For years now, we hear calls for “learning to code.” These calls may be well-intentioned and worthwhile, but they miss the point—what we need is coding to learn.
Seymour Papert, who claimed that “children can learn to program and that learning to program can affect the way they learn everything else,” is the father of computational thinking. But what did he mean by this? “It did not occur to me that anyone could possibly take my statement to mean that learning to program would by itself have consequences for how children learn and think. […] Encouraging programming as an activity meant to be good in itself is far removed, in its nature, from working at identifying ideas that have been disempowered and seeking ways to re-empower them. […] Of course, it is harder to think about ideas than to bring a programming language into a classroom.” (Papert, 2000.)
In this first section, I want to unpack the richness of Papertian thought about the role of computational technology, and explain what I mean by “coding to learn.” This discussion represents “the why” behind most of my educational efforts in the past few years.
The national narrative about “learning to code” is often about jobs, or about producing skilled workers for the needs of our technology fueled economy. Salient quotes from prominent people include:1
President Bill Clinton:
At a time when people are saying “I want a good job – I got out of college and I couldn't find one,” every single year in America there is a standing demand for 120,000 people who are training in computer science.
Michael Bloomberg, Former Mayor, New York City:
New York City’s economic future depends on it, and while we’re already giving thousands of our students the opportunity to learn how to code, much more can and should be done.
Arne Duncan, Former Secretary of Education:
To compete in a global market, our students need high-quality STEM education including computer science skills such as coding.
Sir Richard Branson gets closer to the core of it:
Teaching young people to code early on can help build skills and confidence and energize the classroom with learning-by-doing opportunities.
Meanwhile, anyone repeating the recurrent theme that simply learning to code will somehow make you better at thinking, overall, or that everyone should learn to think like a computer scientist to get better at problem-solving, is just misinterpreting Papert’s ideas.
To bring the point home, let’s study a deep example, from a 1995 semi-obscure gem of a paper by Uri Wilensky, Professor of Learning Sciences and Computer Science at Northwestern University. Wilensky (1995) examines the case study of a learner faced with a probability paradox. Attacking the paradox computationally, she develops strong intuition about the ideas of randomness and distribution. Concepts such as these are a stumbling block for learning probability, and engaging computationally to “solve” a paradox can motivate learners and drive them to build new mathematical understanding.
It was true in the 1990s, but it’s even more critical today, that learning probability and statistics is essential for all students in natural, physical and social sciences. We could argue that it is necessary knowledge to be an informed citizen in modern society, with statistics mentioned in the media with increasing frequency, and data science penetrating all sectors of the economy. Unfortunately, lack of understanding of probability and statistics is rife, even among professionals. College students are also generally averse to the subject, which is typically presented in highly formal instructional settings (formulas to be memorized). Developing intuition about probability is difficult because, in our everyday lives, we rarely encounter large numbers of repeated trials, a fundamental ingredient of probability. Exploratory computational environments give us access to manipulating large numbers and help develop probabilistic reasoning.
In the Wilensky (1995) case study, a learner will explore the meaning of randomness. She is presented with this seemingly well-defined question: If you choose a random chord on a given circle, what is the probability that the chord is longer than the circle’s radius?
It turns out, this question has a hidden ambiguity, and it admits more than one possible answer. The learner in the case study, Ellie, is a professional with good undergraduate background in mathematics. Yet, like virtually anyone else, she will struggle with the meaning of randomness. She begins her exploration of the question by drawing a circle, and tracing a chord that has length equal to the circle’s radius (see the figure below). Then she draws the radii from the chord's endpoints. Looking at this diagram, she sees that she can fit six such equilateral triangles inside the circle. She draws another chord of length equal to the radius, from one endpoint of the first (point P in the figure). She develops an argument for the solution: picking point P, you can draw a chord from it of length smaller than a radius if you pick the second point on either side within an arc of 60 degrees: one sixth of the circle. Thus, the probability of picking a chord shorter than a radius is $1/3$, and a chord longer than a radius is $2/3$. That's Ellie's answer.
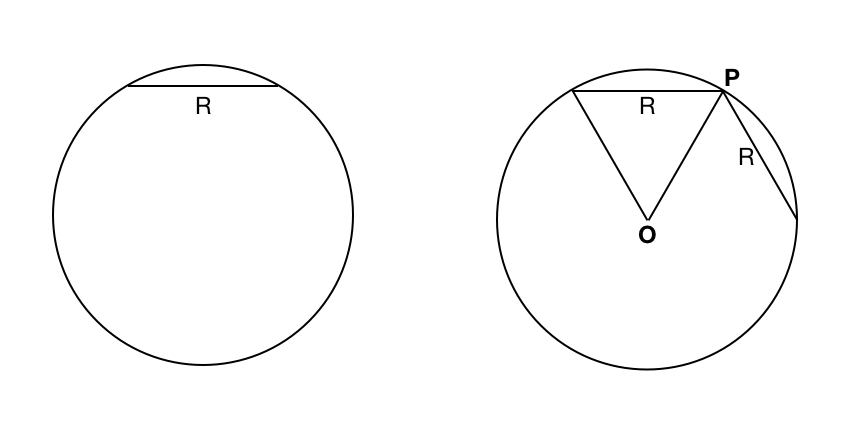 #### A learner's diagram to answer the probability question
#### A learner's diagram to answer the probability question
Ellie's interviewer poses a different way to look a the problem (see figure below). He says: imagine point P is now the midpoint of a chord of length one radius, and we drop a perpendicular line to the center of the circle, O. With the radius drawn from one endpoint of the chord, this forms a right triangle, with one side of length $R/2$ and the hypothenuse of length $R$.
Using Pythagoras, the side OP has length $R \sqrt{3/4}$. Now imagine you draw a circle C2 of that radius: any point inside that circle taken as the midpoint of a chord for C1 will result in a chord longer than $R$. Any point in the annulus between C1 and C2, taken as the midpoint of a chord for C1 will result in a chord shorter than $R$. We take the probability of choosing a random chord that is longer than $R$ as the ratio of the areas of C2 and C1: $3/4 \pi R^2$ vs $\pi R^2$. So the answer is $3/4$.
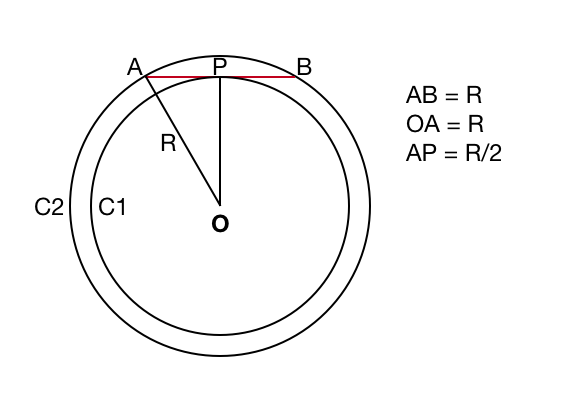 #### A diagram of the inteviewer's challenge to Ellie's answer
#### A diagram of the inteviewer's challenge to Ellie's answer
Faced with the paradox of two different yet reasonable answers to the question, Ellie is uneasy. Surely only one can be the right answer. Prompted by the interviewer, Ellie sets about writing a computer program to simulate an experiment and calculate the "correct" probability value. In the process of writing the program, she is uneasy again: she has to choose a method to generate the random chords. She chose an approach consistent with her initial argument, and computed some statistics, after a while getting the value of $2/3$. But she realizes this doesn't settle the question: if she generated the chords using an method matching the interviewer's idea, she might get $3/4$. Which is the correct way of generating the chords?
Translating her reasoning into a computer program shifted Ellie's attention from the task of finding the probability value, to finding the best way to generate random chords. This shift allows her to investigate what is the meaning of "random." She realizes that depending on which experiment she chooses to implement, she will get one or the other answer.
Programming a simulated experiment for the probability question allowed Ellie to face the dilemma of how to define a random chord. She discovered that different computational experiments generate different sets of chords—i.e., different distributions of chord lengths. Realizing there's no unique way of creating random chords gave her authentic insight into the connection between randomness and distribution.
Wilenski (1995) goes on to discuss the difference between the experience of this learner, and another faced with a specialized "black-box" modeling package. With the latter, learners can manipulate parameters in pre-built distributions, but cannot explore the structure underlying the model. Citing evaluations of the stats package's effectiveness, he notes that learners could never answer correctly this test question: "What is it about a variable that makes it a random variable?" After hours manipulating distributions, they could still not connect with the concept of "random." In contrast, learners in Wilenski's study developed strong intuitions by tackling the question of the meaning of randomness by explicitly writing a computer program to investigate it. He concludes:
This trialogue between Ellie's mental model, the expression of her mental model in encapsulated code and the running of that code, allowed Ellie to successively refine the creative structure of her thought.
Challenge:¶
Think about a topic that you have been involved in or are interested in teaching that could be presented to learners through a computational approach. How might you structure an activity that affords learners the opportunity to engage with complex ideas?
"It does not happen by accident"¶
Many people claim that learning to program brings with it the benefit of acquiring general problem-solving and higher-order thinking skills. The evidence from education research, however, does not support this claim. A meta-study by Palumbo (1990) concluded that the accumulated research shows no connection between learning programming and problem-solving in general. This is important to emphasize because of the frequency with which the claim appears in the media and is quoted by prominent personalities.
Evidence is available, however, showing that problem-solving skills can be taught using programming. The doctoral research of Sharon Carver showed that when she used a detailed model of the skills she wanted the students to develop, she could use programming as a medium to teach those skills (Klahr and Carver, 1988). Programming by itself does not achieve it, but structuring a learning activity aimed at teaching the desired skills using programming can.
The next question is, then: How to achieve learning through programming?
The recent book "Learner-Centered Design of Computing Education" (Guzdial, 2015) makes the case that we can design for skills transfer: it does not happen by accident. It gives design guidance on page 48:
Develop a model for what you want students to learn through computing. Use only the programming needed for that learning to happen.
Use scaffolding and programming environments that support students in learning the programming needed for the learning objectives.
Learning both programming and the target subject (mathematics, physics, probability) may be synergistic: it will take less time than learning each one separately (but more time than learning just programming, or just the isolated target subject). Pace will be paramount to success.
"Programming can be a powerful medium for learning mathematics and science. It does not happen by accident." (Guzdial, 2015)
What is computational thinking?¶
On March 2016, I published an essay titled "Computational Thinking: I do not think it means what you think it means". I grumbled that "computational thinking" has sadly taken on buzzword quality, and offered what it means for me:
To me, as a computational scientist, the essence is what we can do while interacting with computers, as extensions of our mind, to create and discover. That’s not the popular message today. (Barba, 2016)
An opinion piece published in the Communications of the ACM (Wing, 2006) has had the most influence on the use of the term today. The article has more than 4,500 citations in Google Scholar now, about 60% of which from the last three years! (In Barba, 2016, I reported 1,841 citations.) Wing advanced computational thinking as "a universally applicable attitude and skill set everyone, not just computer scientists, would be eager to learn and use." The focus is on problem-solving by "thinking like a computer scientist"—using abstraction and decomposition, recursion and type checking, separation of concerns and avoiding race conditions. As critics have noted (Hemmendinger, 2010), many of these features are not unique to computer science (e.g., abstraction in mathematics) and the call for "thinking like a computer scientist" is rather pompous. More importantly, it misses the point about computational thinking in the sense coined by Papert.
Seymour Papert was a mathematician and computer scientist at MIT, a pioneer in artificial intelligence and creator of the Logo programming language. Alan Kay—inventor of object-oriented programming—said of Papert that "his notion about what the computer is there for in education was [as] the greatest new vehicle for learning about powerful ideas." Papert first uses the phrase "computational thinking" in his seminal book "Mindstorms: Children, computers, and powerful ideas" (1980). His interest, he said, was in "how computers may affect the way people think and learn"(Papert, 1980).
In a later paper (1996), Papert develops his ideas further, claiming that the role of computers in mathematics education should be transformative. An example on teching elementary probability: students work with Logo using an object called random and experiment on screen, while naturally making new functions, like random-color. The learning experience is a far cry from schools introducing probability ideas using dice. "What can children do with this new knowledge besides talk or deal with teacher-initiated problems?"
He proposes several deep ideas, like:
The Power Principle: What comes first, 'using' or 'understanding'? The natural mode of learning is to first use, leading slowly to understanding. New ideas are a source of power to do something.
Project Before Problem: Projects are primary. Problems come up in the course of projects and are sometimes 'solved' and sometimes 'dissolved.' (The student using
random-coloreffects on screen: had you asked here what she was doing, she would not have said 'problem-solving.')
Media Defines Content: Old-school activities involve making inscriptions on paper, while in Papert’s alternative involve 'manipulating a computer-based microworld.' New media open the door to new content.
So, he says: Mathematics education can draw on computation to provide a much richer set of new representations of knowledge that the idea of procedural representation that has slipped into the cognitive discourse. The goal is to use computational thinking to forge ideas.
Unfortunately, the contemporary usage of "computational thinking" has lost much of this depth, and continues to focus on problem-solving and thinking like a computer scientist. It takes careful reading of Seymour Papert to grasp his vision about computing as a medium for human expression, of the computational representation making the mathematics or the physics more lucid to us.
A helpful interpretation by Weintrop et al. (2016) defines computational thinking focusing on its application to mathematics and science, based on a taxonomy in four categories:
- Data practices
- Modeling and simulation practices
- Computational problem-solving
- Systems-thinking practices
Focusing on a taxonomy of practices driven by how scientists use computational thinking to advance their disciplines, this definition is concrete enough to build on when designing courses. It is an "actionable, classroom-ready definition." And with Uri Wilensky, one of the co-authors, having worked with Seymour Papert at the MIT Media Lab, it is true to the origins of the idea.
Computing as a new literacy¶
The phrase "computational literacy" is also often used with a shallow meaning of simply knowing your way around computers and being able to use some standard desktop applications. Andrea diSessa (2001), professor of education at UC Berkeley, develops the deep idea. Conventional literacy, that is, knowing how to read and write, is highly valued in our society. It is utterly essential to education: not just a result of education, but its driving force. Computing, claims diSessa, is the basis of a new literacy, empowering the transformation of science education.
The defining feature of a literacy is that it's infrastructural:
Literacy is a socially widespread deployment of skills and capabilities in a context of material support to achieve valued intellectual ends (diSessa, 2001).
For example, the subject of calculus has become infrastructural in engineering education: all learners study it, and further learning depends on it. This situation was not easy and took at least two centuries to achieve. Even if calculus might have originated from the individual genius of Newton and Leibniz (independently), a complex social process of innovation and interdependence led to infrastructural adoption over many years.
Calculus is a representation system that makes it possible to reason about instantaneous properties of motion. Similarly, algebra makes reasoning about uniform motion straightforward. diSessa tells the story of Galileo's pained efforts to explain his laws of motion, over several pages of reasoning: at the time, algebra as a representation system did not exist. Today, a young student can write Galileo's laws in a few simple equations.
Literacy, in this sense, can be explained as a "material intelligence": an inscription system that makes our reasoning easier and more powerful. Computing, as a new representation system, can similarly lead to faster or deeper learning and discovery. But to achieve this promise, we need infrastructural adoption.
Conclusion¶
We can transform the education of science and engineering students by widespread deployment of computing across the curriculum, but it must be designed deliberately for computational thinking. This term is widely misunderstood, and the popular definitions based on computer science terminology (abstraction, decomposition, etc.) miss the point. So do most of the enthusiastic initiatives in computing "for everybody"—they almost always focus on programming by itself, and are led by instructors with a computer science perspective. We need computation as a material literacy (like calculus, or algebra) that gives learners access to a representation system for reasoning about powerful ideas (like randomness), through computational experimentation. Transforming education in this way can happen only when a community decides that computing is powerful and valuable enough that it's worth the enterprise of teaching it to everyone.
Notes¶
References¶
Barba, L. A., 2016. Computational Thinking: I do not think it means what you think it means, posted on Medium, Inc. and lorenabarba.com, http://bit.ly/com-think
DiSessa, A.A., 2001. Changing minds: Computers, learning, and literacy. MIT Press.
Guzdial, M., 2015. Learner-centered design of computing education: Research on computing for everyone. Synthesis Lectures on Human-Centered Informatics,https://doi.org/10.2200/S00684ED1V01Y201511HCI033
Hemmendinger, D., 2010. A plea for modesty. ACM Inroads, 1(2), pp.4-7, https://doi.org/10.1145/1805724.1805725
Kay, A., 2017. Remembering Seymour Papert, The Brainwaves Video Anthology, https://youtu.be/XTbAdTRFp1k
Klahr, D. and Carver, S.M., 1988. Cognitive objectives in a LOGO debugging curriculum: Instruction, learning, and transfer. Cognitive Psychology, 20(3), pp.362-404, https://doi.org/10.1016/0010-0285(88)90004-7
Palumbo, D.B., 1990. Programming language/problem-solving research: A review of relevant issues. Review of Educational Research, 60(1), pp.65-89, https://doi.org/10.3102%2F00346543060001065
Papert, S., 1980. Mindstorms: Children, computers, and powerful ideas. Basic Books, Inc., NY, https://dl.acm.org/citation.cfm?id=1095592
Papert, S., 1996. An exploration in the space of mathematics educations. International Journal of Computers for Mathematical Learning, 1(1), pp.95-123, https://doi.org/10.1007/BF00191473
Papert, S., 2000. What's the big idea? Toward a pedagogy of idea power. IBM systems journal, 39(3.4), pp.720-729.
Weintrop, D., Beheshti, E., Horn, M., Orton, K., Jona, K., Trouille, L. and Wilensky, U., 2016. Defining computational thinking for mathematics and science classrooms. Journal of Science Education and Technology, 25(1), pp.127-147, https://doi.org/10.1007/s10956-015-9581-5
Wilensky, U., 1995. Paradox, programming, and learning probability: A case study in a connected mathematics framework. The Journal of Mathematical Behavior, 14(2), pp.253-280, https://doi.org/10.1016/0732-3123(95)90010-1
Wing, J.M., 2006. Computational thinking. Communications of the ACM, 49(3), pp.33-35, https://doi.org/10.1145/1118178.1118215