Building an Image Similarity System with 🤗 Transformers¶
In this notebook, you'll learn to build an image similarity system with 🤗 Transformers. Finding out the similarity between a query image and potential candidates is an important use case for information retrieval systems, reverse image search, for example. All the system is trying to answer is, given a query image and a set of candidate images, which images are the most similar to the query image.
🤗 Datasets library¶
This notebook leverages the datasets library as it seamlessly supports parallel processing, which will come in handy when building this system.
Any model and dataset¶
Although the notebook uses a ViT-based model (nateraw/vit-base-beans) and a particular dataset (Beans), it can be easily extended to use other models supporting vision modality and other image datasets. Some notable models you could try:
The approach presented in the notebook can potentially be extended to other modalities as well.
Before we start, let's install the datasets and transformers libraries.
!pip install transformers datasets -q
|████████████████████████████████| 5.8 MB 15.1 MB/s
|████████████████████████████████| 451 kB 75.5 MB/s
|████████████████████████████████| 182 kB 54.0 MB/s
|████████████████████████████████| 7.6 MB 53.7 MB/s
|████████████████████████████████| 212 kB 74.8 MB/s
|████████████████████████████████| 132 kB 73.9 MB/s
|████████████████████████████████| 127 kB 80.5 MB/s
If you're opening this notebook locally, make sure your environment has an install from the last version of those libraries.
We also quickly upload some telemetry - this tells us which examples and software versions are getting used so we know where to prioritize our maintenance efforts. We don't collect (or care about) any personally identifiable information, but if you'd prefer not to be counted, feel free to skip this step or delete this cell entirely.
from transformers.utils import send_example_telemetry
send_example_telemetry("image_similarity_notebook", framework="pytorch")
Building an image similarity system¶
To build this system, we first need to define how we want to compute the similarity between two images. One widely popular practice is to compute dense representations (embeddings) of the given images and then use the cosine similarity metric to determine how similar the two images are.
For this tutorial, we'll be using “embeddings” to represent images in vector space. This gives us a nice way to meaningfully compress the high-dimensional pixel space of images (224 x 224 x 3, for example) to something much lower dimensional (768, for example). The primary advantage of doing this is the reduced computation time in the subsequent steps.

Don't worry if these things do not make sense at all. We will discuss these things in more detail shortly.
Loading a base model to compute embeddings¶
"Embeddings" encode the semantic information of images. To compute the embeddings from the images, we'll use a vision model that has some understanding of how to represent the input images in the vector space. This type of models is also commonly referred to as image encoders.
For loading the model, we leverage the AutoModel class. It provides an interface for us to load any compatible model checkpoint from the Hugging Face Hub. Alongside the model, we also load the processor associated with the model for data preprocessing.
from transformers import AutoFeatureExtractor, AutoModel
model_ckpt = "nateraw/vit-base-beans"
extractor = AutoFeatureExtractor.from_pretrained(model_ckpt)
model = AutoModel.from_pretrained(model_ckpt)
hidden_dim = model.config.hidden_size
Downloading: 0%| | 0.00/228 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/756 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/343M [00:00<?, ?B/s]
Some weights of the model checkpoint at nateraw/vit-base-beans were not used when initializing ViTModel: ['classifier.weight', 'classifier.bias'] - This IS expected if you are initializing ViTModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing ViTModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of ViTModel were not initialized from the model checkpoint at nateraw/vit-base-beans and are newly initialized: ['vit.pooler.dense.bias', 'vit.pooler.dense.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
In this case, the checkpoint was obtained by fine-tuning a Vision Transformer based model on the beans dataset. To learn more about the model, just click the model link and check out its model card.
The warning is telling us that the underlying model didn't use anything from the classifier. Why did we not use AutoModelForImageClassification?
This is because we want to obtain dense representations of the images and not discrete categories, which are what AutoModelForImageClassification would have provided.
Then comes another question - why this checkpoint in particular?
We're using a specific dataset to build the system as mentioned earlier. So, instead of using a generalist model (like the ones trained on the ImageNet-1k dataset, for example), it's better to use a model that has been fine-tuned on the dataset being used. That way, the underlying model has a better understanding of the input images.
Now that we have a model for computing the embeddings, we need some candidate images to query against.
Loading the dataset for candidate images¶
To find out similar images, we need a set of candidate images to query against. We'll use the train split of the beans dataset for that purpose. To know more about the dataset, just follow the link and explore its dataset card.
from datasets import load_dataset
dataset = load_dataset("beans")
Downloading builder script: 0%| | 0.00/3.61k [00:00<?, ?B/s]
Downloading metadata: 0%| | 0.00/2.24k [00:00<?, ?B/s]
Downloading readme: 0%| | 0.00/4.74k [00:00<?, ?B/s]
Downloading and preparing dataset beans/default to /root/.cache/huggingface/datasets/beans/default/0.0.0/90c755fb6db1c0ccdad02e897a37969dbf070bed3755d4391e269ff70642d791...
Downloading data files: 0%| | 0/3 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/144M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/18.5M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/17.7M [00:00<?, ?B/s]
Extracting data files #0: 0%| | 0/1 [00:00<?, ?obj/s]
Extracting data files #1: 0%| | 0/1 [00:00<?, ?obj/s]
Extracting data files #2: 0%| | 0/1 [00:00<?, ?obj/s]
Generating train split: 0%| | 0/1034 [00:00<?, ? examples/s]
Generating validation split: 0%| | 0/133 [00:00<?, ? examples/s]
Generating test split: 0%| | 0/128 [00:00<?, ? examples/s]
Dataset beans downloaded and prepared to /root/.cache/huggingface/datasets/beans/default/0.0.0/90c755fb6db1c0ccdad02e897a37969dbf070bed3755d4391e269ff70642d791. Subsequent calls will reuse this data.
0%| | 0/3 [00:00<?, ?it/s]
# Check a sample image.
dataset["train"][0]["image"]

The dataset has got three columns / features:
dataset["train"].features
{'image_file_path': Value(dtype='string', id=None),
'image': Image(decode=True, id=None),
'labels': ClassLabel(names=['angular_leaf_spot', 'bean_rust', 'healthy'], id=None)}
Next, we set up two dictionaries for our upcoming utilities:
label2idwhich maps the class labels to integers.id2labeldoing the opposite oflabel2id.
labels = dataset["train"].features["labels"].names
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = i
id2label[i] = label
With these components, we can proceed to build our image similarity system. To demonstrate this, we'll use 100 samples from the candidate image dataset to keep the overall runtime short.
num_samples = 100
seed = 42
candidate_subset = dataset["train"].shuffle(seed=seed).select(range(num_samples))
Below, you can find a pictorial overview of the process underlying fetching similar images.

Breaking down the above figure a bit, we have:
- Extract the embeddings from the candidate images (
candidate_subset) storing them in a matrix. - Take a query image and extract its embeddings.
- Iterate over the embedding matrix (computed in step 1) and compute the similarity score between the query embedding and the current candidate embedding. We usually maintain a dictionary-like mapping maintaining a correspondence between some identifier of the candidate image and the similarity scores.
- Sort the mapping structure w.r.t the similarity scores and return the identifiers underlying. We use these identifiers to fetch the candidate samples.
In the next cells, we implement the above procedure in code.
import torchvision.transforms as T
# Data transformation chain.
transformation_chain = T.Compose(
[
# We first resize the input image to 256x256 and then we take center crop.
T.Resize(int((256 / 224) * extractor.size["height"])),
T.CenterCrop(extractor.size["height"]),
T.ToTensor(),
T.Normalize(mean=extractor.image_mean, std=extractor.image_std),
]
)
import torch
def extract_embeddings(model: torch.nn.Module):
"""Utility to compute embeddings."""
device = model.device
def pp(batch):
images = batch["image"]
image_batch_transformed = torch.stack(
[transformation_chain(image) for image in images]
)
new_batch = {"pixel_values": image_batch_transformed.to(device)}
with torch.no_grad():
embeddings = model(**new_batch).last_hidden_state[:, 0].cpu()
return {"embeddings": embeddings}
return pp
# Here, we map embedding extraction utility on our subset of candidate images.
batch_size = 24
device = "cuda" if torch.cuda.is_available() else "cpu"
extract_fn = extract_embeddings(model.to(device))
candidate_subset_emb = candidate_subset.map(extract_fn, batched=True, batch_size=24)
0%| | 0/5 [00:00<?, ?ba/s]
Next, for convenience, we create a list containing the identifiers of the candidate images.
from tqdm.auto import tqdm
candidate_ids = []
for id in tqdm(range(len(candidate_subset_emb))):
label = candidate_subset_emb[id]["labels"]
# Create a unique indentifier.
entry = str(id) + "_" + str(label)
candidate_ids.append(entry)
0%| | 0/100 [00:00<?, ?it/s]
We'll use the matrix of the embeddings of all the candidate images for computing the similarity scores with a query image. We have already computed the candidate image embeddings. In the next cell, we just gather them together in a matrix.
import numpy as np
all_candidate_embeddings = np.array(candidate_subset_emb["embeddings"])
all_candidate_embeddings = torch.from_numpy(all_candidate_embeddings)
We'll use the cosine similarity to compute the similarity score in between two embedding vectors. We'll then use it to fetch similar candidate samples given a query sample.
def compute_scores(emb_one, emb_two):
"""Computes cosine similarity between two vectors."""
scores = torch.nn.functional.cosine_similarity(emb_one, emb_two)
return scores.numpy().tolist()
def fetch_similar(image, top_k=5):
"""Fetches the `top_k` similar images with `image` as the query."""
# Prepare the input query image for embedding computation.
image_transformed = transformation_chain(image).unsqueeze(0)
new_batch = {"pixel_values": image_transformed.to(device)}
# Comute the embedding.
with torch.no_grad():
query_embeddings = model(**new_batch).last_hidden_state[:, 0].cpu()
# Compute similarity scores with all the candidate images at one go.
# We also create a mapping between the candidate image identifiers
# and their similarity scores with the query image.
sim_scores = compute_scores(all_candidate_embeddings, query_embeddings)
similarity_mapping = dict(zip(candidate_ids, sim_scores))
# Sort the mapping dictionary and return `top_k` candidates.
similarity_mapping_sorted = dict(
sorted(similarity_mapping.items(), key=lambda x: x[1], reverse=True)
)
id_entries = list(similarity_mapping_sorted.keys())[:top_k]
ids = list(map(lambda x: int(x.split("_")[0]), id_entries))
labels = list(map(lambda x: int(x.split("_")[-1]), id_entries))
return ids, labels
Now, we can put these utilities to test.
test_idx = np.random.choice(len(dataset["test"]))
test_sample = dataset["test"][test_idx]["image"]
test_label = dataset["test"][test_idx]["labels"]
sim_ids, sim_labels = fetch_similar(test_sample)
print(f"Query label: {test_label}")
print(f"Top 5 candidate labels: {sim_labels}")
Query label: 1 Top 5 candidate labels: [1, 1, 1, 1, 1]
We can notice that given the query image, candidate images having similar labels were fetched.
Now, we can visualize all this.
import matplotlib.pyplot as plt
def plot_images(images, labels):
if not isinstance(labels, list):
labels = labels.tolist()
plt.figure(figsize=(20, 10))
columns = 6
for (i, image) in enumerate(images):
label_id = int(labels[i])
ax = plt.subplot(len(images) / columns + 1, columns, i + 1)
if i == 0:
ax.set_title("Query Image\n" + "Label: {}".format(id2label[label_id]))
else:
ax.set_title(
"Similar Image # " + str(i) + "\nLabel: {}".format(id2label[label_id])
)
plt.imshow(np.array(image).astype("int"))
plt.axis("off")
images = []
labels = []
for id, label in zip(sim_ids, sim_labels):
images.append(candidate_subset_emb[id]["image"])
labels.append(candidate_subset_emb[id]["labels"])
images.insert(0, test_sample)
labels.insert(0, test_label)
plot_images(images, labels)

We now have a working image similarity system. But in reality, you'll be dealing with many more candidate images. So considering that, our current procedure has got multiple drawbacks:
If we store the embeddings as is, the memory requirements can shoot up quickly, especially when dealing with millions of candidate images. However, the embeddings are 768-d in our case, which can still be relatively high in the large-scale regime. They have high-dimensional embeddings that directly affect the subsequent computations involved in the retrieval part. So, if we can somehow reduce the dimensionality of the embeddings without disturbing their meaning, we can still maintain a good trade-off between speed and retrieval quality.
So, in the following sections, we'll implement the hashing utilities to optimize the runtime of our image similarity system.
Random projection and locality-sensitive hashing (LSH)¶
We can choose to just compute the embeddings with our base model and then apply a similarity metric for the system. But in realistic settings, the embeddings are still high dimensional (in this case (768, )). This eats up storage and also increases the query time.
To mitigate that effect, we'll implement the following things:
- First, we reduce the dimensionality of the embeddings with random projection. The main idea is that if the distance between a group of vectors can roughly be preserved on a plane, the dimensionality of the plane can be further reduced.
- We then compute the bitwise hash values of the projected vectors to determine their hash buckets. Similar images will likely be closer in the embedding space. Therefore, they will likely also have the same hash values and are likely to go into the same hash bucket. From a deployment perspective, bitwise hash values are cheaper to store and operate on. If you're unfamiliar with the relevant concepts of hashing, this resource could be helpful.
Following is a pictorial representation of the hashing process (figure source):
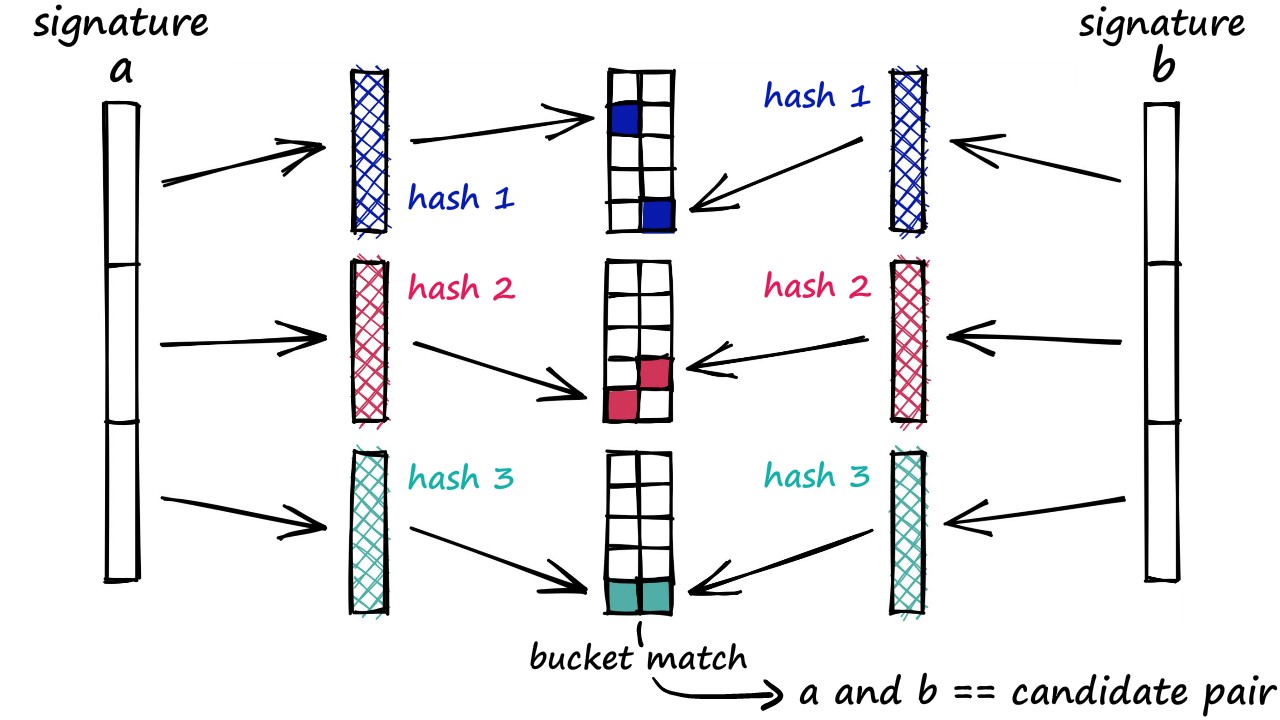
hash_size = 8
np.random.seed(seed)
# Define random vectors to project with.
random_vectors = np.random.randn(hash_size, hidden_dim).T
def hash_func(embedding, random_vectors=random_vectors):
"""Randomly projects the embeddings and then computes bit-wise hashes."""
if not isinstance(embedding, np.ndarray):
embedding = np.array(embedding)
if len(embedding.shape) < 2:
embedding = np.expand_dims(embedding, 0)
# Random projection.
bools = np.dot(embedding, random_vectors) > 0
return [bool2int(bool_vec) for bool_vec in bools]
def bool2int(x):
y = 0
for i, j in enumerate(x):
if j:
y += 1 << i
return y
Next, we define a utility that can be mapped to our dataset for computing hashes of the training images in a parallel manner.
from typing import Union
def compute_hash(model: Union[torch.nn.Module, str]):
"""Computes hash on a given dataset."""
device = model.device
def pp(example_batch):
# Prepare the input images for the model.
image_batch = example_batch["image"]
image_batch_transformed = torch.stack(
[transformation_chain(image) for image in image_batch]
)
new_batch = {"pixel_values": image_batch_transformed.to(device)}
# Compute embeddings and pool them i.e., take the representations from the [CLS]
# token.
with torch.no_grad():
embeddings = model(**new_batch).last_hidden_state[:, 0].cpu().numpy()
# Compute hashes for the batch of images.
hashes = [hash_func(embeddings[i]) for i in range(len(embeddings))]
example_batch["hashes"] = hashes
return example_batch
return pp
Next, we build three utility classes building our hash tables:
TableLSHBuildLSHTable
Collectively, these classes implement Locality Sensitive Hashing (the idea locally close points share the same hashes).
Disclaimer: Some code has been used from this resource for writing these classes.
The Table class¶
The Table class has two methods:
add()lets us build a dictionary mapping the hashes of the candidate images to their identifiers.query()lets us take as inputs the query hashes and check if they exist in the table.
The table built in this class is referred to as a hash bucket.
from typing import List
class Table:
def __init__(self, hash_size: int):
self.table = {}
self.hash_size = hash_size
def add(self, id: int, hashes: List[int], label: int):
# Create a unique indentifier.
entry = {"id_label": str(id) + "_" + str(label)}
# Add the hash values to the current table.
for h in hashes:
if h in self.table:
self.table[h].append(entry)
else:
self.table[h] = [entry]
def query(self, hashes: List[int]):
results = []
# Loop over the query hashes and determine if they exist in
# the current table.
for h in hashes:
if h in self.table:
results.extend(self.table[h])
return results
The LSH class¶
Our dimensionality reduction technique involves a degree of randomness. This can lead to a situation where similar images may not get mapped to the same hash bucket every time the process is run. To reduce this effect, we'll maintain multiple hash tables. The number of hash tables and the reduction dimensionality are the two key hyperparameters here.
class LSH:
def __init__(self, hash_size, num_tables):
self.num_tables = num_tables
self.tables = []
for i in range(self.num_tables):
self.tables.append(Table(hash_size))
def add(self, id: int, hash: List[int], label: int):
for table in self.tables:
table.add(id, hash, label)
def query(self, hashes: List[int]):
results = []
for table in self.tables:
results.extend(table.query(hashes))
return results
The BuildLSHTable class¶
It lets us:
build(): build the hash tables.query()with an input image aka the query image.
device = "cuda" if torch.cuda.is_available() else "cpu"
from PIL import Image
import datasets
class BuildLSHTable:
def __init__(
self,
model: Union[torch.nn.Module, None],
batch_size: int = 48,
hash_size: int = hash_size,
dim: int = hidden_dim,
num_tables: int = 10,
):
self.hash_size = hash_size
self.dim = dim
self.num_tables = num_tables
self.lsh = LSH(self.hash_size, self.num_tables)
self.batch_size = batch_size
self.hash_fn = compute_hash(model.to(device))
def build(self, ds: datasets.DatasetDict):
dataset_hashed = ds.map(self.hash_fn, batched=True, batch_size=self.batch_size)
for id in tqdm(range(len(dataset_hashed))):
hash, label = dataset_hashed[id]["hashes"], dataset_hashed[id]["labels"]
self.lsh.add(id, hash, label)
def query(self, image, verbose=True):
if isinstance(image, str):
image = Image.open(image).convert("RGB")
# Compute the hashes of the query image and fetch the results.
example_batch = dict(image=[image])
hashes = self.hash_fn(example_batch)["hashes"][0]
results = self.lsh.query(hashes)
if verbose:
print("Matches:", len(results))
# Calculate Jaccard index to quantify the similarity.
counts = {}
for r in results:
if r["id_label"] in counts:
counts[r["id_label"]] += 1
else:
counts[r["id_label"]] = 1
for k in counts:
counts[k] = float(counts[k]) / self.dim
return counts
Notes on quantifying similarity:
We're using Jaccard index to quantify the similarity between the query image and the candidate images. As per Scikit Learn's documentation:
it is defined as the size of the intersection divided by the size of the union of two label sets.
Since we're using LSH to build the similarity system and the hashes are effectively sets, Jaccard index is a good metric to use here.
Building the LSH tables¶
lsh_builder = BuildLSHTable(model)
lsh_builder.build(dataset["train"].shuffle(seed=seed))
WARNING:datasets.arrow_dataset:Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/beans/default/0.0.0/90c755fb6db1c0ccdad02e897a37969dbf070bed3755d4391e269ff70642d791/cache-14b4efbce765f9cb.arrow
0%| | 0/22 [00:00<?, ?ba/s]
0%| | 0/1034 [00:00<?, ?it/s]
To get a better a idea of how the tables are represented internally within lsh_builder, let's investigate the contents of a single table.
idx = 0
for hash, entry in lsh_builder.lsh.tables[0].table.items():
if idx == 5:
break
if len(entry) < 5:
print(f"Hash: {hash}, entries: {entry}")
idx += 1
Hash: 255, entries: [{'id_label': '12_0'}]
Hash: 71, entries: [{'id_label': '78_1'}, {'id_label': '374_2'}]
Hash: 228, entries: [{'id_label': '94_2'}, {'id_label': '774_2'}]
Hash: 81, entries: [{'id_label': '115_2'}]
Hash: 181, entries: [{'id_label': '188_0'}, {'id_label': '610_0'}, {'id_label': '985_0'}]
We notice that for a given hash value, we have entries where labels are the same. Because of the randomness induced in the process, we may also notice some entries coming from different labels. It can happen for various reasons:
- The reduction dimensionality is too small for compression.
- The underlying images may be visually quite similar to one another yet have different labels.
In both of the above cases, experimentation is really the key to improving the results.
Now that the LSH tables have been built, we can use them to query them with images.
Inference¶
In this secton, we'll take query images from the test split of our dataset and retrieve the similar images from the set of candidate images we have.
candidate_dataset = dataset["train"].shuffle(seed=seed)
def visualize_lsh(lsh_class: BuildLSHTable, top_k: int = 5):
idx = np.random.choice(len(dataset["test"]))
image = dataset["test"][idx]["image"]
label = dataset["test"][idx]["labels"]
results = lsh_class.query(image)
candidates = []
labels = []
overlaps = []
for idx, r in enumerate(sorted(results, key=results.get, reverse=True)):
if idx == top_k:
break
image_id, label = r.split("_")[0], r.split("_")[1]
candidates.append(candidate_dataset[int(image_id)]["image"])
labels.append(label)
overlaps.append(results[r])
candidates.insert(0, image)
labels.insert(0, label)
plot_images(candidates, labels)
WARNING:datasets.arrow_dataset:Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/beans/default/0.0.0/90c755fb6db1c0ccdad02e897a37969dbf070bed3755d4391e269ff70642d791/cache-14b4efbce765f9cb.arrow
for _ in range(5):
visualize_lsh(lsh_builder)
Matches: 2280 Matches: 480 Matches: 2280 Matches: 590 Matches: 1050





Not bad! Looks like our similarity system is fetching the correct images.
Storage-wise, we'd just have to store the lsh attribute of lsh_builder that has all the LSH tables:
import pickle
with open("lsh.pickle", "wb") as handle:
pickle.dump(lsh_builder.lsh, handle, protocol=pickle.HIGHEST_PROTOCOL)
After this, we can use it like so:
with open("lsh.pickle", "wb") as handle:
lsh_cls = pickle.load(handle)
lsh_builder = BuildLSHTable(model)
lsh_builder.lsh = lsh_cls
This way, instead of storing 768-d floating-point embedding vectors we're just storing 8-bit integers which are much more lightweight. Needless to say, this helps reduce the computation costs too.
Conclusion¶
That was a lot of content covered in this notebook. Be sure to take them step by step. In this section, we want to leave you with some extensions we provide regarding similarity systems.
🤗 Datasets offers direct integrations with FAISS which further simplifies the process of building similarity systems. To know more, you can check out the official documentation and this notebook. Additionally, we have created this Space application that lets you easily demo an image similarity system with more interactivity.
We encourage you to try these tools out and rebuild your own similarity system.