MOSAIKS feature extraction¶
This tutorial demonstrates the MOSAIKS method for extracting feature vectors from satellite imagery patches for use in downstream modeling tasks. It will show:
- How to extract 1km$^2$ patches of Sentinel 2 multispectral imagery for a list of latitude, longitude points
- How to extract summary features from each of these imagery patches
- How to use the summary features in a linear model of the population density at each point
Background¶
Consider the case where you have a dataset of latitude and longitude points associated with some dependent variable (for example: population density, weather, housing prices, biodiversity) and, potentially, other independent variables. You would like to model the dependent variable as a function of the independent variables, but instead of including latitude and longitude directly in this model, you would like to include some high dimensional representation of what the Earth looks like at that point (that hopefully explains some of the variance in the dependent variable!). From the computer vision literature, there are various representation learning techniques that can be used to do this, i.e. extract features vectors from imagery. This notebook gives an implementation of the technique described in Rolf et al. 2021, "A generalizable and accessible approach to machine learning with global satellite imagery" called Multi-task Observation using Satellite Imagery & Kitchen Sinks (MOSAIKS). For more information about MOSAIKS see the project's webpage.
Notes:
- This example uses Sentinel-2 Level-2A data. The techniques used here apply equally well to other remote-sensing datasets.
- If you're running this on the Planetary Computer Hub, make sure to choose the GPU - PyTorch profile when presented with the form to choose your environment.
import warnings
import time
import os
RASTERIO_BEST_PRACTICES = dict( # See https://github.com/pangeo-data/cog-best-practices
CURL_CA_BUNDLE="/etc/ssl/certs/ca-certificates.crt",
GDAL_DISABLE_READDIR_ON_OPEN="EMPTY_DIR",
AWS_NO_SIGN_REQUEST="YES",
GDAL_MAX_RAW_BLOCK_CACHE_SIZE="200000000",
GDAL_SWATH_SIZE="200000000",
VSI_CURL_CACHE_SIZE="200000000",
)
os.environ.update(RASTERIO_BEST_PRACTICES)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import rasterio
import rasterio.warp
import rasterio.mask
import shapely.geometry
import geopandas
import dask_geopandas
from sklearn.linear_model import RidgeCV
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from scipy.stats import spearmanr
from scipy.linalg import LinAlgWarning
from dask.distributed import Client
warnings.filterwarnings(action="ignore", category=LinAlgWarning, module="sklearn")
import pystac_client
import planetary_computer as pc
First we define the pytorch model that we will use to extract the features and a helper method. The MOSAIKS methodology describes several ways to do this and we use the simplest.
def featurize(input_img, model, device):
"""Helper method for running an image patch through the model.
Args:
input_img (np.ndarray): Image in (C x H x W) format with a dtype of uint8.
model (torch.nn.Module): Feature extractor network
"""
assert len(input_img.shape) == 3
input_img = torch.from_numpy(input_img / 255.0).float()
input_img = input_img.to(device)
with torch.no_grad():
feats = model(input_img.unsqueeze(0)).cpu().numpy()
return feats
class RCF(nn.Module):
"""A model for extracting Random Convolution Features (RCF) from input imagery."""
def __init__(self, num_features=16, kernel_size=3, num_input_channels=3):
super(RCF, self).__init__()
# We create `num_features / 2` filters so require `num_features` to be divisible by 2
assert num_features % 2 == 0
self.conv1 = nn.Conv2d(
num_input_channels,
num_features // 2,
kernel_size=kernel_size,
stride=1,
padding=0,
dilation=1,
bias=True,
)
nn.init.normal_(self.conv1.weight, mean=0.0, std=1.0)
nn.init.constant_(self.conv1.bias, -1.0)
def forward(self, x):
x1a = F.relu(self.conv1(x), inplace=True)
x1b = F.relu(-self.conv1(x), inplace=True)
x1a = F.adaptive_avg_pool2d(x1a, (1, 1)).squeeze()
x1b = F.adaptive_avg_pool2d(x1b, (1, 1)).squeeze()
if len(x1a.shape) == 1: # case where we passed a single input
return torch.cat((x1a, x1b), dim=0)
elif len(x1a.shape) == 2: # case where we passed a batch of > 1 inputs
return torch.cat((x1a, x1b), dim=1)
Next, we initialize the model and pytorch components
num_features = 1024
device = torch.device("cuda")
model = RCF(num_features).eval().to(device)
Read dataset of (lat, lon) points and corresponding labels¶
We read a CSV of 100,000 randomly sampled (lat, lon) points over the US and the corresponding population living roughly within 1km$^2$ of the points from the Gridded Population of the World dataset. This data comes from the Code Ocean capsule that accompanies the Rolf et al. 2021 paper.
df = pd.read_csv(
"https://files.codeocean.com/files/verified/fa908bbc-11f9-4421-8bd3-72a4bf00427f_v2.0/data/int/applications/population/outcomes_sampled_population_CONTUS_16_640_UAR_100000_0.csv?download", # noqa: E501
index_col=0,
na_values=[-999],
).dropna()
points = df[["lon", "lat"]]
population = df["population"]
gdf = geopandas.GeoDataFrame(df, geometry=geopandas.points_from_xy(df.lon, df.lat))
gdf
| V1 | V1.1 | ID | lon | lat | population | geometry | |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1225,1595 | -103.046735 | 37.932314 | 0.085924 | POINT (-103.04673 37.93231) |
| 2 | 2 | 2 | 1521,2455 | -91.202438 | 34.647579 | 0.808222 | POINT (-91.20244 34.64758) |
| 4 | 4 | 4 | 828,3849 | -72.003660 | 42.116711 | 101.286320 | POINT (-72.00366 42.11671) |
| 5 | 5 | 5 | 1530,2831 | -86.024002 | 34.545552 | 28.181724 | POINT (-86.02400 34.54555) |
| 6 | 6 | 6 | 1097,2696 | -87.883281 | 39.309455 | 11.923701 | POINT (-87.88328 39.30945) |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 99995 | 99995 | 99995 | 1164,1275 | -107.453915 | 38.591906 | 0.006152 | POINT (-107.45391 38.59191) |
| 99996 | 99996 | 99996 | 343,2466 | -91.050941 | 46.876806 | 1.782686 | POINT (-91.05094 46.87681) |
| 99997 | 99997 | 99997 | 634,3922 | -70.998272 | 44.067430 | 8.383357 | POINT (-70.99827 44.06743) |
| 99998 | 99998 | 99998 | 357,2280 | -93.612615 | 46.744854 | 8.110552 | POINT (-93.61261 46.74485) |
| 100000 | 100000 | 100000 | 1449,2691 | -87.952143 | 35.459263 | 1.972914 | POINT (-87.95214 35.45926) |
67968 rows × 7 columns
Get rid of points with nodata population values
population.plot.hist();
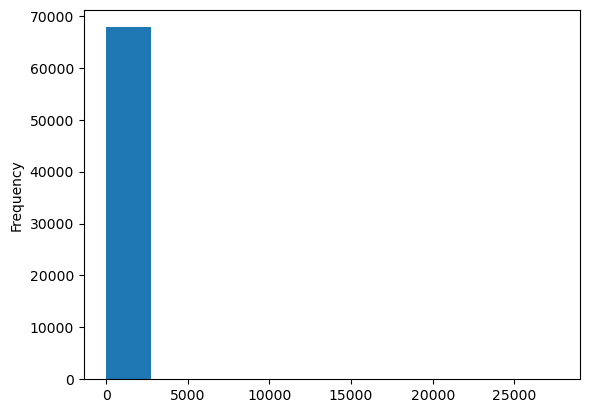
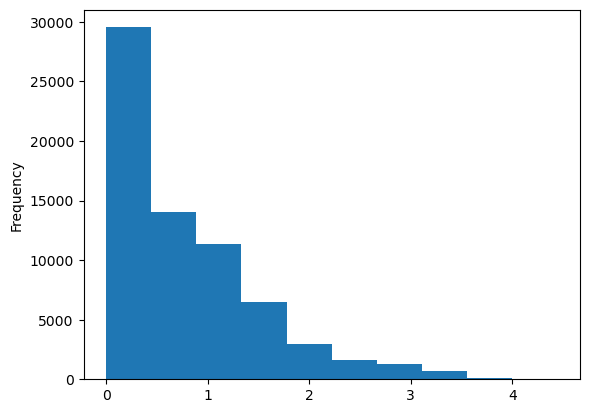
Population is lognormal distributed, so transforming it to log-space makes sense for modeling purposes
population_log = np.log10(population + 1)
population_log.plot.hist();
ax = points.assign(population=population_log).plot.scatter(
x="lon",
y="lat",
c="population",
s=1,
cmap="viridis",
figsize=(10, 6),
colorbar=False,
)
ax.set_axis_off();
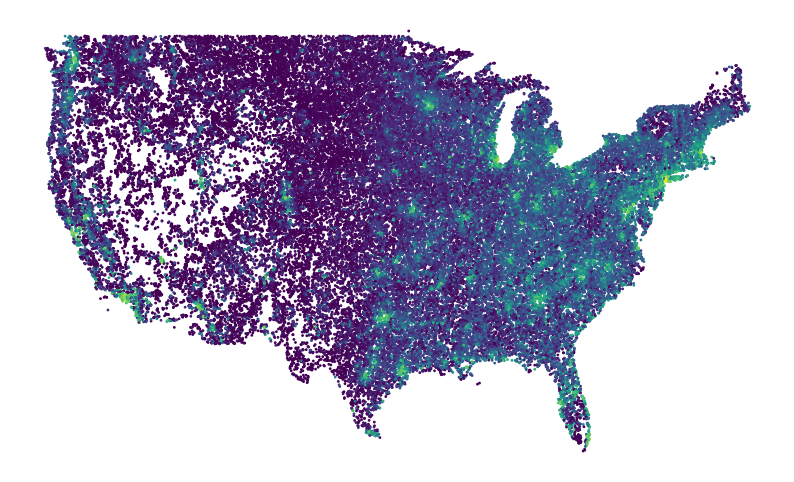
Extract features from the imagery around each point¶
We need to find a suitable Sentinel 2 scene for each point. As usual, we'll use pystac-client to search for items matching some conditions, but we don't just want do make a .search() call for each of the 67,968 remaining points. Each HTTP request is relatively slow. Instead, we will batch or points and search in parallel.
We need to be a bit careful with how we batch up our points though. Since a single Sentinel 2 scene will cover many points, we want to make sure that points which are spatially close together end up in the same batch. In short, we need to spatially partition the dataset. This is implemented in dask-geopandas.
So the overall workflow will be
- Find an appropriate STAC item for each point (in parallel, using the spatially partitioned dataset)
- Feed the points and STAC items to a custom Dataset that can read imagery given a point and the URL of a overlapping S2 scene
- Use a custom Dataloader, which uses our Dataset, to feed our model imagery and save the corresponding features
NPARTITIONS = 250
ddf = dask_geopandas.from_geopandas(gdf, npartitions=1)
hd = ddf.hilbert_distance().compute()
gdf["hd"] = hd
gdf = gdf.sort_values("hd")
dgdf = dask_geopandas.from_geopandas(gdf, npartitions=NPARTITIONS, sort=False)
We'll write a helper function that
def query(points):
"""
Find a STAC item for points in the `points` DataFrame
Parameters
----------
points : geopandas.GeoDataFrame
A GeoDataFrame
Returns
-------
geopandas.GeoDataFrame
A new geopandas.GeoDataFrame with a `stac_item` column containing the STAC
item that covers each point.
"""
intersects = shapely.geometry.mapping(points.unary_union.convex_hull)
search_start = "2018-01-01"
search_end = "2019-12-31"
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1"
)
# The time frame in which we search for non-cloudy imagery
search = catalog.search(
collections=["sentinel-2-l2a"],
intersects=intersects,
datetime=[search_start, search_end],
query={"eo:cloud_cover": {"lt": 10}},
limit=500,
)
ic = search.get_all_items_as_dict()
features = ic["features"]
features_d = {item["id"]: item for item in features}
data = {
"eo:cloud_cover": [],
"geometry": [],
}
index = []
for item in features:
data["eo:cloud_cover"].append(item["properties"]["eo:cloud_cover"])
data["geometry"].append(shapely.geometry.shape(item["geometry"]))
index.append(item["id"])
items = geopandas.GeoDataFrame(data, index=index, geometry="geometry").sort_values(
"eo:cloud_cover"
)
point_list = points.geometry.tolist()
point_items = []
for point in point_list:
covered_by = items[items.covers(point)]
if len(covered_by):
point_items.append(features_d[covered_by.index[0]])
else:
# There weren't any scenes matching our conditions for this point (too cloudy)
point_items.append(None)
return points.assign(stac_item=point_items)
%%time
with Client(n_workers=16) as client:
print(client.dashboard_link)
meta = dgdf._meta.assign(stac_item=[])
df2 = dgdf.map_partitions(query, meta=meta).compute()
2022-09-20 14:39:44,577 - distributed.diskutils - INFO - Found stale lock file and directory '/home/jovyan/PlanetaryComputerExamples/tutorials/dask-worker-space/worker-rz97cdcq', purging
/user/taugspurger@microsoft.com/proxy/8787/status CPU times: user 8.84 s, sys: 5.28 s, total: 14.1 s Wall time: 1min 27s
df2.head()
| V1 | V1.1 | ID | lon | lat | population | geometry | hd | stac_item | |
|---|---|---|---|---|---|---|---|---|---|
| 58227 | 58227 | 58227 | 2253,2012 | -97.303628 | 25.958163 | 0.193628 | POINT (-97.30363 25.95816) | 360793917 | {'id': 'S2A_MSIL2A_20191213T170711_R069_T14RPP... |
| 27993 | 27993 | 27993 | 2245,1999 | -97.482670 | 26.057180 | 244.428020 | POINT (-97.48267 26.05718) | 360931126 | {'id': 'S2A_MSIL2A_20191213T170711_R069_T14RPP... |
| 61808 | 61808 | 61808 | 2246,1986 | -97.661712 | 26.044807 | 525.789124 | POINT (-97.66171 26.04481) | 360950765 | {'id': 'S2A_MSIL2A_20191213T170711_R069_T14RPP... |
| 97710 | 97710 | 97710 | 2240,1992 | -97.579077 | 26.119023 | 70.362312 | POINT (-97.57908 26.11902) | 360966149 | {'id': 'S2A_MSIL2A_20191213T170711_R069_T14RPP... |
| 55442 | 55442 | 55442 | 2231,1994 | -97.551532 | 26.230258 | 44.150997 | POINT (-97.55153 26.23026) | 361043545 | {'id': 'S2B_MSIL2A_20181213T170709_R069_T14RPQ... |
df3 = df2.dropna(subset=["stac_item"])
matching_urls = [
pc.sign(item["assets"]["visual"]["href"]) for item in df3.stac_item.tolist()
]
points = df3[["lon", "lat"]].to_numpy()
population_log = np.log10(df3["population"].to_numpy() + 1)
class CustomDataset(Dataset):
def __init__(self, points, fns, buffer=500):
self.points = points
self.fns = fns
self.buffer = buffer
def __len__(self):
return self.points.shape[0]
def __getitem__(self, idx):
lon, lat = self.points[idx]
fn = self.fns[idx]
if fn is None:
return None
else:
point_geom = shapely.geometry.mapping(shapely.geometry.Point(lon, lat))
with rasterio.Env():
with rasterio.open(fn, "r") as f:
point_geom = rasterio.warp.transform_geom(
"epsg:4326", f.crs.to_string(), point_geom
)
point_shape = shapely.geometry.shape(point_geom)
mask_shape = point_shape.buffer(self.buffer).envelope
mask_geom = shapely.geometry.mapping(mask_shape)
try:
out_image, out_transform = rasterio.mask.mask(
f, [mask_geom], crop=True
)
except ValueError as e:
if "Input shapes do not overlap raster." in str(e):
return None
out_image = out_image / 255.0
out_image = torch.from_numpy(out_image).float()
return out_image
dataset = CustomDataset(points, matching_urls)
dataloader = DataLoader(
dataset,
batch_size=8,
shuffle=False,
num_workers=os.cpu_count() * 2,
collate_fn=lambda x: x,
pin_memory=False,
)
/srv/conda/envs/notebook/lib/python3.9/site-packages/torch/utils/data/dataloader.py:563: UserWarning: This DataLoader will create 8 worker processes in total. Our suggested max number of worker in current system is 4, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary. warnings.warn(_create_warning_msg(
x_all = np.zeros((points.shape[0], num_features), dtype=float)
tic = time.time()
i = 0
for images in dataloader:
for image in images:
if image is not None:
# A full image should be ~101x101 pixels (i.e. ~1km^2 at a 10m/px spatial
# resolution), however we can receive smaller images if an input point
# happens to be at the edge of a S2 scene (a literal edge case). To deal
# with these (edge) cases we crudely drop all images where the spatial
# dimensions aren't both greater than 20 pixels.
if image.shape[1] >= 20 and image.shape[2] >= 20:
image = image.to(device)
with torch.no_grad():
feats = model(image.unsqueeze(0)).cpu().numpy()
x_all[i] = feats
else:
# this happens if the point is close to the edge of a scene
# (one or both of the spatial dimensions of the image are very small)
pass
else:
pass # this happens if we do not find a S2 scene for some point
if i % 1000 == 0:
print(
f"{i}/{points.shape[0]} -- {i / points.shape[0] * 100:0.2f}%"
+ f" -- {time.time()-tic:0.2f} seconds"
)
tic = time.time()
i += 1
0/67922 -- 0.00% -- 2.14 seconds 1000/67922 -- 1.47% -- 9.83 seconds 2000/67922 -- 2.94% -- 10.77 seconds 3000/67922 -- 4.42% -- 8.54 seconds 4000/67922 -- 5.89% -- 9.70 seconds 5000/67922 -- 7.36% -- 10.22 seconds 6000/67922 -- 8.83% -- 9.24 seconds 7000/67922 -- 10.31% -- 8.40 seconds 8000/67922 -- 11.78% -- 10.03 seconds 9000/67922 -- 13.25% -- 10.12 seconds 10000/67922 -- 14.72% -- 7.72 seconds 11000/67922 -- 16.20% -- 8.70 seconds 12000/67922 -- 17.67% -- 9.44 seconds 13000/67922 -- 19.14% -- 9.63 seconds 14000/67922 -- 20.61% -- 8.08 seconds 15000/67922 -- 22.08% -- 6.65 seconds 16000/67922 -- 23.56% -- 7.16 seconds 17000/67922 -- 25.03% -- 9.23 seconds 18000/67922 -- 26.50% -- 8.26 seconds 19000/67922 -- 27.97% -- 7.38 seconds 20000/67922 -- 29.45% -- 9.18 seconds 21000/67922 -- 30.92% -- 8.15 seconds 22000/67922 -- 32.39% -- 6.03 seconds 23000/67922 -- 33.86% -- 6.42 seconds 24000/67922 -- 35.33% -- 7.21 seconds 25000/67922 -- 36.81% -- 4.22 seconds 26000/67922 -- 38.28% -- 5.08 seconds 27000/67922 -- 39.75% -- 5.04 seconds 28000/67922 -- 41.22% -- 6.26 seconds 29000/67922 -- 42.70% -- 7.31 seconds 30000/67922 -- 44.17% -- 9.81 seconds 31000/67922 -- 45.64% -- 9.71 seconds 32000/67922 -- 47.11% -- 8.95 seconds 33000/67922 -- 48.59% -- 8.53 seconds 34000/67922 -- 50.06% -- 8.38 seconds 35000/67922 -- 51.53% -- 9.55 seconds 36000/67922 -- 53.00% -- 8.56 seconds 37000/67922 -- 54.47% -- 7.19 seconds 38000/67922 -- 55.95% -- 7.69 seconds 39000/67922 -- 57.42% -- 6.36 seconds 40000/67922 -- 58.89% -- 6.36 seconds 41000/67922 -- 60.36% -- 6.68 seconds 42000/67922 -- 61.84% -- 6.39 seconds 43000/67922 -- 63.31% -- 3.95 seconds 44000/67922 -- 64.78% -- 6.06 seconds 45000/67922 -- 66.25% -- 5.87 seconds 46000/67922 -- 67.72% -- 5.54 seconds 47000/67922 -- 69.20% -- 9.00 seconds 48000/67922 -- 70.67% -- 7.76 seconds 49000/67922 -- 72.14% -- 7.21 seconds 50000/67922 -- 73.61% -- 7.46 seconds 51000/67922 -- 75.09% -- 6.69 seconds 52000/67922 -- 76.56% -- 7.35 seconds 53000/67922 -- 78.03% -- 7.03 seconds 54000/67922 -- 79.50% -- 7.80 seconds 55000/67922 -- 80.98% -- 6.92 seconds 56000/67922 -- 82.45% -- 7.41 seconds 57000/67922 -- 83.92% -- 6.12 seconds 58000/67922 -- 85.39% -- 6.56 seconds 59000/67922 -- 86.86% -- 6.69 seconds 60000/67922 -- 88.34% -- 8.39 seconds 61000/67922 -- 89.81% -- 10.02 seconds 62000/67922 -- 91.28% -- 8.55 seconds 63000/67922 -- 92.75% -- 8.21 seconds 64000/67922 -- 94.23% -- 7.93 seconds 65000/67922 -- 95.70% -- 6.39 seconds 66000/67922 -- 97.17% -- 8.39 seconds 67000/67922 -- 98.64% -- 8.02 seconds
Use the extracted features and given labels to model population density as a function of imagery¶
We split the available data 80/20 into train/test. We use a cross-validation approach to tune the regularization parameter of a Ridge regression model, then apply the model to the test data and measure the R2.
y_all = population_log.copy()
x_all.shape, y_all.shape
((67922, 1024), (67922,))
And one final masking -- any sample that has all zeros for features means that we were unsuccessful at extracting features for that point.
nofeature_mask = ~(x_all.sum(axis=1) == 0)
x_all = x_all[nofeature_mask]
y_all = y_all[nofeature_mask]
x_all.shape, y_all.shape
((67922, 1024), (67922,))
x_train, x_test, y_train, y_test = train_test_split(
x_all, y_all, test_size=0.2, random_state=0
)
ridge_cv_random = RidgeCV(cv=5, alphas=np.logspace(-8, 8, base=10, num=17))
ridge_cv_random.fit(x_train, y_train)
RidgeCV(alphas=array([1.e-08, 1.e-07, 1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01,
1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06, 1.e+07,
1.e+08]),
cv=5)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RidgeCV(alphas=array([1.e-08, 1.e-07, 1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01,
1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06, 1.e+07,
1.e+08]),
cv=5)print(f"Validation R2 performance {ridge_cv_random.best_score_:0.2f}")
Validation R2 performance 0.55
y_pred = np.maximum(ridge_cv_random.predict(x_test), 0)
plt.figure()
plt.scatter(y_pred, y_test, alpha=0.2, s=4)
plt.xlabel("Predicted", fontsize=15)
plt.ylabel("Ground Truth", fontsize=15)
plt.title(r"$\log_{10}(1 + $people$/$km$^2)$", fontsize=15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.xlim([0, 6])
plt.ylim([0, 6])
plt.text(
0.5,
5,
s="R$^2$ = %0.2f" % (r2_score(y_test, y_pred)),
fontsize=15,
fontweight="bold",
)
m, b = np.polyfit(y_pred, y_test, 1)
plt.plot(y_pred, m * y_pred + b, color="black")
plt.gca().spines.right.set_visible(False)
plt.gca().spines.top.set_visible(False)
plt.show()
plt.close()
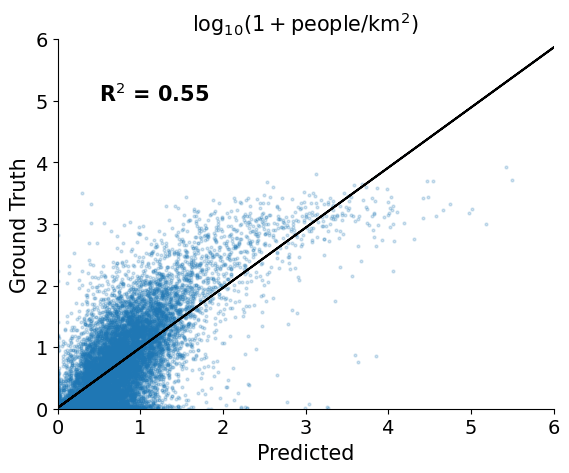
In addition to a R$^2$ value of ~0.55 on the test points, we can see that we have a rank-order correlation (spearman's r) of 0.66.
spearmanr(y_pred, y_test)
SpearmanrResult(correlation=0.6683500144093596, pvalue=0.0)
Spatial extrapolation¶
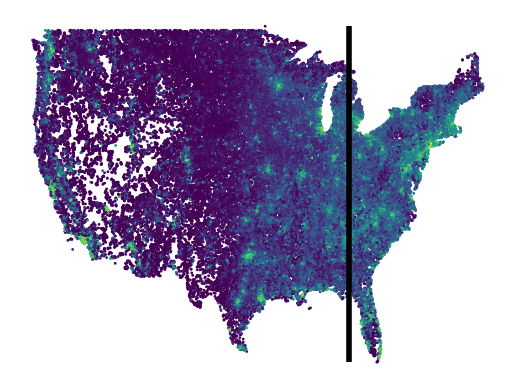
In the previous section we split the points randomly and found that our model can interpolate population density with an R2 of 0.55, however this result does not say anything about how well the model will extrapolate. Whenever you are modeling spatio-temporal data it is important to consider what the model is doing as well as the purpose of the model, then evaluate it appropriately. Here, we test how our modeling approach above is able to extrapolate to areas that it has not been trained on. Specifically we train the linear model with data from the western portion of the US then test it on data from the eastern US and interpret the results.
points = points[nofeature_mask]
First we calculate the 80th percentile longitude of the points in our dataset. Points that are to the west of this value will be in our training split and points to the east of this will be in our testing split.
split_lon = np.percentile(points[:, 0], 80)
train_idxs = np.where(points[:, 0] <= split_lon)[0]
test_idxs = np.where(points[:, 0] > split_lon)[0]
x_train = x_all[train_idxs]
x_test = x_all[test_idxs]
y_train = y_all[train_idxs]
y_test = y_all[test_idxs]
Visually, the split looks like this:
plt.figure()
plt.scatter(points[:, 0], points[:, 1], c=y_all, s=1)
plt.vlines(
split_lon,
ymin=points[:, 1].min(),
ymax=points[:, 1].max(),
color="black",
linewidth=4,
)
plt.axis("off")
plt.show()
plt.close()
ridge_cv = RidgeCV(cv=5, alphas=np.logspace(-8, 8, base=10, num=17))
ridge_cv.fit(x_train, y_train)
RidgeCV(alphas=array([1.e-08, 1.e-07, 1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01,
1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06, 1.e+07,
1.e+08]),
cv=5)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RidgeCV(alphas=array([1.e-08, 1.e-07, 1.e-06, 1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01,
1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06, 1.e+07,
1.e+08]),
cv=5)We can see that our validation performance is similar to that of the random split:
print(f"Validation R2 performance {ridge_cv.best_score_:0.2f}")
Validation R2 performance 0.14
However, our test R$^2$ is much lower, 0.13 compared to 0.55. This shows that the linear model trained on MOSAIKS features and population data sampled from the western US is not able to predict the population density in the eastern US as well. However, from the scatter plot we can see that the predictions aren't random which warrants further investigation...
y_pred = np.maximum(ridge_cv.predict(x_test), 0)
plt.figure()
plt.scatter(y_pred, y_test, alpha=0.2, s=4)
plt.xlabel("Predicted", fontsize=15)
plt.ylabel("Ground Truth", fontsize=15)
plt.title(r"$\log_{10}(1 + $people$/$km$^2)$", fontsize=15)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
plt.xlim([0, 6])
plt.ylim([0, 6])
plt.text(
0.5,
5,
s="R$^2$ = %0.2f" % (r2_score(y_test, y_pred)),
fontsize=15,
fontweight="bold",
)
m, b = np.polyfit(y_pred, y_test, 1)
plt.plot(y_pred, m * y_pred + b, color="black")
plt.gca().spines.right.set_visible(False)
plt.gca().spines.top.set_visible(False)
plt.show()
plt.close()
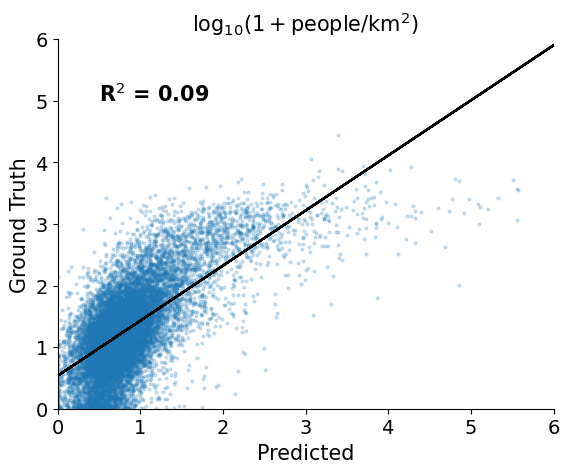
The rank-order correlation is still high, 0.61 compared to 0.66 from the random split. This shows that the model is still able to correctly order the density of input points, however is wrong about the magnitude of the population densities.
spearmanr(y_test, y_pred)
SpearmanrResult(correlation=0.615843938172293, pvalue=0.0)
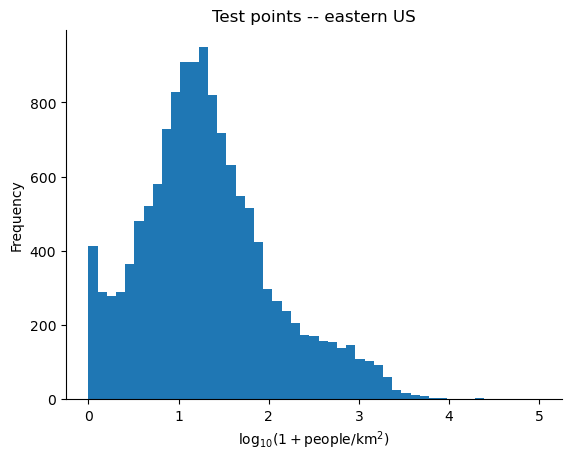
This makes sense when we compare the distributions of population density of points from the western US to that of the eastern US -- the label distributions are completely different. The distribution of MOSAIKS features likely doesn't change, however the mapping between these features and population density definitely varies with space.
bins = np.linspace(0, 5, num=50)
plt.figure()
plt.hist(y_train, bins=bins)
plt.ylabel("Frequency")
plt.xlabel(r"$\log_{10}(1 + $people$/$km$^2)$")
plt.title("Train points -- western US")
plt.gca().spines.right.set_visible(False)
plt.gca().spines.top.set_visible(False)
plt.show()
plt.close()
plt.figure()
plt.hist(y_test, bins=bins)
plt.ylabel("Frequency")
plt.xlabel(r"$\log_{10}(1 + $people$/$km$^2)$")
plt.title("Test points -- eastern US")
plt.gca().spines.right.set_visible(False)
plt.gca().spines.top.set_visible(False)
plt.show()
plt.close()
Estimating the relative population density of points from the corresponding imagery is still useful in a wide variety of applications, e.g. in disaster response settings it might make sense to allocate the most resources to the most densely populated locations, where the precise density isn't as important.