Обзор базовых подходов к решению задачи Uplift Моделирования¶
SCIKIT-UPLIFT REPO | SCIKIT-UPLIFT DOCS | USER GUIDE
ENGLISH VERSION
СТАТЬЯ НА HABR ЧАСТЬ 1 | СТАТЬЯ НА HABR ЧАСТЬ 2
Содержание¶
Введение¶
Прежде чем переходить к обсуждению uplift моделирования, представим некоторую ситуацию.
К вам приходит заказчик с некоторой проблемой: необходимо с помощью sms рассылки прорекламировать достаточно популярный продукт. У вас как у самого настоящего, топового дата саентиста в голове уже вырисовался план:
И тут вы начинаете понимать, что продукт и без того популярный, что без коммуникации продукт достаточно часто устанавливается клиентами, что обычная бинарная классификация обнаружит много таких клиентов, а стоимость коммуникация для нас критична...
Исторически, по воздействию коммуникации маркетологи разделяют всех клиентов на 4 категории:

Спящая собака- человек, который будет реагировать негативно, если с ним прокоммуницировать. Яркий пример: клиенты, которые забыли про платную подписку. Получив напоминание об этом, они обязательно ее отключат. Но если их не трогать, то клиенты по-прежнему будут приносить деньги. В терминах математики: $W_i = 1, Y_i = 0$ или $W_i = 0, Y_i = 1$.Потерянный- человек, который не совершит целевое действие независимо от коммуникаций. Взаимодействие с такими клиентами не приносит дополнительного дохода, но создает дополнительные затраты. В терминах математики: $W_i = 1, Y_i = 0$ или $W_i = 0, Y_i = 0$.Лояльный- человек, который будет реагировать положительно, несмотря ни на что - самый лояльный вид клиентов. По аналогии с предыдущим пунктом, такие клиенты также расходуют ресурсы. Однако в данном случае расходы гораздо больше, так как лояльные еще и пользуются маркетинговым предложением (скидками, купонами и другое). В терминах математики: $W_i = 1, Y_i = 1$ или $W_i = 0, Y_i = 1$.Убеждаемый- это человек, который положительно реагирует на предложение, но при его отсутствии не выполнил бы целевого действия. Это те люди, которых мы хотели бы определить нашей моделью, чтобы с ними прокоммуницировать. В терминах математики: $W_i = 0, Y_i = 0$ или $W_i = 1, Y_i = 1$.
Стоит отметить, что в зависимости от клиентской базы и особенностей компании возможно отсутствие некоторых из этих типов клиентов.
Таким образом, в данной задаче нам хочется не просто спрогнозировать вероятность выполнения целевого действия, а сосредоточить рекламный бюджет на клиентах, которые выполнят целевое действие только при нашем взаимодействии. Иначе говоря, для каждого клиента хочется отдельно оценить две условные вероятности:
- Выполнение целевого действия при нашем воздействии на клиента. Таких клиентов будем относить к тестовой группе (aka treatment): $P^T = P(Y=1 | W = 1)$,
- Выполнение целевого действия без воздействия на клиента. Таких клиентов будем относить к контрольной группе (aka control): $P^C = P(Y=1 | W = 0)$,
где $Y$ - бинарный флаг выполнения целевого действия, $W$ - бинарный флаг наличия коммуникации (в англоязычной литературе - treatment)
Сам же причинно-следственный эффект называется uplift и оценивается как разность двух этих вероятностей:
$$ uplift = P^T - P^C = P(Y = 1 | W = 1) - P(Y = 1 | W = 0)$$Прогнозирование uplift - это задача причинно-следственного вывода. Дело в том, что нужно оценить разницу между двумя событиями, которые являются взаимоисключающими для конкретного клиента (либо мы взаимодействуем с человеком, либо нет; нельзя одновременно совершить два этих действия). Именно поэтому для построения моделей uplift предъявляются дополнительные требования к исходным данным.
Для получения обучающей выборки для моделирования uplift необходимо провести эксперимент:
- Случайным образом разбить репрезентативную часть клиентской базы на тестовую и контрольную группу
- Прокоммуницировать с тестовой группой
Данные, полученные в рамках дизайна такого пилота, позволят нам в дальнейшем построить модель прогнозирования uplift. Стоит также отметить, что эксперимент должен быть максимально похож на кампнию, которая будет запущена позже в более крупном масштабе. Единственным отличием эксперимента от кампании должен быть тот факт, что во время пилота для взаимодействия мы выбираем случайных клиентов, а во время кампании - на основе спрогнозированного значения Uplift. Если кампания, которая в конечном итоге запускается, существенно отличается от эксперимента, используемого для сбора данных о выполнении целевых действий клиентами, то построенная модель может быть менее надежной и точной.
Итак, подходы к прогнозированию uplift направлены на оценку чистого эффекта от воздействия маркетинговых кампаний на клиентов.
Подробнее про uplift можно прочитать в цикле статьй на хабре.
Все классические подходы к моделированию uplift можно разделить на два класса:
- Подходы с применением одной моделью
- Подходы с применением двух моделей
Скачаем и распакуем данные конкурса RetailHero.ai:
import urllib.request
url = 'https://drive.google.com/u/0/uc?id=1fkxNmihuS15kk0PP0QcphL_Z3_z8LLeb&export=download'
urllib.request.urlretrieve(url, '/content/retail_hero.zip')
!unzip /content/retail_hero.zip
!pip install scikit-uplift==0.1.2 catboost=0.22
Импортируем нужные библиотеки и предобработаем данные:
%matplotlib inline
import pandas as pd; pd.set_option('display.max_columns', None)
from sklearn.model_selection import train_test_split
# Чтение данных
df_clients = pd.read_csv('/content/uplift_data/clients.csv', index_col='client_id')
df_train = pd.read_csv('/content/uplift_data/uplift_train.csv', index_col='client_id')
df_test = pd.read_csv('/content/uplift_data/uplift_test.csv', index_col='client_id')
# Извлечение признаков
df_features = df_clients.copy()
df_features['first_issue_time'] = \
(pd.to_datetime(df_features['first_issue_date'])
- pd.Timestamp('1970-01-01')) // pd.Timedelta('1s')
df_features['first_redeem_time'] = \
(pd.to_datetime(df_features['first_redeem_date'])
- pd.Timestamp('1970-01-01')) // pd.Timedelta('1s')
df_features['issue_redeem_delay'] = df_features['first_redeem_time'] \
- df_features['first_issue_time']
df_features = df_features.drop(['first_issue_date', 'first_redeem_date'], axis=1)
indices_train = df_train.index
indices_test = df_test.index
indices_learn, indices_valid = train_test_split(df_train.index, test_size=0.3, random_state=123)
Для удобства объявим некоторые переменные:
X_train = df_features.loc[indices_learn, :]
y_train = df_train.loc[indices_learn, 'target']
treat_train = df_train.loc[indices_learn, 'treatment_flg']
X_val = df_features.loc[indices_valid, :]
y_val = df_train.loc[indices_valid, 'target']
treat_val = df_train.loc[indices_valid, 'treatment_flg']
X_train_full = df_features.loc[indices_train, :]
y_train_full = df_train.loc[:, 'target']
treat_train_full = df_train.loc[:, 'treatment_flg']
X_test = df_features.loc[indices_test, :]
cat_features = ['gender']
models_results = {
'approach': [],
'uplift@30%': []
}
1. Подходы с одной моделью¶
1.1 Одна модель с признаком коммуникации¶
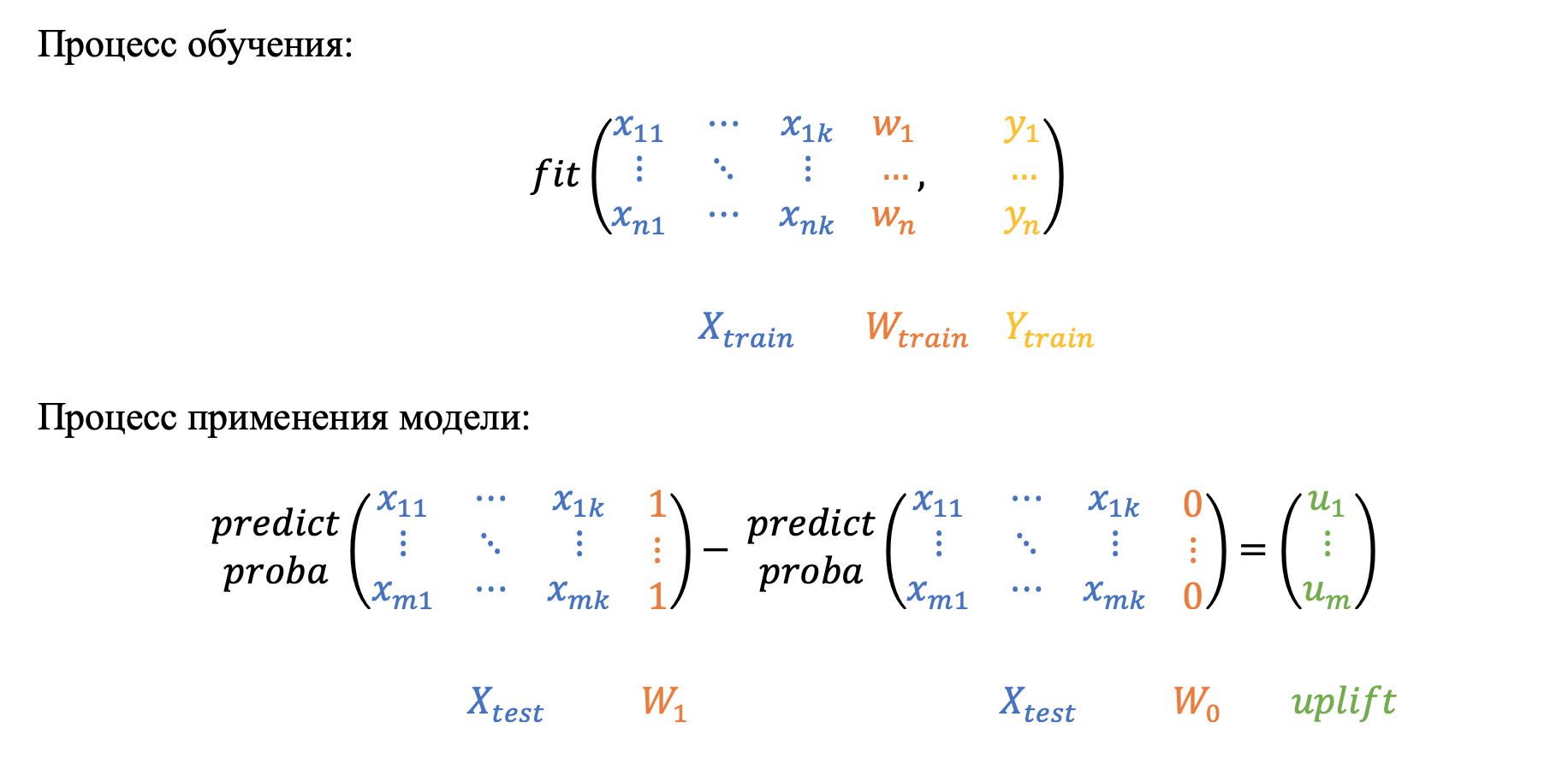
Самое простое и интуитивное решение: модель обучается одновременно на двух группах, при этом бинарный флаг коммуникации выступает в качестве дополнительного признака. Каждый объект из тестовой выборки скорим дважды: с флагом коммуникации равным 1 и равным 0. Вычитая вероятности по каждому наблюдению, получим искомы uplift.
# Инструкция по установке пакета: https://github.com/maks-sh/scikit-uplift
# Ссылка на документацию: https://scikit-uplift.readthedocs.io/en/latest/
from sklift.metrics import uplift_at_k
from sklift.viz import plot_uplift_preds
from sklift.models import SoloModel
# sklift поддерживает любые модели,
# которые удовлетворяют соглашениями scikit-learn
# Для примера воспользуемся catboost
from catboost import CatBoostClassifier
sm = SoloModel(CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True))
sm = sm.fit(X_train, y_train, treat_train, estimator_fit_params={'cat_features': cat_features})
uplift_sm = sm.predict(X_val)
sm_score = uplift_at_k(y_true=y_val, uplift=uplift_sm, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('SoloModel')
models_results['uplift@30%'].append(sm_score)
# Получим условные вероятности выполнения целевого действия при взаимодействии для каждого объекта
sm_trmnt_preds = sm.trmnt_preds_
# И условные вероятности выполнения целевого действия без взаимодействия для каждого объекта
sm_ctrl_preds = sm.ctrl_preds_
# Отрисуем распределения вероятностей и их разность (uplift)
plot_uplift_preds(trmnt_preds=sm_trmnt_preds, ctrl_preds=sm_ctrl_preds);

# С той же легкостью можно обратиться к обученной модели.
# Например, чтобы построить важность признаков:
sm_fi = pd.DataFrame({
'feature_name': sm.estimator.feature_names_,
'feature_score': sm.estimator.feature_importances_
}).sort_values('feature_score', ascending=False).reset_index(drop=True)
sm_fi
| feature_name | feature_score | |
|---|---|---|
| 0 | first_redeem_time | 65.214393 |
| 1 | issue_redeem_delay | 12.564364 |
| 2 | age | 7.891613 |
| 3 | first_issue_time | 7.262806 |
| 4 | treatment | 4.362077 |
| 5 | gender | 2.704747 |
1.2 Трансформация классов¶
Достаточно интересный и математически подтвержденный подход к построению модели, представленный еще в 2012 году. Метод заключается в прогнозировании немного измененного таргета:
$$ Z_i = Y_i \cdot W_i + (1 - Y_i) \cdot (1 - W_i), $$где
- $Z_i$ - новая целевая переменная $i$-ого клиента;
- $Y_i$ - целевая перемнная $i$-ого клиента;
- $W_i$ - флаг коммуникации $i$-ого клиента;
Другими словами, новый класс равен 1, если мы знаем, что на конкретном наблюдении, результат при взаимодействии был бы таким же хорошим, как и в контрольной группе, если бы мы могли знать результат в обеих группах:
$$ Z_i = \begin{cases} 1, & \mbox{if } W_i = 1 \mbox{ and } Y_i = 1 \\ 1, & \mbox{if } W_i = 0 \mbox{ and } Y_i = 0 \\ 0, & \mbox{otherwise} \end{cases} $$Распишем подробнее, чему равна вероятность новой целевой переменной:
$$ P(Z=1|X = x) = \\ = P(Z=1|X = x, W = 1) \cdot P(W = 1|X = x) + \\ + P(Z=1|X = x, W = 0) \cdot P(W = 0|X = x) = \\ = P(Y=1|X = x, W = 1) \cdot P(W = 1|X = x) + \\ + P(Y=0|X = x, W = 0) \cdot P(W = 0|X = x). $$Выше мы обсуждали, что обучающая выборка для моделирования uplift собирается на основе рандомизированного разбиения части клиенской базы на тестовую и контрольную группы. Поэтому коммуникация $ W $ не может зависить от признаков клиента $ X_1, ..., X_m $. Принимая это, мы имеем: $ P(W | X_1, ..., X_m, ) = P(W) $ и
$$ P(Z=1|X = x) = \\ = P^T(Y=1|X = x) \cdot P(W = 1) + \\ + P^C(Y=0|X = x) \cdot P(W = 0) $$Также допустим, что $P(W = 1) = P(W = 0) = \frac{1}{2}$, т.е. во время эксперимента контрольные и тестовые группы были разделены в равных пропорциях. Тогда получим следующее:
$$ P(Z=1|X = x) = \\ = P^T(Y=1|X = x) \cdot \frac{1}{2} + P^C(Y=0|X = x) \cdot \frac{1}{2} \Rightarrow \\ 2 \cdot P(Z=1|X = x) = \\ = P^T(Y=1|X = x) + P^C(Y=0|X = x) = \\ = P^T(Y=1|X = x) + 1 - P^C(Y=1|X = x) \Rightarrow \\ \Rightarrow P^T(Y=1|X = x) - P^C(Y=1|X = x) = \\ = uplift = 2 \cdot P(Z=1|X = x) - 1 $$Таким образом, увеличив вдвое прогноз нового таргета и вычтя из него единицу мы получим значение самого uplift'a, т.е.
$$ uplift = 2 \cdot P(Z=1) - 1 $$Исходя из допущения описанного выше: $P(W = 1) = P(W = 0) = \frac{1}{2}$, данный подход следует использовать только в случаях, когда количество клиентов, с которыми мы прокоммуницировлаи, равно количеству клиентов, с которыми коммуникации не было.
from sklift.models import ClassTransformation
ct = ClassTransformation(CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True))
ct = ct.fit(X_train, y_train, treat_train, estimator_fit_params={'cat_features': cat_features})
uplift_ct = ct.predict(X_val)
ct_score = uplift_at_k(y_true=y_val, uplift=uplift_ct, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('ClassTransformation')
models_results['uplift@30%'].append(ct_score)
/Users/Maksim/Library/Python/3.6/lib/python/site-packages/ipykernel_launcher.py:5: UserWarning: It is recommended to use this approach on treatment balanced data. Current sample size is unbalanced. """
2. Подходы с двумя моделями¶
Подход с двумя моделями можно встретить почти в любой работе по uplift моделированию, он часто используется в качестве бейзлайна. Однако использование двух моделей может привести к некоторым неприятным последствиям: если для обучения будут использоваться принципиально разные модели или природа данных тестовой и контрольной групп будут сильно отличаться, то возвращаемые моделями скоры будут не сопоставимы между собой. Вследствие чего расчет uplift будет не совсем корректным. Для избежания такого эффекта необходимо калибровать модели, чтобы их скоры можно было интерпертировать как вероятности. Калибровка вероятностей модели отлично описана в документации scikit-learn.
2.1 Две независимые модели¶
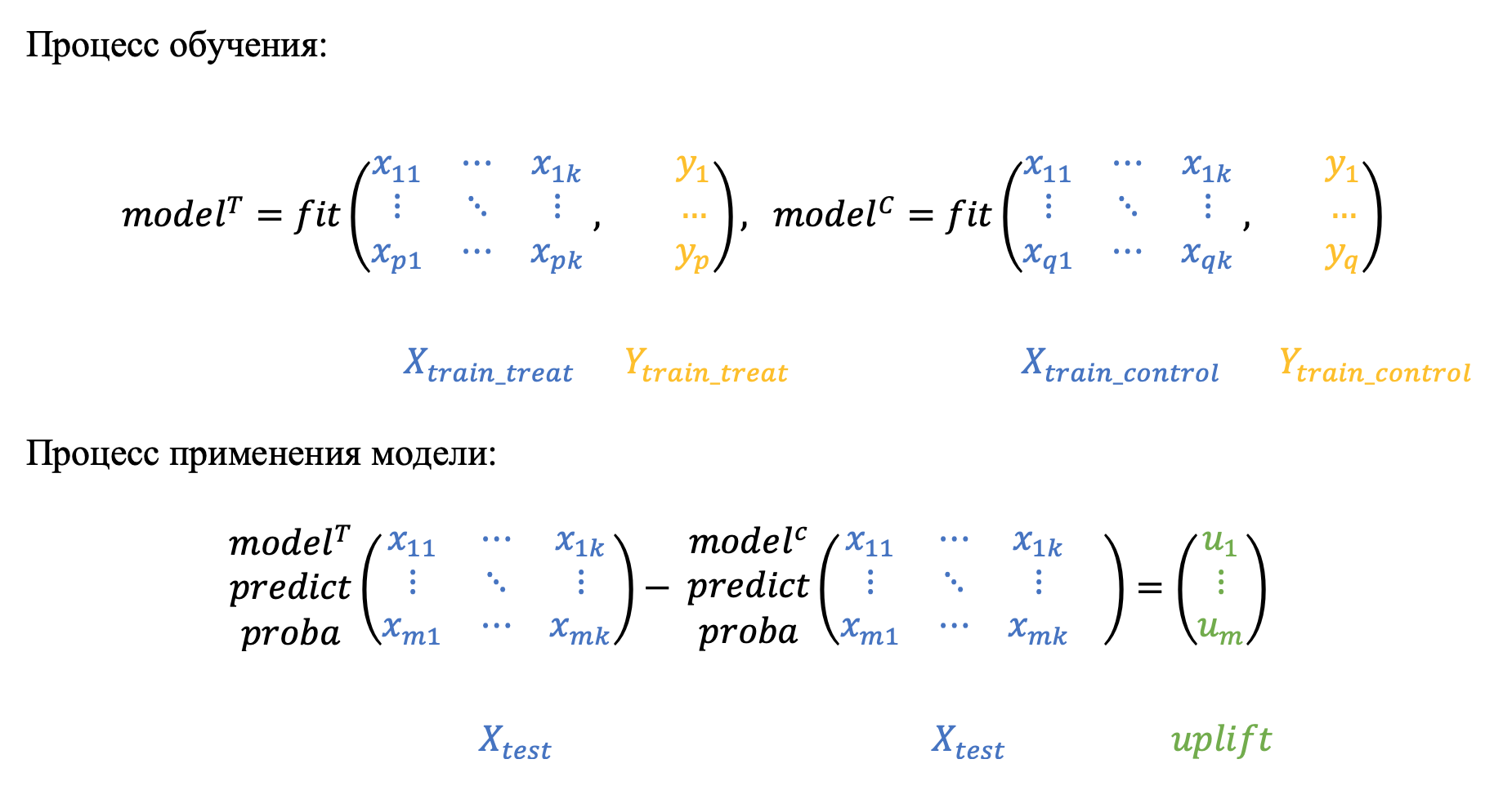
Как понятно из названия, подход заключается в моделировании условных вероятностей тестовой и контрольной групп отдельно. В статьях утверждается, что такой подход достаточно слабый, так как обе модели фокусируются на прогнозировании результата отдельно и поэтому могут пропустить "более слабые" различия в выборках.
from sklift.models import TwoModels
tm = TwoModels(
estimator_trmnt=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
estimator_ctrl=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
method='vanilla'
)
tm = tm.fit(
X_train, y_train, treat_train,
estimator_trmnt_fit_params={'cat_features': cat_features},
estimator_ctrl_fit_params={'cat_features': cat_features}
)
uplift_tm = tm.predict(X_val)
tm_score = uplift_at_k(y_true=y_val, uplift=uplift_tm, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('TwoModels')
models_results['uplift@30%'].append(tm_score)
plot_uplift_preds(trmnt_preds=tm.trmnt_preds_, ctrl_preds=tm.ctrl_preds_);

2.2 Две зависимые модели¶
Подход зависимого представления данных основан на методе цепочек классификаторов, первоначально разработанном для задач многоклассовой классификации. Идея состоит в том, что при наличии $L$ различных меток можно построить $L$ различных классификаторов, каждый из которых решает задачу бинарной классификации и в процессе обучения каждый следующий классификатор использует предсказания предыдущих в качестве дополнительных признаков. Авторы данного метода предложили использовать ту же идею для решения проблемы uplift моделирования в два этапа. В начале мы обучаем классификатор по контрольным данным: $$ P^C = P(Y=1| X, W = 0), $$ затем исполним предсказания $P_C$ в качестве нового признака для обучения второго классификатора на тестовых данных, тем самым эффективно вводя зависимость между двумя наборами данных:
$$ P^T = P(Y=1| X, P_C(X), W = 1) $$Чтобы получить uplift для каждого наблюдения, вычислим разницу:
$$ uplift(x_i) = P^T(x_i, P_C(x_i)) - P^C(x_i) $$Интуитивно второй классификатор изучает разницу между ожидаемым результатом в тесте и контроле, т.е. сам uplift.

tm_ctrl = TwoModels(
estimator_trmnt=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
estimator_ctrl=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
method='ddr_control'
)
tm_ctrl = tm_ctrl.fit(
X_train, y_train, treat_train,
estimator_trmnt_fit_params={'cat_features': cat_features},
estimator_ctrl_fit_params={'cat_features': cat_features}
)
uplift_tm_ctrl = tm_ctrl.predict(X_val)
tm_ctrl_score = uplift_at_k(y_true=y_val, uplift=uplift_tm_ctrl, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('TwoModels_ddr_control')
models_results['uplift@30%'].append(tm_ctrl_score)
plot_uplift_preds(trmnt_preds=tm_ctrl.trmnt_preds_, ctrl_preds=tm_ctrl.ctrl_preds_);

Аналогичным образом можно сначала обучить классификатор $P^T$, а затем использовать его предсказания в качестве признака для классификатора $P^C$.
tm_trmnt = TwoModels(
estimator_trmnt=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
estimator_ctrl=CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True),
method='ddr_treatment'
)
tm_trmnt = tm_trmnt.fit(
X_train, y_train, treat_train,
estimator_trmnt_fit_params={'cat_features': cat_features},
estimator_ctrl_fit_params={'cat_features': cat_features}
)
uplift_tm_trmnt = tm_trmnt.predict(X_val)
tm_trmnt_score = uplift_at_k(y_true=y_val, uplift=uplift_tm_trmnt, treatment=treat_val, strategy='by_group', k=0.3)
models_results['approach'].append('TwoModels_ddr_treatment')
models_results['uplift@30%'].append(tm_trmnt_score)
plot_uplift_preds(trmnt_preds=tm_trmnt.trmnt_preds_, ctrl_preds=tm_trmnt.ctrl_preds_);

Заключение¶
Рассмотрим, какой метод лучше всего показал себя в этой задаче, и проскорим им тестовую выборку:
pd.DataFrame(data=models_results).sort_values('uplift@30%', ascending=False)
| approach | uplift@30% | |
|---|---|---|
| 1 | ClassTransformation | 0.061775 |
| 2 | TwoModels | 0.051637 |
| 3 | TwoModels_ddr_control | 0.047793 |
| 0 | SoloModel | 0.041614 |
| 4 | TwoModels_ddr_treatment | 0.033752 |
Из таблички выше можно понять, что в текущей задаче лучше всего справился подход трансформации целевой перемнной. Обучим модель на всей выборке и предскажем на тест.
ct_full = ClassTransformation(CatBoostClassifier(iterations=20, thread_count=2, random_state=42, silent=True))
ct_full = ct_full.fit(
X_train_full,
y_train_full,
treat_train_full,
estimator_fit_params={'cat_features': cat_features}
)
X_test.loc[:, 'uplift'] = ct_full.predict(X_test.values)
sub = X_test[['uplift']].to_csv('sub1.csv')
!head -n 5 sub1.csv
/Users/Maksim/Library/Python/3.6/lib/python/site-packages/ipykernel_launcher.py:6: UserWarning: It is recommended to use this approach on treatment balanced data. Current sample size is unbalanced.
client_id,uplift 000048b7a6,0.03777380619745441 000073194a,0.0402001184660159 00007c7133,-0.001255842638942739 00007f9014,0.03165865533189738
ct_full_fi = pd.DataFrame({
'feature_name': ct_full.estimator.feature_names_,
'feature_score': ct_full.estimator.feature_importances_
}).sort_values('feature_score', ascending=False).reset_index(drop=True)
ct_full_fi
| feature_name | feature_score | |
|---|---|---|
| 0 | first_redeem_time | 79.642055 |
| 1 | age | 8.808502 |
| 2 | issue_redeem_delay | 5.113192 |
| 3 | first_issue_time | 3.558522 |
| 4 | gender | 2.877728 |
Итак, мы познакомились с uplift моделированием и рассмотрели основные классические подходы его построения. Что дальше? Дальше можно с головй окунуться в разведывательный анализ данных, генерацию новых признаков, подбор моделей и их гиперпарметров, а также изучение новых подходов и библиотек.
Спасибо, что дочитали до конца.
Мне будет приятно, если вы поддержите проект звездочкой на гитхабе или расскажете о нем своим друзьям.