%%html
<script>
function code_toggle() {
if (code_shown){
$('div.input').hide('500');
$('#toggleButton').val('Show Code')
} else {
$('div.input').show('500');
$('#toggleButton').val('Hide Code')
}
code_shown = !code_shown
}
$( document ).ready(function(){
code_shown=false;
$('div.input').hide()
});
</script>
<form action="javascript:code_toggle()"><input type="submit" id="toggleButton" value="Show Code"></form>
<style>
.rendered_html td {
font-size: xx-large;
text-align: left; !important
}
.rendered_html th {
font-size: xx-large;
text-align: left; !important
}
</style>
%%capture
import sys
sys.path.append("..")
import statnlpbook.util as util
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 6.0)
%load_ext tikzmagic
Attention¶
Schedule¶
Background: neural MT (5 min.)
Math: attention (10 min.)
Math: self-attention (10 min.)
Background: BERT (15 min.)
Background: mBERT (5 min.)
Quiz: mBERT (5 min.)


You can't cram the meaning of a whole %&!$ing sentence into a single $&!*ing vector!
— Ray Mooney
Idea¶
- Traditional (non-neural) MT models often perform alignment between sequences

- Can we learn something similar with our encoder–decoder model?
Attention mechanism¶
- Original motivation: Bahdanau et al. 2014, Neural Machine Translation by Jointly Learning to Align and Translate
Idea¶
- Each encoder timestep gives us a contextual representation of the corresponding input token
- A weighted combination of those is a differentiable function
- Computing such a combination for each decoder timestep can give us a soft alignment

What is happening here?¶
Attention model takes as input:
- Hidden state of the decoder $\mathbf{s}_t^{\textrm{dec}}$
- All encoder hidden states $(\mathbf{h}_1^{\textrm{enc}}, \ldots, \mathbf{h}_n^{\textrm{enc}})$
Attention model produces:
- An attention vector $\mathbf{\alpha}_t \in \mathbb{R}^n$ (where $n$ is the length of the source sequence)
- $\mathbf{\alpha}_t$ is computed as a softmax distribution:
How do we compute $f_\mathrm{att}$?¶
Usually with a very simple feedforward neural network.
For example:
$$ f_{\mathrm{att}}(\mathbf{s}_{t-1}^{\textrm{dec}}, \mathbf{h}_j^{\textrm{enc}}) = \tanh \left( \mathbf{W}^s \mathbf{s}_{t-1}^{\textrm{dec}} + \mathbf{W}^h \mathbf{h}_j^{\textrm{enc}} \right) $$This is called additive attention.
Another alternative:
$$ f_{\mathrm{att}}(\mathbf{s}_{t-1}^{\textrm{dec}}, \mathbf{h}_j^{\textrm{enc}}) = \frac{\left(\mathbf{s}_{t-1}^{\textrm{dec}}\right)^\intercal \mathbf{W} \mathbf{h}_j^{\textrm{enc}}} {\sqrt{d_{\mathbf{h}^{\textrm{enc}}}}} $$This is called scaled dot-product attention.
(But many alternatives have been proposed!)
What do we do with $\mathbf{\alpha}_t$?¶
Computing a context vector:
$$ \mathbf{c}_t = \sum_{i=1}^n \mathbf{\alpha}_{t,i} \mathbf{h}_i^\mathrm{enc} $$This is the weighted combination of the input representations!
Include this context vector in the calculation of decoder's hidden state:
$$ \mathbf{s}_t^{\textrm{dec}} = f\left(\mathbf{s}_{t-1}^{\textrm{dec}}, \mathbf{y}_{t-1}^\textrm{dec}, \mathbf{c}_t\right) $$
Intuitively, this implements a mechanism of attention in the decoder. The decoder decides parts of the source sentence to pay attention to. By letting the decoder have an attention mechanism, we relieve the encoder from the burden of having to encode all information in the source sentence into a fixed-length vector.
We can visualize what this model learns in an
Attention matrix¶
$\rightarrow$ Simply concatenate all $\alpha_t$ for $1 \leq t \leq m$

An important caveat¶
- The attention mechanism was motivated by the idea of aligning inputs & outputs
- Attention matrices often correspond to human intuitions about alignment
- But *producing a sensible alignment is not a training objective!*
In other words:
- Do not expect that attention weights will necessarily correspond to sensible alignments!
Another way to think about attention¶
- $\color{purple}{\mathbf{s}_{t-1}^{\textrm{dec}}}$ is the query
- Retrieve the best $\mathbf{h}_j^{\textrm{enc}}$ by taking
$\color{orange}{\mathbf{W} \mathbf{h}_j^{\textrm{enc}}}$ as the key 3. Softly select a $\color{blue}{\mathbf{h}_j^{\textrm{enc}}}$ as value
$$ \mathbf{\alpha}_{t,j} = \text{softmax}\left( \frac{\left(\color{purple}{\mathbf{s}_{t-1}^{\textrm{dec}}}\right)^\intercal \color{orange}{\mathbf{W} \mathbf{h}_j^{\textrm{enc}}}} {\sqrt{d_{\mathbf{h}^{\textrm{enc}}}}} \right) \\ \mathbf{c}_t = \sum_{i=1}^n \mathbf{\alpha}_{t,i} \color{blue}{\mathbf{h}_i^\mathrm{enc}} \\ \mathbf{s}_t^{\textrm{dec}} = f\left(\mathbf{s}_{t-1}^{\textrm{dec}}, \mathbf{y}_{t-1}^\textrm{dec}, \mathbf{c}_t\right) $$Used during decoding to attend to $\mathbf{h}^{\textrm{enc}}$, encoded by Bi-LSTM.
More recent development:
Transformer models¶
- Described in Vaswani et al. (2017) paper famously titled Attention Is All You Need
- Gets rid of RNNs, uses attention calculations everywhere (also called self-attention)
- Used in most current state-of-the-art NMT models
Self-attention¶
Forget about Bi-LSTMs, because Attention is All You Need even for encoding!
Scaled Dot-Product Attention¶
Use $\mathbf{h}_i$ to create three vectors: $\color{purple}{\mathbf{q}_i}=W^q\mathbf{h}_i, \color{orange}{\mathbf{k}_i}=W^k\mathbf{h}_i, \color{blue}{\mathbf{v}_i}=W^v\mathbf{h}_i$.
$$ \mathbf{\alpha}_{i,j} = \text{softmax}\left( \frac{\color{purple}{\mathbf{q}_i}^\intercal \color{orange}{\mathbf{k}_j}} {\sqrt{d_{\mathbf{h}}}} \right) \\ \mathbf{h}_i^\prime = \sum_{j=1}^n \mathbf{\alpha}_{i,j} \color{blue}{\mathbf{v}_j} $$In matrix form:
$$ \text{softmax}\left( \frac{\color{purple}{Q} \color{orange}{K}^\intercal} {\sqrt{d_{\mathbf{h}}}} \right) \color{blue}{V} $$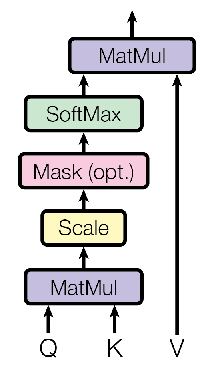
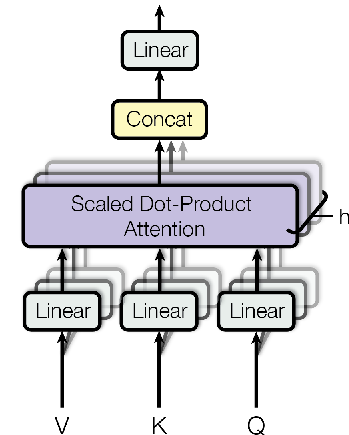

Unlike RNNs, no inherent locality bias!
Transformers for decoding¶
Attends to encoded input and to partial output.
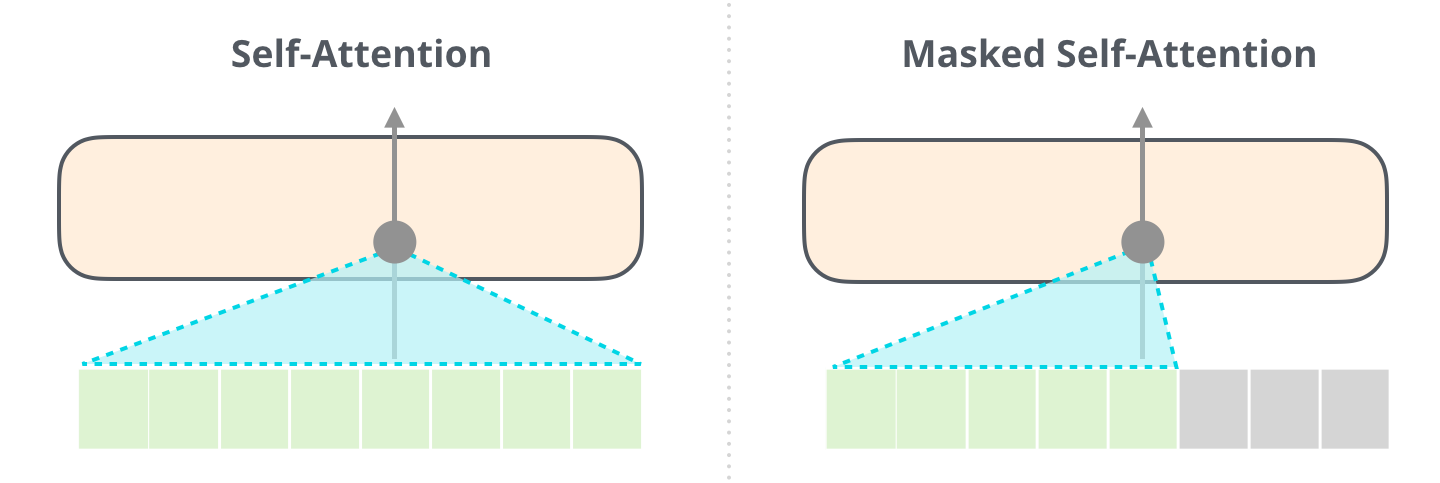
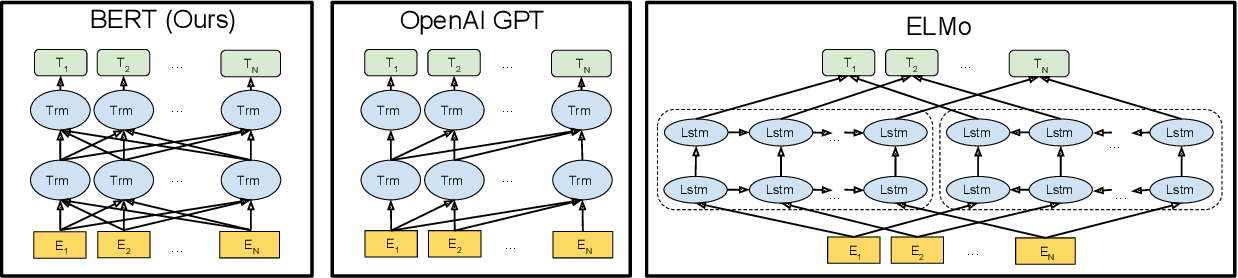
The encoder transformer is sometimes called "bidirectional transformer".

BERT architecture¶
Transformer with $L$ layers of dimension $H$, and $A$ self-attention heads.
- BERT$_\mathrm{BASE}$: $L=12, H=768, A=12$
- BERT$_\mathrm{LARGE}$: $L=24, H=1024, A=16$
Other pre-trained checkpoints: https://github.com/google-research/bert
Trained on 16GB of text from Wikipedia + BookCorpus.
- BERT$_\mathrm{BASE}$: 4 TPUs for 4 days
- BERT$_\mathrm{LARGE}$: 16 TPUs for 4 days
Training objective (1): masked language model¶
Predict masked words given context on both sides:
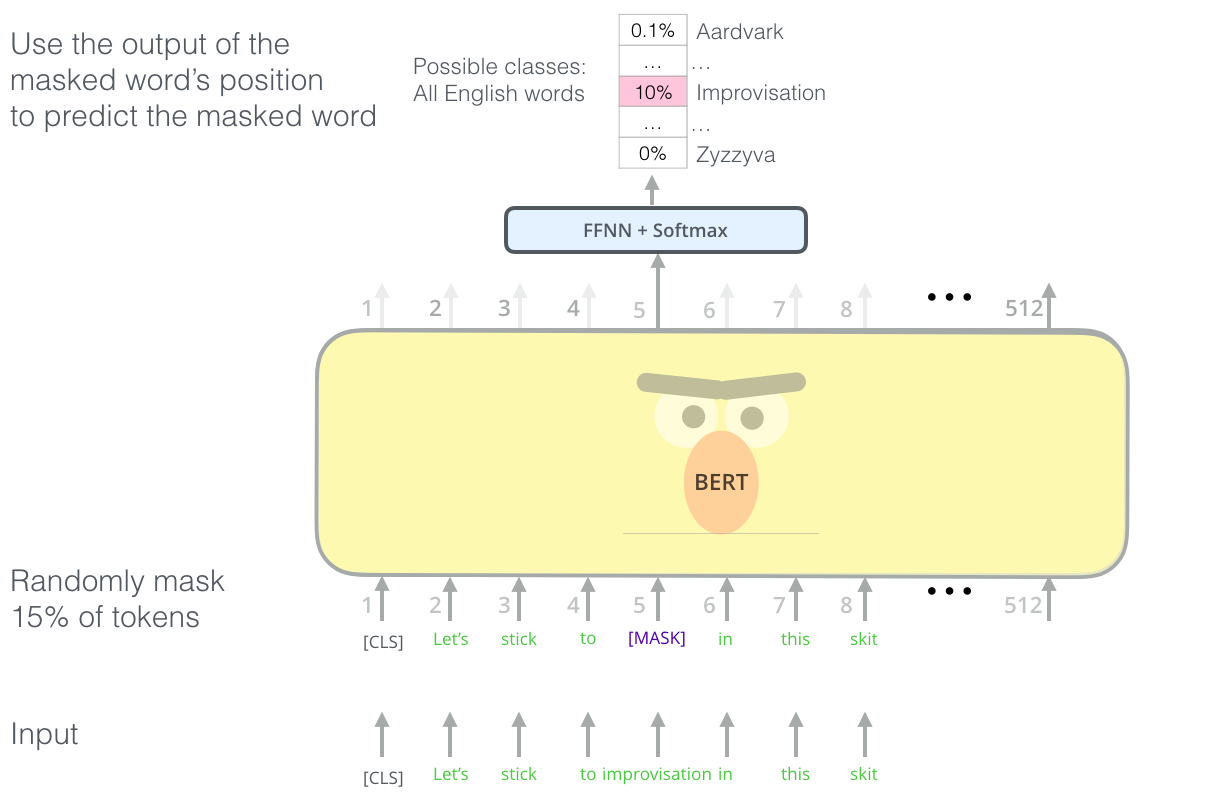
Training objective (2): next sentence prediction¶
Conditional encoding of both sentences:

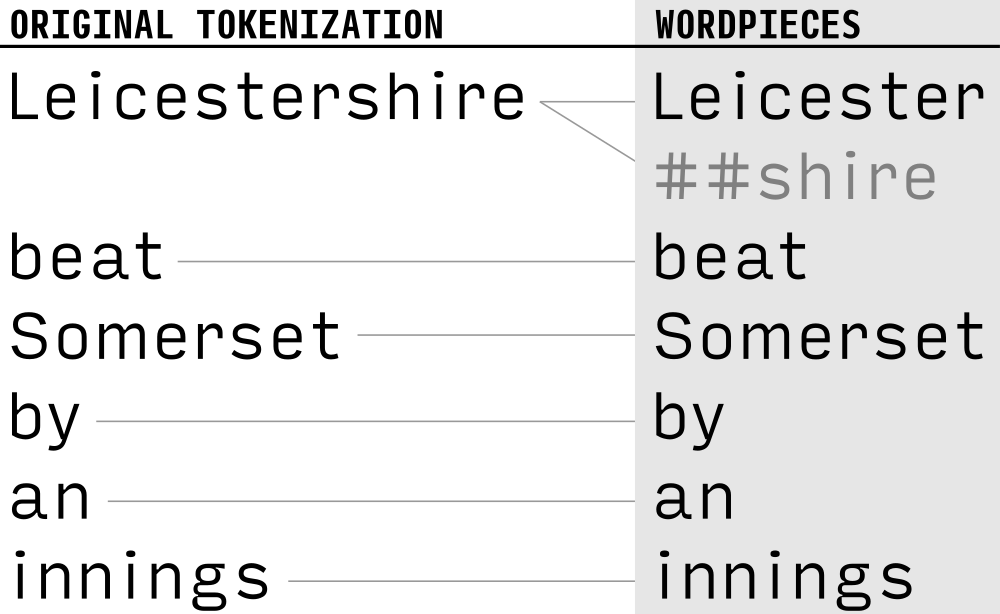
- 30,000 WordPiece vocabulary
- No unknown words!
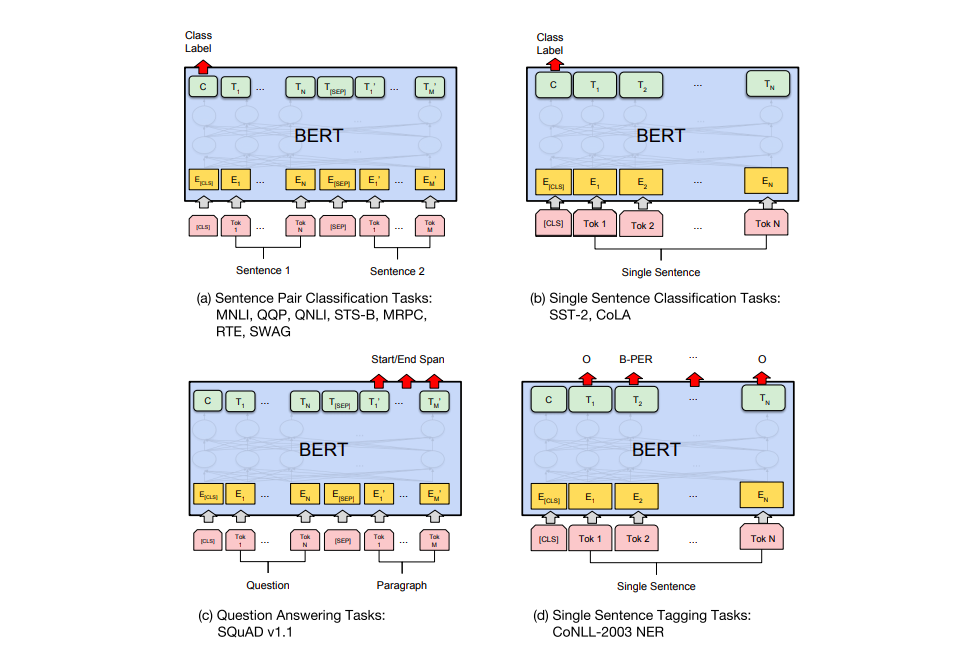


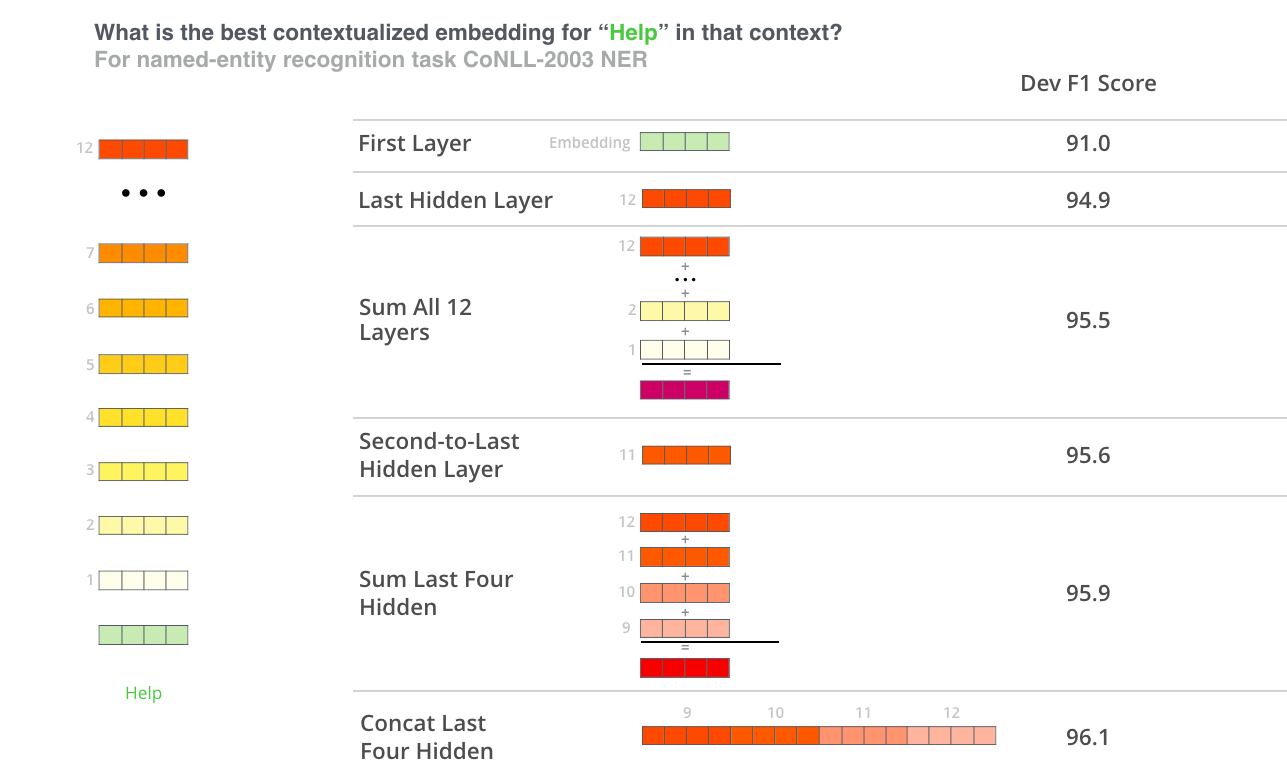
RoBERTa¶
Liu et al., 2019: bigger is better.
BERT with additionally
- CC-News (76GB)
- OpenWebText (38GB)
- Stories (31GB)
and no next-sentence-prediction task (only masked LM).
Training: 1024 GPUs for one day.
Multilingual BERT¶
- One model pre-trained on 104 languages with the largest Wikipedias
- 110k shared WordPiece vocabulary
- Same architecture as BERT$_\mathrm{BASE}$: $L=12, H=768, A=12$
- Same training objectives, no cross-lingual signal
https://github.com/google-research/bert/blob/master/multilingual.md

Other multilingual transformers¶
- XLM (Lample and Conneau, 2019) additionally uses an MT objective
- DistilmBERT (Sanh et al., 2020) is a lighter version of mBERT
- Many monolingual BERTs for languages other than English
(CamemBERT, BERTje, Nordic BERT...)
Zero-shot cross-lingual transfer¶
- Pre-train (or download) mBERT
- Fine-tune on a task in one language (e.g., English)
- Test on the same task in another language
mBERT is unreasonably effective at cross-lingual transfer!
NER F1:

POS accuracy:

Why? (poll)
See also K et al., 2020; Wu and Dredze., 2019.
Summary¶
The attention mechanism alleviates the encoding bottleneck in encoder-decoder architectures
Attention can even replace (bi)-LSTMs, giving self-attention
Transformers rely on self-attention for encoding and decoding
BERT, GPT-$n$ and other transformers are powerful pre-trained contextualized representations
Multilingual pre-trained transformers enable zero-shot cross-lingual transfer
Further reading¶
Attention:
- Lilian Weng's blog post Attention? Attention!
Transformers
- Jay Alammar's blog posts: