Creating a cross-model ensemble using STAC¶
This tutorial builds a cross-collection ensemble of GDPCIR bias corrected and downscaled data, and plots a single variable time series for the ensemble.
# required to locate and authenticate with the stac collection
import planetary_computer
import pystac_client
# required to load a zarr array using xarray
import xarray as xr
# optional imports used in this notebook
import pandas as pd
from dask.diagnostics import ProgressBar
from tqdm.auto import tqdm
Understanding the GDPCIR collections¶
The CIL-GDPCIR datasets are grouped into two collections, depending on the license the data are provided under.
- CIL-GDPCIR-CC0 - provided in public domain using a CC 1.0 Universal Public Domain Dedication
- CIL-GDPCIR-CC-BY - provided under a CC Attribution 4.0 License
Note that the first group, CC0, places no restrictions on the data. CC-BY 4.0 requires citations of the climate models these datasets are derived from. See the ClimateImpactLab/downscaleCMIP6 README for the citation information for each GCM.
Also, note that none of the descriptions of these licenses on this page, in this repository, and associated with this repository constitute legal advice. We are highlighting some of the key terms of these licenses, but this information should not be considered a replacement for the actual license terms, which are provided on the Creative Commons website at the links above.
Structure of the STAC collection¶
The data assets in this collection are a set of Zarr groups which can be opend by tools like xarray. Each Zarr group contains a single data variable (either pr, tasmax, or tasmin). The Planetary Computer provides a single STAC item per experiment, and each STAC item has one asset per data variable.
Altogether, the collection is just over 21TB, with 247,997 individual files. The STAC collection is here to help search and make sense of this huge archive!
For example, let's take a look at the CC0 collection:
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1/",
modifier=planetary_computer.sign_inplace,
)
collection_cc0 = catalog.get_collection("cil-gdpcir-cc0")
collection_cc0
- type "Collection"
- id "cil-gdpcir-cc0"
- stac_version "1.0.0"
- description "The World Climate Research Programme's [6th Coupled Model Intercomparison Project (CMIP6)](https://www.wcrp-climate.org/wgcm-cmip/wgcm-cmip6) represents an enormous advance in the quality, detail, and scope of climate modeling. The [Global Downscaled Projections for Climate Impacts Research](https://github.com/ClimateImpactLab/downscaleCMIP6) dataset makes this modeling more applicable to understanding the impacts of changes in the climate on humans and society with two key developments: trend-preserving bias correction and downscaling. In this dataset, the [Climate Impact Lab](https://impactlab.org) provides global, daily minimum and maximum air temperature at the surface (`tasmin` and `tasmax`) and daily cumulative surface precipitation (`pr`) corresponding to the CMIP6 historical, ssp1-2.6, ssp2-4.5, ssp3-7.0, and ssp5-8.5 scenarios for 25 global climate models on a 1/4-degree regular global grid. ## Accessing the data GDPCIR data can be accessed on the Microsoft Planetary Computer. The dataset is made of of three collections, distinguished by data license: * [Public domain (CC0-1.0) collection](https://planetarycomputer.microsoft.com/dataset/cil-gdpcir-cc0) * [Attribution (CC BY 4.0) collection](https://planetarycomputer.microsoft.com/dataset/cil-gdpcir-cc-by) Each modeling center with bias corrected and downscaled data in this collection falls into one of these license categories - see the [table below](/dataset/cil-gdpcir-cc0#available-institutions-models-and-scenarios-by-license-collection) to see which model is in each collection, and see the section below on [Citing, Licensing, and using data produced by this project](/dataset/cil-gdpcir-cc0#citing-licensing-and-using-data-produced-by-this-project) for citations and additional information about each license. ## Data format & contents The data is stored as partitioned zarr stores (see [https://zarr.readthedocs.io](https://zarr.readthedocs.io)), each of which includes thousands of data and metadata files covering the full time span of the experiment. Historical zarr stores contain just over 50 GB, while SSP zarr stores contain nearly 70GB. Each store is stored as a 32-bit float, with dimensions time (daily datetime), lat (float latitude), and lon (float longitude). The data is chunked at each interval of 365 days and 90 degree interval of latitude and longitude. Therefore, each chunk is `(365, 360, 360)`, with each chunk occupying approximately 180MB in memory. Historical data is daily, excluding leap days, from Jan 1, 1950 to Dec 31, 2014; SSP data is daily, excluding leap days, from Jan 1, 2015 to either Dec 31, 2099 or Dec 31, 2100, depending on data availability in the source GCM. The spatial domain covers all 0.25-degree grid cells, indexed by the grid center, with grid edges on the quarter-degree, using a -180 to 180 longitude convention. Thus, the “lon” coordinate extends from -179.875 to 179.875, and the “lat” coordinate extends from -89.875 to 89.875, with intermediate values at each 0.25-degree increment between (e.g. -179.875, -179.625, -179.375, etc). ## Available institutions, models, and scenarios by license collection | Modeling institution | Source model | Available experiments | License collection | | -------------------- | ----------------- | ------------------------------------------ | ---------------------- | | CAS | FGOALS-g3 [^1] | SSP2-4.5, SSP3-7.0, and SSP5-8.5 | Public domain datasets | | INM | INM-CM4-8 | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | Public domain datasets | | INM | INM-CM5-0 | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | Public domain datasets | | BCC | BCC-CSM2-MR | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | CMCC | CMCC-CM2-SR5 | ssp1-2.6, ssp2-4.5, ssp3-7.0, ssp5-8.5 | CC-BY-40 | | CMCC | CMCC-ESM2 | ssp1-2.6, ssp2-4.5, ssp3-7.0, ssp5-8.5 | CC-BY-40 | | CSIRO-ARCCSS | ACCESS-CM2 | SSP2-4.5 and SSP3-7.0 | CC-BY-40 | | CSIRO | ACCESS-ESM1-5 | SSP1-2.6, SSP2-4.5, and SSP3-7.0 | CC-BY-40 | | MIROC | MIROC-ES2L | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | MIROC | MIROC6 | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | MOHC | HadGEM3-GC31-LL | SSP1-2.6, SSP2-4.5, and SSP5-8.5 | CC-BY-40 | | MOHC | UKESM1-0-LL | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | MPI-M | MPI-ESM1-2-LR | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | MPI-M/DKRZ [^2] | MPI-ESM1-2-HR | SSP1-2.6 and SSP5-8.5 | CC-BY-40 | | NCC | NorESM2-LM | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | NCC | NorESM2-MM | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | NOAA-GFDL | GFDL-CM4 | SSP2-4.5 and SSP5-8.5 | CC-BY-40 | | NOAA-GFDL | GFDL-ESM4 | SSP1-2.6, SSP2-4.5, SSP3-7.0, and SSP5-8.5 | CC-BY-40 | | NUIST | NESM3 | SSP1-2.6, SSP2-4.5, and SSP5-8.5 | CC-BY-40 | | EC-Earth-Consortium | EC-Earth3 | ssp1-2.6, ssp2-4.5, ssp3-7.0, and ssp5-8.5 | CC-BY-40 | | EC-Earth-Consortium | EC-Earth3-AerChem | ssp370 | CC-BY-40 | | EC-Earth-Consortium | EC-Earth3-CC | ssp245 and ssp585 | CC-BY-40 | | EC-Earth-Consortium | EC-Earth3-Veg | ssp1-2.6, ssp2-4.5, ssp3-7.0, and ssp5-8.5 | CC-BY-40 | | EC-Earth-Consortium | EC-Earth3-Veg-LR | ssp1-2.6, ssp2-4.5, ssp3-7.0, and ssp5-8.5 | CC-BY-40 | | CCCma | CanESM5 | ssp1-2.6, ssp2-4.5, ssp3-7.0, ssp5-8.5 | CC-BY-40[^3] | *Notes:* [^1]: At the time of running, no ssp1-2.6 precipitation data was available. Therefore, we provide `tasmin` and `tamax` for this model and experiment, but not `pr`. All other model/experiment combinations in the above table include all three variables. [^2]: The institution which ran MPI-ESM1-2-HR’s historical (CMIP) simulations is `MPI-M`, while the future (ScenarioMIP) simulations were run by `DKRZ`. Therefore, the institution component of `MPI-ESM1-2-HR` filepaths differ between `historical` and `SSP` scenarios. [^3]: This dataset was previously licensed as [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/), but was relicensed under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0) in March, 2023. ## Project methods This project makes use of statistical bias correction and downscaling algorithms, which are specifically designed to accurately represent changes in the extremes. For this reason, we selected Quantile Delta Mapping (QDM), following the method introduced by [Cannon et al. (2015)](https://doi.org/10.1175/JCLI-D-14-00754.1), which preserves quantile-specific trends from the GCM while fitting the full distribution for a given day-of-year to a reference dataset (ERA5). We then introduce a similar method tailored to increase spatial resolution while preserving extreme behavior, Quantile-Preserving Localized-Analog Downscaling (QPLAD). Together, these methods provide a robust means to handle both the central and tail behavior seen in climate model output, while aligning the full distribution to a state-of-the-art reanalysis dataset and providing the spatial granularity needed to study surface impacts. For further documentation, see [Global downscaled projections for climate impacts research (GDPCIR): preserving extremes for modeling future climate impacts](https://egusphere.copernicus.org/preprints/2023/egusphere-2022-1513/) (EGUsphere, 2022 [preprint]). ## Citing, licensing, and using data produced by this project Projects making use of the data produced as part of the Climate Impact Lab Global Downscaled Projections for Climate Impacts Research (CIL GDPCIR) project are requested to cite both this project and the source datasets from which these results are derived. Additionally, the use of data derived from some GCMs *requires* citations, and some modeling centers impose licensing restrictions & requirements on derived works. See each GCM's license info in the links below for more information. ### CIL GDPCIR Users are requested to cite this project in derived works. Our method documentation paper may be cited using the following: > Gergel, D. R., Malevich, S. B., McCusker, K. E., Tenezakis, E., Delgado, M. T., Fish, M. A., and Kopp, R. E.: Global downscaled projections for climate impacts research (GDPCIR): preserving extremes for modeling future climate impacts, EGUsphere [preprint], https://doi.org/10.5194/egusphere-2022-1513, 2023. The code repository may be cited using the following: > Diana Gergel, Kelly McCusker, Brewster Malevich, Emile Tenezakis, Meredith Fish, Michael Delgado (2022). ClimateImpactLab/downscaleCMIP6: (v1.0.0). Zenodo. https://doi.org/10.5281/zenodo.6403794 ### ERA5 Additionally, we request you cite the historical dataset used in bias correction and downscaling, ERA5. See the [ECMWF guide to citing a dataset on the Climate Data Store](https://confluence.ecmwf.int/display/CKB/How+to+acknowledge+and+cite+a+Climate+Data+Store+%28CDS%29+catalogue+entry+and+the+data+published+as+part+of+it): > Hersbach, H, et al. The ERA5 global reanalysis. Q J R Meteorol Soc.2020; 146: 1999–2049. DOI: [10.1002/qj.3803](https://doi.org/10.1002/qj.3803) > > Muñoz Sabater, J., (2019): ERA5-Land hourly data from 1981 to present. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). (Accessed on June 4, 2021), DOI: [10.24381/cds.e2161bac](https://doi.org/10.24381/cds.e2161bac) > > Muñoz Sabater, J., (2021): ERA5-Land hourly data from 1950 to 1980. Copernicus Climate Change Service (C3S) Climate Data Store (CDS). (Accessed on June 4, 2021), DOI: [10.24381/cds.e2161bac](https://doi.org/10.24381/cds.e2161bac) ### GCM-specific citations & licenses The CMIP6 simulation data made available through the Earth System Grid Federation (ESGF) are subject to Creative Commons [BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/) or [BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) licenses. The Climate Impact Lab has reached out to each of the modeling institutions to request waivers from these terms so the outputs of this project may be used with fewer restrictions, and has been granted permission to release the data using the licenses listed here. #### Public Domain Datasets The following bias corrected and downscaled model simulations are available in the public domain using a [CC0 1.0 Universal Public Domain Declaration](https://creativecommons.org/publicdomain/zero/1.0/). Access the collection on Planetary Computer at https://planetarycomputer.microsoft.com/dataset/cil-gdpcir-cc0. * **FGOALS-g3** License description: [data_licenses/FGOALS-g3.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/FGOALS-g3.txt) CMIP Citation: > Li, Lijuan **(2019)**. *CAS FGOALS-g3 model output prepared for CMIP6 CMIP*. Version 20190826. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1783 ScenarioMIP Citation: > Li, Lijuan **(2019)**. *CAS FGOALS-g3 model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20190818; SSP2-4.5 version 20190818; SSP3-7.0 version 20190820; SSP5-8.5 tasmax version 20190819; SSP5-8.5 tasmin version 20190819; SSP5-8.5 pr version 20190818. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2056 * **INM-CM4-8** License description: [data_licenses/INM-CM4-8.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/INM-CM4-8.txt) CMIP Citation: > Volodin, Evgeny; Mortikov, Evgeny; Gritsun, Andrey; Lykossov, Vasily; Galin, Vener; Diansky, Nikolay; Gusev, Anatoly; Kostrykin, Sergey; Iakovlev, Nikolay; Shestakova, Anna; Emelina, Svetlana **(2019)**. *INM INM-CM4-8 model output prepared for CMIP6 CMIP*. Version 20190530. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1422 ScenarioMIP Citation: > Volodin, Evgeny; Mortikov, Evgeny; Gritsun, Andrey; Lykossov, Vasily; Galin, Vener; Diansky, Nikolay; Gusev, Anatoly; Kostrykin, Sergey; Iakovlev, Nikolay; Shestakova, Anna; Emelina, Svetlana **(2019)**. *INM INM-CM4-8 model output prepared for CMIP6 ScenarioMIP*. Version 20190603. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.12321 * **INM-CM5-0** License description: [data_licenses/INM-CM5-0.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/INM-CM5-0.txt) CMIP Citation: > Volodin, Evgeny; Mortikov, Evgeny; Gritsun, Andrey; Lykossov, Vasily; Galin, Vener; Diansky, Nikolay; Gusev, Anatoly; Kostrykin, Sergey; Iakovlev, Nikolay; Shestakova, Anna; Emelina, Svetlana **(2019)**. *INM INM-CM5-0 model output prepared for CMIP6 CMIP*. Version 20190610. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1423 ScenarioMIP Citation: > Volodin, Evgeny; Mortikov, Evgeny; Gritsun, Andrey; Lykossov, Vasily; Galin, Vener; Diansky, Nikolay; Gusev, Anatoly; Kostrykin, Sergey; Iakovlev, Nikolay; Shestakova, Anna; Emelina, Svetlana **(2019)**. *INM INM-CM5-0 model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20190619; SSP2-4.5 version 20190619; SSP3-7.0 version 20190618; SSP5-8.5 version 20190724. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.12322 #### CC-BY-4.0 The following bias corrected and downscaled model simulations are licensed under a [Creative Commons Attribution 4.0 International License](https://creativecommons.org/licenses/by/4.0/). Note that this license requires citation of the source model output (included here). Please see https://creativecommons.org/licenses/by/4.0/ for more information. Access the collection on Planetary Computer at https://planetarycomputer.microsoft.com/dataset/cil-gdpcir-cc-by. * **ACCESS-CM2** License description: [data_licenses/ACCESS-CM2.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/ACCESS-CM2.txt) CMIP Citation: > Dix, Martin; Bi, Doahua; Dobrohotoff, Peter; Fiedler, Russell; Harman, Ian; Law, Rachel; Mackallah, Chloe; Marsland, Simon; O'Farrell, Siobhan; Rashid, Harun; Srbinovsky, Jhan; Sullivan, Arnold; Trenham, Claire; Vohralik, Peter; Watterson, Ian; Williams, Gareth; Woodhouse, Matthew; Bodman, Roger; Dias, Fabio Boeira; Domingues, Catia; Hannah, Nicholas; Heerdegen, Aidan; Savita, Abhishek; Wales, Scott; Allen, Chris; Druken, Kelsey; Evans, Ben; Richards, Clare; Ridzwan, Syazwan Mohamed; Roberts, Dale; Smillie, Jon; Snow, Kate; Ward, Marshall; Yang, Rui **(2019)**. *CSIRO-ARCCSS ACCESS-CM2 model output prepared for CMIP6 CMIP*. Version 20191108. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2281 ScenarioMIP Citation: > Dix, Martin; Bi, Doahua; Dobrohotoff, Peter; Fiedler, Russell; Harman, Ian; Law, Rachel; Mackallah, Chloe; Marsland, Simon; O'Farrell, Siobhan; Rashid, Harun; Srbinovsky, Jhan; Sullivan, Arnold; Trenham, Claire; Vohralik, Peter; Watterson, Ian; Williams, Gareth; Woodhouse, Matthew; Bodman, Roger; Dias, Fabio Boeira; Domingues, Catia; Hannah, Nicholas; Heerdegen, Aidan; Savita, Abhishek; Wales, Scott; Allen, Chris; Druken, Kelsey; Evans, Ben; Richards, Clare; Ridzwan, Syazwan Mohamed; Roberts, Dale; Smillie, Jon; Snow, Kate; Ward, Marshall; Yang, Rui **(2019)**. *CSIRO-ARCCSS ACCESS-CM2 model output prepared for CMIP6 ScenarioMIP*. Version 20191108. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2285 * **ACCESS-ESM1-5** License description: [data_licenses/ACCESS-ESM1-5.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/ACCESS-ESM1-5.txt) CMIP Citation: > Ziehn, Tilo; Chamberlain, Matthew; Lenton, Andrew; Law, Rachel; Bodman, Roger; Dix, Martin; Wang, Yingping; Dobrohotoff, Peter; Srbinovsky, Jhan; Stevens, Lauren; Vohralik, Peter; Mackallah, Chloe; Sullivan, Arnold; O'Farrell, Siobhan; Druken, Kelsey **(2019)**. *CSIRO ACCESS-ESM1.5 model output prepared for CMIP6 CMIP*. Version 20191115. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2288 ScenarioMIP Citation: > Ziehn, Tilo; Chamberlain, Matthew; Lenton, Andrew; Law, Rachel; Bodman, Roger; Dix, Martin; Wang, Yingping; Dobrohotoff, Peter; Srbinovsky, Jhan; Stevens, Lauren; Vohralik, Peter; Mackallah, Chloe; Sullivan, Arnold; O'Farrell, Siobhan; Druken, Kelsey **(2019)**. *CSIRO ACCESS-ESM1.5 model output prepared for CMIP6 ScenarioMIP*. Version 20191115. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2291 * **BCC-CSM2-MR** License description: [data_licenses/BCC-CSM2-MR.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/BCC-CSM2-MR.txt) CMIP Citation: > Xin, Xiaoge; Zhang, Jie; Zhang, Fang; Wu, Tongwen; Shi, Xueli; Li, Jianglong; Chu, Min; Liu, Qianxia; Yan, Jinghui; Ma, Qiang; Wei, Min **(2018)**. *BCC BCC-CSM2MR model output prepared for CMIP6 CMIP*. Version 20181126. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1725 ScenarioMIP Citation: > Xin, Xiaoge; Wu, Tongwen; Shi, Xueli; Zhang, Fang; Li, Jianglong; Chu, Min; Liu, Qianxia; Yan, Jinghui; Ma, Qiang; Wei, Min **(2019)**. *BCC BCC-CSM2MR model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20190315; SSP2-4.5 version 20190318; SSP3-7.0 version 20190318; SSP5-8.5 version 20190318. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1732 * **CMCC-CM2-SR5** License description: [data_licenses/CMCC-CM2-SR5.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/CMCC-CM2-SR5.txt) CMIP Citation: > Lovato, Tomas; Peano, Daniele **(2020)**. *CMCC CMCC-CM2-SR5 model output prepared for CMIP6 CMIP*. Version 20200616. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1362 ScenarioMIP Citation: > Lovato, Tomas; Peano, Daniele **(2020)**. *CMCC CMCC-CM2-SR5 model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20200717; SSP2-4.5 version 20200617; SSP3-7.0 version 20200622; SSP5-8.5 version 20200622. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1365 * **CMCC-ESM2** License description: [data_licenses/CMCC-ESM2.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/CMCC-ESM2.txt) CMIP Citation: > Lovato, Tomas; Peano, Daniele; Butenschön, Momme **(2021)**. *CMCC CMCC-ESM2 model output prepared for CMIP6 CMIP*. Version 20210114. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.13164 ScenarioMIP Citation: > Lovato, Tomas; Peano, Daniele; Butenschön, Momme **(2021)**. *CMCC CMCC-ESM2 model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20210126; SSP2-4.5 version 20210129; SSP3-7.0 version 20210202; SSP5-8.5 version 20210126. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.13168 * **EC-Earth3-AerChem** License description: [data_licenses/EC-Earth3-AerChem.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/EC-Earth3-AerChem.txt) CMIP Citation: > EC-Earth Consortium (EC-Earth) **(2020)**. *EC-Earth-Consortium EC-Earth3-AerChem model output prepared for CMIP6 CMIP*. Version 20200624. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.639 ScenarioMIP Citation: > EC-Earth Consortium (EC-Earth) **(2020)**. *EC-Earth-Consortium EC-Earth3-AerChem model output prepared for CMIP6 ScenarioMIP*. Version 20200827. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.724 * **EC-Earth3-CC** License description: [data_licenses/EC-Earth3-CC.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/EC-Earth3-CC.txt) CMIP Citation: > EC-Earth Consortium (EC-Earth) **(2020)**. *EC-Earth-Consortium EC-Earth-3-CC model output prepared for CMIP6 CMIP*. Version 20210113. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.640 ScenarioMIP Citation: > EC-Earth Consortium (EC-Earth) **(2021)**. *EC-Earth-Consortium EC-Earth3-CC model output prepared for CMIP6 ScenarioMIP*. Version 20210113. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.15327 * **EC-Earth3-Veg-LR** License description: [data_licenses/EC-Earth3-Veg-LR.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/EC-Earth3-Veg-LR.txt) CMIP Citation: > EC-Earth Consortium (EC-Earth) **(2020)**. *EC-Earth-Consortium EC-Earth3-Veg-LR model output prepared for CMIP6 CMIP*. Version 20200217. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.643 ScenarioMIP Citation: > EC-Earth Consortium (EC-Earth) **(2020)**. *EC-Earth-Consortium EC-Earth3-Veg-LR model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20201201; SSP2-4.5 version 20201123; SSP3-7.0 version 20201123; SSP5-8.5 version 20201201. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.728 * **EC-Earth3-Veg** License description: [data_licenses/EC-Earth3-Veg.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/EC-Earth3-Veg.txt) CMIP Citation: > EC-Earth Consortium (EC-Earth) **(2019)**. *EC-Earth-Consortium EC-Earth3-Veg model output prepared for CMIP6 CMIP*. Version 20200225. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.642 ScenarioMIP Citation: > EC-Earth Consortium (EC-Earth) **(2019)**. *EC-Earth-Consortium EC-Earth3-Veg model output prepared for CMIP6 ScenarioMIP*. Version 20200225. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.727 * **EC-Earth3** License description: [data_licenses/EC-Earth3.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/EC-Earth3.txt) CMIP Citation: > EC-Earth Consortium (EC-Earth) **(2019)**. *EC-Earth-Consortium EC-Earth3 model output prepared for CMIP6 CMIP*. Version 20200310. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.181 ScenarioMIP Citation: > EC-Earth Consortium (EC-Earth) **(2019)**. *EC-Earth-Consortium EC-Earth3 model output prepared for CMIP6 ScenarioMIP*. Version 20200310. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.251 * **GFDL-CM4** License description: [data_licenses/GFDL-CM4.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/GFDL-CM4.txt) CMIP Citation: > Guo, Huan; John, Jasmin G; Blanton, Chris; McHugh, Colleen; Nikonov, Serguei; Radhakrishnan, Aparna; Rand, Kristopher; Zadeh, Niki T.; Balaji, V; Durachta, Jeff; Dupuis, Christopher; Menzel, Raymond; Robinson, Thomas; Underwood, Seth; Vahlenkamp, Hans; Bushuk, Mitchell; Dunne, Krista A.; Dussin, Raphael; Gauthier, Paul PG; Ginoux, Paul; Griffies, Stephen M.; Hallberg, Robert; Harrison, Matthew; Hurlin, William; Lin, Pu; Malyshev, Sergey; Naik, Vaishali; Paulot, Fabien; Paynter, David J; Ploshay, Jeffrey; Reichl, Brandon G; Schwarzkopf, Daniel M; Seman, Charles J; Shao, Andrew; Silvers, Levi; Wyman, Bruce; Yan, Xiaoqin; Zeng, Yujin; Adcroft, Alistair; Dunne, John P.; Held, Isaac M; Krasting, John P.; Horowitz, Larry W.; Milly, P.C.D; Shevliakova, Elena; Winton, Michael; Zhao, Ming; Zhang, Rong **(2018)**. *NOAA-GFDL GFDL-CM4 model output*. Version 20180701. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1402 ScenarioMIP Citation: > Guo, Huan; John, Jasmin G; Blanton, Chris; McHugh, Colleen; Nikonov, Serguei; Radhakrishnan, Aparna; Rand, Kristopher; Zadeh, Niki T.; Balaji, V; Durachta, Jeff; Dupuis, Christopher; Menzel, Raymond; Robinson, Thomas; Underwood, Seth; Vahlenkamp, Hans; Dunne, Krista A.; Gauthier, Paul PG; Ginoux, Paul; Griffies, Stephen M.; Hallberg, Robert; Harrison, Matthew; Hurlin, William; Lin, Pu; Malyshev, Sergey; Naik, Vaishali; Paulot, Fabien; Paynter, David J; Ploshay, Jeffrey; Schwarzkopf, Daniel M; Seman, Charles J; Shao, Andrew; Silvers, Levi; Wyman, Bruce; Yan, Xiaoqin; Zeng, Yujin; Adcroft, Alistair; Dunne, John P.; Held, Isaac M; Krasting, John P.; Horowitz, Larry W.; Milly, Chris; Shevliakova, Elena; Winton, Michael; Zhao, Ming; Zhang, Rong **(2018)**. *NOAA-GFDL GFDL-CM4 model output prepared for CMIP6 ScenarioMIP*. Version 20180701. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.9242 * **GFDL-ESM4** License description: [data_licenses/GFDL-ESM4.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/GFDL-ESM4.txt) CMIP Citation: > Krasting, John P.; John, Jasmin G; Blanton, Chris; McHugh, Colleen; Nikonov, Serguei; Radhakrishnan, Aparna; Rand, Kristopher; Zadeh, Niki T.; Balaji, V; Durachta, Jeff; Dupuis, Christopher; Menzel, Raymond; Robinson, Thomas; Underwood, Seth; Vahlenkamp, Hans; Dunne, Krista A.; Gauthier, Paul PG; Ginoux, Paul; Griffies, Stephen M.; Hallberg, Robert; Harrison, Matthew; Hurlin, William; Malyshev, Sergey; Naik, Vaishali; Paulot, Fabien; Paynter, David J; Ploshay, Jeffrey; Reichl, Brandon G; Schwarzkopf, Daniel M; Seman, Charles J; Silvers, Levi; Wyman, Bruce; Zeng, Yujin; Adcroft, Alistair; Dunne, John P.; Dussin, Raphael; Guo, Huan; He, Jian; Held, Isaac M; Horowitz, Larry W.; Lin, Pu; Milly, P.C.D; Shevliakova, Elena; Stock, Charles; Winton, Michael; Wittenberg, Andrew T.; Xie, Yuanyu; Zhao, Ming **(2018)**. *NOAA-GFDL GFDL-ESM4 model output prepared for CMIP6 CMIP*. Version 20190726. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1407 ScenarioMIP Citation: > John, Jasmin G; Blanton, Chris; McHugh, Colleen; Radhakrishnan, Aparna; Rand, Kristopher; Vahlenkamp, Hans; Wilson, Chandin; Zadeh, Niki T.; Dunne, John P.; Dussin, Raphael; Horowitz, Larry W.; Krasting, John P.; Lin, Pu; Malyshev, Sergey; Naik, Vaishali; Ploshay, Jeffrey; Shevliakova, Elena; Silvers, Levi; Stock, Charles; Winton, Michael; Zeng, Yujin **(2018)**. *NOAA-GFDL GFDL-ESM4 model output prepared for CMIP6 ScenarioMIP*. Version 20180701. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1414 * **HadGEM3-GC31-LL** License description: [data_licenses/HadGEM3-GC31-LL.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/HadGEM3-GC31-LL.txt) CMIP Citation: > Ridley, Jeff; Menary, Matthew; Kuhlbrodt, Till; Andrews, Martin; Andrews, Tim **(2018)**. *MOHC HadGEM3-GC31-LL model output prepared for CMIP6 CMIP*. Version 20190624. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.419 ScenarioMIP Citation: > Good, Peter **(2019)**. *MOHC HadGEM3-GC31-LL model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20200114; SSP2-4.5 version 20190908; SSP5-8.5 version 20200114. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.10845 * **MIROC-ES2L** License description: [data_licenses/MIROC-ES2L.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/MIROC-ES2L.txt) CMIP Citation: > Hajima, Tomohiro; Abe, Manabu; Arakawa, Osamu; Suzuki, Tatsuo; Komuro, Yoshiki; Ogura, Tomoo; Ogochi, Koji; Watanabe, Michio; Yamamoto, Akitomo; Tatebe, Hiroaki; Noguchi, Maki A.; Ohgaito, Rumi; Ito, Akinori; Yamazaki, Dai; Ito, Akihiko; Takata, Kumiko; Watanabe, Shingo; Kawamiya, Michio; Tachiiri, Kaoru **(2019)**. *MIROC MIROC-ES2L model output prepared for CMIP6 CMIP*. Version 20191129. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.902 ScenarioMIP Citation: > Tachiiri, Kaoru; Abe, Manabu; Hajima, Tomohiro; Arakawa, Osamu; Suzuki, Tatsuo; Komuro, Yoshiki; Ogochi, Koji; Watanabe, Michio; Yamamoto, Akitomo; Tatebe, Hiroaki; Noguchi, Maki A.; Ohgaito, Rumi; Ito, Akinori; Yamazaki, Dai; Ito, Akihiko; Takata, Kumiko; Watanabe, Shingo; Kawamiya, Michio **(2019)**. *MIROC MIROC-ES2L model output prepared for CMIP6 ScenarioMIP*. Version 20200318. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.936 * **MIROC6** License description: [data_licenses/MIROC6.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/MIROC6.txt) CMIP Citation: > Tatebe, Hiroaki; Watanabe, Masahiro **(2018)**. *MIROC MIROC6 model output prepared for CMIP6 CMIP*. Version 20191016. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.881 ScenarioMIP Citation: > Shiogama, Hideo; Abe, Manabu; Tatebe, Hiroaki **(2019)**. *MIROC MIROC6 model output prepared for CMIP6 ScenarioMIP*. Version 20191016. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.898 * **MPI-ESM1-2-HR** License description: [data_licenses/MPI-ESM1-2-HR.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/MPI-ESM1-2-HR.txt) CMIP Citation: > Jungclaus, Johann; Bittner, Matthias; Wieners, Karl-Hermann; Wachsmann, Fabian; Schupfner, Martin; Legutke, Stephanie; Giorgetta, Marco; Reick, Christian; Gayler, Veronika; Haak, Helmuth; de Vrese, Philipp; Raddatz, Thomas; Esch, Monika; Mauritsen, Thorsten; von Storch, Jin-Song; Behrens, Jörg; Brovkin, Victor; Claussen, Martin; Crueger, Traute; Fast, Irina; Fiedler, Stephanie; Hagemann, Stefan; Hohenegger, Cathy; Jahns, Thomas; Kloster, Silvia; Kinne, Stefan; Lasslop, Gitta; Kornblueh, Luis; Marotzke, Jochem; Matei, Daniela; Meraner, Katharina; Mikolajewicz, Uwe; Modali, Kameswarrao; Müller, Wolfgang; Nabel, Julia; Notz, Dirk; Peters-von Gehlen, Karsten; Pincus, Robert; Pohlmann, Holger; Pongratz, Julia; Rast, Sebastian; Schmidt, Hauke; Schnur, Reiner; Schulzweida, Uwe; Six, Katharina; Stevens, Bjorn; Voigt, Aiko; Roeckner, Erich **(2019)**. *MPI-M MPIESM1.2-HR model output prepared for CMIP6 CMIP*. Version 20190710. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.741 ScenarioMIP Citation: > Schupfner, Martin; Wieners, Karl-Hermann; Wachsmann, Fabian; Steger, Christian; Bittner, Matthias; Jungclaus, Johann; Früh, Barbara; Pankatz, Klaus; Giorgetta, Marco; Reick, Christian; Legutke, Stephanie; Esch, Monika; Gayler, Veronika; Haak, Helmuth; de Vrese, Philipp; Raddatz, Thomas; Mauritsen, Thorsten; von Storch, Jin-Song; Behrens, Jörg; Brovkin, Victor; Claussen, Martin; Crueger, Traute; Fast, Irina; Fiedler, Stephanie; Hagemann, Stefan; Hohenegger, Cathy; Jahns, Thomas; Kloster, Silvia; Kinne, Stefan; Lasslop, Gitta; Kornblueh, Luis; Marotzke, Jochem; Matei, Daniela; Meraner, Katharina; Mikolajewicz, Uwe; Modali, Kameswarrao; Müller, Wolfgang; Nabel, Julia; Notz, Dirk; Peters-von Gehlen, Karsten; Pincus, Robert; Pohlmann, Holger; Pongratz, Julia; Rast, Sebastian; Schmidt, Hauke; Schnur, Reiner; Schulzweida, Uwe; Six, Katharina; Stevens, Bjorn; Voigt, Aiko; Roeckner, Erich **(2019)**. *DKRZ MPI-ESM1.2-HR model output prepared for CMIP6 ScenarioMIP*. Version 20190710. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2450 * **MPI-ESM1-2-LR** License description: [data_licenses/MPI-ESM1-2-LR.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/MPI-ESM1-2-LR.txt) CMIP Citation: > Wieners, Karl-Hermann; Giorgetta, Marco; Jungclaus, Johann; Reick, Christian; Esch, Monika; Bittner, Matthias; Legutke, Stephanie; Schupfner, Martin; Wachsmann, Fabian; Gayler, Veronika; Haak, Helmuth; de Vrese, Philipp; Raddatz, Thomas; Mauritsen, Thorsten; von Storch, Jin-Song; Behrens, Jörg; Brovkin, Victor; Claussen, Martin; Crueger, Traute; Fast, Irina; Fiedler, Stephanie; Hagemann, Stefan; Hohenegger, Cathy; Jahns, Thomas; Kloster, Silvia; Kinne, Stefan; Lasslop, Gitta; Kornblueh, Luis; Marotzke, Jochem; Matei, Daniela; Meraner, Katharina; Mikolajewicz, Uwe; Modali, Kameswarrao; Müller, Wolfgang; Nabel, Julia; Notz, Dirk; Peters-von Gehlen, Karsten; Pincus, Robert; Pohlmann, Holger; Pongratz, Julia; Rast, Sebastian; Schmidt, Hauke; Schnur, Reiner; Schulzweida, Uwe; Six, Katharina; Stevens, Bjorn; Voigt, Aiko; Roeckner, Erich **(2019)**. *MPI-M MPIESM1.2-LR model output prepared for CMIP6 CMIP*. Version 20190710. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.742 ScenarioMIP Citation: > Wieners, Karl-Hermann; Giorgetta, Marco; Jungclaus, Johann; Reick, Christian; Esch, Monika; Bittner, Matthias; Gayler, Veronika; Haak, Helmuth; de Vrese, Philipp; Raddatz, Thomas; Mauritsen, Thorsten; von Storch, Jin-Song; Behrens, Jörg; Brovkin, Victor; Claussen, Martin; Crueger, Traute; Fast, Irina; Fiedler, Stephanie; Hagemann, Stefan; Hohenegger, Cathy; Jahns, Thomas; Kloster, Silvia; Kinne, Stefan; Lasslop, Gitta; Kornblueh, Luis; Marotzke, Jochem; Matei, Daniela; Meraner, Katharina; Mikolajewicz, Uwe; Modali, Kameswarrao; Müller, Wolfgang; Nabel, Julia; Notz, Dirk; Peters-von Gehlen, Karsten; Pincus, Robert; Pohlmann, Holger; Pongratz, Julia; Rast, Sebastian; Schmidt, Hauke; Schnur, Reiner; Schulzweida, Uwe; Six, Katharina; Stevens, Bjorn; Voigt, Aiko; Roeckner, Erich **(2019)**. *MPI-M MPIESM1.2-LR model output prepared for CMIP6 ScenarioMIP*. Version 20190710. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.793 * **NESM3** License description: [data_licenses/NESM3.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/NESM3.txt) CMIP Citation: > Cao, Jian; Wang, Bin **(2019)**. *NUIST NESMv3 model output prepared for CMIP6 CMIP*. Version 20190812. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2021 ScenarioMIP Citation: > Cao, Jian **(2019)**. *NUIST NESMv3 model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20190806; SSP2-4.5 version 20190805; SSP5-8.5 version 20190811. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.2027 * **NorESM2-LM** License description: [data_licenses/NorESM2-LM.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/NorESM2-LM.txt) CMIP Citation: > Seland, Øyvind; Bentsen, Mats; Oliviè, Dirk Jan Leo; Toniazzo, Thomas; Gjermundsen, Ada; Graff, Lise Seland; Debernard, Jens Boldingh; Gupta, Alok Kumar; He, Yanchun; Kirkevåg, Alf; Schwinger, Jörg; Tjiputra, Jerry; Aas, Kjetil Schanke; Bethke, Ingo; Fan, Yuanchao; Griesfeller, Jan; Grini, Alf; Guo, Chuncheng; Ilicak, Mehmet; Karset, Inger Helene Hafsahl; Landgren, Oskar Andreas; Liakka, Johan; Moseid, Kine Onsum; Nummelin, Aleksi; Spensberger, Clemens; Tang, Hui; Zhang, Zhongshi; Heinze, Christoph; Iversen, Trond; Schulz, Michael **(2019)**. *NCC NorESM2-LM model output prepared for CMIP6 CMIP*. Version 20190815. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.502 ScenarioMIP Citation: > Seland, Øyvind; Bentsen, Mats; Oliviè, Dirk Jan Leo; Toniazzo, Thomas; Gjermundsen, Ada; Graff, Lise Seland; Debernard, Jens Boldingh; Gupta, Alok Kumar; He, Yanchun; Kirkevåg, Alf; Schwinger, Jörg; Tjiputra, Jerry; Aas, Kjetil Schanke; Bethke, Ingo; Fan, Yuanchao; Griesfeller, Jan; Grini, Alf; Guo, Chuncheng; Ilicak, Mehmet; Karset, Inger Helene Hafsahl; Landgren, Oskar Andreas; Liakka, Johan; Moseid, Kine Onsum; Nummelin, Aleksi; Spensberger, Clemens; Tang, Hui; Zhang, Zhongshi; Heinze, Christoph; Iversen, Trond; Schulz, Michael **(2019)**. *NCC NorESM2-LM model output prepared for CMIP6 ScenarioMIP*. Version 20191108. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.604 * **NorESM2-MM** License description: [data_licenses/NorESM2-MM.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/NorESM2-MM.txt) CMIP Citation: > Bentsen, Mats; Oliviè, Dirk Jan Leo; Seland, Øyvind; Toniazzo, Thomas; Gjermundsen, Ada; Graff, Lise Seland; Debernard, Jens Boldingh; Gupta, Alok Kumar; He, Yanchun; Kirkevåg, Alf; Schwinger, Jörg; Tjiputra, Jerry; Aas, Kjetil Schanke; Bethke, Ingo; Fan, Yuanchao; Griesfeller, Jan; Grini, Alf; Guo, Chuncheng; Ilicak, Mehmet; Karset, Inger Helene Hafsahl; Landgren, Oskar Andreas; Liakka, Johan; Moseid, Kine Onsum; Nummelin, Aleksi; Spensberger, Clemens; Tang, Hui; Zhang, Zhongshi; Heinze, Christoph; Iversen, Trond; Schulz, Michael **(2019)**. *NCC NorESM2-MM model output prepared for CMIP6 CMIP*. Version 20191108. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.506 ScenarioMIP Citation: > Bentsen, Mats; Oliviè, Dirk Jan Leo; Seland, Øyvind; Toniazzo, Thomas; Gjermundsen, Ada; Graff, Lise Seland; Debernard, Jens Boldingh; Gupta, Alok Kumar; He, Yanchun; Kirkevåg, Alf; Schwinger, Jörg; Tjiputra, Jerry; Aas, Kjetil Schanke; Bethke, Ingo; Fan, Yuanchao; Griesfeller, Jan; Grini, Alf; Guo, Chuncheng; Ilicak, Mehmet; Karset, Inger Helene Hafsahl; Landgren, Oskar Andreas; Liakka, Johan; Moseid, Kine Onsum; Nummelin, Aleksi; Spensberger, Clemens; Tang, Hui; Zhang, Zhongshi; Heinze, Christoph; Iversen, Trond; Schulz, Michael **(2019)**. *NCC NorESM2-MM model output prepared for CMIP6 ScenarioMIP*. Version 20191108. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.608 * **UKESM1-0-LL** License description: [data_licenses/UKESM1-0-LL.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/UKESM1-0-LL.txt) CMIP Citation: > Tang, Yongming; Rumbold, Steve; Ellis, Rich; Kelley, Douglas; Mulcahy, Jane; Sellar, Alistair; Walton, Jeremy; Jones, Colin **(2019)**. *MOHC UKESM1.0-LL model output prepared for CMIP6 CMIP*. Version 20190627. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1569 ScenarioMIP Citation: > Good, Peter; Sellar, Alistair; Tang, Yongming; Rumbold, Steve; Ellis, Rich; Kelley, Douglas; Kuhlbrodt, Till; Walton, Jeremy **(2019)**. *MOHC UKESM1.0-LL model output prepared for CMIP6 ScenarioMIP*. SSP1-2.6 version 20190708; SSP2-4.5 version 20190715; SSP3-7.0 version 20190726; SSP5-8.5 version 20190726. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1567 * **CanESM5** License description: [data_licenses/CanESM5.txt](https://raw.githubusercontent.com/ClimateImpactLab/downscaleCMIP6/master/data_licenses/CanESM5.txt). Note: this dataset was previously licensed under CC BY-SA 4.0, but was relicensed as CC BY 4.0 in March, 2023. CMIP Citation: > Swart, Neil Cameron; Cole, Jason N.S.; Kharin, Viatcheslav V.; Lazare, Mike; Scinocca, John F.; Gillett, Nathan P.; Anstey, James; Arora, Vivek; Christian, James R.; Jiao, Yanjun; Lee, Warren G.; Majaess, Fouad; Saenko, Oleg A.; Seiler, Christian; Seinen, Clint; Shao, Andrew; Solheim, Larry; von Salzen, Knut; Yang, Duo; Winter, Barbara; Sigmond, Michael **(2019)**. *CCCma CanESM5 model output prepared for CMIP6 CMIP*. Version 20190429. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1303 ScenarioMIP Citation: > Swart, Neil Cameron; Cole, Jason N.S.; Kharin, Viatcheslav V.; Lazare, Mike; Scinocca, John F.; Gillett, Nathan P.; Anstey, James; Arora, Vivek; Christian, James R.; Jiao, Yanjun; Lee, Warren G.; Majaess, Fouad; Saenko, Oleg A.; Seiler, Christian; Seinen, Clint; Shao, Andrew; Solheim, Larry; von Salzen, Knut; Yang, Duo; Winter, Barbara; Sigmond, Michael **(2019)**. *CCCma CanESM5 model output prepared for CMIP6 ScenarioMIP*. Version 20190429. Earth System Grid Federation. https://doi.org/10.22033/ESGF/CMIP6.1317 ## Acknowledgements This work is the result of many years worth of work by members of the [Climate Impact Lab](https://impactlab.org), but would not have been possible without many contributions from across the wider scientific and computing communities. Specifically, we would like to acknowledge the World Climate Research Programme's Working Group on Coupled Modeling, which is responsible for CMIP, and we would like to thank the climate modeling groups for producing and making their model output available. We would particularly like to thank the modeling institutions whose results are included as an input to this repository (listed above) for their contributions to the CMIP6 project and for responding to and granting our requests for license waivers. We would also like to thank Lamont-Doherty Earth Observatory, the [Pangeo Consortium](https://github.com/pangeo-data) (and especially the [ESGF Cloud Data Working Group](https://pangeo-data.github.io/pangeo-cmip6-cloud/#)) and Google Cloud and the Google Public Datasets program for making the [CMIP6 Google Cloud collection](https://console.cloud.google.com/marketplace/details/noaa-public/cmip6) possible. In particular we're extremely grateful to [Ryan Abernathey](https://github.com/rabernat), [Naomi Henderson](https://github.com/naomi-henderson), [Charles Blackmon-Luca](https://github.com/charlesbluca), [Aparna Radhakrishnan](https://github.com/aradhakrishnanGFDL), [Julius Busecke](https://github.com/jbusecke), and [Charles Stern](https://github.com/cisaacstern) for the huge amount of work they've done to translate the ESGF CMIP6 netCDF archives into consistently-formattted, analysis-ready zarr stores on Google Cloud. We're also grateful to the [xclim developers](https://github.com/Ouranosinc/xclim/graphs/contributors) ([DOI: 10.5281/zenodo.2795043](https://doi.org/10.5281/zenodo.2795043)), in particular [Pascal Bourgault](https://github.com/aulemahal), [David Huard](https://github.com/huard), and [Travis Logan](https://github.com/tlogan2000), for implementing the QDM bias correction method in the xclim python package, supporting our QPLAD implementation into the package, and ongoing support in integrating dask into downscaling workflows. For method advice and useful conversations, we would like to thank Keith Dixon, Dennis Adams-Smith, and [Joe Hamman](https://github.com/jhamman). ## Financial support This research has been supported by The Rockefeller Foundation and the Microsoft AI for Earth Initiative. ## Additional links: * CIL GDPCIR project homepage: [github.com/ClimateImpactLab/downscaleCMIP6](https://github.com/ClimateImpactLab/downscaleCMIP6) * Project listing on zenodo: https://doi.org/10.5281/zenodo.6403794 * Climate Impact Lab homepage: [impactlab.org](https://impactlab.org)"
links [] 8 items
0
- rel "items"
- href "https://planetarycomputer.microsoft.com/api/stac/v1/collections/cil-gdpcir-cc0/items"
- type "application/geo+json"
1
- rel "parent"
- href "https://planetarycomputer.microsoft.com/api/stac/v1/"
- type "application/json"
2
- rel "root"
- href "https://planetarycomputer.microsoft.com/api/stac/v1/"
- type "application/json"
- title "Microsoft Planetary Computer STAC API"
3
- rel "self"
- href "https://planetarycomputer.microsoft.com/api/stac/v1/collections/cil-gdpcir-cc0"
- type "application/json"
4
- rel "license"
- href "https://spdx.org/licenses/CC0-1.0.html"
- type "text/html"
- title "Creative Commons Zero v1.0 Universal"
5
- rel "cite-as"
- href "https://zenodo.org/record/6403794"
- type "text/html"
6
- rel "describedby"
- href "https://github.com/ClimateImpactLab/downscaleCMIP6/"
- type "text/html"
- title "Project homepage"
7
- rel "describedby"
- href "https://planetarycomputer.microsoft.com/dataset/cil-gdpcir-cc0"
- type "text/html"
- title "Human readable dataset overview and reference"
stac_extensions [] 2 items
- 0 "https://stac-extensions.github.io/item-assets/v1.0.0/schema.json"
- 1 "https://stac-extensions.github.io/scientific/v1.0.0/schema.json"
- sci:doi "10.5194/egusphere-2022-1513"
item_assets
pr
- type "application/vnd+zarr"
roles [] 1 items
- 0 "data"
- title "Precipitation"
- description "Precipitation"
tasmax
- type "application/vnd+zarr"
roles [] 1 items
- 0 "data"
- title "Daily Maximum Near-Surface Air Temperature"
- description "Daily Maximum Near-Surface Air Temperature"
tasmin
- type "application/vnd+zarr"
roles [] 1 items
- 0 "data"
- title "Daily Minimum Near-Surface Air Temperature"
- description "Daily Minimum Near-Surface Air Temperature"
- msft:region "westeurope"
- msft:group_id "cil-gdpcir"
cube:variables
pr
- type "data"
- unit "mm day-1"
attrs
- units "mm day-1"
dimensions [] 3 items
- 0 "time"
- 1 "lat"
- 2 "lon"
tasmax
- type "data"
- unit "K"
attrs
- units "K"
- comment "maximum near-surface (usually, 2 meter) air temperature (add cell_method attribute 'time: max')"
- long_name "Daily Maximum Near-Surface Air Temperature"
- coordinates "height"
- cell_methods "area: mean time: maximum (interval: 5 minutes)"
- cell_measures "area: areacella"
- original_name "TREFHTMX"
- standard_name "air_temperature"
dimensions [] 3 items
- 0 "time"
- 1 "lat"
- 2 "lon"
- description "Daily Maximum Near-Surface Air Temperature"
tasmin
- type "data"
- unit "K"
attrs
- units "K"
- comment "minimum near-surface (usually, 2 meter) air temperature (add cell_method attribute 'time: min')"
- long_name "Daily Minimum Near-Surface Air Temperature"
- coordinates "height"
- cell_methods "area: mean time: minimum (interval: 5 minutes)"
- cell_measures "area: areacella"
- original_name "TREFHTMN"
- standard_name "air_temperature"
dimensions [] 3 items
- 0 "time"
- 1 "lat"
- 2 "lon"
- description "Daily Minimum Near-Surface Air Temperature"
- msft:container "cil-gdpcir"
cube:dimensions
lat
- axis "y"
- step 0.25
- type "spatial"
extent [] 2 items
- 0 -89.875
- 1 89.875
- reference_system "epsg:4326"
lon
- axis "x"
- step 0.25
- type "spatial"
extent [] 2 items
- 0 -179.875
- 1 179.875
- reference_system "epsg:4326"
time
- step "P1DT0H0M0S"
- type "temporal"
extent [] 2 items
- 0 "1950-01-01T12:00:00Z"
- 1 "2100-12-31T12:00:00Z"
- description "time"
- msft:storage_account "rhgeuwest"
- msft:short_description "Climate Impact Lab Global Downscaled Projections for Climate Impacts Research (CC0-1.0)"
- title "CIL Global Downscaled Projections for Climate Impacts Research (CC0-1.0)"
extent
spatial
bbox [] 1 items
0 [] 4 items
- 0 -180
- 1 -90
- 2 180
- 3 90
temporal
interval [] 1 items
0 [] 2 items
- 0 "1950-01-01T00:00:00Z"
- 1 "2100-12-31T00:00:00Z"
- license "CC0-1.0"
keywords [] 5 items
- 0 "CMIP6"
- 1 "Climate Impact Lab"
- 2 "Rhodium Group"
- 3 "Precipitation"
- 4 "Temperature"
providers [] 2 items
0
- name "Climate Impact Lab"
roles [] 1 items
- 0 "producer"
- url "https://impactlab.org/"
1
- name "Microsoft"
roles [] 1 items
- 0 "host"
- url "https://planetarycomputer.microsoft.com/"
summaries
cmip6:variable [] 3 items
- 0 "pr"
- 1 "tasmax"
- 2 "tasmin"
cmip6:source_id [] 3 items
- 0 "FGOALS-g3"
- 1 "INM-CM4-8"
- 2 "INM-CM5-0"
cmip6:experiment_id [] 5 items
- 0 "historical"
- 1 "ssp126"
- 2 "ssp245"
- 3 "ssp370"
- 4 "ssp585"
cmip6:institution_id [] 15 items
- 0 "BCC"
- 1 "CAS"
- 2 "CCCma"
- 3 "CMCC"
- 4 "CSIRO"
- 5 "CSIRO-ARCCSS"
- 6 "DKRZ"
- 7 "EC-Earth-Consortium"
- 8 "INM"
- 9 "MIROC"
- 10 "MOHC"
- 11 "MPI-M"
- 12 "NCC"
- 13 "NOAA-GFDL"
- 14 "NUIST"
assets
thumbnail
- href "https://ai4edatasetspublicassets.blob.core.windows.net/assets/pc_thumbnails/gdpcir.png"
- type "image/png"
- title "Thumbnail"
collection_cc0.summaries.to_dict()
{'cmip6:variable': ['pr', 'tasmax', 'tasmin'],
'cmip6:source_id': ['FGOALS-g3', 'INM-CM4-8', 'INM-CM5-0'],
'cmip6:experiment_id': ['historical', 'ssp126', 'ssp245', 'ssp370', 'ssp585'],
'cmip6:institution_id': ['BCC',
'CAS',
'CCCma',
'CMCC',
'CSIRO',
'CSIRO-ARCCSS',
'DKRZ',
'EC-Earth-Consortium',
'INM',
'MIROC',
'MOHC',
'MPI-M',
'NCC',
'NOAA-GFDL',
'NUIST']}
The CC0 (Public Domain) collection has three models, from which a historical scenario and four future simulations are available.
Note that not all models provide all simulations. See the ClimateImpactLab/downscaleCMIP6 README for a list of the available model/scenario/variable combinations.
Querying the STAC API¶
Use the Planetary Computer STAC API to find the exact data you want. You'll most likely want to query on the controlled vocabularies fields, under the cmip6: prefix. See the collection summary for the set of allowed values for each of those.
Combining collections to form a custom ensemble¶
As an example, if you would like to use both the CC0 and CC-BY collections, you can combine them as follows:
search = catalog.search(
collections=["cil-gdpcir-cc0", "cil-gdpcir-cc-by"],
query={"cmip6:experiment_id": {"eq": "ssp370"}},
)
ensemble = search.item_collection()
len(ensemble)
20
import collections
collections.Counter(x.collection_id for x in ensemble)
Counter({'cil-gdpcir-cc-by': 17, 'cil-gdpcir-cc0': 3})
Reading a single variable across models into xarray¶
# select this variable ID for all models in a collection
variable_id = "tasmax"
datasets_by_model = []
for item in tqdm(ensemble):
asset = item.assets[variable_id]
datasets_by_model.append(
xr.open_dataset(asset.href, **asset.extra_fields["xarray:open_kwargs"])
)
all_datasets = xr.concat(
datasets_by_model,
dim=pd.Index([ds.attrs["source_id"] for ds in datasets_by_model], name="model"),
combine_attrs="drop_conflicts",
)
0%| | 0/20 [00:00<?, ?it/s]
all_datasets
<xarray.Dataset> Size: 3TB
Dimensions: (lat: 720, lon: 1440, model: 20, time: 31390)
Coordinates:
* lat (lat) float64 6kB -89.88 -89.62 -89.38 -89.12 ... 89.38 89.62 89.88
* lon (lon) float64 12kB -179.9 -179.6 -179.4 ... 179.4 179.6 179.9
* time (time) object 251kB 2015-01-01 12:00:00 ... 2100-12-31 12:00:00
* model (model) object 160B 'GFDL-ESM4' 'NorESM2-MM' ... 'BCC-CSM2-MR'
Data variables:
tasmax (model, time, lat, lon) float32 3TB dask.array<chunksize=(1, 365, 360, 360), meta=np.ndarray>
Attributes: (12/25)
contact: climatesci@rhg.com
dc6_bias_correction_method: Quantile Delta Method (QDM)
dc6_citation: Please refer to https://github.com/ClimateI...
dc6_data_version: v20211231
dc6_dataset_name: Rhodium Group/Climate Impact Lab Global Dow...
dc6_description: The prefix dc6 is the project-specific abbr...
... ...
realization_index: 1
realm: atmos
sub_experiment: none
sub_experiment_id: none
table_id: day
variable_id: tasmaxSubsetting the data¶
Now that the metadata has been loaded into xarray, you can use xarray's methods for Indexing and Selecting Data to extract the subset the arrays to the portions meaningful to your analysis.
Note that the data has not been read yet - this is simply working with the coordinates to schedule the task graph using dask.
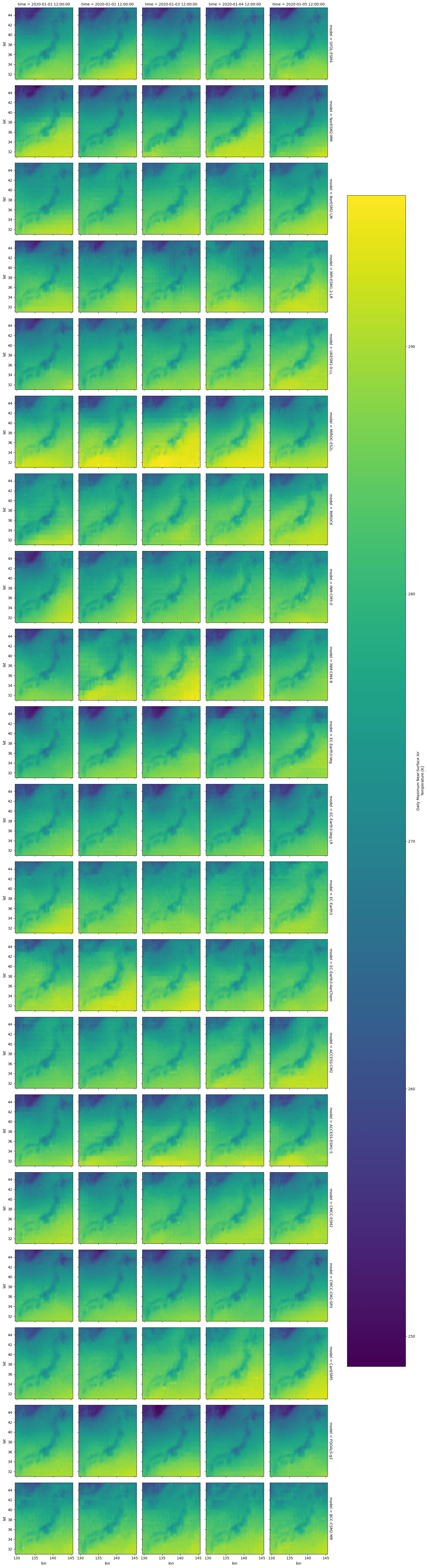
# let's select a subset of the data for the first five days of 2020 over Japan.
# Thanks to https://gist.github.com/graydon/11198540 for the bounding box!
subset = all_datasets.tasmax.sel(
lon=slice(129.408463169, 145.543137242),
lat=slice(31.0295791692, 45.5514834662),
time=slice("2020-01-01", "2020-01-05"),
)
with ProgressBar():
subset = subset.compute()
[########################################] | 100% Completed | 8.90 ss
subset
<xarray.DataArray 'tasmax' (model: 20, time: 5, lat: 58, lon: 64)> Size: 1MB
array([[[[285.73315, 285.4604 , 285.3989 , ..., 288.46887, 288.45538,
288.3411 ],
[285.4088 , 284.85898, 284.64523, ..., 288.25568, 288.40067,
288.26636],
[285.042 , 284.65338, 284.3192 , ..., 288.09857, 288.33298,
288.17307],
...,
[255.6336 , 255.90742, 255.76608, ..., 270.9189 , 271.3525 ,
271.49866],
[255.53918, 256.2673 , 257.10635, ..., 271.33408, 270.98483,
271.3151 ],
[254.87746, 255.66376, 256.50848, ..., 271.04498, 271.05704,
271.30338]],
[[285.91162, 285.58484, 286.10092, ..., 292.35254, 292.3309 ,
292.34427],
[285.565 , 284.94022, 285.75223, ..., 292.1405 , 292.2511 ,
292.22943],
[285.25647, 284.79587, 285.2175 , ..., 291.90317, 292.11487,
292.16623],
...
[263.99496, 263.98923, 265.9909 , ..., 272.94186, 270.91608,
271.09778],
[263.7273 , 264.36838, 267.27963, ..., 271.01 , 270.0902 ,
270.34082],
[262.84192, 263.58743, 266.7099 , ..., 270.6768 , 270.26273,
270.4232 ]],
[[289.9362 , 289.80225, 288.88925, ..., 291.64294, 291.30453,
291.20703],
[289.503 , 289.25168, 288.7057 , ..., 291.51035, 291.37308,
291.30908],
[289.054 , 288.8851 , 287.89902, ..., 291.3675 , 291.34402,
291.34195],
...,
[265.43088, 265.4783 , 268.89062, ..., 270.09174, 269.90125,
270.14105],
[264.06845, 264.98584, 268.8448 , ..., 270.29214, 269.33145,
269.47906],
[263.4161 , 264.3746 , 268.24796, ..., 270.58902, 269.15533,
269.333 ]]]], dtype=float32)
Coordinates:
* lat (lat) float64 464B 31.12 31.38 31.62 31.88 ... 44.88 45.12 45.38
* lon (lon) float64 512B 129.6 129.9 130.1 130.4 ... 144.9 145.1 145.4
* time (time) object 40B 2020-01-01 12:00:00 ... 2020-01-05 12:00:00
* model (model) object 160B 'GFDL-ESM4' 'NorESM2-MM' ... 'BCC-CSM2-MR'
Attributes:
cell_measures: area: areacella
interp_method: conserve_order2
long_name: Daily Maximum Near-Surface Air Temperature
standard_name: air_temperature
units: K
comment: maximum near-surface (usually, 2 meter) air temperature (...At this point, you could do anything you like with the data. See the great xarray getting started guide for more information. For now, we'll plot it all!
subset.plot(row="model", col="time");