Resnet - Implementation from scratch¶
This is my first attempt to implement a NN architecture from scratch. It took much more time than I expected, after three videos and this notebook I believe, I'm in a better position to understand the Resnets and CNNs in general. The purpose of this blog post and the companion videos are to document my learning process, get experience in coding and understand published papers. Please check my resources below. I believe it is the most important part of this notebook.
- toc: true
- badges: true
- comments: true
- categories: [coding]
- image: images/fastbook_images/resnet/ben.png
 Unrelated!
Unrelated!
What is Resnet?¶
Video 1 - What is Resnet? & Implementation of the Basic Block - Resnet From Scratch¶
youtube: https://youtu.be/ocmo0KAJS7M
from fastbook: Resnet: chapter-14
Note: In this chapter, we will build on top of the CNNs introduced in the previous chapter and explain to you the ResNet (residual network) architecture. It was introduced in 2015 by Kaiming He et al. in the article "Deep Residual Learning for Image Recognition" and is by far the most used model architecture nowadays. More recent developments in image models almost always use the same trick of residual connections, and most of the time, they are just a tweak of the original ResNet.
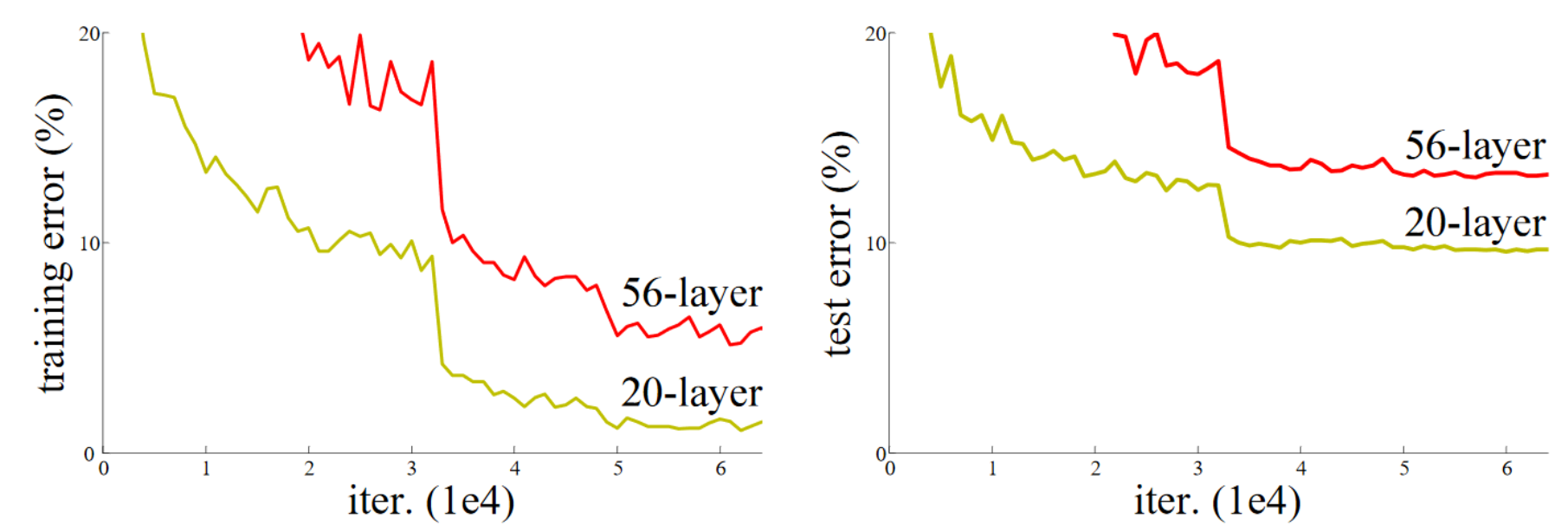
Note: In 2015, the authors of the ResNet paper noticed something that they found curious. Even after using batchnorm, they saw that a network using more layers was doing less well than a network using fewer layers—and there were no other differences between the models. Most interestingly, the difference was observed not only in the validation set, but also in the training set; so, it wasn't just a generalization issue, but a training issue. As the paper explains:

How Resnet works.¶
from fastbook: Resnet: chapter-14
Note:
Again, this is rather inaccessible prose—so let's try to restate it in plain English! If the outcome of a given layer is x, when using a ResNet block that returns y = x+block(x) we're not asking the block to predict y, we are asking it to predict the difference between y and x. So the job of those blocks isn't to predict certain features, but to minimize the error between x and the desired y. A ResNet is, therefore, good at learning about slight differences between doing nothing and passing though a block of two convolutional layers (with trainable weights). This is how these models got their name: they're predicting residuals (reminder: "residual" is prediction minus target).

What does that mean?
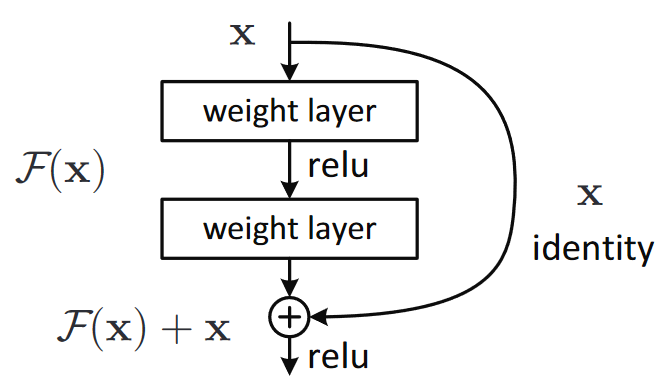
Resnet Stages, Basic Blocks and Layers.¶

What does Basic Block look like?¶
create a basic block/test the block with random tensor with random channel numbers/check downsample
Pytorch Resnet Implementation¶
import torch
import torch.nn as nn
import torchvision.models as models
models.resnet34()
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
Resnet From Scratch¶
Start with basic blocks:¶
class BasicBlock(nn.Module):
def __init__(self,in_chs, out_chs):
super().__init__()
if in_chs==out_chs:
self.stride=1
else:
self.stride=2
self.conv1 = nn.Conv2d(in_chs,out_chs,kernel_size=3, padding=1,stride=self.stride,bias=False)
self.bn1 = nn.BatchNorm2d(out_chs)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(out_chs,out_chs,kernel_size=3, padding=1,stride=1,bias=False)
self.bn2 = nn.BatchNorm2d(out_chs)
if in_chs==out_chs:
self.downsample=None
else:
self.downsample= nn.Sequential(#nn.AvgPool2d(2,2),
nn.Conv2d(in_chs,out_chs, kernel_size=1,stride=2,bias=False),
nn.BatchNorm2d(out_chs))
def forward(self,x):
skip_conn=x
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.conv2(x)
x=self.bn2(x)
if self.downsample:
skip_conn=self.downsample(skip_conn)
x+=skip_conn
x=self.relu(x)
return x
Note: Turns out AvgPool experiment didn't work. I'd thought that maybe getting an avarage of channels before conv2d downsampling could improve the result since kernel size 1 and stride 2 couse some information loss. (I believe :-))
x=torch.randn(1,64,112,112)
basic_block=BasicBlock(64,128)
basic_block(x).shape
torch.Size([1, 128, 56, 56])
Note: This is what I expect. Deccrease the image size by half and double the number of channels.
#m = nn.AvgPool2d(2)
#input = torch.randn(1, 64, 128, 128)
#output = m(input)
#output.shape
Note: 'repeat' is repeatitation of Basic blocks in corresponding stages.
repeat=[3,4,6,3]
channels=[64,128,256,512]
Visualize channels and stages.¶
in_chans=64
for sta,(rep,out_chans) in enumerate(zip(repeat,channels)):
for n in range(rep):
print(sta,in_chans,out_chans)
in_chans=out_chans
0 64 64 0 64 64 0 64 64 1 64 128 1 128 128 1 128 128 1 128 128 2 128 256 2 256 256 2 256 256 2 256 256 2 256 256 2 256 256 3 256 512 3 512 512 3 512 512
Create Basic Block Stages¶
def make_block(basic_b=BasicBlock,repeat=[3,4,6,3],channels=[64,128,256,512]):
in_chans=channels[0]
stages=[]
for sta,(rep,out_chans) in enumerate(zip(repeat,channels)):
blocks=[]
for n in range(rep):
blocks.append(basic_b(in_chans,out_chans))
#print(sta,in_chans,out_chans)
in_chans=out_chans
stages.append((f'conv{sta+2}_x',nn.Sequential(*blocks)))
#print(stages)
return stages
Complete the Resnet implementation¶
class ResneTTe34(nn.Module):
def __init__(self,num_classes):
super().__init__()
#stem
self.conv1=nn.Conv2d(3,64, kernel_size=7, stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU()
self.max_pool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
# res-stages
self.stage_modules= make_block()
for stage in self.stage_modules:
self.add_module(*stage)
self.avg_pool=nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc=nn.Linear(512,num_classes,bias=True)
#self.softmax=nn.Softmax(dim=1)
def forward(self,x):
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.max_pool(x)
x=self.conv2_x(x)
x=self.conv3_x(x)
x=self.conv4_x(x)
x=self.conv5_x(x)
x=self.avg_pool(x)
x=torch.flatten(x,1)
x=self.fc(x)
#x=self.softmax(x)
return x
Note: I don't why but softmax didn't work well.
x=torch.randn(1,3,224,224)
my_resnette=ResneTTe34(10)
my_resnette(x).shape
torch.Size([1, 10])
- after conv layers:
torch.Size([1, 512, 7, 7]) - after avg_pool:
torch.Size([1, 512, 1, 1]) - after flatten:
torch.Size([1, 512]) - after fc:
torch.Size([1, 10])
Training with Fast AI¶
Video - 2 - Resnet Class Implementation - Resnet From Scratch¶
youtube: https://youtu.be/20-TH5qxkS8
import fastbook
fastbook.setup_book()
from fastai.vision.all import *
Dataset: IMAGENETTE_160¶
A subset of 10 easily classified classes from Imagenet: tench, English springer, cassette player, chain saw, church, French horn, garbage truck, gas pump, golf ball, parachute.
path = untar_data(URLs.IMAGENETTE_160)
data_block=DataBlock(
blocks=(ImageBlock, CategoryBlock), get_items=get_image_files,
splitter=GrandparentSplitter(valid_name='val'),
get_y=parent_label, item_tfms=Resize(160),
batch_tfms=[*aug_transforms(min_scale=0.5, size=160),
Normalize.from_stats(*imagenet_stats)],
)
dls = data_block.dataloaders(path, bs=512)
/home/niyazi/anaconda3/envs/fastbook/lib/python3.8/site-packages/torch/_tensor.py:1023: UserWarning: torch.solve is deprecated in favor of torch.linalg.solveand will be removed in a future PyTorch release. torch.linalg.solve has its arguments reversed and does not return the LU factorization. To get the LU factorization see torch.lu, which can be used with torch.lu_solve or torch.lu_unpack. X = torch.solve(B, A).solution should be replaced with X = torch.linalg.solve(A, B) (Triggered internally at /opt/conda/conda-bld/pytorch_1623448278899/work/aten/src/ATen/native/BatchLinearAlgebra.cpp:760.) ret = func(*args, **kwargs)
dls.c
10
Note:
dls.cNumber of classes in the dataloaders.
dls.show_batch(max_n=12)

New Resnet instance:¶
# rn = models.resnet34()
rn=ResneTTe34(10)
rn
ResneTTe34(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(max_pool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(conv2_x): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(conv3_x): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(conv4_x): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(conv5_x): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avg_pool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=10, bias=True)
)
Create a learner.¶
Note: Detailed information about fastai learner class: Documentation
learn = Learner(dls, rn, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
Note: Learn more about fastai learning rate finder: here
learn.lr_find()
SuggestedLRs(valley=0.00010964782268274575)

Training:¶
learn.fit_one_cycle(20, 0.000109)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.380851 | 2.387236 | 0.103439 | 00:10 |
| 1 | 2.212096 | 2.009294 | 0.277962 | 00:11 |
| 2 | 1.998115 | 1.962252 | 0.363312 | 00:11 |
| 3 | 1.782758 | 1.822328 | 0.417580 | 00:11 |
| 4 | 1.590943 | 1.815316 | 0.444586 | 00:11 |
| 5 | 1.441378 | 1.804929 | 0.473121 | 00:11 |
| 6 | 1.309173 | 1.451521 | 0.548025 | 00:11 |
| 7 | 1.202027 | 1.469768 | 0.544204 | 00:11 |
| 8 | 1.106232 | 1.137969 | 0.628790 | 00:10 |
| 9 | 1.023413 | 1.444246 | 0.564331 | 00:11 |
| 10 | 0.944548 | 1.267145 | 0.609936 | 00:11 |
| 11 | 0.878883 | 1.263278 | 0.608662 | 00:10 |
| 12 | 0.824138 | 1.046869 | 0.673631 | 00:11 |
| 13 | 0.780820 | 0.930782 | 0.704713 | 00:11 |
| 14 | 0.738063 | 0.935515 | 0.697070 | 00:10 |
| 15 | 0.693144 | 0.887937 | 0.720510 | 00:11 |
| 16 | 0.660048 | 1.019186 | 0.687643 | 00:10 |
| 17 | 0.623636 | 0.907101 | 0.716688 | 00:10 |
| 18 | 0.594946 | 0.891949 | 0.715924 | 00:11 |
| 19 | 0.583335 | 0.914399 | 0.711083 | 00:11 |
Some Results:¶
Original Resnet34
lrfindgraph was smoother and I am investigating nowMy Implementation baseline accuracy: %62, PyTorch resnet implementation:74
after setting linear chanel
bias=True: %64after setting conv layers
bias=False: %65after
softmaxremoved: %72training 50 epochs
IMAGENETTE_160:%78training 20 epochs with bigger images
IMAGENETTE_320:%82
Video - 3 - Training 'My Resnet' - Resnet From Scratch¶
youtube: https://youtu.be/zxvCyz91UtQ
Pytorch's Resnet34 implementation for Benchmark¶
resnet=models.resnet34()
learn_resnet = Learner(dls, resnet, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn_resnet.lr_find()
SuggestedLRs(valley=0.0004786300996784121)

Looks smoother.
learn_resnet.fit_one_cycle(20, 0.000478)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 6.478988 | 6.033509 | 0.117197 | 00:12 |
| 1 | 5.071272 | 4.286289 | 0.204331 | 00:11 |
| 2 | 3.680538 | 2.191735 | 0.353376 | 00:11 |
| 3 | 2.801381 | 3.466609 | 0.344204 | 00:12 |
| 4 | 2.248471 | 1.444590 | 0.537580 | 00:12 |
| 5 | 1.869702 | 2.074517 | 0.430064 | 00:12 |
| 6 | 1.602450 | 1.283586 | 0.594140 | 00:12 |
| 7 | 1.397508 | 1.226493 | 0.589299 | 00:12 |
| 8 | 1.226750 | 0.929667 | 0.713885 | 00:12 |
| 9 | 1.112665 | 1.189254 | 0.607898 | 00:12 |
| 10 | 1.005993 | 1.106539 | 0.647643 | 00:12 |
| 11 | 0.917422 | 1.082780 | 0.669045 | 00:12 |
| 12 | 0.841141 | 1.346959 | 0.602803 | 00:12 |
| 13 | 0.777760 | 0.885834 | 0.729682 | 00:12 |
| 14 | 0.713249 | 1.043039 | 0.678981 | 00:12 |
| 15 | 0.660397 | 1.161693 | 0.661656 | 00:12 |
| 16 | 0.619790 | 0.947324 | 0.710318 | 00:12 |
| 17 | 0.576243 | 0.822031 | 0.744204 | 00:12 |
| 18 | 0.549599 | 0.861511 | 0.734522 | 00:12 |
| 19 | 0.519339 | 0.836370 | 0.741656 | 00:11 |
A little better result.
A test for 50 epochs. (%5 better)¶
rn_higher_epoch=ResneTTe34(10)
learn_higher_epoch = Learner(dls, rn_higher_epoch, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn_higher_epoch.lr_find()
/home/niyazi/anaconda3/envs/fastbook/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448278899/work/c10/core/TensorImpl.h:1156.) return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
SuggestedLRs(valley=0.00013182566908653826)

learn_higher_epoch.fit_one_cycle(50, 0.000131)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.377973 | 2.386434 | 0.125860 | 00:11 |
| 1 | 2.262577 | 2.187544 | 0.198981 | 00:11 |
| 2 | 2.131813 | 2.076762 | 0.288153 | 00:11 |
| 3 | 1.982456 | 1.810484 | 0.386497 | 00:11 |
| 4 | 1.822840 | 2.068272 | 0.374777 | 00:11 |
| 5 | 1.665031 | 1.880948 | 0.445096 | 00:11 |
| 6 | 1.527851 | 1.564145 | 0.496306 | 00:11 |
| 7 | 1.407204 | 1.601933 | 0.506242 | 00:11 |
| 8 | 1.302459 | 1.382655 | 0.555414 | 00:11 |
| 9 | 1.205924 | 1.412100 | 0.577580 | 00:11 |
| 10 | 1.120911 | 1.306462 | 0.595669 | 00:11 |
| 11 | 1.056995 | 1.286385 | 0.591338 | 00:11 |
| 12 | 0.991353 | 1.091827 | 0.653503 | 00:11 |
| 13 | 0.939019 | 0.991272 | 0.692229 | 00:11 |
| 14 | 0.889291 | 1.482610 | 0.576560 | 00:11 |
| 15 | 0.843552 | 1.134017 | 0.648662 | 00:12 |
| 16 | 0.798295 | 1.556873 | 0.567898 | 00:11 |
| 17 | 0.750999 | 1.271683 | 0.629299 | 00:11 |
| 18 | 0.714964 | 1.453092 | 0.597452 | 00:12 |
| 19 | 0.693228 | 1.105892 | 0.668025 | 00:11 |
| 20 | 0.664791 | 1.161920 | 0.665733 | 00:11 |
| 21 | 0.633090 | 1.229070 | 0.645605 | 00:11 |
| 22 | 0.615386 | 0.935700 | 0.711847 | 00:11 |
| 23 | 0.581805 | 1.142192 | 0.669554 | 00:11 |
| 24 | 0.558872 | 1.138849 | 0.676688 | 00:12 |
| 25 | 0.538580 | 0.860732 | 0.742166 | 00:12 |
| 26 | 0.515516 | 0.977736 | 0.709554 | 00:12 |
| 27 | 0.501689 | 1.064165 | 0.684076 | 00:12 |
| 28 | 0.477749 | 0.935355 | 0.724586 | 00:12 |
| 29 | 0.450755 | 0.950616 | 0.712611 | 00:12 |
| 30 | 0.417243 | 1.084173 | 0.695032 | 00:11 |
| 31 | 0.406682 | 1.021061 | 0.713885 | 00:11 |
| 32 | 0.387076 | 1.004474 | 0.714140 | 00:11 |
| 33 | 0.359906 | 0.797884 | 0.766115 | 00:11 |
| 34 | 0.337195 | 0.814482 | 0.771465 | 00:11 |
| 35 | 0.317810 | 0.904211 | 0.754395 | 00:11 |
| 36 | 0.305618 | 0.925233 | 0.745732 | 00:11 |
| 37 | 0.290424 | 0.813434 | 0.765096 | 00:11 |
| 38 | 0.270168 | 0.856214 | 0.763312 | 00:12 |
| 39 | 0.254928 | 0.915280 | 0.753631 | 00:11 |
| 40 | 0.240487 | 0.881618 | 0.754395 | 00:11 |
| 41 | 0.223493 | 0.808955 | 0.778344 | 00:11 |
| 42 | 0.213208 | 0.911270 | 0.758726 | 00:12 |
| 43 | 0.198452 | 0.811407 | 0.776306 | 00:11 |
| 44 | 0.189459 | 0.895555 | 0.754904 | 00:11 |
| 45 | 0.187922 | 0.868764 | 0.765350 | 00:11 |
| 46 | 0.180785 | 0.811440 | 0.775541 | 00:11 |
| 47 | 0.178707 | 0.826532 | 0.773503 | 00:11 |
| 48 | 0.174185 | 0.817364 | 0.775796 | 00:11 |
| 49 | 0.170915 | 0.805405 | 0.779873 | 00:11 |
Another test with bigger images. (IMAGENETTE_320)¶
path_320 = untar_data(URLs.IMAGENETTE_320)
data_block_320=DataBlock(
blocks=(ImageBlock, CategoryBlock), get_items=get_image_files,
splitter=GrandparentSplitter(valid_name='val'),
get_y=parent_label, item_tfms=Resize(320),
batch_tfms=[*aug_transforms(min_scale=0.5, size=224),
Normalize.from_stats(*imagenet_stats)],
)
dls_320 = data_block_320.dataloaders(path_320, bs=256)
/home/niyazi/anaconda3/envs/fastbook/lib/python3.8/site-packages/torch/_tensor.py:1023: UserWarning: torch.solve is deprecated in favor of torch.linalg.solveand will be removed in a future PyTorch release. torch.linalg.solve has its arguments reversed and does not return the LU factorization. To get the LU factorization see torch.lu, which can be used with torch.lu_solve or torch.lu_unpack. X = torch.solve(B, A).solution should be replaced with X = torch.linalg.solve(A, B) (Triggered internally at /opt/conda/conda-bld/pytorch_1623448278899/work/aten/src/ATen/native/BatchLinearAlgebra.cpp:760.) ret = func(*args, **kwargs)
rn_IM_320=ResneTTe34(10)
learn__IM_320 = Learner(dls_320, rn_IM_320, loss_func=nn.CrossEntropyLoss(), metrics=accuracy
).to_fp16()
learn__IM_320.lr_find()
/home/niyazi/anaconda3/envs/fastbook/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448278899/work/c10/core/TensorImpl.h:1156.) return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
SuggestedLRs(valley=0.00010964782268274575)

learn__IM_320.fit_one_cycle(20, 0.0001096)
| epoch | train_loss | valid_loss | accuracy | time |
|---|---|---|---|---|
| 0 | 2.245787 | 2.379868 | 0.198471 | 00:20 |
| 1 | 1.967387 | 2.148099 | 0.340127 | 00:20 |
| 2 | 1.657673 | 1.542151 | 0.509554 | 00:20 |
| 3 | 1.432339 | 1.860907 | 0.455287 | 00:20 |
| 4 | 1.241912 | 1.308743 | 0.576051 | 00:20 |
| 5 | 1.107367 | 1.259022 | 0.604331 | 00:20 |
| 6 | 1.004726 | 1.330731 | 0.598217 | 00:20 |
| 7 | 0.916032 | 0.902091 | 0.714140 | 00:20 |
| 8 | 0.846182 | 1.346130 | 0.601783 | 00:20 |
| 9 | 0.766183 | 0.942265 | 0.716178 | 00:20 |
| 10 | 0.710231 | 0.875285 | 0.710828 | 00:20 |
| 11 | 0.655968 | 0.812030 | 0.745732 | 00:20 |
| 12 | 0.600506 | 0.853020 | 0.732739 | 00:20 |
| 13 | 0.553901 | 0.720496 | 0.776051 | 00:20 |
| 14 | 0.515389 | 0.691851 | 0.782420 | 00:20 |
| 15 | 0.475770 | 0.630577 | 0.800510 | 00:20 |
| 16 | 0.432293 | 0.619373 | 0.805860 | 00:20 |
| 17 | 0.403326 | 0.561097 | 0.823694 | 00:20 |
| 18 | 0.388080 | 0.583485 | 0.814013 | 00:21 |
| 19 | 0.378337 | 0.578927 | 0.812739 | 00:20 |
Resources:¶
Resnet paper by Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun https://arxiv.org/abs/1512.03385 , https://arxiv.org/pdf/1512.03385.pdf
W&B Paper Reading Group: ResNets by Aman Arora
youtube: https://youtu.be/nspf00KpU-g
W&B Fastbook Reading Group — 14. ResNet
youtube: https://youtu.be/2AdGJVtP3ak
Practical Deep Learning for Coders Book (fastbook)
https://colab.research.google.com/github/fastai/fastbook/blob/master/14_resnet.ipynb
Live Coding Session on ResNet by Aman Arora
youtube: https://youtu.be/AHJhtLDchGo
[Classic] Deep Residual Learning for Image Recognition (Paper Explained) by Yannic Kilcher
youtube: https://youtu.be/GWt6Fu05voI
Andrew Ng Resnet videos.
youtube: https://youtu.be/ZILIbUvp5lk
youtube: https://youtu.be/RYth6EbBUqM