#hide
#default_exp merge
from nbdev.showdoc import show_doc
#export
from nbdev.imports import *
Fix merge conflicts¶
Fix merge conflicts in jupyter notebooks
When working with jupyter notebooks (which are json files behind the scenes) and GitHub, it is very common that a merge conflict (that will add new lines in the notebook source file) will break some notebooks you are working on. This module defines the function fix_conflicts to fix those notebooks for you, and attempt to automatically merge standard conflicts. The remaining ones will be delimited by markdown cells like this:
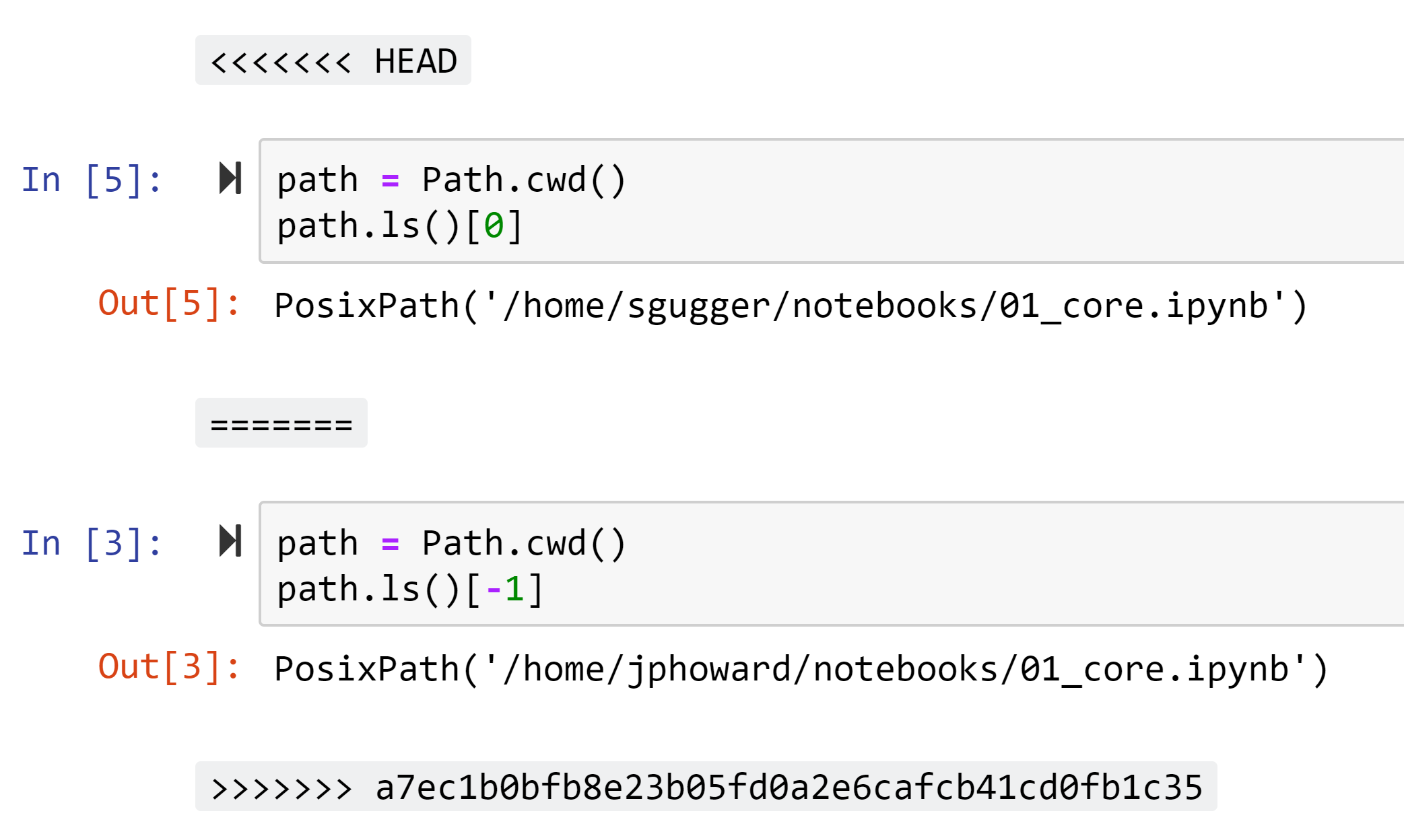
Walk cells¶
#hide
tst_nb="""{
"cells": [
{
"cell_type": "code",
<<<<<<< HEAD
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"z=3\n",
"z"
]
},
{
"cell_type": "code",
"execution_count": 7,
=======
"execution_count": 5,
>>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"6"
]
},
<<<<<<< HEAD
"execution_count": 7,
=======
"execution_count": 5,
>>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"x=3\n",
"y=3\n",
"x+y"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}"""
This is an example of broken notebook we defined in tst_nb. The json format is broken by the lines automatically added by git. Such a file can't be opened again in jupyter notebook, leaving the user with no other choice than to fix the text file manually.
print(tst_nb)
{
"cells": [
{
"cell_type": "code",
<<<<<<< HEAD
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"z=3
",
"z"
]
},
{
"cell_type": "code",
"execution_count": 7,
=======
"execution_count": 5,
>>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"6"
]
},
<<<<<<< HEAD
"execution_count": 7,
=======
"execution_count": 5,
>>>>>>> a7ec1b0bfb8e23b05fd0a2e6cafcb41cd0fb1c35
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"x=3
",
"y=3
",
"x+y"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": []
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3",
"language": "python",
"name": "python3"
}
},
"nbformat": 4,
"nbformat_minor": 2
}
Note that in this example, the second conflict is easily solved: it just concerns the execution count of the second cell and can be solved by choosing either option without really impacting your notebook. This is the kind of conflicts fix_conflicts will (by default) fix automatically. The first conflict is more complicated as it spans across two cells and there is a cell present in one version, not the other. Such a conflict (and generally the ones where the inputs of the cells change form one version to the other) aren't automatically fixed, but fix_conflicts will return a proper json file where the annotations introduced by git will be placed in markdown cells.
The first step to do this is to walk the raw text file to extract the cells. We can't read it as a JSON since it's broken, so we have to parse the text.
#export
def extract_cells(raw_txt):
"Manually extract cells in potential broken json `raw_txt`"
lines = raw_txt.split('\n')
cells = []
i = 0
while not lines[i].startswith(' "cells"'): i+=1
i += 1
start = '\n'.join(lines[:i])
while lines[i] != ' ],':
while lines[i] != ' {': i+=1
j = i
while not lines[j].startswith(' }'): j+=1
c = '\n'.join(lines[i:j+1])
if not c.endswith(','): c = c + ','
cells.append(c)
i = j+1
end = '\n'.join(lines[i:])
return start,cells,end
This function returns the beginning of the text (before the cells are defined), the list of cells and the end of the text (after the cells are defined).
start,cells,end = extract_cells(tst_nb)
test_eq(len(cells), 3)
test_eq(cells[0], """ {
"cell_type": "code",
<<<<<<< HEAD
"execution_count": 6,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"3"
]
},
"execution_count": 6,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"z=3\n",
"z"
]
},""")
#hide
#Test the whole text is there
#We add a , to the last cell (because we might add some after for merge conflicts at the end, so we need to remove it)
test_eq(tst_nb, '\n'.join([start] + cells[:-1] + [cells[-1][:-1]] + [end]))
When walking the broken cells, we will add conflicts marker before and after the cells with conflicts as markdown cells. To do that we use this function.
#export
def get_md_cell(txt):
"A markdown cell with `txt`"
return ''' {
"cell_type": "markdown",
"metadata": {},
"source": [
"''' + txt + '''"
]
},'''
tst = ''' {
"cell_type": "markdown",
"metadata": {},
"source": [
"A bit of markdown"
]
},'''
assert get_md_cell("A bit of markdown") == tst
#export
conflicts = '<<<<<<< ======= >>>>>>>'.split()
#export
def _split_cell(cell, cf, names):
"Split `cell` between `conflicts` given state in `cf`, save `names` of branches if seen"
res1,res2 = [],[]
for line in cell.split('\n'):
if line.startswith(conflicts[cf]):
if names[cf//2] is None: names[cf//2] = line[8:]
cf = (cf+1)%3
continue
if cf<2: res1.append(line)
if cf%2==0: res2.append(line)
return '\n'.join(res1),'\n'.join(res2),cf,names
#hide
tst = '\n'.join(['a', f'{conflicts[0]} HEAD', 'b', conflicts[1], 'c', f'{conflicts[2]} lala', 'd'])
v1,v2,cf,names = _split_cell(tst, 0, [None,None])
assert v1 == 'a\nb\nd'
assert v2 == 'a\nc\nd'
assert cf == 0
assert names == ['HEAD', 'lala']
#hide
tst = '\n'.join(['a', f'{conflicts[0]} HEAD', 'b', conflicts[1], 'c', f'{conflicts[2]} lala', 'd', f'{conflicts[0]} HEAD', 'e'])
v1,v2,cf,names = _split_cell(tst, 0, [None,None])
assert v1 == 'a\nb\nd\ne'
assert v2 == 'a\nc\nd'
assert cf == 1
assert names == ['HEAD', 'lala']
#hide
tst = '\n'.join(['a', f'{conflicts[0]} HEAD', 'b', conflicts[1], 'c', f'{conflicts[2]} lala', 'd', f'{conflicts[0]} HEAD', 'e', conflicts[1]])
v1,v2,cf,names = _split_cell(tst, 0, [None,None])
assert v1 == 'a\nb\nd\ne'
assert v2 == 'a\nc\nd'
assert cf == 2
assert names == ['HEAD', 'lala']
#hide
tst = '\n'.join(['b', conflicts[1], 'c', f'{conflicts[2]} lala', 'd'])
v1,v2,cf,names = _split_cell(tst, 1, ['HEAD',None])
assert v1 == 'b\nd'
assert v2 == 'c\nd'
assert cf == 0
assert names == ['HEAD', 'lala']
#hide
tst = '\n'.join(['c', f'{conflicts[2]} lala', 'd'])
v1,v2,cf,names = _split_cell(tst, 2, ['HEAD',None])
assert v1 == 'd'
assert v2 == 'c\nd'
assert cf == 0
assert names == ['HEAD', 'lala']
#export
_re_conflict = re.compile(r'^<<<<<<<', re.MULTILINE)
#hide
assert _re_conflict.search('a\nb\nc') is None
assert _re_conflict.search('a\n<<<<<<<\nc') is not None
#export
def same_inputs(t1, t2):
"Test if the cells described in `t1` and `t2` have the same inputs"
if len(t1)==0 or len(t2)==0: return False
try:
c1,c2 = json.loads(t1[:-1]),json.loads(t2[:-1])
return c1['source']==c2['source']
except Exception as e: return False
ts = [''' {
"cell_type": "code",
"source": [
"'''+code+'''"
]
},''' for code in ["a=1", "b=1", "a=1"]]
assert same_inputs(ts[0],ts[2])
assert not same_inputs(ts[0], ts[1])
#export
def analyze_cell(cell, cf, names, prev=None, added=False, fast=True, trust_us=True):
"Analyze and solve conflicts in `cell`"
if cf==0 and _re_conflict.search(cell) is None: return cell,cf,names,prev,added
old_cf = cf
v1,v2,cf,names = _split_cell(cell, cf, names)
if fast and same_inputs(v1,v2):
if old_cf==0 and cf==0: return (v2 if trust_us else v1),cf,names,prev,added
v1,v2 = (v2,v2) if trust_us else (v1,v1)
res = []
if old_cf == 0:
added=True
res.append(get_md_cell(f'`{conflicts[0]} {names[0]}`'))
res.append(v1)
if cf ==0:
res.append(get_md_cell(f'`{conflicts[1]}`'))
if prev is not None: res += prev
res.append(v2)
res.append(get_md_cell(f'`{conflicts[2]} {names[1]}`'))
prev = None
else: prev = [v2] if prev is None else prev + [v2]
return '\n'.join([r for r in res if len(r) > 0]),cf,names,prev,added
This is the main function used to walk through the cells of a notebook. cell is the cell we're at, cf the conflict state: 0 if we're not in any conflict, 1 if we are inside the first part of a conflict (between <<<<<<< and =======) and 2 for the second part of a conflict. names contains the names of the branches (they start at [None,None] and get updated as we pass along conflicts). prev contains a copy of what should be included at the start of the second version (if cf=1 or cf=2). added starts at False and keeps track of whether we added any markdown cells (this flag allows us to know if a fast merge didn't leave any conflicts at the end). fast and trust_us are passed along by fix_conflicts: if fast is True, we don't point out conflict between cells if the inputs in the two versions are the same. Instead we merge using the local or remote branch, depending on trust_us.
The function then returns the updated text (with one or several cells, depending on the conflicts to solve), the updated cf, names, prev and added.
tst = '\n'.join(['a', f'{conflicts[0]} HEAD', 'b', conflicts[1], 'c'])
c,cf,names,prev,added = analyze_cell(tst, 0, [None,None], None, False,fast=False)
test_eq(c, get_md_cell('`<<<<<<< HEAD`')+'\na\nb')
test_eq(cf, 2)
test_eq(names, ['HEAD', None])
test_eq(prev, ['a\nc'])
test_eq(added, True)
Here in this example, we were entering cell tst with no conflict state. At the end of the cells, we are still in the second part of the conflict, hence cf=2. The result returns a marker for the branch head, then the whole cell in version 1 (a + b). We save a (prior to the conflict hence common to the two versions) and c (only in version 2) for the next cell in prev (that should contain the resolution of this conflict).
Main function¶
#export
def fix_conflicts(fname, fast=True, trust_us=True):
"Fix broken notebook in `fname`"
fname=Path(fname)
shutil.copy(fname, fname.with_suffix('.ipynb.bak'))
with open(fname, 'r') as f: raw_text = f.read()
start,cells,end = extract_cells(raw_text)
res = [start]
cf,names,prev,added = 0,[None,None],None,False
for cell in cells:
c,cf,names,prev,added = analyze_cell(cell, cf, names, prev, added, fast=fast, trust_us=trust_us)
res.append(c)
if res[-1].endswith(','): res[-1] = res[-1][:-1]
with open(f'{fname}', 'w') as f: f.write('\n'.join([r for r in res+[end] if len(r) > 0]))
if fast and not added: print("Succesfully merged conflicts!")
else: print("One or more conflict remains in the notebook, please inspect manually.")
The function will begin by backing the notebook fname to fname.bak in case something goes wrong. Then it parses the broken json, solving conflicts in cells. If fast=True, every conflict that only involves metadata or outputs of cells will be solved automatically by using the local (trust_us=True) or the remote (trust_us=False) branch. Otherwise, or for conflicts involving the inputs of cells, the json will be repaired by including the two version of the conflicted cell(s) with markdown cells indicating the conflicts. You will be able to open the notebook again and search for the conflicts (look for <<<<<<<) then fix them as you wish.
If fast=True, the function will print a message indicating whether the notebook was fully merged or if conflicts remain.
Export-¶
#hide
from nbdev.export import notebook2script
notebook2script()
Converted 00_export.ipynb. Converted 01_sync.ipynb. Converted 02_showdoc.ipynb. Converted 03_export2html.ipynb. Converted 04_test.ipynb. Converted 05_merge.ipynb. Converted 06_cli.ipynb. Converted 07_clean.ipynb. Converted 99_search.ipynb. Converted index.ipynb. Converted tutorial.ipynb.