Fine-tuning for Image Classification with 🤗 Transformers¶
This notebook shows how to fine-tune any pretrained Vision model for Image Classification on a custom dataset. The idea is to add a randomly initialized classification head on top of a pre-trained encoder, and fine-tune the model altogether on a labeled dataset.
ImageFolder feature¶
This notebook leverages the ImageFolder feature to easily run the notebook on a custom dataset (namely, EuroSAT in this tutorial). You can either load a Dataset from local folders or from local/remote files, like zip or tar.
Any model¶
This notebook is built to run on any image classification dataset with any vision model checkpoint from the Model Hub as long as that model has a version with a Image Classification head, such as:
- in short, any model supported by AutoModelForImageClassification.
Albumentations¶
In this notebook, we are going to leverage the Albumentations library for data augmentation. Note that we have other versions of this notebook available as well with other libraries including:
Depending on the model and the GPU you are using, you might need to adjust the batch size to avoid out-of-memory errors. Set those two parameters, then the rest of the notebook should run smoothly.
In this notebook, we'll fine-tune from the https://huggingface.co/facebook/convnext-tiny-224 checkpoint, but note that there are many, many more available on the hub.
model_checkpoint = "facebook/convnext-tiny-224" # pre-trained model from which to fine-tune
batch_size = 32 # batch size for training and evaluation
Before we start, let's install the datasets, transformers and albumentations libraries.
!pip install -q datasets transformers
|████████████████████████████████| 325 kB 8.7 MB/s
|████████████████████████████████| 4.0 MB 67.0 MB/s
|████████████████████████████████| 77 kB 8.1 MB/s
|████████████████████████████████| 1.1 MB 48.8 MB/s
|████████████████████████████████| 136 kB 72.0 MB/s
|████████████████████████████████| 212 kB 72.9 MB/s
|████████████████████████████████| 127 kB 75.0 MB/s
|████████████████████████████████| 895 kB 67.3 MB/s
|████████████████████████████████| 6.5 MB 56.3 MB/s
|████████████████████████████████| 596 kB 76.4 MB/s
|████████████████████████████████| 144 kB 76.3 MB/s
|████████████████████████████████| 94 kB 3.3 MB/s
|████████████████████████████████| 271 kB 77.3 MB/s
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
datascience 0.10.6 requires folium==0.2.1, but you have folium 0.8.3 which is incompatible.
!pip install -q albumentations
|████████████████████████████████| 631 kB 8.4 MB/s Building wheel for imgaug (setup.py) ... done
If you're opening this notebook locally, make sure your environment has an install from the last version of those libraries.
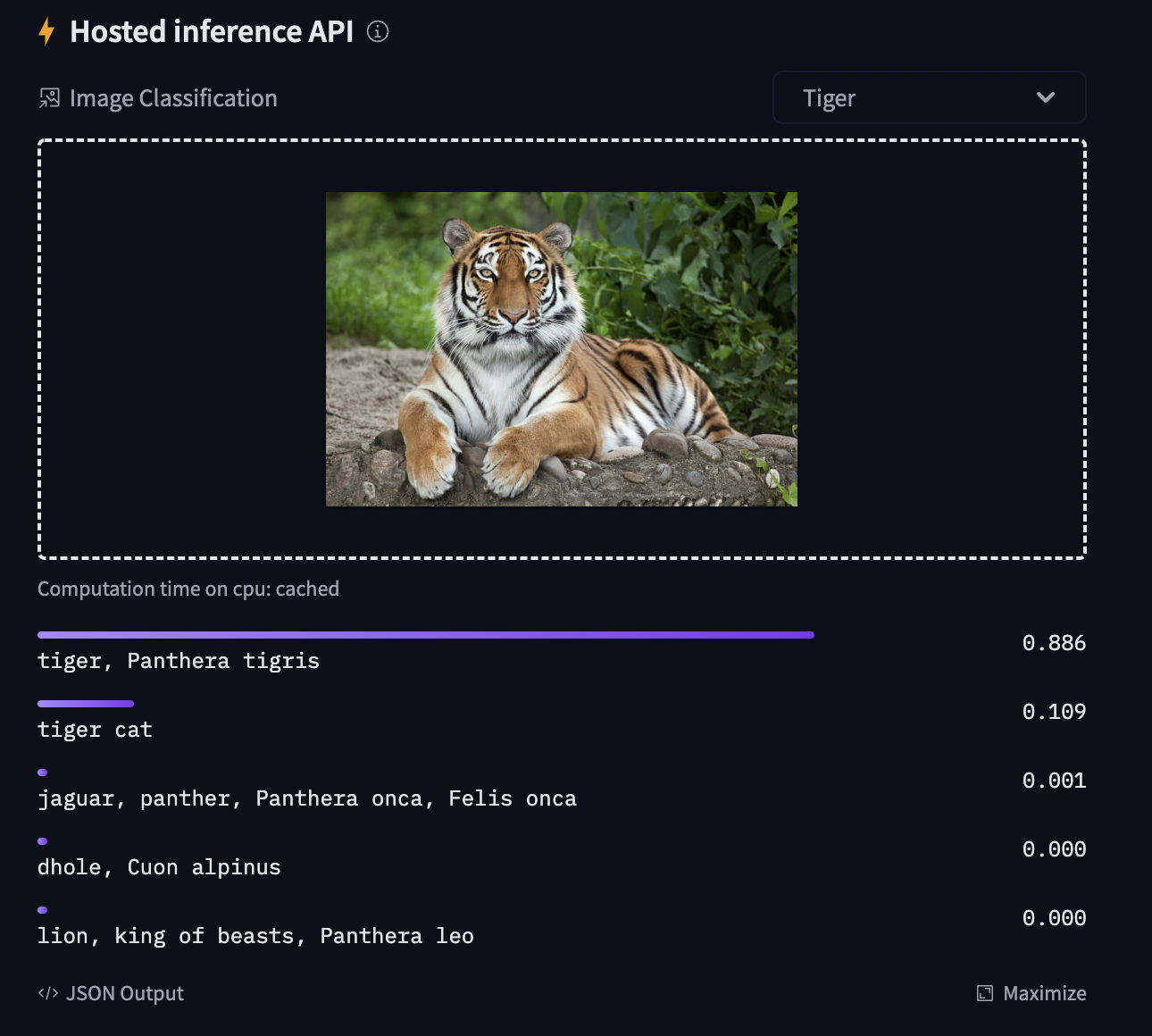
To be able to share your model with the community and generate results like the one shown in the picture below via the inference API, there are a few more steps to follow.
First you have to store your authentication token from the Hugging Face website (sign up here if you haven't already!) then execute the following cell and input your token:
from huggingface_hub import notebook_login
notebook_login()
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
Then you need to install Git-LFS to upload your model checkpoints:
%%capture
!sudo apt -qq install git-lfs
!git config --global credential.helper store
Fine-tuning a model on an image classification task¶
In this notebook, we will see how to fine-tune one of the 🤗 Transformers vision models on an Image Classification dataset.
Given an image, the goal is to predict an appropriate class for it, like "tiger". The screenshot below is taken from a ViT fine-tuned on ImageNet-1k - try out the inference widget!
Loading the dataset¶
We will use the 🤗 Datasets library's ImageFolder feature to download our custom dataset into a DatasetDict.
In this case, the EuroSAT dataset is hosted remotely, so we provide the data_files argument. Alternatively, if you have local folders with images, you can load them using the data_dir argument.
from datasets import load_dataset
# load a custom dataset from local/remote files using the ImageFolder feature
# option 1: local/remote files (supporting the following formats: tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="https://madm.dfki.de/files/sentinel/EuroSAT.zip")
# note that you can also provide several splits:
# dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
# note that you can push your dataset to the hub very easily (and reload afterwards using load_dataset)!
# dataset.push_to_hub("nielsr/eurosat")
# dataset.push_to_hub("nielsr/eurosat", private=True)
# option 2: local folder
# dataset = load_dataset("imagefolder", data_dir="path_to_folder")
# option 3: just load any existing dataset from the hub ...
# dataset = load_dataset("cifar10")
Using custom data configuration default-0537267e6f812d56
Downloading and preparing dataset image_folder/default to /root/.cache/huggingface/datasets/image_folder/default-0537267e6f812d56/0.0.0/ee92df8e96c6907f3c851a987be3fd03d4b93b247e727b69a8e23ac94392a091...
Downloading data files: 0it [00:00, ?it/s]
Downloading data files: 0%| | 0/1 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/94.3M [00:00<?, ?B/s]
Extracting data files: 0%| | 0/1 [00:00<?, ?it/s]
Generating train split: 0 examples [00:00, ? examples/s]
Dataset image_folder downloaded and prepared to /root/.cache/huggingface/datasets/image_folder/default-0537267e6f812d56/0.0.0/ee92df8e96c6907f3c851a987be3fd03d4b93b247e727b69a8e23ac94392a091. Subsequent calls will reuse this data.
0%| | 0/1 [00:00<?, ?it/s]
Let us also load the Accuracy metric, which we'll use to evaluate our model both during and after training.
from datasets import load_metric
metric = load_metric("accuracy")
Downloading builder script: 0%| | 0.00/1.41k [00:00<?, ?B/s]
The dataset object itself is a DatasetDict, which contains one key per split (in this case, only "train" for a training split).
dataset
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 27000
})
})
To access an actual element, you need to select a split first, then give an index:
example = dataset["train"][10]
example
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=64x64 at 0x7FD62DA6B2D0>,
'label': 2}
Each example consists of an image and a corresponding label. We can also verify this by checking the features of the dataset:
dataset["train"].features
{'image': Image(decode=True, id=None),
'label': ClassLabel(num_classes=10, names=['AnnualCrop', 'Forest', 'HerbaceousVegetation', 'Highway', 'Industrial', 'Pasture', 'PermanentCrop', 'Residential', 'River', 'SeaLake'], id=None)}
The cool thing is that we can directly view the image (as the 'image' field is an Image feature), as follows:
example['image']

Let's make it a little bigger as the images in the EuroSAT dataset are of low resolution (64x64 pixels):
example['image'].resize((200, 200))

Let's check the corresponding label:
example['label']
2
As you can see, the label field is not an actual string label. By default the ClassLabel fields are encoded into integers for convenience:
dataset["train"].features["label"]
ClassLabel(num_classes=10, names=['AnnualCrop', 'Forest', 'HerbaceousVegetation', 'Highway', 'Industrial', 'Pasture', 'PermanentCrop', 'Residential', 'River', 'SeaLake'], id=None)
Let's create an id2label dictionary to decode them back to strings and see what they are. The inverse label2id will be useful too, when we load the model later.
labels = dataset["train"].features["label"].names
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = i
id2label[i] = label
id2label[2]
'HerbaceousVegetation'
Preprocessing the data¶
Before we can feed these images to our model, we need to preprocess them.
Preprocessing images typically comes down to (1) resizing them to a particular size (2) normalizing the color channels (R,G,B) using a mean and standard deviation. These are referred to as image transformations.
In addition, one typically performs what is called data augmentation during training (like random cropping and flipping) to make the model more robust and achieve higher accuracy. Data augmentation is also a great technique to increase the size of the training data.
We will use Albumentations for the image transformations/data augmentation in this tutorial, but note that one can use any other package (like torchvision's transforms, imgaug, Kornia, etc.).
To make sure we (1) resize to the appropriate size (2) use the appropriate image mean and standard deviation for the model architecture we are going to use, we instantiate what is called a feature extractor with the AutoFeatureExtractor.from_pretrained method.
This feature extractor is a minimal preprocessor that can be used to prepare images for inference.
from transformers import AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained(model_checkpoint)
feature_extractor
ConvNextFeatureExtractor {
"crop_pct": 0.875,
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ConvNextFeatureExtractor",
"image_mean": [
0.485,
0.456,
0.406
],
"image_std": [
0.229,
0.224,
0.225
],
"resample": 3,
"size": 224
}
The Datasets library is made for processing data very easily. We can write custom functions, which can then be applied on an entire dataset (either using .map() or .set_transform()).
Here we define 2 separate functions, one for training (which includes data augmentation) and one for validation (which only includes resizing, center cropping and normalizing).
import cv2
import albumentations as A
import numpy as np
size = feature_extractor.size
train_transforms = A.Compose([
A.Resize(height=size, width=size),
A.RandomRotate90(),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.Normalize(),
])
val_transforms = A.Compose([
A.Resize(height=size, width=size),
A.Normalize(),
])
def preprocess_train(examples):
examples["pixel_values"] = [
train_transforms(image=np.array(image))["image"] for image in examples["image"]
]
return examples
def preprocess_val(examples):
examples["pixel_values"] = [
val_transforms(image=np.array(image))["image"] for image in examples["image"]
]
return examples
Next, we can preprocess our dataset by applying these functions. We will use the set_transform functionality, which allows to apply the functions above on-the-fly (meaning that they will only be applied when the images are loaded in RAM).
# split up training into training + validation
splits = dataset["train"].train_test_split(test_size=0.1)
train_ds = splits['train']
val_ds = splits['test']
train_ds.set_transform(preprocess_train)
val_ds.set_transform(preprocess_val)
Let's check the first example:
train_ds[0]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=64x64 at 0x7FD610178490>,
'label': 5,
'pixel_values': array([[[-1.415789 , -0.53011197, -0.37525052],
[-1.415789 , -0.53011197, -0.37525052],
[-1.415789 , -0.53011197, -0.37525052],
...,
[-1.34729 , -0.897759 , -0.37525052],
[-1.34729 , -0.897759 , -0.37525052],
[-1.34729 , -0.897759 , -0.37525052]],
[[-1.415789 , -0.53011197, -0.37525052],
[-1.415789 , -0.53011197, -0.37525052],
[-1.415789 , -0.53011197, -0.37525052],
...,
[-1.34729 , -0.897759 , -0.37525052],
[-1.34729 , -0.897759 , -0.37525052],
[-1.34729 , -0.897759 , -0.37525052]],
[[-1.415789 , -0.53011197, -0.37525052],
[-1.415789 , -0.53011197, -0.37525052],
[-1.415789 , -0.53011197, -0.37525052],
...,
[-1.3986642 , -0.93277305, -0.4101089 ],
[-1.3986642 , -0.93277305, -0.4101089 ],
[-1.3986642 , -0.93277305, -0.4101089 ]],
...,
[[-1.5014129 , -0.582633 , -0.35782132],
[-1.5014129 , -0.582633 , -0.35782132],
[-1.5014129 , -0.582633 , -0.35782132],
...,
[-1.4842881 , -0.98529404, -0.5146841 ],
[-1.4671633 , -1.0028011 , -0.49725488],
[-1.4671633 , -1.0028011 , -0.49725488]],
[[-1.5356623 , -0.565126 , -0.3403921 ],
[-1.5356623 , -0.565126 , -0.3403921 ],
[-1.5356623 , -0.565126 , -0.35782132],
...,
[-1.4842881 , -0.98529404, -0.5146841 ],
[-1.4671633 , -1.0028011 , -0.49725488],
[-1.4671633 , -1.0028011 , -0.49725488]],
[[-1.5356623 , -0.565126 , -0.3403921 ],
[-1.5356623 , -0.565126 , -0.3403921 ],
[-1.5356623 , -0.565126 , -0.35782132],
...,
[-1.4842881 , -0.98529404, -0.5146841 ],
[-1.4671633 , -1.0028011 , -0.49725488],
[-1.4671633 , -1.0028011 , -0.49725488]]], dtype=float32)}
Training the model¶
Now that our data is ready, we can download the pretrained model and fine-tune it. For classification we use the AutoModelForImageClassification class. Like with the feature extractor, the from_pretrained method will download and cache the model for us. As the label ids and the number of labels are dataset dependent, we pass num_labels, label2id, and id2label alongside the model_checkpoint he£re.
NOTE: in case you're planning to fine-tune an already fine-tuned checkpoint, like facebook/convnext-tiny-224 (which has already been fine-tuned on ImageNet-1k), then you need to provide the additional argument ignore_mismatched_sizes=True to the from_pretrained method. This will make sure the output head is thrown away and replaced by a new, randomly initialized classification head that includes a custom number of output neurons.
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
num_labels = len(id2label)
model = AutoModelForImageClassification.from_pretrained(
model_checkpoint,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes = True, # provide this in case you'd like to fine-tune an already fine-tuned checkpoint
)
Downloading: 0%| | 0.00/68.0k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/109M [00:00<?, ?B/s]
Some weights of ConvNextForImageClassification were not initialized from the model checkpoint at facebook/convnext-tiny-224 and are newly initialized because the shapes did not match: - classifier.weight: found shape torch.Size([1000, 768]) in the checkpoint and torch.Size([10, 768]) in the model instantiated - classifier.bias: found shape torch.Size([1000]) in the checkpoint and torch.Size([10]) in the model instantiated You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
The warning is telling us we are throwing away some weights (the weights and bias of the pooler layer) and randomly initializing some other (the weights and bias of the classifier layer). This is expected in this case, because we are adding a new head for which we don't have pretrained weights, so the library warns us we should fine-tune this model before using it for inference, which is exactly what we are going to do.
To instantiate a Trainer, we will need to define the training configuration and the evaluation metric. The most important is the TrainingArguments, which is a class that contains all the attributes to customize the training. It requires one folder name, which will be used to save the checkpoints of the model.
Most of the training arguments are pretty self-explanatory, but one that is quite important here is remove_unused_columns=False. This one will drop any features not used by the model's call function. By default it's True because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in our case, we need the unused features ('img' in particular) in order to create 'pixel_values'.
model_name = model_checkpoint.split("/")[-1]
args = TrainingArguments(
f"{model_name}-finetuned-eurosat-albumentations",
remove_unused_columns=False,
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate=5e-5,
per_device_train_batch_size=batch_size,
gradient_accumulation_steps=4,
per_device_eval_batch_size=batch_size,
num_train_epochs=3,
warmup_ratio=0.1,
logging_steps=10,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
push_to_hub=True,
)
Here we set the evaluation to be done at the end of each epoch, tweak the learning rate, use the batch_size defined at the top of the notebook and customize the number of epochs for training, as well as the weight decay. Since the best model might not be the one at the end of training, we ask the Trainer to load the best model it saved (according to metric_name) at the end of training.
The last argument push_to_hub allows the Trainer to push the model to the Hub regularly during training. Remove it if you didn't follow the installation steps at the top of the notebook. If you want to save your model locally with a name that is different from the name of the repository, or if you want to push your model under an organization and not your name space, use the hub_model_id argument to set the repo name (it needs to be the full name, including your namespace: for instance "nielsr/vit-finetuned-cifar10" or "huggingface/nielsr/vit-finetuned-cifar10").
Next, we need to define a function for how to compute the metrics from the predictions, which will just use the metric we loaded earlier. The only preprocessing we have to do is to take the argmax of our predicted logits:
import numpy as np
# the compute_metrics function takes a Named Tuple as input:
# predictions, which are the logits of the model as Numpy arrays,
# and label_ids, which are the ground-truth labels as Numpy arrays.
def compute_metrics(eval_pred):
"""Computes accuracy on a batch of predictions"""
predictions = np.argmax(eval_pred.predictions, axis=1)
return metric.compute(predictions=predictions, references=eval_pred.label_ids)
We also define a collate_fn, which will be used to batch examples together.
Each batch consists of 2 keys, namely pixel_values and labels.
import torch
def collate_fn(examples):
images = []
labels = []
for example in examples:
image = np.moveaxis(example["pixel_values"], source=2, destination=0)
images.append(torch.from_numpy(image))
labels.append(example["label"])
pixel_values = torch.stack(images)
labels = torch.tensor(labels)
return {"pixel_values": pixel_values, "labels": labels}
Then we just need to pass all of this along with our datasets to the Trainer:
trainer = Trainer(
model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=feature_extractor,
compute_metrics=compute_metrics,
data_collator=collate_fn,
)
/content/convnext-tiny-224-finetuned-eurosat-albumentations is already a clone of https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations. Make sure you pull the latest changes with `repo.git_pull()`.
You might wonder why we pass along the feature_extractor as a tokenizer when we already preprocessed our data. This is only to make sure the feature extractor configuration file (stored as JSON) will also be uploaded to the repo on the hub.
Now we can finetune our model by calling the train method:
trainer.train()
/usr/local/lib/python3.7/dist-packages/transformers/optimization.py:309: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning FutureWarning, ***** Running training ***** Num examples = 24300 Num Epochs = 3 Instantaneous batch size per device = 32 Total train batch size (w. parallel, distributed & accumulation) = 128 Gradient Accumulation steps = 4 Total optimization steps = 570
| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 1 | 0.141000 | 0.149633 | 0.954444 |
| 2 | 0.073600 | 0.095782 | 0.971852 |
| 3 | 0.056800 | 0.072716 | 0.974815 |
***** Running Evaluation ***** Num examples = 2700 Batch size = 32 Saving model checkpoint to convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-190 Configuration saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-190/config.json Model weights saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-190/pytorch_model.bin Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-190/preprocessor_config.json Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/preprocessor_config.json ***** Running Evaluation ***** Num examples = 2700 Batch size = 32 Saving model checkpoint to convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-380 Configuration saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-380/config.json Model weights saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-380/pytorch_model.bin Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-380/preprocessor_config.json Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/preprocessor_config.json ***** Running Evaluation ***** Num examples = 2700 Batch size = 32 Saving model checkpoint to convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-570 Configuration saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-570/config.json Model weights saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-570/pytorch_model.bin Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-570/preprocessor_config.json Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/preprocessor_config.json Training completed. Do not forget to share your model on huggingface.co/models =) Loading best model from convnext-tiny-224-finetuned-eurosat-albumentations/checkpoint-570 (score: 0.9748148148148148).
TrainOutput(global_step=570, training_loss=0.34729809766275843, metrics={'train_runtime': 961.6293, 'train_samples_per_second': 75.809, 'train_steps_per_second': 0.593, 'total_flos': 1.8322098956292096e+18, 'train_loss': 0.34729809766275843, 'epoch': 3.0})
We can check with the evaluate method that our Trainer did reload the best model properly (if it was not the last one):
metrics = trainer.evaluate()
print(metrics)
***** Running Evaluation ***** Num examples = 2700 Batch size = 32
{'eval_loss': 0.0727163776755333, 'eval_accuracy': 0.9748148148148148, 'eval_runtime': 13.0419, 'eval_samples_per_second': 207.026, 'eval_steps_per_second': 6.517, 'epoch': 3.0}
You can now upload the result of the training to the Hub, just execute this instruction (note that the Trainer will automatically create a model card for you, as well as adding Tensorboard metrics - see the "Training metrics" tab!):
trainer.push_to_hub()
Saving model checkpoint to convnext-tiny-224-finetuned-eurosat-albumentations Configuration saved in convnext-tiny-224-finetuned-eurosat-albumentations/config.json Model weights saved in convnext-tiny-224-finetuned-eurosat-albumentations/pytorch_model.bin Feature extractor saved in convnext-tiny-224-finetuned-eurosat-albumentations/preprocessor_config.json
Upload file runs/Apr12_12-03-24_1ad162e1ead9/events.out.tfevents.1649765159.1ad162e1ead9.73.4: 24%|##4 …
Upload file runs/Apr12_12-03-24_1ad162e1ead9/events.out.tfevents.1649767032.1ad162e1ead9.73.6: 100%|##########…
To https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations c500b3f..2143b42 main -> main To https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations 2143b42..71339cf main -> main
'https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/commit/2143b423b5cacdde6daebd3ee2b5971ecab463f6'
You can now share this model with all your friends, family, favorite pets: they can all load it with the identifier "your-username/the-name-you-picked" so for instance:
from transformers import AutoModelForImageClassification, AutoFeatureExtractor
feature_extractor = AutoFeatureExtractor.from_pretrained("nielsr/my-awesome-model")
model = AutoModelForImageClassification.from_pretrained("nielsr/my-awesome-model")
Inference¶
Let's say you have a new image, on which you'd like to make a prediction. Let's load a satellite image of a highway (that's not part of the EuroSAT dataset), and see how the model does.
from PIL import Image
import requests
url = 'https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/highway.jpg'
image = Image.open(requests.get(url, stream=True).raw)
image

We'll load the feature extractor and model from the hub (here, we use the Auto Classes, which will make sure the appropriate classes will be loaded automatically based on the config.json and preprocessor_config.json files of the repo on the hub):
from transformers import AutoModelForImageClassification, AutoFeatureExtractor
repo_name = "nielsr/convnext-tiny-224-finetuned-eurosat-albumentations"
feature_extractor = AutoFeatureExtractor.from_pretrained(repo_name)
model = AutoModelForImageClassification.from_pretrained(repo_name)
https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/preprocessor_config.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmp04g0zg5n
Downloading: 0%| | 0.00/266 [00:00<?, ?B/s]
storing https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/preprocessor_config.json in cache at /root/.cache/huggingface/transformers/38b41a2c904b6ce5bb10403bf902ee4263144d862c5a602c83cd120c0c1ba0e6.37be7274d6b5860aee104bb1fbaeb0722fec3850a85bb2557ae9491f17f89433
creating metadata file for /root/.cache/huggingface/transformers/38b41a2c904b6ce5bb10403bf902ee4263144d862c5a602c83cd120c0c1ba0e6.37be7274d6b5860aee104bb1fbaeb0722fec3850a85bb2557ae9491f17f89433
loading feature extractor configuration file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/preprocessor_config.json from cache at /root/.cache/huggingface/transformers/38b41a2c904b6ce5bb10403bf902ee4263144d862c5a602c83cd120c0c1ba0e6.37be7274d6b5860aee104bb1fbaeb0722fec3850a85bb2557ae9491f17f89433
Feature extractor ConvNextFeatureExtractor {
"crop_pct": 0.875,
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ConvNextFeatureExtractor",
"image_mean": [
0.485,
0.456,
0.406
],
"image_std": [
0.229,
0.224,
0.225
],
"resample": 3,
"size": 224
}
https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/config.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpbf9y4q39
Downloading: 0%| | 0.00/1.03k [00:00<?, ?B/s]
storing https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/config.json in cache at /root/.cache/huggingface/transformers/25088566ab29cf0ff360b05880b5f20cdc0c79ab995056a1fb4f98212d021154.4637c3f271a8dfbcfe5c4ee777270112d841a5af95814f0fd086c3c2761e7370
creating metadata file for /root/.cache/huggingface/transformers/25088566ab29cf0ff360b05880b5f20cdc0c79ab995056a1fb4f98212d021154.4637c3f271a8dfbcfe5c4ee777270112d841a5af95814f0fd086c3c2761e7370
loading configuration file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/25088566ab29cf0ff360b05880b5f20cdc0c79ab995056a1fb4f98212d021154.4637c3f271a8dfbcfe5c4ee777270112d841a5af95814f0fd086c3c2761e7370
Model config ConvNextConfig {
"_name_or_path": "nielsr/convnext-tiny-224-finetuned-eurosat-albumentations",
"architectures": [
"ConvNextForImageClassification"
],
"depths": [
3,
3,
9,
3
],
"drop_path_rate": 0.0,
"hidden_act": "gelu",
"hidden_sizes": [
96,
192,
384,
768
],
"id2label": {
"0": "AnnualCrop",
"1": "Forest",
"2": "HerbaceousVegetation",
"3": "Highway",
"4": "Industrial",
"5": "Pasture",
"6": "PermanentCrop",
"7": "Residential",
"8": "River",
"9": "SeaLake"
},
"image_size": 224,
"initializer_range": 0.02,
"label2id": {
"AnnualCrop": 0,
"Forest": 1,
"HerbaceousVegetation": 2,
"Highway": 3,
"Industrial": 4,
"Pasture": 5,
"PermanentCrop": 6,
"Residential": 7,
"River": 8,
"SeaLake": 9
},
"layer_norm_eps": 1e-12,
"layer_scale_init_value": 1e-06,
"model_type": "convnext",
"num_channels": 3,
"num_stages": 4,
"patch_size": 4,
"problem_type": "single_label_classification",
"torch_dtype": "float32",
"transformers_version": "4.18.0"
}
https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/pytorch_model.bin not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpzr_9yxjo
Downloading: 0%| | 0.00/106M [00:00<?, ?B/s]
storing https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/pytorch_model.bin in cache at /root/.cache/huggingface/transformers/3f4bcce35d3279d19b07fb762859d89bce636d8f0235685031ef6494800b9769.d611c768c0b0939188b05c3d505f0b36c97aa57649d4637e3384992d3c5c0b89 creating metadata file for /root/.cache/huggingface/transformers/3f4bcce35d3279d19b07fb762859d89bce636d8f0235685031ef6494800b9769.d611c768c0b0939188b05c3d505f0b36c97aa57649d4637e3384992d3c5c0b89 loading weights file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/3f4bcce35d3279d19b07fb762859d89bce636d8f0235685031ef6494800b9769.d611c768c0b0939188b05c3d505f0b36c97aa57649d4637e3384992d3c5c0b89 All model checkpoint weights were used when initializing ConvNextForImageClassification. All the weights of ConvNextForImageClassification were initialized from the model checkpoint at nielsr/convnext-tiny-224-finetuned-eurosat-albumentations. If your task is similar to the task the model of the checkpoint was trained on, you can already use ConvNextForImageClassification for predictions without further training.
# prepare image for the model
encoding = feature_extractor(image.convert("RGB"), return_tensors="pt")
print(encoding.pixel_values.shape)
torch.Size([1, 3, 224, 224])
import torch
# forward pass
with torch.no_grad():
outputs = model(**encoding)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
Predicted class: Highway
Looks like our model got it correct!
Pipeline API¶
An alternative way to quickly perform inference with any model on the hub is by leveraging the Pipeline API, which abstracts away all the steps we did manually above for us. It will perform the preprocessing, forward pass and postprocessing all in a single object.
Let's showcase this for our trained model:
from transformers import pipeline
pipe = pipeline("image-classification", "nielsr/convnext-tiny-224-finetuned-eurosat-albumentations")
loading configuration file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/25088566ab29cf0ff360b05880b5f20cdc0c79ab995056a1fb4f98212d021154.4637c3f271a8dfbcfe5c4ee777270112d841a5af95814f0fd086c3c2761e7370
Model config ConvNextConfig {
"_name_or_path": "nielsr/convnext-tiny-224-finetuned-eurosat-albumentations",
"architectures": [
"ConvNextForImageClassification"
],
"depths": [
3,
3,
9,
3
],
"drop_path_rate": 0.0,
"hidden_act": "gelu",
"hidden_sizes": [
96,
192,
384,
768
],
"id2label": {
"0": "AnnualCrop",
"1": "Forest",
"2": "HerbaceousVegetation",
"3": "Highway",
"4": "Industrial",
"5": "Pasture",
"6": "PermanentCrop",
"7": "Residential",
"8": "River",
"9": "SeaLake"
},
"image_size": 224,
"initializer_range": 0.02,
"label2id": {
"AnnualCrop": 0,
"Forest": 1,
"HerbaceousVegetation": 2,
"Highway": 3,
"Industrial": 4,
"Pasture": 5,
"PermanentCrop": 6,
"Residential": 7,
"River": 8,
"SeaLake": 9
},
"layer_norm_eps": 1e-12,
"layer_scale_init_value": 1e-06,
"model_type": "convnext",
"num_channels": 3,
"num_stages": 4,
"patch_size": 4,
"problem_type": "single_label_classification",
"torch_dtype": "float32",
"transformers_version": "4.18.0"
}
loading configuration file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/25088566ab29cf0ff360b05880b5f20cdc0c79ab995056a1fb4f98212d021154.4637c3f271a8dfbcfe5c4ee777270112d841a5af95814f0fd086c3c2761e7370
Model config ConvNextConfig {
"_name_or_path": "nielsr/convnext-tiny-224-finetuned-eurosat-albumentations",
"architectures": [
"ConvNextForImageClassification"
],
"depths": [
3,
3,
9,
3
],
"drop_path_rate": 0.0,
"hidden_act": "gelu",
"hidden_sizes": [
96,
192,
384,
768
],
"id2label": {
"0": "AnnualCrop",
"1": "Forest",
"2": "HerbaceousVegetation",
"3": "Highway",
"4": "Industrial",
"5": "Pasture",
"6": "PermanentCrop",
"7": "Residential",
"8": "River",
"9": "SeaLake"
},
"image_size": 224,
"initializer_range": 0.02,
"label2id": {
"AnnualCrop": 0,
"Forest": 1,
"HerbaceousVegetation": 2,
"Highway": 3,
"Industrial": 4,
"Pasture": 5,
"PermanentCrop": 6,
"Residential": 7,
"River": 8,
"SeaLake": 9
},
"layer_norm_eps": 1e-12,
"layer_scale_init_value": 1e-06,
"model_type": "convnext",
"num_channels": 3,
"num_stages": 4,
"patch_size": 4,
"problem_type": "single_label_classification",
"torch_dtype": "float32",
"transformers_version": "4.18.0"
}
loading weights file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/3f4bcce35d3279d19b07fb762859d89bce636d8f0235685031ef6494800b9769.d611c768c0b0939188b05c3d505f0b36c97aa57649d4637e3384992d3c5c0b89
All model checkpoint weights were used when initializing ConvNextForImageClassification.
All the weights of ConvNextForImageClassification were initialized from the model checkpoint at nielsr/convnext-tiny-224-finetuned-eurosat-albumentations.
If your task is similar to the task the model of the checkpoint was trained on, you can already use ConvNextForImageClassification for predictions without further training.
loading feature extractor configuration file https://huggingface.co/nielsr/convnext-tiny-224-finetuned-eurosat-albumentations/resolve/main/preprocessor_config.json from cache at /root/.cache/huggingface/transformers/38b41a2c904b6ce5bb10403bf902ee4263144d862c5a602c83cd120c0c1ba0e6.37be7274d6b5860aee104bb1fbaeb0722fec3850a85bb2557ae9491f17f89433
Feature extractor ConvNextFeatureExtractor {
"crop_pct": 0.875,
"do_normalize": true,
"do_resize": true,
"feature_extractor_type": "ConvNextFeatureExtractor",
"image_mean": [
0.485,
0.456,
0.406
],
"image_std": [
0.229,
0.224,
0.225
],
"resample": 3,
"size": 224
}
pipe(image)
[{'label': 'Highway', 'score': 0.5163754224777222},
{'label': 'River', 'score': 0.11824000626802444},
{'label': 'AnnualCrop', 'score': 0.05467210337519646},
{'label': 'PermanentCrop', 'score': 0.05066365748643875},
{'label': 'Industrial', 'score': 0.049283623695373535}]
As we can see, it does not only show the class label with the highest probability, but does return the top 5 labels, with their corresponding scores. Note that the pipelines also work with local models and feature extractors:
pipe = pipeline("image-classification",
model=model,
feature_extractor=feature_extractor)
pipe(image)
[{'label': 'Highway', 'score': 0.5163754224777222},
{'label': 'River', 'score': 0.11824000626802444},
{'label': 'AnnualCrop', 'score': 0.05467210337519646},
{'label': 'PermanentCrop', 'score': 0.05066365748643875},
{'label': 'Industrial', 'score': 0.049283623695373535}]