Product Recommendation with Feathr¶
This notebook illustrates the use of Feathr Feature Store to create a model that predict users' rating for different products for a e-commerce website.
Model Problem Statement¶
The e-commerce website has collected past user ratings for various products. The website also collected data about user and product, like user age, product category etc. Now we want to predict users' product rating for new product so that we can recommend the new product to users that give a high rating for those products.
Feature Creation Illustration¶
In this example, our observation data has compound entity key where a record is uniquely identified by user_id and product_id. With that, we can think about three types of features:
- User features that are different for different users but are the same for different products. For example, user age is different for different users but it's product-agnostic.
- Product features that are different for different products but are the same for all the users.
- User-to-product features that are different for different users AND different products. For example, a feature to represent if the user has bought this product before or not.
In this example, we will focus on the first two types of features. After we train a model based on those features, we predict the product ratings that users will give for the products.
The feature creation flow is as below:
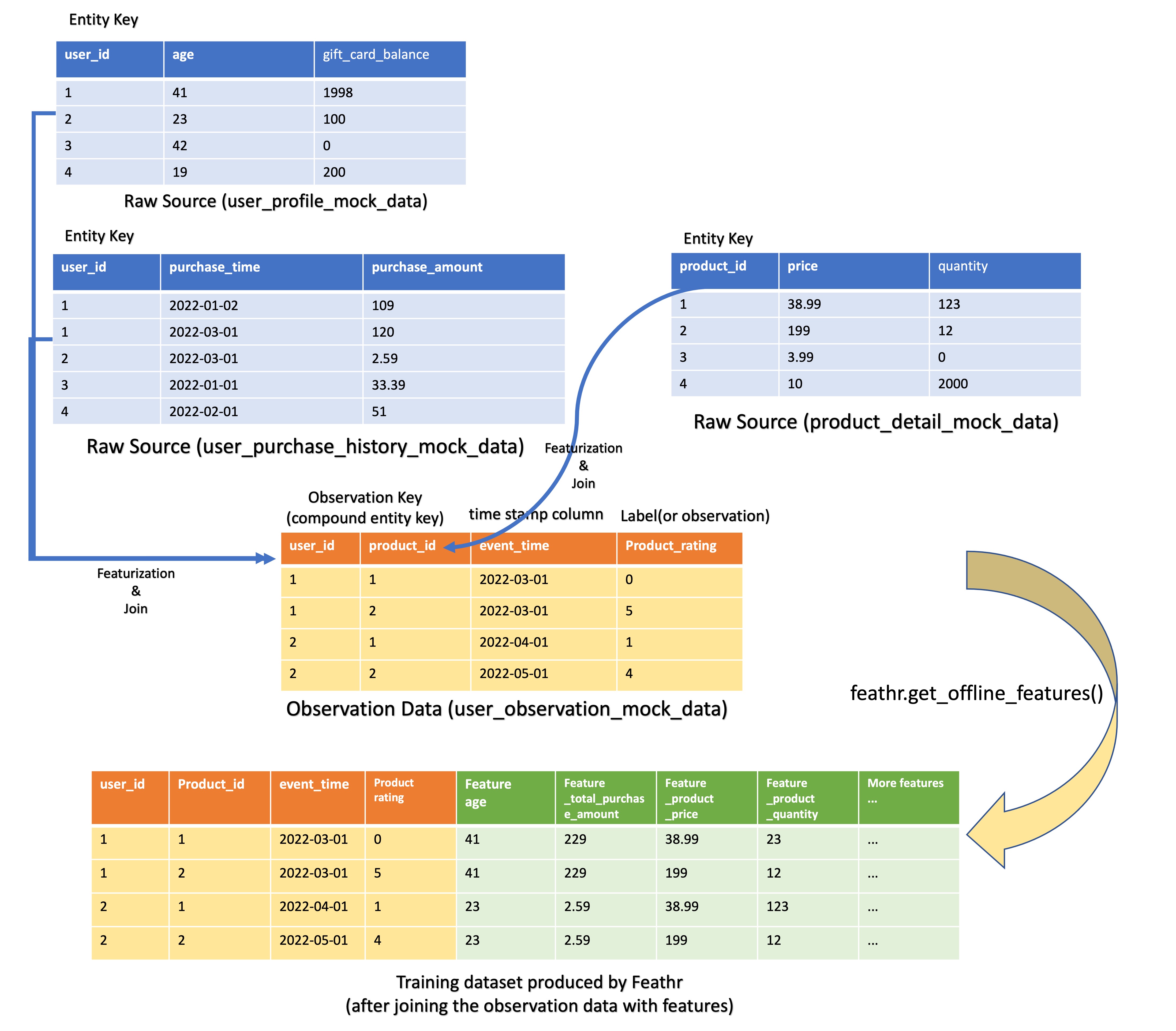
2. Config Feathr Client¶
import glob
import os
import tempfile
from datetime import datetime, timedelta
from math import sqrt
import pandas as pd
from pyspark.sql import DataFrame
from interpret.provider import InlineProvider
from interpret import set_visualize_provider
set_visualize_provider(InlineProvider())
import feathr
from feathr import (
FeathrClient,
BOOLEAN, FLOAT, INT32, ValueType,
Feature, DerivedFeature, FeatureAnchor,
BackfillTime, MaterializationSettings,
FeatureQuery, ObservationSettings,
RedisSink,
INPUT_CONTEXT, HdfsSource,
WindowAggTransformation,
TypedKey,
)
from feathr.datasets.constants import (
PRODUCT_RECOMMENDATION_USER_OBSERVATION_URL,
PRODUCT_RECOMMENDATION_USER_PROFILE_URL,
PRODUCT_RECOMMENDATION_USER_PURCHASE_HISTORY_URL,
PRODUCT_RECOMMENDATION_PRODUCT_DETAIL_URL,
)
from feathr.datasets.utils import maybe_download
from feathr.utils.config import generate_config
from feathr.utils.job_utils import get_result_df
print(f"Feathr version: {feathr.__version__}")
from pathlib import Path
os.environ['SPARK_LOCAL_IP'] = "127.0.0.1"
os.environ['REDIS_PASSWORD'] = "foobared"
PROJECT_NAME = "product_recommendation"
import glob
jar_name = glob.glob("./*.jar")[0]
print(f"Found jar file at {jar_name}")
yaml_config = f"""
api_version: 1
project_config:
project_name: {PROJECT_NAME}
spark_config:
# choice for spark runtime. Currently support: azure_synapse, databricks, local
spark_cluster: 'local'
spark_result_output_parts: '1'
local:
master: 'local[*]'
feathr_runtime_location: "{jar_name}"
online_store:
redis:
# Redis configs to access Redis cluster
host: '127.0.0.1'
port: 6379
ssl_enabled: False
feature_registry:
# The API endpoint of the registry service
api_endpoint: "http://127.0.0.1:8000/api/v1"
"""
feathr_workspace_folder = Path("./feathr_config.yaml")
feathr_workspace_folder.parent.mkdir(exist_ok=True, parents=True)
feathr_workspace_folder.write_text(yaml_config)
Initialize Feathr Client¶
client = FeathrClient(str(feathr_workspace_folder))
3. Prepare Datasets¶
# Download datasets
WORKING_DIR = PROJECT_NAME
user_observation_file_path = f"{WORKING_DIR}/user_observation.csv"
user_profile_file_path = f"{WORKING_DIR}/user_profile.csv"
user_purchase_history_file_path = f"{WORKING_DIR}/user_purchase_history.csv"
product_detail_file_path = f"{WORKING_DIR}/product_detail.csv"
maybe_download(
src_url=PRODUCT_RECOMMENDATION_USER_OBSERVATION_URL,
dst_filepath=user_observation_file_path,
)
maybe_download(
src_url=PRODUCT_RECOMMENDATION_USER_PROFILE_URL,
dst_filepath=user_profile_file_path,
)
maybe_download(
src_url=PRODUCT_RECOMMENDATION_USER_PURCHASE_HISTORY_URL,
dst_filepath=user_purchase_history_file_path,
)
maybe_download(
src_url=PRODUCT_RECOMMENDATION_PRODUCT_DETAIL_URL,
dst_filepath=product_detail_file_path,
)
# In local mode, we can use the same data path as the source.
user_observation_source_path = user_observation_file_path
user_profile_source_path = user_profile_file_path
user_purchase_history_source_path = user_purchase_history_file_path
product_detail_source_path = product_detail_file_path
# Observation dataset
# Observation dataset usually comes with a event_timestamp to denote when the observation happened.
# The label here is product_rating. Our model objective is to predict a user's rating for this product.
pd.read_csv(user_observation_file_path).head()
# User profile dataset
# Used to generate user features
pd.read_csv(user_profile_file_path).head()
# User purchase history dataset.
# Used to generate user features. This is activity type data, so we need to use aggregation to generate features.
pd.read_csv(user_purchase_history_file_path).head()
# Product detail dataset.
# Used to generate product features.
pd.read_csv(product_detail_file_path).head()
What's a feature in Feathr¶
A feature is an individual measurable property or characteristic of a phenomenon which is sometimes time-sensitive.
In Feathr, a feature is defined by the following characteristics:
- The typed key (a.k.a. entity id): identifies the subject of feature, e.g. a user id of 123, a product id of SKU234456.
- The feature name: the unique identifier of the feature, e.g. user_age, total_spending_in_30_days.
- The feature value: the actual value of that aspect at a particular time, e.g. the feature value of the person's age is 30 at year 2022.
- The timestamp: this indicates when the event happened. For example, the user purchased certain product on a certain timestamp. This is usually used for point-in-time join.
You can feel that this is defined from a feature consumer (a person who wants to use a feature) perspective. It only tells us what a feature is like. In later sections, you can see how a feature consumer can access the features in a very simple way.
To define how to produce the feature, we need to specify:
- Feature source: what source data that this feature is based on
- Transformation: what transformation is used to transform the source data into feature. Transformation can be optional when you just want to take a column out from the source data.
(For more details on feature definition, please refer to the Feathr Feature Definition Guide.)
Note: in some cases, such as features defined on top of request data, may have no entity key or timestamp. It is merely a function/transformation executing against request data at runtime. For example, the day of week of the request, which is calculated by converting the request UNIX timestamp. (We won't cover this in the tutorial.)
Define Sources Section with UDFs¶
A feature is called an anchored feature when the feature is directly extracted from the source data, rather than computed on top of other features. The latter case is called derived feature.
A feature source is needed for anchored features that describes the raw data in which the feature values are computed from. See the python documentation to get the details on each input column.
See the python API documentation to get the details of each input fields.
def feathr_udf_preprocessing(df: DataFrame) -> DataFrame:
from pyspark.sql.functions import col
return df.withColumn("tax_rate_decimal", col("tax_rate") / 100)
batch_source = HdfsSource(
name="userProfileData",
path=user_profile_source_path,
preprocessing=feathr_udf_preprocessing,
)
# Let's define some features for users so our recommendation can be customized for users.
user_id = TypedKey(
key_column="user_id",
key_column_type=ValueType.INT32,
description="user id",
full_name="product_recommendation.user_id",
)
feature_user_age = Feature(
name="feature_user_age",
key=user_id,
feature_type=INT32,
transform="age",
)
feature_user_tax_rate = Feature(
name="feature_user_tax_rate",
key=user_id,
feature_type=FLOAT,
transform="tax_rate_decimal",
)
feature_user_gift_card_balance = Feature(
name="feature_user_gift_card_balance",
key=user_id,
feature_type=FLOAT,
transform="gift_card_balance",
)
feature_user_has_valid_credit_card = Feature(
name="feature_user_has_valid_credit_card",
key=user_id,
feature_type=BOOLEAN,
transform="number_of_credit_cards > 0",
)
features = [
feature_user_age,
feature_user_tax_rate,
feature_user_gift_card_balance,
feature_user_has_valid_credit_card,
]
user_feature_anchor = FeatureAnchor(
name="anchored_features", source=batch_source, features=features
)
# Let's define some features for the products so our recommendation can be customized for products.
product_batch_source = HdfsSource(
name="productProfileData",
path=product_detail_source_path,
)
product_id = TypedKey(
key_column="product_id",
key_column_type=ValueType.INT32,
description="product id",
full_name="product_recommendation.product_id",
)
feature_product_quantity = Feature(
name="feature_product_quantity",
key=product_id,
feature_type=FLOAT,
transform="quantity",
)
feature_product_price = Feature(
name="feature_product_price", key=product_id, feature_type=FLOAT, transform="price"
)
product_features = [feature_product_quantity, feature_product_price]
product_feature_anchor = FeatureAnchor(
name="product_anchored_features",
source=product_batch_source,
features=product_features,
)
Define window aggregation features¶
Window aggregation helps us to create more powerful features by compressing large amount of information. For example, we can compute average purchase amount over the last 90 days from the purchase history to capture user's recent consumption trend.
To create window aggregation features, we define WindowAggTransformation with following arguments:
agg_expr: the field/column you want to aggregate. It can be an ANSI SQL expression, e.g.cast_float(purchase_amount)to caststrtype values tofloat.agg_func: the aggregation function, e.g.AVG. See below table for the full list of supported functions.window: the aggregation window size, e.g.90dto aggregate over the 90 days.
| Aggregation Type | Input Type | Description |
|---|---|---|
SUM, COUNT, MAX, MIN, AVG |
Numeric | Applies the the numerical operation on the numeric inputs. |
MAX_POOLING, MIN_POOLING, AVG_POOLING |
Numeric Vector | Applies the max/min/avg operation on a per entry basis for a given a collection of numbers. |
LATEST |
Any | Returns the latest not-null values from within the defined time window. |
After you have defined features and sources, bring them together to build an anchor:
Note that if the features comes directly from the observation data, the
sourceargument should beINPUT_CONTEXTto indicate the source of the anchor is the observation data.
purchase_history_data = HdfsSource(
name="purchase_history_data",
path=user_purchase_history_source_path,
event_timestamp_column="purchase_date",
timestamp_format="yyyy-MM-dd",
)
agg_features = [
Feature(
name="feature_user_avg_purchase_for_90days",
key=user_id,
feature_type=FLOAT,
transform=WindowAggTransformation(
agg_expr="cast_float(purchase_amount)", agg_func="AVG", window="90d"
),
)
]
user_agg_feature_anchor = FeatureAnchor(
name="aggregationFeatures", source=purchase_history_data, features=agg_features
)
Derived Features Section¶
Derived features are the features that are computed from other features. They could be computed from anchored features or other derived features.
derived_features = [
DerivedFeature(
name="feature_user_purchasing_power",
key=user_id,
feature_type=FLOAT,
input_features=[feature_user_gift_card_balance, feature_user_has_valid_credit_card],
transform="feature_user_gift_card_balance + if(boolean(feature_user_has_valid_credit_card), 100, 0)",
)
]
Build features¶
Lastly, we need to build those features so that it can be consumed later. Note that we have to build both the "anchor" and the "derived" features which is not anchored to a source.
client.build_features(
anchor_list=[user_agg_feature_anchor, user_feature_anchor, product_feature_anchor],
derived_feature_list=derived_features,
)
5. Create Training Data using Point-in-Time Correct Feature join¶
To create a training dataset using Feathr, we need to provide a feature join settings to specify what features and how these features should be joined to the observation data.
Also note that since a FeatureQuery accepts features of the same join key, we define two query objects, one for user_id key and the other one for product_id and pass them together to compute offline features.
To learn more on this topic, please refer to Point-in-time Correctness document.
user_feature_query = FeatureQuery(
feature_list=[feat.name for feat in features + agg_features + derived_features],
key=user_id,
)
product_feature_query = FeatureQuery(
feature_list=[feat.name for feat in product_features],
key=product_id,
)
settings = ObservationSettings(
observation_path=user_observation_source_path,
event_timestamp_column="event_timestamp",
timestamp_format="yyyy-MM-dd",
)
client.get_offline_features(
observation_settings=settings,
feature_query=[user_feature_query, product_feature_query],
output_path=user_profile_source_path.rpartition("/")[0] + f"/product_recommendation_features.avro",
)
client.wait_job_to_finish(timeout_sec=100)
Let's use the helper function get_result_df to download the result and view it:
res_df = get_result_df(client)
res_df.head()
Train a machine learning model¶
After getting all the features, let's train a machine learning model with the converted feature by Feathr. Here, we use EBM (Explainable Boosting Machine) regressor from InterpretML package to visualize the modeling results.
from interpret import show
from interpret.glassbox import ExplainableBoostingRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
# Fill None values with 0
final_df = (
res_df
.drop(["event_timestamp"], axis=1, errors="ignore")
.fillna(0)
)
# Split data into train and test
X_train, X_test, y_train, y_test = train_test_split(
final_df.drop(["product_rating"], axis=1),
final_df["product_rating"].astype("float64"),
test_size=0.2,
random_state=42,
)
ebm = ExplainableBoostingRegressor()
ebm.fit(X_train, y_train)
# show(ebm_global) # Will run on 127.0.0.1/localhost at port 7080
# Note, currently InterpretML's visualization dashboard doesn't work w/ VSCODE notebook viewer
# https://github.com/interpretml/interpret/issues/317
ebm_global = ebm.explain_global()
show(ebm_global)
# Predict and evaluate
y_pred = ebm.predict(X_test)
rmse = sqrt(mean_squared_error(y_test.values.flatten(), y_pred))
print(f"Root mean squared error: {rmse}")
6. Feature Materialization¶
While Feathr can compute the feature value from the feature definition on-the-fly at request time, it can also pre-compute and materialize the feature value to offline and/or online storage.
We can push the generated features to the online store like below:
# Materialize user features
# Note, you can only materialize features of same entity key into one table.
redisSink = RedisSink(table_name="user_features")
settings = MaterializationSettings(
name="user_feature_setting",
sinks=[redisSink],
feature_names=["feature_user_age", "feature_user_gift_card_balance"],
)
client.materialize_features(settings=settings, allow_materialize_non_agg_feature=True)
client.wait_job_to_finish(timeout_sec=100)
We can then get the features from the online store (Redis):
client.get_online_features(
"user_features", "2", ["feature_user_age", "feature_user_gift_card_balance"]
)
client.multi_get_online_features(
"user_features", ["1", "2"], ["feature_user_age", "feature_user_gift_card_balance"]
)
7. Feature Registration¶
We can also register the features and share them across teams:
try:
client.register_features()
except Exception as e:
print(e)
print(client.list_registered_features(project_name=PROJECT_NAME))
You should be able to see the Feathr UI by visiting the website below:
from IPython.display import IFrame
IFrame("http://localhost:8081/projects", 900,500)
8. Chat with Feathr (Experimental, powered by ChatGPT)¶
First, let's setup the API_KEY for ChatGPT. You can find your api key at https://platform.openai.com/account/api-keys.
os.environ['CHATGPT_API_KEY'] = 'YOUR_CHAT_GPT_API_KEY'
Load 'feathr' chat magic
%reload_ext feathr.chat
Start chat!
%feathr "What are the available features"
%feathr "What are the available data sources"
%feathr "Create a feature tax_rate_demical = tax_rate/100"
%feathr "Join feature tax_rate_demical with my observation data in point-in-time manner"
%feathr "Materialize my feature tax_rate_demical"
Cleanup¶
# Cleaning up the output files. CAUTION: this maybe dangerous if you "reused" the project name.
import shutil
shutil.rmtree(WORKING_DIR, ignore_errors=False)