Overview¶
Following our section on data collection, we shift focus to analyzing social data. The course will now cover basic tools in Network and Text Analysis, applying these to previously collected data. We start with Network Science.
Networks, or graphs, are crucial for representing and analyzing social systems. This week introduces networks through three main topics:
- Context: An overview of network science history and basic network concepts.
- The NetworkX Library: Introduction to this Python library for network analysis.
- Basic Network Analysis: We will analyze and visualize the network of Computational Social Scientists using NetworkX.
The objective is to ensure you learn about the field of network science and get hands-on experience using the NetworkX library for fundamental analysis.
Part 1: Basic mathematical description of networks¶
This week, let's start with some lecturing. First, we will go through the history of Network Science.
Video Lecture. Start by watching the "History of Networks"
from IPython.display import YouTubeVideo
YouTubeVideo("kt6J36e0JCk",width=800, height=450)
Video Lecture. Then check out a short video on "Network Notation"
YouTubeVideo("_AT9HaTE9nE",width=800, height=450)
Reading. To better familiarize with basic concepts in Network Science, we will read two chapters in the Network Science book by Laszlo Barabasi. You can read the whole book for free here.
Prelude to Part 2: The NetworkX library¶
In this course, we will leverage the NetworkX Python library for network analysis. To effectively work with real-world networks, it is essential that you familiarize with NetworkX beforehand.
Exercise
- Download the NetworkX project's tutorial. Familiarize with the basics like creating graphs, accessing node and edge properties, and visualizing graphs.
- Experiment with the tutorial code. Feel free to tweak it to understand how things work.
Part 2: Basic analysis of the network of Computational Social Scientists¶
Ok, enough with theory. It is time to go back to our dataset. We will build the network of Computational Social Scientists. Then, we will use some Network Science to study some of its properties.
Exercise 1: Constructing the Computational Social Scientists Network
In this exercise, we will create a network of researchers in the field of Computational Social Science using the NetworkX library. In our network, nodes represent authors of academic papers, with a direct link from node A to node B indicating a joint paper written by both. The link's weight reflects the number of papers written by both A and B.
Part 1: Network Construction
Weighted Edgelist Creation: Start with your dataframe of papers. Construct a weighted edgelist where each list element is a tuple containing three elements: the author ids of two collaborating authors and the total number of papers they've co-authored. Ensure each author pair is listed only once.
Graph Construction:
- Use NetworkX to create an undirected
Graph.- Employ the
add_weighted_edges_fromfunction to populate the graph with the weighted edgelist from step 1, creating a weighted, undirected graph.Node Attributes:
- For each node, add attributes for the author's display name, country, citation count, and the year of their first publication in Computational Social Science. This information should be retrieved from your authors dataset. You can use the papers dataset to retreive the total number of citations per author.
- Save the network as a JSON file.
Part 2: Preliminary Network Analysis Now, with the network constructed, perform a basic analysis to explore its features.
Network Metrics:
- What is the total number of nodes (authors) and links (collaborations) in the network?
- Calculate the network's density (the ratio of actual links to the maximum possible number of links). Would you say that the network is sparse? Justify your answer.
- Is the network fully connected (i.e., is there a direct or indirect path between every pair of nodes within the network), or is it disconnected?
- If the network is disconnected, how many connected components does it have? A connected component is defined as a subset of nodes within the network where a path exists between any pair of nodes in that subset.
- How many isolated nodes are there in your network? An isolated node is defined as a node with no connections to any other node in the network.
- Discuss the results above on network density, and connectivity. Are your findings in line with what you expected? Why?
Degree Analysis:
- Compute the average, median, mode, minimum, and maximum degree of the nodes. Perform the same analysis for node strength (weighted degree). What do these metrics tell us about the network?
Top Authors:
- Identify the top 5 authors by degree. What role do these node play in the network?
- Research these authors online. What areas do they specialize in? Do you think that their work aligns with the themes of Computational Social Science? If not, what could be possible reasons?
Take the network of Computational Social Scientists you built in the exercise above.
To get an idea about how the network looks like, we start visualizing it. For this exercise, we will use the awesome library netwulf created by Ulf Aslak and Ben Maier, two colleagues of mine.
You can install it via pip install netwulf.
Netwulf is built on top of d3-force, a Javascript library that simulates the dynamics of particles moving in 2D. In the visualization, particles correspond to network nodes subject to forces:
- Nodes are attracted to the center of the viz
- Nodes repel each other
- Nodes linked by an edge will preferably stay at a fixed distance to each other.
Come and ask me if you want to know more!
Exercise 2: Visualize the network of Computational Social scientists.
- Extract the largest connected components from your network. The largest connected component is the one with the largest number of nodes.
- Visualize the largest connected component using the function
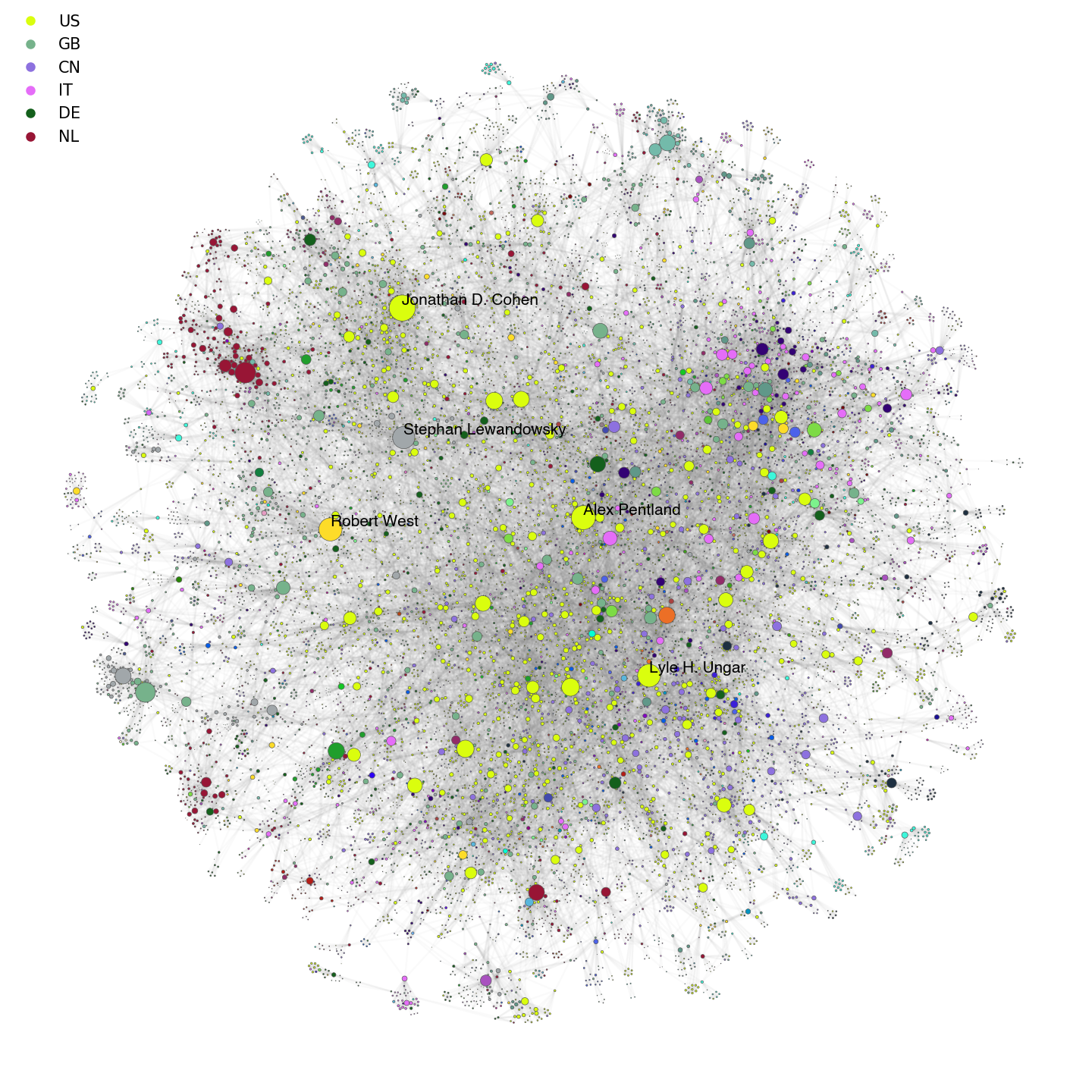
visualizeof the Netwulf package.- Play with the parameters of the netwulf algorithm to obtain a visualization you like. To understand better what the parameters mean, have a look at the documentation. Your visualization may look similar to the one below, where I made the size of nodes proportional to their strength (sum of weights of incoming edges), and I added the names of the top Computational Social Scientists by degree... But not necessarily! Just have fun making your own version. You can save the figure directly from the interactive visualization panel, or plot it in higher resolution in matplotlib following this example.
- Describe the structure you observe. Can you identify nodes with a privileged position in the network?
- Optional: You can color nodes based on a property of your interest (e.g. country, citations). For example, I colored nodes based on their country. What do you observe? Can you find specific nodes properties that seem to correlate with a node's position in the network?
Note: I encourage you to use Netwulf because they enable to make better visualizations, but you can also try to use the draw function built in NetworkX.
Go on DTU Learn and complete the Survey: Week 4 - The Network