Consuming Messages from Kafka Tour Producer Using Scala Spark¶
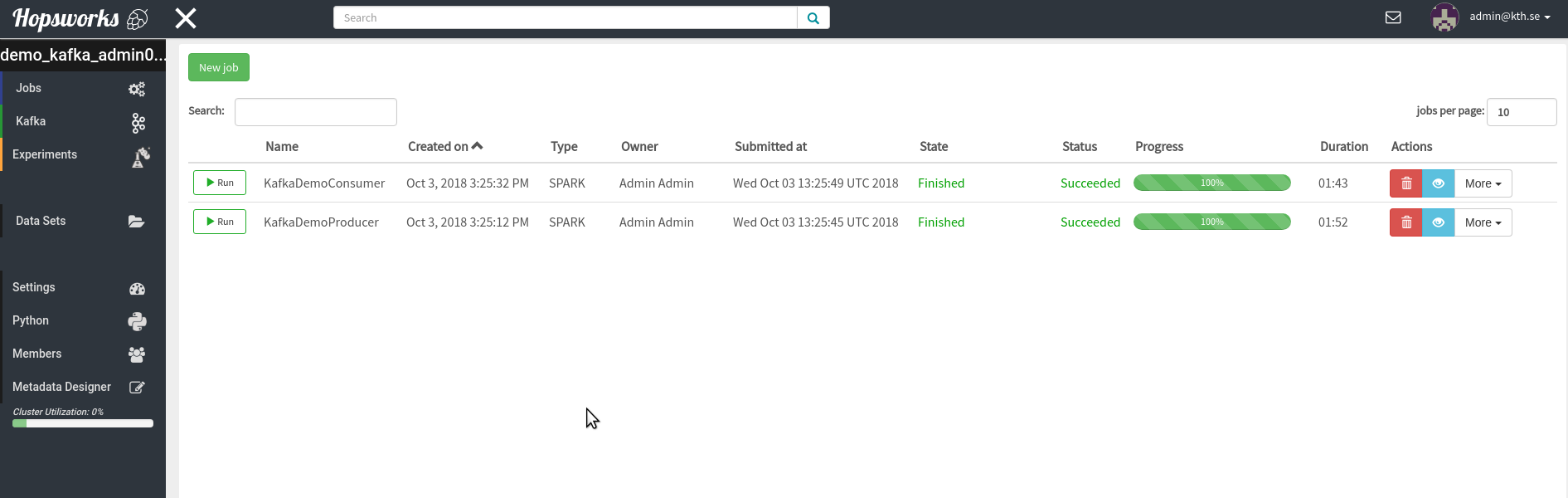
To run this notebook you should have taken the Kafka tour and created the Producer and Consumer jobs. I.e your Job UI should look like this:
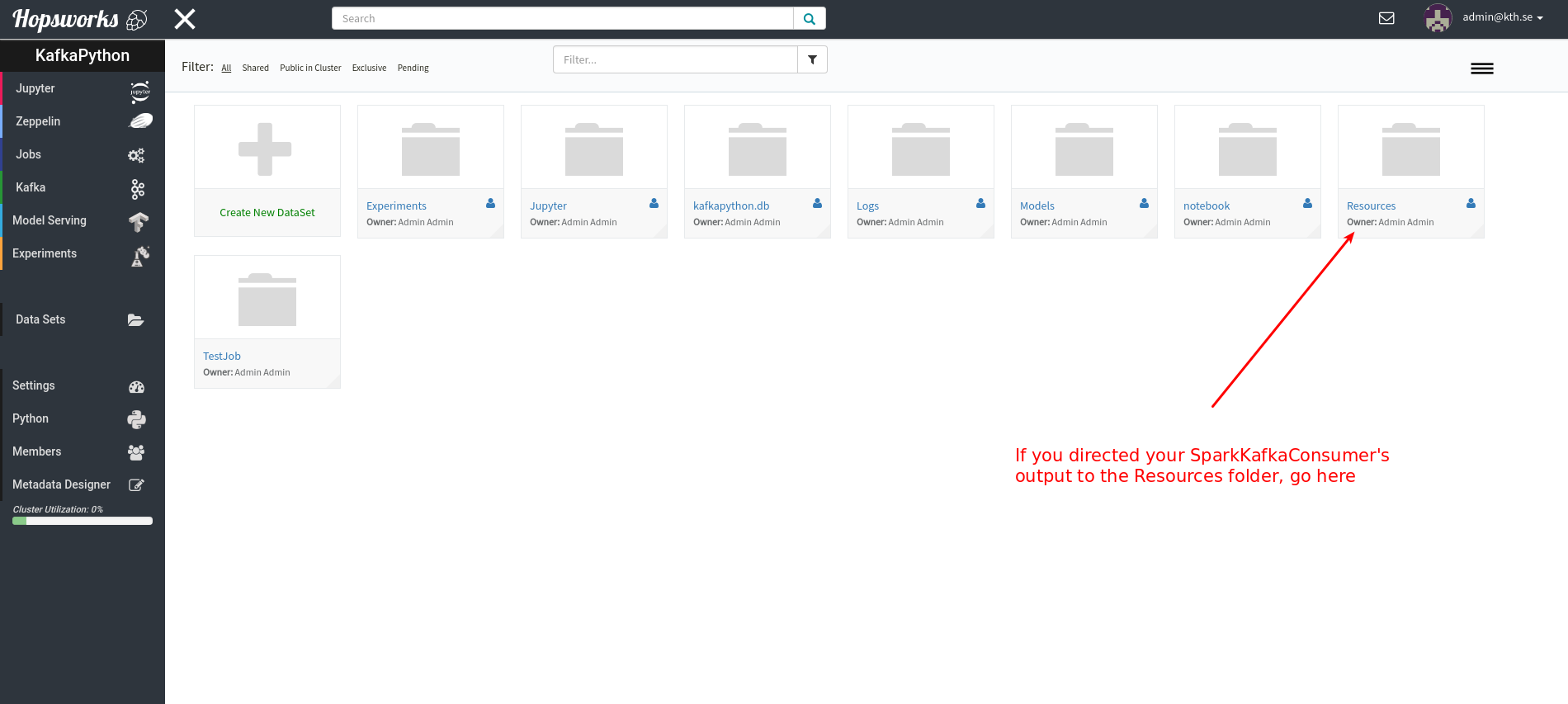
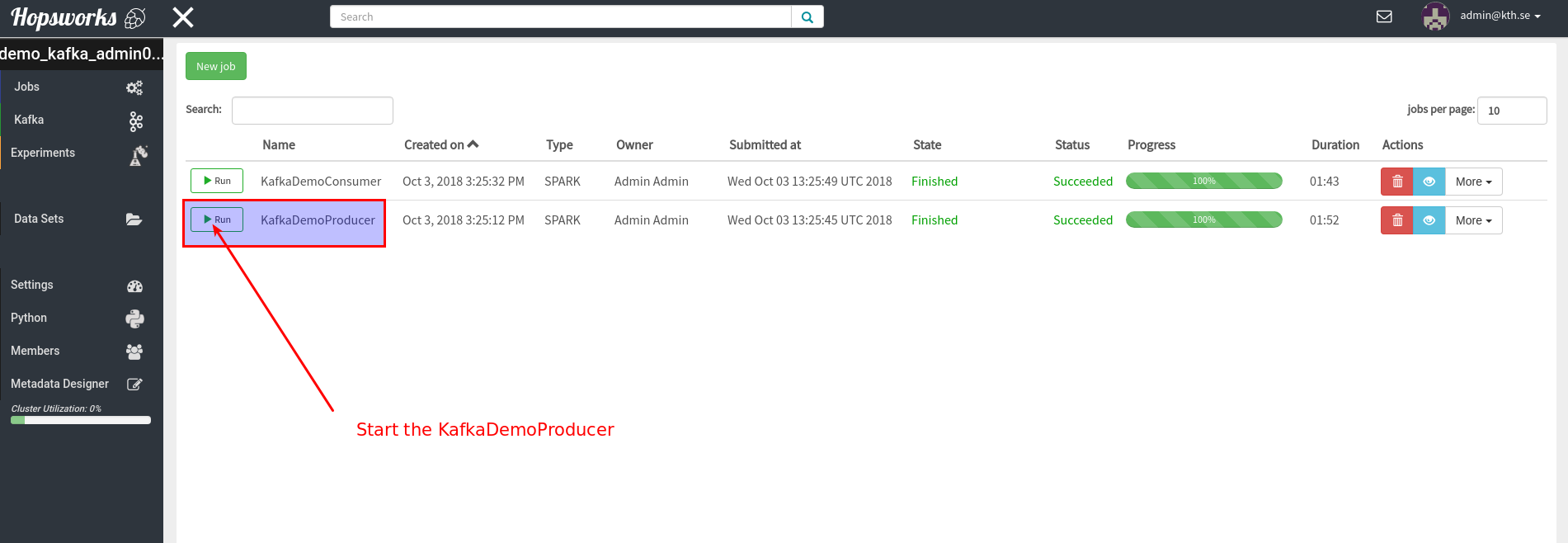
In this notebook we will consume messages from Kafka that were produced by the producer-job created in the Demo. Go to the Jobs-UI in hopsworks and start the Kafka producer job:
Imports¶
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kafka.common.serialization.StringSerializer
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import io.hops.util.Hops
import org.apache.spark._
import org.apache.spark.streaming._
Starting Spark application
SparkSession available as 'spark'. import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.kafka.common.serialization.StringSerializer import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import io.hops.util.Hops import org.apache.spark._ import org.apache.spark.streaming._
Constants¶
Update the TOPIC_NAME field to reflect the name of your Kafka topic that was created in your Kafka tour (e.g "DemoKafkaTopic_3")
Update the OUTPUT_PATH field to where the output data should be written
val topicName = "test2"
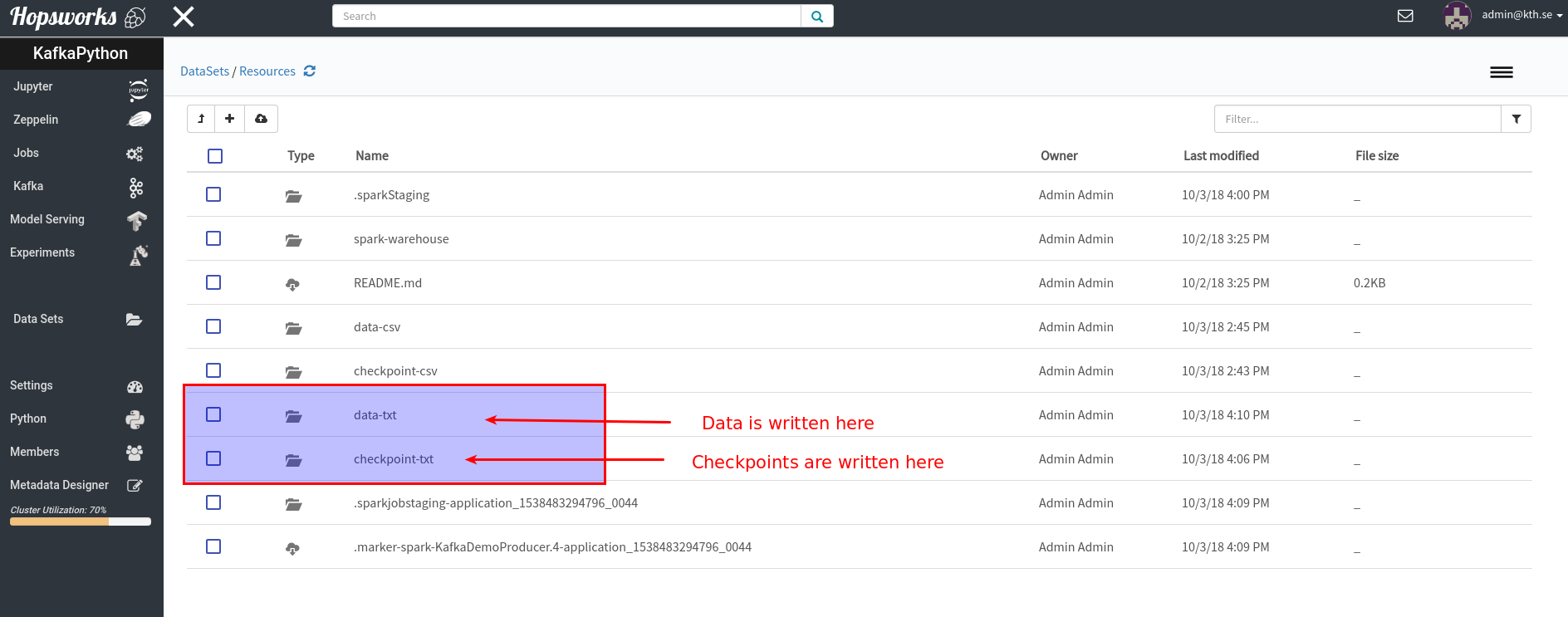
val outputPath = "/Projects/" + Hops.getProjectName() + "/Resources/data2-txt"
val checkpointPath = "/Projects/" + Hops.getProjectName() + "/Resources/checkpoint2-txt"
topicName: String = test2 outputPath: String = /Projects/KafkaPython/Resources/data2-txt checkpointPath: String = /Projects/KafkaPython/Resources/checkpoint2-txt
Consume the Kafka Topic using Spark and Write to a Sink¶
The below snippet creates a streaming DataFrame with Kafka as a data source. Spark is lazy so it will not start streaming the data from Kafka into the dataframe until we specify an output sink (which we do later on in this notebook)
val df = spark.readStream.format("kafka").
option("kafka.bootstrap.servers", Hops.getBrokerEndpoints()).
option("kafka.security.protocol","SSL").
option("kafka.ssl.truststore.location",Hops.getTrustStore()).
option("kafka.ssl.truststore.password", Hops.getKeystorePwd().filterNot(_.toInt < 32).filterNot(_.toInt == 64)).
option("kafka.ssl.keystore.location",Hops.getKeyStore()).
option("kafka.ssl.keystore.password",Hops.getKeystorePwd().filterNot(_.toInt < 32).filterNot(_.toInt == 64)).
option("kafka.ssl.key.password",Hops.getKeystorePwd().filterNot(_.toInt < 32).filterNot(_.toInt == 64)).
option("subscribe", topicName).load();
df: org.apache.spark.sql.DataFrame = [key: binary, value: binary ... 5 more fields]
When using Kafka as a data source, Spark gives us a default kafka schema as printed below
df.printSchema()
root |-- key: binary (nullable = true) |-- value: binary (nullable = true) |-- topic: string (nullable = true) |-- partition: integer (nullable = true) |-- offset: long (nullable = true) |-- timestamp: timestamp (nullable = true) |-- timestampType: integer (nullable = true)
We are using the Spark structured streaming engine, which means that we can express stream queries just as we would do in batch jobs.
Below we filter the input stream to select only the message values
val messages = df.selectExpr("CAST(value AS STRING)")
messages: org.apache.spark.sql.DataFrame = [value: string]
Specify the output query and the sink of the stream job to be a CSV file in HopsFS.
By using checkpointing and a WAL, spark gives us end-to-end exactly-once fault-tolerance
val query = messages.
writeStream.
format("text").
option("path", outputPath).
option("checkpointLocation", checkpointPath).
start()
query: org.apache.spark.sql.streaming.StreamingQuery = org.apache.spark.sql.execution.streaming.StreamingQueryWrapper@19e5278f
Run the streaming job, in theory streaming jobs should run forever.
The call below will be blocking and not terminate. To kill this job you have to restart the pyspark kernel.
query.awaitTermination()
query.stop()
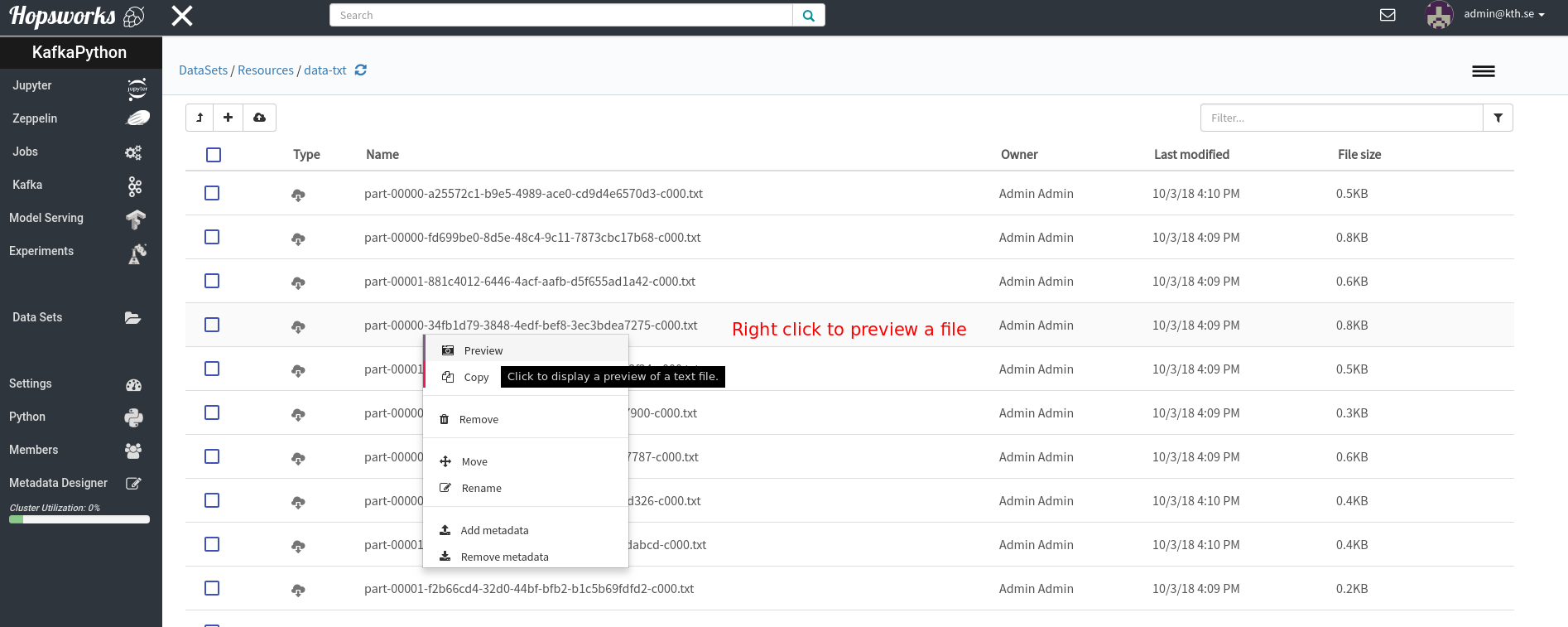
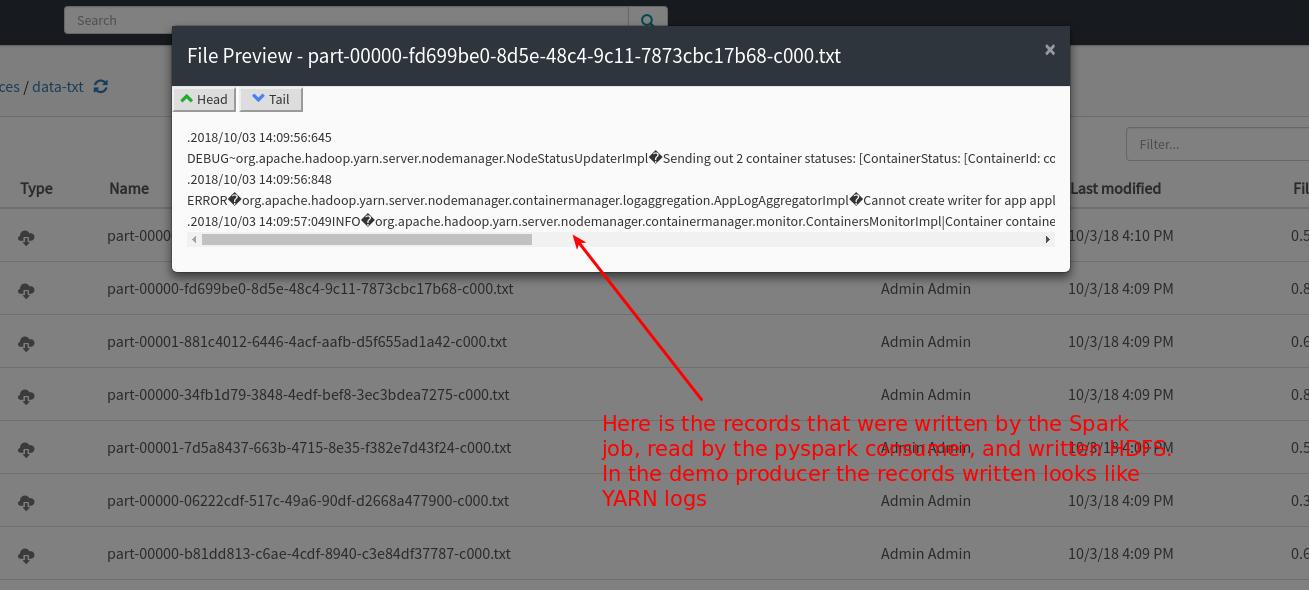
While the job is running you can go to the HDFS file browser in the Hopsworks UI to preview the files: