![]()
In [1]:
from traitlets.config.manager import BaseJSONConfigManager
from pathlib import Path
In [2]:
path = Path.home() / ".jupyter" / "nbconfig"
cm = BaseJSONConfigManager(config_dir=str(path))
cm.update(
"rise",
{
"autolaunch": False,
"enable_chalkboard": True,
"scroll": True,
"slideNumber": True,
"controls": True,
"progress": True,
"history": True,
"center": True,
"width": "100%",
"height": "100%",
"theme": "beige",
"transition": "concave",
"start_slideshow_at": "selected"
}
)
Out[2]:
{'autolaunch': False,
'enable_chalkboard': True,
'scroll': True,
'slideNumber': True,
'controls': True,
'progress': True,
'history': True,
'center': True,
'width': '100%',
'height': '100%',
'theme': 'beige',
'transition': 'concave',
'start_slideshow_at': 'selected'}
Outline¶
- My background
- NLP applications in business
- Doing linguistic analysis with programs
- Machine learning 101
- Text representation
- Transfer learning
- Hands-on walkthrough (HOW)
My background¶
Education¶

Experience¶
AI Engineer, Wisers Information Limited
AI Engineer, Hamastar Technology
Boya Postdoc Researcher (博雅博士後), Peking University
English Lecturer, National Taipei University of Technology
NLP applications in business¶
- Document-level sentiment

- Category-specific sentiment
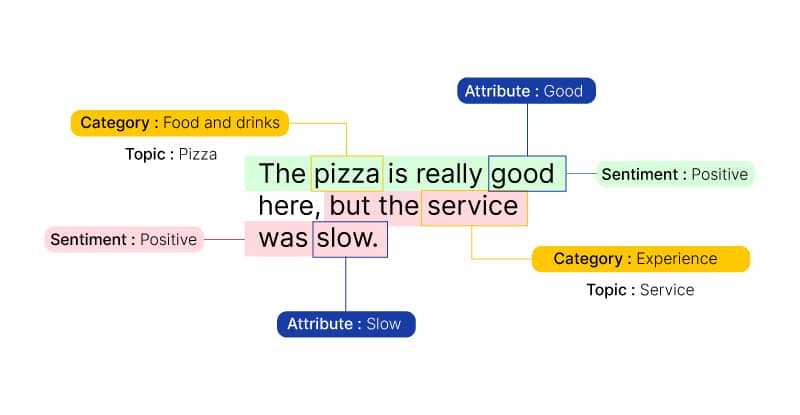
- Chatbot

- Revenues from the NLP market

Doing linguistic analysis with programs¶

Programming languages¶
- Common languages in data science

- Languages across different roles

- If you've taken linguistics, you can learn any language, right?
- If linguists can decipher an alien language, they can also crack a programming language, right?
Developer tools¶
Basic¶
- NLTK, a toolkit for starters

- gensim, a tool that simplifies the process of converting texts to numbers
- spaCy, an industrial-strength solution for end-to-end pipelines

Advanced¶
- Deep learning frameworks
PyTorch, made by Facebook/MetaTensorFlow, made by GoogleTransformers, made by Hugging Face

Common NLP tasks¶
Install tools¶
- spaCy
In [ ]:
!pip install -U pip setuptools wheel
!pip install -U spacy
!python -m spacy download zh_core_web_md
In [4]:
import spacy
- jieba_tw, which is jieba optimized for Taiwan Mandarin
In [5]:
!git clone -l -s https://github.com/L706077/jieba-zh_TW.git jieba_tw
%cd jieba_tw
fatal: destination path 'jieba_tw' already exists and is not an empty directory. /content/jieba_tw
In [6]:
import jieba
In [7]:
%cd ../
/content
Tokenization¶

In [8]:
nlp = spacy.load("zh_core_web_md")
nlp.pipe_names
Out[8]:
['tok2vec', 'tagger', 'parser', 'attribute_ruler', 'ner']
- Sample text:
宜家家居新店店店長的名字好長喔! - This is what inspired me to come up with this example.

In [9]:
text = "宜家家居新店店店長的名字好長喔!"
doc = nlp(text)
tokens = [tok.text for tok in doc]
" | ".join(tokens)
Out[9]:
'宜家家 | 居 | 新店 | 店 | 店長 | 的 | 名字 | 好 | 長喔 | !'
In [10]:
text = "宜家家居新店店店长的名字好长喔!"
doc = nlp(text)
tokens = [tok.text for tok in doc]
" | ".join(tokens)
Out[10]:
'宜家家 | 居 | 新店 | 店 | 店长 | 的 | 名字 | 好长喔 | !'
In [11]:
text = "宜家家居新店店店長的名字好長喔!"
tokens = jieba.cut(text)
" | ".join(tokens)
Building prefix dict from the default dictionary ... Loading model from cache /tmp/jieba.cache Loading model cost 0.629 seconds. Prefix dict has been built succesfully.
Out[11]:
'宜家 | 家居 | 新店店 | 店長 | 的 | 名字 | 好長 | 喔 | !'
In [12]:
text = "宜家家居新店店店长的名字好长喔!"
tokens = jieba.cut(text)
" | ".join(tokens)
Out[12]:
'宜家 | 家居 | 新店店 | 店 | 长 | 的 | 名字 | 好 | 长 | 喔 | !'
- The default tokenizer of spaCy is
jieba, and we'll replace it withjieba_twto get better results on Taiwan Mandarin.
In [13]:
from spacy.tokens import Doc
class TwTokenizer:
def __init__(self, vocab):
self.vocab = vocab
def __call__(self, text):
words = list(jieba.cut(text))
spaces = [False] * len(words)
return Doc(self.vocab, words=words, spaces=spaces)
In [14]:
nlp.tokenizer = TwTokenizer(nlp.vocab)
- You can replace the sentence stored in
textwith anything off the top of your head.
In [15]:
text = "宜家家居新店店店長的名字好長喔!"
doc = nlp(text)
tokens = [tok.text for tok in doc]
" | ".join(tokens)
Out[15]:
'宜家 | 家居 | 新店店 | 店長 | 的 | 名字 | 好長 | 喔 | !'
Part-of-speech (POS) tagger¶
Token.pos_for universal POS tags
In [16]:
for tok in doc:
print(f"{tok.text} >>> {tok.pos_}")
宜家 >>> NOUN 家居 >>> NOUN 新店店 >>> NOUN 店長 >>> NOUN 的 >>> PART 名字 >>> NOUN 好長 >>> VERB 喔 >>> INTJ ! >>> PUNCT
Token.tag_for language-specific POS tags
In [17]:
for tok in doc:
print(f"{tok.text} >>> {tok.tag_} | {spacy.explain(tok.tag_)}")
宜家 >>> NN | noun, singular or mass 家居 >>> NN | noun, singular or mass 新店店 >>> NN | noun, singular or mass 店長 >>> NN | noun, singular or mass 的 >>> DEG | associative 的 名字 >>> NN | noun, singular or mass 好長 >>> VV | other verb 喔 >>> IJ | interjection ! >>> PU | punctuation
Dependency parser¶
In [18]:
from spacy import displacy
In [19]:
text = "我想要三份2號餐"
doc = nlp(text)
displacy.render(doc, style='dep',jupyter=True, options={'distance':130})
Token.dep_for dependency tags
In [20]:
for tok in doc:
print(f"{tok.text} >>> {tok.dep_}")
我 >>> nsubj 想要 >>> ROOT 三 >>> nummod 份 >>> mark:clf 2 >>> dep 號餐 >>> dobj
In [21]:
from spacy.matcher import Matcher
In [22]:
matcher = Matcher(nlp.vocab)
order_pattern = [{"POS": "NUM", "OP": "+"}, # for one or more NUM
{"POS": "NOUN"}]
matcher.add("ORDER", [order_pattern])
matches = matcher(doc)
In [23]:
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(f"The order is >>> {span.text}")
The order is >>> 2號餐 The order is >>> 份2號餐 The order is >>> 三份2號餐
Named entity recognition (NER)¶
In [24]:
text = """
(中央社)COVID-19疫情使遠距、實體相輔相成的模式成為教學常態,台灣師範大學今天宣布成立網路大學辦公室,並開設3個數位碩士在職專班,向全世界招生。
台師大今天舉辦記者會為網路大學辦公室揭牌,校長吳正己表示,在COVID-19(2019年冠狀病毒疾病)疫情下,線上教學大幅增加,教育部也大幅放寬數位學習學制及招生對象限制。
"""
doc = nlp(text)
displacy.render(doc, style='ent',jupyter=True)
(
中央社
ORG
)
COVID
GPE
-
19
CARDINAL
疫情使遠距、實體相輔相成的模式成為教學常態,
台灣師範大學
ORG
今天
DATE
宣布成立網路大學辦公室,並開設
3
CARDINAL
個數位碩士在職專班,向全世界招生。
台師大
GPE
今天
DATE
舉辦記者會為網路大學辦公室揭牌,校長吳正己表示,在
COVID
GPE
-19(
2019年
DATE
冠狀病毒疾病)疫情下,
線上
GPE
教學大幅增加,
教育部
ORG
也大幅放寬數位學習學制及招生對象限制。
Span.label_for NER tags
In [25]:
for span in doc.ents:
print(f"{span.text} >>> {span.label_}")
中央社 >>> ORG COVID >>> GPE 19 >>> CARDINAL 台灣師範大學 >>> ORG 今天 >>> DATE 3 >>> CARDINAL 台師大 >>> GPE 今天 >>> DATE COVID >>> GPE 2019年 >>> DATE 線上 >>> GPE 教育部 >>> ORG
In [26]:
from spacy.matcher import PhraseMatcher
from spacy.tokens import Span
In [27]:
phrase_matcher = PhraseMatcher(nlp.vocab)
ntnu_terms = ['台灣師大','台師大',]
phrase_matcher.add('NTNU', list(nlp.pipe(ntnu_terms)))
In [28]:
matches = phrase_matcher(doc)
org_spans = [span for span in doc.ents if span.label_=="ORG"]
for match_id, start, end in matches:
new_ent = Span(doc, start, end, "ORG")
org_spans.append(new_ent)
doc.ents = org_spans
displacy.render(doc, style='ent',jupyter=True)
(
中央社
ORG
)COVID-19疫情使遠距、實體相輔相成的模式成為教學常態,
台灣師範大學
ORG
今天宣布成立網路大學辦公室,並開設3個數位碩士在職專班,向全世界招生。
台師大
ORG
今天舉辦記者會為網路大學辦公室揭牌,校長吳正己表示,在COVID-19(2019年冠狀病毒疾病)疫情下,線上教學大幅增加,
教育部
ORG
也大幅放寬數位學習學制及招生對象限制。
- You can interact with models without knowing any code by using this Web APP that I created.
In [29]:
from IPython.display import IFrame
In [30]:
IFrame(src='https://share.streamlit.io/howard-haowen/spacy-streamlit/app.py', width=700, height=1000)
Out[30]:
Machine learning 101¶
- Classical programming vs machine learning
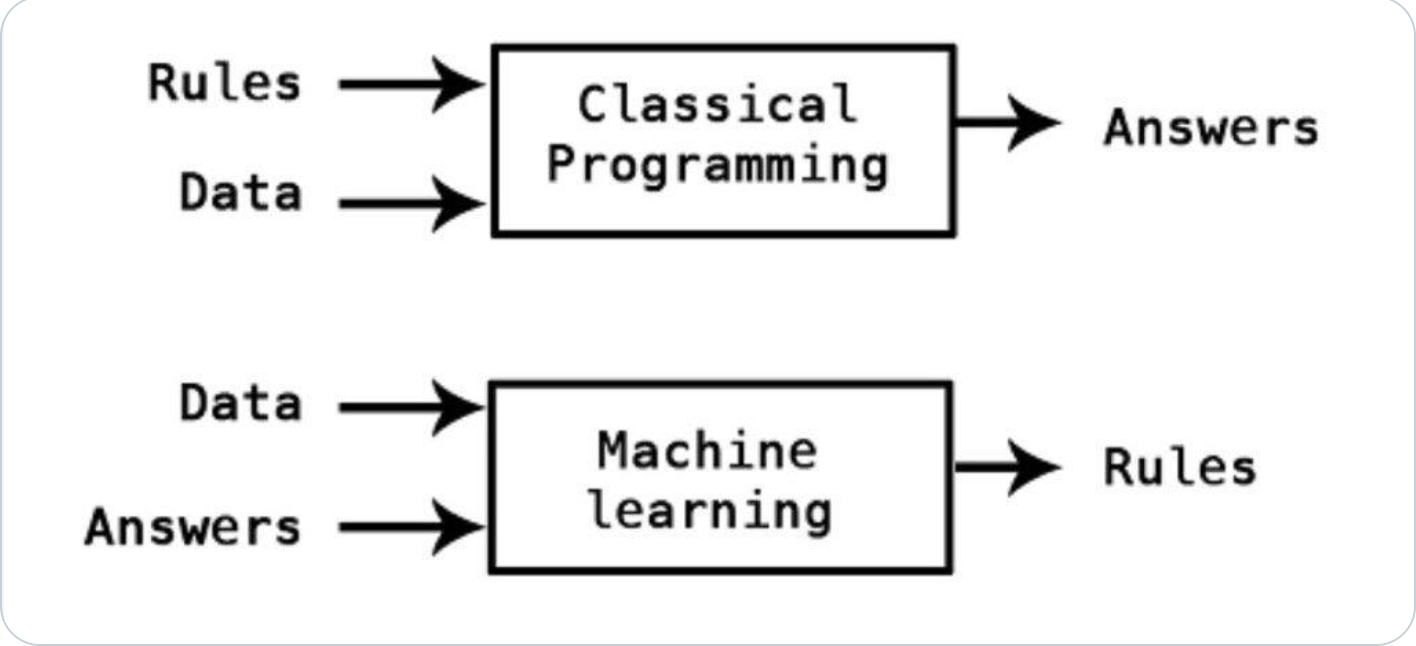
- ML models learn from instances, so it's not surprising that they make mistakes.

- AI > ML > DL

- All forms of data, be it images, sounds, or texts, have to be first converted into numbers to be fed into a training algorithm.
- The process of transforming raw data to a sequence of numbers (i.e. vectors) is called
feature engineering.
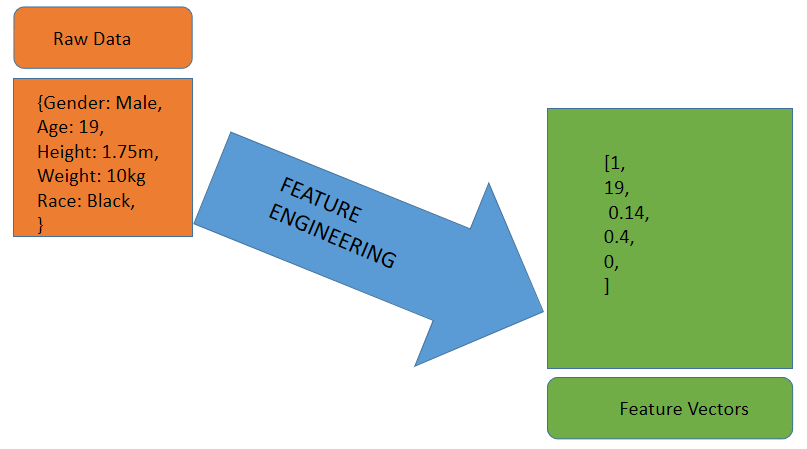
- Two stages of a machine learning project: training and prediction
- Taking sentiment analysis as an example

Text representation¶
Representing images¶

In [1]:
import numpy as np
import cv2
import matplotlib.pyplot as plt
%matplotlib inline
In [2]:
!wget -O sample.jpg http://www.paulvangent.com/wp-content/uploads/2018/08/J2FOX3F.jpg
--2022-03-19 02:04:11-- http://www.paulvangent.com/wp-content/uploads/2018/08/J2FOX3F.jpg Resolving www.paulvangent.com (www.paulvangent.com)... 46.30.213.30, 2a02:2350:5:10a:f2:d80c:fe33:f3de Connecting to www.paulvangent.com (www.paulvangent.com)|46.30.213.30|:80... connected. HTTP request sent, awaiting response... 200 OK Length: 50600 (49K) [image/jpeg] Saving to: ‘sample.jpg’ sample.jpg 100%[===================>] 49.41K 93.3KB/s in 0.5s 2022-03-19 02:04:12 (93.3 KB/s) - ‘sample.jpg’ saved [50600/50600]
In [3]:
img = cv2.imread('sample.jpg')
img.shape
Out[3]:
(412, 640, 3)
In [34]:
print(img)
[[[245 247 248] [104 106 106] [ 50 50 50] ... [ 26 26 32] [ 26 26 32] [ 27 27 33]] [[240 242 243] [ 99 101 102] [ 45 45 45] ... [ 19 19 25] [ 19 19 25] [ 19 19 25]] [[242 246 247] [102 106 107] [ 48 50 50] ... [ 20 19 28] [ 21 20 29] [ 21 20 29]] ... [[234 243 240] [ 79 87 86] [ 15 24 27] ... [ 84 84 84] [ 83 83 83] [ 82 82 82]] [[235 244 241] [ 79 87 86] [ 16 25 28] ... [ 84 84 84] [ 83 83 83] [ 82 82 82]] [[235 244 241] [ 80 88 87] [ 16 25 28] ... [ 84 84 84] [ 83 83 83] [ 82 82 82]]]
In [6]:
img_gray = cv2.imread('sample.jpg', cv2.IMREAD_GRAYSCALE)
img_gray.shape
Out[6]:
(412, 640)
In [7]:
plt.imshow(img_gray, cmap='gray')
plt.show()

- You can change
100below to any number between 1 and 255.
In [8]:
modified_img = img_gray - 100
plt.imshow(modified_img, cmap='gray')
plt.show()

Representing texts¶
- Compared with images, texts are much harder to represent in numbers.
- There're three major types of text representation:
- Symoblic representation
- Distributional representation
- Distributed representation
Download a dataset¶
In [39]:
!wget -O Dcard.db https://github.com/howard-haowen/NLP-demos/raw/main/Dcard_20220304.db
--2022-03-18 13:00:53-- https://github.com/howard-haowen/NLP-demos/raw/main/Dcard_20220304.db Resolving github.com (github.com)... 140.82.114.4 Connecting to github.com (github.com)|140.82.114.4|:443... connected. HTTP request sent, awaiting response... 302 Found Location: https://raw.githubusercontent.com/howard-haowen/NLP-demos/main/Dcard_20220304.db [following] --2022-03-18 13:00:53-- https://raw.githubusercontent.com/howard-haowen/NLP-demos/main/Dcard_20220304.db Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 151552 (148K) [application/octet-stream] Saving to: ‘Dcard.db’ Dcard.db 100%[===================>] 148.00K --.-KB/s in 0.02s 2022-03-18 13:00:53 (6.74 MB/s) - ‘Dcard.db’ saved [151552/151552]
In [40]:
import sqlite3
import pandas as pd
In [41]:
conn = sqlite3.connect("Dcard.db")
data = pd.read_sql("SELECT * FROM Posts;", conn)
data.head()
Out[41]:
| createdAt | title | excerpt | categories | topics | forum_en | forum_zh | |
|---|---|---|---|---|---|---|---|
| 0 | 2022-03-04T07:54:19.886Z | 專題需要數據🥺🥺幫填~ | 希望各位能花個20秒幫我填一下 | dressup | 穿搭 | ||
| 1 | 2022-03-04T07:42:59.512Z | #詢問 找衣服🥲 | 想找這套衣服🥲,但發現不知道該用什麼關鍵字找,(圖是草屯囝仔的校園演唱會截圖) | 詢問 | 衣服 | 鞋子 | 衣物 | 男生穿搭 | 尋找 | dressup | 穿搭 |
| 2 | 2022-03-04T07:24:25.147Z | #黑特 網購50% FIFTY PERCENT請三思 | 因為文會有點長,先說結論是,50%是目前網購過的平台退貨最麻煩的一家,甚至我認為根本是刻意刁... | 黑特 | 網購 | 三思 | 退貨 | 售後服務 | dressup | 穿搭 | |
| 3 | 2022-03-04T06:39:13.017Z | 尋衣服 | 來源:覺得呱吉這襯衫好好看~~,或有人知道有類似的嗎 | 衣服 | 尋找 | 日常穿搭 | 男生穿搭 | dressup | 穿搭 | |
| 4 | 2022-03-04T06:28:06.137Z | #詢問 想問 | 各位,因為這個證件夾臺灣買不到,是美國outlet 的限量版貨,所以在以下的這間蝦皮上買,但... | 詢問 | 穿搭 | 閒聊版 | 閒聊排解 | 假貨 | dressup | 穿搭 |
In [42]:
data.groupby("forum_en").size()
Out[42]:
forum_en dressup 30 food 30 funny 30 girl 30 horoscopes 30 makeup 30 money 30 netflix 30 relationship 30 talk 30 trending 30 youtuber 30 dtype: int64
In [43]:
data.shape
Out[43]:
(360, 7)
In [44]:
cols = ["excerpt", "forum_en", "forum_zh"]
df = data[cols]
df
Out[44]:
| excerpt | forum_en | forum_zh | |
|---|---|---|---|
| 0 | 希望各位能花個20秒幫我填一下 | dressup | 穿搭 |
| 1 | 想找這套衣服🥲,但發現不知道該用什麼關鍵字找,(圖是草屯囝仔的校園演唱會截圖) | dressup | 穿搭 |
| 2 | 因為文會有點長,先說結論是,50%是目前網購過的平台退貨最麻煩的一家,甚至我認為根本是刻意刁... | dressup | 穿搭 |
| 3 | 來源:覺得呱吉這襯衫好好看~~,或有人知道有類似的嗎 | dressup | 穿搭 |
| 4 | 各位,因為這個證件夾臺灣買不到,是美國outlet 的限量版貨,所以在以下的這間蝦皮上買,但... | dressup | 穿搭 |
| ... | ... | ... | ... |
| 355 | 昨天上了第一支影片,之前有發過沒有線條的動畫影片,新的頻道改成有線條的,感覺大家好像比較喜歡... | youtuber | YouTuber |
| 356 | 今天全台灣大停電,應該過幾天就會有個戴面具的出來說,一定是中共……,我從上個影片就預測了…… | youtuber | YouTuber |
| 357 | 想問有沒有人知道阿神和放火是認識還是有結過什麼仇之類的嗎?首先我個人基本沒關注過放火,但是最... | youtuber | YouTuber |
| 358 | 無意引戰,單純分享我的觀察與個人想法~這幾天看了Dcard幾篇關於Rice& Shine的貼... | youtuber | YouTuber |
| 359 | 哈哈哈哈,沒錯我就是親友團來介紹一個我覺得很北七的頻道,現在觀看真的低的可憐,也沒事啦,就多... | youtuber | YouTuber |
360 rows × 3 columns
- You can change
62below to any number between 0 and 359.
In [45]:
docid = 62
sample_text = df.loc[docid, "excerpt"]
sample_text
Out[45]:
'昨天在屈臣氏買的新品,手刀來分享心得!!!!,🥑價格: $305/320ml~~很大條,成分主打維生素B群、紅石榴跟枸杞,跟其他兩款一樣都是果萃的美白,這款有很少女的莓果香,甜甜的感覺,味道有點像美國'
Preprocess texts¶

In [46]:
def preprocess_text(text: str) -> list:
doc = nlp.make_doc(text)
res = [tok for tok in doc if not tok.is_punct]
res = [tok for tok in res if not tok.is_stop] # stop words
res = [tok for tok in res if not tok.like_email]
res = [tok for tok in res if not tok.like_url]
res = [tok for tok in res if not tok.like_num]
res = [tok for tok in res if not tok.is_ascii]
res = [tok.text for tok in res if not tok.is_space]
return res
- Think of stop words as highly frequent words, typically those that non-native speakers tend to make mistakes on.

In [47]:
processed_text = preprocess_text(sample_text)
print(f"Before preprocessing:\n {sample_text}")
print(f"After preprocessing:\n {processed_text}")
Before preprocessing: 昨天在屈臣氏買的新品,手刀來分享心得!!!!,🥑價格: $305/320ml~~很大條,成分主打維生素B群、紅石榴跟枸杞,跟其他兩款一樣都是果萃的美白,這款有很少女的莓果香,甜甜的感覺,味道有點像美國 After preprocessing: ['昨天', '屈臣氏', '買', '新品', '手刀', '來', '分享', '心得', '🥑', '價格', '條', '成分', '主打', '維生素', 'B群', '紅', '石榴', '枸杞', '兩', '款', '一樣', '果萃', '美白', '這', '款有', '少女', '莓果', '香', '甜甜', '感覺', '味道', '有點', '美國']
In [ ]:
df.loc[:,"toks"] = df["excerpt"].apply(preprocess_text)
In [49]:
df.head()
Out[49]:
| excerpt | forum_en | forum_zh | toks | |
|---|---|---|---|---|
| 0 | 希望各位能花個20秒幫我填一下 | dressup | 穿搭 | [希望, 位, 花, 個, 秒, 幫, 填] |
| 1 | 想找這套衣服🥲,但發現不知道該用什麼關鍵字找,(圖是草屯囝仔的校園演唱會截圖) | dressup | 穿搭 | [想, 找, 這, 套, 衣服, 🥲, 發現, 該, 用什麼, 關鍵字, 找, 圖是, 草屯... |
| 2 | 因為文會有點長,先說結論是,50%是目前網購過的平台退貨最麻煩的一家,甚至我認為根本是刻意刁... | dressup | 穿搭 | [因為, 文會, 有點, 長, 先, 說, 結論, 網購, 過, 平台, 退貨, 麻煩, 家... |
| 3 | 來源:覺得呱吉這襯衫好好看~~,或有人知道有類似的嗎 | dressup | 穿搭 | [來源, 覺得, 呱吉, 這, 襯衫, 好好, 類似, 嗎] |
| 4 | 各位,因為這個證件夾臺灣買不到,是美國outlet 的限量版貨,所以在以下的這間蝦皮上買,但... | dressup | 穿搭 | [位, 因為, 這, 個, 證件, 夾, 臺灣, 買不到, 美國, 限量版, 貨, 這, 間... |
In [51]:
df["forum_en"].unique()
Out[51]:
array(['dressup', 'relationship', 'makeup', 'food', 'horoscopes', 'talk',
'trending', 'money', 'funny', 'girl', 'netflix', 'youtuber'],
dtype=object)
- You can choose any forum name from above and append it to
selected_forums.
In [52]:
selected_forums = ["trending", "netflix", "money", "makeup", "dressup"]
forum_filt = df["forum_en"].isin(selected_forums)
sample_df = df[forum_filt]
sample_df.reset_index(inplace=True, drop=True)
- One common way to get rid of outliers is to filter by text length.
In [53]:
sample_df[sample_df["excerpt"].apply(len)<=10]
Out[53]:
| index | excerpt | forum_en | forum_zh | toks | |
|---|---|---|---|---|---|
| 8 | 8 | dressup | 穿搭 | [] | |
| 29 | 29 | dressup | 穿搭 | [] | |
| 39 | 69 | 是在笑屁笑啦🤷️ | makeup | 美妝 | [笑, 屁笑, 🤷, , ️] |
| 58 | 88 | 如題,請教各位 | makeup | 美妝 | [如題, 請教, 位] |
| 66 | 186 | trending | 時事 | [] | |
| 78 | 198 | 感覺離戰爭好近 | trending | 時事 | [感覺, 離, 戰爭, 好近] |
| 82 | 202 | trending | 時事 | [] | |
| 88 | 208 | 金曲不敗 | trending | 時事 | [金曲, 敗] |
| 100 | 220 | money | 理財 | [] | |
| 144 | 324 | netflix | Netflix | [] |
In [54]:
sample_df = sample_df[sample_df["excerpt"].apply(len)>10]
In [55]:
sample_df.reset_index(inplace=True, drop=True)
In [56]:
sample_df.shape
Out[56]:
(140, 6)
Symbolic representation¶
TF-IDF (term frequency-inverse document frequency)¶

- TF-IDF is based on the Bag-of-Words (BOW) model.
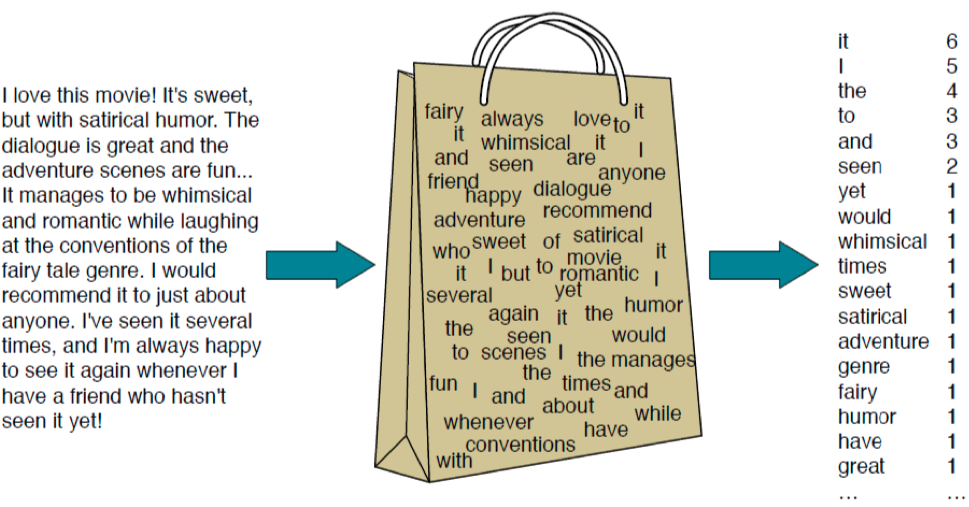
In [50]:
from gensim import corpora, models
- A gensim dictionary stores a mapping between words and their integer IDs.
In [57]:
texts = sample_df["toks"].to_list()
dictionary = corpora.Dictionary(texts)
print(dictionary.token2id)
{'位': 0, '個': 1, '填': 2, '希望': 3, '幫': 4, '秒': 5, '花': 6, '囝仔': 7, '圖是': 8, '套': 9, '想': 10, '截圖': 11, '找': 12, '校園': 13, '演唱會': 14, '用什麼': 15, '發現': 16, '草屯': 17, '衣服': 18, '該': 19, '這': 20, '關鍵字': 21, '\U0001f972': 22, '以為': 23, '保障': 24, '先': 25, '刁難': 26, '刻意': 27, '原本': 28, '售後': 29, '因為': 30, '家': 31, '實體店': 32, '平台': 33, '念頭': 34, '打消': 35, '文會': 36, '會': 37, '有點': 38, '服務': 39, '正': 40, '比較': 41, '沒想到': 42, '糟': 43, '結論': 44, '網購': 45, '認為': 46, '說': 47, '讓': 48, '退貨': 49, '遇過': 50, '過': 51, '長': 52, '顧客': 53, '麻煩': 54, '來源': 55, '呱吉': 56, '嗎': 57, '好好': 58, '襯衫': 59, '覺得': 60, '類似': 61, '不會': 62, '假': 63, '夾': 64, '美國': 65, '臺灣': 66, '蝦皮': 67, '請': 68, '謝謝': 69, '證件': 70, '貨': 71, '買': 72, '買不到': 73, '買到': 74, '這會': 75, '還是': 76, '間': 77, '限量版': 78, '下單': 79, '什麼': 80, '入手': 81, '取消': 82, '後': 83, '斷貨': 84, '方式': 85, '訂單': 86, '請問': 87, '賣': 88, '雙鞋': 89, '´': 90, '▽': 91, '們': 92, '分享': 93, '到來': 94, '厚重': 95, '哈囉': 96, '單品': 97, '囉': 98, '大使': 99, '小魚': 100, '已經': 101, '放到': 102, '春夏': 103, '春天': 104, '歐膩': 105, '溫柔': 106, '為了': 107, '現在': 108, '穿搭': 109, '萬年': 110, '衣櫃': 111, '裡面': 112, '迎接': 113, '開箱': 114, '靴子': 115, 'ノ': 116, '件': 117, '來問': 118, '出來': 119, '實體': 120, '店面': 121, '想問': 122, '改短': 123, '有夠': 124, '為什麼': 125, '燒到': 126, '穿': 127, '網頁': 128, '褲子': 129, '試穿': 130, '請人': 131, '資訊': 132, '跳': 133, '近期': 134, '逛過': 135, '點': 136, '一場': 137, '三天': 138, '偏': 139, '做': 140, '兩': 141, '出遊': 142, '出門': 143, '參考': 144, '墾丁': 145, '夜': 146, '太多': 147, '帶': 148, '旅': 149, '旅程': 150, '東西': 151, '畢竟': 152, '簡單': 153, '色系': 154, '記錄': 155, '走': 156, '踏上': 157, '雖然': 158, '黑白': 159, '\U0001f90d': 160, '代購': 161, '叫壯': 162, '小弟': 163, '怪怪': 164, '推薦': 165, '有沒有': 166, '服飾': 167, '男生': 168, '美系': 169, '賣場': 170, '韓版': 171, '體型': 172, '吸引': 173, '哪裡': 174, '問': 175, '弱弱': 176, '狐狸': 177, '脆脆': 178, '貓咪': 179, '些賣': 180, '假貨': 181, '包包': 182, '正品': 183, '直播': 184, '精品': 185, '上衣': 186, '下架': 187, '剛剛': 188, '客廳': 189, '本來': 190, '結果': 191, '詢問': 192, '🥺': 193, '女生': 194, '挺': 195, '推出': 196, '款': 197, '短袖': 198, '胸部': 199, '適合': 200, '一樣': 201, '不用': 202, '中': 203, '喜歡': 204, '塊': 205, '太': 206, '小腿': 207, '微肉': 208, '擺盪': 209, '用力': 210, '瘦子': 211, '發達': 212, '肌': 213, '胖': 214, '身材': 215, '身高': 216, '長靴': 217, '體重': 218, '丟': 219, '半夜': 220, '外套': 221, '天': 222, '實現': 223, '幾': 224, '想要': 225, '找到': 226, '整整': 227, '朋友': 228, '沒': 229, '沒有': 230, '消息': 231, '男友': 232, '網路': 233, '購買': 234, '還': 235, '難以': 236, '大四': 237, '好看': 238, '學生': 239, '選手': 240, '偶然': 241, '品牌': 242, '大戰': 243, '好心人': 244, '如題': 245, '支持': 246, '星際': 247, '正版': 248, '爬文': 249, '經': 250, '表弟': 251, '評價': 252, '送': 253, '選擇性': 254, '好了': 255, '實在': 256, '寬褲': 257, '平常': 258, '怎麼': 259, '搭': 260, '條': 261, '照片': 262, '種': 263, '練習': 264, '西裝': 265, '這樣': 266, '配了': 267, '風格': 268, '來': 269, '其實': 270, '前': 271, '十年': 272, '卡包': 273, '外': 274, '扣除': 275, '掉': 276, '次': 277, '版開': 278, '男夾': 279, '當': 280, '短夾': 281, '禮物': 282, '算是': 283, '耐操': 284, '超': 285, '零錢包': 286, '努力': 287, '女兒': 288, '媽媽': 289, '少女': 290, '幾乎': 291, '幾年': 292, '懶': 293, '手機': 294, '打扮': 295, '拍照': 296, '放棄': 297, '時期': 298, '熟女': 299, '生完': 300, '維持': 301, '裡': 302, '規格': 303, '越來越': 304, '邋遢': 305, '˂': 306, '˶': 307, '̗': 308, '̀': 309, 'ᴗ': 310, 'ᵕ': 311, '三月': 312, '不知不覺': 313, '來到': 314, '咿': 315, '嗨': 316, '回暖': 317, '天氣': 318, '嫌棄': 319, '我們': 320, '漸漸': 321, '看下去': 322, '秋冬': 323, '繼續': 324, '話': 325, '𝚌': 326, '𝚐': 327, '𝚔': 328, '𝚖': 329, '🧸': 330, '二手': 331, '五分': 332, '全新': 333, '官網': 334, '直紋': 335, '聯名': 336, '號': 337, '難過': 338, '不錯': 339, '他們': 340, '年初': 341, '無腦': 342, '版型': 343, '產品': 344, '瘋狂': 345, '真的': 346, '褲': 347, '買下': 348, '追蹤': 349, '這不': 350, '韓貨': 351, '黑色': 352, '牌子': 353, '這是': 354, 'ㄉ': 355, '身邊': 356, '類': 357, '˵': 358, '̫': 359, '᷄': 360, '᷅': 361, '⁻': 362, '好人': 363, '片': 364, '介紹': 365, '光感': 366, '全包': 367, '哭出': 368, '唇彩': 369, '唇膏': 370, '唇釉': 371, '支': 372, '沉迷': 373, '空氣': 374, '絲絨': 375, '要來': 376, '變成': 377, '那麼': 378, '錢包': 379, '開玩笑': 380, '中國': 381, '口紅': 382, '堆': 383, '大開眼界': 384, '寶庫': 385, '小紅書': 386, '想到': 387, '搜尋': 388, '淘寶': 389, '生火': 390, '眼影': 391, '笑': 392, '腮紅': 393, '開始': 394, 'B群': 395, '主打': 396, '價格': 397, '味道': 398, '屈臣氏': 399, '心得': 400, '感覺': 401, '成分': 402, '手刀': 403, '新品': 404, '昨天': 405, '果萃': 406, '枸杞': 407, '款有': 408, '甜甜': 409, '石榴': 410, '紅': 411, '維生素': 412, '美白': 413, '莓果': 414, '香': 415, '🥑': 416, '優惠': 417, '克蘭詩': 418, '入坑': 419, '印象': 420, '專屬': 421, '常會': 422, '折扣': 423, '林三益': 424, '玄玄': 425, '發': 426, '瞜': 427, '碼': 428, '蘭蔻': 429, '蠻': 430, '長會': 431, '限定組': 432, '隱藏': 433, '雅勻': 434, '一門': 435, '不厭': 436, '保養品': 437, '刺刺': 438, '大致上': 439, '妖豔': 440, '學問': 441, '小心翼翼': 442, '擦上': 443, '放心': 444, '敏感': 445, '服用': 446, '泛紅': 447, '濃郁': 448, '牌': 449, '百試': 450, '立馬': 451, '耶': 452, '醫美': 453, '香味': 454, '交友': 455, '充滿': 456, '南部': 457, '台積電': 458, '同事': 459, '單身': 460, '壓縮機': 461, '工程師': 462, '揣測': 463, '日本': 464, '根據': 465, '歲': 466, '濕氣': 467, '無塵': 468, '稀少': 469, '統計': 470, '衣裡': 471, '認識': 472, '透過': 473, '進口': 474, '一陣子': 475, '乾性': 476, '保養': 477, '刺激': 478, '嚴重': 479, '忽冷': 480, '忽熱': 481, '摧殘': 482, '狀態': 483, '穩定': 484, '肌膚': 485, '臉頰': 486, '變得': 487, '轉用': 488, '🆘': 489, '付款': 490, '以來': 491, '力點': 492, '噴': 493, '困擾': 494, '地方': 495, '嫩粉': 496, '專業': 497, '對話': 498, '從': 499, '截': 500, '排版': 501, '接觸': 502, '擦': 503, '文': 504, '是業': 505, '桃色': 506, '正文': 507, '烏唇': 508, '發文': 509, '給': 510, '罵': 511, '美妝': 512, '蜜': 513, '證明': 514, '需': 515, '首': 516, '鮭魚': 517, '🤣': 518, '下好': 519, '交替': 520, '伺機而動': 521, '出現': 522, '動動': 523, '回溫': 524, '外加': 525, '多加': 526, '感謝': 527, '戴口罩': 528, '手填': 529, '於是': 530, '晚上': 531, '極光': 532, '水': 533, '油脂': 534, '混合': 535, '琥珀': 536, '瓶': 537, '粉刺': 538, '臉': 539, '藍色': 540, '補': 541, '酸': 542, '上市': 543, '乾': 544, '剛': 545, '好久': 546, '快速': 547, '拍攝': 548, '櫃姐': 549, '滿': 550, '皆': 551, '聽': 552, '見': 553, '質地': 554, '輕薄': 555, '鏡頭': 556, '限量': 557, '霧面': 558, '顏色': 559, '亞歷山大': 560, '台北': 561, '嘗試': 562, '女孩': 563, '日式': 564, '毛文': 565, '海神': 566, '無從': 567, '版上': 568, '經驗': 569, '除毛': 570, '下標': 571, '中間': 572, '妝': 573, '弱': 574, '彩妝師': 575, '畫': 576, '精華': 577, '罐': 578, '置入': 579, '腦波': 580, '腦粉': 581, '著': 582, '超愛': 583, '身為': 584, '內包': 585, '推': 586, '會長': 587, '痘印': 588, '皮膚科': 589, '藻針': 590, '⭕': 591, '作品': 592, '前後': 593, '副': 594, '台南市': 595, '喜好': 596, '地點': 597, '對': 598, '小時': 599, '底色': 600, '拋棄式': 601, '拍': 602, '操作': 603, '收集': 604, '新手': 605, '時間': 606, '更多': 607, '有無': 608, '東區': 609, '條件': 610, '眉型': 611, '私訊': 612, '討論': 613, '設計': 614, '貼文': 615, '配合': 616, '針具': 617, '非': 618, '️': 619, '一間': 620, '仿': 621, '公司': 622, '包': 623, '各式各樣': 624, '好奇': 625, '小三': 626, '工廠': 627, '應該': 628, '特地': 629, '美日': 630, '貴': 631, '賺': 632, '辦法': 633, '長得': 634, '難道': 635, '口服': 636, '台南': 637, '療程': 638, '請教': 639, '進行': 640, '⬆': 641, '不屑': 642, '不懈': 643, '不過': 644, '先來': 645, '出沒': 646, '圖': 647, '張': 648, '摳': 649, '摸到': 650, '撒花': 651, '社區': 652, '終於': 653, '經過': 654, '脖子': 655, '貓貓': 656, '逼出來': 657, '防雷': 658, '打電話': 659, '時代': 660, '有放': 661, '桌上': 662, '母親節': 663, '熱情': 664, '統一': 665, '逛街': 666, '預購': 667, 'ω': 668, '一點': 669, '上班': 670, '低調': 671, '偏白': 672, '友善': 673, '妝容': 674, '挑': 675, '搞定': 676, '整個': 677, '百搭': 678, '盤': 679, '眼影盤': 680, '膚色': 681, '芋芋': 682, '配色': 683, '體積': 684, '鮮奶': 685, '黃皮': 686, '之類': 687, '保濕': 688, '先擋': 689, '凝膠': 690, '剛好': 691, '化妝水': 692, '層': 693, '差': 694, '年近': 695, '後來': 696, '懶得': 697, '效果': 698, '時候': 699, '月': 700, '狀況': 701, '用了': 702, '用完': 703, '皮膚': 704, '精華液': 705, '著用': 706, '蘆薈': 707, '中午': 708, '失敗': 709, '學會': 710, '實實在在': 711, '就塌': 712, '手殘': 713, '擁有': 714, '教學': 715, '早上': 716, '朋朋': 717, '朋朋們': 718, '濃密': 719, '獨角獸': 720, '睫毛': 721, '細軟': 722, '翹': 723, '黏貼': 724, '˘': 725, '久': 726, '乾爹': 727, '廢人': 728, '心到': 729, '收回來': 730, '文章': 731, '新年': 732, '明明': 733, '求': 734, '秋子': 735, '程序': 736, '篇': 737, '結束': 738, '總之': 739, '轉變': 740, '連假': 741, '開工': 742, '꒰': 743, '꒱': 744, '問問': 745, '意見': 746, '推銷': 747, '提升': 748, '暗沉': 749, '粗糙': 750, '膚況': 751, '蠟黃': 752, '諮詢': 753, '通路': 754, '進一步': 755, '防曬': 756, '不行': 757, '包裝': 758, '台灣': 759, '奢華': 760, '櫃': 761, '氣到': 762, '氣墊': 763, '滑': 764, '發售': 765, '發摟到': 766, '粉紅': 767, '花去': 768, '訊息': 769, '錢': 770, '關注': 771, '隔壁': 772, '雅詩蘭黛': 773, '˃': 774, '̀': 775, '́': 776, '̶': 777, '͈': 778, 'و': 779, '௰': 780, '上圖': 781, '勤勞': 782, '大理石': 783, '好辣': 784, '小粉': 785, '打給': 786, '更新': 787, '洗': 788, '異常': 789, '翻翻': 790, '賣關子': 791, '遮瑕': 792, '齁': 793, '亮顏': 794, '優': 795, '口罩': 796, '型': 797, '度優': 798, '懇請': 799, '我塑': 800, '抗汗': 801, '持久': 802, '持妝': 803, '沾': 804, '爆汗': 805, '粉餅': 806, '綠色': 807, '膚質': 808, '蘭芝': 809, '訴求': 810, '雅': 811, '霧感': 812, '顆': 813, 'о': 814, '∀': 815, '一盒': 816, '三盒': 817, '元': 818, '划算': 819, '原價': 820, '名': 821, '寶雅': 822, '心中': 823, '有出': 824, '特價': 825, '盒': 826, '約會': 827, '超級': 828, '逛': 829, '隔天': 830, '面膜': 831, 'ㄧ': 832, '原生': 833, '參差不齊': 834, '哈嚕': 835, '完妝': 836, '尤里': 837, '整理': 838, '有長': 839, '潛水': 840, '版': 841, '短': 842, '緊張': 843, '缺口': 844, '莫名': 845, '處理': 846, '頑固': 847, '並': 848, '友好': 849, '台美': 850, '同盟': 851, '民主': 852, '美台': 853, '俄羅斯': 854, '假設': 855, '出征': 856, '勢必': 857, '北約': 858, '國家': 859, '導致': 860, '戰爭': 861, '打贏': 862, '撒野': 863, '最多': 864, '歐洲': 865, '歸屬於': 866, '波蘭': 867, '烏克蘭': 868, '理由': 869, '發起': 870, '緊鄰': 871, '讓給': 872, '門口': 873, '宜蘭縣': 874, '屏東縣': 875, '桃園市': 876, '臺東縣': 877, '苗栗縣': 878, '高雄市': 879, '停完': 880, '好多': 881, '處分': 882, '電後': 883, '領': 884, '仔': 885, '全': 886, '台': 887, '死忠': 888, '沒電': 889, '缺電': 890, '肺電': 891, '陪': 892, '任用': 893, '冠上': 894, '喜劇': 895, '國內': 896, '地區': 897, '外國': 898, '大失': 899, '大臣': 900, '媒體': 901, '導演': 902, '得票率': 903, '擔任': 904, '斯基': 905, '民心': 906, '演員': 907, '澤倫': 908, '為': 909, '烏東': 910, '無論': 911, '爭議': 912, '片場': 913, '當選': 914, '總統': 915, '腐敗': 916, '貪污': 917, '連任': 918, '開戰': 919, '高': 920, '供電': 921, '台電': 922, '員工': 923, '認真': 924, '責無旁貸': 925, '停電': 926, '國民黨': 927, '好事': 928, '好像': 929, '懂': 930, '抓到': 931, '機會': 932, '民進黨': 933, '為何': 934, '看來': 935, '罄竹難書': 936, '記得': 937, '過什麼': 938, '雞蛋': 939, '骨頭': 940, '鬥': 941, '到民': 942, '去年': 943, '問題': 944, '執政黨': 945, '增加': 946, '洗地': 947, '為啥': 948, '苗苗': 949, '選票': 950, '電網': 951, '馬政府': 952, '麽': 953, '核食': 954, '照句': 955, '疏失': 956, '福食': 957, '答': 958, '範例': 959, '解答': 960, '造樣': 961, '開放': 962, '題目': 963, '一團': 964, '中華民國': 965, '台派': 966, '名字': 967, '戰成': 968, '爸爸': 969, '講': 970, '跳針': 971, '開示': 972, '位於': 973, '俄軍': 974, '將': 975, '拜登': 976, '持續': 977, '攻勢': 978, '札': 979, '核電廠': 980, '波羅': 981, '火災': 982, '熱': 983, '白宮': 984, '稍早': 985, '致電': 986, '起火': 987, '世界': 988, '全體': 989, '各國': 990, '幫忙': 991, '殉國': 992, '烏俄': 993, '物資': 994, '英勇': 995, '誒': 996, '軍民': 997, '這麼': 998, '位當': 999, '供應': 1000, '內': 1001, '全世界': 1002, '出錯': 1003, '台灣人': 1004, '喔': 1005, '年': 1006, '拜託': 1007, '接受': 1008, '發生': 1009, '社畜': 1010, '藉口': 1011, '設施': 1012, '說出去': 1013, '這麼多': 1014, '點腦': 1015, '一早': 1016, '今早': 1017, '傳出': 1018, '公布': 1019, '凌晨': 1020, '台股': 1021, '壓低': 1022, '市場': 1023, '幣圈': 1024, '想必': 1025, '指數': 1026, '數據': 1027, '百點': 1028, '股市': 1029, '與': 1030, '跳空': 1031, '金融': 1032, '開低': 1033, '震撼彈': 1034, '非農': 1035, '介意': 1036, '依舊': 1037, '做出': 1038, '別': 1039, '南部人': 1040, '反駁': 1041, '同意': 1042, '攜手': 1043, '救': 1044, '明知道': 1045, '當初': 1046, '肚子': 1047, '自得': 1048, '自業': 1049, '這下': 1050, '選擇': 1051, '面臨': 1052, '餓': 1053, '下午': 1054, '下山': 1055, '佔': 1056, '停工': 1057, '即將': 1058, '太陽': 1059, '太陽能板': 1060, '手電筒': 1061, '有讀': 1062, '發電量': 1063, '看好': 1064, '過書': 1065, '出手': 1066, '富豪': 1067, '布丁': 1068, '攻下': 1069, '死亡': 1070, '首都': 1071, '駭客': 1072, '一檔': 1073, '中共': 1074, '主動': 1075, '之餘': 1076, '停': 1077, '出擊': 1078, '包子': 1079, '原因': 1080, '台大': 1081, '大戲': 1082, '害怕': 1083, '攻不下': 1084, '普丁': 1085, '演了': 1086, '習': 1087, '自顧不暇': 1088, '落': 1089, '蔡': 1090, '處境': 1091, '裡應外合': 1092, '誘使': 1093, '龐佩奧': 1094, '全民': 1095, '吃': 1096, '大便': 1097, '幹': 1098, '沒事': 1099, '給力': 1100, '詩': 1101, '閒暇': 1102, '一昧': 1103, '事': 1104, '公投': 1105, '奇怪': 1106, '底下': 1107, '承擔': 1108, '投反': 1109, '時': 1110, '核四': 1111, '片罵': 1112, '留言區': 1113, '當然': 1114, '負一': 1115, '負載': 1116, '責任': 1117, '路': 1118, '中俄': 1119, '侵略': 1120, '別國': 1121, '包圍': 1122, '可見': 1123, '哽咽': 1124, '坦克': 1125, '妄想': 1126, '家親': 1127, '戰場': 1128, '無情': 1129, '留學生': 1130, '舔': 1131, '萬無一失': 1132, '裝甲車': 1133, '語氣': 1134, '輛': 1135, '逃離': 1136, '逃難': 1137, '過程': 1138, '遭': 1139, '不斷': 1140, '中國人': 1141, '中國黨': 1142, '位覺': 1143, '侯友宜': 1144, '反饋': 1145, '在狄卡': 1146, '執政': 1147, '年來': 1148, '底層': 1149, '廢料': 1150, '意外': 1151, '柯': 1152, '核': 1153, '滯台': 1154, '發表': 1155, '社會': 1156, '聲稱': 1157, '言論': 1158, '質疑': 1159, '青給': 1160, '韓粉': 1161, '高潮': 1162, '高興': 1163, '一線': 1164, '不可能': 1165, '中央社': 1166, '人員': 1167, '你們': 1168, '依法': 1169, '偵辦': 1170, '免洗': 1171, '出事': 1172, '動作': 1173, '台鐵': 1174, '地檢署': 1175, '大樓': 1176, '指出': 1177, '政': 1178, '暖市': 1179, '永遠': 1180, '燒掉': 1181, '犯錯': 1182, '發抖': 1183, '究責': 1184, '第一槍': 1185, '系統': 1186, '絕對': 1187, '調查': 1188, '通知': 1189, '開': 1190, '面': 1191, '年終': 1192, '建議': 1193, '減半': 1194, '獎金': 1195, '納稅': 1196, '紕漏': 1197, '自首': 1198, '解決': 1199, '辛苦': 1200, '領著': 1201, '高雄': 1202, '高雄人': 1203, '⋯': 1204, '下定決心': 1205, '債務': 1206, '加一加': 1207, '卻': 1208, '回頭': 1209, '多萬': 1210, '家人': 1211, '戒賭': 1212, '手上': 1213, '打算': 1214, '拿去': 1215, '有錢': 1216, '欠': 1217, '沈迷': 1218, '無力': 1219, '簽': 1220, '組頭': 1221, '總共': 1222, '總是': 1223, '賭球': 1224, '賺錢': 1225, '軍官': 1226, '還債': 1227, '開口': 1228, '一年': 1229, '付清': 1230, '公務員': 1231, '公教': 1232, '卡費': 1233, '土銀': 1234, '在職': 1235, '太慢': 1236, '存款': 1237, '客服': 1238, '審核': 1239, '專案': 1240, '工作天': 1241, '年收': 1242, '房貸': 1243, '收到': 1244, '股票': 1245, '萬': 1246, '負債': 1247, '貸': 1248, '交流': 1249, '住': 1250, '分配': 1251, '多久': 1252, '存': 1253, '定存': 1254, '年紀': 1255, '年輕': 1256, '懂事': 1257, '房屋': 1258, '投資': 1259, '標的': 1260, '現金': 1261, '筆': 1262, '綁': 1263, '萬元': 1264, '計畫': 1265, '運用': 1266, '開心': 1267, '高雄市區': 1268, '低迷': 1269, '合約': 1270, '情緒': 1271, '懵了': 1272, '打開': 1273, '整體': 1274, '暴漲暴跌': 1275, '熊市': 1276, '現貨': 1277, '盤面': 1278, '稱為': 1279, '著急': 1280, '處於': 1281, '行情': 1282, '試試': 1283, '買入': 1284, '震盪': 1285, '頁面': 1286, '體驗': 1287, '低': 1288, '匯差': 1289, '台幣': 1290, '外幣': 1291, '多文': 1292, '手續費': 1293, '漲時': 1294, '爬': 1295, '美元': 1296, '買賣': 1297, '買進': 1298, '賣掉': 1299, '轉回': 1300, '關於': 1301, '交易': 1302, '以圖': 1303, '來選': 1304, '前言': 1305, '勝率': 1306, '專研': 1307, '成效': 1308, '檢視': 1309, '現象': 1310, '程式': 1311, '策略': 1312, '要用': 1313, '語言': 1314, '軟體': 1315, '默默': 1316, '刷': 1317, '刷卡': 1318, '房': 1319, '扣掉': 1320, '搭配': 1321, '訂了': 1322, '訂房': 1323, '退掉': 1324, '過了': 1325, '郵局': 1326, '金融卡': 1327, '間房': 1328, '下班': 1329, '休假': 1330, '住家': 1331, '供吃': 1332, '偶爾': 1333, '加油': 1334, '包含': 1335, '外食': 1336, '女友': 1337, '家裡': 1338, '收入': 1339, '月薪': 1340, '煮飯': 1341, '玩': 1342, '生活': 1343, '純': 1344, '苦': 1345, '被動': 1346, '陪伴': 1347, '頂多': 1348, '並非': 1349, '人性': 1350, '作': 1351, '來臨': 1352, '克服': 1353, '區塊': 1354, '大師級': 1355, '實質': 1356, '弱點': 1357, '心態': 1358, '心理': 1359, '心魔': 1360, '成功': 1361, '戰勝': 1362, '技巧': 1363, '控制': 1364, '炒': 1365, '無': 1366, '獲利': 1367, '自我': 1368, '英雄': 1369, '誰': 1370, '較量': 1371, '鏈': 1372, '靈魂': 1373, '高手': 1374, '鬥爭': 1375, '位置': 1376, '區間': 1377, '午夜': 1378, '反彈': 1379, '受阻': 1380, '回調': 1381, '壓力': 1382, '小幅': 1383, '後續': 1384, '拉升': 1385, '探底': 1386, '昨晚': 1387, '期間': 1388, '比特幣': 1389, '波': 1390, '突破': 1391, '線': 1392, '試探性': 1393, '財神': 1394, '走勢': 1395, '隨後': 1396, '串聯': 1397, '交易所': 1398, '加密': 1399, '帳戶': 1400, '幣安': 1401, '收益': 1402, '本金': 1403, '火幣': 1404, '當日': 1405, '註記': 1406, '資金': 1407, '下殺': 1408, '下跌': 1409, '下路': 1410, '創逾': 1411, '升息': 1412, '原物料': 1413, '工業': 1414, '漲幅': 1415, '聯準會': 1416, '股': 1417, '費半': 1418, '週': 1419, '道瓊': 1420, '達克': 1421, '那斯': 1422, '飽爾': 1423, '高科技': 1424, '交易量': 1425, '來得及': 1426, '大戶': 1427, '投': 1428, '折': 1429, '指定': 1430, '更換': 1431, '營業員': 1432, '爭取': 1433, '百萬': 1434, '線上': 1435, '變': 1436, '辦': 1437, '通過': 1438, '初心': 1439, '利率': 1440, '家族': 1441, '手': 1442, '操作手機': 1443, '放': 1444, '爸媽': 1445, '獲得': 1446, '稍微': 1447, '規劃': 1448, '閒置': 1449, '元大': 1450, '想過': 1451, '槓桿': 1452, '油油': 1453, '粉絲': 1454, '肥宅': 1455, '錢會': 1456, '長期': 1457, '\u200d': 1458, '其餘': 1459, '媽': 1460, '媽付': 1461, '存滿': 1462, '存錢': 1463, '存錢筒': 1464, '手機費': 1465, '月光族': 1466, '植牙': 1467, '美食': 1468, '舉手': 1469, '萬二': 1470, '薪資': 1471, '費': 1472, '購物': 1473, '開銷': 1474, '⠀': 1475, '一般人': 1476, '出國': 1477, '唸書': 1478, '大學': 1479, '小孩': 1480, '指': 1481, '教育金': 1482, '準備': 1483, '累積': 1484, '藉由': 1485, '談論': 1486, '費用': 1487, '較': 1488, '較長': 1489, '金額': 1490, '高等': 1491, '國泰': 1492, '據點': 1493, '旗下': 1494, '臨櫃': 1495, '證券戶': 1496, '辦理': 1497, '銀行': 1498, '開戶': 1499, '新光': 1500, '永豐': 1501, '版面': 1502, '證卷': 1503, '配置': 1504, '危險': 1505, '年化': 1506, '想法': 1507, '數百': 1508, '瞭解': 1509, '礦池': 1510, '聽到': 1511, '背後': 1512, '許多': 1513, '達到': 1514, '雙幣': 1515, '風險': 1516, '利嘛': 1517, '加碼': 1518, '感動': 1519, '變紅': 1520, '霸脫': 1521, '高點': 1522, '出借': 1523, '列表': 1524, '永豐金': 1525, '無法': 1526, '申請': 1527, '股息': 1528, '買過': 1529, '開發金': 1530, '分析': 1531, '卡': 1532, '在於': 1533, '大盤': 1534, '平日': 1535, '悲觀': 1536, '技術面': 1537, '提高': 1538, '時去': 1539, '有時': 1540, '目的': 1541, '看盤': 1542, '神明': 1543, '籌碼面': 1544, '落漆': 1545, '補強': 1546, '隨手': 1547, '面子': 1548, '佩服': 1549, '前情': 1550, '厲害': 1551, '外資': 1552, '大漲': 1553, '天下無敵': 1554, '巧合': 1555, '提': 1556, '族群': 1557, '答對': 1558, '美光': 1559, '臨晨': 1560, '航運': 1561, '調評': 1562, '難': 1563, '多去': 1564, '少新': 1565, '建商': 1566, '慘': 1567, '房仲': 1568, '房子': 1569, '持有': 1570, '捷運': 1571, '案例': 1572, '檯面': 1573, '蓋多': 1574, '賠': 1575, '賣房': 1576, '跌': 1577, '騙人': 1578, '上網': 1579, '保人': 1580, '在學': 1581, '工作': 1582, '查': 1583, '正職': 1584, '沒辦法': 1585, '能當': 1586, '頭期款': 1587, '選': 1588, '人問': 1589, '價值': 1590, '否認': 1591, '回事': 1592, '實話': 1593, '幣': 1594, '投機': 1595, '炒幣': 1596, '率是': 1597, '笨蛋': 1598, '行業': 1599, '中山': 1600, '事項': 1601, '動動手': 1602, '問卷': 1603, '單位': 1604, '國立': 1605, '填寫': 1606, '填答': 1607, '忙': 1608, '數位': 1609, '為例': 1610, '用戶': 1611, '研究': 1612, '要請': 1613, '誘因': 1614, '京子': 1615, '亮眼': 1616, '僅次於': 1617, '冠軍': 1618, '則': 1619, '剛典': 1620, '妻': 1621, '季八集': 1622, '安藤': 1623, '岩田': 1624, '成人級': 1625, '成績': 1626, '拿下': 1627, '排行': 1628, '改編': 1629, '政信': 1630, '旋即': 1631, '日劇': 1632, '曾經': 1633, '本劇': 1634, '殭屍': 1635, '漫畫': 1636, '熱播': 1637, '熱銷': 1638, '登上': 1639, '篠原涼子': 1640, '金魚': 1641, '長谷川': 1642, '開播': 1643, '黑澤': 1644, '不聞不問': 1645, '人群': 1646, '孩子': 1647, '幫助': 1648, '新': 1649, '法官': 1650, '注視': 1651, '海報': 1652, '淚目': 1653, '漠然': 1654, '理念': 1655, '發布': 1656, '立場': 1657, '羅瑾熙': 1658, '部長': 1659, '青少年': 1660, '上線': 1661, '十月': 1662, '底': 1663, '獵人': 1664, '⌚': 1665, '上架': 1666, '傳記': 1667, '冒險片': 1668, '劇情': 1669, '旗幟': 1670, '極地': 1671, '歷史': 1672, '海賊': 1673, '滿愛': 1674, '議題': 1675, '這禮拜': 1676, '電影': 1677, '霜雪': 1678, '鬼怪': 1679, '🥇': 1680, '🥈': 1681, '🥉': 1682, '原來': 1683, '搞': 1684, '笑死': 1685, '轉': 1686, '主角': 1687, '主題曲': 1688, '作為': 1689, '劇中': 1690, '告別': 1691, '崔宥莉': 1692, '心情': 1693, '心愛': 1694, '悲傷': 1695, '慢慢': 1696, '描述': 1697, '收聽': 1698, '有限': 1699, '歌手': 1700, '歌曲': 1701, '燦榮': 1702, '生命': 1703, '田美': 1704, '發行': 1705, '網站': 1706, '鄭': 1707, '音源': 1708, '一集': 1709, '三大': 1710, '了本': 1711, '全球': 1712, '厭惡': 1713, '口碑': 1714, '少年': 1715, '少年犯': 1716, '法庭': 1717, '為止': 1718, '特色': 1719, '犯罪': 1720, '發酵': 1721, '至極': 1722, '英語': 1723, '觀眾': 1724, '說明': 1725, '躍升': 1726, '金惠秀': 1727, '開宗明義': 1728, '韓國': 1729, '題材': 1730, '飾演': 1731, '首度': 1732, '不適': 1733, '佐': 1734, '律師': 1735, '文森': 1736, '殘忍': 1737, '特別': 1738, '結局': 1739, '臥床': 1740, '身體': 1741, '遊戲': 1742, '驅魔': 1743, '魷魚': 1744, '麵館': 1745, '黑道': 1746, '二十五二十一': 1747, '保重': 1748, '劇組': 1749, '南柱赫': 1750, '影響': 1751, '恢復': 1752, '播出': 1753, '新冠': 1754, '日後': 1755, '檢測': 1756, '泰梨': 1757, '為事': 1758, '確診': 1759, '肺炎': 1760, '苞娜': 1761, '週末': 1762, '金泰梨': 1763, '陰性': 1764, '隔離': 1765, '下一集': 1766, '手點': 1767, '播放': 1768, '智慧': 1769, '求助': 1770, '自動': 1771, '超過': 1772, '電腦': 1773, '電視': 1774, '受': 1775, '圖用': 1776, '失望': 1777, '好評': 1778, '密碼': 1779, '廁所': 1780, '愛上': 1781, '男女': 1782, '痛苦': 1783, '相親': 1784, '看完': 1785, '社內': 1786, '等待': 1787, '集': 1788, '集換': 1789, '順': 1790, '馬上': 1791, '劇': 1792, '合作': 1793, '審判': 1794, '律政': 1795, '日': 1796, '洪': 1797, '私生活': 1798, '編劇': 1799, '金玟錫': 1800, '鍾燦': 1801, '韓語': 1802, '년': 1803, '소': 1804, '심': 1805, '판': 1806, '一月份': 1807, '中華': 1808, '二月': 1809, '付': 1810, '份': 1811, '信用卡': 1812, '帳單': 1813, '月租費': 1814, '盜刷': 1815, '肯定': 1816, '自從': 1817, '計費': 1818, '週期': 1819, '電信': 1820, '季播': 1821, '黑鏡': 1822, '下載': 1823, '人用': 1824, '字幕': 1825, '字體': 1826, '應用': 1827, '網頁版': 1828, '同時': 1829, '觀看': 1830, '作畫': 1831, '健': 1832, '出水': 1833, '判官': 1834, '動畫': 1835, '原創': 1836, '國王': 1837, '小圓': 1838, '小畑': 1839, '巨人': 1840, '心靈': 1841, '排名': 1842, '東京': 1843, '淹水': 1844, '潮到': 1845, '虛淵玄': 1846, '製作': 1847, '角色': 1848, '進擊': 1849, '魔法': 1850, '具': 1851, '原': 1852, '娑婆': 1853, '封': 1854, '專輯': 1855, '小將': 1856, '景伊': 1857, '柔美': 1858, '毒樓': 1859, '法院': 1860, '泰成': 1861, '監製': 1862, '祭司': 1863, '紙牌屋': 1864, '細胞': 1865, '聲帶': 1866, '訶': 1867, '那一天': 1868, '配樂': 1869, '金': 1870, '雪降': 1871, '電視劇': 1872, '音樂': 1873, '黎明': 1874, '黑': 1875, '些能': 1876, '人身': 1877, '壞': 1878, '多數': 1879, '家庭': 1880, '少數': 1881, '必須': 1882, '成了': 1883, '教育出': 1884, '歸咎於': 1885, '規避': 1886, '過錯': 1887, '雖說': 1888, '名稱': 1889, '嗚': 1890, '嗚嗚': 1891, '城市': 1892, '好好笑': 1893, '捨不得': 1894, '期待': 1895, '翻拍': 1896, '聽說': 1897, '上來': 1898, '下手': 1899, '不出': 1900, '大神': 1901, '女子': 1902, '小說': 1903, '所以然': 1904, '查了': 1905, '查查': 1906, '版本': 1907, '興趣': 1908, '順序': 1909, '🤨': 1910, '一部': 1911, '保健': 1912, '傑克': 1913, '戲': 1914, '拿走': 1915, '提問': 1916, '當天': 1917, '腎上腺素': 1918, '自殺': 1919, '賽門': 1920, '小黑': 1921, '查不到': 1922, '白癡': 1923, '能用': 1924, '蘋果': 1925, '訂閱': 1926, '主演': 1927, '取自': 1928, '圍繞': 1929, '季': 1930, '季度': 1931, '極度': 1932, '秀': 1933, '節目': 1934, '簡介': 1935, '處決': 1936, '討厭': 1937, '認同': 1938, '講述': 1939, '金憓': 1940, '金武烈': 1941, '韓劇': 1942, '人權': 1943, '口號': 1944, '和平': 1945, '回應': 1946, '失': 1947, '屬於': 1948, '廣場': 1949, '抱有': 1950, '換來': 1951, '政府': 1952, '暴力': 1953, '最初': 1954, '未來': 1955, '演變成': 1956, '獨立': 1957, '當時': 1958, '發展': 1959, '百': 1960, '萬人': 1961, '血腥': 1962, '見證': 1963, '運動': 1964, '革命': 1965, '齊聚': 1966, '封面': 1967, '演唱': 1968, '熱烈': 1969, '男團': 1970, 'Д': 1971, 'ຶ': 1972, '不長': 1973, '分局': 1974, '影集': 1975, '推爆': 1976, '耐看': 1977, '荒謬': 1978, '追': 1979, '前三集': 1980, '寫實': 1981, '悶': 1982, '服裝': 1983, '板發': 1984, '格陵蘭': 1985, '正傳': 1986, '段': 1987, '海豹': 1988, '渡海': 1989, '無聊': 1990, '皮': 1991, '細緻': 1992, '老實': 1993, '考據': 1994, '船': 1995, '部': 1996, '部位': 1997, '共鳴': 1998, '大推': 1999, '性格': 2000, '提到': 2001, '海嘯': 2002, '疫情': 2003, '聲音': 2004, '討喜': 2005, '讚美': 2006, '重雷': 2007, '開頭': 2008}
In [58]:
print(dictionary)
Dictionary(2009 unique tokens: ['位', '個', '填', '希望', '幫']...)
In [59]:
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
In [60]:
dictionary.num_docs
Out[60]:
140
- You can change the value of
docidto any number between 0 and 139.
In [61]:
docid = 73
raw_text_in_corpus = sample_df.loc[docid,'excerpt']
tokens_in_raw_text = sample_df.loc[docid,'toks']
print("Raw sample text:")
print(raw_text_in_corpus)
print("Tokens of sample text:")
print(tokens_in_raw_text)
Raw sample text: 一個是等烏克蘭首都被攻下,一個是等布丁死亡,有俄羅斯自家富豪出手了,BTW俄羅斯自家的駭客也在幫忙打布丁 Tokens of sample text: ['個', '烏克蘭', '首都', '攻下', '個', '布丁', '死亡', '俄羅斯', '富豪', '出手', '俄羅斯', '駭客', '幫忙', '布丁']
- A gensim corpus stores a mapping between word IDs and their frequencies in a document.
In [62]:
corpus[docid]
Out[62]:
[(1, 2), (854, 2), (868, 1), (991, 1), (1066, 1), (1067, 1), (1068, 2), (1069, 1), (1070, 1), (1071, 1), (1072, 1)]
In [63]:
for id, freq in corpus[docid]:
print(f"{dictionary[id]} >>> occurs {freq} times(s) in this doc")
個 >>> occurs 2 times(s) in this doc 俄羅斯 >>> occurs 2 times(s) in this doc 烏克蘭 >>> occurs 1 times(s) in this doc 幫忙 >>> occurs 1 times(s) in this doc 出手 >>> occurs 1 times(s) in this doc 富豪 >>> occurs 1 times(s) in this doc 布丁 >>> occurs 2 times(s) in this doc 攻下 >>> occurs 1 times(s) in this doc 死亡 >>> occurs 1 times(s) in this doc 首都 >>> occurs 1 times(s) in this doc 駭客 >>> occurs 1 times(s) in this doc
- A gensim model stores a mapping between word IDs and their scores as measured by that model based on the corpus.
In [64]:
tfidf[corpus[docid]]
Out[64]:
[(1, 0.15147118274062674), (854, 0.3716399607099024), (868, 0.15304212827789748), (991, 0.23691682188324237), (1066, 0.2755700903370344), (1067, 0.2755700903370344), (1068, 0.5511401806740688), (1069, 0.2755700903370344), (1070, 0.2755700903370344), (1071, 0.2755700903370344), (1072, 0.2755700903370344)]
In [65]:
for id, score in tfidf[corpus[docid]]:
print(f"{dictionary[id]} >>> whose tfidf is {score} in the corpus")
個 >>> whose tfidf is 0.15147118274062674 in the corpus 俄羅斯 >>> whose tfidf is 0.3716399607099024 in the corpus 烏克蘭 >>> whose tfidf is 0.15304212827789748 in the corpus 幫忙 >>> whose tfidf is 0.23691682188324237 in the corpus 出手 >>> whose tfidf is 0.2755700903370344 in the corpus 富豪 >>> whose tfidf is 0.2755700903370344 in the corpus 布丁 >>> whose tfidf is 0.5511401806740688 in the corpus 攻下 >>> whose tfidf is 0.2755700903370344 in the corpus 死亡 >>> whose tfidf is 0.2755700903370344 in the corpus 首都 >>> whose tfidf is 0.2755700903370344 in the corpus 駭客 >>> whose tfidf is 0.2755700903370344 in the corpus
- With the TF-IDF model, we can now convert any word in the corpus to a number.
- To convert a document into number, we'll need the Document-Term Matrix (DTM).
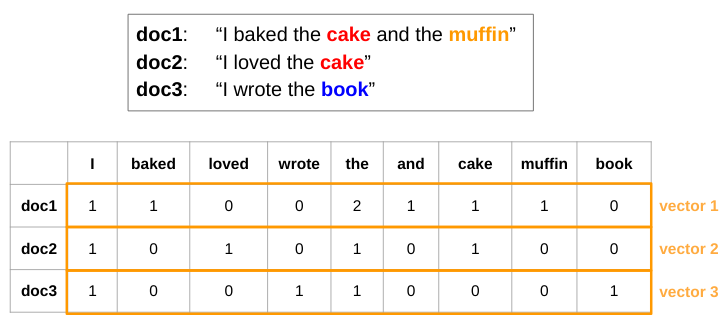
In [66]:
def vectorize_doc(docid):
id_tfidf = tfidf[corpus[docid]]
vector = {dictionary[id]: tfidf for id, tfidf in id_tfidf}
return vector
In [67]:
dtm_data = [vectorize_doc(docid) for docid in sample_df.index]
dtm_df = pd.DataFrame(dtm_data)
dtm_df.fillna(0, inplace=True)
In [68]:
dtm_df
Out[68]:
| 位 | 個 | 填 | 希望 | 幫 | 秒 | 花 | 囝仔 | 圖是 | 套 | ... | 大推 | 性格 | 提到 | 海嘯 | 疫情 | 聲音 | 討喜 | 讚美 | 重雷 | 開頭 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.281965 | 0.155875 | 0.487609 | 0.328501 | 0.343826 | 0.487609 | 0.441073 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 1 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.292414 | 0.292414 | 0.227406 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 2 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 3 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 4 | 0.127547 | 0.070510 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 135 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 136 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 137 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 138 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 139 | 0.112257 | 0.062058 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.225801 | 0.225801 | 0.225801 | 0.225801 | 0.225801 | 0.225801 | 0.225801 | 0.225801 | 0.225801 | 0.225801 |
140 rows × 2009 columns
- Each document can now be prepresented by a vector in 2009 dimensions.
In [69]:
text = sample_df.loc[docid, "excerpt"]
vec = dtm_df.loc[docid]
print(f"Text:\n{text}")
print(f"Vector:\n{vec}")
Text:
一個是等烏克蘭首都被攻下,一個是等布丁死亡,有俄羅斯自家富豪出手了,BTW俄羅斯自家的駭客也在幫忙打布丁
Vector:
位 0.000000
個 0.151471
填 0.000000
希望 0.000000
幫 0.000000
...
聲音 0.000000
討喜 0.000000
讚美 0.000000
重雷 0.000000
開頭 0.000000
Name: 73, Length: 2009, dtype: float64
- Disadvantages of TF-IDF
- A document is represented by a vector in N dimensions (where N==size of the vocab).
- The values of many dimensions in a vector are 0 (called
sparse vectors).
PCA (Principal Component Analysis)¶
- PCA, a technique for reducing dimensions

In [70]:
from sklearn.decomposition import PCA
import numpy as np
import plotly.express as px
/usr/local/lib/python3.7/dist-packages/distributed/config.py:20: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details. defaults = yaml.load(f)
- With PCA, we can easily reduce the dimension of a document vector from 2009 to 20.
- After the reduction, a sparse vector becomes a dense one.
In [71]:
pca = PCA(n_components=20)
transformed_data = pca.fit_transform(dtm_df)
transformed_data[docid]
Out[71]:
array([-0.09593937, 0.08866023, 0.07769523, -0.09343106, -0.20431264,
0.139582 , -0.29602169, -0.02982684, -0.24764987, -0.02938505,
0.04872477, 0.04076477, 0.04735796, 0.0764895 , -0.13701334,
0.00522563, 0.00850476, 0.03513411, 0.05439893, 0.07387785])
In [72]:
!pip install --upgrade plotly
Requirement already satisfied: plotly in /usr/local/lib/python3.7/dist-packages (5.6.0) Requirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from plotly) (1.15.0) Requirement already satisfied: tenacity>=6.2.0 in /usr/local/lib/python3.7/dist-packages (from plotly) (8.0.1) WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
In [73]:
!pip install pyyaml==5.4.1
Requirement already satisfied: pyyaml==5.4.1 in /usr/local/lib/python3.7/dist-packages (5.4.1) WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
In [74]:
pca = PCA(n_components=120)
pca.fit(dtm_df)
exp_var_cumul = np.cumsum(pca.explained_variance_ratio_ * 100)
px.area(
x=range(1, exp_var_cumul.shape[0] + 1),
y=exp_var_cumul,
labels={"x": "# Components", "y": "Explained Variance %"}
)
In [75]:
pca = PCA(n_components=3)
components = pca.fit_transform(dtm_df)
total_var = pca.explained_variance_ratio_.sum() * 100
px.scatter_3d(
components, x=0, y=1, z=2, color=sample_df['forum_en'],
title=f'Total explained variance: {total_var:.2f}%',
labels={'0': 'PC 1', '1': 'PC 2', '2': 'PC 3'}
)
In [76]:
from gensim import similarities
In [77]:
def search_by_tfidf(tokenized_text: list) -> tuple:
vec_bow = dictionary.doc2bow(tokenized_text)
vec_tfidf = tfidf[vec_bow]
index = similarities.MatrixSimilarity(tfidf[corpus])
sims = index[vec_tfidf]
sims = sorted(enumerate(sims), key=lambda item: item[1], reverse=True)
indexes = [tup[0] for tup in sims]
scores = [tup[1] for tup in sims]
return (indexes, scores)
- You can change the value of
docidto any number between 0 and 149.
In [78]:
docid = 73
tokens_in_raw_text = sample_df.loc[docid,'toks']
indexes, scores = search_by_tfidf(tokens_in_raw_text)
results_df = sample_df.loc[indexes][['excerpt', 'forum_en', 'forum_zh']]
results_df['tfidf_sim'] = scores
results_df
Out[78]:
| excerpt | forum_en | forum_zh | tfidf_sim | |
|---|---|---|---|---|
| 73 | 一個是等烏克蘭首都被攻下,一個是等布丁死亡,有俄羅斯自家富豪出手了,BTW俄羅斯自家的駭客也... | trending | 時事 | 1.000000 |
| 57 | 現在最多支持俄羅斯發起戰爭的理由就是這個了,假設今天俄羅斯打贏了,烏克蘭歸屬於俄羅斯,結果北... | trending | 時事 | 0.253894 |
| 74 | 全台大停電我只想只有一個原因!,美國看到俄羅斯就攻不下烏克蘭,想要在俄羅斯自顧不暇之餘誘使中... | trending | 時事 | 0.119545 |
| 68 | 誒,烏俄戰爭都打這麼久了 ,世界各國只是物資上的幫忙,是想要看烏克蘭全體軍民英勇殉國嗎? | trending | 時事 | 0.083784 |
| 70 | 想必有操作金融市場的朋友,不管是股市或幣圈,今早都來了一個震撼彈。台股指數跳空開低4百點,幣... | trending | 時事 | 0.069376 |
| ... | ... | ... | ... | ... |
| 128 | 《少年法院》的原聲帶配樂由音樂導演金泰成監製,電影有「1987:黎明到來的那一天」「黑祭司」... | netflix | Netflix | 0.000000 |
| 130 | 第一次看到城市名稱這麼有感覺的 好好笑,真的好捨不得結束哦嗚嗚嗚,聽說韓國要翻拍了,期待期待! | netflix | Netflix | 0.000000 |
| 136 | 《二十五,二十一》第五首原聲帶歌曲由男團SEVENTEEN的DK來擔任,在當DK要演唱原聲帶... | netflix | Netflix | 0.000000 |
| 137 | 我想問有沒有類似荒謬分局那種一集時間不長,但是很耐看,很多季的影集嗎(;´༎ຶД༎ຶ`),最... | netflix | Netflix | 0.000000 |
| 138 | 借板發一下,感謝。1這部老實講比正傳悶,悶很多,有點小失望,看前三集除了格陵蘭人渡海那段,其... | netflix | Netflix | 0.000000 |
140 rows × 4 columns
Distributional representation¶
Distributional hypothesis: Linguistic items with similar distributions have similar meanings. (Wikipedia)

word2vec¶
- Input: number of all unique words
- Output: dimensions of a word vector
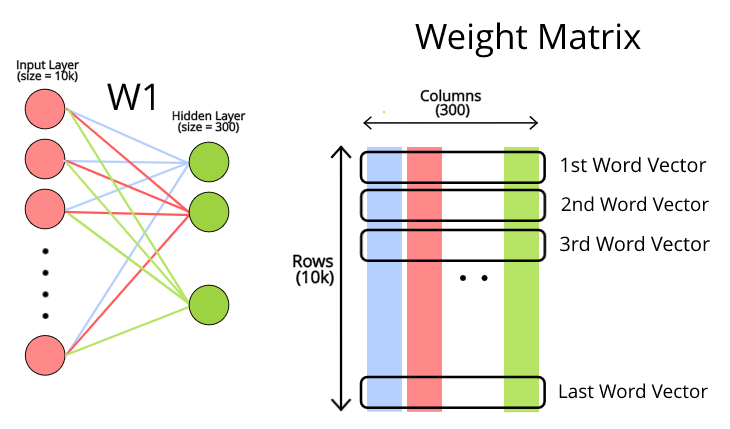
- Window size: 5
- Training mission: predict the targt word from context words
- Target word: the word in blue
- Context words: the words in red

- A token is represented by a 300-dimension dense vector.
In [79]:
doc = nlp("教授")
tok = doc[0]
tok.vector
Out[79]:
array([ 2.2328 , -1.1713 , -3.3528 , -1.1691 , -0.26724 , 4.4476 ,
-0.66089 , 2.6248 , -1.5367 , -2.8449 , -4.0233 , 1.5727 ,
1.978 , 2.7964 , 1.003 , 0.29978 , 0.056525, 3.7048 ,
2.0446 , 2.2452 , -5.7184 , 0.77814 , -1.8383 , -0.017231,
-1.91 , -6.4355 , -4.6737 , -0.13519 , 0.66087 , -1.6718 ,
3.5934 , 2.3382 , -4.5406 , 1.6124 , -2.2361 , -6.0387 ,
-3.4078 , 1.1304 , 0.80933 , 1.9734 , 2.3314 , -0.9882 ,
-1.1947 , 2.2628 , -1.3687 , -6.4278 , 0.15906 , 0.047335,
-2.8157 , -1.6407 , 2.4385 , -0.84336 , 3.081 , 5.9188 ,
-1.3019 , 1.2971 , 7.2325 , 2.9722 , -0.45552 , 1.5148 ,
-1.1193 , 3.8739 , 1.482 , -2.4657 , 1.4627 , -3.562 ,
-2.1737 , -1.4306 , 3.4363 , -1.2796 , -1.4106 , 2.2146 ,
2.9325 , -2.5172 , 2.7192 , -0.84556 , -2.5362 , 2.2079 ,
-3.2217 , -2.2081 , 4.6204 , 0.98445 , -0.53713 , 1.5325 ,
0.60471 , 1.774 , 2.5593 , 4.8882 , -2.9012 , 0.56529 ,
-0.16369 , -2.6124 , -0.89601 , 3.6279 , -3.0837 , 7.4534 ,
5.5267 , 0.30507 , -0.21904 , 2.1489 , -3.5027 , -2.8241 ,
1.7284 , -1.7447 , 0.05638 , -7.6138 , -3.8239 , -0.44218 ,
2.7571 , 2.5495 , -3.6081 , -0.30223 , 2.2124 , -0.82708 ,
-1.4102 , -0.81168 , -1.8045 , 1.6797 , -0.43188 , -2.769 ,
-4.9266 , 1.0018 , 0.022032, 1.6223 , -0.097899, 1.541 ,
-4.1115 , -4.2305 , -2.0175 , -2.7113 , 1.8462 , 1.115 ,
-2.4203 , 7.1492 , -1.3467 , 5.1815 , -1.6418 , -0.90401 ,
-0.030428, 2.4756 , -3.3246 , 1.2715 , -3.9147 , -2.4505 ,
-1.9256 , 0.61014 , 1.52 , 0.20039 , 6.3868 , -3.6932 ,
-0.25369 , 1.993 , 1.2806 , -1.4946 , -3.8367 , 0.44791 ,
2.2502 , 2.687 , -1.9332 , 1.6963 , 3.1247 , -4.6094 ,
-0.90111 , 4.4618 , -5.5256 , -0.044889, -1.496 , 2.8646 ,
1.9181 , 0.82574 , 0.024646, -4.0564 , 1.1392 , -1.8365 ,
-0.38447 , 0.063265, 1.2402 , -0.45659 , -1.7064 , -3.4588 ,
-0.23503 , -3.1285 , -2.8034 , 2.1534 , -1.2622 , -4.0139 ,
-3.3527 , 3.9156 , 4.1822 , -1.1544 , -1.8433 , -3.4078 ,
0.43852 , -1.3131 , -0.92715 , 4.6758 , 1.8561 , 3.4259 ,
1.2407 , -0.10015 , -0.4736 , -1.1884 , 2.5849 , -1.7642 ,
-5.4619 , 2.8648 , 5.4742 , -1.9069 , 0.87298 , -3.3007 ,
0.64926 , 1.2753 , 0.57441 , 5.3602 , 3.4332 , -3.4726 ,
0.41052 , -4.5747 , 1.3222 , 0.64865 , -1.7875 , 0.68921 ,
-0.16166 , 2.2868 , 0.91401 , 1.388 , 7.0462 , -1.5426 ,
0.47719 , -3.237 , -1.0982 , 4.7626 , 3.4092 , -0.2124 ,
-0.4526 , 4.4247 , -0.83311 , -0.99074 , 2.1257 , -0.91728 ,
2.3176 , 0.91452 , -1.436 , 2.2201 , 0.90931 , -0.46145 ,
-1.7671 , -1.594 , 1.4875 , -3.7585 , -3.826 , 4.4597 ,
-8.0136 , -1.7391 , -4.4454 , 1.2797 , 1.2241 , -0.85194 ,
0.42698 , -0.9868 , -5.0362 , -6.1074 , 3.8487 , 3.2342 ,
1.6124 , -1.2368 , -1.0743 , -1.1119 , 2.7379 , 4.4379 ,
3.8747 , 0.83282 , -4.6553 , -1.303 , -0.27529 , -1.2466 ,
-1.5356 , -4.7198 , -5.2186 , 1.2375 , 1.3111 , -0.26792 ,
0.79845 , -0.25837 , 2.2433 , -2.5042 , 2.5327 , 1.6947 ,
-3.1678 , -0.55927 , -1.17 , -1.2356 , 0.3977 , 1.8565 ,
-1.4511 , 2.0813 , 1.5979 , -0.50737 , 2.5565 , 0.63113 ],
dtype=float32)
In [80]:
tok.vector.shape
Out[80]:
(300,)
- You can try to replace the values of
word_1,word_2, andword_3to other Chinese words.
In [81]:
word_1 = nlp.vocab["高興"]
word_2 = nlp.vocab["高雄"]
word_3 = nlp.vocab["開心"]
word_1_word_2 = word_1.similarity(word_2)
word_1_word_3 = word_1.similarity(word_3)
print(f"Distance btn Word 1 and 2: {word_1_word_2}")
print(f"Distance btn Word 1 and 3: {word_1_word_3}")
Distance btn Word 1 and 2: 0.27085748314857483 Distance btn Word 1 and 3: 0.8141297101974487
- Cosine similarity

- Formula for calculating cosine similarity between two vectors
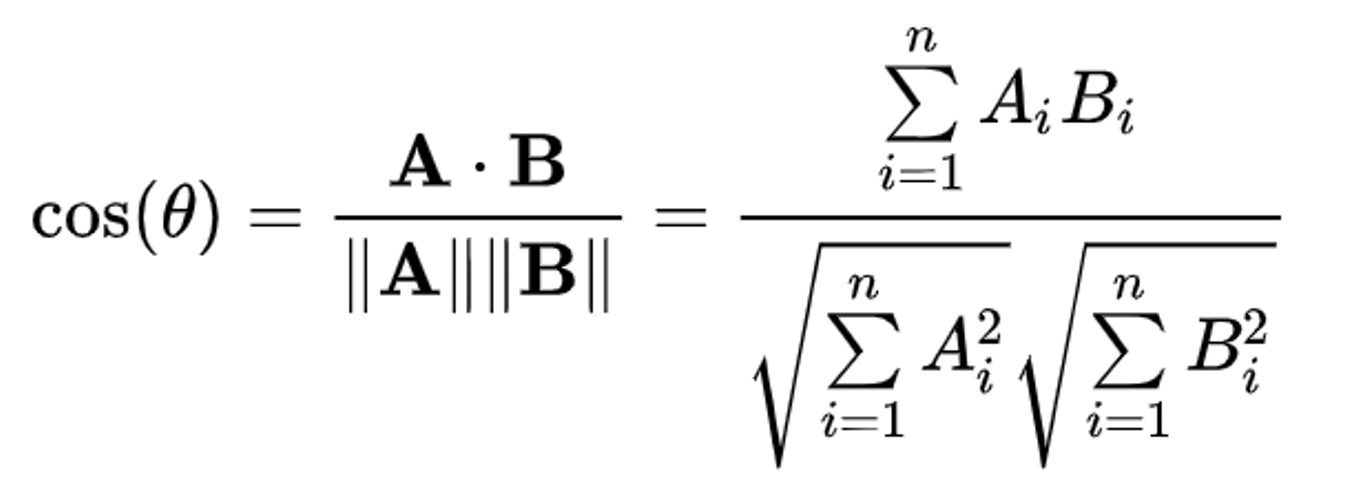
- You can replace the numbers
79,80, and139with any number between 0 and 139.
In [82]:
text_1 = sample_df.loc[73, "excerpt"]
text_2 = sample_df.loc[74, "excerpt"]
text_3 = sample_df.loc[139, "excerpt"]
print(f"Text 1 > {text_1}")
print(f"Text 2 > {text_2}")
print(f"Text 3 > {text_3}")
Text 1 > 一個是等烏克蘭首都被攻下,一個是等布丁死亡,有俄羅斯自家富豪出手了,BTW俄羅斯自家的駭客也在幫忙打布丁 Text 2 > 全台大停電我只想只有一個原因!,美國看到俄羅斯就攻不下烏克蘭,想要在俄羅斯自顧不暇之餘誘使中共主動出擊,龐佩奧才和蔡總統裡應外合演了停電的一檔大戲!,雖然習包子害怕自己落的跟普丁一樣的處境,在台灣大停 Text 3 > #重雷,因為版上都是讚美的聲音…,其實幾位主角性格都很討喜,只是太多人大大大推了 個人看了反而有點小失望,第一集開頭用2020疫情和1997金融海嘯來提到,「時代影響了很多人」也覺得很有共鳴,因為我們
In [83]:
doc_1 = nlp(text_1)
doc_2 = nlp(text_2)
doc_3 = nlp(text_3)
doc_1_doc_2 = doc_1.similarity(doc_2)
doc_1_doc_3 = doc_1.similarity(doc_3)
print(f"Distance btn Text 1 and 2: {doc_1_doc_2}")
print(f"Distance btn Text 1 and 3: {doc_1_doc_3}")
Distance btn Text 1 and 2: 0.9008373137883697 Distance btn Text 1 and 3: 0.8674700824214483
- If you're trying to be creative, feel free to replace the sentences for
doc01,doc02, anddoc03with any Chinese texts.
In [84]:
doc01 = nlp("防Omicron威脅 一至三類今起可打第3劑")
doc02 = nlp("第3劑開打…賣場設站隨到隨打 首波4.8萬人符資格")
doc03 = nlp("西半部低溫特報 全台平地最冷在基隆僅8度")
sim01 = doc01.similarity(doc02)
sim02 = doc01.similarity(doc03)
print(f"Distance btn Text 1 and 2: {sim01}")
print(f"Distance btn Text 1 and 3: {sim02}")
Distance btn Text 1 and 2: 0.5731685167538273 Distance btn Text 1 and 3: 0.4037113663445769
Distributed representation¶
Transformer¶
- Transformer is a deep learning architecture for transforming one sequence to another.
- It's the foundation of many state-of-the-art models, including BERT and GPT.
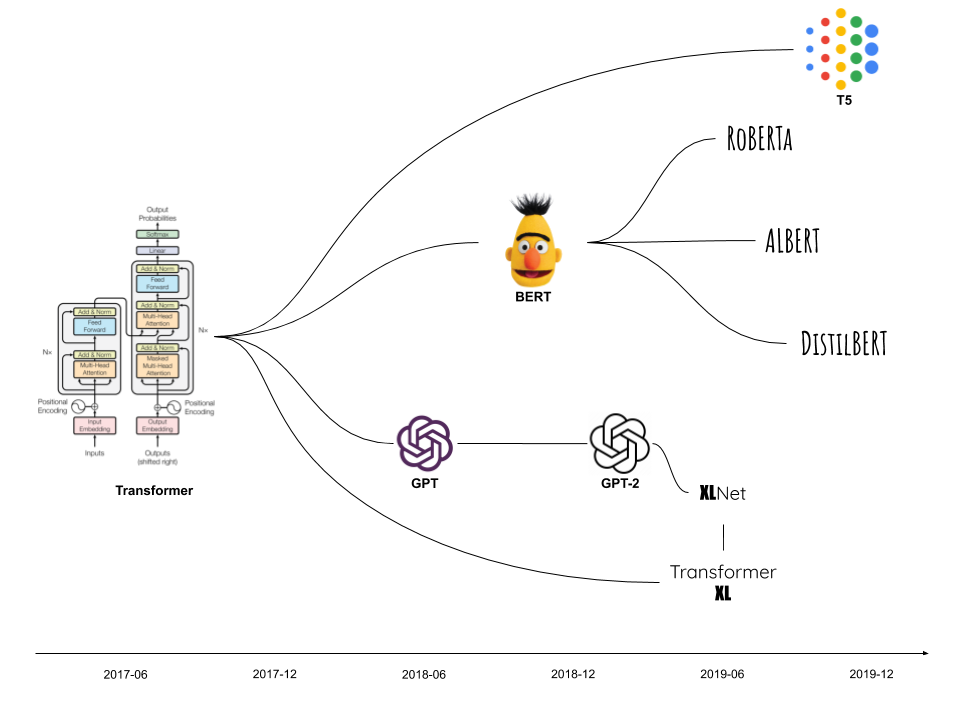
- Disadvantages of distributional representation like word2vec
- A given token is represented by the same vector irrespective of its context.

- Disadvantages of distributional representation like word2vec
- A word out of the vocabulary scope has no vector.

- Disadvantages of distributional representation like word2vec
- The relationship holding between words may go beyond the window size.

- Transformer solves all these problems and its killing feature is self-attention.
![]()
Transfer learning¶
![]()
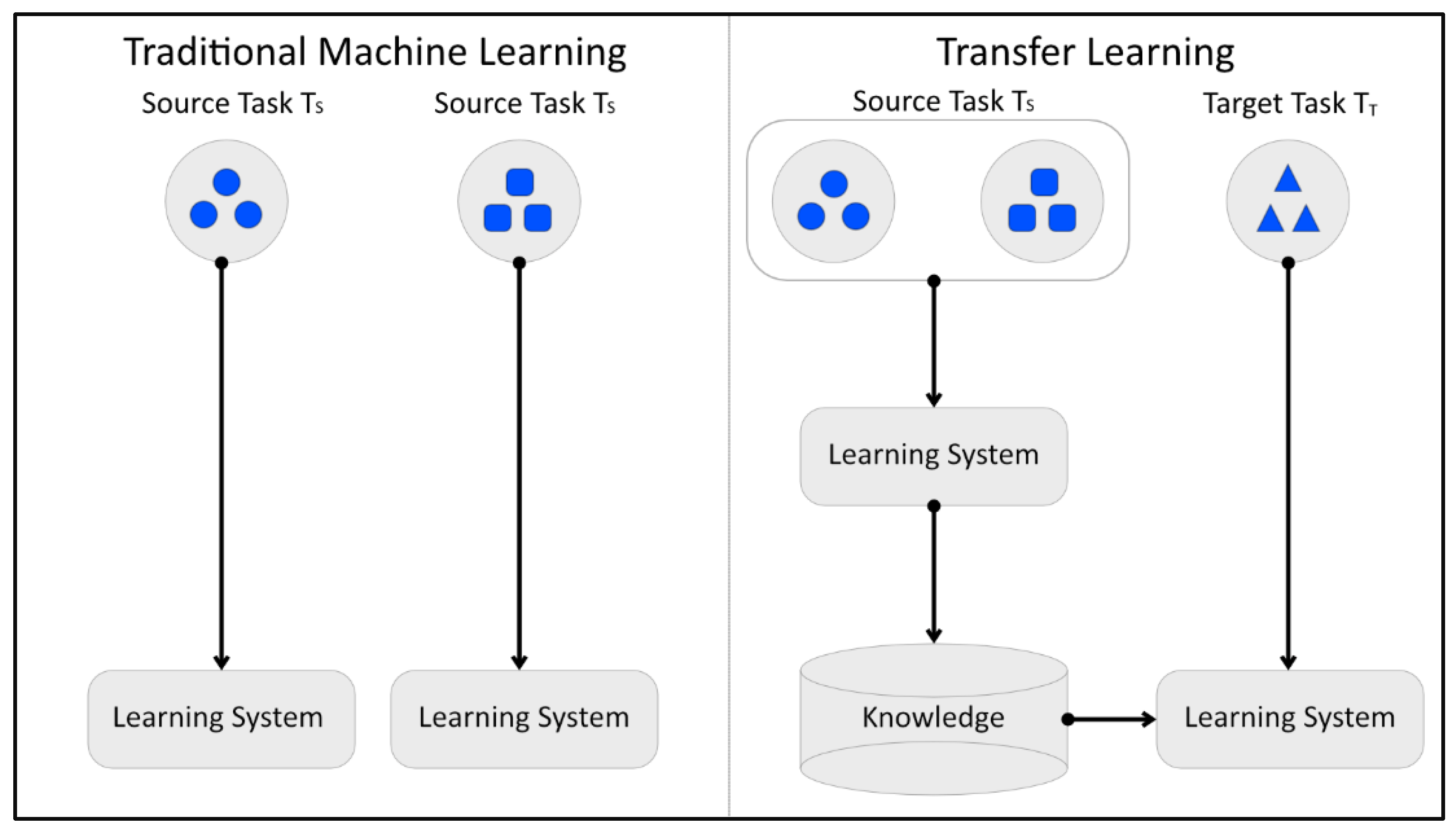
Intuition of transfer learning¶
- Transfer learning taps into a skill previously learned when one tries to learn a new skill.

- In traditional machine learning, a model learns from scratch.
- In transfer learning, a model reuses the knowledge that a previously trained model has learned.
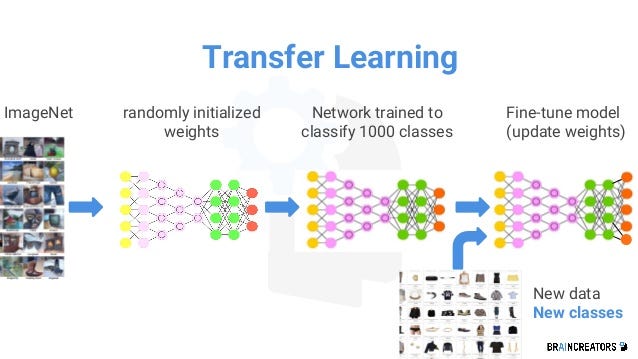
- In deep learning, the knowledge gained in a trained model is mathematically weights of model parameters.
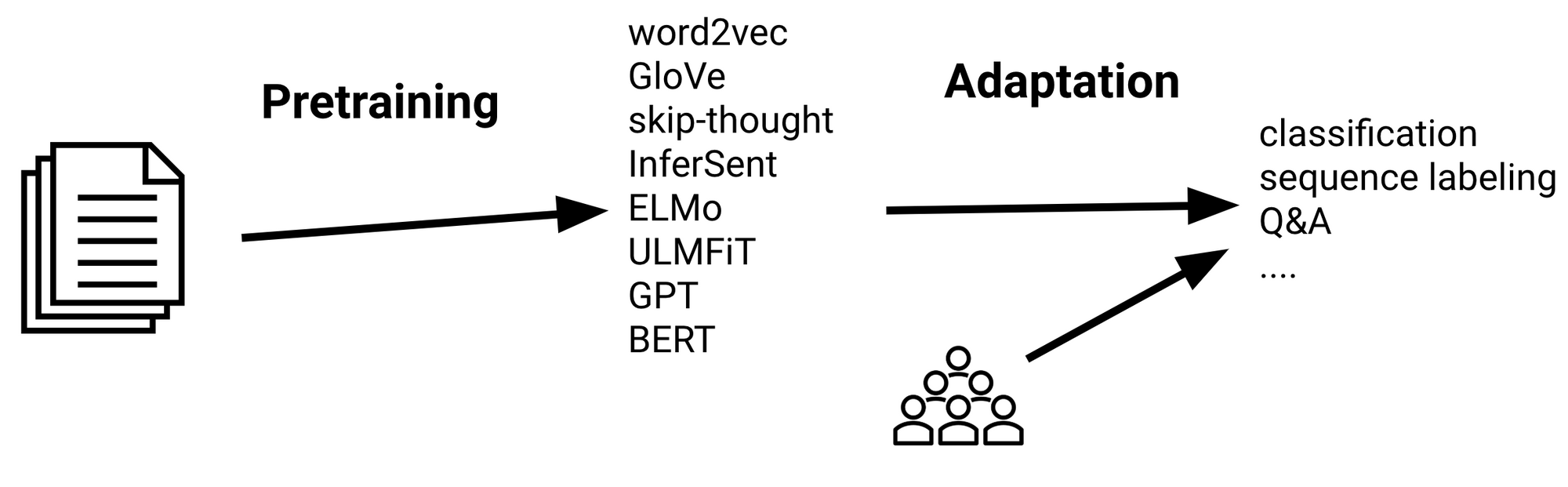
- In NLP, various source models are quite effective in transfering knowledge to target models, including word2vec and BERT.
- With transfer learning, we can easily stand on the shoulders of giants.

Types of transfer learning¶
- Domain adaptation
- Train on Wikipedia texts
- Predict on tweets

- Cross-lingual learning
- Train on English
- Predict on Spanish
- Multi-task learning (Liu et al. 2019)
- Sequential learning
- BERT is trained to
- predict a missing token in a random position
- predict whether a sentence follows another
- Use BERT's knowledge to train a new model for a new skill
- BERT is trained to
- spaCy's framework makes it easy to do sequential transfer learning.

Hands-on walkthrough (HOW)¶

Dataset¶
In [85]:
cols = ["excerpt", "forum_en", "forum_zh", "toks"]
sample_df[cols]
Out[85]:
| excerpt | forum_en | forum_zh | toks | |
|---|---|---|---|---|
| 0 | 希望各位能花個20秒幫我填一下 | dressup | 穿搭 | [希望, 位, 花, 個, 秒, 幫, 填] |
| 1 | 想找這套衣服🥲,但發現不知道該用什麼關鍵字找,(圖是草屯囝仔的校園演唱會截圖) | dressup | 穿搭 | [想, 找, 這, 套, 衣服, 🥲, 發現, 該, 用什麼, 關鍵字, 找, 圖是, 草屯... |
| 2 | 因為文會有點長,先說結論是,50%是目前網購過的平台退貨最麻煩的一家,甚至我認為根本是刻意刁... | dressup | 穿搭 | [因為, 文會, 有點, 長, 先, 說, 結論, 網購, 過, 平台, 退貨, 麻煩, 家... |
| 3 | 來源:覺得呱吉這襯衫好好看~~,或有人知道有類似的嗎 | dressup | 穿搭 | [來源, 覺得, 呱吉, 這, 襯衫, 好好, 類似, 嗎] |
| 4 | 各位,因為這個證件夾臺灣買不到,是美國outlet 的限量版貨,所以在以下的這間蝦皮上買,但... | dressup | 穿搭 | [位, 因為, 這, 個, 證件, 夾, 臺灣, 買不到, 美國, 限量版, 貨, 這, 間... |
| ... | ... | ... | ... | ... |
| 135 | 最初只是和平的人權運動,最後卻演變成一場血腥暴力的革命,烏克蘭人民用93天讓世界見證了他們的... | netflix | Netflix | [最初, 和平, 人權, 運動, 卻, 演變成, 一場, 血腥, 暴力, 革命, 烏克蘭, ... |
| 136 | 《二十五,二十一》第五首原聲帶歌曲由男團SEVENTEEN的DK來擔任,在當DK要演唱原聲帶... | netflix | Netflix | [首, 原, 聲帶, 歌曲, 男團, 來, 擔任, 當, 演唱, 原, 聲帶, 消息, 時,... |
| 137 | 我想問有沒有類似荒謬分局那種一集時間不長,但是很耐看,很多季的影集嗎(;´༎ຶД༎ຶ`),最... | netflix | Netflix | [想問, 有沒有, 類似, 荒謬, 分局, 種, 一集, 時間, 不長, 耐看, 季, 影集... |
| 138 | 借板發一下,感謝。1這部老實講比正傳悶,悶很多,有點小失望,看前三集除了格陵蘭人渡海那段,其... | netflix | Netflix | [板發, 感謝, 這, 部, 老實, 講, 正傳, 悶, 悶, 有點, 失望, 前三集, 格... |
| 139 | #重雷,因為版上都是讚美的聲音…,其實幾位主角性格都很討喜,只是太多人大大大推了 個人看了反... | netflix | Netflix | [重雷, 因為, 版上, 讚美, 聲音, 其實, 幾, 位, 主角, 性格, 討喜, 太多,... |
140 rows × 4 columns
Two text classification models¶
Classification is a very common task.
Many problems can be cast as a classification task, including
- Sentiment analysis
- Part-of-speech tagging
- Dependency parsing
- Named entity recognition
- Intent recognition for chatbots
We'll train two classification models that take a text as input and predict a label for it.
- TF-IDF: no transfer learning
- Transformer: leveraging transfer learning
TF-IDF¶
In [163]:
from sklearn import feature_extraction, model_selection, pipeline
from sklearn.svm import SVC
from sklearn import metrics
import time
In [87]:
train_df, test_df = model_selection.train_test_split(sample_df, test_size=0.3, random_state=100)
train_y = train_df["forum_en"].values
test_y = test_df["forum_en"].values
In [88]:
train_df.groupby("forum_en").size()
Out[88]:
forum_en dressup 24 makeup 17 money 17 netflix 17 trending 23 dtype: int64
In [89]:
test_df.groupby("forum_en").size()
Out[89]:
forum_en dressup 4 makeup 11 money 12 netflix 12 trending 3 dtype: int64
- Let's use Support Vector Machine (SVC) for the classification algorithm.
- SVC projects data in the input space to a feature space in higher dimensioons.
In [165]:
vectorizer = feature_extraction.text.TfidfVectorizer(max_features=2000, ngram_range=(1,2))
corpus = train_df["toks"].apply(lambda x: " ".join(x))
vectorizer.fit(corpus)
train_X = vectorizer.transform(corpus)
svc_clf = SVC(C=1, gamma="auto", kernel='linear',probability=False)
model = pipeline.Pipeline([("vectorizer", vectorizer),
("svm", svc_clf)])
In [166]:
start = time.time()
model["svm"].fit(train_X, train_y)
end = time.time()
print(f"It took {end-start} secs to train the model.")
It took 0.005840778350830078 secs to train the model.
In [167]:
test_X = test_df["toks"].apply(lambda x: " ".join(x))
start = time.time()
predictions = model.predict(test_X)
end = time.time()
print(f"It took {end-start} secs to make predictions on the testing data.")
It took 0.005638599395751953 secs to make predictions on the testing data.
In [169]:
predictions
Out[169]:
array(['dressup', 'dressup', 'netflix', 'money', 'trending', 'dressup',
'makeup', 'dressup', 'dressup', 'makeup', 'dressup', 'trending',
'makeup', 'dressup', 'makeup', 'dressup', 'money', 'netflix',
'makeup', 'dressup', 'trending', 'money', 'netflix', 'netflix',
'dressup', 'dressup', 'money', 'dressup', 'dressup', 'dressup',
'money', 'trending', 'dressup', 'dressup', 'money', 'trending',
'makeup', 'dressup', 'dressup', 'trending', 'trending', 'trending'],
dtype=object)
In [168]:
class_report = metrics.classification_report(test_y, predictions, output_dict=True)
report_df = pd.DataFrame(class_report).transpose()
report_df
Out[168]:
| precision | recall | f1-score | support | |
|---|---|---|---|---|
| dressup | 0.166667 | 0.750000 | 0.272727 | 4.000000 |
| makeup | 0.333333 | 0.181818 | 0.235294 | 11.000000 |
| money | 1.000000 | 0.500000 | 0.666667 | 12.000000 |
| netflix | 1.000000 | 0.333333 | 0.500000 | 12.000000 |
| trending | 0.375000 | 1.000000 | 0.545455 | 3.000000 |
| accuracy | 0.428571 | 0.428571 | 0.428571 | 0.428571 |
| macro avg | 0.575000 | 0.553030 | 0.444029 | 42.000000 |
| weighted avg | 0.701389 | 0.428571 | 0.459893 | 42.000000 |
- Common metrics for the performance of classification models
Transformer¶
In [94]:
!nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2020 NVIDIA Corporation Built on Mon_Oct_12_20:09:46_PDT_2020 Cuda compilation tools, release 11.1, V11.1.105 Build cuda_11.1.TC455_06.29190527_0
- Change
cuda111to the correponding cuda version of your machine.
In [ ]:
!pip install -U spacy[cuda111,transformers]
In [ ]:
!python -m spacy download zh_core_web_trf
In [97]:
import spacy_transformers
In [98]:
spacy.prefer_gpu()
nlp = spacy.load("zh_core_web_trf")
In [99]:
nlp.pipe_names
Out[99]:
['transformer', 'tagger', 'parser', 'attribute_ruler', 'ner']
In [100]:
text = "宜家家居新店店店長的名字好長喔!"
doc = nlp(text)
doc._.trf_data.wordpieces
Out[100]:
WordpieceBatch(strings=[['[CLS]', '宜', '家', '家', '居', '新', '店', '店', '店', '長', '的', '名', '字', '好', '長', '喔', '!', '[SEP]']], input_ids=array([[ 101, 2139, 2157, 2157, 2233, 3173, 2421, 2421, 2421, 7269, 4638,
1399, 2099, 1962, 7269, 1595, 8013, 102]], dtype=int32), attention_mask=array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1.]], dtype=float32), lengths=[18], token_type_ids=array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32))
- The sample text includes 18 tokens, each in 768 dimensions.
In [101]:
doc._.trf_data.tensors[0].shape
Out[101]:
(1, 18, 768)
In [102]:
unique_labels = train_df['forum_en'].unique().tolist()
unique_labels
Out[102]:
['trending', 'dressup', 'netflix', 'money', 'makeup']
In [103]:
train_df['tuples'] = train_df.apply(lambda row: (row['excerpt'], row['forum_en']), axis=1)
train_data = train_df['tuples'].tolist()
test_df['tuples'] = test_df.apply(lambda row: (row['excerpt'], row['forum_en']), axis=1)
test_data = test_df['tuples'].tolist()
In [112]:
train_data[-3:]
Out[112]:
[('位於烏克蘭、歐洲最大的札波羅熱(Zaporizhzhia)核電廠在俄軍攻勢下起火,美國總統拜登稍早立即致電烏克蘭總統澤倫斯基(Volodymyr Zelensky),白宮將會持續密切關注核電廠火災狀況',
'trending'),
('最近一直看有沒有不錯的賣場,有人知道這家是不是正的嗎,謝謝🥺🥺', 'dressup'),
('2/13-2/15我踏上了一場說走就走的旅程,一個人三天兩夜的墾丁之旅,穿搭偏簡單 走黑白色系\U0001f90d,(畢竟自己出門 不要帶太多東西比較好,雖然偏簡單 還是想記錄一下,如果有想自己出遊的人也可以做個參考~',
'dressup')]
In [115]:
from tqdm.auto import tqdm
from spacy.tokens import DocBin
def make_docs(data_list, unique_labels, dest_path):
nlp = spacy.blank('zh')
docs = []
for doc, label in tqdm(nlp.pipe(data_list, as_tuples=True), total=len(data_list)):
label_dict = {label: False for label in unique_labels}
doc.cats = label_dict
doc.cats[label] = True
docs.append(doc)
doc_bin = DocBin(docs=docs)
doc_bin.to_disk(dest_path)
In [116]:
make_docs(train_data, unique_labels, "train.spacy")
make_docs(test_data, unique_labels, "test.spacy")
0%| | 0/98 [00:00<?, ?it/s]
0%| | 0/42 [00:00<?, ?it/s]
In [124]:
!python -m spacy init config ./config.cfg --lang zh --pipeline transformer,textcat --optimize accuracy --gpu
ℹ Generated config template specific for your use case - Language: zh - Pipeline: textcat - Optimize for: accuracy - Hardware: GPU - Transformer: bert-base-chinese ✔ Auto-filled config with all values ✔ Saved config config.cfg You can now add your data and train your pipeline: python -m spacy train config.cfg --paths.train ./train.spacy --paths.dev ./dev.spacy
In [125]:
!cat config.cfg
[paths]
train = null
dev = null
vectors = null
init_tok2vec = null
[system]
gpu_allocator = "pytorch"
seed = 0
[nlp]
lang = "zh"
pipeline = ["transformer","textcat"]
batch_size = 128
disabled = []
before_creation = null
after_creation = null
after_pipeline_creation = null
[nlp.tokenizer]
@tokenizers = "spacy.zh.ChineseTokenizer"
segmenter = "char"
[components]
[components.textcat]
factory = "textcat"
scorer = {"@scorers":"spacy.textcat_scorer.v1"}
threshold = 0.5
[components.textcat.model]
@architectures = "spacy.TextCatEnsemble.v2"
nO = null
[components.textcat.model.linear_model]
@architectures = "spacy.TextCatBOW.v2"
exclusive_classes = true
ngram_size = 1
no_output_layer = false
nO = null
[components.textcat.model.tok2vec]
@architectures = "spacy-transformers.TransformerListener.v1"
grad_factor = 1.0
pooling = {"@layers":"reduce_mean.v1"}
upstream = "*"
[components.transformer]
factory = "transformer"
max_batch_items = 4096
set_extra_annotations = {"@annotation_setters":"spacy-transformers.null_annotation_setter.v1"}
[components.transformer.model]
@architectures = "spacy-transformers.TransformerModel.v3"
name = "bert-base-chinese"
mixed_precision = false
[components.transformer.model.get_spans]
@span_getters = "spacy-transformers.strided_spans.v1"
window = 128
stride = 96
[components.transformer.model.grad_scaler_config]
[components.transformer.model.tokenizer_config]
use_fast = true
[components.transformer.model.transformer_config]
[corpora]
[corpora.dev]
@readers = "spacy.Corpus.v1"
path = ${paths.dev}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[corpora.train]
@readers = "spacy.Corpus.v1"
path = ${paths.train}
max_length = 0
gold_preproc = false
limit = 0
augmenter = null
[training]
accumulate_gradient = 3
dev_corpus = "corpora.dev"
train_corpus = "corpora.train"
seed = ${system.seed}
gpu_allocator = ${system.gpu_allocator}
dropout = 0.1
patience = 1600
max_epochs = 0
max_steps = 20000
eval_frequency = 200
frozen_components = []
annotating_components = []
before_to_disk = null
[training.batcher]
@batchers = "spacy.batch_by_padded.v1"
discard_oversize = true
size = 2000
buffer = 256
get_length = null
[training.logger]
@loggers = "spacy.ConsoleLogger.v1"
progress_bar = false
[training.optimizer]
@optimizers = "Adam.v1"
beta1 = 0.9
beta2 = 0.999
L2_is_weight_decay = true
L2 = 0.01
grad_clip = 1.0
use_averages = false
eps = 0.00000001
[training.optimizer.learn_rate]
@schedules = "warmup_linear.v1"
warmup_steps = 250
total_steps = 20000
initial_rate = 0.00005
[training.score_weights]
cats_score = 1.0
cats_score_desc = null
cats_micro_p = null
cats_micro_r = null
cats_micro_f = null
cats_macro_p = null
cats_macro_r = null
cats_macro_f = null
cats_macro_auc = null
cats_f_per_type = null
cats_macro_auc_per_type = null
[pretraining]
[initialize]
vectors = ${paths.vectors}
init_tok2vec = ${paths.init_tok2vec}
vocab_data = null
lookups = null
before_init = null
after_init = null
[initialize.components]
[initialize.tokenizer]
pkuseg_model = null
pkuseg_user_dict = "default"
In [126]:
!mkdir output
- Abort the execution of the following cell if it runs for too long.
In [134]:
start = time.time()
!python -m spacy train ./config.cfg --output ./output --paths.train ./train.spacy --paths.dev ./test.spacy --gpu-id 0 --verbose
end = time.time()
print(f"It took {end-start} secs to train the model.")
[2022-03-18 13:32:23,319] [DEBUG] Config overrides from CLI: ['paths.train', 'paths.dev'] ℹ Saving to output directory: output ℹ Using GPU: 0 =========================== Initializing pipeline =========================== [2022-03-18 13:32:26,310] [INFO] Set up nlp object from config [2022-03-18 13:32:26,323] [DEBUG] Loading corpus from path: test.spacy [2022-03-18 13:32:26,324] [DEBUG] Loading corpus from path: train.spacy [2022-03-18 13:32:26,324] [INFO] Pipeline: ['transformer', 'textcat'] [2022-03-18 13:32:26,330] [INFO] Created vocabulary [2022-03-18 13:32:26,332] [INFO] Finished initializing nlp object Some weights of the model checkpoint at bert-base-chinese were not used when initializing BertModel: ['cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.bias', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.bias'] - This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). [2022-03-18 13:32:36,584] [INFO] Initialized pipeline components: ['transformer', 'textcat'] ✔ Initialized pipeline ============================= Training pipeline ============================= [2022-03-18 13:32:36,598] [DEBUG] Loading corpus from path: test.spacy [2022-03-18 13:32:36,599] [DEBUG] Loading corpus from path: train.spacy [2022-03-18 13:32:36,650] [DEBUG] Removed existing output directory: output/model-best [2022-03-18 13:32:36,704] [DEBUG] Removed existing output directory: output/model-last ℹ Pipeline: ['transformer', 'textcat'] ℹ Initial learn rate: 0.0 E # LOSS TRANS... LOSS TEXTCAT CATS_SCORE SCORE --- ------ ------------- ------------ ---------- ------ 0 0 0.00 0.80 0.00 0.00 66 200 0.00 36.54 94.98 0.95 Aborted! It took 471.73191380500793 secs to train the model.
- Load the model that we just trained.
In [ ]:
mynlp = spacy.load("./output/model-last")
In [140]:
test_indexes = test_df.index.tolist()
print(test_indexes)
[139, 97, 134, 110, 81, 26, 35, 32, 84, 95, 25, 69, 40, 28, 125, 133, 99, 117, 11, 46, 51, 101, 136, 121, 37, 21, 89, 119, 118, 29, 96, 52, 45, 106, 92, 62, 130, 82, 33, 105, 111, 120]
- Feel free to change the value of
docidto any number intest_indexes.
In [150]:
docid = 139
sample_text = test_df.loc[docid, 'excerpt']
sample_cat = test_df.loc[docid, 'forum_en']
print(f"Sample text: \n{sample_text}")
print(f"True category: \n{sample_cat}")
Sample text: #重雷,因為版上都是讚美的聲音…,其實幾位主角性格都很討喜,只是太多人大大大推了 個人看了反而有點小失望,第一集開頭用2020疫情和1997金融海嘯來提到,「時代影響了很多人」也覺得很有共鳴,因為我們 True category: netflix
In [152]:
doc = mynlp(sample_text)
max_cat = max(doc.cats, key=doc.cats.get)
print(f"Category probabilities:\n{doc.cats}")
print(f"Predicted category: {max_cat}")
Category probabilities:
{'trending': 0.002882840344682336, 'dressup': 0.0029310560785233974, 'netflix': 0.9875414967536926, 'money': 0.0030496492981910706, 'makeup': 0.003594897221773863}
Predicted category: netflix
- Feel free to revise the sentence stored in
text.
In [151]:
text = "今年似乎又開始流行連身裙了呢"
doc = mynlp(text)
max_cat = max(doc.cats, key=doc.cats.get)
print(f"Category probabilities:\n{doc.cats}")
print(f"Predicted category: {max_cat}")
Category probabilities:
{'trending': 0.0022079325281083584, 'dressup': 0.9901031255722046, 'netflix': 0.002575943013653159, 'money': 0.002191048115491867, 'makeup': 0.0029218546114861965}
Predicted category: dressup
In [ ]:
import json
In [162]:
model_meta_path = "./output/model-best/meta.json"
with open(model_meta_path) as json_file:
trained_metrics = json.load(json_file)
trained_metrics['performance']
Out[162]:
{'cats_f_per_type': {'dressup': {'f': 0.8888888889, 'p': 0.8, 'r': 1.0},
'makeup': {'f': 0.9, 'p': 1.0, 'r': 0.8181818182},
'money': {'f': 0.96, 'p': 0.9230769231, 'r': 1.0},
'netflix': {'f': 1.0, 'p': 1.0, 'r': 1.0},
'trending': {'f': 1.0, 'p': 1.0, 'r': 1.0}},
'cats_macro_auc': 0.9899175113,
'cats_macro_auc_per_type': 0.0,
'cats_macro_f': 0.9497777778,
'cats_macro_p': 0.9446153846,
'cats_macro_r': 0.9636363636,
'cats_micro_f': 0.9523809524,
'cats_micro_p': 0.9523809524,
'cats_micro_r': 0.9523809524,
'cats_score': 0.9497777778,
'cats_score_desc': 'macro F',
'textcat_loss': 36.5435999353,
'transformer_loss': 0.0006216127}
In [146]:
import random
def show_test():
idx = random.choice(test_indexes)
text = test_df.at[idx, 'excerpt']
label = test_df.at[idx, 'forum_en']
predicted_proba = mynlp(text).cats
predicted_cat = max(predicted_proba, key=predicted_proba.get)
print(f"Index in test data: {idx}")
print(f"Text: {text}")
print(f"True category: {label}")
print(f"Category probabilities:\n{predicted_proba}")
print(f"Predicted category: {predicted_cat}")
In [147]:
show_test()
Index in test data: 25
Text: 有人知道這是什麼牌子嗎
True category: dressup
Category probabilities:
{'trending': 0.0024371894542127848, 'dressup': 0.9893414974212646, 'netflix': 0.0024927842896431684, 'money': 0.0022952246945351362, 'makeup': 0.003433354664593935}
Predicted category: dressup
In [154]:
show_test()
Index in test data: 32
Text: 因為自己本身是敏感肌,所以用保養品都會很小心翼翼看成分,目前覺得醫美牌大致上幾乎都蠻安全的,算是可放心服用~另外味道也是一門學問,基本上香味太濃郁妖豔的,擦上去就是立馬泛紅或刺刺的,百試不厭耶!,而且
True category: makeup
Category probabilities:
{'trending': 0.0046507827937603, 'dressup': 0.005224997643381357, 'netflix': 0.005102104041725397, 'money': 0.005229421425610781, 'makeup': 0.9797927141189575}
Predicted category: makeup
In [149]:
show_test()
Index in test data: 92
Text: 2022.03.03,當日收益:151.1178,本金:50w,註記:無,程式使用API串聯,幣安,火幣,kraken,ok等一線交易所進行交易,資金皆在自己的交易所帳戶內️️,Instagram:加密
True category: money
Category probabilities:
{'trending': 0.003693468403071165, 'dressup': 0.003174132201820612, 'netflix': 0.0034728439059108496, 'money': 0.9856423735618591, 'makeup': 0.004017228726297617}
Predicted category: money
- With powerful techniques like deep learning and transfer learning, it's sometimes not easy to explain to customers/clients/bosses why your models make good predictions.

References¶
Articles¶
- An Introduction to Machine Learning
- [Top Natural Language
Processing Applications in Business](https://www.accenture.com/_acnmedia/pdf-106/accenture-unlocking-value-unstructured-data.pdf)
Books¶

