Copyright (c) Microsoft Corporation. All rights reserved.
Licensed under the MIT License.
Hard Negative Sampling for Object Detection¶
You built an object detection model, evaluated it on a test set, and are happy with its accuracy. Now you deploy the model in a real-world application and you may find that the model over-fires heavily, i.e. it detects objects where none are.
This is a common problem in machine learning because our training set only contains a limited number of images, which is not sufficient to model the appearance of every object and every background in the world. Hard negative sampling (or hard negative mining) is a useful technique to address this problem. It is a way to make the model more robust to over-fitting by identifying images which are hard for the model and hence should be added to the training set.
The technique is widely used when one has a large number of negative images however adding all to the training set would cause (i) training to become too slow; and (ii) overwhelm training with too high a ratio of negatives to positives. For many negative images the model likely already performs well and hence adding them to the training set would not improve accuracy. Therefore, we try to identify those negative images where the model is incorrect.
Note that hard-negative mining is a special case of active learning where the task is to identify images which are hard for the model, annotate these images with the ground truth label, and to add them to the training set. Hard could be defined as the model being wrong, or as the model being uncertain about a prediction.
Overview¶
In this notebook, we train our model on a training set T as usual, test the model on un-seen negative candidate images U, and see on which images in U the model over-fires. These images are then introduces into the training set T and the model is re-trained. As dataset, we use the fridge objects images (watter_bottle, carton, can, and milk_bottle), similar to the 01_training_introduction notebook.
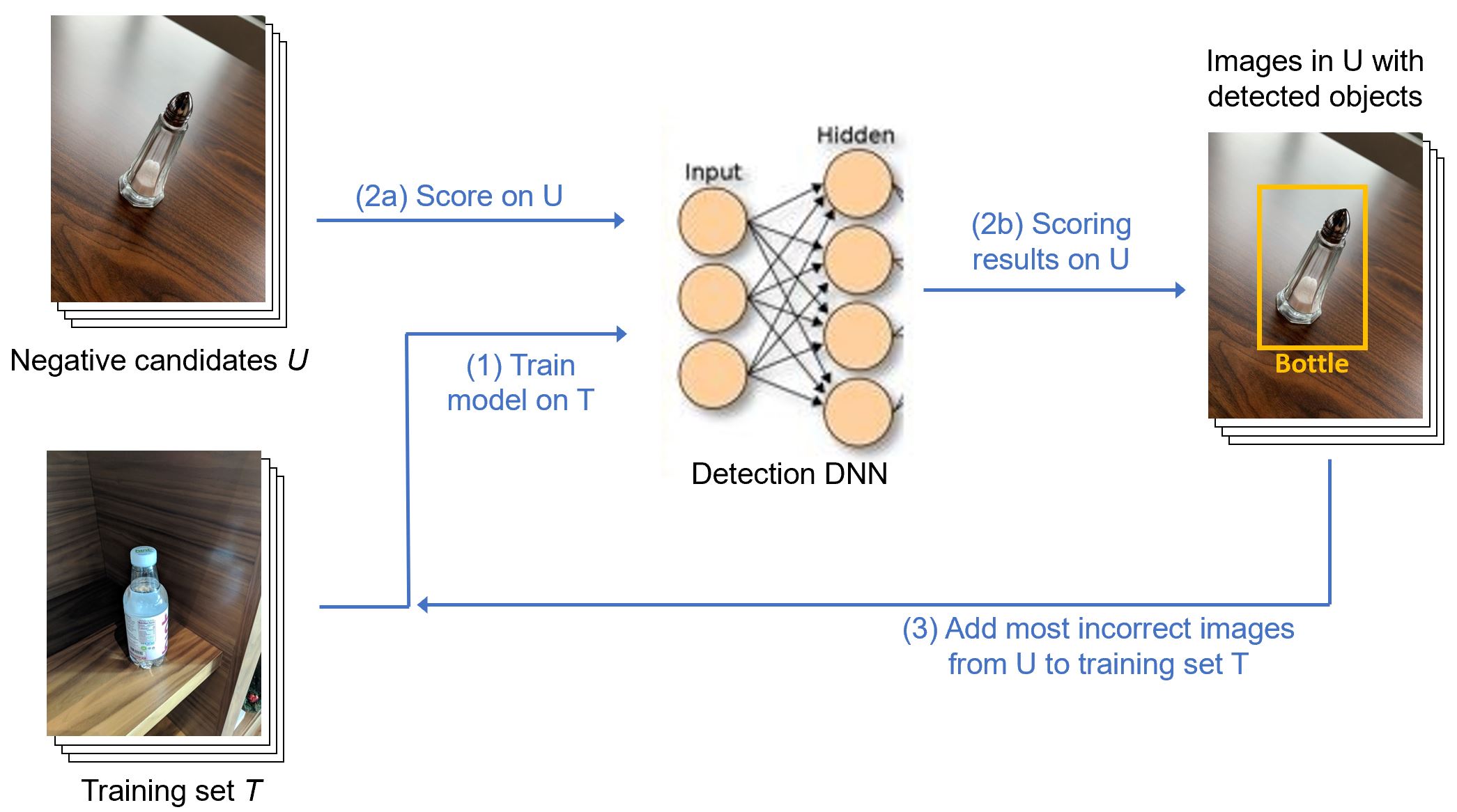
The overall hard negative mining process is as follows:
- First, prepare training set T and negative-candidate set U. A small proportion of both sets are set aside for evaluation.
- Second, load a pre-trained detection model.
- Next, mine hard negatives by following steps as shown in the figure:
- Train the model on T.
- Score the model on U.
- Identify
NEGATIVE_NUMimages in U where the model is most incorrect and add to T.
- Finally, repeat these steps until the model stops improving.
import sys
sys.path.append("../../")
import os
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import scrapbook as sb
import torch
import torchvision
from torchvision import transforms
from utils_cv.classification.data import Urls as UrlsIC
from utils_cv.common.data import unzip_url
from utils_cv.common.gpu import which_processor, is_windows
from utils_cv.detection.data import Urls as UrlsOD
from utils_cv.detection.dataset import DetectionDataset, get_transform
from utils_cv.detection.model import DetectionLearner, get_pretrained_fasterrcnn
from utils_cv.detection.plot import plot_detections, plot_grid
# Change matplotlib backend so that plots are shown on windows machines
if is_windows():
plt.switch_backend('TkAgg')
print(f"TorchVision: {torchvision.__version__}")
which_processor()
TorchVision: 0.4.0 Torch is using GPU: Tesla V100-PCIE-16GB
# Ensure edits to libraries are loaded and plotting is shown in the notebook.
%reload_ext autoreload
%autoreload 2
%matplotlib inline
Default parameters. Choose NEGATIVE_NUM so that the number of negative images to be added at each iteration corresponds to roughly 10-20% of the total number of images in the training set. If NEGATIVE_NUM is too low, then too few hard negatives get added to make a noticeable difference.
# Path to training images, and to the negative images
DATA_PATH = unzip_url(UrlsOD.fridge_objects_path, exist_ok=True)
NEG_DATA_PATH = unzip_url(UrlsIC.fridge_objects_negatives_path, exist_ok=True)
# Number of negative images to add to the training set after each negative mining iteration.
# Here set to 10, but this value should be around 10-20% of the total number of images in the training set.
NEGATIVE_NUM = 10
# Model parameters corresponding to the "fast_inference" parameters in the 03_training_accuracy_vs_speed notebook.
EPOCHS = 10
LEARNING_RATE = 0.005
IM_SIZE = 500
BATCH_SIZE = 2
# Use GPU if available
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
print(f"Using torch device: {device}")
assert str(device)=="cuda", "Model evaluation requires CUDA capable GPU"
Using torch device: cuda
1. Prepare datasets¶
We prepare our datasets in the following way:
- Training images in
data.train_dswhich includes initially only fridge objects images, and after running hard-negative mining also negative images. - Negative candidate images in
neg_data.train_ds. - Test images in
data.test_dsto evaluate accuracy on fridge objects images, and inneg_data.test_dsto evaluate how often the model misfires on images which do not contain an object-of-interest.
# Model training dataset T, split into 75% training and 25% test
data = DetectionDataset(DATA_PATH, train_pct=0.75)
print(f"Positive dataset: {len(data.train_ds)} training images and {len(data.test_ds)} test images.")
# Negative images split into hard-negative mining candidates U, and a negative test set.
# Setting "allow_negatives=True" since the negative images don't have an .xml file with ground truth annotations
neg_data = DetectionDataset(NEG_DATA_PATH, train_pct=0.80, batch_size=BATCH_SIZE,
im_dir = "", allow_negatives = True,
train_transforms = get_transform(train=False))
print(f"Negative dataset: {len(neg_data.train_ds)} candidates for hard negative mining and {len(neg_data.test_ds)} test images.")
Positive dataset: 96 training images and 32 test images. Negative dataset: 52 candidates for hard negative mining and 12 test images.
2. Prepare a model¶
Initialize a pre-trained Faster R-CNN model similar to the 01_training_introduction notebook.
# Pre-trained Faster R-CNN model
detector = DetectionLearner(data, im_size=IM_SIZE)
# Record after each mining iteration the validation accuracy and how many objects were found in the negative test set
valid_accs = []
num_neg_detections = []
3. Train the model on T¶
Model training. As described at the start of this notebook, you likely need to repeat the steps from here until the end of the notebook several times to achieve optimal results.
# Fine-tune model. After each epoch prints the accuracy on the validation set.
detector.fit(EPOCHS, lr=LEARNING_RATE, print_freq=30)
Show the accuracy on the validation set for this and all previous mining iterations.
# Get validation accuracy on test set at IOU=0.5:0.95
acc = float(detector.ap[-1]["bbox"])
valid_accs.append(acc)
# Plot validation accuracy versus number of hard-negative mining iterations
from utils_cv.common.plot import line_graph
line_graph(
values=(valid_accs),
labels=("Validation"),
x_guides=range(len(valid_accs)),
x_name="Hard negative mining iteration",
y_name="mAP@0.5:0.95",
)

4. Score the model on U¶
Run inference on all negative candidate images. The images where the model is most incorrect will later be added as hard negatives to the training set.
detections = detector.predict_dl(neg_data.train_dl, threshold=0)
detections[0]
{'idx': 60,
'det_bboxes': [],
'im_path': 'C:\\Users\\pabuehle\\Desktop\\ComputerVision\\data\\fridgeObjectsNegative\\IMG_1859.jpg'}
Count how many objects were detected in the negative test set. This number typically goes down dramatically after a few mining iterations, and is an indicator how much the model over-fires on unseen images.
# Count number of mis-detections on negative test set
test_detections = detector.predict_dl(neg_data.test_dl, threshold=0)
bbox_scores = [bbox.score for det in test_detections for bbox in det['det_bboxes']]
num_neg_detections.append(len(bbox_scores))
# Plot
from utils_cv.common.plot import line_graph
line_graph(
values=(num_neg_detections),
labels=("Negative test set"),
x_guides=range(len(num_neg_detections)),
x_name="Hard negative mining iteration",
y_name="Number of detections",
)

5. Hard negative mining¶
Use the negative candidate images where the model is most incorrect as hard negatives.
# For each image, get maximum score (i.e. confidence in the detection) over all detected bounding boxes in the image
max_scores = []
for idx, detection in enumerate(detections):
if len(detection['det_bboxes']) > 0:
max_score = max([d.score for d in detection['det_bboxes']])
else:
max_score = float('-inf')
max_scores.append(max_score)
# Use the n images with highest maximum score as hard negatives
hard_im_ids = np.argsort(max_scores)[::-1]
hard_im_ids = hard_im_ids[:NEGATIVE_NUM]
hard_im_scores =[max_scores[i] for i in hard_im_ids]
print(f"Indentified {len(hard_im_scores)} hard negative images with detection scores in range {min(hard_im_scores)} to {max(hard_im_scores):4.2f}")
Indentified 10 hard negative images with detection scores in range -inf to 0.83
Plot some of the identified hard negatives images. This will likely mistake objects which were not part of the training set as the objects-of-interest.
# Get image paths and ground truth boxes for the hard negative images
dataset_ids = [detections[i]['idx'] for i in hard_im_ids]
im_paths = [neg_data.train_ds.dataset.im_paths[i] for i in dataset_ids]
gt_bboxes = [neg_data.train_ds.dataset.anno_bboxes[i] for i in dataset_ids]
# Plot
def _grid_helper():
for i in hard_im_ids:
yield detections[i], neg_data, None, None
plot_grid(plot_detections, _grid_helper(), rows=1)

6. Add hard negatives to T¶
We now add the identified hard negative images to the training set.
# Add identified hard negatives to training set
data.add_images(im_paths, gt_bboxes, target = "train")
print(f"Added {len(im_paths)} hard negative images. Now: {len(data.train_ds)} training images and {len(data.test_ds)} test images")
print(f"Completed {len(valid_accs)} hard negative iterations.")
# Preserve some of the notebook outputs
sb.glue("valid_accs", valid_accs)
sb.glue("hard_im_scores", list(hard_im_scores))
Added 10 hard negative images. Now: 126 training images and 32 test images Completed 3 hard negative iterations.
Repeat¶
Now, repeat all steps starting from "3. Train the model on T" to re-train the model and the training set T with added and add more hard negative images to the training set. Stop once the accuracy valid_accs stopped improving and if the number of (mis)detections in the negative test set num_neg_detections stops decreasing.