Chapter 3: Khai thác SHAP để đo lường tác động của thuộc tính¶
3.1 Vấn đề¶
- Biết cách nhúng SHAP vào một mô hình ML để ước tính giá trị SHAP cho từng quan sát, với từng thuộc tính;
- Biết cách đọc ma trận kết quả của SHAP;
- Cải thiện mô hình nhờ SHAP;
- Nắm được ưu/nhược điểm của SHAP.
3.2 Giải thuật SHAP¶
- Phát triển cùng khái niệm eXplainable AI (XAI): cân bằng được tính phức tạo (với hiệu suất cao) với khả năng giải thích;
- Shapley Additive exPlanations: một cách tuyệt vời để reverse engineering từ kết quả của một thuật toán.
Lý thuyết trò chơi và kỹ thuật học máy¶
SHAP được dựa trên giá trị Shapley - một khái niệm từ lý thuyết trò chơi. Trong bối cảnh ban đầu, Shapley nghiên cứu làm thế nào để phân chia công bằng một giải thưởng giữa các thành viên của một liên minh dựa trên đóng góp của từng thành viên. Áp dụng vào học máy, chúng ta coi mỗi đặc trưng như một "thành viên" và kết quả dự đoán như "giải thưởng". SHAP sẽ tính toán mức độ đóng góp của từng đặc trưng vào kết quả cuối cùng.
SHAP đánh giá ảnh hưởng của một đặc trưng bằng cách so sánh các dự đoán của mô hình khi có mặt và không có mặt đặc trưng đó. Nó không chỉ xem xét ảnh hưởng riêng lẻ mà còn xem xét sự tương tác giữa các đặc trưng.
Mỗi đặc trưng sẽ được gán một "giá trị SHAP" - một con số thể hiện mức độ và chiều hướng ảnh hưởng của nó tới dự đoán:
- Giá trị dương: Đặc trưng đẩy dự đoán lên cao hơn
- Giá trị âm: Đặc trưng kéo dự đoán xuống thấp hơn
- Giá trị gần 0: Đặc trưng ít ảnh hưởng
Force Plots - Single Instance¶
Hình minh họa dưới đây (nguồn Aidan Cooper)
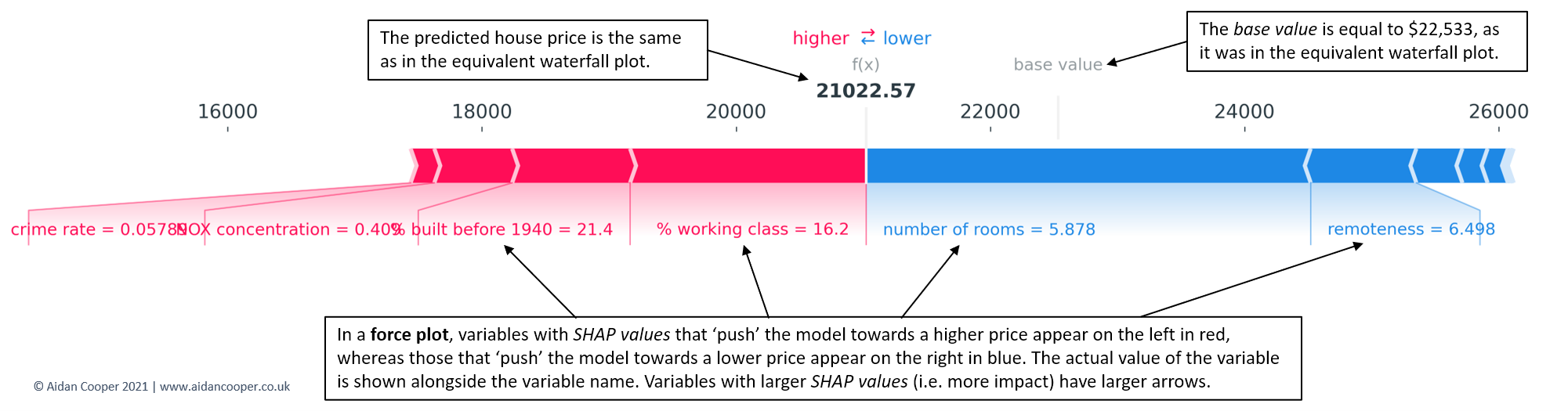
Hãy:
- Chú ý đến độ dài và màu sắc của các mũi tên
- Xem xét cả chiều dương và âm
- So sánh tác động tương đối của các đặc trưng
SHAP Feature Importance¶
Minh họa tầm quan trọng của mỗi đặc tính lên kết quả, hình minh họa bên dưới (nguồn Aidan Cooper)
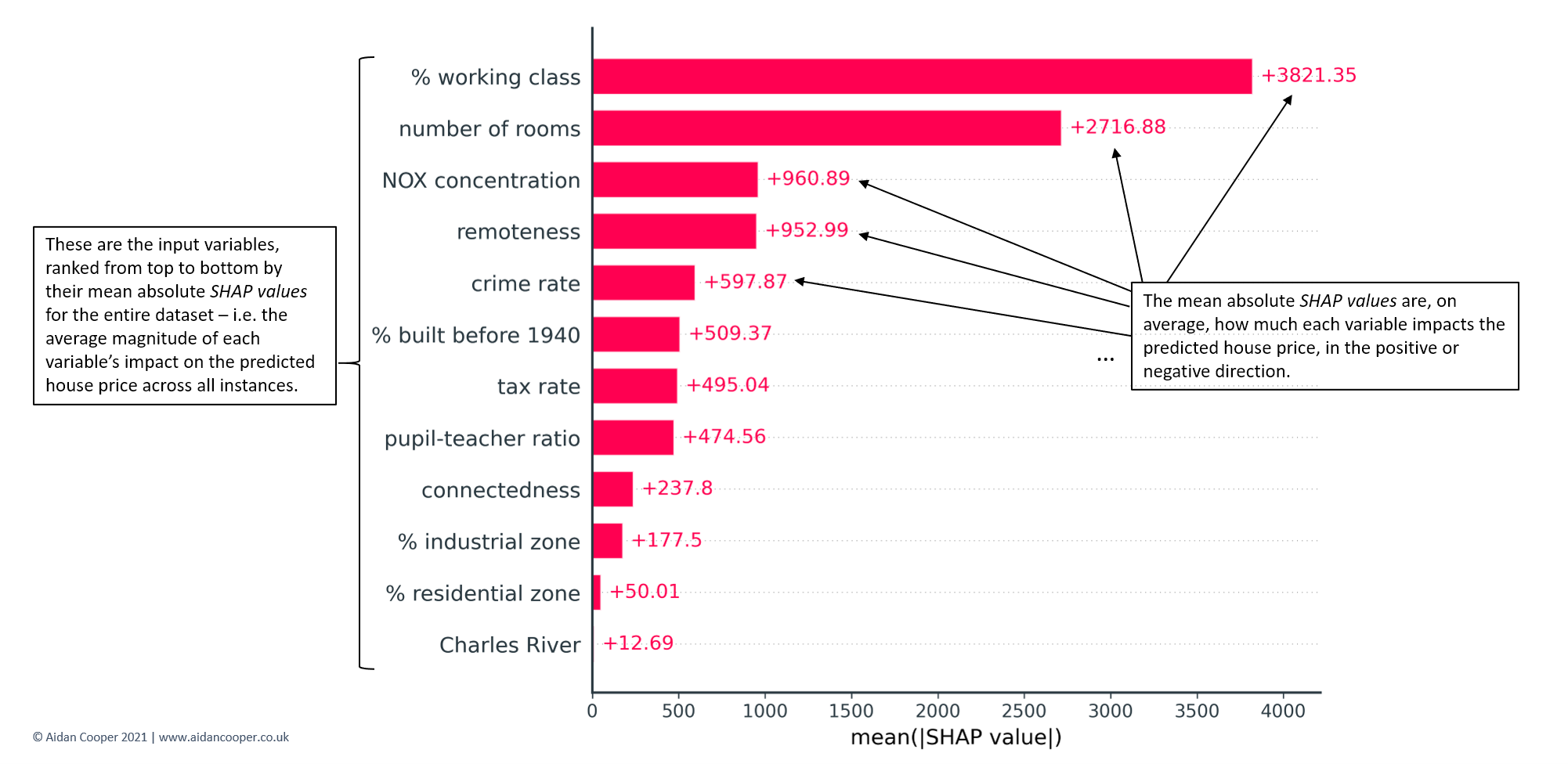
3.3 Quy trình thực hiện¶
Import libraries
import os
import pandas as pd
import warnings
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
warnings.simplefilter("ignore")
Data pre-processing
# Đọc dữ liệu
project_dir = os.path.abspath(os.path.join(os.getcwd(), ".."))
data_path = os.path.join(project_dir, "data", "raw", "credit_risk_data.csv")
dataset = pd.read_csv(data_path)
# create new df that replicate original data
df1 = pd.DataFrame({"mucdich": dataset["mucdich"]})
df2 = pd.DataFrame({"diaphuong": dataset["diaphuong"]})
# encoding
le = LabelEncoder()
df1["mucdichec"] = le.fit_transform(dataset["mucdich"])
df2["diaphuongec"] = le.fit_transform(dataset["diaphuong"])
# ghi lại vào tập dữ liệu gốc
dataset["mucdich"] = df1.loc[:, "mucdichec"]
dataset["diaphuong"] = df2.loc[:, "diaphuongec"]
# chia nhóm thuộc tính
numerical_features = ["tienvay", "laisuat", "khoantragop", "thunhap", "fico", "sotk"]
categorical_features = [
"trangthai",
"xephang",
"kinhnghiem",
"tsdb",
"xacminh",
"mucdich",
"diaphuong",
]
# xác định target và feature
target = ["trangthai"]
features = list(set(list(dataset.columns)) - set(target) - set(["makhachhang"]))
# phân chia train test
X = dataset[features].values
y = dataset[target].values
# tỷ lệ 9 - 1
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=42
)
Running Decision Tree
DT_classifier = DecisionTreeClassifier(max_depth=6, min_samples_leaf=47)
DT_classifier.fit(X_train, y_train)
DecisionTreeClassifier(max_depth=6, min_samples_leaf=47)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
DecisionTreeClassifier(max_depth=6, min_samples_leaf=47)
Nhúng SHAP vào Decision Tree¶
import shap
explainer = shap.Explainer(DT_classifier)
# Tính giá trị SHAP cho mỗi thuộc tính của tập dữ liệu X_Train
shap_values = explainer(X_train)
shap_values = explainer.shap_values(X_train)
shap_values.shape # no need to shap_values.values.shape
(54072, 12, 2)
Data Framing the result of the 47624th customer
pd.DataFrame({
'Thuộc tính': features,
'0': shap_values[47624,:,0],
'1': shap_values[47624,:,1]
})
| Thuộc tính | 0 | 1 | |
|---|---|---|---|
| 0 | fico | -0.001029 | 0.001029 |
| 1 | kinhnghiem | 0.000623 | -0.000623 |
| 2 | xacminh | -0.000422 | 0.000422 |
| 3 | mucdich | 0.000000 | 0.000000 |
| 4 | khoantragop | 0.040420 | -0.040420 |
| 5 | xephang | 0.000000 | 0.000000 |
| 6 | tienvay | 0.005429 | -0.005429 |
| 7 | sotk | 0.009612 | -0.009612 |
| 8 | diaphuong | 0.000000 | 0.000000 |
| 9 | thunhap | -0.020613 | 0.020613 |
| 10 | tsdb | 0.000000 | 0.000000 |
| 11 | laisuat | -0.028019 | 0.028019 |
Biểu diễn giá trị SHAP của một khách hàng thuộc lớp 0¶