1. Machine Learning Overview¶
How to learn machine learning¶

머신러닝이란 간단하게 말해 기존에 있던 데이터를 어떠한 알고리즘을 사용하여 모델을 만들어내고, 새로운 데이터에 그 모델을 적용을 시켜서 예측을 하는 방법이다.
그래서 핵심이 되는 것은 아래의 그림이다.

머신러닝에서 중요한 것은 역시나 알고리즘을 사용하여 모델을 잘 설계하는 것이다. 하지만 위의 그림에서 또 중요한 것은 기존의 데이터와 새로운 데이터이다. 아래의 그림을 보자.

위의 그림은 옥자라는 영화가 있을 때, 과연 몇 명이나 볼 것인가를 예측하고 싶은 것이다. 그래서 왓챠에 있는 '보고싶어요'수와 실제 총 관객 수를 이용하여 머신러닝 알고리즘의 하나인 Linear Regression을 통해 나타낸 것이다. 마션, 킹스맨, 캡틴 아메리카, 인터스텔라의 기존의 데이터로 머신러닝을 통해 학습을 시키고, 옥자의 왓챠 '보고싶어요'수를 통해 새로운 데이터로 727만 명이라는 예측을 할 수 있는 것이다.
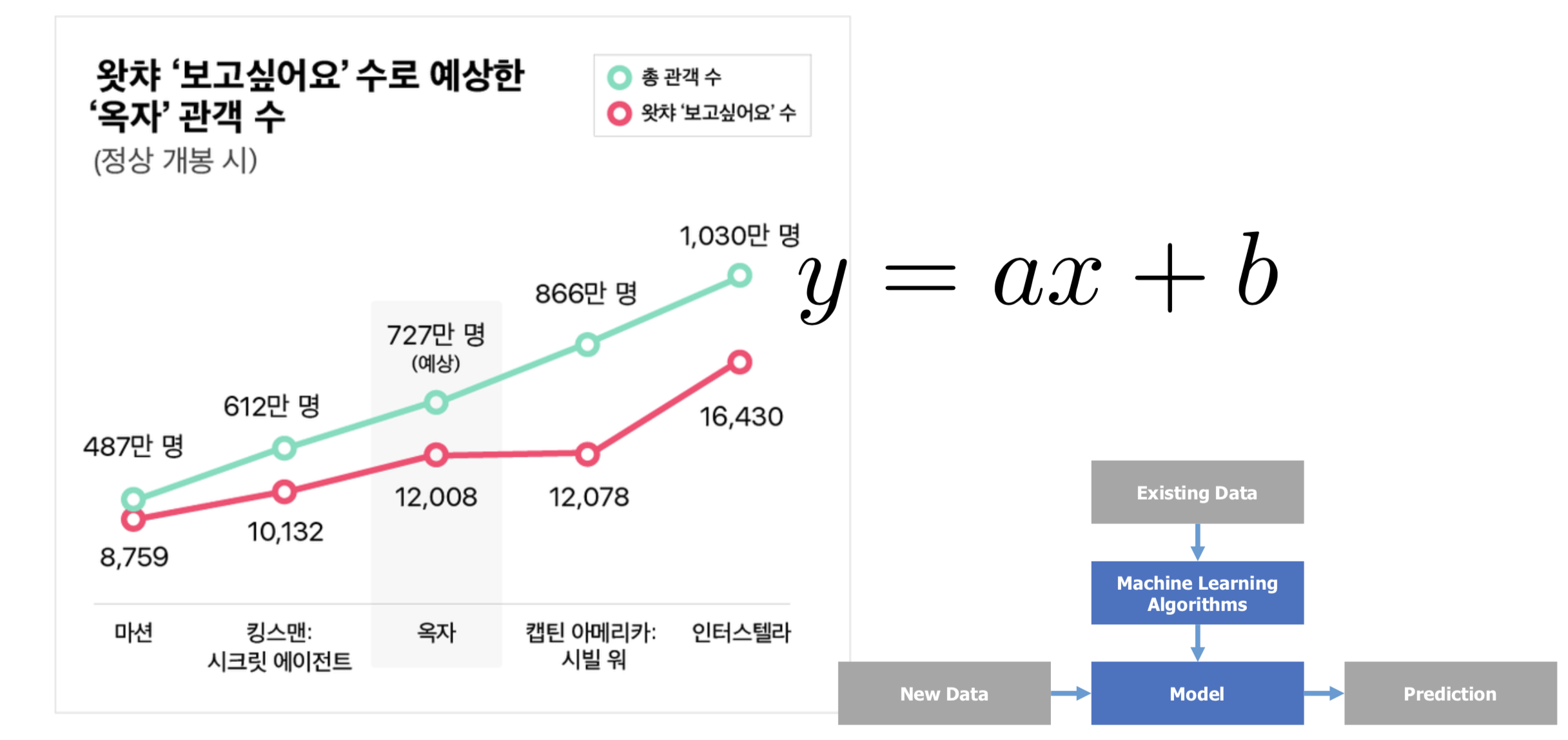
그래서 우리는 위의 그림과 같은 선을 1차 함수로 표현할 수 있는데 'y = ax + b'의 꼴로 표현할 수 있다. 여기서 x가 왓챠의 '보고싶어요'수를 의미하고 y는 총 관객 수를 말한다. 우리가 구하고 싶은 것은 a와 b이며, a와 b만 알아내면 위의 그림과 같이 선을 그릴 수가 있다.
a와 b를 알기 위한 주요 핵심은 앞서 말했듯이 모델과 알고리즘이다. 모델의 경우 예측을 위한 수학 공식, 함수 그리고 1차 방정식, 확률분포, condition rule이라고 할 수 있고, 알고리즘의 경우 어떠한 문제를 풀기 위한 과정 또는 Model을 생성하기 위한 (훈련) 과정이라고 말할 수 있다.
그래서 우리는 먼저 모델들을 만드는 방법들에 대해서 알아보고, 이 모델들을 이해하기 위해서 모델을 학습할 때 영향을 주는 것들에 대해서 알아보자.
2. An understanding of data¶
The concept of a feature¶

먼저 위의 그림을 보면 주어진 x값을 독립변수라고 한다. 아까 왓챠의 '보고싶어요'수를 떠올리면 편하다. 다음으로 주어진 y값을 종속변수라고 하고 앞서 봤던 실제 관객의 수를 떠올리면 된다. 그리고 우리가 아직 모르는 a와 b는 알고리즘을 통해서 최적값을 찾아내야 하는 것이다.
그렇지만 실제 데이터에서 y값에 영향을 주는 독립변수 x값은 하나가 아니다. 다음의 그림을 보자.

위의 그림은 Boston House Price Dataset이라고 하여 머신러닝 등 데이터 분석을 처음 배울 때 가장 대표적으로 사용하는 Example Dataset이다. 1978년에 발표된 데이터로, 미국 인구통계 조사 결과 미국 보스턴 지역의 주택 가격에 영향 요소들을 정리한 것이다.
보다시피 주어진 x값은 하나가 아니라 13개가 될 수 있고 더 많아질 수도 있다.

이렇게 13개의 x변수, 1개의 y변수가 있을 때 위와 같은 식으로 표현할 수 있다. 이렇게 x변수의 실제 데이터를 우리는 featrue(특징)이라고 부른다.
featrue라는 것은 머신러닝에서 데이터의 특징을 나타내는 변수이고, feature, 독립변수, input 변수 등이라고 보통 부르는데 다 같은 의미이다. 일반적으로 Table 상에 Data를 표현할 때, Column을 의미한다고 보면 된다. 그래서 하나의 data instance(= row, 실제 데이터)는 feature들을 이용하여 vector의 형태로 표현할 수 있다.
저기서 베타값은 weight값이라고도 하고, 세타라고도 하는데 총 13개의 변수 앞에는 weight값이 들어가게 된다. 그래서 y = ax + b에서 a가 위의 수식에서는 베타이고, b는 마지막 베타 제로를 의미하게 된다.
결국 우리는 x와 y를 가지고 있고 컴퓨터에게 "베타를 어떻게 알아낼꺼야?"라고 가르쳐 주어야 한다. 그래서 가르쳐 주기 위해서 대표적으로 feature들을 vector의 형태로 만들어준다.
아래의 그림처럼 data가 있다고 해보자. 그러면 두 번째 그림처럼 feature들을 이용하여 vector의 형태로 표현할 수 있다.

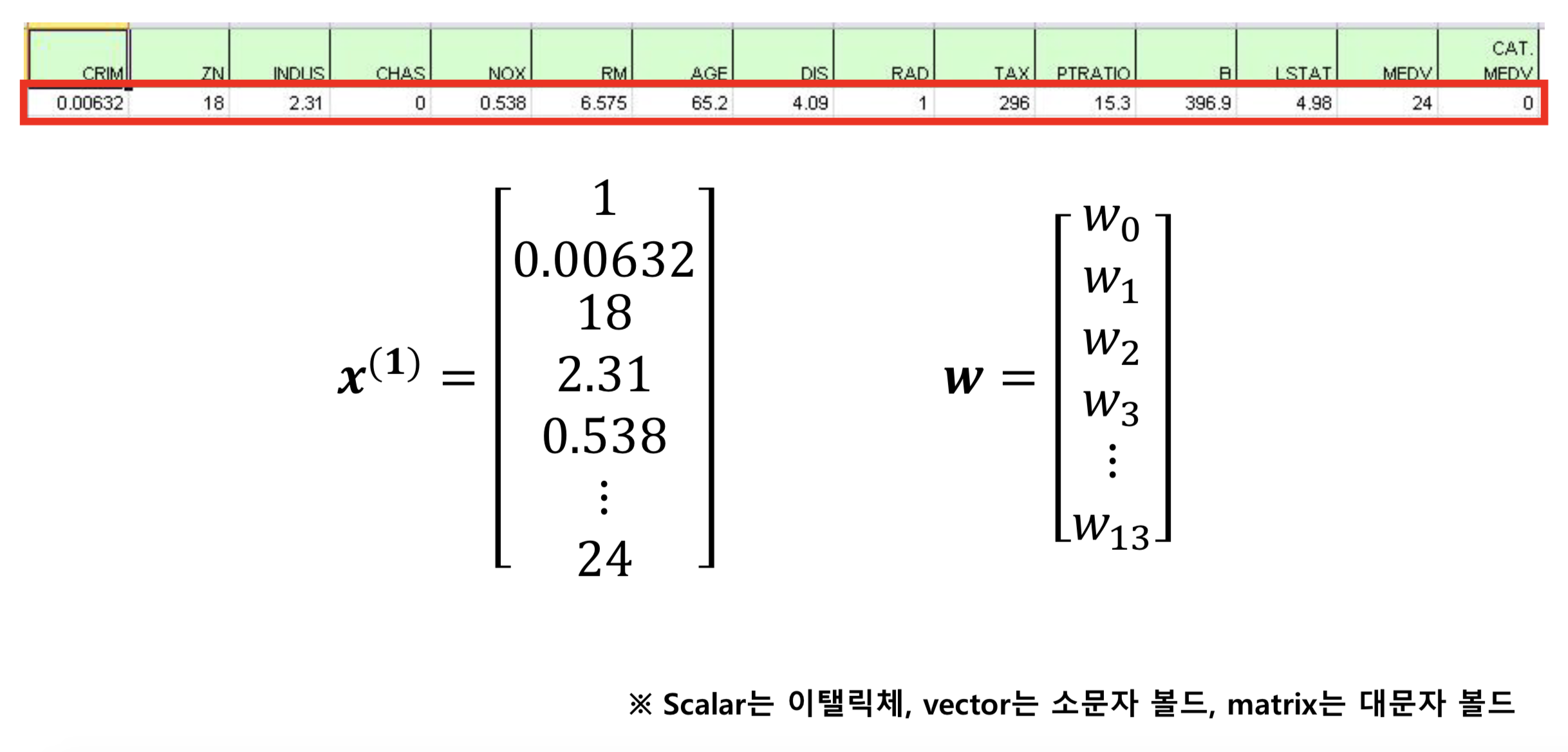
그래서 보통 전체적으로 vector형태로 사용할 때 아래의 수식처럼 쓴다.

선형대수의 표기법을 사용하여 $W^T X$로 쓸 수 있고, 실제로 transpose를 한 뒤에 matrix의 곱 연산을 통해 계산이 이루어진다.
그러면 featrue의 갯수에 따라서 차원도 달라질 것이고 이에 따른 시각화도 달라질 것이다.

1개 또는 2개 정도면 표현이 가능한데 만약에 n개라면 우리가 상상할 수도 없을 것이고, 표현하기도 힘들 것이다.

위의 그림처럼 5차원까지는 표현할 수도 있겠지만 n차원이라면 차원의 저주(curse of dimensionality)가 생긴다. 데이터의 차원이 증가할 수록(=feature가 증가할 수록) 데이터를 표현하는 공간이 증가하기 때문에 문제가 발생하고, 따라서 데이터 분포나 모델 추정의 어려움이 생긴다.
따라서 featrue를 정할 때는 내가 예측하고자 하는 것에 정말 필요한 feature인지를 생각해야하고, 차원이 증가함에 따른 해결 방법들도 알아두어야 한다.
결국 우리는 $Y = W^T X$를 코드로 표현해야 하는데 그전에 먼저 알아야 되는 것 중에 하나인 데이터를 불러오는 것에 있어서 데이터를 표현하는 방식에 대해서 알아보자.
Expression of data¶
아래의 그림처럼 data를 표현할 수 있다. 책마다 표현은 조금 다를 수 있다.

전체 데이터를 data table 또는 sample이라고 부를 것이고, column에 위치에 있는 것은 attribute나 field, feature라고 할 것이다. 그리고 한 명의 데이터 또는 한 집의 데이터인 row에 위치하는 것은 instance, tuple이라고 부를 것이다. feature 하나에 있는 모든 column을 feature vector라고 부를 것이며, 각 value들을 data라고 부를 것이다.

그래서 앞서 본 data table과 같은 데이터들을 컴퓨터가 처리해주기 위해서는 데이터를 호출해야하는 데, 그럴 때 주로 사용하는 것이 'Pandas'라고 하는 것이다. pandas를 사용하여 우리는 엑셀처럼 데이터를 호출해서 핸들링을 할 수 있는 도구이다.

보다 더 자세한 내용은 뒤에서 정리할 것이다.
그리고 데이터를 vector 형태로 표현하고 matrix 형태로 표현하고 그것을 핸들링을 해야하는 데 이럴 때 필요한 도구가 바로 Numpy이다. numpy는 벡터연산에 있어서 최적의 라이브러리이다.

그래서 먼저 numpy와 pandas에 대해 먼저 공부하여 아래의 수식처럼 전체 데이터 sample(data table)에 대해서 'y = ax + b'의 수식을 기본적으로 어떤 식으로 핸들링 할 것인지에 대해서 알아볼 것이다.
