Accessing Esri 10m Land Use/Land Cover (9-class) data with the Planetary Computer STAC API¶
This dataset contains global estimates of 10-class land use/land cover for 2017 - 2022, derived from ESA Sentinel-2 imagery at 10m resolution. In this notebook, we'll demonstrate how to access and work with this data through the Planetary Computer.
Environment setup¶
This notebook works with or without an API key, but you will be given more permissive access to the data with an API key. The Planetary Computer Hub is pre-configured to use your API key.
import dask.distributed
from matplotlib.colors import ListedColormap
import pystac_client
import cartopy.crs as ccrs
import numpy as np
import pandas as pd
import planetary_computer
import rasterio
import rasterio.features
import stackstac
# Set the environment variable PC_SDK_SUBSCRIPTION_KEY, or set it here.
# The Hub sets PC_SDK_SUBSCRIPTION_KEY automatically.
# pc.settings.set_subscription_key(<YOUR API Key>)
Data access¶
The datasets hosted by the Planetary Computer are available from Azure Blob Storage. We'll use pystac-client to search the Planetary Computer's STAC API for the subset of the data that we care about, and then we'll load the data directly from Azure Blob Storage. We'll specify a modifier so that we can access the data stored in the Planetary Computer's private Blob Storage Containers. See Reading from the STAC API and Using tokens for data access for more.
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
Select a region and find data items¶
We'll pick an area in Thailand and use the STAC API to find what data items are available.
bbox_of_interest = [100.0868, 13.7554, 100.3354, 13.986]
search = catalog.search(collections=["io-lulc-9-class"], bbox=bbox_of_interest)
items = search.item_collection()
print(f"Returned {len(items)} Items")
Returned 6 Items
We found several items that intersect with our area of interest, one per year.
We'll use the stackstac library to read all of these into a single xarray.DataArray.
# The STAC metadata contains some information we'll want to use when creating
# our merged dataset. Get the EPSG code of the first item and the nodata value.
item = items[0]
# Create a single DataArray from out multiple resutls with the corresponding
# rasters projected to a single CRS. Note that we set the dtype to ubyte, which
# matches our data, since stackstac will use float64 by default.
stack = (
stackstac.stack(
items,
dtype=np.ubyte,
fill_value=255,
bounds_latlon=bbox_of_interest,
sortby_date=False,
)
.assign_coords(
time=pd.to_datetime([item.properties["start_datetime"] for item in items])
.tz_convert(None)
.to_numpy()
)
.sortby("time")
)
stack
<xarray.DataArray 'stackstac-ffe6a4c6af8232bd9842eba59c37bf4c' (time: 6,
band: 1,
y: 2565, x: 2701)>
dask.array<getitem, shape=(6, 1, 2565, 2701), dtype=uint8, chunksize=(1, 1, 1024, 1024), chunktype=numpy.ndarray>
Coordinates: (12/15)
* time (time) datetime64[ns] 2017-01-01 2018-01-01 ... 2022-01-01
id (time) <U8 '47P-2017' '47P-2018' ... '47P-2021' '47P-2022'
* band (band) <U4 'data'
* x (x) float64 6.174e+05 6.174e+05 ... 6.444e+05 6.444e+05
* y (y) float64 1.547e+06 1.547e+06 ... 1.521e+06 1.521e+06
end_datetime (time) <U20 '2018-01-01T00:00:00Z' ... '2023-01-01T00:00...
... ...
proj:bbox object {1771251.1832111736, 830743.294771302, 884301.183...
start_datetime (time) <U20 '2017-01-01T00:00:00Z' ... '2022-01-01T00:00...
io:supercell_id <U3 '47P'
proj:transform object {0.0, 10.0, 169263.29477130197, 1771251.183211173...
raster:bands object {'nodata': 0, 'spatial_resolution': 10}
epsg int64 32647
Attributes:
spec: RasterSpec(epsg=32647, bounds=(617370.0, 1520940.0, 644380.0...
crs: epsg:32647
transform: | 10.00, 0.00, 617370.00|\n| 0.00,-10.00, 1546590.00|\n| 0.0...
resolution: 10.0Start up a local Dask cluster to allow us to do parallel reads. Use the following URL to open a dashboard in the Hub's Dask Extension.
client = dask.distributed.Client(processes=False)
print(f"/proxy/{client.scheduler_info()['services']['dashboard']}/status")
/proxy/8787/status
Mosaic and clip the raster¶
So far, we haven't read in any data. Stackstac has used the STAC metadata to construct a DataArray that will contain our Item data. Let's mosaic the rasters across the time dimension (remember, they're all from a single synthesized "time") and drop the single band dimension. Finally, we ask Dask to read the actual data by calling .compute().
merged = stack.squeeze().compute()
Now a quick plot to check that we've got the data we want.
g = merged.plot(col="time")
for ax in g.axes.flat:
ax.set_axis_off()

It looks good, but it doesn't look like a land cover map. The source GeoTIFFs contain a colormap and the STAC metadata contains the class names. We'll open one of the source files just to read this metadata and construct the right colors and names for our plot.
from pystac.extensions.item_assets import ItemAssetsExtension
collection = catalog.get_collection("io-lulc-9-class")
ia = ItemAssetsExtension.ext(collection)
x = ia.item_assets["data"]
class_names = {x["summary"]: x["values"][0] for x in x.properties["file:values"]}
values_to_classes = {v: k for k, v in class_names.items()}
class_count = len(class_names)
class_names
{'No Data': 0,
'Water': 1,
'Trees': 2,
'Flooded vegetation': 4,
'Crops': 5,
'Built area': 7,
'Bare ground': 8,
'Snow/ice': 9,
'Clouds': 10,
'Rangeland': 11}
with rasterio.open(item.assets["data"].href) as src:
colormap_def = src.colormap(1) # get metadata colormap for band 1
colormap = [
np.array(colormap_def[i]) / 255 for i in range(max(class_names.values()) + 1)
] # transform to matplotlib color format
cmap = ListedColormap(colormap)
vmin = 0
vmax = max(class_names.values()) + 1
epsg = merged.epsg.item()
p = merged.plot(
subplot_kws=dict(projection=ccrs.epsg(epsg)),
col="time",
transform=ccrs.epsg(epsg),
cmap=cmap,
vmin=vmin,
vmax=vmax,
figsize=(16, 6),
)
ticks = np.linspace(0.5, vmax - 0.5, vmax - vmin)
labels = [values_to_classes.get(i, "") for i in range(cmap.N)]
p.cbar.set_ticks(ticks, labels=labels)
p.cbar.set_label("Class")

That looks better. Let's also plot a histogram of the pixel values to see the distribution of land cover types within our area of interest. We can reuse the colormap we generated to help tie the two visualizations together.
colors = list(cmap.colors)
ax = (
pd.value_counts(merged.data.ravel(), sort=False)
.sort_index()
.reindex(range(cmap.N), fill_value=0)
.rename(values_to_classes)
.plot.barh(color=colors, rot=0, width=0.9)
)
ax.set(
title="Distribution of Land Cover classes",
ylabel="Landcover class",
xlabel="Class count",
);
/var/folders/cb/fj2byfwd3pv960xpfrz42yph0000gn/T/ipykernel_63630/4112736583.py:4: FutureWarning: pandas.value_counts is deprecated and will be removed in a future version. Use pd.Series(obj).value_counts() instead. pd.value_counts(merged.data.ravel(), sort=False)

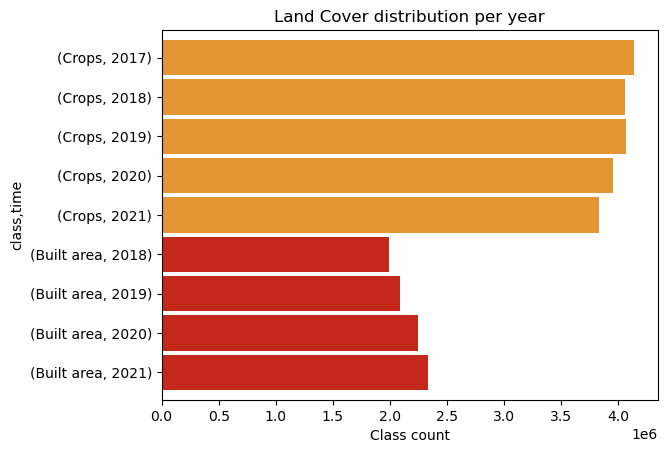
We can make a similar plot per year.
df = merged.stack(pixel=("y", "x")).T.to_pandas()
counts = (
df.stack()
.rename("class")
.reset_index()
.groupby("time")["class"]
.value_counts()
.nlargest(9)
.rename("count")
.swaplevel()
.sort_index(ascending=False)
.rename(lambda x: x.year, level="time")
)
colors = cmap(counts.index.get_level_values("class") / cmap.N)
ax = counts.rename(values_to_classes, level="class").plot.barh(color=colors, width=0.9)
ax.set(xlabel="Class count", title="Land Cover distribution per year");
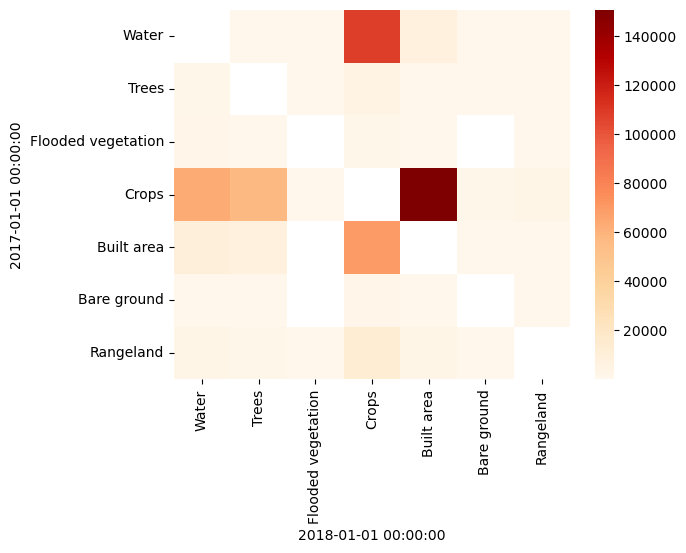
Finally, we can plot the transitions between years, to show which classes are transitioning to which other classes:
import seaborn as sns
by_year = df.groupby("2017-01-01")["2018-01-01"].value_counts()
years = by_year.index.levels[0]
classes = by_year.index.levels[1]
idx = pd.MultiIndex.from_product([years, classes])
transitions = by_year.reindex(idx, fill_value=0)
by_year[by_year.index.get_level_values(0) == by_year.index.get_level_values(1)] = np.nan
transitions = by_year.unstack().rename(
columns=values_to_classes, index=values_to_classes
)
sns.heatmap(transitions, cmap="OrRd");