import pandas as pd
import lux
# Collecting basic usage statistics for Lux (For more information, see: https://tinyurl.com/logging-consent)
lux.logger = True # Remove this line if you do not want your interactions recorded
In this tutorial, we look at the Happy Planet Index dataset, which contains metrics related to well-being for 140 countries around the world. We demonstrate how you can select visualizations of interest and export them for further analysis.
df = pd.read_csv('https://github.com/lux-org/lux-datasets/blob/master/data/hpi.csv?raw=true')
lux.config.default_display = "lux" # Set Lux as default display
Note that for the convienience of this tutorial, we have set Lux as the default display so we don't have to Toggle from the Pandas table display everytime we print the dataframe.
Exporting one or more visualizations from recommendation widget¶
In Lux, you can click on visualizations of interest and export them into a separate widget for further processing.
df
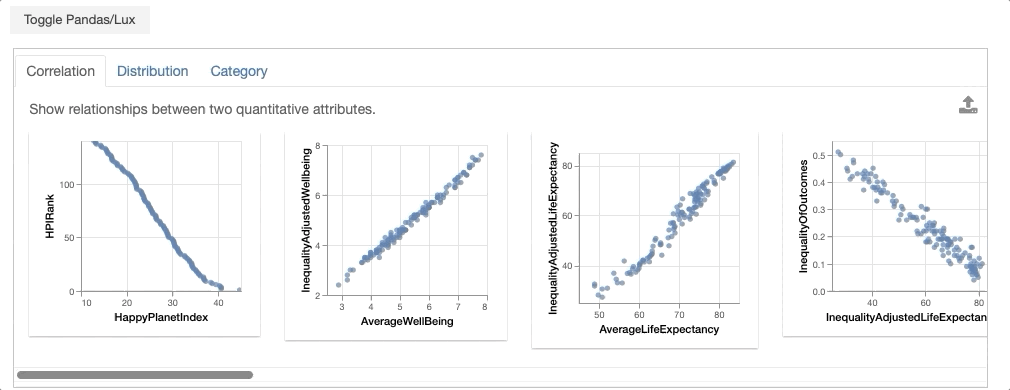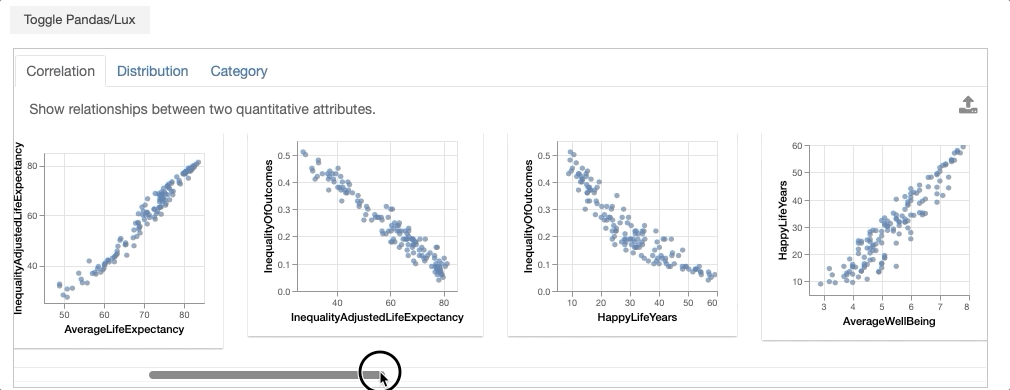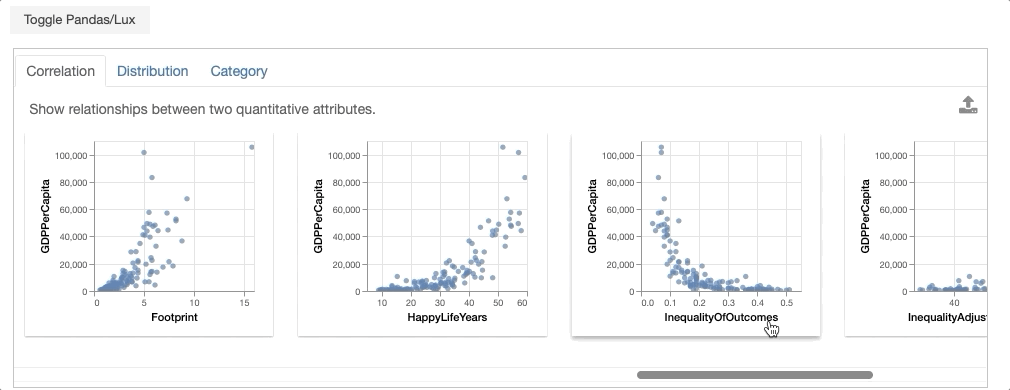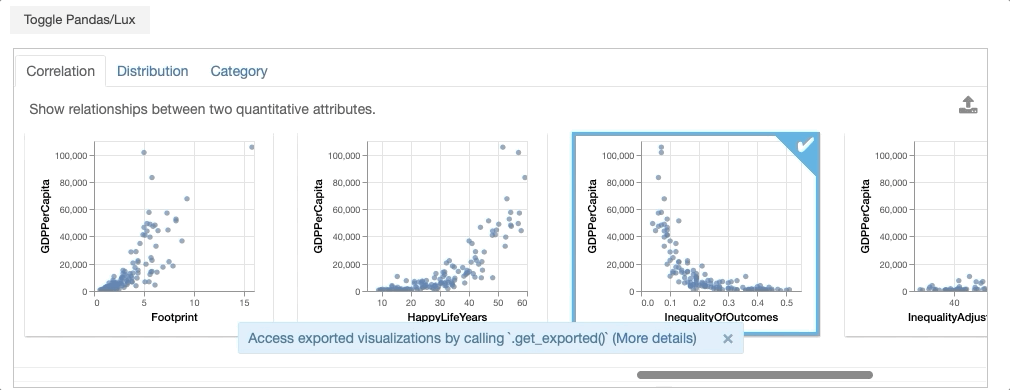
bookmarked_charts = df.exported
bookmarked_charts
From the dataframe recommendations, the visualization showing the relationship between GDPPerCapita and Footprint is very interesting. In particular, there is an outlier with extremely high ecological footprint as well as high GDP per capita. So we click on this visualization and click on the export button.
df
# Click on the GDPPerCapita v.s. Footprint vis and export it first before running this cell
vis = df.exported[0]
vis
vis
Setting Vis as the Updated Intent¶
Often, we might be interested in other visualizations that is related to a visualization of interest and want to learn more. With the exported Vis, we can update the intent associated with dataframe to be based on the selected Vis to get more recommendations related to this visualization.
df.intent = vis
df
Accessing Widget State¶
We can access the set of recommendations generated for the dataframes via the properties recommendation.
df.recommendation
The resulting output is a dictionary, keyed by the name of the recommendation category.
df.recommendation["Enhance"]
You can also access the vis represented by the current intent via the property current_vis.
df.current_vis
Exporting Visualizations as Code¶
Let's revist our earlier recommendations by clearing the specified intent.
df.clear_intent()
df
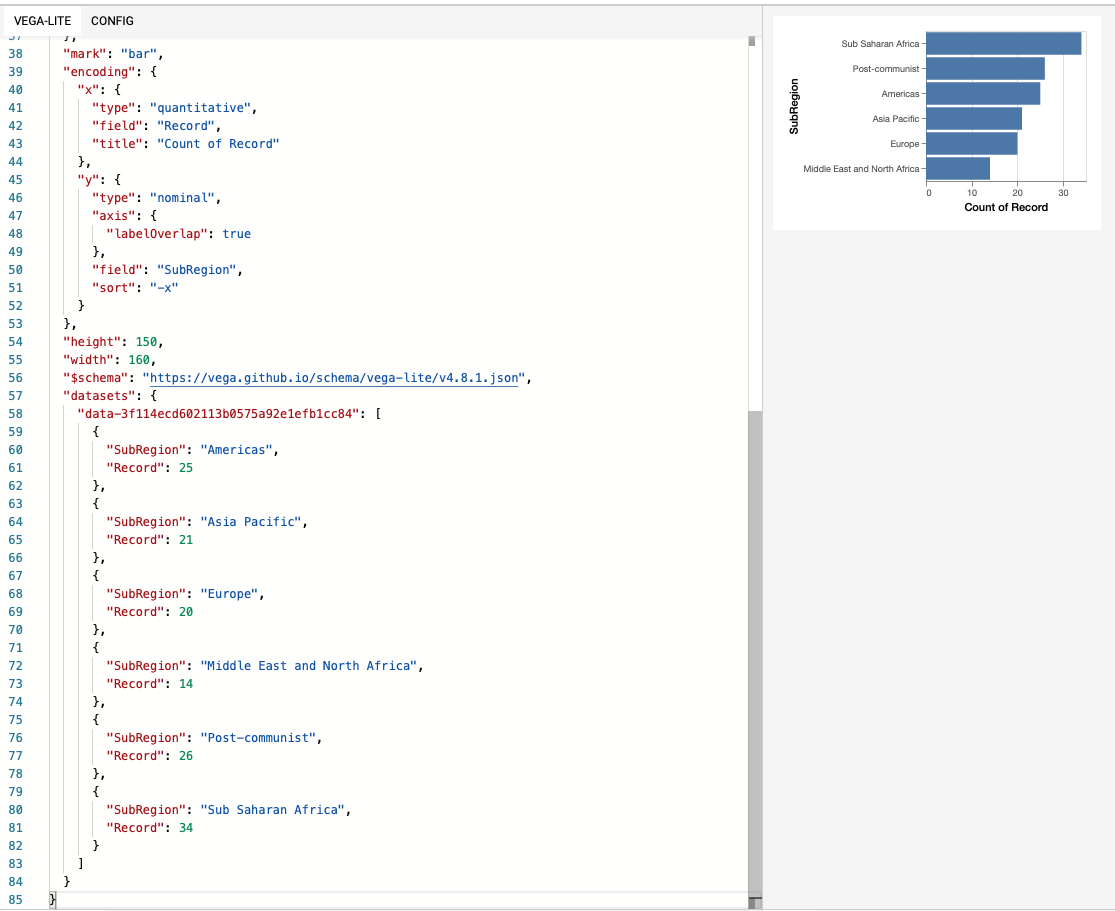
Looking at the Occurrence tab, we are interested in the bar chart distribution of country SubRegion.
vis = df.recommendation["Occurrence"][0]
vis
print (vis.to_Altair())
This can be copy-and-pasted back into a new notebook cell for further editing.
import altair as alt
visData = pd.DataFrame({'SubRegion': {0: 'Americas', 1: 'Asia Pacific', 2: 'Europe', 3: 'Middle East and North Africa', 4: 'Post-communist', 5: 'Sub Saharan Africa'}, 'Record': {0: 25, 1: 21, 2: 20, 3: 14, 4: 26, 5: 34}})
chart = alt.Chart(visData).mark_bar().encode(
y = alt.Y('SubRegion', type= 'nominal', axis=alt.Axis(labelOverlap=True), sort ='-x'),
x = alt.X('Record', type= 'quantitative', title='Count of Record'),
)
chart = chart.configure_mark(tooltip=alt.TooltipContent('encoding')) # Setting tooltip as non-null
chart = chart.configure_title(fontWeight=500,fontSize=13,font='Helvetica Neue')
chart = chart.configure_axis(titleFontWeight=500,titleFontSize=11,titleFont='Helvetica Neue',
labelFontWeight=400,labelFontSize=8,labelFont='Helvetica Neue',labelColor='#505050')
chart = chart.configure_legend(titleFontWeight=500,titleFontSize=10,titleFont='Helvetica Neue',
labelFontWeight=400,labelFontSize=8,labelFont='Helvetica Neue')
chart = chart.properties(width=160,height=150)
chart
You can also export this as Vega-Lite specification and vis/edit the specification on Vega Editor.
print (vis.to_VegaLite())
Let's say now we are interested in the scatter plot of the HPIRank and HappyPlanetIndex.
vis = df.recommendation["Correlation"][0]
Since the dataframes associated with points on a scatterplot is large, by default Lux infers the variable name used locally for the data, and uses that as the data in the printed code block.
print (vis.to_Altair())
Alternatively, if we wanted to include the actual data in the returned codeblock, we could set the parameter standalone to be True in to_Altair.
print (vis.to_Altair(standalone=True))