Accessing MODIS snow data with the Planetary Computer STAC API¶
The planetary computer hosts two snow-related MODIS 6.1 products:
- Snow cover daily (10A1)
- Snow cover 8-day (10A2)
For more information about the products themselves, check out the Data Pages at the bottom of this document.
Environment setup¶
This notebook works with or without an API key, but you will be given more permissive access to the data with an API key. The Planetary Computer Hub is pre-configured to use your API key.
import odc.stac
import planetary_computer
import pystac_client
import rich.table
Data access¶
The datasets hosted by the Planetary Computer are available from Azure Blob Storage. We'll use pystac-client to search the Planetary Computer's STAC API for the subset of the data that we care about, and then we'll load the data directly from Azure Blob Storage. We'll specify a modifier so that we can access the data stored in the Planetary Computer's private Blob Storage Containers. See Reading from the STAC API and Using tokens for data access for more.
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
Query for available data¶
MODIS is a global dataset with a variety of products available within each larger category (vegetation, snow, fire, temperature, and reflectance).
The MODIS group contains a complete listing of available collections.
Each collection's id is in the format modis-{product}-061, where product is the MODIS product id.
The -061 suffix indicates that all of the MODIS collections are part of the MODIS 6.1 update.
We'll look at the snow cover around the Mount of the Holy Cross in Colorado and how it progresses throughout the winter, using the daily snow product (10A1).
longitude = -106.481687
latitude = 39.466829
mount_of_the_holy_cross = [longitude, latitude]
geometry = {
"type": "Point",
"coordinates": mount_of_the_holy_cross,
}
datetimes = [
"2020-11",
"2020-12",
"2021-01",
"2021-02",
"2021-03",
"2021-04",
"2021-05",
"2021-06",
]
items = dict()
for datetime in datetimes:
print(f"Fetching {datetime}")
search = catalog.search(
collections=["modis-10A1-061"],
intersects=geometry,
datetime=datetime,
)
items[datetime] = search.get_all_items()[0]
print(items)
Fetching 2020-11
Fetching 2020-12
Fetching 2021-01
Fetching 2021-02
Fetching 2021-03
Fetching 2021-04
Fetching 2021-05
Fetching 2021-06
{'2020-11': <Item id=MYD10A1.A2020335.h09v05.061.2020357065201>, '2020-12': <Item id=MYD10A1.A2020366.h09v05.061.2021006153327>, '2021-01': <Item id=MYD10A1.A2021031.h09v05.061.2021033145105>, '2021-02': <Item id=MYD10A1.A2021059.h09v05.061.2021061192703>, '2021-03': <Item id=MYD10A1.A2021090.h09v05.061.2021092034817>, '2021-04': <Item id=MYD10A1.A2021120.h09v05.061.2021122125544>, '2021-05': <Item id=MYD10A1.A2021151.h09v05.061.2021153050114>, '2021-06': <Item id=MYD10A1.A2021181.h09v05.061.2021183182721>}
Available assets¶
Each item has several available assets, including the original HDF file and a Cloud-optimized GeoTIFF of each subdataset.
t = rich.table.Table("Key", "Title")
for key, asset in items["2020-11"].assets.items():
t.add_row(key, asset.title)
t
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Key ┃ Title ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ hdf │ Source data containing all bands │ │ NDSI │ Raw NDSI values (i.e. prior to screening). │ │ metadata │ Federal Geographic Data Committee (FGDC) Metadata │ │ orbit_pnt │ Pointer to the orbit of the swath mapped into each grid cell. │ │ granule_pnt │ Pointer for identifying the swath mapped into each grid cell. │ │ NDSI_Snow_Cover │ Gridded NDSI snow cover and data flag values. │ │ Snow_Albedo_Daily_Tile │ Daily snow albedo corresponding to the NDSI_Snow_Cover parameter. │ │ NDSI_Snow_Cover_Basic_QA │ A general estimate of the quality of the algorithm result. │ │ NDSI_Snow_Cover_Algorithm_Flags_QA │ Algorithm-specific bit flags set for data screens and for inland water. │ │ tilejson │ TileJSON with default rendering │ │ rendered_preview │ Rendered preview │ └────────────────────────────────────┴─────────────────────────────────────────────────────────────────────────┘
Loading the snow cover data¶
For this example, we'll visualize and compare the snow cover month to month.
Let's grab each snow cover COG and load them into an xarray using odc-stac.
We'll also apply the scaling as defined by the raster:bands extension.
The MODIS coordinate reference system is a sinusoidal grid, which means that views in a naïve XY raster look skewed.
For visualization purposes, we reproject to a spherical Mercator projection for intuitive, north-up visualization.
The NDSI Snow Cover values are defined as:
0–100: NDSI snow cover
200: missing data
201: no decision
211: night
237: inland water
239: ocean
250: cloud
254: detector saturated
255: fill
We want to mask out all numbers greater than 100.
bbox = [longitude - 0.5, latitude - 0.5, longitude + 0.5, latitude + 0.5]
data = odc.stac.load(
items.values(),
crs="EPSG:3857",
bbox=bbox,
bands="NDSI_Snow_Cover",
resolution=500,
)
data = data.where(data <= 100, drop=True)
data
<xarray.Dataset>
Dimensions: (time: 8, y: 290, x: 224)
Coordinates:
* y (y) float64 4.861e+06 4.861e+06 ... 4.717e+06 4.717e+06
* x (x) float64 -1.191e+07 -1.191e+07 ... -1.18e+07 -1.18e+07
spatial_ref int32 3857
* time (time) datetime64[ns] 2020-11-30 2020-12-31 ... 2021-06-30
Data variables:
NDSI_Snow_Cover (time, y, x) float64 nan nan nan nan ... nan nan nan nanDisplaying the data¶
Let's display the snow cover for each month.
g = data["NDSI_Snow_Cover"].plot.imshow(
col="time", vmin=0, vmax=100, col_wrap=4, size=4
)
months = data["NDSI_Snow_Cover"].time.to_pandas().dt.strftime("%B %Y")
for ax, month in zip(g.axes.flat, months):
ax.set_title(month)
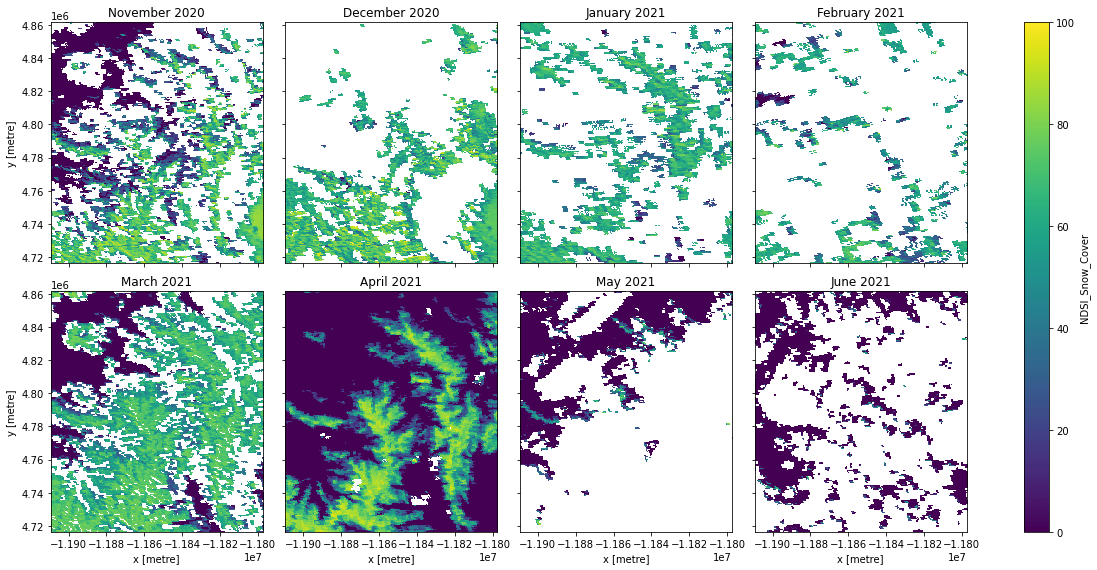
You'll notice there's a lot of missing values due to masking, probably due to clouds.
More sophisticated analysis would use the NDSI_Snow_Cover_Basic_QA and other bands to merge information from multiple scenes, or pick the best scenes for analysis.
Data pages¶
These pages include links to the user guides: