweet_negative2进行情感分析
作业2:¶
使用https://github.com/victorneo/Twitter-Sentimental-Analysis 所提供的推特数据进行情感分析,可以使用其代码 https://github.com/victorneo/Twitter-Sentimental-Analysis/blob/master/classification.py

推荐阅读:¶
movies reviews情感分析 http://nbviewer.jupyter.org/github/rasbt/python-machine-learning-book/blob/master/code/ch08/ch08.ipynb
Sentiment analysis with machine learning in R http://chengjun.github.io/en/2014/04/sentiment-analysis-with-machine-learning-in-R/
使用R包sentiment进行情感分析 https://site.douban.com/146782/widget/notes/15462869/note/344846192/
中文的手机评论的情感分析 https://github.com/computational-class/Review-Helpfulness-Prediction
基于词典的中文情感倾向分析 https://site.douban.com/146782/widget/notes/15462869/note/355625387/
Sentiment Analysis using TextBlob¶
安装textblob¶
https://github.com/sloria/TextBlob
pip install -U textblob
python -m textblob.download_corpora
from textblob import TextBlob
text = '''
The titular threat of The Blob has always struck me as the ultimate movie
monster: an insatiably hungry, amoeba-like mass able to penetrate
virtually any safeguard, capable of--as a doomed doctor chillingly
describes it--"assimilating flesh on contact.
Snide comparisons to gelatin be damned, it's a concept with the most
devastating of potential consequences, not unlike the grey goo scenario
proposed by technological theorists fearful of
artificial intelligence run rampant.
'''
blob = TextBlob(text)
blob.tags # [('The', 'DT'), ('titular', 'JJ'),
# ('threat', 'NN'), ('of', 'IN'), ...]
blob.noun_phrases # WordList(['titular threat', 'blob',
# 'ultimate movie monster',
# 'amoeba-like mass', ...])
for sentence in blob.sentences:
print(sentence.sentiment.polarity)
# 0.060
# -0.341
blob.translate(to="es") # 'La amenaza titular de The Blob...'
Sentiment Analysis Using GraphLab¶
In this notebook, I will explain how to develop sentiment analysis classifiers that are based on a bag-of-words model. Then, I will demonstrate how these classifiers can be utilized to solve Kaggle's "When Bag of Words Meets Bags of Popcorn" challenge.
Code Recipe: Creating Sentiment Classifier¶
Using GraphLab it is very easy and straight foward to create a sentiment classifier based on bag-of-words model. Given a dataset stored as a CSV file, you can construct your sentiment classifier using the following code:
import graphlab as gl
train_data = gl.SFrame.read_csv(traindata_path,header=True,
delimiter='\t',quote_char='"',
column_type_hints = {'id':str,
'sentiment' : int,
'review':str } )
train_data['1grams features'] = gl.text_analytics.count_ngrams(
train_data['review'],1)
train_data['2grams features'] = gl.text_analytics.count_ngrams(
train_data['review'],2)
cls = gl.classifier.create(train_data, target='sentiment',
features=['1grams features',
'2grams features'])
In the rest of this notebook, we will explain this code recipe in details, by demonstrating how this recipe can used to create IMDB movie reviews sentiment classifier.
Set up¶
Before we begin constructing the classifiers, we need to import some Python libraries: graphlab (gl), and IPython display utilities. We also set IPython notebook and GraphLab Canvas to produce plots directly in this notebook.
import graphlab as gl
from IPython.display import display
from IPython.display import Image
gl.canvas.set_target('ipynb')
Throughout this notebook, I will use Kaggle's IMDB movies reviews datasets that is available to download from the following link: https://www.kaggle.com/c/word2vec-nlp-tutorial/data. I downloaded labeledTrainData.tsv and testData.tsv files, and unzipped them to the following local files.
DeepLearningMovies¶
Kaggle's competition for using Google's word2vec package for sentiment analysis
traindata_path = "/Users/datalab/bigdata/kaggle_popcorn_data/labeledTrainData.tsv"
testdata_path = "/Users/datalab/bigdata/kaggle_popcorn_data/testData.tsv"
Loading Data¶
We will load the data with IMDB movie reviews to an SFrame using SFrame.read_csv function.
movies_reviews_data = gl.SFrame.read_csv(traindata_path,header=True,
delimiter='\t',quote_char='"',
column_type_hints = {'id':str,
'sentiment' : str,
'review':str } )
By using the SFrame show function, we can visualize the data and notice that the train dataset consists of 12,500 positive and 12,500 negative, and overall 24,932 unique reviews.
movies_reviews_data
Constructing Bag-of-Words Classifier¶
One of the common techniques to perform document classification (and reviews classification) is using Bag-of-Words model, in which the frequency of each word in the document is used as a feature for training a classifier. GraphLab's text analytics toolkit makes it easy to calculate the frequency of each word in each review. Namely, by using the count_ngrams function with n=1, we can calculate the frequency of each word in each review. By running the following command:
movies_reviews_data['1grams features'] = gl.text_analytics.count_ngrams(movies_reviews_data ['review'],1)
By running the last command, we created a new column in movies_reviews_data SFrame object. In this column each value is a dictionary object, where each dictionary's keys are the different words which appear in the corresponding review, and the dictionary's values are the frequency of each word. We can view the values of this new column using the following command.
movies_reviews_data#[['review','1grams features']]
We are now ready to construct and evaluate the movie reviews sentiment classifier using the calculated above features. But first, to be able to perform a quick evaluation of the constructed classifier, we need to create labeled train and test datasets. We will create train and test datasets by randomly splitting the train dataset into two parts. The first part will contain 80% of the labeled train dataset and will be used as the training dataset, while the second part will contain 20% of the labeled train dataset and will be used as the testing dataset. We will create these two dataset by using the following command:
train_set, test_set = movies_reviews_data.random_split(0.8, seed=5)
We are now ready to create a classifier using the following command:
model_1 = gl.classifier.create(train_set, target='sentiment', \
features=['1grams features'])
We can evaluate the performence of the classifier by evaluating it on the test dataset
result1 = model_1.evaluate(test_set)
In order to get an easy view of the classifier's prediction result, we define and use the following function
def print_statistics(result):
print "*" * 30
print "Accuracy : ", result["accuracy"]
print "Confusion Matrix: \n", result["confusion_matrix"]
print_statistics(result1)
As can be seen in the results above, in just a few relatively straight foward lines of code, we have developed a sentiment classifier that has accuracy of about ~0.88. Next, we demonstrate how we can improve the classifier accuracy even more.
Improving The Classifier¶
One way to improve the movie reviews sentiment classifier is to extract more meaningful features from the reviews. One method to add additional features, which might be meaningful, is to calculate the frequency of every two consecutive words in each review. To calculate the frequency of each two consecutive words in each review, as before, we will use GraphLab's count_ngrams function only this time we will set n to be equal 2 (n=2) to create new column named '2grams features'.
movies_reviews_data['2grams features'] = gl.text_analytics.count_ngrams(movies_reviews_data['review'],2)
movies_reviews_data
As before, we will construct and evaluate a movie reviews sentiment classifier. However, this time we will use both the '1grams features' and the '2grams features' features
train_set, test_set = movies_reviews_data.random_split(0.8, seed=5)
model_2 = gl.classifier.create(train_set, target='sentiment', features=['1grams features','2grams features'])
result2 = model_2.evaluate(test_set)
print_statistics(result2)
Indeed, the new constructed classifier seems to be more accurate with an accuracy of about ~0.9.
Unlabeled Test File¶
To test how well the presented method works, we will use all the 25,000 labeled IMDB movie reviews in the train dataset to construct a classifier. Afterwards, we will utilize the constructed classifier to predict sentiment for each review in the unlabeled dataset. Lastly, we will create a submission file according to Kaggle's guidelines and submit it.
traindata_path = "/Users/datalab/bigdata/kaggle_popcorn_data/labeledTrainData.tsv"
testdata_path = "/Users/datalab/bigdata/kaggle_popcorn_data/testData.tsv"
#creating classifier using all 25,000 reviews
train_data = gl.SFrame.read_csv(traindata_path,header=True, delimiter='\t',quote_char='"',
column_type_hints = {'id':str, 'sentiment' : int, 'review':str } )
train_data['1grams features'] = gl.text_analytics.count_ngrams(train_data['review'],1)
train_data['2grams features'] = gl.text_analytics.count_ngrams(train_data['review'],2)
cls = gl.classifier.create(train_data, target='sentiment', features=['1grams features','2grams features'])
#creating the test dataset
test_data = gl.SFrame.read_csv(testdata_path,header=True, delimiter='\t',quote_char='"',
column_type_hints = {'id':str, 'review':str } )
test_data['1grams features'] = gl.text_analytics.count_ngrams(test_data['review'],1)
test_data['2grams features'] = gl.text_analytics.count_ngrams(test_data['review'],2)
#predicting the sentiment of each review in the test dataset
test_data['sentiment'] = cls.classify(test_data)['class'].astype(int)
#saving the prediction to a CSV for submission
test_data[['id','sentiment']].save("/Users/datalab/bigdata/kaggle_popcorn_data/predictions.csv", format="csv")
We then submitted the predictions.csv file to the Kaggle challange website and scored AUC of about 0.88.
Further Readings¶
Further reading materials can be found in the following links:
http://en.wikipedia.org/wiki/Bag-of-words_model
https://dato.com/products/create/docs/generated/graphlab.SFrame.html
https://dato.com/products/create/docs/graphlab.toolkits.classifier.html
https://www.kaggle.com/c/word2vec-nlp-tutorial/details/part-1-for-beginners-bag-of-words
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. (2011). "Learning Word Vectors for Sentiment Analysis." The 49th Annual Meeting of the Association for Computational Linguistics (ACL 2011).