Clean Bibliography¶
To goal of this notebook is to clean your .bib file to ensure that it only contains the full first names of references that you have cited in your paper. The full first names will then be used to query the probabilistic gender classifier, Gender API. The full names will be used to query for probabilistic race using the ethnicolr package.
The only required file you need is your manuscript's bibliography in .bib format. Your .bib must only contain references cited in the manuscript. Otherwise, the estimated proportions will be inaccurate.
If you intend to analyze the reference list of a published paper instead of your own manuscript in progress, search the paper on Web of Knowledge (you will need institutional access). Next, download the .bib file from Web of Science following these instructions, but start from Step 4 and on Step 6 select BibTeX instead of Plain Text.
If you are not using LaTeX, collect and organize only the references you have cited in your manuscript using your reference manager of choice (e.g. Mendeley, Zotero, EndNote, ReadCube, etc.) and export that selected bibliography as a .bib file. Please try to export your .bib in an output style that uses full first names (rather than only first initials) and using the full author lists (rather than abbreviated author lists with "et al."). If first initials are included, our code will automatically retrieve about 70% of those names using the article title or DOI.
- Export
.bibfrom Mendeley - Export
.bibfrom Zotero - Export
.bibfrom EndNote. Note: Please export full first names by either choosing an output style that does so by default (e.g. in MLA style) or by customizing an output style. - Export
.bibfrom Read Cube Papers
For those working in LaTeX, we can use an optional .aux file to automatically filter your .bib to check that it only contains entries which are cited in your manuscript.
| Input | Output |
|---|---|
.bib file(s)(REQUIRED) |
cleanBib.csv: table of author first names, titles, and .bib keys |
.aux file (OPTIONAL) |
predictions.csv: table of author first names, estimated gender classification, and confidence |
.tex file (OPTIONAL) |
race_gender_citations.pdf: heat map of your citations broken down by probabilistic gender and race estimations |
yourTexFile_gendercolor.tex: your .tex file modified to compile .pdf with in-line citations colored-coded by gender pairs |
1. Import functions¶
Upload your .bib file(s) and optionally an .aux file generated from compiling your LaTeX manuscript and your .tex file
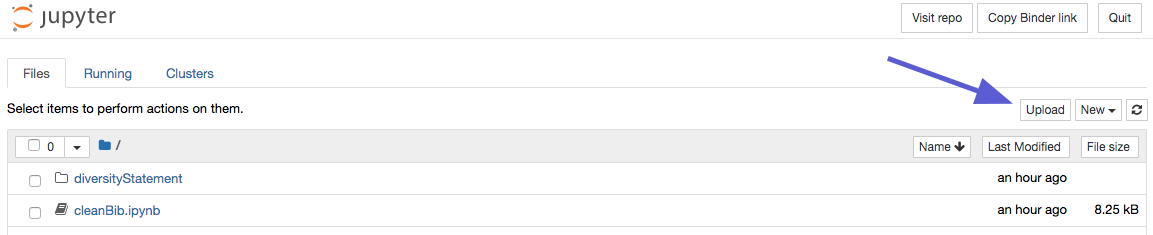

Then, run the code block below. (click to select the block and then press Ctrl+Enter; or click the block and press the Run button in the top menubar)
import glob
from habanero import Crossref
import sys
import os
from pathlib import Path
wd = Path(os.getcwd())
sys.path.insert(1, f'{wd.absolute()}/utils')
from preprocessing import *
from ethnicolr import pred_fl_reg_name
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"
import tensorflow as tf
import seaborn as sns
import matplotlib.pyplot as plt
np.warnings.filterwarnings('ignore', category=np.VisibleDeprecationWarning)
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
cr = Crossref()
homedir = '/home/jovyan/'
bib_files = glob.glob(homedir + '*.bib')
paper_aux_file = glob.glob(homedir + '*.aux')
paper_bib_file = 'library_paper.bib'
try:
tex_file = glob.glob(homedir + "*.tex")[0]
except:
print('No optional .tex file found.')
2. Define the first and last author of your paper.¶
For example:
yourFirstAuthor = 'Teich, Erin G.'
yourLastAuthor = 'Bassett, Danielle S.'
And optionally, define any co-first or co-last author(s), making sure to keep the square brackets to define a list.
For example:
optionalEqualContributors = ['Dworkin, Jordan', 'Stiso, Jennifer']
or
optionalEqualContributors = ['Dworkin, Jordan']
If you are analyzing published papers' reference lists from Web of Science, change the variable checkingPublishedArticle to True:
checkingPublishedArticle = True
Then, run the code block below. (click to select the block and then press Ctrl+Enter; or click the block and press the Run button in the top menubar)
NOTE: Please edit your .bib file using information printed by the code and provided in cleanedBib.csv. Edit directly within the Binder environment by clicking the .bib file (as shown below), making modifications, and saving the file (as shown below).
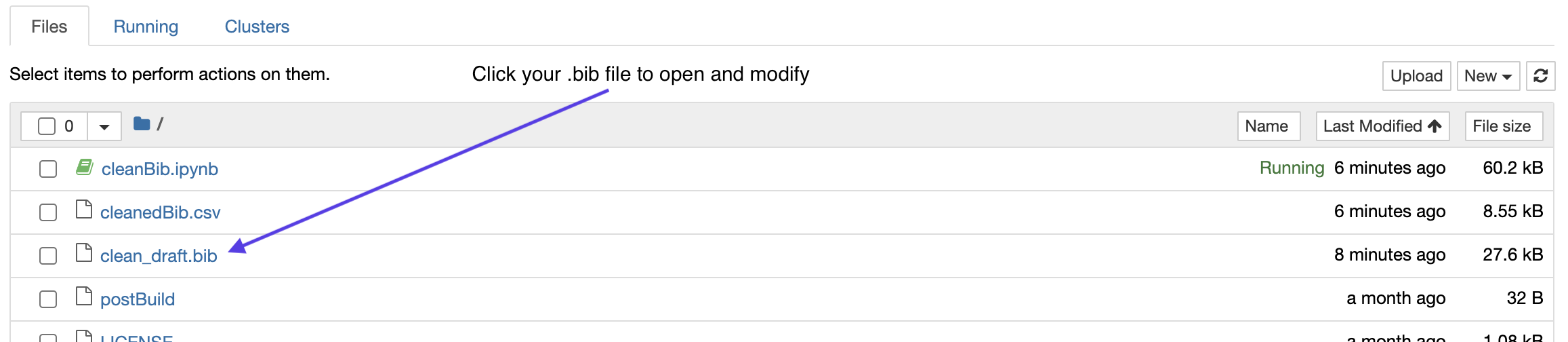

Common issues include:
- Bibliography entry did not include a last author because the author list was truncated by "and Others" or "et al."
- Some older journals articles only provide first initial and not full first names, in which case you will need to go digging via Google to identify that person.
- In rare cases where the author cannot be identified even after searching by hand, replace the first name with "UNKNOWNNAMES" so that the classifier will estimate the gender as unknown.
yourFirstAuthor = 'LastName, FirstName OptionalMiddleInitial'
yourLastAuthor = 'LastName, FirstName OptionalMiddleInitial'
optionalEqualContributors = ['LastName, FirstName OptionalMiddleInitial', 'LastName, FirstName OptionalMiddleInitial']
checkingPublishedArticle = False
if paper_aux_file:
find_unused_cites(paper_aux_file)
bib_data = get_bib_data(bib_files[0])
if checkingPublishedArticle:
get_names_published(homedir, bib_data, cr)
else:
# find and print duplicates
bib_data = get_duplicates(bib_data, bib_files[0])
# get names, remove CDS, find self cites
get_names(homedir, bib_data, yourFirstAuthor, yourLastAuthor, optionalEqualContributors, cr)
bib_check(homedir)
3. Estimate gender and race of authors from cleaned bibliography¶
Checkpoint for cleaned bibliography and using Gender API to estimate genders and race by names¶
After registering for a gender-api account (free), use your 500 free monthly search credits by pasting your API key in the code for the line indicated below (replace only YOUR ACCOUNT KEY HERE):
genderAPI_key = '&key=YOUR ACCOUNT KEY HERE'
You can find your key in your account's profile page.
Then, run the code blocks below to estimate how many credits we will need to use. (click to select the block and then press Ctrl+Enter; or click the block and press the Run button in the top menubar)
genderAPI_key = '&key='
# Check your credit balance
check_genderAPI_balance(genderAPI_key, homedir)
4. Describe the proportions of genders in your reference list and compare it to published base rates in neuroscience.¶
NOTE: your free GenderAPI account has 500 queries per month. This box contains the code that will use your limited API credits/queries if it runs without error. Re-running all code repeatedly will repeatedly use these credits.
Run the code blocks below. (click to select the block and then press Ctrl+Enter; or click the block and press the Run button in the top menubar)
mm, wm, mw, ww, WW, aw, wa, aa, citation_matrix, paper_df = get_pred_demos((yourFirstAuthor+' '+yourLastAuthor).replace(',',''), homedir, bib_data, genderAPI_key)
statement, statementLatex = print_statements(mm, wm, mw, ww, WW, aw, wa, aa)
5. Print the Diversity Statement and visualize your results¶
The example template can be copied and pasted into your manuscript. We have included it in our methods or references section. If you are using LaTeX, the bibliography file can be found here.
Additional info about the neuroscience benchmark¶
For the top 5 neuroscience journals (Nature Neuroscience, Neuron, Brain, Journal of Neuroscience, and Neuroimage), the expected gender proportions in reference lists as reported by Dworkin et al. are 58.4% for man/man, 9.4% for man/woman, 25.5% for woman/man, and 6.7% for woman/woman. Expected proportions were calculated by randomly sampling papers from 28,505 articles in the 5 journals, estimating gender breakdowns using probabilistic name classification tools, and regressing for relevant article variables like publication date, journal, number of authors, review article or not, and first-/last-author seniority. See Dworkin et al. for more details.
Using a similar random draw model regressing for relevant variables, the expected race proportions in reference lists as reported by Bertolero et al. were 51.8% for white/white, 12.8% for white/author-of-color, 23.5% for author-of-color/white, and 11.9% for author-of-color/author-of-color.
This box does NOT contain code that will use your limited API credits/queries.
Run the code block below. (click to select the block and then press Ctrl+Enter; or click the block and press the Run button in the top menubar)
print('Plain text template:')
print(statement)
print('\n')
print('LaTeX template:')
print(statementLatex)
paper_df.to_csv('/home/jovyan/predictions.csv')
plot_heatmaps(citation_matrix, homedir)
plot_histograms()
(OPTIONAL) Color-code your .tex file using the estimated gender classifications¶
Running this code-block will optionally output your uploaded .tex file with color-coding for gender pair classifications. You can find the example below's pre-print here.

colorful_latex(paper_df, homedir, tex_file, bib_data)