Feathr Feature Store For Customer360 on Azure - Demo Notebook¶
This notebook illustrates the use of Feathr Feature Store to create one of the use case for Customer 360. This usecase predicts Sales amount by the Discount offered. It includes following steps:
- Install and set up Feathr with Azure
- Create shareable features with Feathr feature definition configs.
- Create a training dataset via point-in-time feature join.
- Compute and write features.
- Train a model using these features to predict Sales Amount.
- Materialize feature value to online store.
- Fetch feature value in real-time from online store for online scoring.
The feature flow is as follows:

Prerequisite: Provision cloud resources¶
First step is to provision required cloud resources if you want to use Feathr. Feathr provides a python based client to interact with cloud resources.
Please follow the steps here to provision required cloud resources. Due to the complexity of the possible cloud environment, it is almost impossible to create a script that works for all the use cases. Because of this, azure_resource_provision.sh is a full end to end command line to create all the required resources, and you can tailor the script as needed, while the companion documentation can be used as a complete guide for using that shell script.
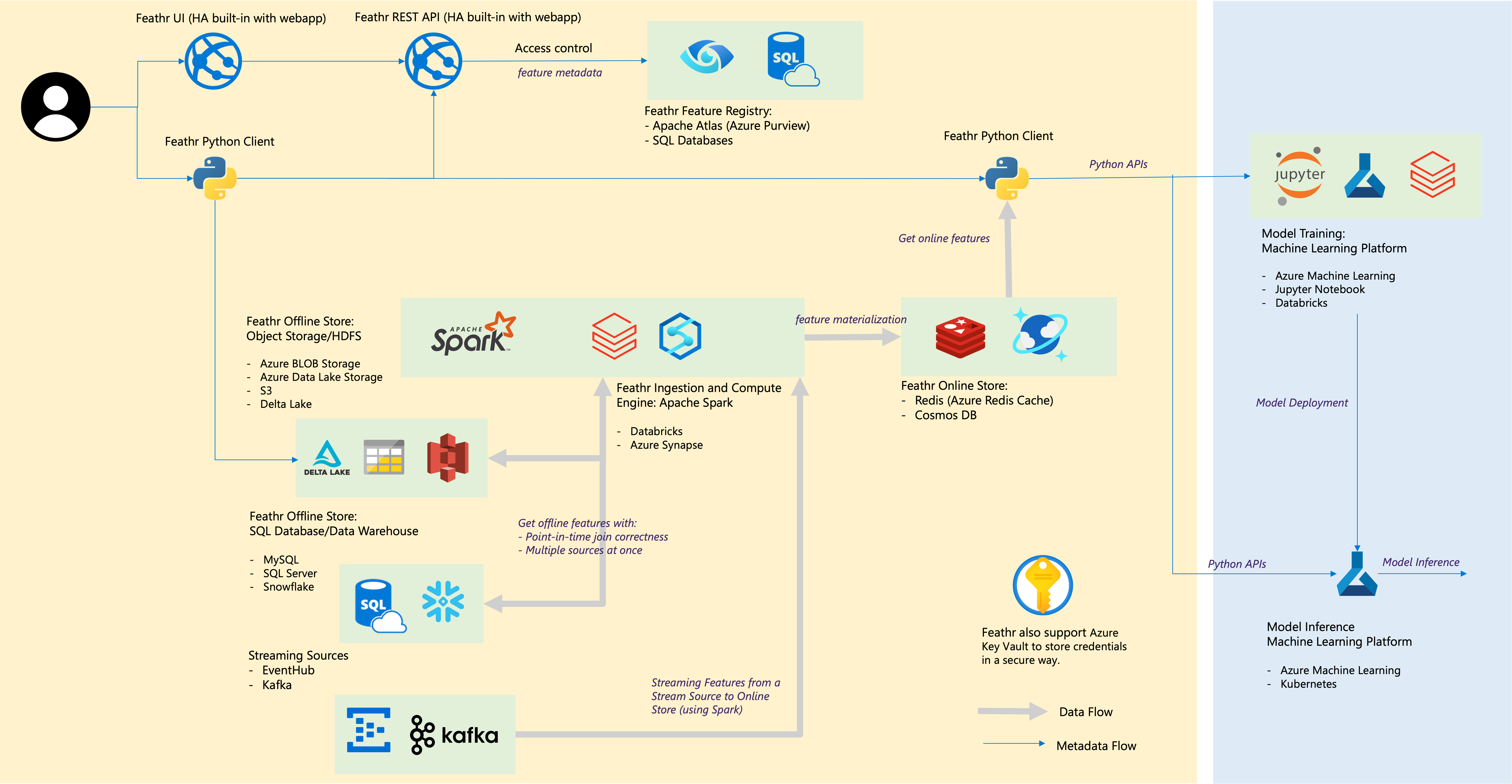
And the architecture is as below:
key = "blobstorekey"
acnt = "studiofeathrazuredevsto"
container = "studio-feathrazure-dev-fs"
mntpnt = "/mnt/studio-feathrazure-dev-fs"
def mountStorageContainer(storageAccount, storageAccountKey, storageContainer, blobMountPoint):
try:
print("Mounting {0} to {1}:".format(storageContainer, blobMountPoint))
dbutils.fs.unmount(blobMountPoint)
except Exception as e:
print("....Container is not mounted; Attempting mounting now..")
mountStatus = dbutils.fs.mount(source = "wasbs://{0}@{1}.blob.core.windows.net/".format(storageContainer, storageAccount),
mount_point = blobMountPoint,
extra_configs = {"fs.azure.account.key.{0}.blob.core.windows.net".format(storageAccount): storageAccountKey})
print("....Status of mount is: " + str(mountStatus))
print()
mountStorageContainer(acnt,key,container,mntpnt)
df = spark.read.format("csv").option("header", "true").load("/mnt/studio-feathrazure-dev-fs/data/customer360.csv")
display(df)
Prerequisite: Install Feathr¶
Install Feathr using pip:
%pip install --force-reinstall git+https://github.com/feathr-ai/feathr.git@registry_fix#subdirectory=feathr_project pandavro scikit-learn
Prerequisite: Configure the required environment¶
In the first step (Provision cloud resources), you should have provisioned all the required cloud resources. If you use Feathr CLI to create a workspace, you should have a folder with a file called feathr_config.yaml in it with all the required configurations. Otherwise, update the configuration below.
The code below will write this configuration string to a temporary location and load it to Feathr. Please still refer to feathr_config.yaml and use that as the source of truth. It should also have more explanations on the meaning of each variable.
import tempfile
yaml_config = """
api_version: 1
project_config:
project_name: 'customer360'
required_environment_variables:
- 'REDIS_PASSWORD'
- 'ADLS_ACCOUNT'
- 'ADLS_KEY'
- 'BLOB_ACCOUNT'
- 'BLOB_KEY'
- 'DATABRICKS_WORKSPACE_TOKEN_VALUE '
offline_store:
adls:
adls_enabled: true
wasb:
wasb_enabled: true
s3:
s3_enabled: false
s3_endpoint: 's3.amazonaws.com'
jdbc:
jdbc_enabled: false
jdbc_database: ''
jdbc_table: ''
snowflake:
snowflake_enabled: false
url: "<replace_with_your_snowflake_account>.snowflakecomputing.com"
user: "<replace_with_your_user>"
role: "<replace_with_your_user_role>"
warehouse: "<replace_with_your_warehouse>"
spark_config:
spark_cluster: 'databricks'
spark_result_output_parts: '1'
azure_synapse:
dev_url: 'https://feathrazure.dev.azuresynapse.net'
pool_name: 'spark3'
workspace_dir: 'abfss://container@blobaccountname.dfs.core.windows.net/demo_data1/'
executor_size: 'Small'
executor_num: 1
databricks:
workspace_instance_url: "https://<replace_with_your_databricks_host>.azuredatabricks.net/"
workspace_token_value: ""
config_template: '{"run_name":"","new_cluster":{"spark_version":"9.1.x-scala2.12","node_type_id":"Standard_D3_v2","num_workers":2,"spark_conf":{}},"libraries":[{"jar":""}],"spark_jar_task":{"main_class_name":"","parameters":[""]}}'
work_dir: 'dbfs:/customer360'
online_store:
redis:
host: '<replace_with_your_redis>.redis.cache.windows.net'
port: 6380
ssl_enabled: True
feature_registry:
api_endpoint: "https://<replace_with_your_api_endpoint>.azurewebsites.net/api/v1"
"""
# write this configuration string to a temporary location and load it to Feathr
tmp = tempfile.NamedTemporaryFile(mode='w', delete=False)
with open(tmp.name, "w") as text_file:
text_file.write(yaml_config)
Import necessary libraries¶
import glob
import os
import tempfile
from datetime import datetime, timedelta
from math import sqrt
import pandas as pd
import pandavro as pdx
from feathr import FeathrClient
from feathr import BOOLEAN, FLOAT, INT32, ValueType,STRING
from feathr import Feature, DerivedFeature, FeatureAnchor
from feathr import FeatureAnchor
from feathr.client import FeathrClient
from feathr import DerivedFeature
from feathr import BackfillTime, MaterializationSettings
from feathr import FeatureQuery, ObservationSettings
from feathr import RedisSink
from feathr import INPUT_CONTEXT, HdfsSource
from feathr import WindowAggTransformation
from feathr import TypedKey
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
Setup necessary environment variables¶
You have to setup the environment variables in order to run this sample. More environment variables can be set by referring to feathr_config.yaml and use that as the source of truth. It should also have more explanations on the meaning of each variable.
import os
os.environ['REDIS_PASSWORD'] = ''
os.environ['ADLS_ACCOUNT'] = ''
os.environ['ADLS_KEY'] = ''
os.environ['BLOB_ACCOUNT'] = ""
os.environ['BLOB_KEY'] = ''
os.environ['DATABRICKS_WORKSPACE_TOKEN_VALUE'] = ''
Initialize a feathr client¶
client = FeathrClient(config_path=tmp.name)
Define Sources Section¶
A feature source is needed for anchored features that describes the raw data in which the feature values are computed from. See the python documentation to get the details on each input column.
batch_source = HdfsSource(name="cosmos_final_data",
path="abfss://container@blobaccountname.dfs.core.windows.net/data/customer360.csv",
event_timestamp_column="sales_order_dt",
timestamp_format="yyyy-MM-dd")
Defining Features with Feathr:¶
In Feathr, a feature is viewed as a function, mapping from entity id or key, and timestamp to a feature value.
Define Anchors and Features¶
A feature is called an anchored feature when the feature is directly extracted from the source data, rather than computed on top of other features.
f_sales_cust_id = Feature(name = "f_sales_cust_id",
feature_type = STRING, transform = "sales_cust_id" )
f_sales_tran_id = Feature(name = "f_sales_tran_id",
feature_type = STRING, transform = "sales_tran_id" )
f_sales_order_id = Feature(name = "f_sales_order_id",
feature_type = STRING, transform = "sales_order_id" )
f_sales_item_quantity = Feature(name = "f_sales_item_quantity",
feature_type = INT32, transform = "cast_float(sales_item_quantity)" )
f_sales_order_dt = Feature(name = "f_sales_order_dt",
feature_type = STRING, transform = "sales_order_dt" )
f_sales_sell_price = Feature(name = "f_sales_sell_price",
feature_type = INT32, transform = "cast_float(sales_sell_price)" )
f_sales_discount_amt = Feature(name = "f_sales_discount_amt",
feature_type = INT32, transform = "cast_float(sales_discount_amt)" )
f_payment_preference = Feature(name = "f_payment_preference",
feature_type = STRING, transform = "payment_preference" )
features = [f_sales_cust_id, f_sales_tran_id, f_sales_order_id, f_sales_item_quantity,
f_sales_order_dt, f_sales_sell_price, f_sales_discount_amt, f_payment_preference]
request_anchor = FeatureAnchor(name="request_features",
source=INPUT_CONTEXT,
features=features)
Define Derived Features¶
Derived features are the features that are computed from other features. They could be computed from anchored features, or other derived features.
f_total_sales_amount = DerivedFeature(name = "f_total_sales_amount",
feature_type = FLOAT,
input_features = [f_sales_item_quantity,f_sales_sell_price],
transform = "f_sales_item_quantity * f_sales_sell_price")
f_total_sales_discount= DerivedFeature(name = "f_total_sales_discount",
feature_type = FLOAT,
input_features = [f_sales_item_quantity,f_sales_discount_amt],
transform = "f_sales_item_quantity * f_sales_discount_amt")
f_total_amount_paid= DerivedFeature(name = "f_total_amount_paid",
feature_type = FLOAT,
input_features = [f_sales_sell_price,f_sales_discount_amt],
transform ="f_sales_sell_price - f_sales_discount_amt")
Define Aggregate features and anchor the features to batch source.¶
Note that if the data source is from the observation data, the source section should be INPUT_CONTEXT to indicate the source of those defined anchors.
customer_ID = TypedKey(key_column="sales_cust_id",
key_column_type=ValueType.INT32,
description="customer ID",
full_name="cosmos.sales_cust_id")
agg_features = [Feature(name="f_avg_customer_sales_amount",
key=customer_ID,
feature_type=FLOAT,
transform=WindowAggTransformation(agg_expr="cast_float(sales_sell_price)",
agg_func="AVG",
window="1d")),
Feature(name="f_avg_customer_discount_amount",
key=customer_ID,
feature_type=FLOAT,
transform=WindowAggTransformation(agg_expr="cast_float(sales_discount_amt)",
agg_func="AVG",
window="1d")),
Feature(name="f_avg_item_ordered_by_customer",
key=customer_ID,
feature_type=FLOAT,
transform=WindowAggTransformation(agg_expr="cast_float(sales_item_quantity)",
agg_func="AVG",
window="1d"))]
agg_anchor = FeatureAnchor(name="aggregationFeatures",
source=batch_source,
features=agg_features)
Building Features¶
And then we need to build those features so that it can be consumed later. Note that we have to build both the "anchor" and the "derived" features (which is not anchored to a source).
client.build_features(anchor_list=[request_anchor,agg_anchor], derived_feature_list=[f_total_sales_amount, f_total_sales_discount,f_total_amount_paid])
Registering Features¶
We can also register the features with an Apache Atlas compatible service, such as Azure Purview, and share the registered features across teams:
client.register_features()
client.list_registered_features(project_name="customer360")
Create training data using point-in-time correct feature join¶
A training dataset usually contains entity id columns, multiple feature columns, event timestamp column and label/target column.
To create a training dataset using Feathr, one needs to provide a feature join configuration file to specify what features and how these features should be joined to the observation data.
feature_query = FeatureQuery(
feature_list=["f_avg_item_ordered_by_customer","f_avg_customer_discount_amount","f_avg_customer_sales_amount","f_total_sales_discount"], key=customer_ID)
settings = ObservationSettings(
observation_path="abfss://container@blobaccountname.dfs.core.windows.net/data/customer360.csv",
event_timestamp_column="sales_order_dt",
timestamp_format="yyyy-MM-dd")
Materialize feature value into offline storage¶
While Feathr can compute the feature value from the feature definition on-the-fly at request time, it can also pre-compute and materialize the feature value to offline and/or online storage.
client.get_offline_features(observation_settings=settings,
feature_query=feature_query,
output_path="abfss://container@blobaccountname.dfs.core.windows.net/data/output/output.avro")
client.wait_job_to_finish(timeout_sec=500)
Reading training data from offline storage¶
path = '/mnt/studio-feathrazure-dev-fs/cosmos/output/output'
df= spark.read.format("avro").load(path)
df = df.toPandas()
display(df)
Train a ML model¶
After getting all the features, let's train a machine learning model with the converted feature by Feathr:
X = df['f_total_sales_discount']
y = df['f_total_sales_amount']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size = 0.7, test_size = 0.3, random_state = 100)
# Add a constant to get an intercept
X_train_sm = sm.add_constant(X_train)
# Fit the resgression line using 'OLS'
lr = sm.OLS(y_train, X_train_sm).fit()
# Add a constant to X_test
X_test_sm = sm.add_constant(X_test)
# Predict the y values corresponding to X_test_sm
y_pred = lr.predict(X_test_sm)
# Checking the R-squared on the test set
r_squared = r2_score(y_test, y_pred)
r_squared
print("Model MAPE:")
print(1 - r_squared)
print()
print("Model Accuracy:")
print(r_squared)
Materialize feature value into online storage¶
We can push the generated features to the online store like below
redisSink = RedisSink(table_name="Customer360")
settings = MaterializationSettings("cosmos_feathr_table",
sinks=[redisSink],
feature_names=["f_avg_item_ordered_by_customer","f_avg_customer_discount_amount"])
client.materialize_features(settings, allow_materialize_non_agg_feature =True)
client.wait_job_to_finish(timeout_sec=500)
Fetching feature value for online inference¶
For features that are already materialized by the previous step, their latest value can be queried via the client's get_online_features or multi_get_online_features API.
client.get_online_features(feature_table = "Customer360",
key = "KB-16240",
feature_names = ['f_avg_item_ordered_by_customer'])