Run the code cell below with the ▶| button above to set up this notebook, or type SHIFT-ENTER:
from datascience import *
import pandas as pd
import geojson
import numpy as np
import matplotlib.pyplot as plt
import folium
from IPython.display import HTML, display, IFrame
from folium import plugins
%matplotlib inline
from scipy import stats
import ipywidgets as widgets
from soc_module import *
import warnings
warnings.filterwarnings('ignore')
from datetime import datetime
import re
Sociology 130 Module: "The Neighborhood Project"¶
Welcome to the data science part of your project! You have gathered data and entered it here from your assigned census tracts. Now it's time to explore our class data and quantify our observations using Python, a popular programming language used in data science.
You won't need any prior programming knowledge to do this! The purpose of this module is not to teach you programming, but rather to show you the power of these tools and give you the intuition for how they work. It also allows us to quickly produce summarizations of our data!
Table of Contents¶
Completing the Notebooks¶
QUESTION cells are in blue and ask you to answers questions or fill in code cells. To receive full credit for your assignment, you must complete all QUESTION cells.
Part 0: Introduction to Python and Jupyter Notebooks: ¶
1. Cells and Code¶
In a notebook, each rectangle containing text or code is called a cell.
Cells (like this one) can be edited by double-clicking on them. This cell is a text cell, written in a simple format called Markdown to add formatting and section headings. You don't need to worry about Markdown today, but it's a pretty fun+easy tool to learn.
After you edit a cell, click the "run cell" button at the top that looks like ▶| to confirm any changes. (Try not to delete the instructions.) You can also press SHIFT-ENTER to run any cell or progress from one cell to the next.
Other cells contain code in the Python programming language. Running a code cell will execute all of the code it contains.
Try running this cell:
print("Hello, World!")
When you need to run an entire Jupyter notebook, click on the "Cell" option at the top and then select "Run All". This should execute each cell of the notebook.
# <-- Hash symbol marks a "comment" in Python that would not be executed or printed out.
# Comments are often used to explain the actual code.
Technical Issues¶
If you run a cell and see a NameError message below the cell, you probably forgot to run one of the cells above it. Make sure you run all the cells in order each time you open the notebook. You can do this easily by going to the "Cell" menu at the top and clicking "Run all".
If at the top right side of the notebook you get a flag "Cannot Connect to Kernel", this may have happened due to poor internet connectivity. Try clicking "Kernel" at the top left and selecting either "Restart" or "Restart & Run All".
Still having issues? Come to Data Peer Consulting Office Hours at 3rd Floor Moffitt! Find a Peer Consultant with the expertise you need and get your questions answered: Office Hours Schedule is linked here
Save and Access the Notebook¶
To save your progress in your Jupyter notebook, click on the floppy disk icon at the top left corner or go to the File menu and select "Save and Checkpoint". If you want to come back to this notebook later, use the link provided by your professor or go to https://datahub.berkeley.edu and sign in with your bCourses account.
Part 1: Class Data¶
We can read in the data you submitted through the form by asking Google for the form information and turning it into a table.
# The following two lines read two spreadsheets.
image_data = Table.read_table("data/image_data.csv")
class_data = Table.read_table("data/class_data.csv")
# The following block cleans entries in the "Census Tract" column.
image_data["Census Tract"] = [str(i) for i in image_data["Census Tract"]]
class_data["Census Tract"] = [str(i) for i in class_data["Census Tract"]]
sub = lambda s: re.sub(r"\.[0-9]*", "", s) # Defines a function that removes decimals.
# Applies the function defined above to the "Census Tract" column in both tables.
image_data["Census Tract"] = image_data.apply(sub, "Census Tract")
class_data["Census Tract"] = class_data.apply(sub, "Census Tract")
image_data.show(5)
class_data.show(5)
That's a lot of columns! Now that our data is inside the class_data variable, we can ask that varible for some information. We can get a list of the column names with the .labels attribute of the table:
class_data.labels
Let's get some summary statistics and do some plotting.
How many of you reported on which census tracts?
class_data.group("Census Tract").show()
We can use the .plot.barh() method to this to visualize the counts:
class_data.group("Census Tract").barh("Census Tract")
One of the key principles of coding is to recycle the code we have written and reduce repetition.
We can write a short function, bar_chart_column, to plot the counts for any of our columns in the table. All we have to do is select the column label in the dropdown.
# This function takes one argument: COL.
# It then draws a bar chart for this column.
def bar_chart_column(col):
bar_chart_data.group(col).barh(col)
bar_chart_data = class_data.drop("What kinds of establishments are there on the block face? Select all that apply.")
# Interative widget. Feel free to choose any column
# in the dropdown menu.
dropdown = widgets.Dropdown(options=bar_chart_data.labels[1:], description="Column")
display(widgets.interactive(bar_chart_column, col=dropdown))
We can then ask for these columns and plot their means too.
(class_data
.to_df()
.iloc[:,2:] # Keeps all the rows, but keeps only columns that have indices >= 2
.mean() # Takes the mean of each column
.plot # Draws a bar chart.
.barh());
One of the questions had checkbox answers that listed all of the establishments that were observed by each student in their assigned census tract. Let's create a seperate column for each of the possible options. A value of 1 in the column indicates that the estalishment was observed. A value of 0 indicates that the establishment was not observed.
This is called one-hot encoding.
# Extracts responses about establishments.
raw_establishment_responses = class_data.to_df().iloc[:, 12]
# For each response, split it into a list of options selected.
split_establishment_responses = [response.split(", ") for response in raw_establishment_responses
if not pd.isnull(response)]
# The variable above is a list of lists.
# We want to flatten the list.
establishments = pd.Series([item for sublist in split_establishment_responses for item in sublist])
# Now let's do one-hot encoding!
ests_table = Table.empty().with_column("Types of Establishments", class_data["Types of Establishments"])
for establishment in establishments.unique():
establishment_data = []
for row in class_data.rows:
ests = row.item('Types of Establishments')
if not pd.isnull(ests):
row_establishments = ests.split(', ')
if establishment in row_establishments:
establishment_data.append(1)
else:
establishment_data.append(0)
ests_table[establishment] = establishment_data
ests_table.show(5)
# Find the sum of each of the establishments.
col_sums = []
for col in ests_table.drop(0).labels:
col_sums.append(sum(ests_table[col]))
# Put them into a series : index ~ type of establishment, value ~ count
establishment_counts = pd.Series(col_sums, index = ests_table.drop(0).labels)
establishment_counts = establishment_counts.drop("N/A")
establishment_counts.plot.barh()
plt.title(ests_table.labels[0])
plt.show()
Mapping¶
We can also visualize how your responses mapped out over the census tracts. We'll use a library called folium to map your observations onto a map of the census tracts, and include popups with your comments and photos.
alameda = geojson.load(open("data/alameda-2010.geojson"))
myMap = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
map_data(myMap, alameda, image_data).save("maps/map1.html") # remove null row
IFrame('maps/map1.html', width=700, height=400)
Click around census tracts near yours to see if the other students' observations are similar and see if you can eyeball any trends. Check out other areas on the map and see if there are trends for tracts in specific areas.
QUESTION: Do specific characteristics cluster in different areas? Which ones? Which characteristsics seem to cluster together? What types of data do you think will correlate with socioeconomic characteristics like median income, poverty rate, education? Why?
Type your answer here, replacing this text.
Part 2: Our Metrics¶
Now that you have made some predictions, we can compare our data with socioeconomic data from the U.S. Census for the different tracts we visited and see if we can find evidence to support them. From your data, we can create some point scales that measure different aspects of a neighborhood.
For example, we can make a scale called “social disorder” for the first part of your responses. Let's first subeset our data:
#class data is not changed after selection
social_disorder = class_data.select(range(1, 12))
social_disorder.show(5)
Now we'll need to scale the values because all responses were not on the same scale. But for this part, the higher the value the more negative the social disorder was:
social_disorder = scale_values(social_disorder, np.arange(1, 11))
social_disorder.show(5)
Now that our values are scaled, we can take the mean across all observation for a given census tract for a given column, and then take the mean across columns:
#extracting means across columns
means = social_disorder.group("Census Tract", np.mean).drop("Census Tract").values.mean(axis=1)
#assigning Census Tract to their respective means
social_disorder = Table().with_columns(
"Census Tract", np.unique(social_disorder.column("Census Tract")),
"Social Disorder", means
)
social_disorder
Remember, the higher the value the more negative we perceived the census tract to be.
We can do the same for our amenities part:
#adding 2 new columns to Establishments table to create a new table for amenities
#note: the columns are added at the end of the table
amenities = ests_table.with_columns(
"Census Tract", class_data.column("Census Tract"),
"Trees", class_data.column("Amount of Trees Linked the Block Fence (1 (Few) to 3 (Most) scale)")
)
#converting Trees values to binary: 0 if "1 (Few)" and 1 if more
amenities["Trees"] = [(0, 1)[value > 1] for value in amenities["Trees"]]
amenities.show(5)
Certain amenities are positive and indicate desirable conditions in a neighborhood. These characteristics include things like School or Daycares, and supermarkets. Let's create a table containing only positive amenities
#selecting all the necessary columns from amenities table to be included in positive_amenities
positive_amenities = amenities.select(
'Census Tract',
'Banks or credit unions',
'Chain retail stores',
'Community center',
'Eating places/restaurants',
'Fire station',
'Parks',
'Playgrounds',
# 'Public library',
'Post office',
'Professional offices (doctor dentist lawyer accountant real estate)',
'Schools or daycare centers',
'Supermarkets/grocery stores',
'Trees'
)
positive_amenities.show(5)
To make positive amenities comparable between census tracts, we can find the mean of positive amenities for each census tract. A higher value indicates a more positive census tract
#extracting means across columns
means = positive_amenities.group("Census Tract", np.mean).drop("Census Tract").values.mean(axis=1)
#assigning Census Tract to the respective means of positive amenities
positive_amenities = Table().with_columns(
"Census Tract", np.unique(positive_amenities.column("Census Tract")),
"Positive Amenities", means
)
positive_amenities
Certain amenities are negative and indicate undesirable conditions in a neighborhood. These characteristics include things like Bars or Fast Food Restaurants. Let's create a Data Frame with only negative amenities
#selecting all the necessary columns from amenities table to be included in negative_amenities
negative_amenities = amenities.select(
'Census Tract',
'Auto repair/auto body shop',
'Bars and alcoholic beverage services',
'Bodega deli corner-store convenience store',
'Fast food or take-out places',
'Gas station',
'Liquor stores or Marijuana Dispensaries',
'Manufacturing' ,
'Payday lenders check cashers or pawn shops',
'Warehouses'
)
negative_amenities.show(5)
To make negative amenities comparable between census tracts, we can find the mean of negative amenities for each census tract. A higher value indicates a more negative census tract
#extracting means across columns
means = negative_amenities.group("Census Tract", np.mean).drop("Census Tract").values.mean(axis=1)
#assigning Census Tract to the respective means of negative amenities
negative_amenities = Table().with_columns(
"Census Tract", np.unique(negative_amenities.column("Census Tract")),
"Negative Amenities", means
)
negative_amenities
official_data = Table.read_table("data/merged-census.csv")
official_data["Census Tract"] = [str(i) for i in official_data["Census Tract"]]
# sub is the function that removes decimals. We defined this function in Part 1.
official_data["Census Tract"] = official_data.apply(sub, "Census Tract")
official_data
We can add our columns to this table to put it all in one place:
joined_data = (official_data
.join("Census Tract", social_disorder)
.join("Census Tract", positive_amenities)
.join("Census Tract", negative_amenities)
)
joined_data
# Add zeros for all features in tracts for which we did not collect data
unobserved_tracts = [str(alameda["features"][x]['properties']['name10']) for x in range(len(alameda["features"])) \
if alameda["features"][x]['properties']['name10'] not in list(joined_data["Census Tract"])]
unobserved_data = Table().with_column("Census Tract", unobserved_tracts)
for col in joined_data.labels[1:]:
unobserved_data[col] = np.zeros(len(unobserved_tracts))
# Append these rows filled with 0 to the end of the table.
joined_data = joined_data.append(unobserved_data)
joined_data.show(5)
Mapping Exploration¶
Before we quantify the relationship between the census data and our own metrics, let's do some exploratory mapping. We can now add our social disorder and amenities metrics to the popup too!
First we'll map a choropleth of unemployment:
map2 = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
folium.features.Choropleth(geo_data=alameda,
name='unemployment',
data=joined_data.to_df(),
columns=['Census Tract', 'Unemployment %'],
key_on='feature.properties.name10',
fill_color='BuPu',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Unemployment Rate (%)'
).add_to(map2)
folium.LayerControl().add_to(map2)
map2.save("maps/map2.html")
IFrame('maps/map2.html', width=700, height=400)
Household Median Income:
map3 = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
folium.Choropleth(geo_data=alameda,
name='household median income',
data=joined_data.to_df(),
columns=['Census Tract', 'Household Median Income'],
key_on='feature.properties.name10',
fill_color='BuPu',
fill_opacity=0.7,
line_opacity=0.2,
legend_name='Household Median Income'
).add_to(map3)
map3.save("maps/map3.html")
IFrame('maps/map3.html', width=700, height=400)
Bachelor's Degree or higher %:
map4 = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
folium.Choropleth(geo_data=alameda,
name=">= bachelor's %",
data=joined_data.to_df(),
columns=['Census Tract', "Bachelor's Degree or higher %"],
key_on='feature.properties.name10',
fill_color='BuPu',
fill_opacity=0.7,
line_opacity=0.2,
legend_name=">= Bachelors Degree"
).add_to(map4)
map4.save("maps/map4.html")
IFrame('maps/map4.html', width=700, height=400)
Now our "social disorder":
df = joined_data.to_df()
df["Social Disorder"].min()
map5 = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
folium.Choropleth(geo_data=alameda,
name='social disorder',
data=joined_data.to_df(),
columns=['Census Tract', "Social Disorder"],
key_on='feature.properties.name10',
fill_color='BuPu',
fill_opacity=0.7,
line_opacity=0.2,
legend_name="Social Disorder"
).add_to(map5)
map5.save("maps/map5.html")
IFrame('maps/map5.html', width=700, height=400)
Now "Positive Amenities":
map6 = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
folium.Choropleth(geo_data=alameda,
name='positive amenities',
data=joined_data.to_df(),
columns=['Census Tract', "Positive Amenities"],
key_on='feature.properties.name10',
fill_color='BuPu',
fill_opacity=0.7,
line_opacity=0.2,
legend_name="Positive Amenities"
).add_to(map6)
map6.save("maps/map6.html")
IFrame('maps/map6.html', width=700, height=400)
Finally, "Negative Amenities"
map7 = folium.Map(location=(37.8044, -122.2711), zoom_start=11.4)
folium.Choropleth(geo_data=alameda,
name='negative amenities',
data=joined_data.to_df(),
# change the second element with any column you like!
columns=['Census Tract', "Negative Amenities"],
key_on='feature.properties.name10',
fill_color='BuPu',
fill_opacity=0.7,
line_opacity=0.2,
legend_name="Negative Amenities" # also remember to change the legend name
).add_to(map7)
map7.save("maps/map7.html")
IFrame('maps/map7.html', width=700, height=400)
QUESTION: What do you notice?
Type your answer here, replacing this text.
QUESTION: Try copying and pasting one of the mapping cells above and change the column_name variable to a different variable (column in our data) you'd like to map, then run the cell!
Hint: Go to the cell above (map7 cell) and read the comments in the code. You will find how to change the variables plotted!
...
Variable Distributions¶
We can also visualize the distributions of these variables according to census tract with histograms. A histogram will create bins, or ranges, within a variable and then count up the frequency for that bin. If we look at household median income, we may have bins of $10,000, and then we'd count how many tracts fall within that bin:
# only take rows where we have data
valid_data = joined_data.where(joined_data['Unemployment %'] != 0)
# some interactive function
def viz_dist(var_name, tract):
x = valid_data.where(var_name, lambda x: not pd.isna(x))[var_name]
plt.hist(x)
plt.axvline(x=valid_data.where("Census Tract", tract)[var_name], color = "RED")
plt.xlabel(var_name, fontsize=18)
plt.show()
display(widgets.interactive(viz_dist, var_name=list(valid_data.labels[1:]),
tract=list(valid_data["Census Tract"])))
QUESTION: What do these distributions tell you?
Type your answer here, replacing this text.
Part 4: Correlation¶
Let's first analyze income levels. We have sorted the data according to income level. Compare the income levels to the level of social disorder and amenities. Is there a correlation you can spot(as one increases or decreases, does the other do the same)?
(valid_data
.sort("Household Median Income", descending=True)
.select("Household Median Income", "Social Disorder", "Positive Amenities", "Negative Amenities")
).show()
QUESTION: Did you look at the whole table? A common mistake is to assume that since the top 10 results follow or do not follow a pattern, the rest don't. Real life data is often messy and not clean. Does the correlation continue throughout the whole table (a.k.a. as income decreases the points decrease) or is there no pattern? What does this mean about the data?
Type your answer here, replacing this text.
Eyeballing patterns is not the same as a statisical measure of a correlation; you must quantify it with numbers and statistics to prove your thoughts. Looking at the tables is not a very statistical measure of how much a variable correlates to the results. What does it mean for a variable "income" to match 7 out of the top 15 social disorder points? Does this correlate to the rest of the results? How well does it correlate?
The correlation coefficient - r¶
The correlation coefficient ranges from −1 to 1. A value of 1 implies that a linear equation describes the relationship between X and Y perfectly, with all data points lying on a line for which Y increases as X increases. A value of −1 implies that all data points lie on a line for which Y decreases as X increases. A value of 0 implies that there is no linear correlation between the variables. ~Wikipedia
r = 1: the scatter diagram is a perfect straight line sloping upwards
r = -1: the scatter diagram is a perfect straight line sloping downwards.
Let's calculate the correlation coefficient between acceleration and price. We can use the corr method of a DataFrame to generate a correlation matrix of our joined_data:
valid_data.to_df().corr()
You'll notice that the matrix is mirrored with a 1.000000 going down the diagonal. This matrix yields the correlation coefficient for each variable to every other variable in our data.
For example, if we look at the Social Disorder, we see that there is a 0.911115 correlation, implying that there is a strong positive relationship between our constructed social disorder variable and the unemployment rate (i.e., as one goes up the other goes up too).
QUESTION: What else do you notice about the correlation values above?
Type your answere here, replacing this text.
Part 5: Regression¶
We will now use a method called linear regression to make a graph that will show the best fit line that correlates to the data. The slope of the line will show whether it is positively correlated or negatively correlated. The code that we've created so far has helped us establish a relationship between our two variables. Once a relationship has been established, it's time to create a model of the data. To do this we'll find the equation of the regression line!
The regression line is the best fit line for our data. It’s like an average of where all the points line up. In linear regression, the regression line is a perfectly straight line! Below is a picture showing the best fit line.
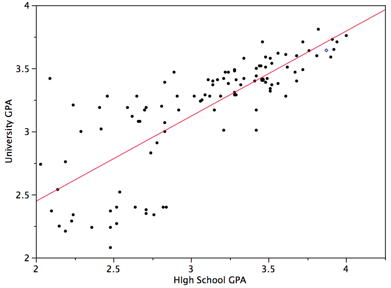
As you can infer from the picture, once we find the slope and the y-intercept we can start predicting values! The equation for the above regression to predict university GPA based on high school GPA would look like this:
$\text{UNIGPA}_i= \alpha + \beta \cdot \text{HSGPA} + \epsilon_i$
The variable we want to predict (or model) is the left side y variable, the variable which we think has an influence on our left side variable is on the right side. The $\alpha$ term is the y-intercept and the $\epsilon_i$ describes the randomness.
We can set up a visualization to choose which variables we want as x and y and then plot the line of best fit:
def f(x_variable, y_variable):
if "median house value" in [x_variable, y_variable]:
# if not all census tracts have values, we drop N/A values and create new table
drop_na = joined_data.to_df().dropna()
#selecting columns from the new table
x = drop_na[x_variable]
y = drop_na[y_variable]
else:
x = joined_data[x_variable]
y = joined_data[y_variable]
#plotting the graph
plt.scatter(x, y)
plt.xlabel(x_variable, fontsize=18)
plt.ylabel(y_variable, fontsize=18)
plt.plot(np.unique(x), np.poly1d(np.polyfit(x, y, 1))(np.unique(x)), color="r") #calculate line of best fit
plt.show()
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y) #gets the r_value
print("R-squared: ", r_value**2)
display(widgets.interactive(f, x_variable=list(valid_data)[1:], y_variable=list(valid_data)[1:]))
*Note:* The R-squared tells us how much of the variation in the data can be explained by our model.
Why is this a better method than just sorting tables? First of all, we are now comparing all of the data in the graph to the variable, rather than comparing what our eyes glance quickly over. It shows a more complete picture than just saying "There are some similar results in the top half of the sorted data". Second of all, the graph gives a more intuitive sense to see if your variable does match the data. You can quickly see if the data points match up with the regression line. Lastly, the r-squared value will give you a way to quantify how good the variable is to explain the data.
One of the beautiful things about computer science and statistics is that you do not need to reinvent the wheel. You don't need to know how to calculate the R-squared value, or draw the regression line; someone has already implemented it! You simply need to tell the computer to calculate it. However, if you are interested in these mathematical models, take a data science or statistics course!
Peer Consulting Office Hours¶
Not quite understand everything covered in this notebook? Curious about concepts covered in this lab at a deeper level? Looking for more data enabled courses with modules like this? Come to Peer Consulting Office Hours at 3rd Floor Moffitt! Find a Peer Consultant with the expertise you need and get your questions answered: Office Hours Schedule is linked here!
We Want Your Feedback!¶
Help us make your module experience better in future courses: *Please fill out our short feedback form!*
Fall 2019 Notebook revised by: Yana Mykhailovska, Timlan Wong, Xiantao Wang
Fall 2018 Notebook developed by: Keeley Takimoto, Anna Nguyen, Taj Shaik, Keiko Kamei
Adapted from Spring 2018 and Fall 2017 materials by: Anna Nguyen, Sujude Dalieh, Michaela Palmer, Gavin Poe, Theodore Tran
Data Science Modules: http://data.berkeley.edu/education/modules