Tutorial on advanced features¶
from IPython.core.display import HTML, display
display(HTML("<style>.container { width:80% !important; }</style>"))
display(HTML("<style>div.output_scroll { height: 44em; }</style>"))
# install popmon (if not installed yet)
import sys
!"{sys.executable}" -m pip install -q popmon
import pandas as pd
import popmon
from popmon import resources
from popmon.config import Report, Settings
Data generation¶
Let's first load some data!
df = pd.read_csv(
resources.data("flight_delays.csv.gz"), index_col=0, parse_dates=["DATE"]
)
Simple report¶
Now we can go ahead and generate our first report!
df.pm_stability_report(time_axis="DATE")
If you inspect the report in the above example, you can see that for example for the maximum departure_delay on 2015-08-22 was more extreme than expected.
The time axis is a bit weird now (split into 40 bins of 9 days each), but fortunately we can specify that ourselves using the time_width parameter!
We'll also set the time_offset, which we set equal to the first data in the document (otherwise we may end up with the first bin containing only half a week of data).
Finally, for the remaining examples, we'll use extended_report=False in order to keep the size of the notebook somewhat limited.
settings = Settings(time_axis="DATE")
settings.report.extended_report = False
df.pm_stability_report(time_width="1w", time_offset="2015-07-02", settings=settings)
Finally, we could make the thresholds used in the traffic lights more stringent. For example, we could show the yellow traffic light for deviations bigger than 7 standard deviations, and the red traffic light for deviations bigger than 10 standard deviations.
settings = Settings(time_axis="DATE")
settings.report.extended_report = False
settings.monitoring.pull_rules = {"*_pull": [10, 7, -7, -10]}
df.pm_stability_report(
time_width="1w",
time_offset="2015-07-02",
settings=settings,
)
There are quite a few more parameters in pm_stability_report(), for example to select which features to use (e.g. features=['x']), or how to bin the different features (bin_specs={'x': {'bin_width': 1, 'bin_offset': 0}}).
We suggest that you check them out on your own!
Have a look at the documentation for popmon.pipeline.report.df_stability_report() (which corresponds to df.pm_stability_report()).
What about Spark DataFrames?¶
No problem! We can easily perform the same steps on a Spark DataFrame. One important thing to note there is that we need to include two jar files (used to create the histograms using Histogrammar) when we create our Spark session. These will be automatically downloaded the first time you run this command.
# download histogrammar jar files if not already installed, used for histogramming of spark dataframe
try:
from pyspark import __version__ as pyspark_version
from pyspark.sql import SparkSession
pyspark_installed = True
except ImportError:
print("pyspark needs to be installed for this example")
pyspark_installed = False
if pyspark_installed:
scala = "2.12" if int(pyspark_version[0]) >= 3 else "2.11"
hist_jar = f"io.github.histogrammar:histogrammar_{scala}:1.0.20"
hist_spark_jar = f"io.github.histogrammar:histogrammar-sparksql_{scala}:1.0.20"
spark = SparkSession.builder.config(
"spark.jars.packages", f"{hist_spark_jar},{hist_jar}"
).getOrCreate()
sdf = spark.createDataFrame(df)
settings = Settings(time_axis="DATE")
settings.report.extended_report = False
sdf.pm_stability_report(
time_width="1w",
time_offset="2015-07-02",
settings=settings,
)
Using other reference types¶
Using an external reference¶
Let's go back to Pandas again! (While all of this functionality also works on Spark DataFrames, it's just faster to illustrate it with Pandas.) What if we want to compare our DataFrame to another DataFrame? For example, because we trained a machine learning model on another DataFrame (which we'll call the reference data) and we want to monitor whether the new data (the current DataFrame) comes from a similar distribution? We can do that by specifying an external reference DataFrame.
settings = Settings(time_axis="DATE", reference_type="external")
settings.report.extended_report = False
df_ref = pd.read_csv(
resources.data("flight_delays_reference.csv.gz"), index_col=0, parse_dates=["DATE"]
)
df.pm_stability_report(
time_width="1w",
time_offset="2015-07-02",
reference=df_ref,
settings=settings,
)
Using an expanding reference¶
We can also use an expanding reference, which for each time slot uses all preceding time slots as a reference.
settings = Settings(time_axis="DATE")
settings.report.extended_report = False
settings.reference_type = "expanding"
df.pm_stability_report(
time_width="1w",
time_offset="2015-07-02",
settings=settings,
)
Using a rolling window reference¶
And finally, we can use a rolling window reference. Here we can play with some additional parameters: shift and window. We'll set the window parameter to 5.
settings = Settings(time_axis="DATE", reference_type="rolling")
settings.report.extended_report = False
settings.comparison.window = 5
df.pm_stability_report(
time_width="1w",
time_offset="2015-07-02",
settings=settings,
)
Accessing the datastore¶
When you need programmtic access to popmon's results, then you can access the datastore directly. For instanfce, you would like the exact maximum value of a histogram.
Plotting the individual histograms¶
Sometimes, when you're diving into alerts from the report, you may want to plot some individual histograms. Fortunately, you can! Let's first have a look at how these histograms are stored.
report = df.pm_stability_report(
time_axis="DATE", time_width="1w", time_offset="2015-07-02"
)
list(report.datastore.keys())
split_hists = report.datastore["split_hists"]["DEPARTURE_DELAY"]
split_hists
Here we see the histograms for each time slot. Let us focus on the first time slot and plot the corresponding histogram.
split_hist = split_hists.query("date == '2015-07-05 12:00:00'")
split_hist.histogram[0].plot.matplotlib();
And let's also plot the corresponding reference histogram.
split_hist.histogram_ref[0].plot.matplotlib();
Integrations¶
Access to the datastore means that its possible to integrate popmon in almost any workflow. To give an example, one could store the histogram data in a PostgreSQL database and load that from Grafana and benefit from their visualisation and alert handling features (e.g. send an email or slack message upon alert) [#158]. Similar flows are possible when popmon is integrated in a workflow scheduler framework, such as Airflow.
If you have set up such a workflow, please consider contributing this as a feature. In order to do so, open an issue in the repository.
Saving the report and the histograms to disk¶
If you run popmon regularly on the same dataset, you may want to store the report and the histograms to disk, so you can keep track of the alerts and easily inspect the histograms if anything goes wrong.
# As HTML report
report.to_file("report.html")
# Alternatively, as serialized Python object
# import pickle
# with open("report.pkl", "wb") as f:
# pickle.dump(report, f)
Tuning parameters after generating the report¶
If you want to tune parameters after you've created the report, you can do so easily using report.regenerate()
report_settings = Settings()
report_settings.report.last_n = 0
report_settings.report.skip_first_n = 0
report_settings.report.skip_last_n = 0
report_settings.report.section.histograms.plot_hist_n = 0
report_settings.report.report_filepath = None
report.regenerate(
store_key="html_report",
sections_key="report_sections",
settings=report_settings,
)
Building your own pipelines¶
The stability_report() interface covers many use cases, but if you need more flexibility, you can define your own custom pipeline. We provide an example here!
from popmon.analysis.profiling import HistProfiler
from popmon.base import Pipeline
from popmon.hist.hist_splitter import HistSplitter
from popmon.pipeline.report import StabilityReport
from popmon.visualization import ReportGenerator, SectionGenerator
datastore = {
"hists": df.pm_make_histograms(
time_axis="DATE", time_width="1w", time_offset="2015-07-02"
)
}
class CustomPipeline(Pipeline):
def __init__(self):
modules = [
HistSplitter(
read_key="hists", store_key="split_hists", feature_begins_with="DATE"
),
HistProfiler(read_key="split_hists", store_key="profiles"),
SectionGenerator(
section_name="Profiles",
read_key="profiles",
store_key="report_sections",
settings=report_settings.report,
),
ReportGenerator(
read_key="report_sections",
store_key="html_report",
settings=report_settings.report,
),
]
super().__init__(modules)
pipeline = CustomPipeline()
datastore = pipeline.transform(datastore)
stability_report = StabilityReport(datastore)
stability_report
The above makes a very simple report, containing only the profiles (and no comparisons, traffic lights or alerts). The next examples shows how you can add the comparisons!
from popmon.analysis.comparison.hist_comparer import ReferenceHistComparer
datastore = {
"hists": df.pm_make_histograms(
time_axis="DATE", time_width="1w", time_offset="2015-07-02"
)
}
class CustomComparisonsPipeline(Pipeline):
def __init__(self):
modules = [
HistSplitter(
read_key="hists", store_key="split_hists", feature_begins_with="DATE"
),
HistProfiler(read_key="split_hists", store_key="profiles"),
ReferenceHistComparer(
reference_key="split_hists",
assign_to_key="split_hists",
store_key="comparisons",
),
SectionGenerator(
section_name="Profiles",
read_key="profiles",
store_key="report_sections",
settings=report_settings.report,
),
SectionGenerator(
section_name="Comparisons",
read_key="comparisons",
store_key="report_sections",
settings=report_settings.report,
),
ReportGenerator(
read_key="report_sections",
store_key="html_report",
settings=report_settings.report,
),
]
super().__init__(modules)
pipeline = CustomComparisonsPipeline()
datastore = pipeline.transform(datastore)
stability_report = StabilityReport(datastore)
stability_report
If you're interested in more complex examples, check the code in popmon.pipeline.report_pipelines.
Using the custom pipelines it becomes relatively easy to include new profiles and new comparisons. If you do, be sure to let us know! You may be able to make a pull request and add it to the package.
Pipeline Visualization¶
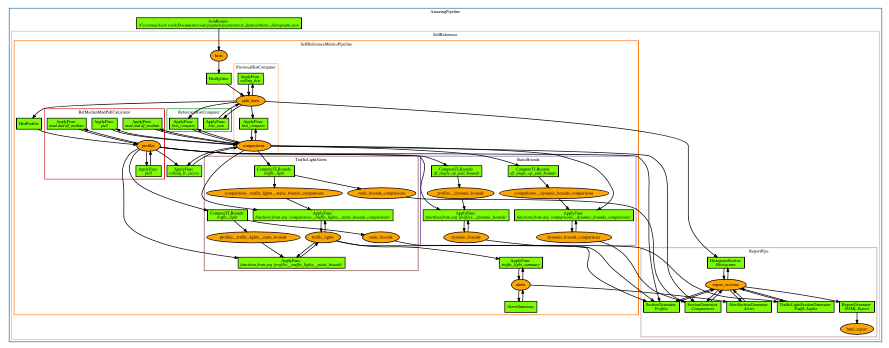 (Click to enlarge)
(Click to enlarge)
Visualization of the pipeline can be useful when debugging, or for didactic purposes. There is a script included with the package that you can use. The plotting is configurable, and depending on the options you will obtain a result that can be used for understanding the data flow, the high-level components and the (re)use of datasets. The parameters are: subgraph (yes/no), version datasets (yes/no) and display edge labels (yes/no).