%%html
<script>
function code_toggle() {
if (code_shown){
$('div.input').hide('500');
$('#toggleButton').val('Show Code')
} else {
$('div.input').show('500');
$('#toggleButton').val('Hide Code')
}
code_shown = !code_shown
}
$( document ).ready(function(){
code_shown=false;
$('div.input').hide()
});
</script>
<form action="javascript:code_toggle()"><input type="submit" id="toggleButton" value="Show Code"></form>
<style>
.rendered_html td {
font-size: xx-large;
text-align: left; !important
}
.rendered_html th {
font-size: xx-large;
text-align: left; !important
}
</style>
%%capture
import sys
sys.path.append("..")
import statnlpbook.util as util
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 6.0)
%load_ext tikzmagic
The tikzmagic extension is already loaded. To reload it, use: %reload_ext tikzmagic
Machine Translation¶
- Challenges
- History
- Statistical MT
- Neural MT
- Evaluation

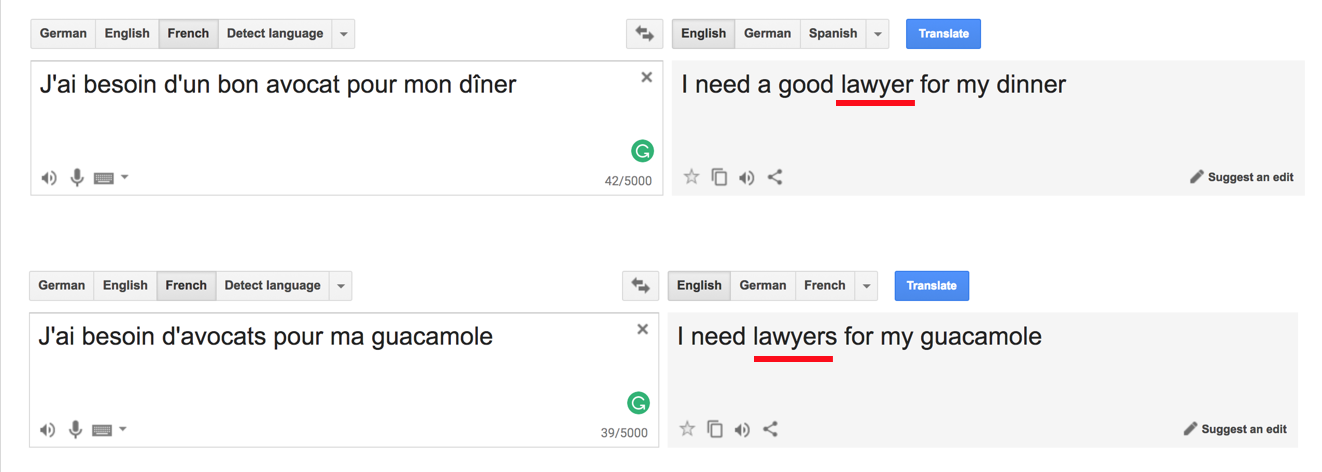
Many things could go wrong.

Challenges¶
Divergences between languages include:
- Word order
- Grammatical (morphological) marking (e.g., gender)
- Division of concept space (e.g., English "wall" vs. German "Mauer"/"Wand")
Addressing them requires resolving ambiguities:
- Word sense (e.g., "bass")
- Attributes with grammatical marking (e.g., formality in Japanese)
- Reference in pro-drop contexts (e.g., in Mandarin Chinese)
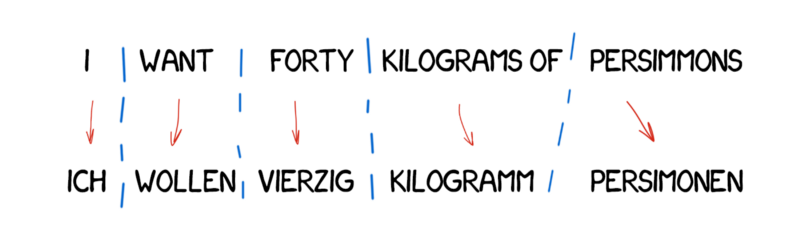
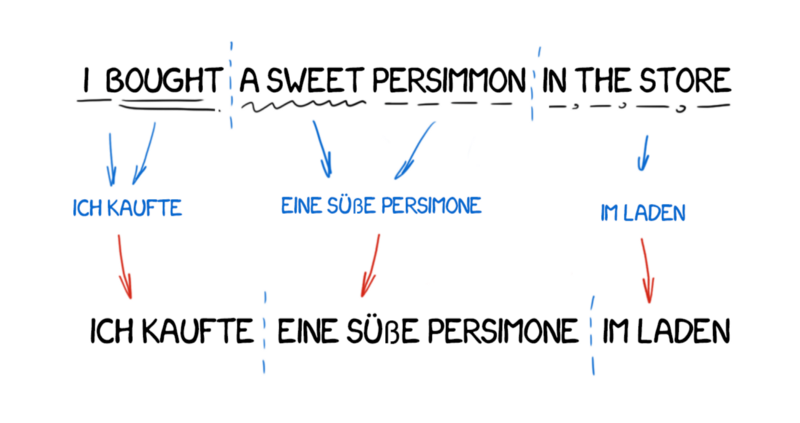
Transfer-based Machine Translation¶
Add rules to inflect/join/split words based on source and target syntax.
Interlingua¶
The ideal: transform to and from a language-independent representation.
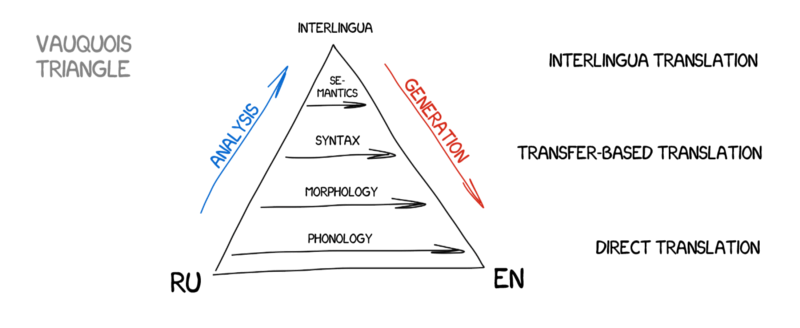
Too hard to achieve with rules!
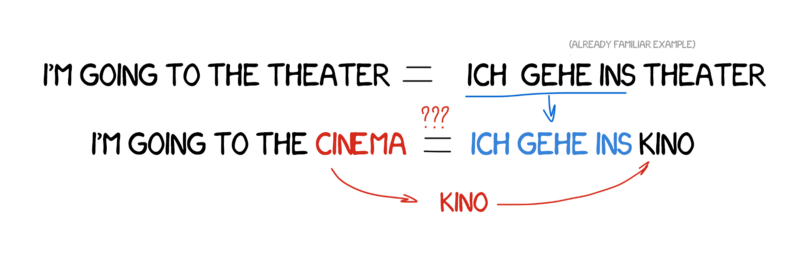
Example-based Machine Translation (EBMT)¶
Retrieve a similar example from a translation database, and make adjustments as necessary.
Statistical Machine Translation (SMT)¶
IBM Translation Models¶
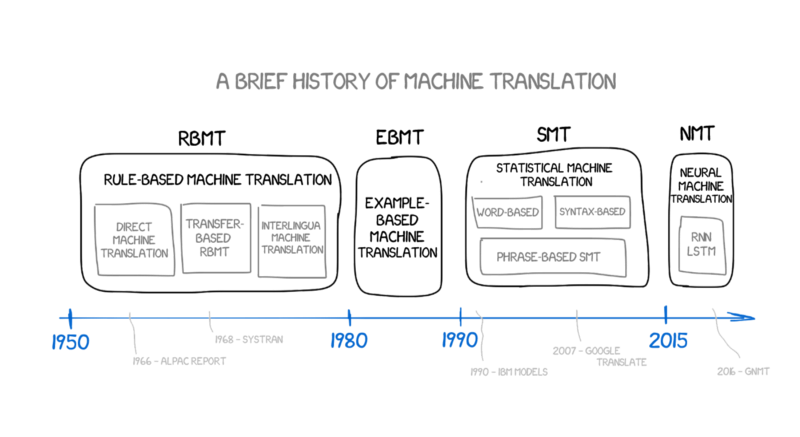
In the late 80s and early 90s, IBM researchers revolutionised MT using statistical approaches instead of rules.
 (Source: freeCodeCamp)
(Source: freeCodeCamp)
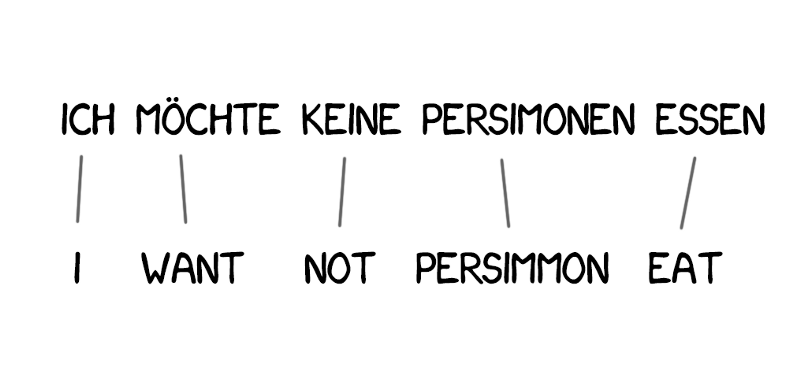
IBM Model 1¶
Simple word-by-word translation, but with statistical dictionaries.
(Source: freeCodeCamp)
(Source: freeCodeCamp)
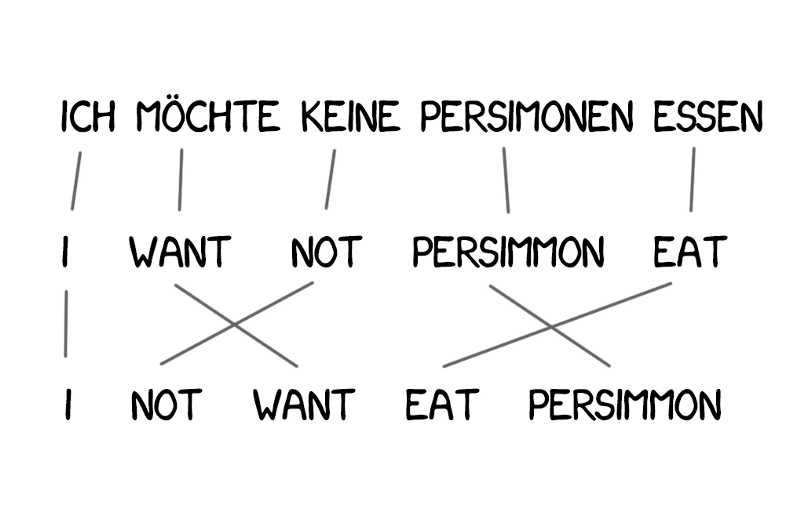
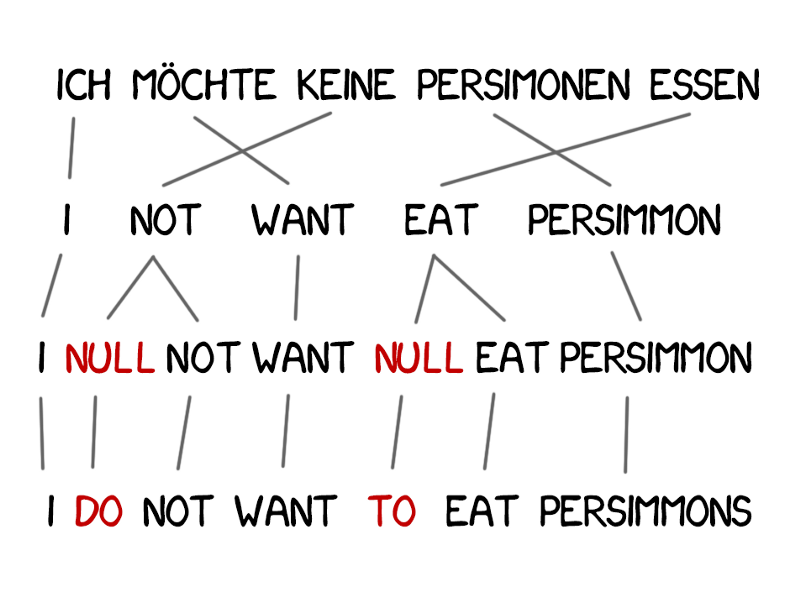
MT as Structured Prediction¶
Model $p(\target,\source)$: how likely the target $\target$ is to be a translation of source $\source$.
$$p(\textrm{I like music}, \textrm{音楽 が 好き}) \gg p(\textrm{I like persimmons}, \textrm{音楽 が 好き})$$- How is the scoring function defined (modeling)?
- How are the parameters $\params$ learned (training)?
- How is translation $\argmax$ found (decoding)?
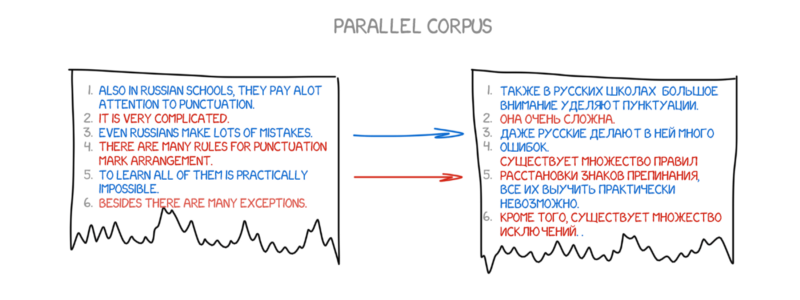
Generative Models¶
Estimate $\prob(\target,\source)$: how is the $(\target,\source)$ data generated?
Noisy Channel¶
- Imagine a message $\target$ is sent through a noisy channel and $\source$ is received at the end.
- Can we recover what was $\target$?
- Language model $\prob(\target)$: does the target $\target$ look like real language?
- Translation model: $\prob(\source|\target)$: does the source $\source$ match the target $\target$?
This defines a joint distribution
$$\prob(\target,\source) = \prob(\target) \prob(\source|\target)$$Word-based SMT¶
Decompose source and target to words, with statistical alignment.
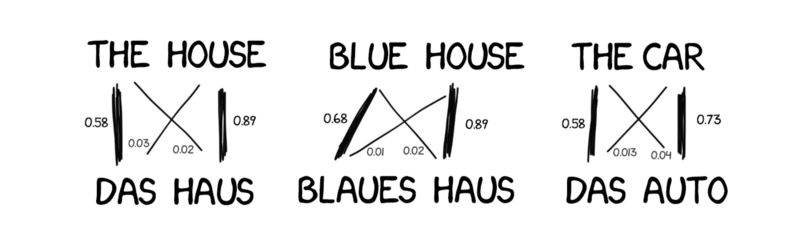
(Source: freeCodeCamp)
Phrase-based SMT¶
Decompose source and target to phrases and look them up in phrase tables.
(Source: freeCodeCamp)
Neural Machine Translation (NMT)¶
Model $s_\params(\target,\source)$ directly using a neural network.
(Source: freeCodeCamp)
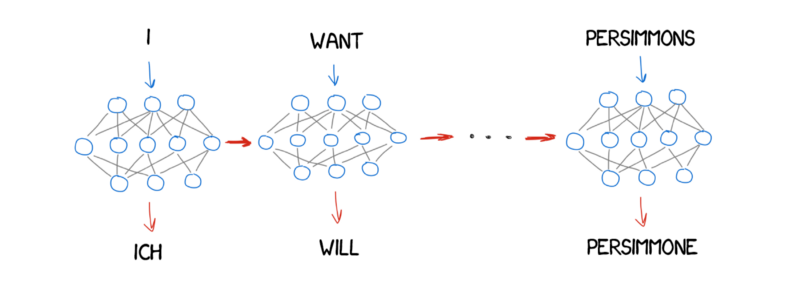
Sequence-to-sequence models (seq2seq)¶
Encoder–decoder architecture first "read" the input sequence and then generate an output sequence (Sutskever et al., 2014, Cho et al., 2014).

(Examples are Basque–English)
We can use RNNs for that!¶
Example architecture:
- Encoder: word embedding layer + Bi-LSTM to capture contextual information
- Decoder: Uni-directional LSTM (because we need to decode word by word) + softmax layer on top

The end-of-sequence symbol </S> is necessary to know when to start and stop generating.
Output words depend on each other!
Autoregressive MT¶
At each step, feed the predicted word to the decoder as input for predicting the next word.

Training¶
- Loss function: negative log-likelihood
- Teacher forcing: always feed the ground truth into the decoder.
Alternative:
- Scheduled sampling: with a certain probability, use model predictions instead.
Decoding¶
- Greedy decoding:
- Always pick the most likely word (according to the softmax)
- Continue generating more words until the
</S>symbol is predicted
- Beam search:
- In each step chooses best next source word to translate
- Append a target word based on source word
- Maintains a list of top-$k$ hypotheses in a beam

Word alignment¶
In rule-based and statistical MT, word alignments are crucial.

Can we use them in neural MT?


Transformers¶
Replace LSTMs by self-attention. Attend to encoded input and to partial output (autoregressive).
MT evaluation¶
We're training the model with negative log-likelihood, but that's not the best way to evaluate it.
Consider:
- After lunch, he went to the gym.
- After he had lunch, he went to the gym.
- He went to the gym after lunch.
- He went to the gym after lunchtime.
In machine translation, there are often several acceptable variations!
Human evaluation¶
- Faithfulness (or meaning preservation) to evaluate the "translation model"
- Fluency to evaluate the "target language model"
In general, manual evaluation is the best way, but it is not scalable. Automatic metrics are therefore often used.
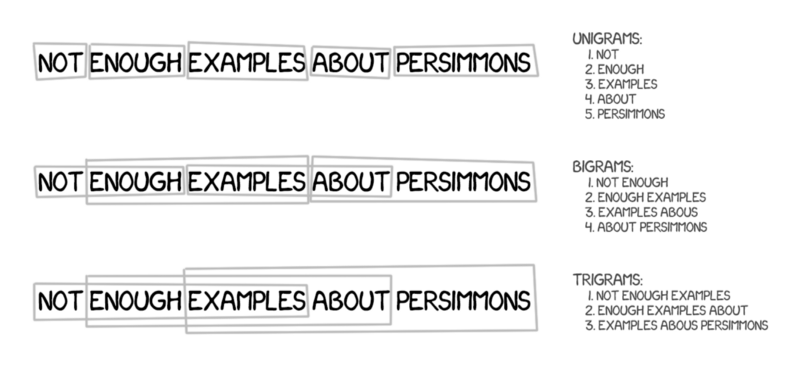
BLEU score¶
A widely used reference-based metric (Papineni et al., 2002):
- Compare the prediction to one or more reference translations.
- Count the number of matching $n$-grams between them.
- It is common to consider $1 \le n \le 4$
- Divide by total number of $n$-grams.
The BLEU score will range between 0 (no match at all) and 1.0 (perfect match, 100%)
Recommended library: sacreBLEU
BLEU score examples¶
!pip install sacrebleu
Collecting sacrebleu
Downloading sacrebleu-2.3.1-py3-none-any.whl (118 kB)
|████████████████████████████████| 118 kB 4.7 MB/s eta 0:00:01
Collecting tabulate>=0.8.9
Downloading tabulate-0.9.0-py3-none-any.whl (35 kB)
Requirement already satisfied: regex in /home/daniel/anaconda3/envs/stat-nlp-book/lib/python3.8/site-packages (from sacrebleu) (2020.7.14)
Requirement already satisfied: numpy>=1.17 in /home/daniel/anaconda3/envs/stat-nlp-book/lib/python3.8/site-packages (from sacrebleu) (1.19.1)
Requirement already satisfied: colorama in /home/daniel/anaconda3/envs/stat-nlp-book/lib/python3.8/site-packages (from sacrebleu) (0.4.5)
Collecting portalocker
Downloading portalocker-2.6.0-py2.py3-none-any.whl (15 kB)
Collecting lxml
Downloading lxml-4.9.1-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.manylinux_2_24_x86_64.whl (6.9 MB)
|████████████████████████████████| 6.9 MB 31.1 MB/s eta 0:00:01
Installing collected packages: tabulate, portalocker, lxml, sacrebleu
Successfully installed lxml-4.9.1 portalocker-2.6.0 sacrebleu-2.3.1 tabulate-0.9.0
from sacrebleu.metrics import BLEU
bleu = BLEU()
refs = [["After lunch, he went to the gym.",
"He went to the gym after lunch."]]
bleu.corpus_score(["After lunch, he went to the gym."], refs).score
100.00000000000004
bleu.corpus_score(["Turtles are great animals to the gym."], refs).score
30.509752160562883
bleu.corpus_score(["After he had lunch, he went to the gym."], refs).score
69.89307622784945
bleu.corpus_score(["Before lunch, he went to the gym."], refs).score
86.33400213704509
- BLEU is very simplistic
- Many alternatives have been proposed, including chrF (Popović, 2015) and BERTScore (Zhang et al., 2020)
- ...but BLEU still remains very popular
Improving efficiency and quality in MT¶
- More data
- Bigger models
- Better neural network architectures
- Semi-supervised learning
- Transfer learning
Further reading¶
Non-neural machine translation:
- Ilya Pestov's article A history of machine translation from the Cold War to deep learning
- Slides on SMT from this repo
- Mike Collins's Lecture notes on IBM Model 1 and 2
Sequence-to-sequence models:
And beyond...
- Philipp Koehn, Neural Machine Translation, §13.6–13.8 gives a great overview of further refinements and challenges