Plan real-world action using counterfactual example analysis and causal analysis¶
This notebook demonstrates the use of the Responsible AI Toolbox to make decisions from diabetes progression data. It walks through the API calls necessary to create a widget with causal inferencing insights, then guides a visual analysis of the data.
Launch Responsible AI Toolbox¶
The following section examines the code necessary to create the dataset. It then generates insights using the responsibleai API that can be visually analyzed.
Train a Model¶
The following section can be skipped. It loads a dataset for illustrative purposes.
import shap
import sklearn
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
First, load the diabetes dataset and specify the different types of features. Then, clean it and put it into a DataFrame with named columns.
data = sklearn.datasets.load_diabetes()
target_feature = 'y'
continuous_features = data.feature_names
data_df = pd.DataFrame(data.data, columns=data.feature_names)
After loading and cleaning the data, split the datapoints into training and test sets. Assemble separate datasets for the training and test data.
X_train, X_test, y_train, y_test = train_test_split(data_df, data.target, test_size=0.2, random_state=7)
train_data = X_train.copy()
test_data = X_test.copy()
train_data[target_feature] = y_train
test_data[target_feature] = y_test
data.feature_names
You may define features_to_drop and drop any features from X_train. The model will be trained without features_to_drop. If features_to_drop is not set, X_train_after_drop will be the same as X_train.
features_to_drop = []
X_train_after_drop = X_train.drop(features_to_drop, axis=1)
Train a nearest-neighbors classifier on the training data.
model = RandomForestRegressor(random_state=0)
model.fit(X_train_after_drop, y_train)
Create Model and Data Insights¶
from raiwidgets import ResponsibleAIDashboard
from responsibleai import RAIInsights
To use Responsible AI Toolbox, initialize a RAIInsights object upon which different components can be loaded.
RAIInsights accepts the model, the train dataset, the test dataset, the target feature string and the task type string as its arguments.
You may also create the FeatureMetadata container, identify any feature of your choice as the identity_feature, specify a list of strings of categorical feature names via the categorical_features parameter, and specify dropped features via the dropped_features parameter. The FeatureMetadata may also be passed into the RAIInsights.
from responsibleai.feature_metadata import FeatureMetadata
# Add 's1' as an identity feature, set features_to_drop as dropped features
feature_metadata = FeatureMetadata(identity_feature_name='s1', categorical_features=[], dropped_features=features_to_drop)
rai_insights = RAIInsights(model, train_data, test_data, target_feature, 'regression',
feature_metadata=feature_metadata)
Add the components of the toolbox that are focused on decision-making.
# Counterfactuals: accepts total number of counterfactuals to generate, the range that their label should fall under,
# and a list of strings of categorical feature names
rai_insights.counterfactual.add(total_CFs=20, desired_range=[50, 120])
# Causal Inference: determines causation between features
rai_insights.causal.add(treatment_features=['bmi', 'bp', 's2'])
Once all the desired components have been loaded, compute insights on the test set.
rai_insights.compute()
Compose some cohorts which can be injected into the ResponsibleAIDashboard.
from raiutils.cohort import Cohort, CohortFilter, CohortFilterMethods
# Cohort on age and bmi features in the dataset
cohort_filter_age = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[40],
column='age')
cohort_filter_bmi = CohortFilter(
method=CohortFilterMethods.METHOD_GREATER,
arg=[0],
column='bmi')
user_cohort_age_and_bmi= Cohort(name='Cohort Age and BMI')
user_cohort_age_and_bmi.add_cohort_filter(cohort_filter_age)
user_cohort_age_and_bmi.add_cohort_filter(cohort_filter_bmi)
# Cohort on index
cohort_filter_index = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[20],
column='Index')
user_cohort_index = Cohort(name='Cohort Index')
user_cohort_index.add_cohort_filter(cohort_filter_index)
# Cohort on predicted y values
cohort_filter_predicted_y = CohortFilter(
method=CohortFilterMethods.METHOD_LESS,
arg=[165.0],
column='Predicted Y')
user_cohort_predicted_y = Cohort(name='Cohort Predicted Y')
user_cohort_predicted_y.add_cohort_filter(cohort_filter_predicted_y)
# Cohort on true y values
cohort_filter_true_y = CohortFilter(
method=CohortFilterMethods.METHOD_GREATER,
arg=[45.0],
column='True Y')
user_cohort_true_y = Cohort(name='Cohort True Y')
user_cohort_true_y.add_cohort_filter(cohort_filter_true_y)
# Cohort on true y values
cohort_filter_regression_error = CohortFilter(
method=CohortFilterMethods.METHOD_GREATER,
arg=[20.0],
column='Error')
user_cohort_regression_error = Cohort(name='Cohort Regression Error')
user_cohort_regression_error.add_cohort_filter(cohort_filter_regression_error)
cohort_list = [user_cohort_age_and_bmi,
user_cohort_index,
user_cohort_predicted_y,
user_cohort_true_y,
user_cohort_regression_error]
Finally, visualize and explore the model insights. Use the resulting widget or follow the link to view this in a new tab.
ResponsibleAIDashboard(rai_insights, cohort_list=cohort_list)
Take Real-World Action¶
What-If Counterfactuals Analysis¶
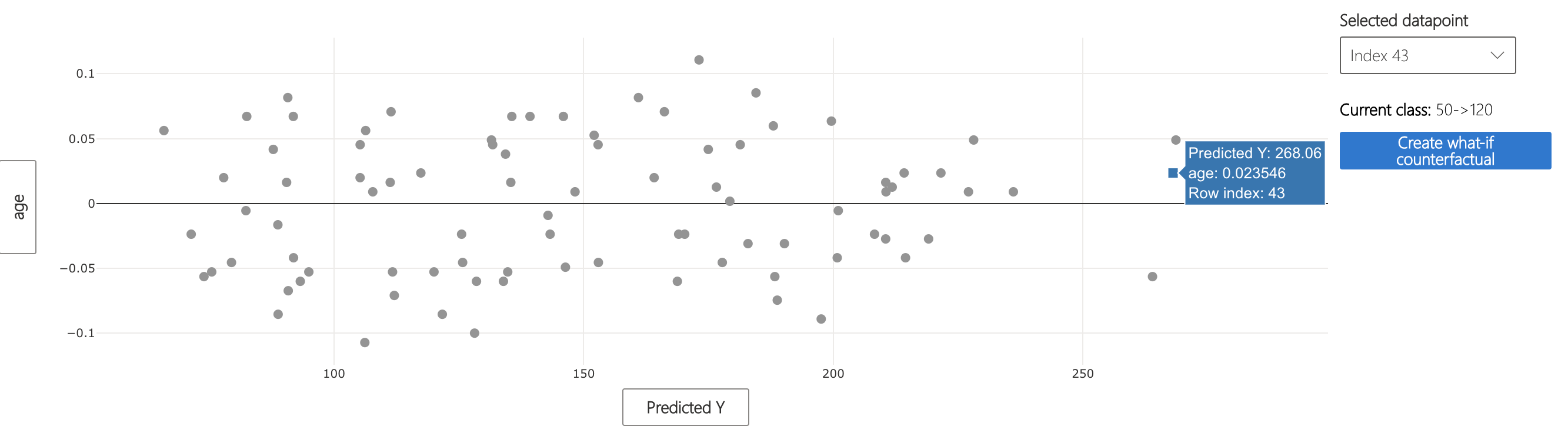
Let's imagine that the diabetes progression scores predicted by the model are used to determine medical insurance rates. If the score is greater than 120, there is a higher rate. Patient 43's model score of 268.08 results in this increased rate, and they want to know how they should change their health to get a lower rate prediction from the model (leading to lower insurance price).
The What-If counterfactuals component shows how slightly different feature values affect model predictions. This can be used to solve Patient 43's problem.
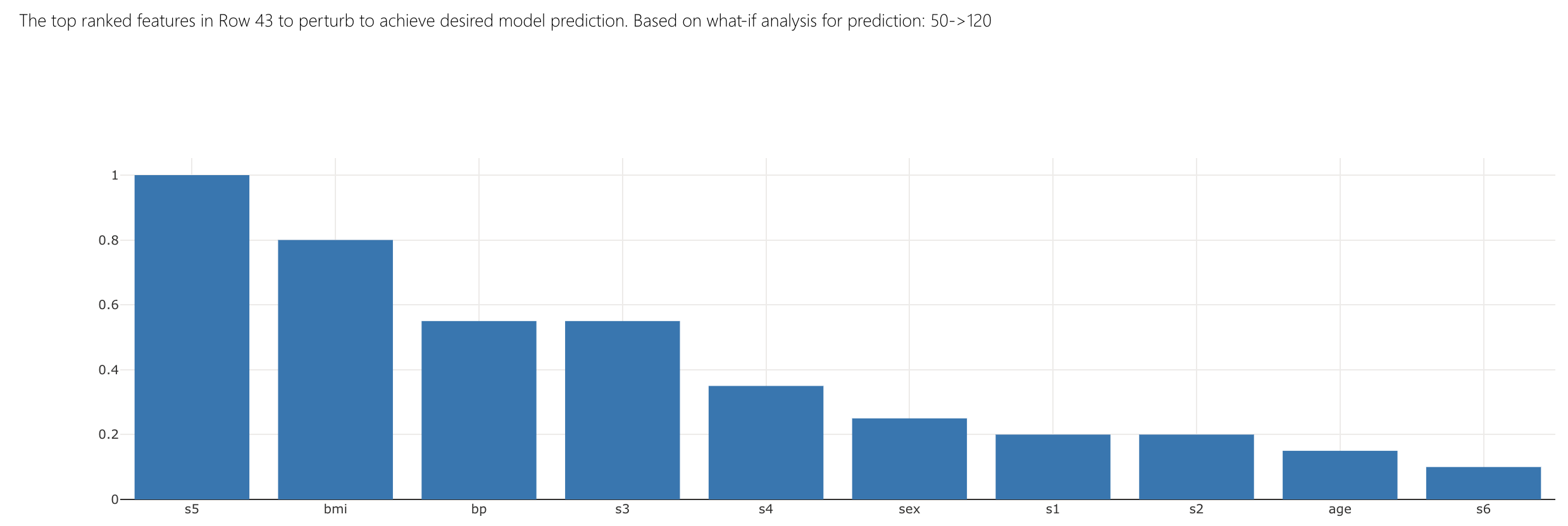
What can Patient 43 do to create the desired change? The top ranked features bar plot shows that bmi and s5 are the best to perturb to bring the model score within 120.
Let's see how that can be achieved. Change bmi to -0.04 and s5 to -0.042 and see what the result is.
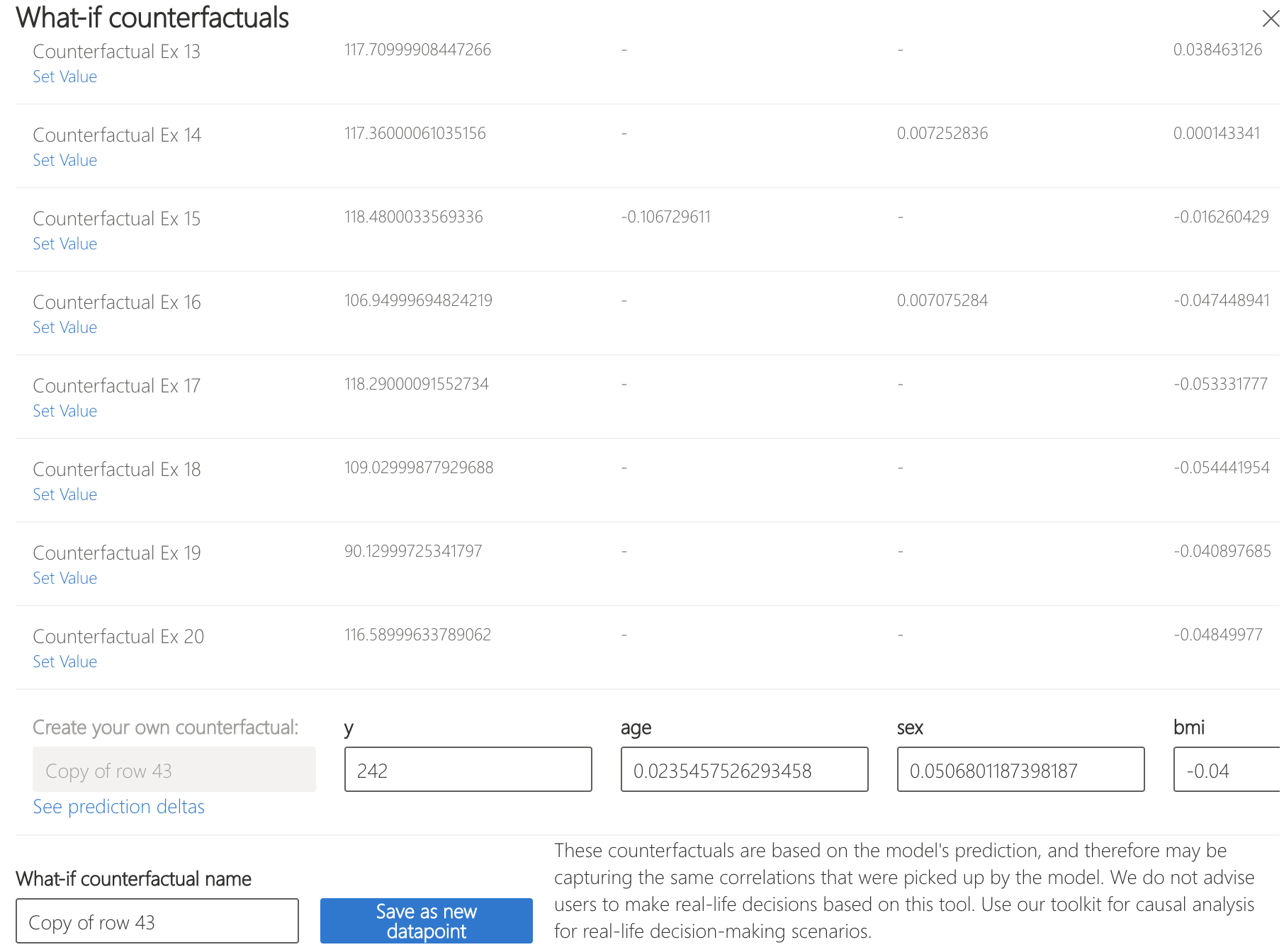
As we can see, the model's prediction has dropped to 131.22. Thus, Patient 43 should work on reducing their body mass index and serum triglycerides level to bring the model score under the insurance threshold.
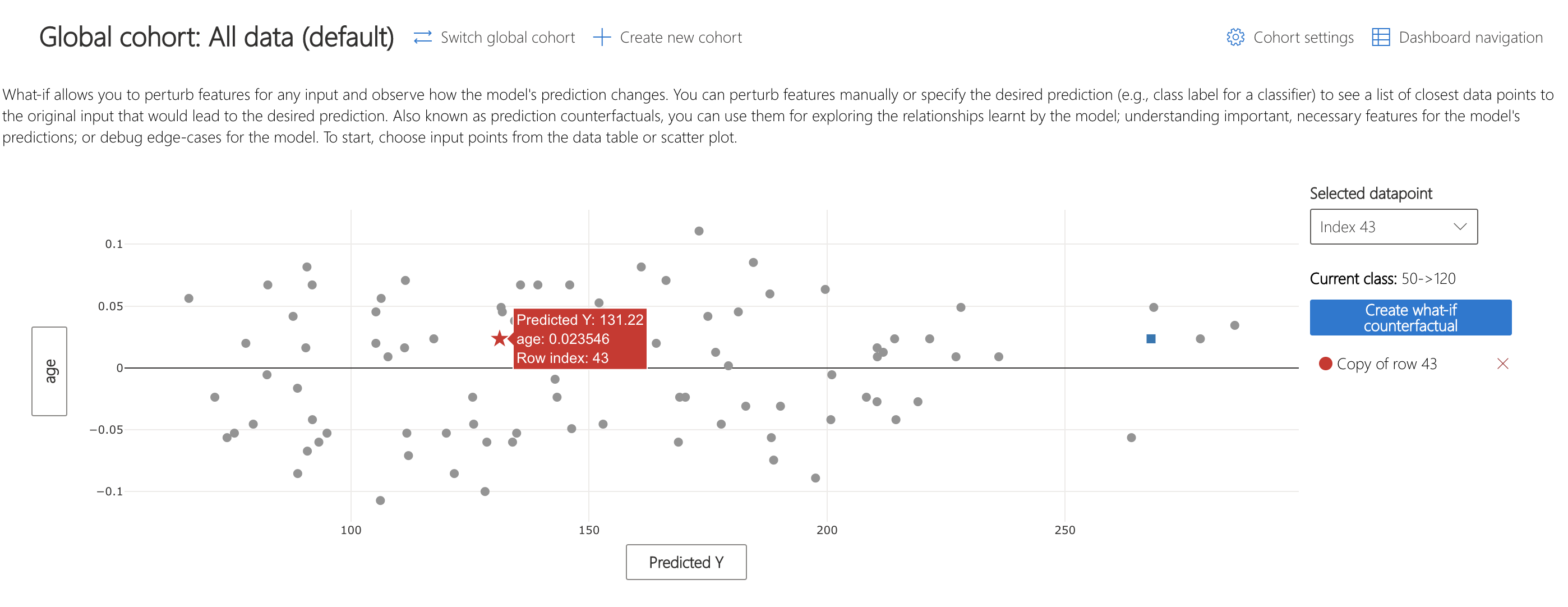
Note that this result does not mean that reducing bmi and s5 causes the diabetes progression score to go down. It simply decreases the model prediction. To investigate causal relationships, continue reading:
Causal Analysis¶
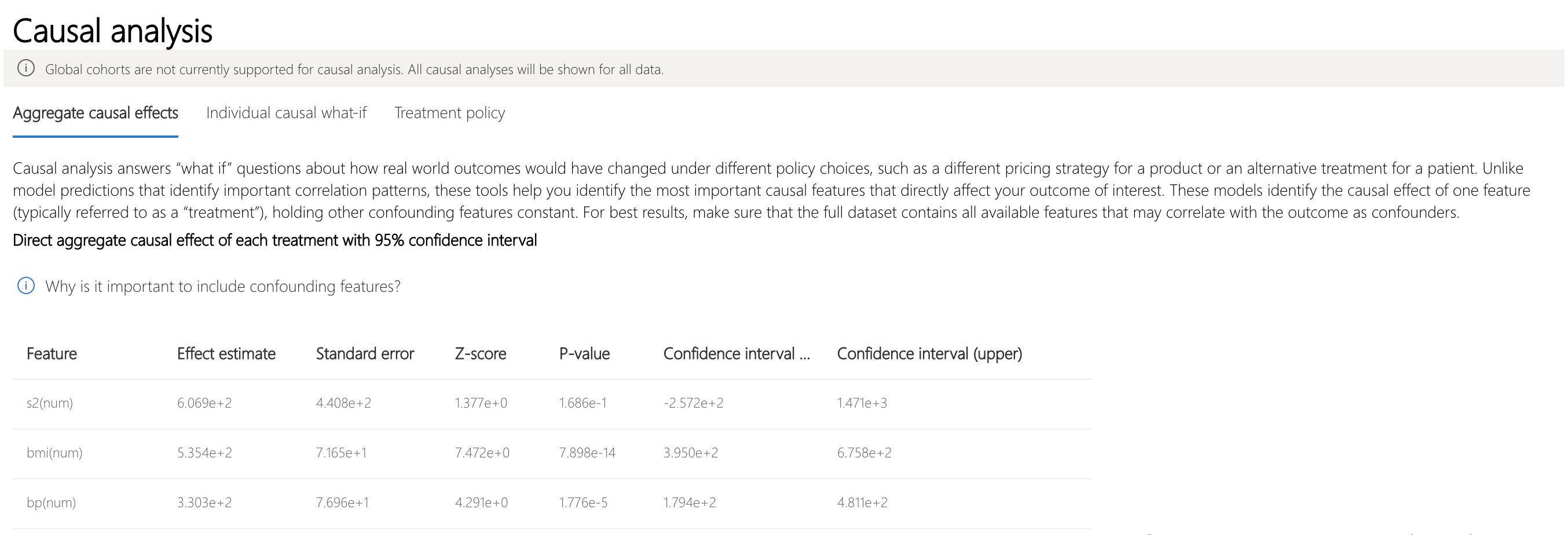
Now suppose that a doctor wishes to know how to reduce the progression of diabetes in her patients. This can be explored in the Causal Inference component of the Responsible AI Toolbox.
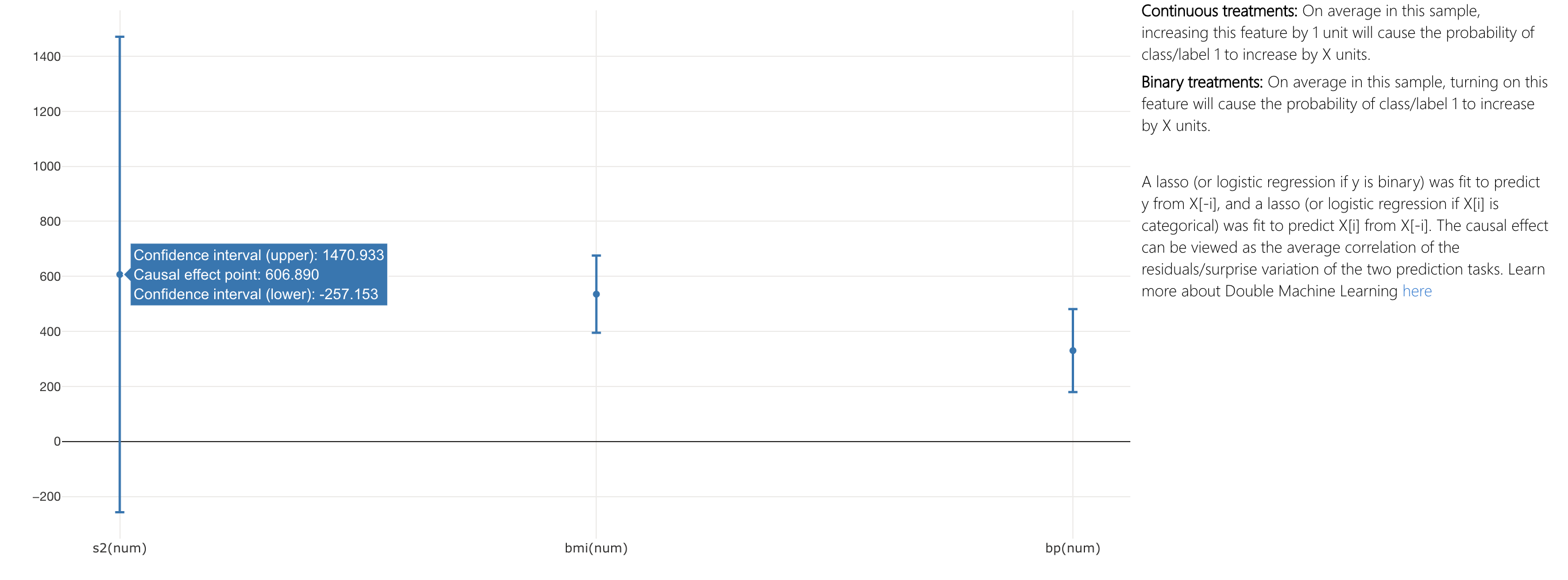
In the "Aggregate causal effects" tab, it is possible to see how perturbing features causes lower disease progression. It appears that increasing s2 (LDL) by one unit, would increase diabetes progression by 606.89 units.
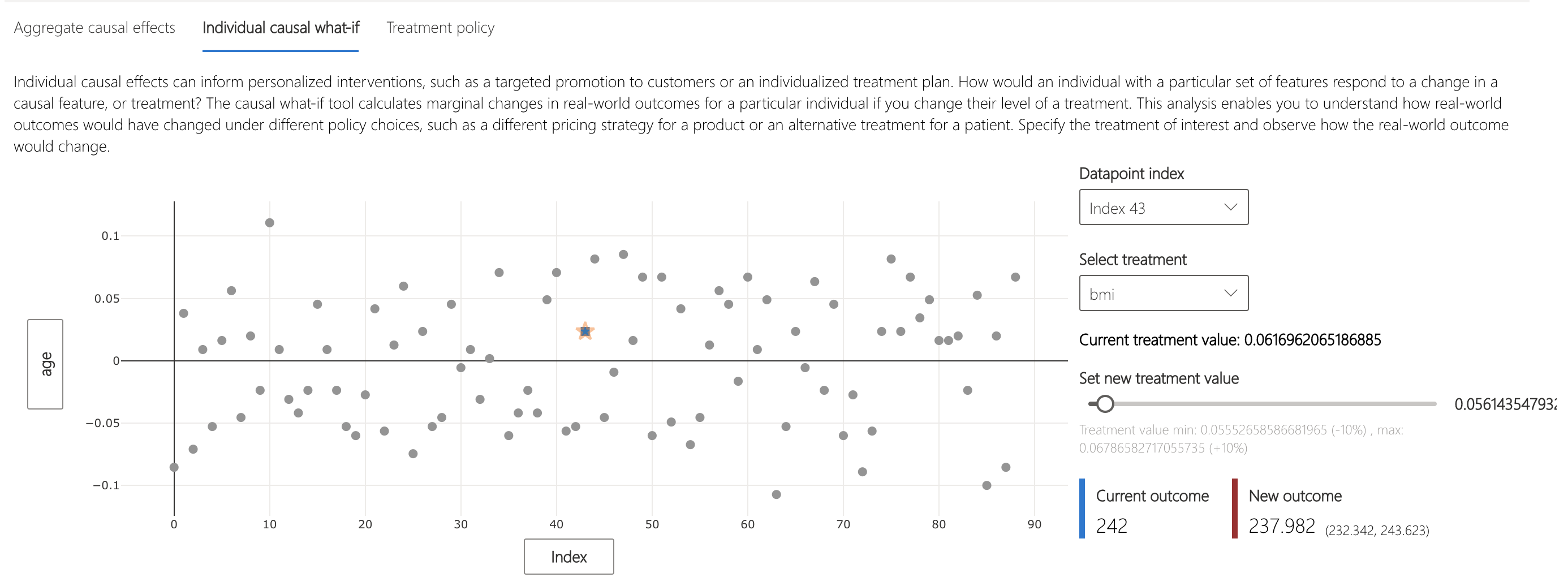
Let's revisit Patient 43. Instead of simply reducing the model score, they've decided to focus on actually improving their health to manage their diabetes better. In the "Individual causal what-if" tab, it shows that decreasing his/her bmi to 0.05 reduces diabetes progression from 242 to 237.982.
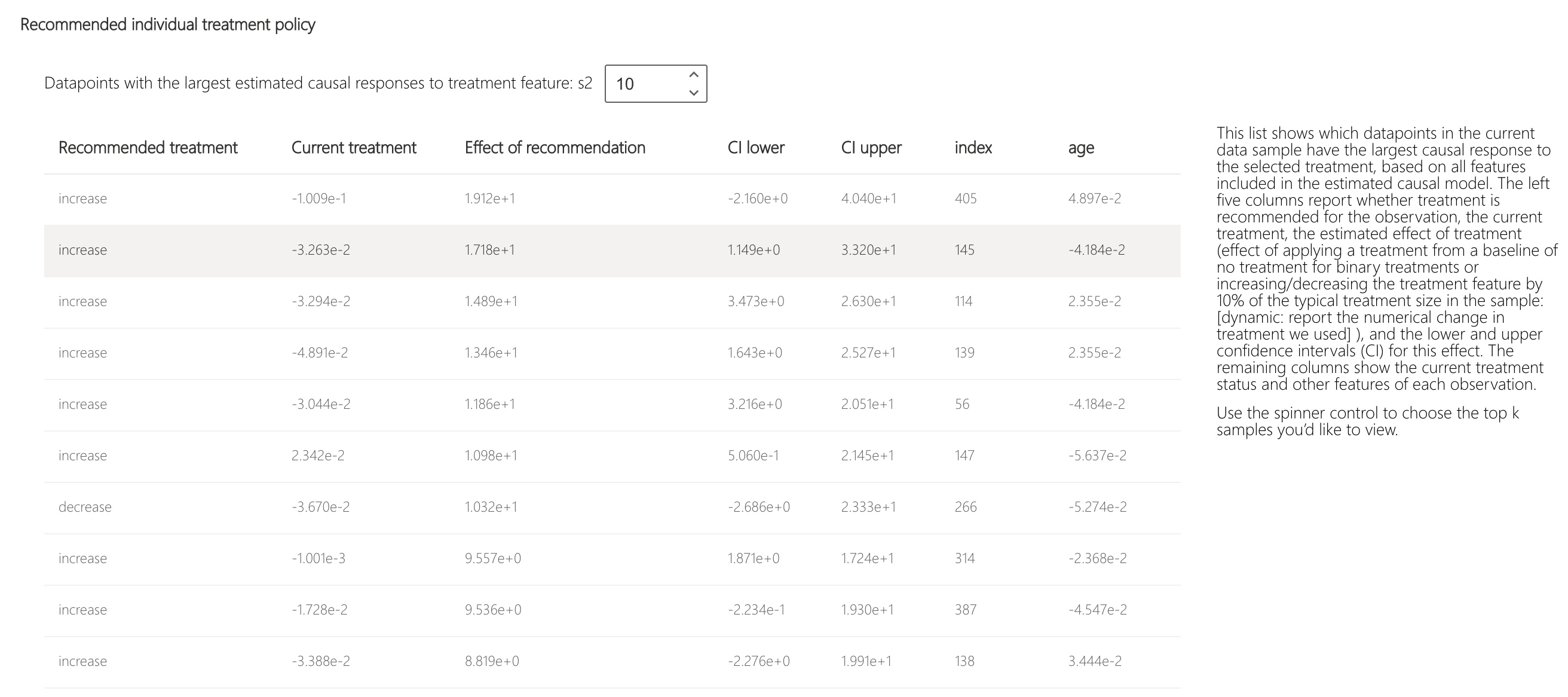
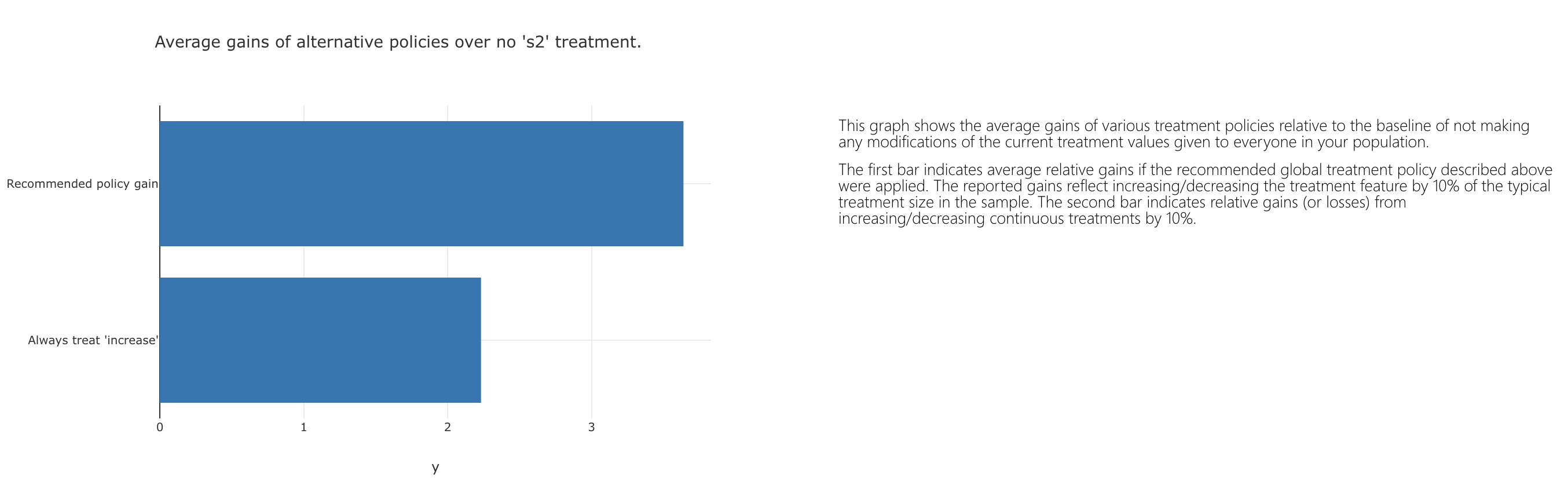
To put that into a formal intervention policy, switch to the "Treatment policy" tab. This view helps build policies for future interventions. You can identify what parts of your sample experience the largest responses to changes in causal features, or treatments, and construct rules to define which future populations should be targeted for particular interventions.

Is that change the best overall treatment for them? Let's investigate different policies. Going back to the "Treatment policy" tab, we see that going with the above intervention of s2 feature outperforms perturbing that with a "always increase" intervention.
Finally, you can see a list demonstrating which datapoints (patients) in the current data sample have the largest causal response to the selected treatment (s2 feature change), based on all features included in the estimated causal model.