6: Visual Analytics¶
What do we mean by “Visual Analytics”?¶
- “Visual Analytics is the science of analytical reasoning supported by a highly interactive visual interface.” [Wong and Thomas 2004]
- “Visual Analytics combines automated analysis techniques with interactive visualisations for an effective understanding, reasoning and decision making on the basis of very large and complex datasets” [Keim 2010]
- “Detect the expected and discover the unexpected”
We have already discussed statistics, machine learning, and visualization. Visual analytics is essentially the combination of all three – the use of interactive visual interfaces to support statistical and analytical reasoning about data. A key emphasis here is the interactivity of the system – much like the knowledge generation feedback loop and the data science workflows discussed in Section 2, visual analytics is about how we develop analytical reasoning through iterative use of the system to interact, filter, and zoom in on key details of the data, as part of the exploration process. We have discussed static forms of data visualisation in Section 5, however the greatest challenge of any visualization is carefully deciding on what data should be shown, and how this should be represented. Visual analytics essentially allow us to interactively update the parameters of the visualization to create a dynamic and engaging interactive experience that helps inform decision making.
If we consider automated methods, and we consider visualization methods, what are their strengths and weaknesses? Automated methods scale well to large data, however they may suffer from local optima problems, or run in a “black box” fashion that does not facilitate understanding of their process. Visualisation methods can be interactive, but can suffer from scalability. Visual analytics aim to combine the best of both approaches, where a user will alternate between visual and automated methods, and provides a collaborative approach for problem-solving and story-telling between the user and the machine.
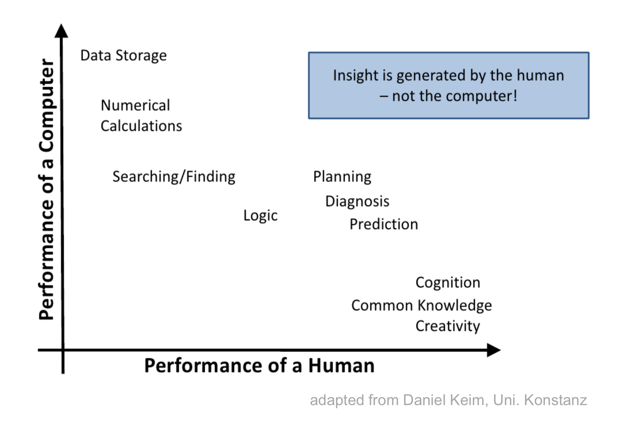
Let us consider the ability matrix here. We know that computers excel in some tasks, yet humans excel in others. Visual analytics aims to find the appropriate balance between the two. Often, people describe it as “providing insight” – yet, we need to consider “what do we mean by insight?”. Insight is something that is generated by a human, not a computer. So then how does a computer system (e.g., a visual analytics tools) help to generate insight? Arguably, visualization and visual analytics are about “saving time” in a manner that supports cognition.
Dashboards¶
Dashboards are now widely used in many analysis platforms. The term originates from the car dashboard – we do not need to know every detail about the underlying system, such as the exact operations of cylinders and other mechanisms under the bonnet, however we do need the key details such as current speed, and we need a means to be alerted when things go wrong. The same is true in many cyber security scenarios – what we want to know is whether the infrastructure is operating as intended, some key details about the operation of the infrastructure, and if there is a problem, will the dashboard alert us correctly and in a timely-manner, with useful and meaningful information such that we can diagnose the problem and return to normal operations. A simple Google search for “visual analytics dashboard” will reveal a number of different designs and structures that have been used. Key summary statistics shown using pie charts and radial plots are often quite common – used in a number of “business” dashboards for presenting company financials. Key here is that these are for explanatory visualisation, they help convey the story or narrative. When interacting with a dashboard, it is about exploration, and so we can begin to understand how a dashboard can help achieve both focus-and-context, or overview and detail. Many dashboards may also “link” visualisations – whereby interactions and selections in one chart may update all related charts. Combining interaction across different linked visualisations makes dashboards a very powerful and effective form of exploration.
We introduced Plotly in our visualisation practical, and more recently, Plotly Dash has become "the most downloaded, trusted framework for building ML & data science web apps." It is popular since it is written in Python, yet produces rich HTML-based interactive visualisations, without the need for further languages such as Javascript.
User Interaction¶
Humans learn by “doing” – it is the same in visualisation. It allows users to examine how something works, and specifically, it allows us to assess the strengths and weaknesses in our analysis. Typical interactions may include parameter selection (e.g., selecting a date range), filtering and selection (e.g., selecting a particular group of users), brushing (e.g. selecting a particular region on an axis), reordering (e.g., changing the data on an axis), and zoom (e.g., increase detail for a given region on a map). It is useful to think about interaction components such as those used in HTML 5 such as radio buttons, checkmark buttons, sliders, buttons, date time selections, as well as operations such as click, drag, hover, and focus. As this course primarily uses Python Notebooks, we can incorporate "Widgets" such as sliders, text entry, drop-down menus, radio buttons, buttons, date and colour pickers, file upload dialogs, tabs, and accordions, and many more directly into our notebooks to interact with Pandas. We will explore how to achieve this further in our practical work.
A number of interaction methods have evolved in recent times: mouse and keyboard, stylus pen, touchscreen, hand gestures (such as Leap Motion and Kinect), and voice. When designing systems, we need to be mindful of the intended mode of operation, and the associated costs of interactions. Amazon Alexa is a prime example of voice command – it allows hands-free operation of a system to perform tasks such as playing music and listening to weather reports. However, it may be less appropriate to inspect a parallel coordinates plot via voice – it may be difficult to articulate exactly what interaction is required, or it may be that the commands are simply too long for them to be convenient any more. Likewise, hand gestures work well for video games that may be about an immersive experience, but wouldn’t neceessarily lend themselves well for searching a database. We have to think about tiredness and fatigue caused by any interaction method, and the complexity of the interactions. Mouse and keyboards remain most common in many computing applications, due to their familiarity for users. Yet, users who have been primarily exposed to touchscreens and touch keyboard (especially on mobile devices) may find they can type quicker on a mobile than a traditional keyboard. Therefore, designing effective user interaction involves knowing the intended audience, and how they are expected to use the system, and for what duration. Some systems may seek to combine multi-modal interactions – such as voice and touch. The ACM CHI conference is a long-standing academic venue for research publications in the area of human-computer interaction.
Challenges in Visual Analytics¶
You may hear talk about “big data” – yet we need to ask what the actual investigation is that requires big data. Humans can not comprehend the complete dataset, and machine may not be able to “process” the complete dataset (whatever we may be referring to by the “process” here). Visual analytics supports memory externalisation such that the system can serve to “remind” the user of some detail when needed, rather than the user be expected to recall all previous observations of data. Similarly, users can not visualise all data at once. As system designers, we need to make decisions about the level of perception that is appropriate when data is being conveyed to the user (or at least, offer the user a means of adjusting this level). Scalability will continue to dominate visual analytics as a challenge – however, the power of the human is to identify the appropriate way of incorporating more scalable methods for data analysis – such as machine learning – to then support the investigation of the data.
How do we account for semantics in our data? For example, think about document collections (e.g., e-mail conversations). A system can calculate metrics such as word count and word occurrences, but a computer would not understand the true definition of a word. Even if it can infer that similar words occur together, there is a need for human intervention to assess the appropriateness of the words used. We’ll explore this further in our Section on text analytics.
Uncertainty is a fundamental challenge in data analytics. Data is gathered from a sensor (which could be a packet capturer, a video camera, a software tool or a hardware sensor). How do we know that the sensor is gathering data reliably? How can we use visual analytics to inform about our confidence in the data, or the uncertainty that may have been introduced, and how should users comprehend this information? If a sensor is 65% confident, how does the user make best use of this information? (e.g., Frenquentist vs Bayesian probabilities). There will also be uncertainty in our users – how can we ensure they will use tools in the way they are designed? How can we ensure they will act in the way that is intended (e.g., providing correct information). Could visual analytics help to identify security concerns based on how users interact with a system (either deliberately or accidentally).
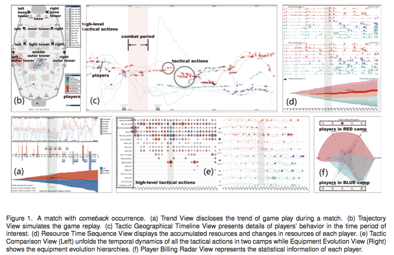
Finally, how do we evaluate a good visual analytics system? Many dashboards are developed based on intuition, or from templates, but how do we scientifically assess design choices made? There is much research in the area about how we develop guidelines for reproducable visual analytics systems, rather than working on the assumption of bespoke software development. The IEEE VIS community, and especially for us, the IEEE VizSec community (Visualisation for Cyber Security), are two important research venues where this is an ongoing discussion. We show 5 examples of different visual analytics applications. When examining these, think about how design choices have been made, how they support multiple linked views for exploration, and how you may expect a user to interact with the system from start to finish. The pictures are linked where you can find the research papers, and range from topics of insider threat detection, through to online gaming, taxi trajectories, text analysis, and massive open online courses.


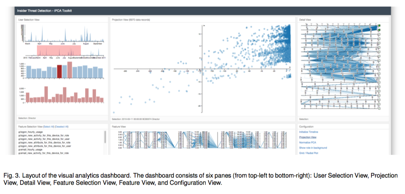
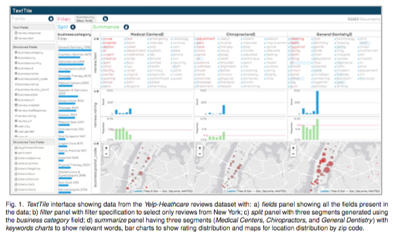
Further reading¶
- P. A. Legg, "Enhancing cyber situation awareness for Non-Expert Users using visual analytics," 2016 International Conference On Cyber Situational Awareness, Data Analytics And Assessment (CyberSA), 2016, pp. 1-8, doi: 10.1109/CyberSA.2016.7503278.
- Agarwal, R. Building Dashboards using Dash. Towards Data Science (2020)