Machine Learning and Statistics for Physicists¶
Material for a UC Irvine course offered by the Department of Physics and Astronomy.
Content is maintained on github and distributed under a BSD3 license.
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
import numpy as np
import pandas as pd
import matplotlib.collections
import scipy.signal
from sklearn import model_selection
import tensorflow as tf
from mls import locate_data
Neural Network Architectures for Deep Learning¶
We previously took a bottom-up look at how a neural network is composed of basic building blocks. Now, we take a top-down look at some of the novel network architectures that are enabling the current deep-learning revolution:
- Convolutional networks
- Unsupervised learning networks
- Recurrent networks
- Reinforcement learning
We conclude with some reflections on where "deep learning" is headed.
The examples below use higher-level tensorflow APIs than we have seen before, so we start with a brief introduction to them.
High-Level Tensorflow APIs¶
In our earlier examples, we built our networks using low-level tensorflow primitives. For more complex networks composed of standard building blocks, there are convenient higher-level application programming interfaces (APIs) that abstract aways the low-level graphs and sessions.
Reading Data¶
The tf.data API handles data used to train and test a network, replacing the low-level placeholders we used earlier. For a small dataset that fits in memory, use:
dataset = tf.data.Dataset.from_tensor_slices((dict(X), y))
Creating a Dataset adds nodes to a graph so you should normally wrap your code to create a Dataset in a function that tensorflow will call in the appropriate context. For example, to split the 300 circles samples above into train (200) and test (100) datasets:
X = pd.read_hdf(locate_data('circles_data.hf5'))
y = pd.read_hdf(locate_data('circles_targets.hf5'))
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=100, random_state=123)
def get_train_data(batch_size=50):
dataset = tf.data.Dataset.from_tensor_slices((dict(X_train), y_train))
return dataset.shuffle(len(X_train)).repeat().batch(batch_size)
def get_test_data(batch_size=50):
dataset = tf.data.Dataset.from_tensor_slices((dict(X_test), y_test))
return dataset.batch(batch_size)
While from_tensor_slices is convenient, it is not very efficient since the whole dataset is added to the graph with constant nodes (and potentially copied multiple times). Alternatively, convert your data to tensorflow's binary file format so it can be read as a TFRecordDataset.
Building a Model¶
The tf.estimator API builds and runs a graph for training, evaluation and prediction. This API generates a lot of INFO log messages, which can be suppressed using:
tf.logging.set_verbosity(tf.logging.WARN)
First specify the names and types (but not values) of the features that feed the network's input layer:
inputs = [tf.feature_column.numeric_column(key=key) for key in X]
Next, build the network graph. There are pre-made estimators for standard architectures that are easy to use. For example, to recreate our earlier architecture of a single 4-node hidden layer with sigmoid activation:
config = tf.estimator.RunConfig(
model_dir='tfs/circle',
tf_random_seed=123
)
classifier = tf.estimator.DNNClassifier(
config=config,
feature_columns=inputs,
hidden_units=[4],
activation_fn=tf.sigmoid,
n_classes=2
)
There are only a limited number of pre-defined models available so you often have to build a custom estimator using the intermediate-level layers API. See convolutional-network example below.
Training a Model¶
An estimator remembers any previous training (using files saved to its model_dir) so if you really want to start from scratch you will need to clear this history:
!rm -rf tfs/circle/*
The train method runs a specified number of steps (each learning from one batch of training data):
classifier.train(input_fn=get_train_data, steps=5000);
After training, you can list the model parameters and access their values:
classifier.get_variable_names()
['dnn/hiddenlayer_0/bias', 'dnn/hiddenlayer_0/bias/t_0/Adagrad', 'dnn/hiddenlayer_0/kernel', 'dnn/hiddenlayer_0/kernel/t_0/Adagrad', 'dnn/logits/bias', 'dnn/logits/bias/t_0/Adagrad', 'dnn/logits/kernel', 'dnn/logits/kernel/t_0/Adagrad', 'global_step']
classifier.get_variable_value('dnn/hiddenlayer_0/kernel')
array([[ 3.63177538, 2.65476751, 2.22977662, -2.82275248],
[-1.96610606, 3.19546986, -3.34953451, -2.45343661]], dtype=float32)
Testing a Model¶
results = classifier.evaluate(input_fn=get_test_data)
results
{'accuracy': 1.0,
'accuracy_baseline': 0.52999997,
'auc': 1.0,
'auc_precision_recall': 1.0,
'average_loss': 0.10356656,
'global_step': 5000,
'label/mean': 0.52999997,
'loss': 5.178328,
'prediction/mean': 0.52209604}
Convolutional Networks¶
A convolutional neural network (CNN) is a special architecture that:
- Assumes that input features measure some property on a grid. The grid is usually spatial or temporal, but this is not required. For example, a 1D spectrum or time series, a 2D monochrome image, or a 3D stack of 2D images in different filters (RGB, etc).
- Performs translation-invariant learning efficiently. For example, identifying a galaxy wherever it appears in an image, or a transient pulse wherever it appears in a time series. The main efficiency is a much reduced number of parameters compared to the number of input features, relative to the dense fully connected networks we have seen so far.
We will use the following problem to motivate and demonstration a CNN:
- The input data consists of triplets of digitized waveforms.
- Each waveform has a slowly varying level with some narrow pulses superimposed.
- Each triplet has a single pulse that is synchronized (coincident) in all three waveforms.
- Waveforms also contain a random number of unsynchronized "background" pulses.
- Synchronized and unsynchronized pulses can overlap in time and between traces.
The goal is to identify the location of the synchronized pulses in each triplet. This is a simplified version of a common task in data acquisition trigger systems and transient analysis pipelines.
def generate(N=10000, ntrace=3, nt=100, nbg=1., A=5., nsmooth=3, T=1., seed=123):
gen = np.random.RandomState(seed=seed)
t_grid = np.linspace(0., T, nt)
# Generate the smooth background shapes as superpositions of random cosines.
wlen = 2 * T * gen.lognormal(mean=0., sigma=0.2, size=(nsmooth, N, ntrace, 1))
phase = gen.uniform(size=wlen.shape)
X = np.cos(2 * np.pi * (t_grid + phase * wlen) / wlen).sum(axis=0)
# Superimpose short pulses.
sigma = 0.02 * T
tsig = T * gen.uniform(0.05, 0.95, size=N)
y = np.empty(N, dtype=int)
nbg = gen.poisson(lam=nbg, size=(N, ntrace))
for i in range(N):
# Add a coincident pulse to all traces.
xsig = A * np.exp(-0.5 * (t_grid - tsig[i]) ** 2 / sigma ** 2)
y[i] = np.argmax(xsig)
X[i] += xsig
# Add non-coincident background pulses to each trace.
for j in range(ntrace):
if nbg[i, j] > 0:
t0 = T * gen.uniform(size=(nbg[i, j], 1))
X[i, j] += (A * np.exp(-0.5 * (t_grid - t0) ** 2 / sigma ** 2)).sum(axis=0)
return X.astype(np.float32), y
X, y = generate()
def plot_traces(X, y):
Nsample, Ntrace, D = X.shape
_, ax = plt.subplots(Nsample, 1, figsize=(9, 1.5 * Nsample))
t = np.linspace(0., 1., 100)
dt = t[1] - t[0]
for i in range(Nsample):
for j in range(Ntrace):
ax[i].plot(t, X[i, j], lw=1)
ax[i].axvline(t[y[i]], c='k', ls=':')
ax[i].set_yticks([])
ax[i].set_xticks([])
ax[i].set_xlim(-0.5 * dt, 1 + 0.5 * dt)
plt.subplots_adjust(left=0.01, right=0.99, bottom=0.01, top=0.99, hspace=0.1)
plot_traces(X[:5], y[:5])

The derivative of $f(x)$ can be approximated as $$ f'(x) \simeq \frac{f(x + \delta) - f(x - \delta)}{2\delta} $$ for small $\delta$. We can use this approximation to convert an array of $f(n \Delta x)$ values into an array of estimated $f'(n \Delta x)$ values using:
K = np.array([-1, 0, +1]) / ( 2 * dx)
fp[0] = K.dot(f[[0,1,2]])
fp[1] = K.dot(f[[1,2,3]])
...
fp[N-2] = K.dot(f[[N-3,N-2,N-1]]
The numpy convolve function automates this process of sliding an arbitrary kernel $K$ along an input array like this. The result only estimates a first (or higher-order) derivative when the kernel contains special values (and you should normally use the numpy gradient function for this), but any convolution is a valid and potentially useful transformation.
The kernel needs to completely overlap the input array it is being convolved with, which means that the output array is smaller and offset. Alternatively, you can pad the input array with zeros to extend the output array. There are three different conventions for handling these edge effects via the mode parameter to np.convolve:
- valid: no zero padding, so output length is $N - K + 1$ and offset is $(K-1)/2$.
- same: apply zero padding and trim so output length equals input length $N$, and offset is zero.
- full: apply zero padding without trimming, so output length is $N + K - 1$ and offset is $-(K-1)/2$.
(Here $N$ and $K$ are the input and kernel lengths, respectively).
We can use a convolution to identify features in our input data:
def plot_convolved(x, kernel, smax=50):
t = np.arange(len(x))
plt.plot(t, x, lw=1, c='gray')
z = np.convolve(x, kernel, mode='same')
for sel, c in zip(((z > 0), (z < 0)), 'rb'):
plt.scatter(t[sel], x[sel], c=c, s=smax * np.abs(z[sel]), lw=0)
plt.gca()
plt.grid('off')
First, let's pick out regions of large positive (red) or negative slope (notice how the edge padding causes some artifacts):
plot_convolved(X[1, 1], [0.5,0,-0.5])

We can also pick out regions of large curvature (using the finite-difference coefficients for a second derivative):
plot_convolved(X[1, 1], [1.,-2.,1.])

We can apply both of these convolutions to transform our input data to a new representation that highlights regions of large first or second derivative. Use a tanh activation to accentuate the effect:
def apply_convolutions(X, *kernels):
N1, N2, D = X.shape
out = []
for i in range(N1):
sample = []
for j in range(N2):
for K in kernels:
sample.append(np.tanh(np.convolve(X[i, j], K, mode='valid')))
out.append(sample)
return np.asarray(out)
out = apply_convolutions(X, [0.5,0,-0.5], [1.,-2.,1.])
The resulting array can be viewed as a synthetic image and offers an easy way to visually identify individual narrow peaks and their correlations between traces:
def plot_synthetic(Z):
_, ax = plt.subplots(len(Z), 1, figsize=(9, len(Z)))
for i, z in enumerate(Z):
ax[i].imshow(z, aspect='auto', origin='upper', interpolation='none',
cmap='coolwarm', vmin=-1, vmax=+1);
ax[i].grid('off')
ax[i].axis('off')
plt.subplots_adjust(left=0.01, right=0.99, bottom=0.01, top=0.99, hspace=0.1)
plot_synthetic(out[:5])

The patterns that identify individual and coincident peaks are all translation invariant so can be identified in this array using a new convolution, but now in the 2D space of these synthetic images.
Since matrix convolution is a linear operation, it is a special case of our general neural network unit, $$ \mathbf{f}(\mathbf{x}) = W\mathbf{x} + \mathbf{b} \; , $$ but with the matrix $W$ now having many repeated elements so its effective number of dimensions is greatly reduced in typical applications.
A convolutional layer takes an arbitrary input array and applies a number of filters with the same shape in parallel. By default, the filter kernels march with single-element steps through the input array, but you can also specify larger stride vector.
In the general case, the input array, kernels and stride vector are all multidimensional, but with the same dimension. Tensorflow provides convenience functions for 1D, 2D and 3D convolutional layers, for example:
hidden = tf.layers.Conv2D(
filters=3, kernel_size=[4, 5], strides=[2, 1],
padding='same', activation=tf.nn.relu)
Note that padding specifies how edges effects are handled, but only same and valid are supported (and valid is the default). You can also implement higher-dimensional convolutional layers using the lower-level APIs.
A convolutional neural network (CNN) is a network containing convolutional layers. A typical architecture starts with convolutional layers, processing the input, then finishes with some fully connected dense layers to calculate the output. Since one of the goals of a CNN is reduce the number of parameters, a CNN often also incorporates pooling layers to reduce the size of the array fed to to later layers by "downsampling" (typically using a maximum or mean value). See these Stanford CS231n notes for more details in the context of image classification.
def pulse_model(features, labels, mode, params):
"""Build a graph to TRAIN/TEST/PREDICT a pulse coincidence detection model.
"""
D = params['time_steps']
M = params['number_of_traces']
n1 = params['conv1_width']
n2 = params['conv2_width']
eta = params['learning_rate']
assert n1 % 2 == 1 and n2 % 2 == 1
# Build the input layer.
inputs = tf.reshape(features['X'], [-1, M, D, 1])
# Add the first convolutional layer.
conv1 = tf.layers.conv2d(
inputs=inputs, filters=2, kernel_size=[1, n1],
padding='same', activation=tf.tanh, name='conv1')
# Add the second convolutional (and output) layer.
logits = tf.layers.conv2d(
inputs=conv1, filters=1, kernel_size=[M, n2],
padding='valid', activation=None, name='conv2')
# Flatten the outputs.
logits = tf.reshape(logits, [-1, D - n2 + 1])
# Calculate the offset between input labels and the output-layer node index
# that is introduced by using padding='valid' for the output layer below.
offset = (n2 - 1) // 2
# Calculate the network's predicted best label.
predicted_labels = tf.argmax(logits, axis=1) + offset
# Calculate the network's predicted probability of each label.
probs = tf.nn.softmax(logits)
# Calculate the network's predicted mean label.
bins = tf.range(0., D - n2 + 1., dtype=np.float32) + offset
mean_labels = tf.reduce_sum(bins * probs, axis=-1)
# Return predicted labels and probabilities in PREDICT mode.
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions={
'label': predicted_labels,
'probs': tf.nn.softmax(logits)
})
# Calculate the loss for TRAIN and EVAL modes. We need to offset the labels
# used here so they correspond to output-layer node indices.
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels - offset, logits=logits)
# Compute evaluation metrics.
if mode == tf.estimator.ModeKeys.EVAL:
accuracy = tf.metrics.accuracy(labels=labels, predictions=predicted_labels)
rmse = tf.metrics.root_mean_squared_error(
labels=tf.cast(labels, np.float32), predictions=mean_labels)
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops={'accuracy': accuracy, 'rmse': rmse})
# Create optimizer.
assert mode == tf.estimator.ModeKeys.TRAIN
optimizer = tf.train.AdamOptimizer(learning_rate=eta)
step = optimizer.minimize(loss, global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=step)
tf.logging.set_verbosity(tf.logging.WARN)
!rm -rf tfs/pulses
config = tf.estimator.RunConfig(
model_dir='tfs/pulses',
tf_random_seed=123
)
pulse = tf.estimator.Estimator(
config=config,
model_fn=pulse_model,
params = dict(
time_steps=100,
number_of_traces=3,
conv1_width=3,
conv2_width=7,
learning_rate=0.01))
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.4, random_state=123)
pulse.train(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': X_train}, y=y_train,
batch_size=500, num_epochs=None, shuffle=True),
steps=500);
Compare the kernels learned during training with the derivative kernels we used above. We find that they are qualitatively similar:
- The "odd" kernel correlates most strongly with a rising slope, so approximately measures $+f'(t)$.
- The "even" kernel correlates most strongly with a local maximum, so approximately measures $-f''(t)$.
- The odd-numbered rows of the image are correlated with the odd kernel, and correlate with a pulse that rises (red) on the left and falls on the right (blue).
- The even-numbered rows of the image are correlated with the even kernel, and correlate with a pulse that peaks (dark red) at the center.
Note that nothing in the network architecture requires that the three traces be processed the same way in the second convolutional layer (right-hand image), and we do find some variations. A more detailed analysis of these weights would take into account the additional bias parameters and the influence of the activations.
def plot_kernels():
M = pulse.params['number_of_traces']
n1 = pulse.params['conv1_width']
n2 = pulse.params['conv2_width']
K1 = pulse.get_variable_value('conv1/kernel')
K2 = pulse.get_variable_value('conv2/kernel')
assert K1.shape == (1, n1, 1, 2)
assert K2.shape == (M, n2, 2, 1)
_, ax = plt.subplots(1, 2, figsize=(10, 3))
# Plot the two 1D kernels used in the first layer.
dt = np.arange(n1) - 0.5 * (n1 - 1)
ax[0].plot(dt, K1[0, :, 0, 0], 'o:', label='even')
ax[0].plot(dt, K1[0, :, 0, 1], 'o:', label='odd')
ax[0].legend(fontsize='x-large')
# Assemble an image of the second-layer kernel that can be compared with plot_synthetic().
K2img = np.empty((M, 2, n2))
K2img[:, 0] = K2[:, :, 0, 0]
K2img[:, 1] = K2[:, :, 1, 0]
vlim = np.max(np.abs(K2))
ax[1].imshow(K2img.reshape(2 * M, n2), aspect='auto', origin='upper',
interpolation='none', cmap='coolwarm', vmin=-vlim, vmax=+vlim)
ax[1].axis('off')
ax[1].grid('off')
plt.tight_layout()
plot_kernels()

Evaluate how well the trained network performs on the test data:
results = pulse.evaluate(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': X_test}, y=y_test,
num_epochs=1, shuffle=False))
We find that about 95% of test samples are classified "correctly", defined as the network predicting the bin containing the the coincidence maximum exactly. However, The RMS error between the predicted and true bins is only 0.4 bins, indicating that the network usually predicts a neighboring bin in the 5% of "incorrect" test cases.
results
{'accuracy': 0.94674999,
'global_step': 500,
'loss': 0.14994568,
'rmse': 0.40537277}
Finally, compare the predicted (gray histogram) and true (dotted line) coincidence locations for a few test samples:
def plot_predictions(X, y):
# Calculate predicted labels and PDFs over labels.
predictions = pulse.predict(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': X}, y=None, num_epochs=1, shuffle=False))
Nsample, Ntrace, D = X.shape
t = np.linspace(0., 1., 100)
dt = t[1] - t[0]
bins = np.linspace(-0.5 * dt, 1 + 0.5 * dt, len(t) + 1)
probs = np.zeros(D)
# Plot input data, truth, and predictions.
_, ax = plt.subplots(Nsample, 1, figsize=(9, 1.5 * Nsample))
for i, pred in enumerate(predictions):
label = pred['label']
# Plot the input traces.
for x in X[i]:
ax[i].plot(t, x, lw=1)
# Indicate the true coincidence position.
ax[i].axvline(t[y[i]], c='k', ls=':')
# Indicate the predicted probability distribution.
n2 = D - len(pred['probs']) + 1
offset = (n2 - 1) // 2
probs[offset:-offset] = pred['probs']
rhs = ax[i].twinx()
rhs.hist(t, weights=probs, bins=bins, histtype='stepfilled', alpha=0.25, color='k')
rhs.set_ylim(0., 1.)
rhs.set_xlim(bins[0], bins[-1])
rhs.set_yticks([])
ax[i].set_xticks([])
ax[i].set_yticks([])
ax[i].grid('off')
ax[i].set_xlim(bins[0], bins[-1])
plt.subplots_adjust(left=0.01, right=0.99, bottom=0.01, top=0.99, hspace=0.1)
plot_predictions(X_test[:5], y_test[:5])

Note that our loss function does not know that consecutive labels are close and being off by one is almost as good as getting the right label. We could change this by treating this as a regression problem, but a nice feature of our multi-category approach is that we can predict a a full probability density over labels (the gray histograms above) which is often useful.
Networks for Unsupervised Learning¶
Neural networks are usually used for supervised learning since their learning is accomplished by optimizing a loss function that compares the network's outputs with some target values. However, it is possible to perform unsupervised learning if we can somehow use the same data for both the input values and the target output values. This requires that the network have the same number of input and output nodes, and effectively means that we are asking it to learn the identify function, which does not sound obviously useful.
Suppose we have a single hidden layer with the same number of nodes as the input and output layers, then all the network has to do is pass each input value through to the output, which does not require any training at all! However, if the hidden layer has fewer nodes then we are asking the network to solve a more interesting problem: how can the input dataset be encoded and then decoded. This is the same dimensionality reduction problem we discussed earlier, and is known as an autoencoder network since it learns to encode itself:
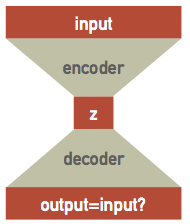
The network can be thought of as the combination of separate encoder and decoder networks, with the encoder feeding its output latent variables $\mathbf{z}$ into the decoder. Although the architecture looks symmetric, the encoder and decoder will generally learn different parameters because of the asymmetry introduced by nonlinear activations. These is a high-level design pattern and the internal architectures of the encoder and decoder networks should be customized for the type of data being encoded (and typically combined convolutional and dense layers).
See this blog post for an example based on decoding handwritten digits.
Autoencoder Example¶
Re-use the spectral data for an example. Recall that there are only 200 samples in 500 dimensions:
X = pd.read_hdf(locate_data('spectra_data.hf5')).values
for i in (0, 6, 7):
plt.plot(X[i], '.', ms=5)

The tensorflow layers API initializes parameters assuming that inputs are roughly normalized:
X0 = np.mean(X, axis=0)
Xmax = np.max(np.abs(X - X0))
Xn = (X - X0) / Xmax
original = lambda x: Xmax * x + X0
assert np.allclose(X, original(Xn))
for i in (0, 6, 7):
plt.plot(Xn[i], '.', ms=5)

Tensorflow does not provide a premade autoencoder so we build a custom estimator using the intermediate-level layers API:
def autoencoder_model(features, labels, mode, params):
"""Build a graph to TRAIN/TEST/PREDICT an autoencoder model.
"""
D = params['dimension']
C = params['n_components']
eta = params['learning_rate']
# Build the input layer.
inputs = tf.reshape(features['X'], [-1, D])
# Add encoder hidden layers with softsign activations.
encoded = inputs
for units in params['hidden_units']:
encoded = tf.layers.dense(inputs=encoded, units=units, activation=tf.nn.softsign)
# Add the final encoder layer with linear activation.
latent = tf.layers.dense(inputs=encoded, units=C, activation=None)
# Add decoder hidden layers with softsign activations.
decoded = latent
for units in params['hidden_units'][::-1]:
decoded = tf.layers.dense(inputs=decoded, units=units, activation=tf.nn.softsign)
# The final decoder layer has linear activation.
outputs = tf.layers.dense(inputs=decoded, units=D, activation=None)
# Return predicted labels and probabilities in PREDICT mode.
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions={
'latent': latent, 'output': outputs})
# Calculate the loss for TRAIN and EVAL modes.
loss = tf.nn.l2_loss(outputs - inputs)
# Compute evaluation metrics.
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss)
# Create optimizer.
optimizer = tf.train.AdamOptimizer(learning_rate=eta)
step = optimizer.minimize(loss, global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=step)
The subsequent steps are similar to the previous examples:
tf.logging.set_verbosity(tf.logging.WARN)
!rm -rf tfs/autoenc
config = tf.estimator.RunConfig(
model_dir='tfs/autoenc',
tf_random_seed=123
)
autoenc = tf.estimator.Estimator(
config=config,
model_fn=autoencoder_model,
params = dict(
dimension=500,
hidden_units=[4],
n_components=2,
learning_rate=0.01))
autoenc.train(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': Xn}, y=None,
batch_size=200, num_epochs=None, shuffle=True),
steps=1000);
def plot_reconstructed(Xn, model):
predictions = model.predict(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': Xn}, y=None, num_epochs=1, shuffle=False))
N, D = Xn.shape
fig = plt.figure(figsize=(8.5, 4))
for i, pred in enumerate(predictions):
Xr = original(pred['output'])
plt.plot(original(Xn[i]), '.', ms=5)
plt.plot(Xr, 'k-', lw=1, alpha=0.5)
plt.xlim(-0.5, D+0.5)
plt.xlabel('Feature #')
plt.ylabel('Normalized Feature Value')
plot_reconstructed(Xn[[0, 6, 7]], model=autoenc)

def plot_latent(Xn, model):
predictions = model.predict(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': Xn}, y=None, num_epochs=1, shuffle=False))
latent = []
for pred in predictions:
latent.append(pred['latent'])
df = pd.DataFrame(latent)
sns.pairplot(df)
return df
latent = plot_latent(Xn, model=autoenc)

Variational Autoencoder¶
A further refinement on the autoencoder idea is to learn a posterior probability distribution in the latent variable space, instead of simply mapping each input to its corresponding point in the latent variable space. This is easier than it sounds if we assume that the posterior for each individual sample is described by an (uncorrelated) multi-variate Gaussian.
In practice, we simply need to learn how to transform each input to a corresponding vector of means $\mathbf{\mu}$ and sigmas $\mathbf{\sigma}$ in the latent variable space, effectively doubling the the number of output values for the encoder network, now re-interpreted as a posterior inference network. Since this first stage is effectively a variational model of the posterior, learning its parameters is equivalent to performing a variational inference and we call this approach a variational autoencoder (VAE).
The decoder network is also re-interpreted as a probabilistic generator of realistic (smoothed) data. It is a generator rather than a decoder since it is no longer directly connected to the inputs. After training, it can be useful as a standalone simulator of realistic inputs.
Finally we need a prior we we take to be a unit (multivariate) Gaussian in the latent-variable space. This is an arbitrary choice, but some choice is necessary in order to setup the balance between the influence of each input against some prior that is a key feature of Bayesian learning. In effect, we are reversing the way we usually build a model, which is to specify the parameters then ask what their prior should be. Instead, we are specifying the prior and then learning a (latent) parameter space that can explain the data with this prior.
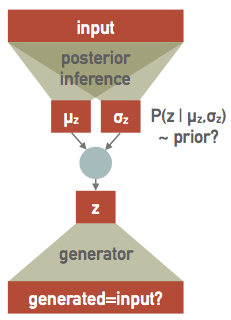
In a bit more detail, the upper network implements a variational model $Q(z;X,\Theta)$ for the posterior probability density $P(X\mid z)$ of a single sample $X$, parameterized by its weights and biases in $\Theta$. Specifically, $Q$ is a multivariate Gaussian in $z$ with parameters $\mu_z(X, \Theta)$ and $\sigma_z(X, \Theta)$ output by the upper network.
The lower network generates $X$ from $z$ and the the part of the loss function that compares its output against the input plays the role of the negative-log likelihood $-\log P(X\mid z)$ of a single sample $X$.
Recall that in variational inference, we minimize the negative ELBO: $$ -\int d z\, Q(z; X,\Theta) \log P(X\mid z) + \text{KL}(Q\parallel P) = \langle -\log P(X\mid z)\rangle_{z\sim Q} + \text{KL}(Q\parallel P) \; , $$ where $P$ is the prior on $z$. Since both $Q$ and $P$ are (multivariate) Gaussians, we can evaluate their KL divergence analytically, as $$ \text{KL}(Q\parallel P) = \frac{1}{2} \sum_{i=1}^C\, \left[ \mu_{z,i}^2 + \sigma_{z,i}^2 - \log \sigma_{z,i}^2 - 1 \right] $$ where $C$ is the dimension of the latent space. Therefore the total loss function we want to optimize combines the likelihood, which compares the input with the generated output, and a KL divergence term. If we assume that the data samples have Gaussian homoscedastic noise with variance $\sigma_x^2$, then the first time in the negative ELBO is $$ -\log P(X\mid z) = \frac{1}{2\sigma_x^2} \left| \mathbf{X}_{out} - \mathbf{X}_{in}\right|^2 + \text{constant} \; . $$ Note that is almost the $L_2$ loss, but since we are combining it with the KL term, we must keep track of the $\sigma_x^{-2}$ scaling. With this choice of noise model, $\sigma_x$ is a hyperparameter but other noise models (e.g., Poisson errors) would not need any hyperparameter. After normalization, the uncertainties in this dataset correspond to $\sigma_x \simeq 0.017$.
Finally, training the overall network accomplishes two goals in parallel:
- Find a latent space where a unit Gaussian prior can explain the training data.
- Perform variational inference to find the best $Q(z; X, \Theta)$ that approximates the posteriors $P(z\mid X)$ for each training sample.
See this tutorial for more details on the probabilistic background of VAE.
Our custom estimator to implement a VAE shares most of its code with the earlier autoencoder:
def variational_autoencoder_model(features, labels, mode, params):
"""Build a graph to TRAIN/TEST/PREDICT a variational autoencoder model.
"""
D = params['dimension']
C = params['n_components']
eta = params['learning_rate']
sigx = params['noise_sigma']
# Build the input layer.
inputs = tf.reshape(features['X'], [-1, D])
# Add encoder hidden layers with softsign activations.
encoded = inputs
for units in params['hidden_units']:
encoded = tf.layers.dense(inputs=encoded, units=units, activation=tf.nn.softsign)
# Add the final encoder layer with linear activation.
# Estimate the posterior mean and t=log(sigma) in the latent space.
latent_mu = tf.layers.dense(inputs=encoded, units=C, activation=None)
latent_t = tf.layers.dense(inputs=encoded, units=C, activation=None)
# Draw random samples from the encoded posterior.
sigma = tf.exp(latent_t)
latent = latent_mu + sigma * tf.random_normal(tf.shape(sigma))
# Add decoder hidden layers with softsign activations.
decoded = latent
for units in params['hidden_units'][::-1]:
decoded = tf.layers.dense(inputs=decoded, units=units, activation=tf.nn.softsign)
# The final decoder layer has linear activation.
outputs = tf.layers.dense(inputs=decoded, units=D, activation=None)
# Return predicted labels and probabilities in PREDICT mode.
if mode == tf.estimator.ModeKeys.PREDICT:
return tf.estimator.EstimatorSpec(mode, predictions={
'mean': latent_mu,
'sigma': sigma,
'latent': latent,
'output': outputs})
# Calculate the loss for TRAIN and EVAL modes.
decoder_loss = tf.reduce_sum((outputs - inputs) ** 2, axis=1) / (2 * sigx)
kl_loss = 0.5 * tf.reduce_sum(latent_mu ** 2 + sigma ** 2 - 2 * latent_t - 1, axis=1)
loss = tf.reduce_mean(decoder_loss + kl_loss)
# Compute evaluation metrics.
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss)
# Create optimizer.
optimizer = tf.train.AdamOptimizer(learning_rate=eta)
step = optimizer.minimize(loss, global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=step)
tf.logging.set_verbosity(tf.logging.WARN)
!rm -rf tfs/vae
config = tf.estimator.RunConfig(
model_dir='tfs/vae',
tf_random_seed=123
)
vae = tf.estimator.Estimator(
config=config,
model_fn=variational_autoencoder_model,
params = dict(
dimension=500,
hidden_units=[],
n_components=2,
noise_sigma=0.015,
learning_rate=0.001))
vae.train(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': Xn}, y=None,
batch_size=250, num_epochs=None, shuffle=True),
steps=10000);
The plots below summarize the trained network's predictions. The left plot shows random samples drawn from the posteriors of individual samples and the right plot shows the distribution of the training data in the latent space. A few samples are highlighted in red in both plots: ellipses in the right-hand plot show each sample's posterior compared with the prior (dotted red circle).
def plot_predicted(Xn, model=vae, nsamples=5, nsig=2.45):
predictions = model.predict(
input_fn=tf.estimator.inputs.numpy_input_fn(
x={'X': Xn}, y=None, num_epochs=1, shuffle=False))
N, D = Xn.shape
mean, sigma, z = [], [], []
_, ax = plt.subplots(1, 2, figsize=(12, 6))
for i, pred in enumerate(predictions):
Xr = original(pred['output'])
if i < nsamples:
ax[0].plot(Xr, 'r-', lw=1, alpha=0.5, zorder=10)
else:
ax[0].plot(Xr, 'k-', lw=4, alpha=0.02)
mean.append(pred['mean'])
sigma.append(pred['sigma'])
z.append(pred['latent'])
ax[0].set_xlim(-0.5, D+0.5)
ax[0].set_xlabel('Feature #')
ax[0].set_ylabel('Feature Value')
mean = np.array(mean)
sigma = np.array(sigma)
z = np.array(z)
ax[1].scatter(z[:, 0], z[:, 1], s=10, lw=0)
ax[1].add_artist(plt.Circle([0,0], nsig, ls=':', fc='none', ec='r', lw=1))
mu = mean[:nsamples]
ax[1].scatter(mu[:, 0], mu[:, 1], s=25, marker='+', color='r')
widths = nsig * sigma[:nsamples, 0]
heights = nsig * sigma[:nsamples, 1]
angles = np.zeros_like(widths)
ax[1].add_collection(matplotlib.collections.EllipseCollection(
widths, heights, angles, units='xy', offsets=mu, linewidths=1,
transOffset=ax[1].transData, facecolors='none', edgecolors='r'))
ax[1].set_xlabel('Latent variable $z_1$')
ax[1].set_ylabel('Latent variable $z_2$')
plot_predicted(Xn)

Generative-Adversarial Network¶
Building on the theme of a probabilistic generator, we can set up an "arms race" between two networks:
- A generator that learns to synthesize realistic data.
- An adversary that learns to discriminate between real and generated data.
This is the central idea of a generative-adversarial network (GAN), which is a recent idea (2014):
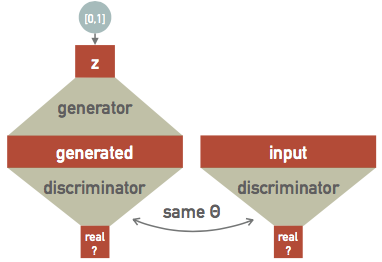
Each training step now has several parts:
- Generate some random data.
- Test how well the discriminator identifies the generated data as a fake.
- Feed the same discriminator some real data.
- Test how well the discriminator identifies the real data as real.
Optimizing the loss function then simultaneously improves the generator and the discriminator. The usual goal of training a GAN is to obtain a useful generator of realistic data.
See this blog post for an example based on image generation.
Recurrent Networks¶
All the architectures we have seen so far are feed-foward networks, with input data always from left (input layer) to right (output layer). A recurrent neural network (RNN) adds links that feed back into a previous layer. This simple modification adds significant complexity but also expressive power (comparable to the electronics revolution associated with the idea of transistor feedback).
Architectures with feedback are still maturing but some useful building blocks have emerged, such as the long short-term memory unit, which allows a network to remember some internal state but also forget it based on new input.
Some practical considerations for RNN designs:
- The order of training data is now significant and defines a "model time", but the network can be reset whenever needed.
- Input data can be packaged into variable-length messages that generate variable (and different) length output messages. This is exactly what language translation needs.
- Optimization of the weights using gradients is still possible but requires "unrolling" the network by cloning it enough times to process the longest allowed messages.
A feed-foward network implements a universal approximating function. Since the internal state of an RNN acts like local variables, you can think of an RNN as a universal approximating program.
See this blog post for an example based on natural language synthesis.
Reinforcement Learning¶
The architectures we have seen so far all have target output values associated with each input sample, which are necessary to update the network parameters during the learning (loss optimization) phase:
However, we can relax this requirement of being able to calculate a loss after each new input as long as we eventually get some feedback on how well our input-to-output mapping is doing. This is the key idea of reinforcement learning (RL):
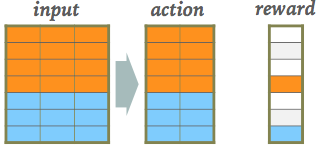
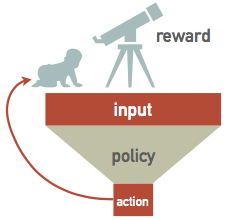
A RL network watches some external "reality" (which is often simulated) and learns a policy for how to take actions. A sequence of actions eventually leads to some feedback, which is then used to take a single step in optimizing the policy network's parameters:
See this blog post for an example based on image generation.
Deep Learning Outlook¶
The depth of "deep learning" comes primarily from network architectures that stack many layers. In another sense, deep learning is very shallow since it often performs well using little to no specific knowledge about the problem it is solving, using generic building blocks.
The field of modern deep learning started around 2012 when the architectures described above were first used successfully, and the necessary large-scale computing and datasets were available. Massive neural networks are now the state of the art for many benchmark problems, including image classification, speech recognition and language translation.
However, less than a decade into the field, there are signs that deep learning is reaching its limits. Some of the pioneers are focusing on new directions such as capsule networks and causal inference. Others are taking a critical look at the current state of the field:
- Deep learning does not use data efficiently.
- Deep learning does not integrate prior knowledge.
- Deep learning often give correct answers but without associated uncertainties.
- Deep learning applications are hard to interpret and transfer to related problems.
- Deep learning is excellent at learning stable input-output mappings but does cope well with varying conditions.
- Deep learning cannot distinguish between correlation and causation.
These are mostly concerns for the future of neural networks as a general model for artificial intelligence, but they also limit the potential of scientific applications.
However, there are many challenges in scientific data analysis and interpretation that could benefit from deep learning approaches, so I encourage you to follow the field and experiment.