Week 8: Reinforcement Learning for seq2seq¶
This time we'll solve a problem of transribing hebrew words in english, also known as g2p (grapheme2phoneme)
- word (sequence of letters in source language) -> translation (sequence of letters in target language)
Unlike most deep learning practicioners do, we won't only train it to maximize likelihood of correct translation, but also employ reinforcement learning to actually teach it to translate with as few errors as possible.
About the task¶
One notable property of Hebrew is that it's consonant language. That is, there are no wovels in the written language. One could represent wovels with diacritics above consonants, but you don't expect people to do that in everyay life.
Therefore, some hebrew characters will correspond to several english letters and others - to none, so we should use encoder-decoder architecture to figure that out.
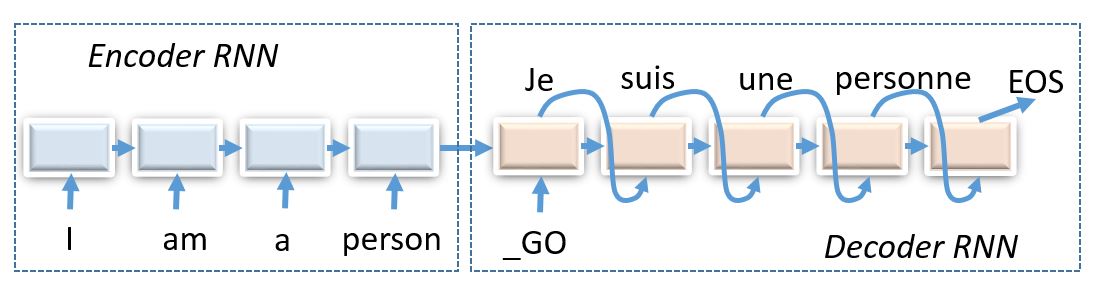 (img: esciencegroup.files.wordpress.com)
(img: esciencegroup.files.wordpress.com)
Encoder-decoder architectures are about converting anything to anything, including
- Machine translation and spoken dialogue systems
- Image captioning and image2latex (convolutional encoder, recurrent decoder)
- Generating images by captions (recurrent encoder, convolutional decoder)
- Grapheme2phoneme - convert words to transcripts
We chose simplified Hebrew->English machine translation for words and short phrases (character-level), as it is relatively quick to train even without a gpu cluster.
EASY_MODE = True #If True, only translates phrases shorter than 20 characters (way easier).
#Useful for initial coding.
#If false, works with all phrases (please switch to this mode for homework assignment)
MODE = "he-to-en" # way we translate. Either "he-to-en" or "en-to-he"
MAX_OUTPUT_LENGTH = 50 if not EASY_MODE else 20 # maximal length of _generated_ output, does not affect training
REPORT_FREQ = 100 # how often to evaluate validation score
Step 1: preprocessing¶
We shall store dataset as a dictionary
{ word1:[translation1,translation2,...], word2:[...],...}.
This is mostly due to the fact that many words have several correct translations.
We have implemented this thing for you so that you can focus on more interesting parts.
Attention python2 users! You may want to cast everything to unicode later during homework phase, just make sure you do it everywhere.
import numpy as np
from collections import defaultdict
word_to_translation = defaultdict(list) #our dictionary
bos = '_'
eos = ';'
with open("main_dataset.txt") as fin:
for line in fin:
en,he = line[:-1].lower().replace(bos,' ').replace(eos,' ').split('\t')
word,trans = (he,en) if MODE=='he-to-en' else (en,he)
if len(word) < 3: continue
if EASY_MODE:
if max(len(word),len(trans))>20:
continue
word_to_translation[word].append(trans)
print ("size = ",len(word_to_translation))
#get all unique lines in source language
all_words = np.array(list(word_to_translation.keys()))
# get all unique lines in translation language
all_translations = np.array([ts for all_ts in word_to_translation.values() for ts in all_ts])
split the dataset¶
We hold out 20% of all words to be used for validation.
from sklearn.model_selection import train_test_split
train_words,test_words = train_test_split(all_words,test_size=0.1,random_state=42)
Building vocabularies¶
We now need to build vocabularies that map strings to token ids and vice versa. We're gonna need these fellas when we feed training data into model or convert output matrices into english words.
from voc import Vocab
inp_voc = Vocab.from_lines(''.join(all_words), bos=bos, eos=eos, sep='')
out_voc = Vocab.from_lines(''.join(all_translations), bos=bos, eos=eos, sep='')
# Here's how you cast lines into ids and backwards.
batch_lines = all_words[:5]
batch_ids = inp_voc.to_matrix(batch_lines)
batch_lines_restored = inp_voc.to_lines(batch_ids)
print("lines")
print(batch_lines)
print("\nwords to ids (0 = bos, 1 = eos):")
print(batch_ids)
print("\nback to words")
print(batch_lines_restored)
Draw word/translation length distributions to estimate the scope of the task.
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=[8,4])
plt.subplot(1,2,1)
plt.title("words")
plt.hist(list(map(len,all_words)),bins=20);
plt.subplot(1,2,2)
plt.title('translations')
plt.hist(list(map(len,all_translations)),bins=20);
Step 3: deploy encoder-decoder (1 point)¶
assignment starts here
Our architecture consists of two main blocks:
- Encoder reads words character by character and outputs code vector (usually a function of last RNN state)
- Decoder takes that code vector and produces translations character by character
Than it gets fed into a model that follows this simple interface:
model(inp, out, **flags) -> logp- takes symbolic int32 matrices of hebrew words and their english translations. Computes the log-probabilities of all possible english characters given english prefices and hebrew word.model.translate(inp, **flags) -> out, logp- takes symbolic int32 matrix of hebrew words, produces output tokens sampled from the model and output log-probabilities for all possible tokens at each tick.
That's all! It's as hard as it gets. With those two methods alone you can implement all kinds of prediction and training.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from basic_model_torch import BasicTranslationModel
model = BasicTranslationModel(inp_voc, out_voc,
emb_size=64, hid_size=256)
# Play around with symbolic_translate and symbolic_score
inp = Variable(torch.LongTensor(np.random.randint(0,10,[3,5])))
out = Variable(torch.LongTensor(np.random.randint(0,10,[3,5])))
# translate inp (with untrained model)
sampled_out, logp = model.translate(inp, greedy=False)
print("Sample translations:\n", sampled_out)
print("Log-probabilities at each step:\n",logp)
# score logp(out | inp) with untrained input
logp = model(inp, out)
print("Symbolic_score output:\n", logp)
print("Log-probabilities of output tokens:\n", torch.gather(logp, dim=2, index=out[:,:,None]))
def translate(lines, max_len=MAX_OUTPUT_LENGTH):
"""
You are given a list of input lines.
Make your neural network translate them.
:return: a list of output lines
"""
# Convert lines to a matrix of indices
lines_ix = inp_voc.to_matrix(lines)
lines_ix = Variable(torch.LongTensor(lines_ix))
# Compute translations in form of indices
trans_ix = <YOUR CODE>
# Convert translations back into strings
return out_voc.to_lines(trans_ix.data.numpy())
print("Sample inputs:",all_words[:3])
print("Dummy translations:",translate(all_words[:3]))
trans = translate(all_words[:3])
assert translate(all_words[:3]) == translate(all_words[:3]), "make sure translation is deterministic (use greedy=True and disable any noise layers)"
assert type(translate(all_words[:3])) is list and (type(translate(all_words[:1])[0]) is str or type(translate(all_words[:1])[0]) is unicode), "translate(lines) must return a sequence of strings!"
# note: if translation freezes, make sure you used max_len parameter
print("Tests passed!")
Scoring function¶
LogLikelihood is a poor estimator of model performance.
- If we predict zero probability once, it shouldn't ruin entire model.
- It is enough to learn just one translation if there are several correct ones.
- What matters is how many mistakes model's gonna make when it translates!
Therefore, we will use minimal Levenshtein distance. It measures how many characters do we need to add/remove/replace from model translation to make it perfect. Alternatively, one could use character-level BLEU/RougeL or other similar metrics.
The catch here is that Levenshtein distance is not differentiable: it isn't even continuous. We can't train our neural network to maximize it by gradient descent.
import editdistance # !pip install editdistance
def get_distance(word,trans):
"""
A function that takes word and predicted translation
and evaluates (Levenshtein's) edit distance to closest correct translation
"""
references = word_to_translation[word]
assert len(references)!=0,"wrong/unknown word"
return min(editdistance.eval(trans,ref) for ref in references)
def score(words, bsize=100):
"""a function that computes levenshtein distance for bsize random samples"""
assert isinstance(words,np.ndarray)
batch_words = np.random.choice(words,size=bsize,replace=False)
batch_trans = translate(batch_words)
distances = list(map(get_distance,batch_words,batch_trans))
return np.array(distances,dtype='float32')
#should be around 5-50 and decrease rapidly after training :)
[score(test_words,10).mean() for _ in range(5)]
Step 2: Supervised pre-training (2 points)¶
Here we define a function that trains our model through maximizing log-likelihood a.k.a. minimizing crossentropy.
import random
def sample_batch(words, word_to_translation, batch_size):
"""
sample random batch of words and random correct translation for each word
example usage:
batch_x,batch_y = sample_batch(train_words, word_to_translations,10)
"""
#choose words
batch_words = np.random.choice(words,size=batch_size)
#choose translations
batch_trans_candidates = list(map(word_to_translation.get, batch_words))
batch_trans = list(map(random.choice, batch_trans_candidates))
return batch_words, batch_trans
bx,by = sample_batch(train_words, word_to_translation, batch_size=3)
print("Source:")
print(bx)
print("Target:")
print(by)
from basic_model_torch import infer_length, infer_mask, to_one_hot
def compute_loss_on_batch(input_sequence, reference_answers):
""" Compute crossentropy loss given a batch of sources and translations """
input_sequence = Variable(torch.LongTensor(inp_voc.to_matrix(input_sequence)))
reference_answers = Variable(torch.LongTensor(out_voc.to_matrix(reference_answers)))
# Compute log-probabilities of all possible tokens at each step. Use model interface.
logprobs_seq = ###YOUR CODE
# compute elementwise crossentropy as negative log-probabilities of reference_answers.
crossentropy = - torch.sum(logprobs_seq * to_one_hot(reference_answers, len(out_voc)), dim = -1)
assert crossentropy.dim() == 2, "please return elementwise crossentropy, don't compute mean just yet"
# average with mask
mask = infer_mask(reference_answers, out_voc.eos_ix)
loss = torch.sum(crossentropy * mask) / torch.sum(mask)
return loss
#test it
loss = compute_loss_on_batch(*sample_batch(train_words, word_to_translation, 3))
print('loss = ', loss)
assert isinstance(loss, Variable) and tuple(loss.data.shape)==(1,)
loss.backward()
for w in model.parameters():
assert w.grad is not None and torch.max(torch.abs(w.grad)).data.numpy()[0] != 0, \
"Loss is not differentiable w.r.t. a weight with shape %s. Check comput_loss_on_batch." % (w.size(),)
Actually train the model¶
Minibatches and stuff...
from IPython.display import clear_output
from tqdm import tqdm, trange #or use tqdm_notebook,tnrange
loss_history = []
editdist_history = []
entropy_history = []
opt = torch.optim.Adam(model.parameters())
for i in trange(25000):
loss = compute_loss_on_batch(*sample_batch(train_words,word_to_translation,32))
#train with backprop
loss.backward()
opt.step()
opt.zero_grad()
loss_history.append(loss.data.numpy()[0])
if (i+1)%REPORT_FREQ==0:
clear_output(True)
current_scores = score(test_words)
editdist_history.append(current_scores.mean())
plt.figure(figsize=(12,4))
plt.subplot(131)
plt.title('train loss / traning time')
plt.plot(loss_history)
plt.grid()
plt.subplot(132)
plt.title('val score distribution')
plt.hist(current_scores, bins = 20)
plt.subplot(133)
plt.title('val score / traning time (lower is better)')
plt.plot(editdist_history)
plt.grid()
plt.show()
print("llh=%.3f, mean score=%.3f"%(np.mean(loss_history[-10:]),np.mean(editdist_history[-10:])))
How to interpret the plots:
- Train loss - that's your model's crossentropy over minibatches. It should go down steadily. Most importantly, it shouldn't be NaN :)
- Val score distribution - distribution of translation edit distance (score) within batch. It should move to the left over time.
- Val score / training time - it's your current mean edit distance. This plot is much whimsier than loss, but make sure it goes below 8 by 2500 steps.
If it doesn't, first try to re-create both model and opt. You may have changed it's weight too much while debugging. If that doesn't help, it's debugging time.
for word in train_words[:10]:
print("%s -> %s"%(word,translate([word])[0]))
test_scores = []
for start_i in trange(0,len(test_words),32):
batch_words = test_words[start_i:start_i+32]
batch_trans = translate(batch_words)
distances = list(map(get_distance,batch_words,batch_trans))
test_scores.extend(distances)
print("Supervised test score:",np.mean(test_scores))
Self-critical policy gradient (2 points)¶
In this section you'll implement algorithm called self-critical sequence training (here's an article).
The algorithm is a vanilla policy gradient with a special baseline.
∇J=Ex∼p(s)Ey∼π(y|x)∇logπ(y|x)⋅(R(x,y)−b(x))Here reward R(x,y) is a negative levenshtein distance (since we minimize it). The baseline b(x) represents how well model fares on word x.
In practice, this means that we compute baseline as a score of greedy translation, b(x)=R(x,ygreedy(x)).
Luckily, we already obtained the required outputs: model.greedy_translations, model.greedy_mask and we only need to compute levenshtein using compute_levenshtein function.
def compute_reward(input_sequence, translations):
""" computes sample-wise reward given token ids for inputs and translations """
distances = list(map(get_distance,
inp_voc.to_lines(input_sequence.data.numpy()),
out_voc.to_lines(translations.data.numpy())))
# use negative levenshtein distance so that larger reward means better policy
return - Variable(torch.FloatTensor(distances))
def scst_objective_on_batch(input_sequence, max_len=MAX_OUTPUT_LENGTH):
""" Compute pseudo-loss for policy gradient given a batch of sources """
input_sequence = Variable(torch.LongTensor(inp_voc.to_matrix(input_sequence)))
# use model to __sample__ symbolic translations given input_sequence
sample_translations, sample_logp = ###YOUR CODE
# use model to __greedy__ symbolic translations given input_sequence
greedy_translations, greedy_logp = ###YOUR CODE
#compute rewards and advantage
rewards = compute_reward(input_sequence, sample_translations)
baseline = <compute __negative__ levenshtein for greedy mode>
# compute advantage using rewards and baseline
advantage = ###YOUR CODE
# compute log_pi(a_t|s_t), shape = [batch, seq_length]
logp_sample = torch.sum(sample_logp * to_one_hot(sample_translations, len(out_voc)), dim=-1)
# policy gradient pseudo-loss. Gradient of J is exactly policy gradient.
J = logp_sample * advantage[:,None]
assert J.dim() == 2, "please return elementwise objective, don't compute mean just yet"
# average with mask
mask = infer_mask(sample_translations, out_voc.eos_ix)
loss = - torch.sum(J * mask) / torch.sum(mask)
# regularize with negative entropy. Don't forget the sign!
# note: for entropy you need probabilities for all tokens (sample_logp), not just logp_sample
entropy = <compute entropy matrix of shape [batch,seq_length], H=-sum(p*log_p), don't forget the sign!>
assert entropy.dim() == 2, "please make sure elementwise entropy is of shape [batch,time]"
reg = - 0.01 * torch.sum(entropy * mask) / torch.sum(mask)
return loss + reg, torch.sum(entropy * mask) / torch.sum(mask)
Policy gradient training¶
entropy_history = [np.nan] * len(loss_history)
opt = torch.optim.Adam(model.parameters(), lr=1e-5)
for i in trange(100000):
loss, ent = scst_objective_on_batch(sample_batch(train_words,word_to_translation,32)[0])
#train with backprop
loss.backward()
opt.step()
opt.zero_grad()
loss_history.append(loss.data.numpy()[0])
entropy_history.append(ent.data.numpy()[0])
if (i+1)%REPORT_FREQ==0:
clear_output(True)
current_scores = score(test_words)
editdist_history.append(current_scores.mean())
plt.figure(figsize=(12,4))
plt.subplot(131)
plt.title('val score distribution')
plt.hist(current_scores, bins = 20)
plt.subplot(132)
plt.title('val score / traning time')
plt.plot(editdist_history)
plt.grid()
plt.subplot(133)
plt.title('policy entropy / traning time')
plt.plot(entropy_history)
plt.grid()
plt.show()
print("J=%.3f, mean score=%.3f"%(np.mean(loss_history[-10:]),np.mean(editdist_history[-10:])))
Debugging tips:

As usual, don't expect improvements right away, but in general the model should be able to show some positive changes by 5k steps.
Entropy is a good indicator of many problems.
- If it reaches zero, you may need greater entropy regularizer.
- If it has rapid changes time to time, you may need gradient clipping.
- If it oscillates up and down in an erratic manner... it's perfectly okay for entropy to do so. But it should decrease at the end.
We don't show loss_history cuz it's uninformative for pseudo-losses in policy gradient. However, if something goes wrong you can check it to see if everything isn't a constant zero.
Results¶
for word in train_words[:10]:
print("%s -> %s"%(word,translate([word])[0]))
test_scores = []
for start_i in trange(0,len(test_words),32):
batch_words = test_words[start_i:start_i+32]
batch_trans = translate(batch_words)
distances = list(map(get_distance,batch_words,batch_trans))
test_scores.extend(distances)
print("Supervised test score:",np.mean(test_scores))
# ^^ If you get Out Of MemoryError, please replace this with batched computation
Step 6: Make it actually work (5++ pts)¶
In this section we want you to finally restart with EASY_MODE=False and experiment to find a good model/curriculum for that task.
We recommend the following architecture
encoder---decoder
P(y|h)
^
LSTM -> LSTM
^ ^
LSTM -> LSTM
^ ^
input y_prev
with both LSTMs having equal or more units than the default gru.
It's okay to modify the code above without copy-pasting it.
Some tips:
You will likely need to adjust pre-training time for such a network.
Supervised pre-training may benefit from clipping gradients somehow.
SCST may indulge a higher learning rate in some cases and changing entropy regularizer over time.
There's more than one way of sending information from encoder to decoder, especially if there's more than one layer:
- Vanilla: layer_i of encoder last state goes to layer_i of decoder initial state
- Intermediate layers: add dense (and possibly concat) layers between encoder last and decoder first.
- Every tick: feed encoder last state on every iteration of decoder.
It's often useful to save pre-trained model parameters to not re-train it every time you want new policy gradient parameters.
When leaving training for nighttime, try setting REPORT_FREQ to a larger value (e.g. 500) not to waste time on it.
(advanced deep learning) It may be a good idea to first train on small phrases and then adapt to larger ones (a.k.a. training curriculum).
(advanced nlp) You may want to switch from raw utf8 to something like unicode or even syllables to make task easier.
(advanced nlp) Since hebrew words are written with vowels omitted, you may want to use a small Hebrew vowel markup dataset at
he-pron-wiktionary.txt.
Formal criteria:
To get 5 points we want you to build an architecture that:
- doesn't consist of single GRU
- works better than single GRU baseline.
- We also want you to provide either learning curve or trained model, preferably both
- ... and write a brief report or experiment log describing what you did and how it fared.
assert not EASY_MODE, "make sure you set EASY_MODE = False at the top of the notebook."
[your report/log here or anywhere you please]
Contributions: This notebook is brought to you by
- Yandex MT team
- Denis Mazur (DeniskaMazur), Oleg Vasilev (Omrigan), Dmitry Emelyanenko (TixFeniks) and Fedor Ratnikov (justheuristic)
- Dataset is parsed from Wiktionary, which is under CC-BY-SA and GFDL licenses.