Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.
Deployment of a model to an Azure Container Instance (ACI)¶

1. Introduction ¶
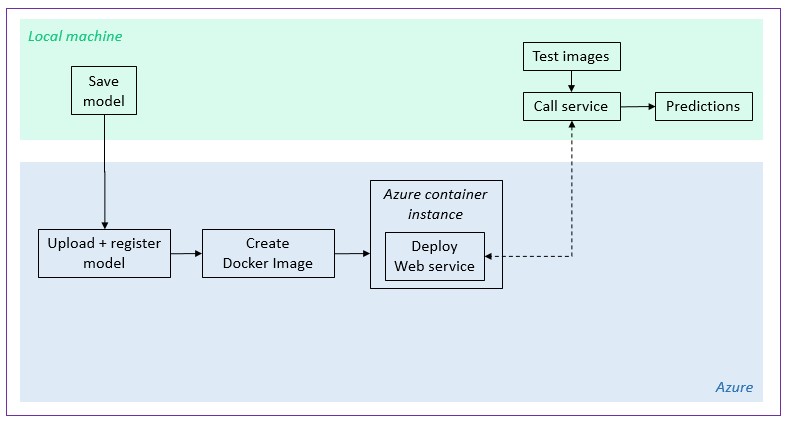
While building a good performing model is important, for it to be useful, it needs to be accessible. In this notebook, we will learn how to make this possible by deploying our model onto Azure. We will more particularly see how to:
- Register a model there
- Create a Docker image that contains our model
- Deploy a web service on Azure Container Instances using this Docker image.
Pre-requisites ¶
For this notebook to run properly on our machine, an Azure workspace is required. If we don't have one, we need to first run through the short 20_azure_workspace_setup.ipynb notebook to create it.
Library import ¶
Throughout this notebook, we will be using a variety of libraries. We are listing them here for better readibility.
# For automatic reloading of modified libraries
%reload_ext autoreload
%autoreload 2
# Regular python libraries
import os
import sys
# fast.ai
from fastai.vision import models
# Azure
import azureml.core
from azureml.core import Experiment, Workspace
from azureml.core.image import ContainerImage
from azureml.core.model import Model
from azureml.core.webservice import AciWebservice, Webservice
from azureml.exceptions import WebserviceException
# Computer Vision repository
sys.path.extend([".", "../.."])
# This "sys.path.extend()" statement allows us to move up the directory hierarchy
# and access the utils_cv package
from utils_cv.common.deployment import generate_yaml
from utils_cv.common.data import root_path
from utils_cv.classification.model import IMAGENET_IM_SIZE, model_to_learner
# Check core SDK version number
print(f"Azure ML SDK Version: {azureml.core.VERSION}")
Azure ML SDK Version: 1.0.48
2. Model retrieval and export ¶
For demonstration purposes, we will use here a ResNet18 model, pretrained on ImageNet. The following steps would be the same if we had trained a model locally (cf. 01_training_introduction.ipynb notebook for details).
Let's first retrieve the model.
learn = model_to_learner(models.resnet18(pretrained=True), IMAGENET_IM_SIZE)
To be able to use this model, we need to export it to our local machine. We store it in an outputs/ subfolder.
output_folder = os.path.join(os.getcwd(), 'outputs')
model_name = 'im_classif_resnet18' # Name we will give our model both locally and on Azure
pickled_model_name = f'{model_name}.pkl'
os.makedirs(output_folder, exist_ok=True)
learn.export(os.path.join(output_folder, pickled_model_name))
To create or access an Azure ML Workspace, you will need the following information. If you are coming from previous notebook you can retreive existing workspace, or create a new one if you are just starting with this notebook.
- subscription ID: the ID of the Azure subscription we are using
- resource group: the name of the resource group in which our workspace resides
- workspace region: the geographical area in which our workspace resides (e.g. "eastus2" -- other examples are ---available here -- note the lack of spaces)
- workspace name: the name of the workspace we want to create or retrieve.
subscription_id = "YOUR_SUBSCRIPTION_ID"
resource_group = "YOUR_RESOURCE_GROUP_NAME"
workspace_name = "YOUR_WORKSPACE_NAME"
workspace_region = "YOUR_WORKSPACE_REGION" #Possible values eastus, eastus2 and so on.
3. Model deployment on Azure ¶
3.A Workspace retrieval ¶
In prior notebook notebook, we created a workspace. This is a critical object from which we will build all the pieces we need to deploy our model as a web service. Let's start by retrieving it.
# A util method that creates a workspace or retrieves one if it exists, also takes care of Azure Authentication
from utils_cv.common.azureml import get_or_create_workspace
ws = get_or_create_workspace(
subscription_id,
resource_group,
workspace_name,
workspace_region)
# Print the workspace attributes
print('Workspace name: ' + ws.name,
'Workspace region: ' + ws.location,
'Subscription id: ' + ws.subscription_id,
'Resource group: ' + ws.resource_group, sep = '\n')
WARNING - Warning: Falling back to use azure cli login credentials. If you run your code in unattended mode, i.e., where you can't give a user input, then we recommend to use ServicePrincipalAuthentication or MsiAuthentication. Please refer to aka.ms/aml-notebook-auth for different authentication mechanisms in azureml-sdk.
Workspace name: amlnotebookws Workspace region: eastus Resource group: amlnotebookrg
3.B Model registration ¶
Our final goal is to deploy our model as a web service. To do so, we need to first register it in our workspace, i.e. place it in our workspace's model registry. We can do this in 2 ways:
- register the model directly
- upload the model on Azure and then register it there.
The advantage of the first method is that it does not require the setup of an experiment or of any runs. The advantage of the second fashion is that we can keep track of the models that we used or trained in a given experiment, and understand where the ones we ended up registering come from.
The cells below show each of the methods.
Without experiment ¶
We leverage the register method from the Azure ML Model object. For that, we just need the location of the model we saved on our local machine, its name and our workspace object.
model = Model.register(
model_path = os.path.join('outputs', pickled_model_name),
model_name = model_name,
tags = {"Model": "Pretrained ResNet18"},
description = "Image classifier",
workspace = ws
)
Registering model im_classif_resnet18
With an experiment ¶
An experiment contains a series of trials called Runs. A run typically contains some tasks, such as training a model, etc. Through a run's methods, we can log several metrics such as training and test loss and accuracy, and even tag our run. The full description of the run class is available here. In our case, however, we just need the run to attach our model file to our workspace and experiment.
We do this by using run.upload_file() and run.register_model(), which takes:
- a
model_namethat represents what our model does - and the
model_pathrelative to the run.
Using run.upload_file() and specifying the outputs/ folder allows us to check the presence of the uploaded model on the Azure portal. This is especially convenient when we want to try different versions of a model, or even different models entirely, and keep track of them all, even if we end up registering only the best performing one.
Let's first create a new experiment. If an experiment with the same name already exists in our workspace, the run we will generate will be recorded under that already existing experiment.
# Create a new/Retrieve an existing experiment
experiment_name = 'image-classifier-webservice'
experiment = Experiment(workspace=ws, name=experiment_name)
print(f"New/Existing experiment:\n \
--> Name: {experiment.name}\n \
--> Workspace name: {experiment.workspace.name}")
New/Existing experiment:
--> Name: image-classifier-webservice
--> Workspace name: amlnotebookws
# Initialize the run
run = experiment.start_logging(snapshot_directory=None)
# "snapshot_directory=None" prevents a snapshot from being saved -- this helps keep the amount of storage used low
Now that we have launched our run, we can see our experiment on the Azure portal, under Experiments (in the left-hand side list).
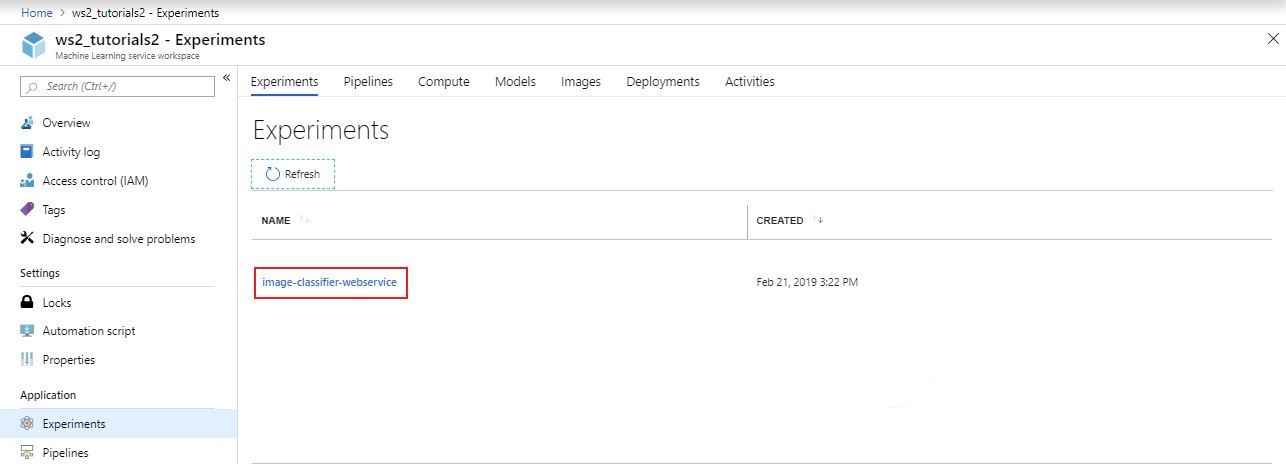
We can now attach our local model to our workspace and experiment.
# Upload the model (.pkl) file to Azure
run.upload_file(
name=os.path.join('outputs', pickled_model_name),
path_or_stream=os.path.join(os.getcwd(), 'outputs', pickled_model_name)
)
<azureml._restclient.models.batch_artifact_content_information_dto.BatchArtifactContentInformationDto at 0x1a2e939c88>
# Register the model with the workspace
model = run.register_model(
model_name=model_name,
model_path=os.path.join('outputs', pickled_model_name),
tags = {"Model": "Pretrained ResNet18"},
)
# !!! We need to make sure that the model name we use here is the same as in the scoring script below !!!
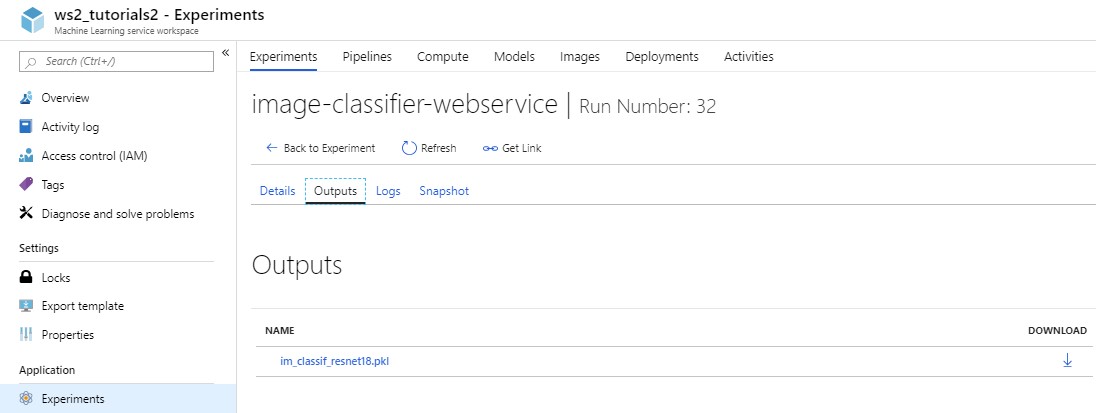
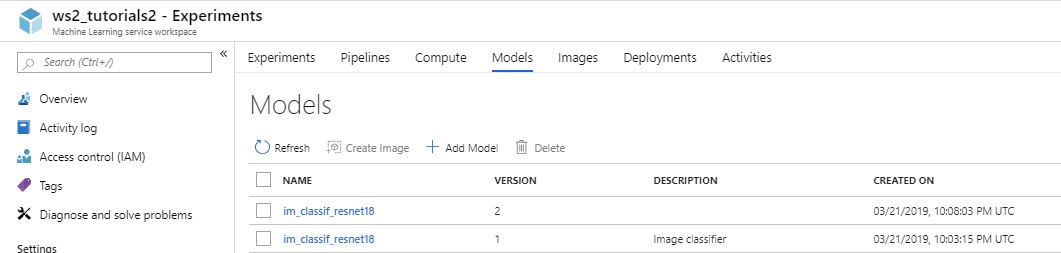
Now that the model is uploaded and registered, we can see it on the Azure platform, under Outputs and Models
We can also check that it is programatically accessible
print(f"Model:\n --> Name: {model.name}\n \
--> ID: {model.id}\n \
--> Path:{model._get_model_path_remote(model.name, model.version, ws)}")
Model:
--> Name: im_classif_resnet18
--> ID: im_classif_resnet18:8
--> Path:azureml-models/im_classif_resnet18/8/im_classif_resnet18.pkl
run.get_file_names()
['outputs/im_classif_resnet18.pkl']
If we are also interested in verifying which model we uploaded, we can download it to our local machine
model.download(exist_ok=True)
'im_classif_resnet18.pkl'
Note: If we ran the cells in both the "with an experiment" and "without experiment" sections, we got 2 iterations of the same model registered on Azure. This is not a problem as any operation that we perform on the "model" object, later on, will be associated with the latest version of the model that we registered. To clean things up, we can go to the portal, select the model we do not want and click the "Delete" button. In general, we would register the model using only one of these 2 methods.
We are all done with our model registration, so we can close our run.
# Close the run
run.complete()
# Access the portal
run
| Experiment | Id | Type | Status | Details Page | Docs Page |
|---|---|---|---|---|---|
| image-classifier-webservice | 58a22e83-11da-4062-b8ca-0d140fa176e5 | Running | Link to Azure Portal | Link to Documentation |
3.C Scoring script ¶
For the web service to return predictions on a given input image, we need to provide it with instructions on how to use the model we just registered. These instructions are stored in the scoring script.
This script must contain two required functions, init() and run(input_data):
- In the
init()function, we typically load the model into a global object. This function is executed only once when the Docker container is started. - In the
run(input_data)function, the model is used to predict a value based on the input data. The input and output ofruntypically use JSON as serialization and de-serialization format but we are not limited to that.
Note: The "run()" function here is different from the "run" object we created in our experiment
This file must also be stored in the current directory.
scoring_script = "score.py"
%%writefile $scoring_script
# Copyright (c) Microsoft. All rights reserved.
# Licensed under the MIT license.
import os
import json
from base64 import b64decode
from io import BytesIO
from azureml.core.model import Model
from fastai.vision import load_learner, open_image
def init():
global model
model_path = Model.get_model_path(model_name='im_classif_resnet18')
# ! We cannot use the *model_name* variable here otherwise the execution on Azure will fail !
model_dir_path, model_filename = os.path.split(model_path)
model = load_learner(path=model_dir_path, fname=model_filename)
def run(raw_data):
# Expects raw_data to be a list within a json file
result = []
for im_string in json.loads(raw_data)['data']:
im_bytes = b64decode(im_string)
try:
im = open_image(BytesIO(im_bytes))
pred_class, pred_idx, outputs = model.predict(im)
result.append({"label": str(pred_class), "probability": str(outputs[pred_idx].item())})
except Exception as e:
result.append({"label": str(e), "probability": ''})
return result
Overwriting score.py
3.D Environment setup ¶
In order to make predictions on the Azure platform, it is important to create an environment as similar as possible to the one in which the model was trained. Here, we use a fast.ai pretrained model that also requires pytorch and a few other libraries. To re-create this environment, we use a Docker container. We configure it via a yaml file that will contain all the conda dependencies needed by the model. This yaml file is a subset of <repo_root>/classification/environment.yml.
# Create a deployment-specific yaml file from classification/environment.yml
try:
generate_yaml(
directory=os.path.join(root_path()),
ref_filename='environment.yml',
needed_libraries=['pytorch', 'spacy', 'fastai', 'dataclasses'],
conda_filename='myenv.yml'
)
# Note: Take a look at the generate_yaml() function for details on how to create your yaml file from scratch
except FileNotFoundError:
raise FileNotFoundError("The *environment.yml* file is missing - Please make sure to retrieve it from the github repository")
# Conda environment specification. The dependencies defined in this file will
# be automatically provisioned for runs with userManagedDependencies=False.
# Details about the Conda environment file format:
# https://conda.io/docs/user-guide/tasks/manage-environments.html#create-env-file-manually
name: project_environment
dependencies:
# The python interpreter version.
# Currently Azure ML only supports 3.5.2 and later.
- python=3.6.2
- pip:
# Required packages for AzureML execution, history, and data preparation.
- azureml-defaults
- pytorch==1.0.0
- fastai==1.0.48
- spacy
- dataclasses
channels:
- conda-forge
- defaults
- pytorch
- fastai
There are different ways of creating a Docker image on Azure. Here, we create it separately from the service it will be used by. This way of proceeding gives us direct access to the Docker image object. Thus, if the service deployment fails, but the Docker image gets deployed successfully, we can try deploying the service again, without having to create a new image all over again.
# Configure the Docker image
try:
image_config = ContainerImage.image_configuration(
execution_script = "score.py",
runtime = "python",
conda_file = "myenv.yml",
description = "Image with fast.ai Resnet18 model (fastai 1.0.48)",
tags = {'training set': "ImageNet",
'architecture': "CNN ResNet18",
'type': 'Pretrained'}
)
except WebserviceException:
raise FileNotFoundError("The files *score.py* and/or *myenv.yaml* could not be found - Please run the cells above again")
# Create the Docker image
try:
docker_image = ContainerImage.create(
name = "image-classif-resnet18-f48",
models = [model],
image_config = image_config,
workspace = ws
)
# The image name should not contain more than 32 characters, and should not contain any spaces, dots or underscores
except WebserviceException:
raise FileNotFoundError("The files *score.py* and/or *myenv.yaml* could not be found - Please run the cells above again")
Creating image
%%time
docker_image.wait_for_creation(show_output = True) # This can take up to 12 min
Running....................................................................................................................................... Succeeded Image creation operation finished for image image-classif-resnet18-f48:2, operation "Succeeded" CPU times: user 980 ms, sys: 192 ms, total: 1.17 s Wall time: 11min 35s
When the image gets successfully created, we expect to see:
Creating image Running ..... SucceededImage creation operation finished for image <docker_image_name>, operation "Succeeded" Wall time: Xmin
It happens, sometimes, that the deployment of the Docker image fails. Re-running the previous command typically solves the problem. If it doesn't, however, we can run the following one and inspect the deployment logs.
print(ws.images["image-classif-resnet18-f48"].image_build_log_uri)
https://amlnotebstorage914c3d2fd.blob.core.windows.net/azureml/ImageLogs/1a39d9e5-6432-4a4b-95ec-13211a811a60/build.log?sv=2018-03-28&sr=b&sig=kjIXAcI69WUzWofD77LKHotev2f%2BQhXjoHyBEBEkqZU%3D&st=2019-07-18T17%3A58%3A03Z&se=2019-08-17T18%3A03%3A03Z&sp=rl
3.E Computational resources ¶
In this notebook, we use Azure Container Instances (ACI) which are good for quick and cost-effective development/test deployment scenarios.
To set them up properly, we need to indicate the number of CPU cores and the amount of memory we want to allocate to our web service. Optional tags and descriptions are also available for us to identify the instances in AzureML when looking at the Compute tab in the Azure Portal. We also enable monitoring, through the enable_app_insights parameter. Once our web app is up and running, this will allow us to measure the amount of traffic it gets, how long it takes to respond, the type of exceptions that get raised, etc. We will do so through Application Insights, which is an application performance management service.
Note: For production workloads, it is better to use Azure Kubernetes Service (AKS) instead. We will demonstrate how to do this in the next notebook.
# Create a deployment configuration with 1 CPU and 5 gigabytes of RAM, and add monitoring to it
aci_config = AciWebservice.deploy_configuration(
cpu_cores=1,
memory_gb=5,
enable_app_insights=True,
tags={'webservice': 'image classification model (fastai 1.0.48)'},
description='This service classifies images into 1000 different groups.'
)
3.F Web service deployment ¶
The final step to deploying our web service is to call WebService.deploy_from_image(). This function uses the Docker image and the deployment configuration we created above to perform the following:
- Deploy the docker image to an Azure Container Instance
- Call the
init()function in our scoring file - Provide an HTTP endpoint for scoring calls
The deploy_from_image method requires the following parameters:
- workspace: the workspace containing the service
- name: a unique name used to identify the service in the workspace
- image: a docker image object that contains the environment needed for scoring/inference
- deployment_config: a configuration object describing the compute type
Azure Container Instances have no associated ComputeTarget, so we do not specify any here. Remember, we already provided information on the number of CPUs and the amount of memory needed in the service configuration file above.
Note: The web service creation can take a few minutes
# Define how to deploy the web service
service_name = 'im-classif-websvc'
service = Webservice.deploy_from_image(
workspace=ws,
name=service_name,
image=docker_image,
deployment_config=aci_config
)
Creating service
An alternative way of deploying the service is to deploy from the model directly. In that case, we would need to provide the docker image configuration object (image_config), and our list of models (just one of them here).
The advantage of deploy_from_image over deploy_from_model is that the former allows us
to re-use the same Docker image in case the deployment of this service fails, or even for other
types of deployments, as we will see in the next notebook.
# Deploy the web service
service.wait_for_deployment(show_output=True)
Running............................................ SucceededACI service creation operation finished, operation "Succeeded"
When successful, we expect to see the following:
Creating service Running ..... SucceededACI service creation operation finished, operation "Succeeded"
In the case where the deployment is not successful, we can look at the image and service logs to debug. These instructions can also be helpful.
# Access the service logs
# print(service.get_logs())
# Retrieve the service status
print(f"Service {service.name} is _{service.state}_ and available at {service.scoring_uri}")
Service im-classif-websvc is _Healthy_ and available at http://c7bf18e3-cef1-4179-a524-59f862ffa1d9.eastus.azurecontainer.io/score
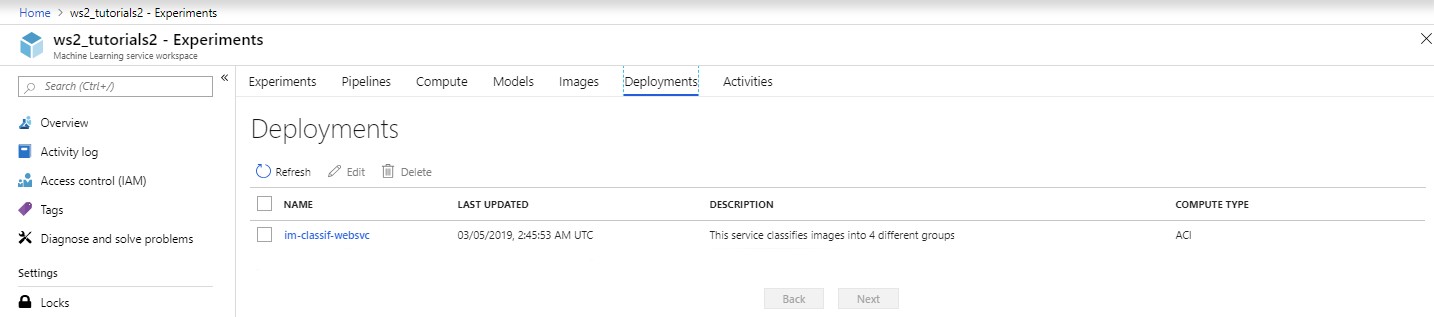
We can also check the presence and status of both our new Docker image and web service on the Azure portal, under the Images and Deployments tabs, respectively.

4. Notes on web service deployment ¶
As we discussed above, Azure Container Instances tend to be used to develop and test deployments. They are typically configured with CPUs, which usually suffice when the number of requests per second is not too high. When working with several instances, we can configure them further by specifically allocating CPU resources to each of them.
For production requirements, i.e. when > 100 requests per second are expected, we recommend deploying models to Azure Kubernetes Service (AKS). It is a convenient infrastructure as it manages hosted Kubernetes environments, and makes it easy to deploy and manage containerized applications without container orchestration expertise. It also supports deployments with CPU clusters and deployments with GPU clusters.
We will see an example of this in the next notebook.
5. Clean up ¶
Throughout the notebook, we used a workspace and Azure container instances. To get a sense of the cost we incurred, we can refer to this calculator. We can also navigate to the Cost Management + Billing pane on the portal, click on our subscription ID, and click on the Cost Analysis tab to check our credit usage.
In order not to incur extra costs, let's delete the resources we no longer need.
Once we have verified that our web service works well on ACI (cf. "Next steps" section below), we can delete it. This helps reduce costs, since the container group we were paying for no longer exists, and allows us to keep our workspace clean.
# service.delete()
At this point, the main resource we are paying for is the Standard Azure Container Registry (ACR), which contains our Docker image. Details on pricing are available here.
We may decide to use our Docker image in a separate ACI or even in an AKS deployment. In that case, we should keep it available in our workspace. However, if we no longer have a use for it, we can delete it.
# docker_image.delete()
If our goal is to continue using our workspace, we should keep it available. On the contrary, if we plan on no longer using it and its associated resources, we can delete it.
Note: Deleting the workspace will delete all the experiments, outputs, models, Docker images, deployments, etc. that we created in that workspace
# ws.delete(delete_dependent_resources=True)
# This deletes our workspace, the container registry, the account storage, Application Insights and the key vault
6. Next steps ¶
In the next tutorial, we will leverage the same Docker image, and deploy our model on AKS. We will then test both of our web services in the 23_aci_aks_web_service_testing.ipynb notebook.