Méthodologie de prise en compte des relations entre champs dans les représentations tabulaires¶
Ce document propose une évolution de la méthodologie de validation des fichiers tabulaires (cf exemple du guide Etalab de préparation des données à l'ouverture et la circulation). Seuls sont abordés ci-dessous les compléments qui pourraient être apportés à la démarche existante.
Ce Notebook est disponible en consultation sur nbviewer
0 - Introduction¶
0.1 - Objectif¶
Les outils de définition des schémas de données (ex. TableSchema) définissent d'une part des informations descriptives et explicatives d'une structure de données et d'autre part des régles à respecter pour documenter cette structure.
Les règles définies concernent principalement les champs pris séparément mais n'intègrent pas les relations entre les champs qui composent cette structure.
Exemple de règles non actuellement traitées :
- une "personne" est associée à un seul "numéro de sécurité sociale" (et réciproquement)
- un "élève" appartient à une seule "classe"
Les relations entre champs sont importantes dans la cohérence d'un jeu de données. Elles sont d'ailleurs bien souvent exprimées dans les modèles de données qui les décrivent.
Pourtant elles ne sont pas repris dans les schémas de données ni contrôlées dans la phase de création des jeux de données.
L'évolution proposée consiste donc à prendre en compte ces relations entre champs au niveau de la phase de préparation ainsi qu'au niveau de la phase d'exploitation:
0.2 - Exemple¶
Afin de faciliter la compréhension du sujet, un exemple sera traité tout au long de cette présentation. Il concerne les infrastructures de charge des véhicules électriques (IRVE) qui fait l'objet d'un schéma de données détaillé et d'un jeu de données important lien data.gouv.fr
Une analyse du jeu de données IRVE complet est accessible sur ce lien.
L'exemple présenté est également détaillé sur ce lien.
1 - Préparation : Etablissement du schéma de données¶
1.1 Description du modèle de données conceptuel¶
Le modèle de données conceptuel permet de décrire la structuration des informations qui composent les jeux de données.
La modélisation la plus utilisée et la plus adaptée à des jeux de données tabulaires est la modélisation "entité-association". Celle-ci permet de décrire :
- les entités,
- les associations et dépendances entre entités,
- les identifiants et attributs qui explicitent les entités.
La modélisation initiale ne prend pas en compte les contraintes d'implémentation, elle est un outil de dialogue entre les différents intervenants.
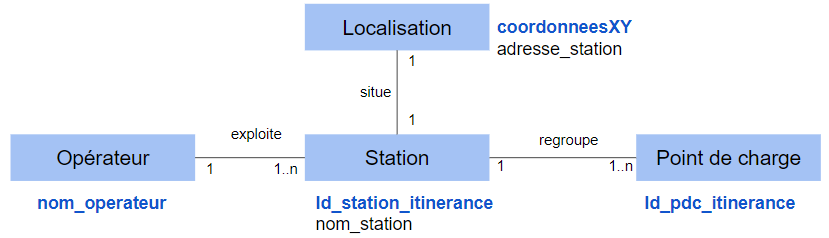
Exemple IRVE:
Dans l'exemple simplifié, on considère deux entités principales :
- les stations : elles sont identifiées de façon unique par un "Id" et cractérisées par un nom,
- les points de charge : Ce sont les équipements associés à une station qui assurent la connection aux véhicules à charger. Ils sont identifiés également par un "Id".
Deux autres entités sont également présentes :
- une localisation : identifiée par une coordonnées géographique et décrite par une adresse
- un opérateur : l'exploitant de l'infrastructure. Il est identifié par un nom
1.2 Description du modèle de données logique¶
Le modèle de données logique décline le modèle conceptuel en fonction du système d'information envisagé (ex. base de données relationnelle, modélisation objet, ...).
Dans le cas d'une implémentation tabulaire, le modèle logique fait apparaître chacun des futurs champs sous la forme d'une entité avec les règles suivantes :
- les entités du modèle conceptuel sont remplacées par les entités correspondantes aux identifiants
- les attributs du modèle conceptuel sont transformés en nouvelles entités
- les entités attributs sont associées aux entités identifiants par des relations 1-n
Le modèle logique se déduit donc directement du modèle conceptuel.
Remarque :
1 - La relation 1-n entre attributs et identifiants exprime le fait qu'un attribut décrit un objet donné. Elle peut être renforcée en une relation 1-1 si l'attribut considéré doit être unique pour un identifiant donné.
2 - Dans une implémentation en base de données relationnelle, la notion d'attributs peut rester attachée à la notion d'entité lorsqu'une "table" intègre à la fois les identifiants et les attributs.
Exemple IRVE:
Le modèle logique déduit du modèle conceptuel précédent est le suivant :
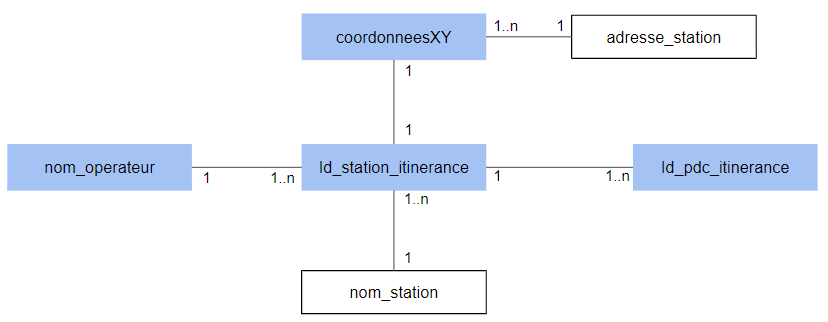
Si le nom de la station doit être unique, on peut renforcer la relation 1-n entre id_station_itinerance et nom_station par une relation 1-1.
1.3 Modèle physique¶
Le modèle physique consiste d'une part à décrire les champs dans le schéma de données et d'autre part à préciser le découpage en fichiers.
1.3.1 Structure des champs¶
Les champs sont définis dans le schéma de données (non détaillé ici). Il convient donc d'ajouter à ce schéma les relations exprimées au niveau du modèle logique.
Pour cela, une propriété relationship avec deux valeurs possibles est ajoutée dans le schéma de données pour les champs concernés :
derivedqui exprime une relation 1 - ncoupledqui exprime une relation 1 - 1
Remarque :
1 - La propriété
coupledest symétrique, elle peut donc être portée indifféremment par un des deux champs (contrairement à la propriétéderived).
2 - Une cardinalité 0-n (ou 0-1) dans une représentation tabulaire est équivalente à indiquer que le champ est optionnel (valeur indéfinie - null, Nan, None ou autre - autorisée dans le champs correspondant).
3 - Cette nouvelle propriété fait l'objet d'une demande d'évolution de TableSchema (issue 803 en cours d'instruction)
Exemple IRVE:
Les propriétés se substituent aux cardinalités :
Avec la syntaxe TableSchema la structure des champs est la suivante (en complément des [propriétés existantes](https://schema.data.gouv.fr/schemas/etalab/schema-irve/2.1.0/schema.json)) :
"fields": [ { "name": "nom_operateur", "relationship" : { "parent" : "id_station_itinerance", "link" : "derived" } }, { "name": "id_station_itinerance", "relationship" : { "parent" : "id_pdc_itinerance", "link" : "derived" } }, { "name": "nom_station", "relationship" : { "parent" : "id_station_itinerance", "link" : "derived" } }, { "name": "adresse_station", "relationship" : { "parent" : "coordonneesXY", "link" : "derived" } }, { "name": "coordonnéesXY", "relationship" : { "parent" : "id_station_itinerance", "link" : "coupled" } } ]
1.3.2 Découpage en fichiers¶
Plusieurs stratégies sont possibles :
- minimiser le nombre de fichiers : Ceci permet de faciliter l'accès aux données (ex. exploitation directe dans un tableur)
- créer un fichier par entité principale : Ceci permet de faire respecter "physiquement" la structure définie
Dans le cas multifichiers, la séparation s'effectue nécessairement au niveau des entités identifiants.
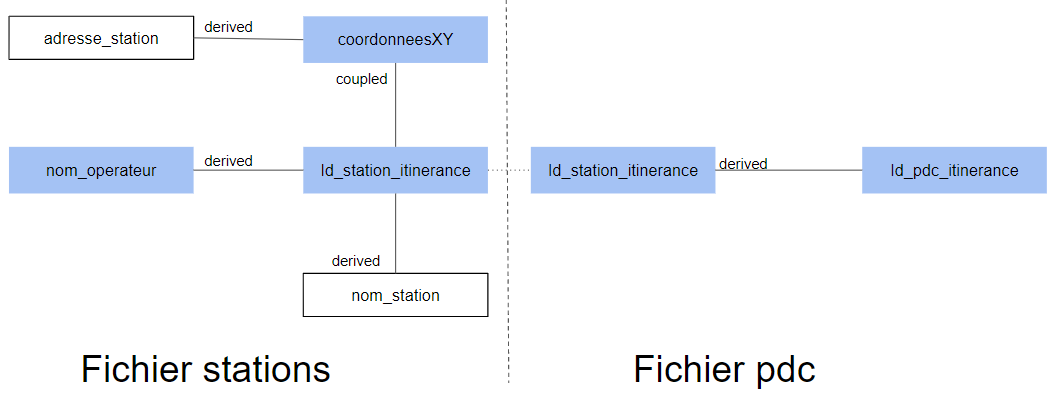
Exemple IRVE:
Un exemple d'implémentation à deux fichiers est présenté ci-dessous :
Un exemple de fichier unique documenté avec 4 points de charge est donné ci-dessous :
| nom_operateur | id_station_itinerance | nom_station | adresse_station | coordonneesXY | id_pdc_itinerance |
|---|---|---|---|---|---|
| SEVDEC | FRSEVP1SCH01 | SCH01 | 151 Rue d'Uelzen 76230 Bois-Guillaume | [1.106329, 49.474202] | FRSEVE1SCH0101 |
| SEVDEC | FRSEVP1SCH03 | SCH03 | 151 Rue d'Uelzen 76230 Bois-Guillaume | [1.106329, 49.474202] | FRSEVE1SCH0301 |
| SEVDEC | FRSEVP1SCH02 | SCH02 | 151 Rue d'Uelzen 76230 Bois-Guillaume | [1.106329, 49.474202] | FRSEVE1SCH0201 |
| Sodetrel | FRS35PSD35711 | RENNES - PLACE HONORE COMMEREUC | 13 Place Honoré Commeurec 35000 Rennes | [-1.679739, 48.108482] | FRS35ESD357111 |
2 - Exploitation : Documentation et assemblage des jeux de données¶
La documentation des jeux de données consiste à documenter un ensemble de lignes conformément à la structure des fichiers définie.
La principale attente de cette phase est de pouvoir détecter et corriger au plus tôt et simplement les éventuels écarts par rapport aux règles définies.
Quatre niveaux d'analyse sont à prendre en compte :
- validation unitaire d'une donnée pour un champ
- validation d'un enregistrement (multi-champs)
- validation interne du jeu de données (multi enregistrements)
- validation externe du jeu de données (multi jeux de données)
Les deux premiers niveaux sont traités dans les outils existants (non détaillé ici).
Le troisième niveau consiste à valider les règles définies par la propriété relationship sur le jeu de données avant une demande d'intégration dans le fichier global.
Le quatrième niveau est identique fonctionnellement au troisième mais ne peut s'effectuer que sur l'agrégation de l'ensemble des jeux de données.
La restitution des erreurs peut s'effectuer simplement par l'ajout de champs de contrôle booléens associés à chaque propriété testée.
Remarque :
1 - Pour être exploitable simplement, l'outil de contrôle doit permettre de localiser et restituer précisément les erreurs identifiées.
2 - L'outil indiqué dans ce lien est un exemple simple de contrôle mais celui-ci ne permet pas la localisation des erreurs
3 - L'agrégation de plusieurs jeux de données validés ne se traduit pas nécessairement par un fichier valide. La validation externe d'un jeu de données peut donc conduire à identifier des erreurs qui portent potentiellement sur des jeux de données qui avaient déjà été validés
4 - Pour intégrer le 4e niveau dès la saisie, le contrôle global doit pouvoir être activé à la demande (ex. via un service mis à disposition par le détenteur du fichier d'agrégation des jeux de données). ceci peut être couteux en ressources et en temps de réponse.
Exemple IRVE:
L'activation et la validation de ces règles sur un jeu de données sont présentées sur ce lien. Il présente notamment la mise en oeuvre d'un outil permettant à la fois la détection et la localisation des erreurs.