Constrained K-Means demo - Chicago Weather Dataset¶
H2O K-Means algorithm¶
K-Means falls in the general category of clustering algorithms. Clustering is a form of unsupervised learning that tries to find structures in the data without using any labels or target values. Clustering partitions a set of observations into separate groupings such that observation in a given group is more similar to another observation in the same group than to another observation in a different group.
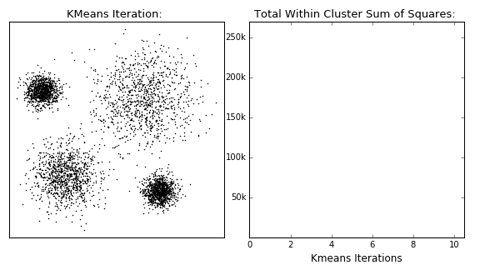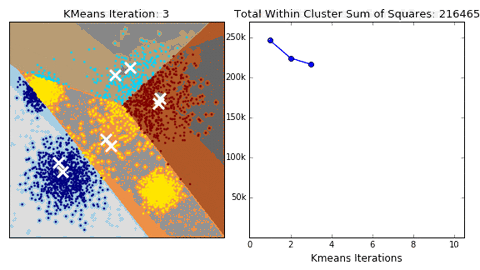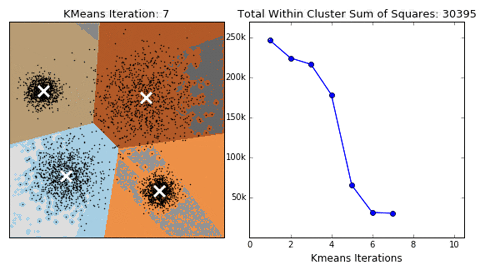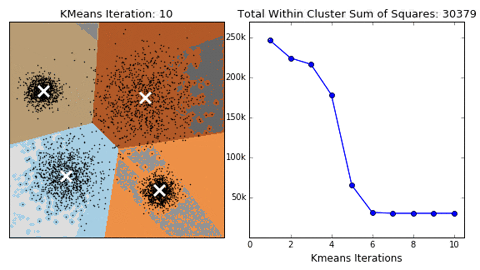
More about H2O K-means Clustering: http://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/k-means.html
Constrained K-Means algorithm in H2O¶
Using the cluster_size_constraints parameter, a user can set the minimum size of each cluster during the training by an array of numbers. The size of the array must be equal as the k parameter.
To satisfy the custom minimal cluster size, the calculation of clusters is converted to the Minimal Cost Flow problem. Instead of using the Lloyd iteration algorithm, a graph is constructed based on the distances and constraints. The goal is to go iteratively through the input edges and create an optimal spanning tree that satisfies the constraints.
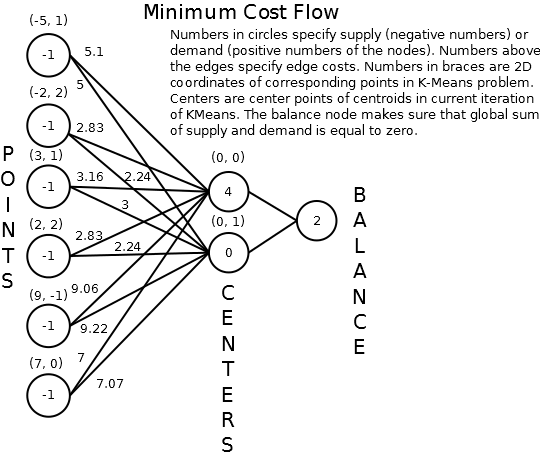
More information about how to convert the standard K-means algorithm to the Minimal Cost Flow problem is described in this paper: https://pdfs.semanticscholar.org/ecad/eb93378d7911c2f7b9bd83a8af55d7fa9e06.pdf.
Minimum-cost flow problem can be efficiently solved in polynomial time. Currently, the performance of this implementation of Constrained K-means algorithm is slow due to many repeatable calculations which cannot be parallelized and more optimized at H2O backend.
Expected time with various sized data:
- 5 000 rows, 5 features ~ 0h 4m 3s
- 10 000 rows, 5 features ~ 0h 9m 21s
- 15 000 rows, 5 features ~ 0h 22m 25s
- 20 000 rows, 5 features ~ 0h 39m 27s
- 25 000 rows, 5 features ~ 1h 06m 8s
- 30 000 rows, 5 features ~ 1h 26m 43s
- 35 000 rows, 5 features ~ 1h 44m 7s
- 40 000 rows, 5 features ~ 2h 13m 31s
- 45 000 rows, 5 features ~ 2h 4m 29s
- 50 000 rows, 5 features ~ 4h 4m 18s
(OS debian 10.0 (x86-64), processor Intel© Core™ i7-7700HQ CPU @ 2.80GHz × 4, RAM 23.1 GiB)
Shorter time using Aggregator Model¶
To solve Constrained K-means in a shorter time, you can used the H2O Aggregator model to aggregate data to smaller size first and then pass these data to the Constrained K-means model to calculate the final centroids to be used with scoring. The results won't be as accurate as a result from a model with the whole dataset. However, it should help solve the problem of a huge datasets.
However, there are some assumptions:
- the large dataset has to consist of many similar data points - if not, the insensitive aggregation can break the structure of the dataset
- the resulting clustering may not meet the initial constraints exactly when scoring (this also applies to Constrained K-means model, scoring use only result centroids to score and no constraints defined before)
The H2O Aggregator method is a clustering-based method for reducing a numerical/categorical dataset into a dataset with fewer rows. Aggregator maintains outliers as outliers but lumps together dense clusters into exemplars with an attached count column showing the member points.
More about H2O Aggregator: http://docs.h2o.ai/h2o/latest-stable/h2o-docs/data-science/aggregator.html
# run h2o Kmeans
# Import h2o library
import h2o
from h2o.estimators import H2OKMeansEstimator
# init h2o cluster
h2o.init(strict_version_check=False, url="http://192.168.59.147:54321")
versionFromGradle='3.29.0',projectVersion='3.29.0.99999',branch='maurever_PUBDEV-6447_constrained_kmeans_improvement',lastCommitHash='162ceb18eae8b773028f27b284129c3ef752d001',gitDescribe='jenkins-master-4952-11-g162ceb18ea-dirty',compiledOn='2020-02-20 15:01:59',compiledBy='mori' Checking whether there is an H2O instance running at http://192.168.59.147:54321 . connected.
| H2O cluster uptime: | 12 mins 05 secs |
| H2O cluster timezone: | Europe/Berlin |
| H2O data parsing timezone: | UTC |
| H2O cluster version: | 3.29.0.99999 |
| H2O cluster version age: | 1 hour and 28 minutes |
| H2O cluster name: | mori |
| H2O cluster total nodes: | 1 |
| H2O cluster free memory: | 5.102 Gb |
| H2O cluster total cores: | 8 |
| H2O cluster allowed cores: | 8 |
| H2O cluster status: | locked, healthy |
| H2O connection url: | http://192.168.59.147:54321 |
| H2O connection proxy: | None |
| H2O internal security: | False |
| H2O API Extensions: | Amazon S3, XGBoost, Algos, AutoML, Core V3, TargetEncoder, Core V4 |
| Python version: | 3.7.3 candidate |
Data - Chicago Weather dataset¶
- 5162 rows
- 5 features (monht, day, year, maximal temperature, mean teperature)
# load data
import pandas as pd
data = pd.read_csv("../../smalldata/chicago/chicagoAllWeather.csv")
data = data.iloc[:,[1, 2, 3, 4, 5]]
print(data.shape)
data.head()
(5162, 5)
| month | day | year | maxTemp | meanTemp | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 2001 | 23.0 | 14.0 |
| 1 | 1 | 2 | 2001 | 18.0 | 12.0 |
| 2 | 1 | 3 | 2001 | 28.0 | 18.0 |
| 3 | 1 | 4 | 2001 | 30.0 | 24.0 |
| 4 | 1 | 5 | 2001 | 36.0 | 30.0 |
# import time to measure elapsed time
from timeit import default_timer as timer
from datetime import timedelta
import time
start = timer()
end = timer()
print("Time:", timedelta(seconds=end-start))
Time: 0:00:00.000010
Traditional K-means¶
Constrained K-means¶
data_h2o = h2o.H2OFrame(data)
# run h2o Kmeans to get good starting points
h2o_km = H2OKMeansEstimator(k=3, init="furthest", standardize=True)
start = timer()
h2o_km.train(training_frame=data_h2o)
end = timer()
user_points = h2o.H2OFrame(h2o_km.centers())
# show details
h2o_km.show()
time_km = timedelta(seconds=end-start)
print("Time:", time_km)
Parse progress: |█████████████████████████████████████████████████████████| 100% kmeans Model Build progress: |████████████████████████████████████████████| 100% Parse progress: |█████████████████████████████████████████████████████████| 100% Model Details ============= H2OKMeansEstimator : K-means Model Key: KMeans_model_python_1582207404277_9 Model Summary:
| number_of_rows | number_of_clusters | number_of_categorical_columns | number_of_iterations | within_cluster_sum_of_squares | total_sum_of_squares | between_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 5162.0 | 3.0 | 0.0 | 10.0 | 13948.755191 | 25779.0 | 11830.244809 |
ModelMetricsClustering: kmeans ** Reported on train data. ** MSE: NaN RMSE: NaN Total Within Cluster Sum of Square Error: 13948.755224513394 Total Sum of Square Error to Grand Mean: 25778.999972296842 Between Cluster Sum of Square Error: 11830.244747783448 Centroid Statistics:
| centroid | size | within_cluster_sum_of_squares | ||
|---|---|---|---|---|
| 0 | 1.0 | 2503.0 | 6566.945375 | |
| 1 | 2.0 | 1527.0 | 4341.602251 | |
| 2 | 3.0 | 1132.0 | 3040.207599 |
Scoring History:
| timestamp | duration | iterations | number_of_reassigned_observations | within_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|
| 0 | 2020-02-20 15:15:30 | 0.002 sec | 0.0 | NaN | NaN | |
| 1 | 2020-02-20 15:15:30 | 0.034 sec | 1.0 | 5162.0 | 24519.632818 | |
| 2 | 2020-02-20 15:15:30 | 0.047 sec | 2.0 | 637.0 | 14993.412521 | |
| 3 | 2020-02-20 15:15:30 | 0.058 sec | 3.0 | 257.0 | 14091.382859 | |
| 4 | 2020-02-20 15:15:30 | 0.065 sec | 4.0 | 101.0 | 13966.675115 | |
| 5 | 2020-02-20 15:15:30 | 0.074 sec | 5.0 | 38.0 | 13951.869333 | |
| 6 | 2020-02-20 15:15:30 | 0.081 sec | 6.0 | 11.0 | 13949.273464 | |
| 7 | 2020-02-20 15:15:30 | 0.088 sec | 7.0 | 6.0 | 13948.879016 | |
| 8 | 2020-02-20 15:15:30 | 0.093 sec | 8.0 | 1.0 | 13948.764310 | |
| 9 | 2020-02-20 15:15:30 | 0.098 sec | 9.0 | 1.0 | 13948.759892 | |
| 10 | 2020-02-20 15:15:30 | 0.102 sec | 10.0 | 0.0 | 13948.755191 |
Time: 0:00:00.234061
# run h2o constrained Kmeans
h2o_km_co = H2OKMeansEstimator(k=3, user_points=user_points, cluster_size_constraints=[1000, 2000, 1000], standardize=True)
start = timer()
h2o_km_co.train(training_frame=data_h2o)
end = timer()
# show details
h2o_km_co.show()
time_km_co = timedelta(seconds=end-start)
print("Time:", time_km_co)
kmeans Model Build progress: |████████████████████████████████████████████| 100% Model Details ============= H2OKMeansEstimator : K-means Model Key: KMeans_model_python_1582207404277_10 Model Summary:
| number_of_rows | number_of_clusters | number_of_categorical_columns | number_of_iterations | within_cluster_sum_of_squares | total_sum_of_squares | between_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 5162.0 | 3.0 | 0.0 | 4.0 | 14652.275631 | 25779.0 | 11126.724369 |
ModelMetricsClustering: kmeans ** Reported on train data. ** MSE: NaN RMSE: NaN Total Within Cluster Sum of Square Error: 14652.275630919356 Total Sum of Square Error to Grand Mean: 25778.999999999396 Between Cluster Sum of Square Error: 11126.72436908004 Centroid Statistics:
| centroid | size | within_cluster_sum_of_squares | ||
|---|---|---|---|---|
| 0 | 1.0 | 2021.0 | 4923.251099 | |
| 1 | 2.0 | 2000.0 | 6661.188217 | |
| 2 | 3.0 | 1141.0 | 3067.836315 |
Scoring History:
| timestamp | duration | iterations | number_of_reassigned_observations | within_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|
| 0 | 2020-02-20 15:15:30 | 0.001 sec | 0.0 | NaN | NaN | |
| 1 | 2020-02-20 15:15:54 | 24.140 sec | 1.0 | 5162.0 | 15180.211372 | |
| 2 | 2020-02-20 15:16:16 | 45.825 sec | 2.0 | 50.0 | 14654.534258 | |
| 3 | 2020-02-20 15:16:38 | 1 min 7.299 sec | 3.0 | 8.0 | 14652.367654 | |
| 4 | 2020-02-20 15:16:59 | 1 min 28.649 sec | 4.0 | 0.0 | 14652.275631 |
Time: 0:01:29.918478
Constrained K-means reduced data using Aggregator - changed size 1/2 of original data¶
from h2o.estimators.aggregator import H2OAggregatorEstimator
# original data size 5162, constraints 1000, 2000, 1000
# aggregated data size ~ 2581, constaints 500, 1000, 500
params = {
"target_num_exemplars": 2581,
"rel_tol_num_exemplars": 0.01,
"categorical_encoding": "eigen"
}
agg = H2OAggregatorEstimator(**params)
start = timer()
agg.train(training_frame=data_h2o)
data_agg = agg.aggregated_frame
# run h2o Kmeans
h2o_km_co_agg = H2OKMeansEstimator(k=3, user_points=user_points, cluster_size_constraints=[500, 1000, 500], standardize=True)
h2o_km_co_agg.train(x=["month", "day", "year", "maxTemp", "meanTemp"],training_frame=data_agg)
end = timer()
# show details
h2o_km_co_agg.show()
time_km_co_12 = timedelta(seconds=end-start)
print("Time:", time_km_co_12)
aggregator Model Build progress: |████████████████████████████████████████| 100% kmeans Model Build progress: |████████████████████████████████████████████| 100% Model Details ============= H2OKMeansEstimator : K-means Model Key: KMeans_model_python_1582207404277_12 Model Summary:
| number_of_rows | number_of_clusters | number_of_categorical_columns | number_of_iterations | within_cluster_sum_of_squares | total_sum_of_squares | between_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 2564.0 | 3.0 | 0.0 | 4.0 | 7292.073037 | 12799.0 | 5506.926963 |
ModelMetricsClustering: kmeans ** Reported on train data. ** MSE: NaN RMSE: NaN Total Within Cluster Sum of Square Error: 7292.073036736721 Total Sum of Square Error to Grand Mean: 12798.99999999936 Between Cluster Sum of Square Error: 5506.926963262638 Centroid Statistics:
| centroid | size | within_cluster_sum_of_squares | ||
|---|---|---|---|---|
| 0 | 1.0 | 1004.0 | 2541.127853 | |
| 1 | 2.0 | 1000.0 | 3225.245253 | |
| 2 | 3.0 | 560.0 | 1525.699931 |
Scoring History:
| timestamp | duration | iterations | number_of_reassigned_observations | within_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|
| 0 | 2020-02-20 15:17:01 | 0.003 sec | 0.0 | NaN | NaN | |
| 1 | 2020-02-20 15:17:09 | 8.222 sec | 1.0 | 2564.0 | 7453.636111 | |
| 2 | 2020-02-20 15:17:16 | 15.442 sec | 2.0 | 7.0 | 7292.141367 | |
| 3 | 2020-02-20 15:17:24 | 22.998 sec | 3.0 | 2.0 | 7292.076435 | |
| 4 | 2020-02-20 15:17:32 | 30.972 sec | 4.0 | 0.0 | 7292.073037 |
Time: 0:00:32.137910
Constrained K-means reduced data using Aggregator - changed size 1/4 of original data¶
from h2o.estimators.aggregator import H2OAggregatorEstimator
# original data size 5162, constraints 1000, 2000, 1000
# aggregated data size ~ 1290, constaints 250, 500, 250
params = {
"target_num_exemplars": 1290,
"rel_tol_num_exemplars": 0.01,
"categorical_encoding": "eigen"
}
agg_14 = H2OAggregatorEstimator(**params)
start = timer()
agg_14.train(training_frame=data_h2o)
data_agg_14 = agg_14.aggregated_frame
# run h2o Kmeans
h2o_km_co_agg_14 = H2OKMeansEstimator(k=3, user_points=user_points, cluster_size_constraints=[240, 480, 240], standardize=True)
h2o_km_co_agg_14.train(x=list(range(5)),training_frame=data_agg_14)
end = timer()
# show details
h2o_km_co_agg_14.show()
time_km_co_14 = timedelta(seconds=end-start)
print("Time:", time_km_co_14)
aggregator Model Build progress: |████████████████████████████████████████| 100% kmeans Model Build progress: |████████████████████████████████████████████| 100% Model Details ============= H2OKMeansEstimator : K-means Model Key: KMeans_model_python_1582207404277_14 Model Summary:
| number_of_rows | number_of_clusters | number_of_categorical_columns | number_of_iterations | within_cluster_sum_of_squares | total_sum_of_squares | between_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|---|---|
| 0 | 1298.0 | 3.0 | 0.0 | 3.0 | 3663.728438 | 6477.0 | 2813.271562 |
ModelMetricsClustering: kmeans ** Reported on train data. ** MSE: NaN RMSE: NaN Total Within Cluster Sum of Square Error: 3663.7284382884254 Total Sum of Square Error to Grand Mean: 6476.999999999918 Between Cluster Sum of Square Error: 2813.2715617114927 Centroid Statistics:
| centroid | size | within_cluster_sum_of_squares | ||
|---|---|---|---|---|
| 0 | 1.0 | 524.0 | 1358.489507 | |
| 1 | 2.0 | 480.0 | 1512.732712 | |
| 2 | 3.0 | 294.0 | 792.506219 |
Scoring History:
| timestamp | duration | iterations | number_of_reassigned_observations | within_cluster_sum_of_squares | ||
|---|---|---|---|---|---|---|
| 0 | 2020-02-20 15:17:33 | 0.001 sec | 0.0 | NaN | NaN | |
| 1 | 2020-02-20 15:17:35 | 2.760 sec | 1.0 | 1298.0 | 3686.655930 | |
| 2 | 2020-02-20 15:17:38 | 5.298 sec | 2.0 | 2.0 | 3663.741297 | |
| 3 | 2020-02-20 15:17:42 | 8.967 sec | 3.0 | 0.0 | 3663.728438 |
Time: 0:00:10.153074
Results¶
centers_km_co = h2o_km_co.centers()
centers_km_co_agg_12 = h2o_km_co_agg.centers()
centers_km_co_agg_14 = h2o_km_co_agg_14.centers()
centers_all = pd.concat([pd.DataFrame(centers_km_co).sort_values(by=[0]), pd.DataFrame(centers_km_co_agg_12).sort_values(by=[0]), pd.DataFrame(centers_km_co_agg_14).sort_values(by=[0])])
Difference between coordinates of original data and aggregated data¶
diff_first_cluster = pd.concat([centers_all.iloc[0,:] - centers_all.iloc[3,:], centers_all.iloc[0,:] - centers_all.iloc[6,:]], axis=1, ignore_index=True).transpose()
diff_first_cluster.index = ["1/2", "1/4"]
diff_first_cluster.style.bar(subset=[0,1,2,3,4], align='mid', color=['#d65f5f', '#5fba7d'], width=90)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 1/2 | 0.13 | 0.209 | -0.0635 | 1.08995 | 1.13402 |
| 1/4 | 0.36225 | 0.304667 | -0.0118333 | 3.69444 | 3.45049 |
diff_second_cluster = pd.concat([centers_all.iloc[1,:] - centers_all.iloc[4,:], centers_all.iloc[1,:] - centers_all.iloc[7,:]], axis=1, ignore_index=True).transpose()
diff_second_cluster.index = ["1/2", "1/4"]
diff_second_cluster.style.bar(subset=[0,1,2,3,4], align='mid', color=['#d65f5f', '#5fba7d'], width=90)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 1/2 | 0.180962 | 0.318738 | 0.216757 | 1.42131 | 1.6473 |
| 1/4 | 0.427229 | 0.287581 | 0.260362 | 2.06556 | 2.21081 |
diff_third_cluster = pd.concat([centers_all.iloc[2,:] - centers_all.iloc[5,:], centers_all.iloc[2,:] - centers_all.iloc[8,:]], axis=1, ignore_index=True).transpose()
diff_third_cluster.index = ["1/2", "1/4"]
diff_third_cluster.style.bar(subset=[0,1,2,3,4], color=['#d65f5f', '#5fba7d'], align="mid", width=90)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 1/2 | -0.0389132 | 0.418558 | 0.0399649 | 0.201598 | 0.31681 |
| 1/4 | -0.0300697 | 0.476211 | 0.286904 | 0.855841 | 0.845892 |