This example is a demonstration of Crowdom's data labeling tasks workflow.
For this example, we chose a simple classification task - we ask workers to identify animals on the photos.
The purpose of the data labeling process is to get ground truth labels for the source data. The source data in this example is images, their URLs are in a file tasks.json, the result is returned as a Pandas dataframe, as in this sample:

Workflow¶
This is a scheme of typical steps in Crowdom data labeling workflow.
All steps on the diagram are clickable and will take you to the corresponding section of the notebook.
Arrows indicate possible interaction between stages.
Dashed elements mean that the corresponding action is optional.

Setup environment¶
Install required packages, import commonly used modules.
%pip install crowdom
from datetime import timedelta
from IPython.display import display
import os
import pandas as pd
from typing import Dict
import toloka.client as toloka
from crowdom import base, datasource, client, objects, pricing, params as labeling_params
You can tune logging config to get more logs for processes tracing, debug and issue reports.
Logging customization¶
In this example config logs are sent to:
crowdom.logfile, from DEBUG level- stdout, from INFO level.
%pip install pyyaml
import yaml
import logging.config
with open('logging.yaml') as f:
logging.config.dictConfig(yaml.full_load(f.read()))
Crowdsourcing platfrom authorization¶
Crowdom uses Toloka as crowdsourcing platform – a place where you can publish your tasks for workers.
For now, we expect that you have already created an account in Toloka. To publish tasks, we need you to specify your OAuth token.
In future versions of Crowdom, you won't need your own Toloka account.
OAuth token¶
Toloka OAuth token is a confidential data that needs to be handled in a secure manner.
If you are working in DataSphere, please create secret with name TOLOKA_TOKEN. It will be later referenced from environment variable.
Otherwise, we will ask you to enter the token via stdin and then clear the cell output to minimize the risks.
from IPython.display import clear_output
token = os.getenv('TOLOKA_TOKEN') or input('Enter your token: ')
clear_output()
Authorization¶
toloka_client = client.create_toloka_client(token=token)
If you want to first check your task in test environment, use sandbox version of Toloka.
Test environment¶
toloka_client = client.create_toloka_client(token=token, environment=toloka.TolokaClient.Environment.SANDBOX)
Labeling task definition¶
In this section we will define the task we trying to solve. Read more about task definition in manual.
As we are dealing with a classification task, we need to define options for it.
In general, you can launch data labeling in different languages. Provide a dict with localized versions for different languages, so you can use same code for launches with different data or workers language.
Here, specify languages you plan using during your data labeling. You will be able to expand this list later.
Languages are specified using ISO 639-1 code.
class Animal(base.Class):
DOG = 'dog'
CAT = 'cat'
OTHER = 'other'
@classmethod
def labels(cls) -> Dict['Animal', Dict[str, str]]:
return {
cls.DOG: {'EN': 'dog', 'RU': 'собака'},
cls.CAT: {'EN': 'cat', 'RU': 'кошка'},
cls.OTHER: {'EN': 'other', 'RU': 'другое'}}
Now we need to define a function of this task.
We are working with photos, so Image is the only input for our function, and previously defined Animal class is resulting output of it.
function = base.ClassificationFunction(inputs=(objects.Image,), cls=Animal)
Worker interface preview¶
Now we can view how workers will see the tasks.
Each function argument has corresponding UI widget – textarea for output Text, audio player for input Audio, radio button group for the options (Animal in this example).
Widgets are arranged from top to bottom in the order of function arguments. Widgets for output are usually located in the bottom part.
example_image_url = 'https://tlk.s3.yandex.net/dataset/cats_vs_dogs/cats/f00a3fa52c694e0fa51a165e22cf4628.jpg'
example_image = (objects.Image(url=example_image_url),)
# you can choose any of languages for which you've defined options
client.TaskPreview(example_image, task_function=function, lang='EN').display_link()
You can preview task interface right here, inside a cell iframe output:
Embedded preview¶
client.TaskPreview(example_image, task_function=function, lang='EN').display()
Workers instruction¶
Provide textual instructions for workers.
instruction = {
'EN': 'Identify the animal in the photo',
'RU': 'Определите, какое животное на фотографии'}
For advanced task, the instruction have to be structured by specifying various cases, giving examples, etc.
We recommend you to format the instruction using the widely used Markdown format, as done below:
Formatting instruction¶
Toloka uses subset of HTML as instruction format, we recommend you to use Markdown as a more convenient way to format your text, and later convert it to HTML.
Worker will see options as they described in Animal.get_label(), so make sure you use the same option depiction in your instruction.
%pip install markdown2
import markdown2
instruction = {}
for worker_lang in ['EN', 'RU']:
with open(f'instruction_{worker_lang}.md') as f:
instruction[worker_lang] = markdown2.markdown(f.read())
You can preview generated HTML in cell output.
Instruction preview¶
Please note that Toloka will sanitize resulting HTML using its subset, so a full check of the instruction is possible only at task verification step.
from IPython.display import display, HTML
display(HTML(instruction['EN']))
Labeling task specification¶
Task specification contains all information for your tasks publication. Specify the following items:
- id, technical identifier of your task
- function of your task
- name, which workers will see in tasks feed
- for technical reasons, we ask you to always specify a name for English (EN)
- description – brief description of your task
- instruction for task
task_spec = base.TaskSpec(
id='dogs&cats',
function=function,
name={'EN': 'Cat or dog', 'RU': 'Кошка или собака'},
description={'EN': 'Identification of animals in photos', 'RU': 'Определение животных на изображениях'},
instruction=instruction)
Workers in their task feed will see your task for EN language like this, depending on where they are doing the tasks:
Browser |
Mobile app |
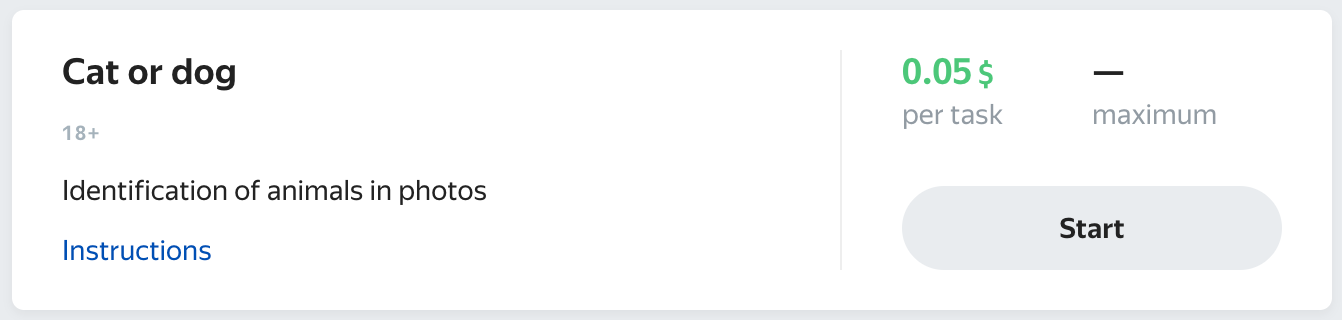
|

|
Define language of your data. Workers who know this language will be selected to perform data labeling.
In fact, task can be language-agnostic – not requiring knowledge of any language. But currently Crowdom always selects workers by language, so we ask you to specify it as workers filter.
Proper support for language-agnostic tasks will appear in future versions of Crowdom.
lang = 'EN'
task_spec_en, localized version of your task_spec, will be used further in code.
task_spec_en = client.PreparedTaskSpec(task_spec, lang)
Task cost¶
Determining an appropriate price for a task is a difficult problem. The price depends on many factors, including place of residence of workers, your choice in favor of the quality or speed of data labeling and etc.
But the main factor is the time that the worker spends on the task.
Task duration hint is an estimate of how much time typical worker will perform one task.
For variable sized data (i.e. texts or audio records), this assumption should be made using average data size for your tasks batch.
We will ask you to specify this value by yourself or with help of experts in later steps.
Note that it will be just an initial estimate. Later, after launching data labeling on crowd, you will be able to refine this value, using worker's task performing metrics.
Importing source data¶
In this section we will import the data you want to label from file.
Images are source data for our example. Images, as well as video and audio recordings, are considered as media objects. Usually such objects are stored in files. In case of Crowdom, media objects are specified by their URL in S3 storage. Such URLs have to be reachable for workers in crowdsourcing platform, so, in terms of S3 storage, S3 objects corresponding to URLs should have public access or be stored in public bucket.
File with source data is expected to be a JSON list, with each item having keys named like name and typed like corresponding type entry for each row in this cell's output dataframe.
In our example, each item have single key image corresponding to image URL. You can see an example of the file in tasks.json that we use as a data source.
datasource.file_format(task_spec_en.task_mapping)
input_objects = datasource.read_tasks('tasks.json', task_spec_en.task_mapping)
control_objects = None
In real-life situations, data labeling is often connected with other processes, such as machine learning, developing quality evalution metrics and etc.
In future versions of Crowdom, a more convenient way of importing source data will appear, combining data labeling with connected processes.
Workers in crowdsourcing platforms may make mistakes or perform tasks poorly, so to provide quality of data labeling various quality control methods are needed. One of important method is control tasks.
If you already have reference labeling, you can import it as control tasks in section below. If not, you should run task verification to generate some control tasks with the help of experts.
Reference labeling¶
In addition to the source data, a reference labeling is expected in the file. For our task, reference labeling is correct classification option, located in choice field.
datasource.file_format(task_spec_en.task_mapping, has_solutions=True)
control_objects = datasource.read_tasks('control_tasks.json', task_spec_en.task_mapping, has_solutions=True)
If you are not sure about your reference labeling quality, run task verification to check it.
Define task duration hint. If you find it difficult to specify this value, or you want more precise initial estimate, run a task verification to define it.
task_duration_hint = timedelta(seconds=10)
Task verification and feedback¶
Before launching data labeling on crowd, it is advisable to make sure that the workers will not have problems with completing tasks.
Task verification is a process in which crowd experts check your task for readiness to launch on crowd.
Crowd experts check various aspects of your tasks, such as the completeness and consistency of the worker instructions, the correspondence of the instructions to the source data, the complexity of the task and the need for its decomposition, etc.
Verification is carried out by labeling a small part of your source data by experts. After the labeling, the experts give feedback, according to which you may need to refine the definition of your task.
For now, we expect that you will form a group of experts yourself by registering. You can also register yourself as an expert.
_Crowd experts automatic management will appear in future versions of Crowdom_.
Unlike workers, the instruction for experts has a special form - first a block with instructions for workers, then a block about expert annotation.

Experts reward definition¶
Define task duration hint, it is needed for an fare reward for an experts, in case if you use help of external Toloka experts.
You don't need a very accurate estimate, you will get an updated value after verification. In case of doubt, enter an upper-bound estimate.
task_duration_hint = timedelta(seconds=20)
from crowdom import experts, project
if control_objects:
scenario = project.Scenario.EXPERT_LABELING_OF_SOLVED_TASKS
objects = control_objects
else:
scenario = project.Scenario.EXPERT_LABELING_OF_TASKS
objects = input_objects
experts_task_spec = client.PreparedTaskSpec(task_spec, lang, scenario)
You have two reward options:
- Inhouse experts – experts are employees of your company and already receive payment for their work. In this case, you pay the minimum rate for task, which is the Toloka fee as a platform.
- External Toloka experts – you have selected experts among the workers in Toloka and payment is carried out in the usual way for Toloka.
Inhouse experts¶
You will see the final price, taking into account the minimum rate, before the verification launch.
avg_price_per_hour = None
External Toloka experts¶
For experts from Toloka, specify reward via earnings per hour.
avg_price_per_hour = 3.5 # USD
Pricing config¶
Use the price defined above to generate the config.
pricing_options = pricing.get_expert_pricing_options(
task_duration_hint, experts_task_spec.task_mapping, avg_price_per_hour)
pricing_config = pricing.choose_default_expert_option(pricing_options, avg_price_per_hour)
Getting feedback¶
client.define_task(experts_task_spec, toloka_client)
For purposes of task verification, i.e. understanding that the task needs to be clarified, experts do not need to label all your tasks, especially if there are many of them. Select just a few dozen random tasks.
raw_feedback = client.launch_experts(
experts_task_spec,
client.ExpertParams(
task_duration_hint=task_duration_hint,
pricing_config=pricing_config,
),
objects[:20],
experts.ExpertCase.TASK_VERIFICATION,
toloka_client,
interactive=True)
You can use dict with ID-name mapping from registration notebook to see your expert names instead of obscure Toloka worker ids.
worker_id_to_name = {'f87548bd9c317ed987e22c8ebe3dea3c': 'bob'} # {'< hex 32-digit id >': '< username >'}
feedback = client.ExpertLabelingResults(raw_feedback, experts_task_spec, worker_id_to_name)
Study feedback from experts.
If you didn't specify reference labeling, then the experts performer data labeling themselves. Their labeling is in the choice column.
_ok column denotes if task (or task with solution, if you specified reference labeling) is correct according to instructions (True if correct).
_comment for incorrect tasks describes what the problem with the task is. For correct tasks, it contains a comment that workers will be able to read if training will be created.
feedback_df = feedback.get_results()
with pd.option_context('max_colwidth', 100):
display(feedback_df)
You can manage these feedback like a regular Pandas dataframe.
I.e., get a subset of images filtered by some condition, e.g. tasks your experts considered incorrect, classified as CAT, and spent at least 10 seconds on. You can also preview links to see workers task UI.
condition = (feedback_df[feedback.OK_FIELD] == False) & \
(feedback_df['choice'] == 'cat') & \
(feedback_df[feedback.DURATION_FIELD] >= timedelta(seconds=10))
with pd.option_context('max_colwidth', 100):
display(feedback.html_with_task_previews(feedback_df[condition]))
Аfter studying the feedback – per-task feedback in dataframe or general points in a chat with experts, you can decide that the task needs to be refined – i.e. you need clarifications in the instructions, or some data is needed to be filtered out, since it will not be possible to label it on crowd for some reasons.
If task refinement is necessary¶
Return to task definition step.
If task is ready for crowd¶
Now we can refine crowd task cost by task duration hint clarification.
If you didn't specify reference labeling, we can calculate estimation automatically, using experts task performing durations, since experts carried out labeling themselves. Keep in mind that the experts were also spending time on expert annotation (_ok, _comment).
If you specify reference labeling, we don't have good enough estimation, because they performed only expert annotation without getting a labeling. To get an estimation, consult with them in your chat.
You can also consult with experts in case of absence of reference labeling, if you think that expert annotation made a significant change in performing duration, what usually happens in the case of simple task.
task_duration_hint = feedback_df['duration'].mean().to_pytimedelta() # with reference labeling
# task_duration_hint = timedelta(seconds=experts_proposed_value) # without reference labeling
task_duration_hint
Refine this estimation with experts if it seems unsuitable.
As you could see in the experts feedback dataframe, the experts could have marked some tasks as correct. Such tasks can be used as control tasks, which are required for quality of data labeling.
control_objects, _ = feedback.get_correct_objects()
Experts could accompany some correct tasks with hints (_comment column) that workers will be able to study for a better understanding of the instructions on real-life examples.
Create training in section below, if you want workers to be trained on these examples before accessing your tasks. It will improve quality of data labeling.
Creating workers training¶
training_objects, comments = feedback.get_correct_objects(application=client.ExpertLabelingApplication.TRAINING)
Specify the approximate time that workers will spend on training. Note that training is not paid, so workers may not want to go through too long training.
training_config = pricing.choose_default_training_option(
pricing.get_training_options(task_duration_hint, len(training_objects), training_time=timedelta(minutes=2)))
client.define_task(task_spec_en, toloka_client)
client.create_training(
task_spec_en,
training_objects,
comments,
toloka_client,
training_config)
Labeling efficiency optimization¶
Effeciency depends on cost, quality and speed of data labeling process.
Labeling may be done with different end goals in mind, and those goals may mean different balance between cost, quality and speed. We will determine this tradeoff by choosing labeling params.

You can skip any customization in this section and use default options, which we consider suitable for a wide range of typical tasks, or tune parameters to you liking.
In Yandex.Toloka a minimum unit of work for workers is called assignment, and it consists of several individual tasks.
Your individual tasks that are to be labeled are called real tasks. If control tasks are an applicable option of quality control in your case, real and control tasks would be present in each assignment, shuffled and visually indistinguishable from each other.
Workers are paid by each accepted assignment, so, if assignment gets rejected, worker will not get any partial fee for it.
params_form = labeling_params.get_interface(task_spec_en, task_duration_hint, toloka_client)
After you tune parameters, extract them automatically from the form:
params = params_form.get_params()
If you want to define your own parameters from scratch, create them with code.
Efficiency customization¶
Define pricing config, using pricing plots above as a hint.
You can look at properties of your variant of pricing config as in this code sample.
Please remember, that task price is calculated based on average workers income for selected language. If you make your config with significant less income, your task can become unattractive to workers. On the other hand, assigning a high income does not mean that there are only high-quality workers.
from crowdom import classification, classification_loop, control, worker
correct_control_task_ratio_for_acceptance = .6
pricing_config = pricing.PoolPricingConfig(assignment_price=.02, real_tasks_count=30, control_tasks_count=4)
pricing_config_with_properties = pricing.calculate_properties_for_pricing_config(
config=pricing_config,
task_duration_hint=task_duration_hint,
correct_control_task_ratio_for_acceptance=correct_control_task_ratio_for_acceptance,
task_mapping=task_spec_en.task_mapping)
print(f'your pricing config properties:\n'
f'\tprice per hour: {pricing_config_with_properties.price_per_hour:.2f}$\n'
f'\trobustness: {pricing_config_with_properties.robustness:.3f}')
Define quality and control params.
control_params = control.Control(
rules=control.RuleBuilder().add_static_reward(
threshold=correct_control_task_ratio_for_acceptance).add_speed_control(
# if worker complete tasks in 10% of expected time, we will reject assignment assuming fraud/scripts/random clicking
# specify 0 to disable this control option
ratio_rand=.1,
# if worker complete tasks in 30% of expected time, we will block him for a while, suspecting poor performance
# specify 0 to disable this control option
ratio_poor=.3,
).build())
params = client.Params(
task_duration_hint=task_duration_hint,
pricing_config=pricing_config,
overlap=classification_loop.DynamicOverlap(min_overlap=2, max_overlap=3, confidence=.85),
control=control_params,
aggregation_algorithm=classification.AggregationAlgorithm.MAX_LIKELIHOOD,
worker_filter=worker.WorkerFilter(
filters=[
worker.WorkerFilter.Params(
langs={worker.LanguageRequirement(lang=lang)},
regions=worker.lang_to_default_regions.get(lang, {}),
age_range=(18, None),
),
],
training_score=80,
),
)
Labeling of your data¶
Now we finally publish tasks to workers, wait for data labeling completion and study results.
We will ask you to confirm the launch of the data labeling by showing you the interval of the total price.
You will see metrics on plots during data labeling process.
client.define_task(task_spec_en, toloka_client)
You can stop the data labeling process by interrupting the cell.
The tasks that have not yet been completed will not be available to the workers, and the completed ones will be paid for.
artifacts = client.launch(
task_spec_en,
params,
input_objects,
control_objects,
toloka_client,
interactive=True)

You can refine task duration hint, using real workers stats on Task duration distributon plot.
results = artifacts.results
Results study¶
You can study results in three ways:
- Display ground truth (most probable option)
- Display probabilites for all options
- Display raw workers labeling
with pd.option_context('max_colwidth', 100):
display(results.predict())
with pd.option_context('max_colwidth', 100):
display(results.predict_proba())
with pd.option_context('max_colwidth', 100):
display(results.worker_labels())
You can manage these results like a regular Pandas dataframe.
I.e., get a subset of images classified as CAT, that required 3 answers to converge and still have low confidence. You can also preview links to see workers task UI.
df = results.predict()
condition = (df[results.RESULT_FIELD] == 'cat') & (df[results.OVERLAP_FIELD] == 3) & (df[results.CONFIDENCE_FIELD] < 0.7)
with pd.option_context('max_colwidth', 100):
display(results.html_with_task_previews(df[condition]))
If you want to evaluate the final quality of the data labeling that Crowdom provides you with, run quality verification with help of your domain experts.
Labeling quality verification¶
You can run verification on random sample of labeled objects:
import random
sample_size = min(20, int(0.1 * len(input_objects)))
control_objects = random.sample(client.select_control_tasks(input_objects, results.raw, min_confidence=.0), sample_size)
Quality verification closely resembles task verification with reference labeling. Revisit this section, substituting experts.ExpertCase.TASK_VERIFICATION by experts.ExpertCase.LABELING_QUALITY_VERIFICATION, and collect the results and evaluate accuracy of them:
test_results.get_accuracy()
What's next?¶
You can perform further data labeling launches.
Unless you want to update your Task definition or Efficiency parameters, you don't need to re-run corresponding cells.
Just prepare new file in Importing source data section and run Labeling.
Updating control tasks¶
In regular labeling processes control tasks should in turn be regularly updated.
А convenient way to select control tasks from workers' data labeling, as well as support for generating control tasks through data augmentation, will appear in future versions of Crowdom.
For now, you can select new control tasks from data labeling with highest confidence and target overlap:
control_tasks = client.select_control_tasks(input_objects, results.raw, min_confidence=.95)
These selected tasks reflect the opinion of the crowd, it is advisable to verify these tasks with help of experts. Control tasks verification closely resembles quality verification – run verification and select tasks marked as OK from feedback dataframe.