In [1]:
# Reveal.js
from notebook.services.config import ConfigManager
cm = ConfigManager()
cm.update('livereveal', {
'theme': 'white',
'transition': 'none',
'controls': 'false',
'progress': 'true',
})
Out[1]:
{'theme': 'white',
'transition': 'none',
'controls': 'false',
'progress': 'true'}
In [2]:
%%capture
%load_ext autoreload
%autoreload 2
# %cd ..
import sys
sys.path.append("..")
import statnlpbook.util as util
util.execute_notebook('language_models.ipynb')
In [3]:
%%html
<script>
function code_toggle() {
if (code_shown){
$('div.input').hide('500');
$('#toggleButton').val('Show Code')
} else {
$('div.input').show('500');
$('#toggleButton').val('Hide Code')
}
code_shown = !code_shown
}
$( document ).ready(function(){
code_shown=false;
$('div.input').hide()
});
</script>
<form action="javascript:code_toggle()"><input type="submit" id="toggleButton" value="Show Code"></form>
In [3]:
from IPython.display import Image
import random
Transformer Language Models¶
In [8]:
Image(url='mt_figures/transformer.png'+'?'+str(random.random()), width=500)
Out[8]:

BERT training objective (1): masked language model¶
Predict masked words given context on both sides:
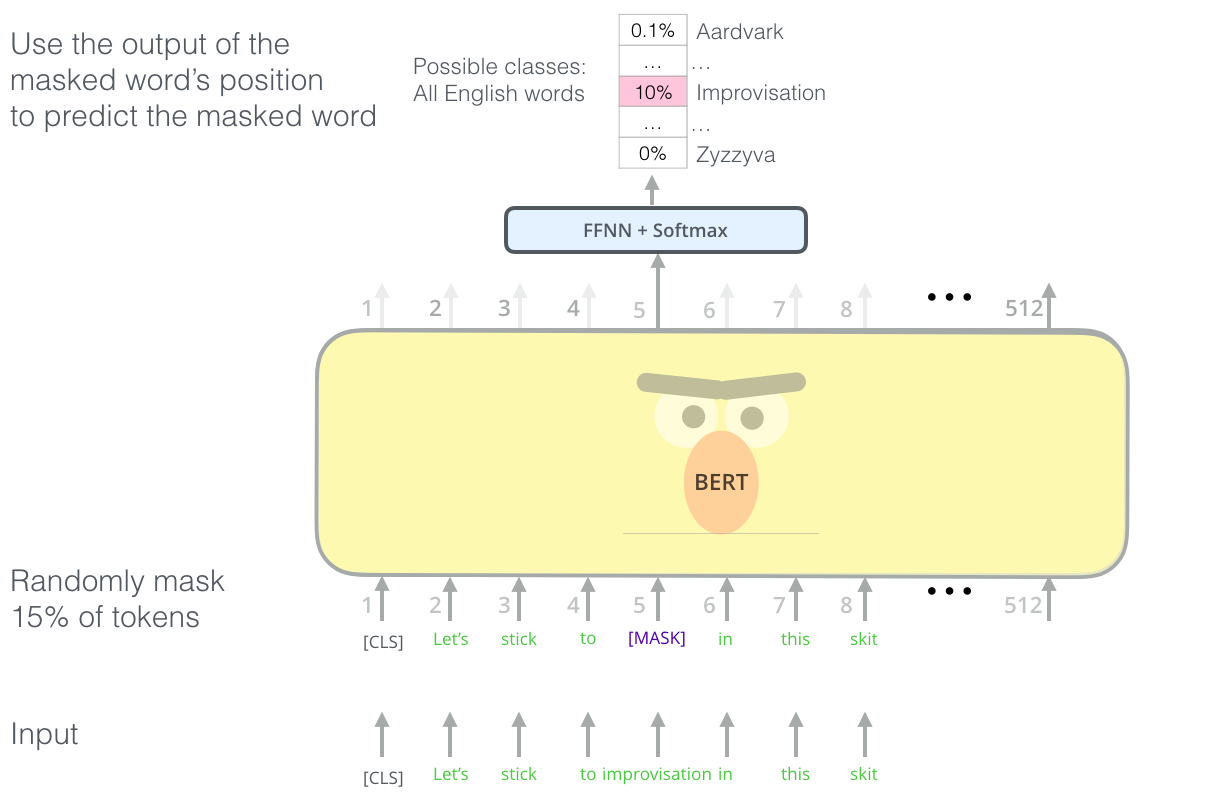
(from The Illustrated BERT)
BERT Training objective (2): next sentence prediction¶
Conditional encoding of both sentences:

(from The Illustrated BERT)
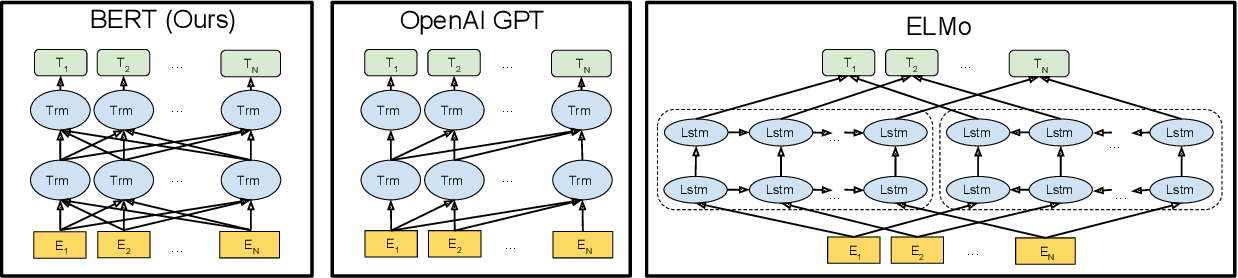
BERT architecture¶
Transformer with $L$ layers of dimension $H$, and $A$ self-attention heads.
- BERT$_\mathrm{BASE}$: $L=12, H=768, A=12$
- BERT$_\mathrm{LARGE}$: $L=24, H=1024, A=16$
(Many other variations available through HuggingFace Transformers)
Trained on 16GB of text from Wikipedia + BookCorpus.
- BERT$_\mathrm{BASE}$: 4 TPUs for 4 days
- BERT$_\mathrm{LARGE}$: 16 TPUs for 4 days
SNLI results¶
| Model | Accuracy |
|---|---|
| LSTM | 77.6 |
| LSTMs with conditional encoding | 80.9 |
| LSTMs with conditional encoding + attention | 82.3 |
| LSTMs with word-by-word attention | 83.5 |
| Self-attention | 85.6 |
| BERT$_\mathrm{BASE}$ | 89.2 |
| BERT$_\mathrm{LARGE}$ | 90.4 |
RoBERTa¶
Same architecture as BERT but better hyperparameter tuning and more training data (Liu et al., 2019):
- CC-News (76GB)
- OpenWebText (38GB)
- Stories (31GB)
and no next-sentence-prediction task (only masked LM).
Training: 1024 GPUs for one day.
SNLI results¶
| Model | Accuracy |
|---|---|
| LSTM | 77.6 |
| LSTMs with conditional encoding | 80.9 |
| LSTMs with conditional encoding + attention | 82.3 |
| LSTMs with word-by-word attention | 83.5 |
| Self-attention | 85.6 |
| BERT$_\mathrm{BASE}$ | 89.2 |
| BERT$_\mathrm{LARGE}$ | 90.4 |
| RoBERTa$_\mathrm{BASE}$ | 90.7 |
| RoBERTa$_\mathrm{LARGE}$ | 91.4 |
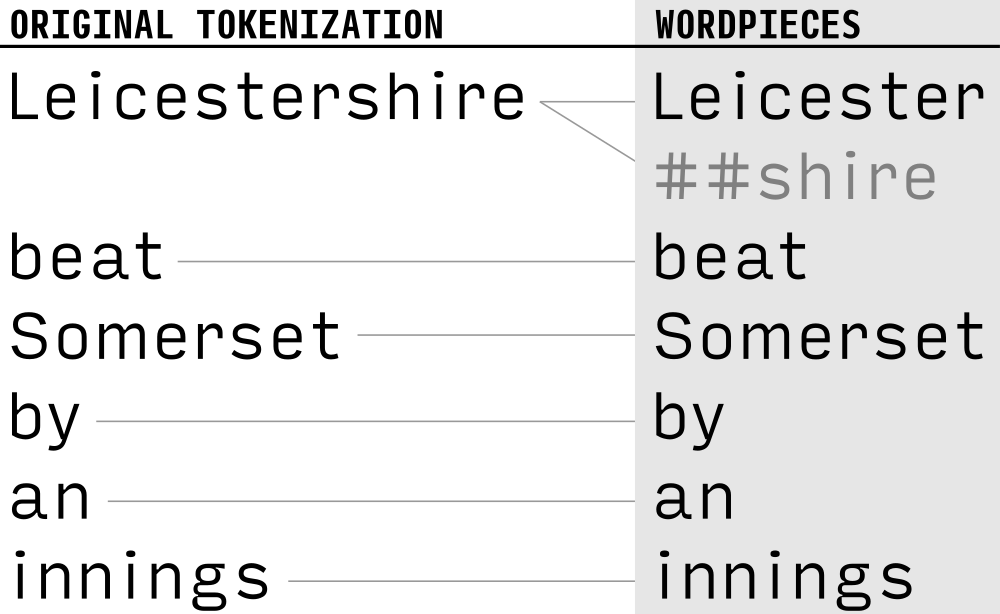
BERT tokenisation: not words, but WordPieces¶
WordPiece and BPE (byte-pair encoding) tokenise text to subwords (Sennrich et al., 2016, Wu et al., 2016)
- BERT has a 30,000 WordPiece vocabulary, including ~10,000 unique characters.
- No unknown words!
(from BERT for NER)


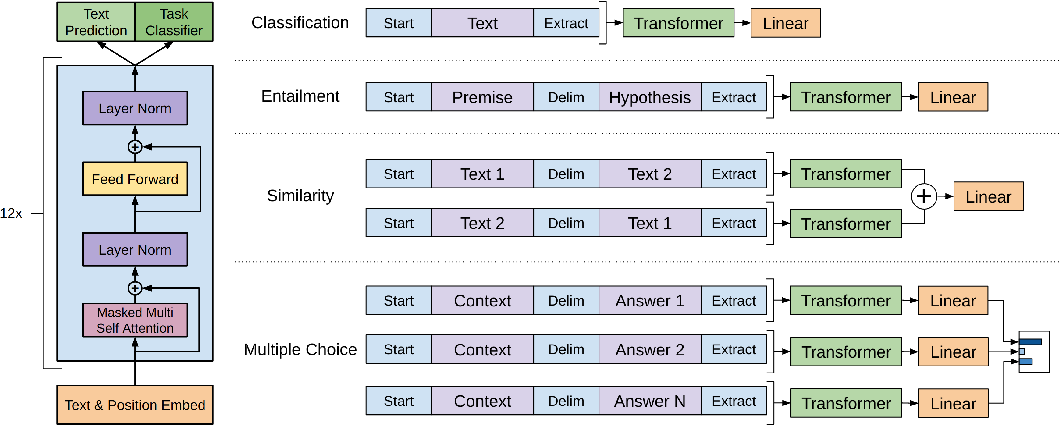


Using BERT (and friends) for NLI¶

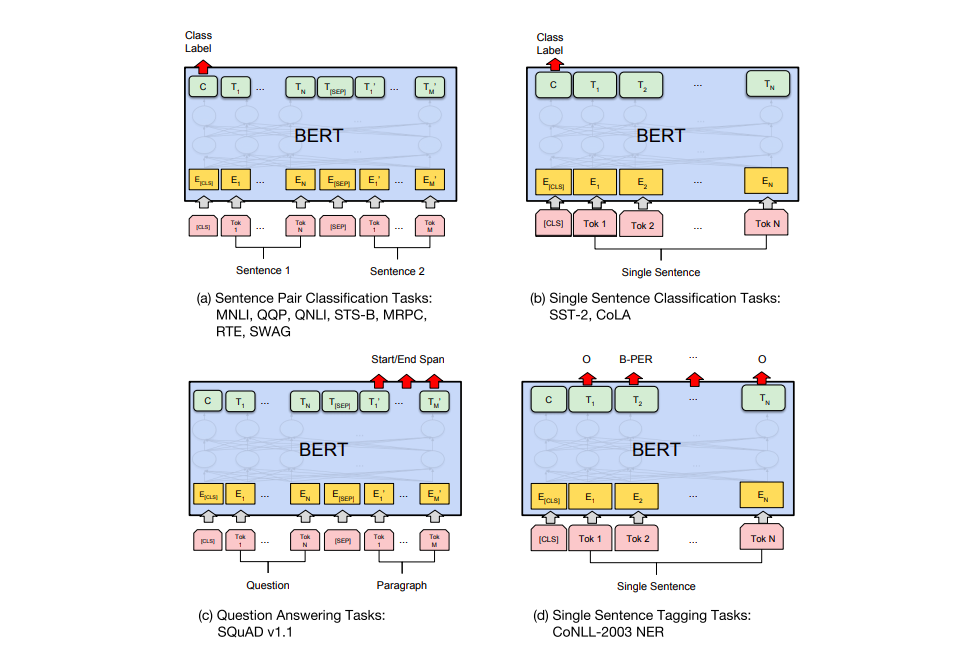
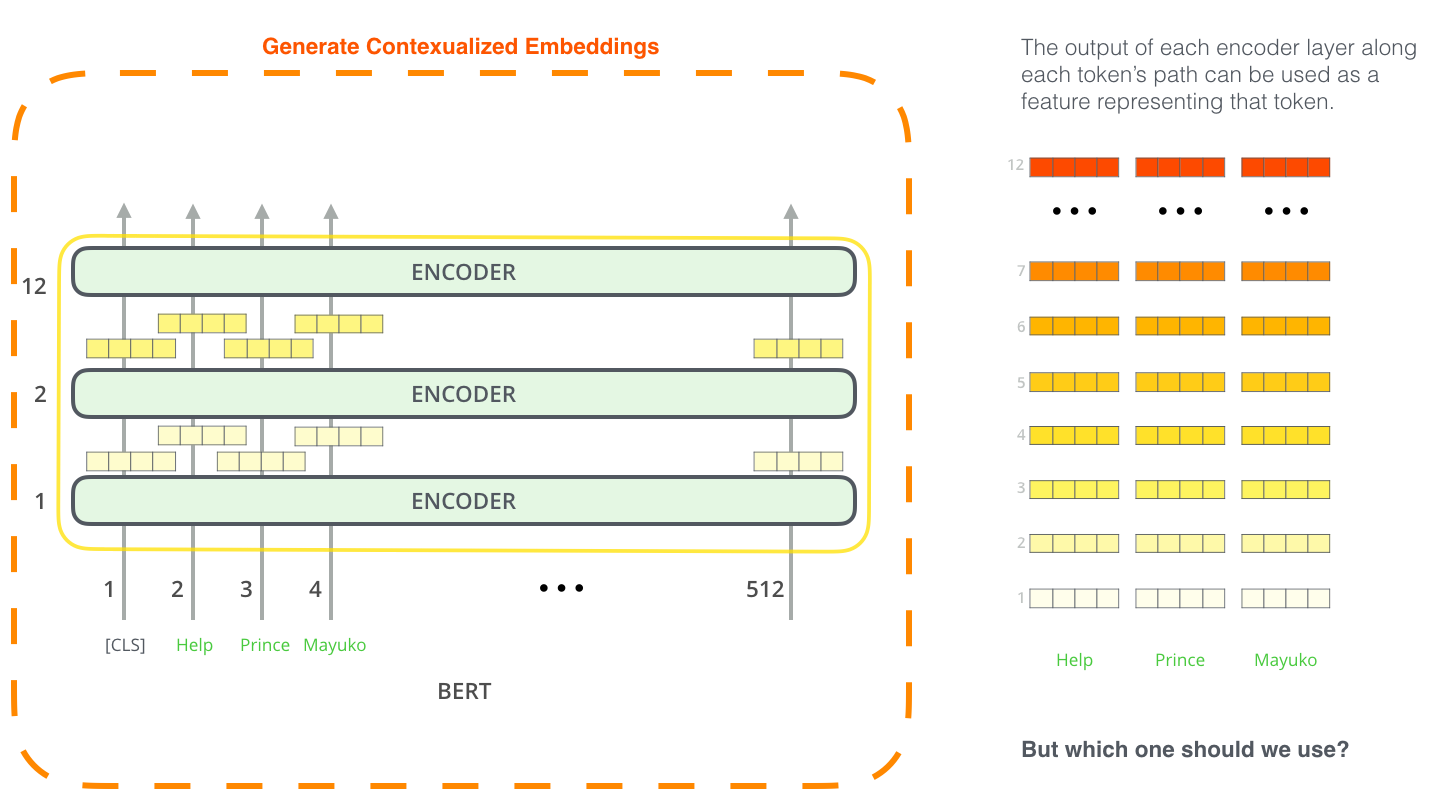
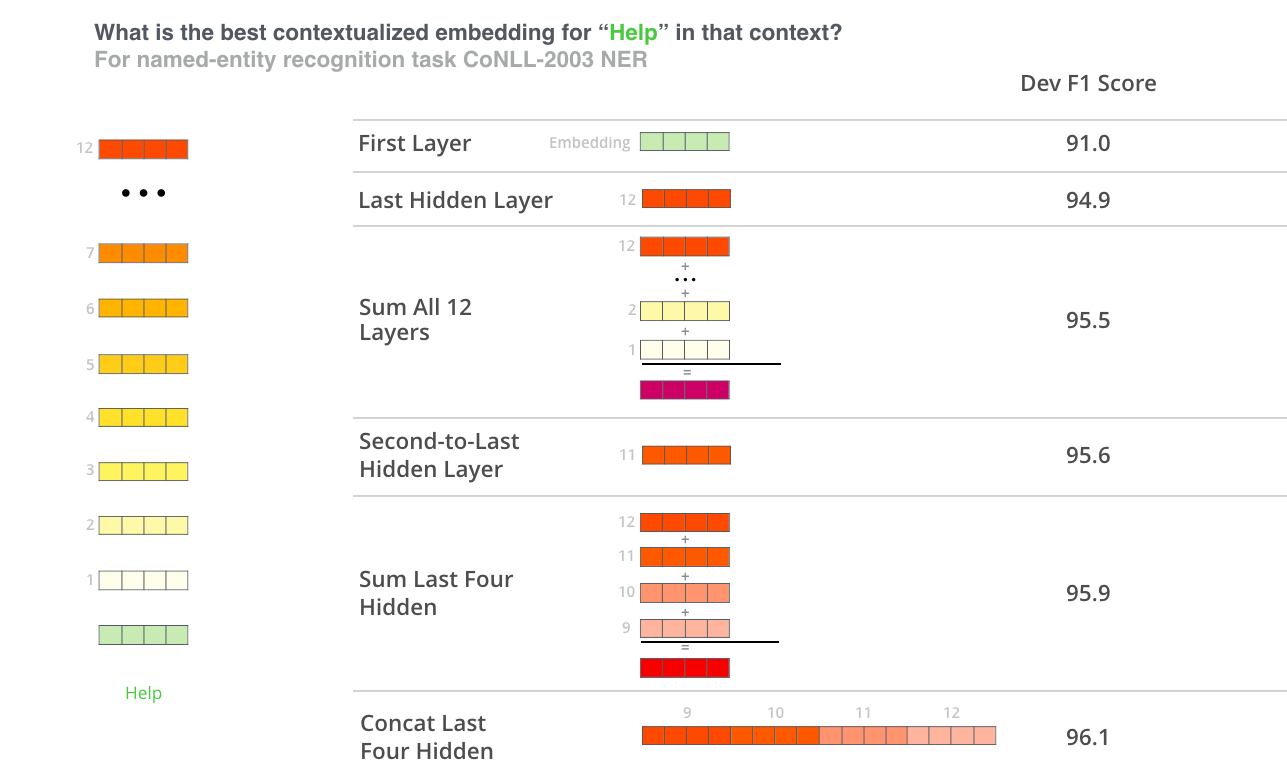
(from The Illustrated BERT)
Multilingual BERT¶
- One model pre-trained on 104 languages with the largest Wikipedias
- 110k shared WordPiece vocabulary
- Same architecture as BERT$_\mathrm{BASE}$: $L=12, H=768, A=12$
- Same training objectives, no cross-lingual signal
https://github.com/google-research/bert/blob/master/multilingual.md
Other multilingual transformers¶
- XLM and XLM-R (Lample and Conneau, 2019)
- DistilmBERT (Sanh et al., 2020) is a lighter version of mBERT
- Many monolingual BERTs for languages other than English
(CamemBERT, BERTje, Nordic BERT...)
Summary¶
- Static word embeddings do not differ depending on context
- Contextualised representations are dynamic
- Popular pre-trained contextual representations:
- ELMo: bidirectional language model with LSTMs
- GPT: transformer language models
- BERT: transformer masked language model
Outlook¶
- Transformer models keep coming out: larger, trained on more data, languages and domains, etc.
- Increasing energy usage and climate impact: see https://github.com/danielhers/climate-awareness-nlp
- In the machine translation lecture, you will learn how to use them for cross-lingual tasks
Additional Reading¶
- Jurafsky & Martin Chapter 11
- Jay Alammar's blog posts: