Accessing TerraClimate data with the Planetary Computer STAC API¶
TerraClimate is a dataset of monthly climate and climatic water balance for global terrestrial surfaces from 1958 to the present. These data provide important inputs for ecological and hydrological studies at global scales that require high spatial resolution and time-varying data. All data have monthly temporal resolution and a ~4-km (1/24th degree) spatial resolution. The data cover the period from 1958-2019.
This example will show you how temperature has increased over the past 60 years across the globe.
Environment setup¶
import warnings
import pystac_client
import planetary_computer
import xarray as xr
warnings.filterwarnings("ignore", "invalid value", RuntimeWarning)
Data access¶
The datasets hosted by the Planetary Computer are available from Azure Blob Storage. We'll use pystac-client to search the Planetary Computer's STAC API for the subset of the data that we care about, and then we'll load the data directly from Azure Blob Storage. We'll specify a modifier so that we can access the data stored in the Planetary Computer's private Blob Storage Containers. See Reading from the STAC API and Using tokens for data access for more.
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
collection = catalog.get_collection("terraclimate")
The collection contains assets, which are links to the root of a Zarr store, which can be opened with xarray.
asset = collection.assets["zarr-abfs"]
asset
Asset: TerraClimate Azure Blob File System Zarr root
| href: az://cpdata/raw/terraclimate/4000m/raster.zarr |
| Title: TerraClimate Azure Blob File System Zarr root |
| Description: Azure Blob File System URI of the TerraClimate Zarr Group on Azure Blob Storage for use with adlfs. |
| Media type: application/vnd+zarr |
| Roles: ['data', 'zarr', 'abfs'] |
| Owner: |
| xarray:storage_options: {'account_name': 'cpdataeuwest', 'credential': 'st=2023-01-24T19%3A45%3A16Z&se=2023-02-01T19%3A45%3A16Z&sp=rl&sv=2021-06-08&sr=c&skoid=c85c15d6-d1ae-42d4-af60-e2ca0f81359b&sktid=72f988bf-86f1-41af-91ab-2d7cd011db47&skt=2023-01-25T19%3A45%3A15Z&ske=2023-02-01T19%3A45%3A15Z&sks=b&skv=2021-06-08&sig=oK2IJ9AaXN35bokPyNBba9bdqlIWkrfT829yy%2Byfw9w%3D'} |
if "xarray:storage_options" in asset.extra_fields:
ds = xr.open_zarr(
asset.href,
storage_options=asset.extra_fields["xarray:storage_options"],
consolidated=True,
)
else:
ds = xr.open_dataset(
asset.href,
**asset.extra_fields["xarray:open_kwargs"],
)
ds
<xarray.Dataset>
Dimensions: (time: 744, lat: 4320, lon: 8640, crs: 1)
Coordinates:
* crs (crs) int16 3
* lat (lat) float64 89.98 89.94 89.9 ... -89.94 -89.98
* lon (lon) float64 -180.0 -179.9 -179.9 ... 179.9 180.0
* time (time) datetime64[ns] 1958-01-01 ... 2019-12-01
Data variables: (12/18)
aet (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
def (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
pdsi (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
pet (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
ppt (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
ppt_station_influence (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
... ...
tmin (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
tmin_station_influence (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
vap (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
vap_station_influence (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
vpd (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>
ws (time, lat, lon) float32 dask.array<chunksize=(12, 1440, 1440), meta=np.ndarray>We'll process the data in parallel using Dask.
from dask_gateway import GatewayCluster
cluster = GatewayCluster()
cluster.scale(16)
client = cluster.get_client()
print(cluster.dashboard_link)
The link printed out above can be opened in a new tab or the Dask labextension. See Scale with Dask for more on using Dask, and how to access the Dashboard.
Analyze and plot global temperature¶
We can quickly plot a map of one of the variables. In this case, we are downsampling (coarsening) the dataset for easier plotting.
import cartopy.crs as ccrs
import matplotlib.pyplot as plt
average_max_temp = ds.isel(time=-1)["tmax"].coarsen(lat=8, lon=8).mean().load()
fig, ax = plt.subplots(figsize=(20, 10), subplot_kw=dict(projection=ccrs.Robinson()))
average_max_temp.plot(ax=ax, transform=ccrs.PlateCarree())
ax.coastlines();
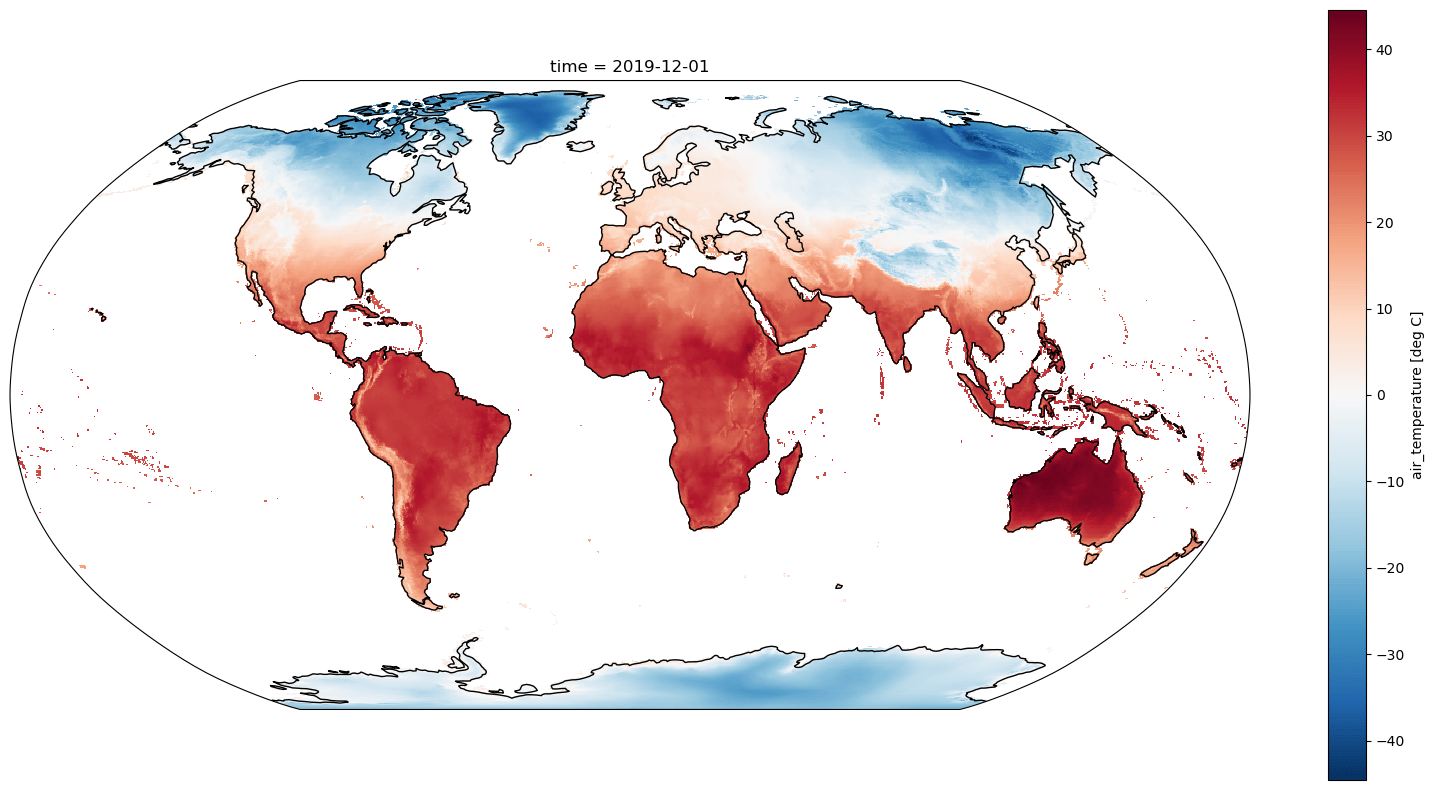
Let's see how temperature has changed over the observational record, when averaged across the entire domain. Since we'll do some other calculations below we'll also add .load() to execute the command instead of specifying it lazily. Note that there are some data quality issues before 1965 so we'll start our analysis there.
temperature = (
ds["tmax"].sel(time=slice("1965", None)).mean(dim=["lat", "lon"]).persist()
)
temperature.plot(figsize=(12, 6));
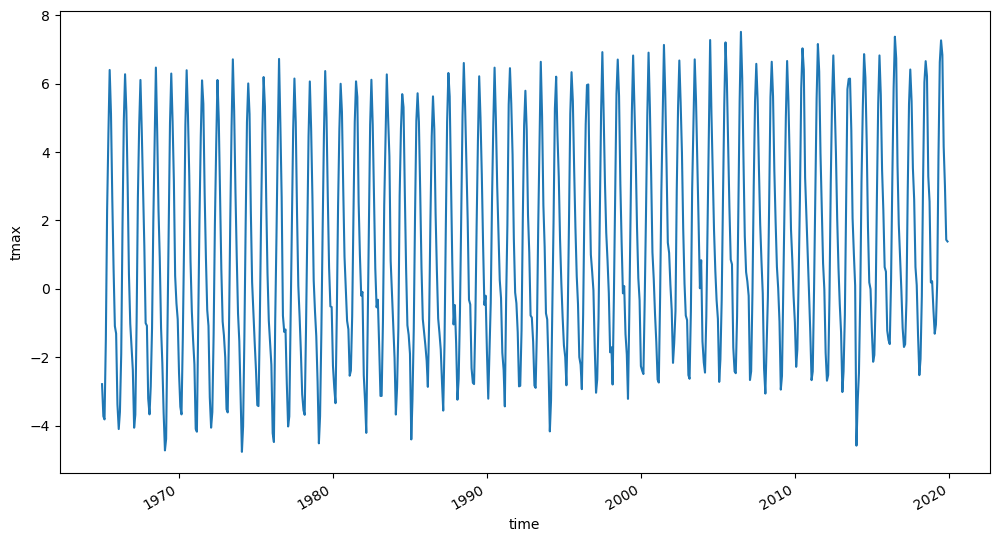
With all the seasonal fluctuations (from summer and winter) though, it can be hard to see any obvious trends. So let's try grouping by year and plotting that timeseries.
temperature.groupby("time.year").mean().plot(figsize=(12, 6));

Now the increase in temperature is obvious, even when averaged across the entire domain.
Finally, let's see how those changes are different in different parts of the world. And let's focus just on summer months in the northern hemisphere, when it's hottest. Let's take a climatological slice at the beginning of the period and the same at the end of the period, calculate the difference, and map it to see how different parts of the world have changed differently.
First we'll just grab the summer months.
%%time
import dask
summer_months = [6, 7, 8]
summer = ds.tmax.where(ds.time.dt.month.isin(summer_months), drop=True)
early_period = slice("1958-01-01", "1988-12-31")
late_period = slice("1988-01-01", "2018-12-31")
early, late = dask.compute(
summer.sel(time=early_period).mean(dim="time"),
summer.sel(time=late_period).mean(dim="time"),
)
increase = (late - early).coarsen(lat=8, lon=8).mean()
CPU times: user 1.59 s, sys: 385 ms, total: 1.97 s Wall time: 54.4 s
fig, ax = plt.subplots(figsize=(20, 10), subplot_kw=dict(projection=ccrs.Robinson()))
increase.plot(ax=ax, transform=ccrs.PlateCarree(), robust=True)
ax.coastlines();
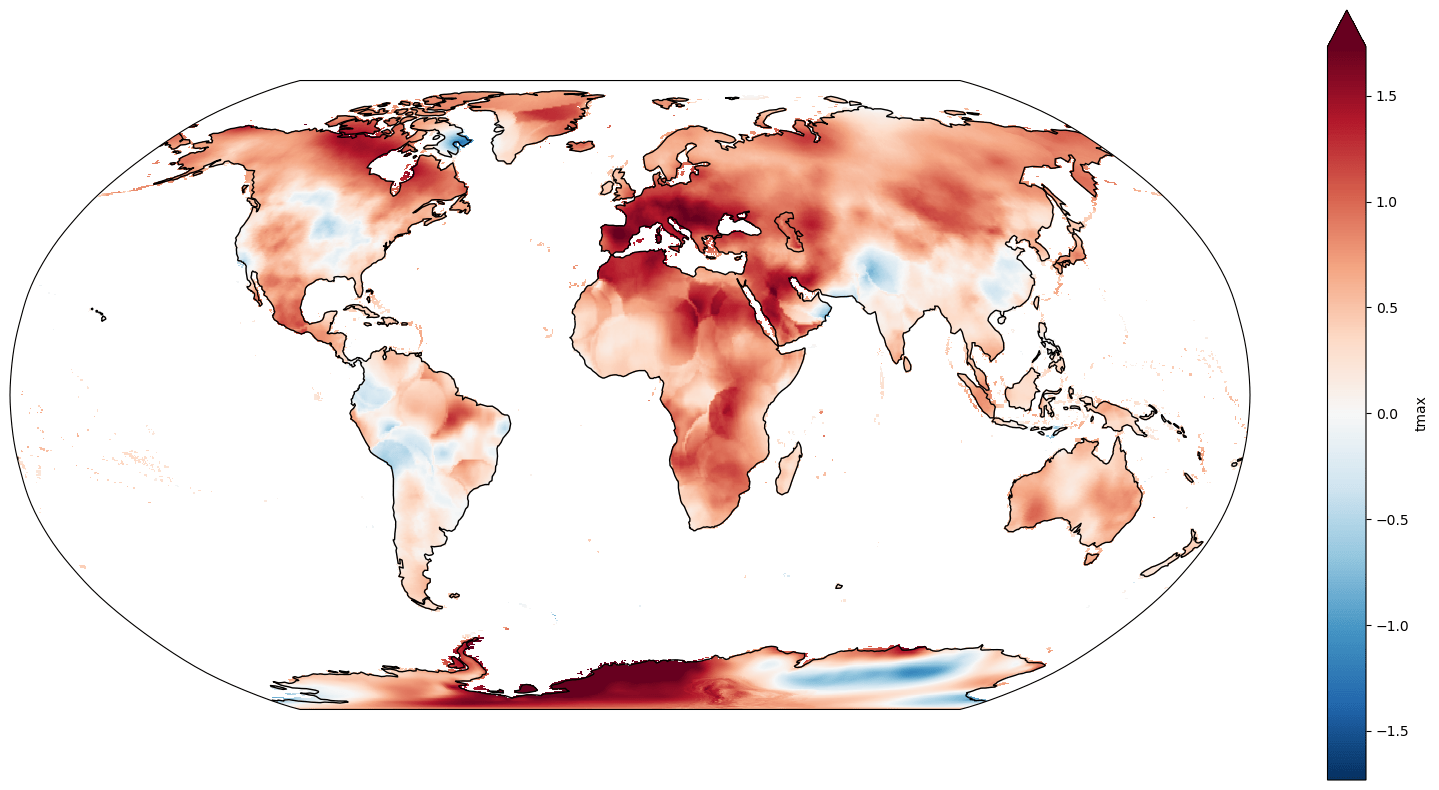
This shows us that changes in summer temperature haven't been felt equally around the globe. Note the enhanced warming in the polar regions, a phenomenon known as "Arctic amplification".