Типы данных¶
В этой лекции будут рассмотрены основные понятия языка программирования Python: переменные и типы данных. Лекция содержит большое количество теоретического материала, необходимого для дальнейшего изучения Python. Без понимания рассматриваемых в данной лекции концепций дальнейшее прохождение курса будет затруднено, поэтому ей стоит уделить максимум внимания.
Содержание лекции¶
Переменные¶
Все данные, к которым обращается программа, хранятся в оперативной памяти компьютера, при этом каждый байт имеет свой адрес - некоторое число, уникальным образом идентифицирующее его и позволяющее CPU его найти, когда потребуется прочитать или записать значение. Например, в 64-битной операционной системе для адресации используется 64-битное число, как правило записываемое в шестнадцатеричной системе счисления (вот так может выглядеть адрес одного байта: 37A15F8037099910). В низкоуровневых языках программирования разработчику часто приходится оперировать подобными адресами, что требует хорошего знания устройства оперативной памяти и принципов ее работы. Получающаяся в результате программа очень сложна для понимания - даже подготовленному специалисту требуется время, чтобы разобраться в ней.
В высокоуровневых языках вроде Python вместо непосредственно адресов используются переменные, представляющие собой именованные области памяти. Как следует из этого определения, переменная задает соответствие между некоторым именем, называемым также идентификатором, и участком памяти. Это позволяет в дальнейшем для доступа к памяти использовать вместо малопонятных числовых адресов их текстовые идентификаторы.
Переменные в языке Python создаются (по другому еще говорят определяются) с помощью инструкции присваивания =. Ниже представлена программа, в которой создаются две переменные и вычисляется их сумма.
a = 1
b = 2
a + b
3
Рассмотрим эту программу подробно. В первых двух строчках нашего примера мы выделяем где-то в памяти (нам совершенно не важно, где именно) две области для хранения чисел 1 и 2, а затем связываем адреса этих областей с идентификаторами a и b. При выполнении операции +, интерпретатор Python в первую очередь определяет, какие адреса связаны с переменными, входящими в выражение, затем считывает числа, хранящиеся по данным адресам, и наконец выполняет сложение.
Важно уяснить для себя, что в Python знак = используется для создания, инициализации и изменения переменных, а не как операция определения равенства двух значений. Когда мы пишем a = 1, мы даем команду интерпретатору не сравнить значение a с 1, а выделить участок памяти, поместить в него число 1 и связать его с именем "a".
Справа от знака = при создании переменной может находиться:
- литерал - константа, включаемая непосредственно в код программы (в примере выше литералами являются числа 1 и 2)
- другая, созданная ранее переменная
- любое выражение, содержащее комбинацию арифметических и иных операций, литералов и уже созданных переменных
С учетом вышесказанного, рассмотрим чуть более сложный пример (обратите внимание, что мы выводим значения переменных, просто перечисляя их через запятую):
a = 10
b = a
c = b + 1
d = a + b + c
a, b, c, d
(10, 10, 11, 31)
Если вы попытаетесь обратиться к переменной, которая не была определена ранее, интерпретатор сгенерирует исключение NameError и выведет соответствующее сообщение об ошибке:
x = 10
x + y
--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-3-ec3418874d45> in <module>() 1 x = 10 ----> 2 x + y NameError: name 'y' is not defined
Допустимые идентификаторы¶
Не всякая последовательность символов является допустимым идентификатором, который может использоваться в качестве имени переменной в языке Python. По правилам, корректный идентификатор должен начинаться с буквы или символа подчеркивания "_", при этом буквы не обязаны быть из английского алфавита. Далее может идти последовательность букв, цифр и знаков подчеркивания произвольной длины. Примерами допустимых идентификаторов являются _variable_01 и моя_переменная, а недопустимых - 1_variable и a^b. Имена переменных чувствительны к регистру, то есть var, Var и VAR являются тремя разными идентификаторами.
Существует еще одно ограничение на имена переменных: они не должны совпадать с каким-либо из ключевых слов, зарезервированных для обозначения инструкций языка программирования Python. Полный список таких слов представлен ниже.
and continue except global lambda pass while
as def False if None raise with
assert del finally import nonlocal return yield
break elif for in not True
class else from is or try
В заключение перечислим некоторые рекомендации относительно выбора имен переменных в языке программирования Python:
- Не используйте в качестве имен переменных идентификаторы встроенных атрибутов Python или имена очень похожие на них. В качестве примера одного из таких атрибутов можно привести исключение
NameError- вы можете создать переменную с таким именем, однако этого делать не стоит. Разумеется, нужен некоторый опыт программирования на Python, чтобы знать, какие имена уже присутствуют в Python и не использовать их для своих переменных. - Не используйте имена, начинающиеся и заканчивающиеся двумя символами подчеркивания, например
__variable__. Причина в том, что в Python существует много предопределенных системных переменных, названных по таком шаблону. - Никогда не используйте в качестве имени переменной русские слова или их транслитерацию - это считается плохим стилем программирования. Идентификаторы
моя_переменнаяилиmoya_peremennaya- плохие! - Имя переменной должно быть по возможности кратким и в то же время отражать, что в ней содержится - это улучшает читабельность вашего исходного кода. Например, для переменной, в которой хранится средняя температура по больнице, хорошо подходят имена
average_temperatureиavg_temp, и совсем не подходит -avegare_temperature_in_the_hospitalиa(мы в коротких примерах курса позволяем себе использовать однобуквенные переменные, но в реальном проекте их стоит избегать).
Определение типа данных¶
Тип данных - это характеристика любой переменной, определяющая набор допустимых значений этой переменной и операции, которые можно выполнять с ней. Когда программист указывает, какой тип данных имеет та или иная переменная, компилятор или интерпретатор получает возможность провести дополнительную оптимизацию кода (например, операция сложения целых чисел выполняется гораздо быстрее сложения действительных, поэтому если известно, что числа в выражении целые, можно использовать более быструю операцию без потери точности вычислений), а самое главное - он может проверить правильность программы, обнаруживая ситуации, когда в переменной или операции оказывается значение, не подходящее по типу.
В языке программирования Python используется неявная строгая динамическая типизация. Разберем, что означает эта формулировака:
- неявная - говорит о том, что типы переменных в Python не указываются явно, а задаются интерпретатором на основании того, какое значение стоит в правой части инструкции присваивания
=. В качестве примера языка программирования с явной типизацией можно привести C++, в котором при создании переменной нужно явно указывать ее тип:int a = 1(int является типом для хранения целых значений в C++) - строгая - говорит о том, что интерпретатор Python внимательно следит, чтобы в одном выражении не использовались разные типы данных (за исключением типов, которые можно безопасно преобразовать к какому-то общему типу). На другом полюсе находятся языки вроде PHP, в которых используется слабая типизация и разрешаются выражения, содержащие переменные с совершенно разными типами.
- динамическая - говорит о том, что одна и та же переменная может иметь разный тип в течение выполнения программы, который определяется по последней инструкции присваивания
=для данной переменной. В других языках программирования (например, Java) может использоваться статическая типизация, что означает, что тип не может быть изменен после того, как он назначен переменной.
Поскольку язык Python является типизированным, любой литерал, переменная или целое выражение, состоящее из комбинации арифметических и иных операций, выполненных над ними, обладает своим типом.
Целочисленные типы¶
В языке Python существует два целочисленных типа:
- int (от англ. integer) - целое число практически неограниченного размера (лишь бы хватило оперативной памяти для его хранения)
- bool (от англ. boolean) - логический (также называемый булевым) тип, принимающий одно из двух возможных значение: истина (True) или ложь (False)
Как уже упоминалось ранее, в языке Python тип переменной назначается самим интерпретатором в тот момент, когда вы ее создаете. При этом переменная получает тот же тип, что и выражение, которое находится справа от знака =.
Литералы, имеющие тип int, представляют собой целые числа записанные в десятичной, двоичной, восьмеричной или шестнадцатеричной системе счисления. В примере ниже всем переменным присваивается одно и то же число 762, но записанное в разных системах счисления.
i1 = 762 # десятичная система счисления
i2 = 0b1011111010 # двоичная система счисления указывается с помощью префикса "0b" перед числом
i3 = 0o1372 # восьмеричная система счисления указывается с помощью префикса "0o" перед числом
i4 = 0x2FA # шестнадцатеричная система счисления указывается с помощью префикса "0x" перед числом
i1, i2, i3, i4
(762, 762, 762, 762)
Литералов булевого типа, как можно было догадаться, всего два (никакие другие значения булевый тип не может принимать):
b1 = True
b2 = False
b1, b2
(True, False)
В языке Python существует специальная функция type, с помощью которой можно узнать тип переменной или литерала. Чтобы сделать это, нужно вызвать функцию type: написать ее имя в исходном коде и указать в скобках переменную или литерал, чей тип нужно определить. Подробнее о функциях мы поговорим в одной и следующих лекций, а сейчас давайте просто убедимся, что переменная, созданная с помощью литерала определенного типа, получает тип этого литерала:
i1 = 10
b1 = True
type(i1), type(10), type(b1), type(True)
(int, int, bool, bool)
Типы с плавающей точкой¶
Числами с плавающей точкой называются обычные действительные числа, у которых после точки, разделяющей целую и дробную часть может стоять произвольное количество цифр. По причине того, что десятичная точка может находится в разных местах действительного числа, ее и назвали "плавающей". В противовес этому в некоторых языках программирования существует тип для чисел с фиксированной точкой, все значения которого имеют строго определенное количество знаков после десятичной точки. Такой тип может использоваться для хранения денежных сумм, потому что заранее известно, что в дробной части не нужно хранить более чем два знака (например, 100.53$).
Python предоставляет три типа для работы со значениями с плавающей точкой:
- float (от англ. floating) - действительное число ограниченной точности
- complex - комплексное число ограниченной точности
- Decimal - действительное число произвольной точности
Литералы с типом float записываются как числа с десятичной точкой или с помощью экспоненциальной формы. Литералы комплексных чисел записываются как действительная и мнимая части, объединенные знаком + или -, а за мнимной частью следует буква j. При этом если действительная часть равна нулю, то ее можно не указывать вообще.
f1 = 3.14
f2 = 3.28e-3 # экспоненциальная форма, символы 'e-3' означают умножение числа слева от них на 10 в степени -3
c1 = 1.5 + 2.5j
c2 = -10j
f1, f2, c1, c2
(3.14, 0.00328, (1.5+2.5j), (-0-10j))
С помощью функции type мы можем убедиться в том, что переменные получили тот тип, который мы ожидали:
type(f1), type(f2), type(c1), type(c2)
(float, float, complex, complex)
Тип данных complex удобно привести в качестве примера так называемого сложного типа, т.е. типа, имеющего некоторую внутреннюю структуру, к которой есть доступ у программиста (подробнее о сложных типах мы будем говорить в лекции, посвященной классам). Известно, что комплексное число состоит из действительной и мнимой части - вот и тип данных complex внури себя хранит отдельно действительную и мнимую части, представляя их с помощью типа float. Чтобы обратиться к внутренним атрибутам сложного типа используется операция .:
c = -3.5 + 1j
c.real, c.imag
(-3.5, 1.0)
При описании типов float и complex мы говорили о том, что они позволяют хранить значения лишь с ограниченной точностью, то есть при определенных операциях с ними значение, которое в итоге сохранится в переменной, может иметь некоторую погрешность. Поскольку действительная и мнимая часть типа complex имеют тип float (убедитесь в этом сами), то проблемы потери точности при операциях с типом complex являются логическим следствием проблем с типом float, поэтому в дальнейшем мы будем говорить только о нем.
Причина потери точности при работе с переменными с типом float кроется в его физическом представлении, описанном в стандарте IEEE 754, а также в специфике действительных чисел. Согласно стандарту, переменная с типом float имеет размер 64 бита или 8 байт. С помощью 64 бит можно сохранить не более $2^{64}$ различных значений, однако даже между 0 и 0.1 бесконечное количество действительных чисел. Поэтому в стандарте определен специальный механизм отображения бесконечного количества действительных чисел на конечное множество возможных значений типа float. При этом отображении каждому возможному значению типа float ставится в соответствие не одно действительное число, а сразу целый интервал. Таким образом, все действительные числа из этого интервала отображаются в одно и то же значение типа float. Поскольку интервал берется очень маленький, это оказывает незначительную погрешность на результаты вычислений (макимально возможная ошибка составляет примерно $2*10^{-16}$). Однако главная проблема, возникающая при отображении, заключается в том, что одни действительные числа имеют точное представление в переменных типа float, а другие нет. Чтобы увидеть это, нам потребуется функция print, которая используется для вывода произвольной информации на экран, и функция format, с помощью которой можно преобразовывать выводимую информацию некоторым образом, например, указывать количество отображаемых знаков после десятичной точки.
a = 0.5
b = 0.1
print('{:.55f}'.format(a)) # выводим 55 знаков после десятичной точки
print('{:.55f}'.format(b)) # выводим 55 знаков после десятичной точки
a, b # при таком способе вывода интерпретатор отбрасывает "дальние" знаки после десятичной
# точки и выполняет округление, чтобы результат лучше смотрелся на экране
0.5000000000000000000000000000000000000000000000000000000 0.1000000000000000055511151231257827021181583404541015625
(0.5, 0.1)
Заметьте, что число 0.5 представляется абсолютно точно, в то время, как число 0.1 содержит "мусор" в последних знаках. При выполнении вычислений эта ошибка накапливается, что может привести к неожиданным результам при сравнении переменных с типом float. В следующем примере мы используем операцию сравнения ==, которая дает результат True, если значение слева равно значению справа и False в противном случае:
a = 0.1 + 0.1
b = 0.1 + 0.1 + 0.1
a == 0.2, b == 0.3
(True, False)
Как видите, результат первого сравнения тот, что и ожидался, а вот результат второго оказался неправильным из-за накопившейся ошибки. По этой причине сравнения переменных с типом float должны выполняться очень аккуратно, учитывая погрешность в их представлении (в стиле $\left|a-b\right|<=\epsilon$, где $\epsilon$ - устраивающая погрешность).
Еще одна особенность, связанная с типом float, заключается в том, что допустимый диапазон значений для него ограничен интервалом от примерно $-1.79*10^{308}$ до $1.79*10^{308}$. Если попытаться присвоить переменной типа float число вне этого диапазона, то она станет равна специальному значению, трактуемому как $-\infty$ или $+\infty$ (-inf или inf).
a = 1e10
b = a * (-1e300)
c = a * 1e300
b, c
(-inf, inf)
От проблем типа float нас избавляет тип Decimal, чьи значения всегда представляются точно вплоть до определяемого программистом количества знаков после десятичной точки и кроме того не имеют ограничения на минимум или максимум. К сожалению, вычисления с типом Decimal выполняются гораздо медленнее, чем с типом float, поэтому использовать его нужно только в случаях, когда точность имеет критическое значение.
Все типы, которые мы рассматривали до этого, называются встроенными: они являются неотъемлемой частью языка Python и доступны для использования всегда. Тип Decimal не относится к встроенным, и чтобы использовать его, нам потребуется еще одна инструкция, которую мы будем рассматривать подробно в дальнейших лекциях. Эта инструкция называется import и нужна она для того, чтобы подключать к нашей программе модули - файлы, в которых содержатся различные дополнения для языка программирования Python. Описание типа Decimalнаходится в модуле, который называется decimal. Поскольку литералов с типом Decimal не существует, модуль предоставляет специальную функцию, которая преобразует строковое представление действительного числа (указываемое в одинарных или двойных кавычках) в значение типа Decimal. Обратите внимание, что обращение к функции из модуля имеет вид имя_модуля.имя_функции.
import decimal
a = decimal.Decimal('3.141592') # используем функцию decimal.Decimal() для создания переменной с типом Decimal
b = decimal.Decimal("2.718281")
a + b
Decimal('5.859873')
Убедимся теперь, что тип Decimal хранит значения без потери точности: используя его, перепишем рассмотренный ранее пример для типа float.
import decimal
a = decimal.Decimal('0.1') + decimal.Decimal('0.1')
b = decimal.Decimal('0.1') + decimal.Decimal('0.1') + decimal.Decimal('0.1')
a == decimal.Decimal('0.2'), b == decimal.Decimal('0.3')
(True, True)
Как видите, оба сравнения дали ожидаемый результат.
Заметим, что переменные типа Decimal нельзя смешивать в арифметических варажениях с переменными типа float, иначе интерпретатор сгенерирует исключение TypeError. Это как раз пример того, как интерепретатор заботится о программисте с помощью системы типов. Он "видит" противоречие в выражении - одна переменная гарантирует точность представления действительного числа, хранящегося в ней, а другая нет. Следовательно, итоговый результат может содержать погрешность, поэтому интерпретатор решает на всякий случай перестать выполнять такую программу и выдать сообщение об ошибке. Программист в этом случае сразу увидит, что написал потенциально ошибочный код и исправит ситуацию (например, поменяет тип переменной float на тип Decimal).
import decimal
a = decimal.Decimal('0.1') # a имеет тип Decimal
b = 0.1 # b имеет тип float
a + b # значение типа Decimal складывается со значением типа float
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-15-d018ee54750b> in <module>() 4 b = 0.1 # b имеет тип float 5 ----> 6 a + b # значение типа Decimal складывается со значением типа float TypeError: unsupported operand type(s) for +: 'decimal.Decimal' and 'float'
Важным свойством типа Decimal является то, что его можно дополнительно настроить, задав желаемую точность и метод округления в арфиметических выражениях с этим типом, а также некоторые другие параметры, которые в совокупности называются контекстом типа Decimal. Контекст представляет собой переменную сложного типа Context, получить которую можно с помощью функции getcontext из модуля decimal:
import decimal
context = decimal.getcontext()
context
Context(prec=28, rounding=ROUND_HALF_EVEN, Emin=-999999, Emax=999999, capitals=1, clamp=0, flags=[], traps=[InvalidOperation, DivisionByZero, Overflow])
Внутренний атрибут prec контекста содержит количество точных знаков в числе с типом Decimal, причем учитываются как знаки до десятичной точки, так и после. Атрибиут rounding определяет используемый метод округления, если при выполнении арифметической операции с переменными типа Decimal результат не может быть представлен точно. Мы не будем подробно рассматривать все атрибуты контекста - информацию по ним можно найти в официальной документации Python, доступной в меню Help.
import decimal
a = decimal.Decimal('1.723')
b = decimal.Decimal('1.051')
decimal.getcontext().prec = 4
c = a + b
decimal.getcontext().prec = 2
d = a + b
c, d
(Decimal('2.774'), Decimal('2.8'))
В примере выше можно заметить, как работает атрибут prec: при вычислении переменной c он равен 4, поэтому c получает абсолютно точное значение, а при вычислении d точность равна 2, поэтому вычисляются лишь первые два знака, причем для второго используется округление.
Строки¶
Для работы с текстовыми строками в языке программирования Python предназначен тип данных str. Литералы этого типа представляют собой текст, обрамленный с помощью одинарных или двойных кавычек (при этом важно, чтобы с обеих сторон использовался один и тот же символ кавычек):
s1 = 'hello'
s2 = "world"
s1, s2, type(s1), type(s2)
('hello', 'world', str, str)
Вы можете сами выбрать, какие именно кавычки использовать для литералов строкового типа в своих программах. Главное, чтобы вы не использовали их вперемешку. Авторам курса нравится, что для набора символа одинарной кавычки не нужно использовать клавишу Shift, поэтому в примерах используется он.
Если в строковом литерале есть символы одинарных или двойных кавычек, то для того, чтобы интерпретатор Python не принял их за кавычки, ограничивающие литерал, перед каждой из внутренних кавычек ставится символ "" (это называется экранированием символа). Рассмотрим пример, где внутренний символ кавычки не экранируется:
s1 = 'my favourite book is 'Tom Sawyer'' # кавычки, используемые для выделения названия книги не экранируются
s1
File "<ipython-input-19-fd94de0ea25c>", line 1 s1 = 'my favourite book is 'Tom Sawyer'' # кавычки, используемые для выделения названия книги не экранируются ^ SyntaxError: invalid syntax
Как видите, интерпретатор сгенерировал исключение SyntaxError. Это произошло по той причине, что в процессе разбора исходного кода он обнаружил строковый литерал 'my favourite book is ', а после него какую-то совершенно незнакомую ему конструкцию Tom Sawyer. Исправим ошибку в предыдущем примере:
s1 = 'my favourite book is \'Tom Sawyer\'' # внутренние кавычки экранированы
s1
"my favourite book is 'Tom Sawyer'"
Существует еще другие полезные конструкции, которые можно добавлять в строковые литералы с помощью символа "". Перечислим некоторые из них:
- \\ - чтобы добавить в литерал символ "" (по сути, это аналогично экранированию кавычки, только для символа "")
- \t - добавить в литерал табуляцию (горизонтальный отступ)
- \n - добавить в литерал перевод строки
При нашем обычном способе вывода значений переменных, интерпретатор не обрабатывает специальные последовательности, описанные выше. Чтобы увидеть их действие, нужно вновь воспользоваться функцией print:
s1 = 'this\tis\ttabulation\texample' # используем табуляцию вместо пробелов
s2 = '\\\\' # на самом деле это литерал из двух символов "\"
s3 = 'first line\nsecond line'
print(s1)
print(s2)
print(s3)
this is tabulation example \\ first line second line
В памяти компьютера любые текстовые данные представляют собой набор чисел. Для отображения их как привычного текста используются различные таблицы кодировки, устанавливающие соответствие между этими числами и определенными символами. Наиболее известной кодировкой является ASCII, ниже представлен фрагмент ее таблицы:
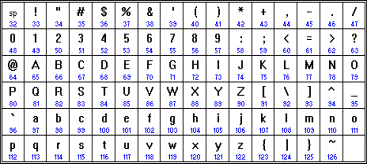
Из нее видно, что, например, числу 119 в памяти компьютера соответствует буква "w" английского алфавита, а числу 87 - она же, но заглавная.
Кодировка ASCII используется только для английского алфавита. Чтобы иметь возможность закодировать любой символ любого известного алфавита был создан стандарт кодирования Unicode. В нем описываются практически все известные алфавиты, каждому символу которых поставлено в соответствии некоторое число для представления его в памяти компьютера. В языке программирования Python тип данных str используется для хранения символов в кодировке Unicode.
s = 'это строка, содержащая текст на русском языке'
s
'это строка, содержащая текст на русском языке'
Ссылки¶
В языке программирования Python все переменные являются ссылками - так называются специальные объекты, которые хранят не само значение, а адрес участка памяти, где это значение хранится. По сути, в языке Python понятия переменной и ссылки являются взаимозаменяемыми. Чтобы понять, как переменные-ссылки связаны с их значениями, рассмотрим следующий пример:
a = 1
a = a + 1
b = a
a, b
(2, 2)
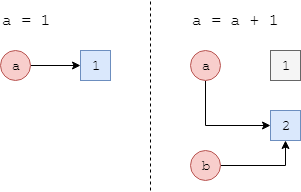
На рисунке выше значение типа int, хранящееся в памяти, представлено в квадрате, а переменные-ссылки - кругом. Этот рисунок иллюстрирует то, что происходит при выполнении программы:
- При выполнении первой инструкции в памяти выделяется участок для хранения числа 1 и создается переменная
a, которая является ссылкой, то есть хранит не значение 1, а его адрес в памяти. - Во второй инструкции вначале через ссылку получается текущее значение, связанное с идентификатором
a(это 1), затем оно складывается с 1. Полученный результат (число 2) сохраняется в некоторый новый участок памяти, и его адрес присваиваетсяa - Третья инструкция показывает, что когда переменной присваивается другая переменная (а не константа или результат некоторого арифметического выражения), никакого нового участка памяти не выделяется, вместо этого интерпретатор просто заставляет новую переменную
bссылаться туда же, куда ссылаетсяa.
Обратите внимание на то, что после выполнения программы участок памяти, на который ссылалась переменная a в конце первой инструкции, оказывается неиспользуемым (серый квадрат) - на него больше нет ссылок. Такие участки памяти называются мусором, потому что программе, когда-то ранее создавшей их в процессе своего выполнения, они больше не нужны. Чтобы память, занимаемая мусором, снова стала доступна программе, интерпретатор Python периодически в фоновом режиме запускает специальную программу, называемую сборщиком мусора, чья задача - обнаруживать ненужные уже участки памяти и осовобождать их для дальнейшего использования.
В некоторых языках программирования отсутствует автоматическая сборка мусора, и программисту приходится самому следить за тем, чтобы его программа не забывала освобождать ненужные участки памяти, иначе происходит так называемая утечка: из-за того, что некоторые участки не осовобождаются, программе постепенно остается все меньше и меньше памяти, пока она не закончится совсем, и программа аварийно не завершит свою работу.
Язык Python предоставляет специальную операцию is, которая дает результат True, если две переменные являются ссылками на одну и ту же область памяти, и False в противном случае. Операция is not возвращает противоположный результат: True, если переменные являются ссылками на разные области памяти и False в противном случае. Рассмотрим пример и рисунок, поясняющий его:
a = 500
b = a
c = 500
a is b, a == b, a is not c, a == c
(True, True, True, True)
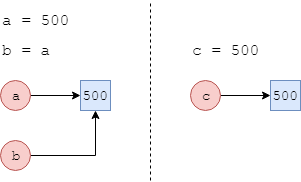
Из рисунка видно, что в результате выполнения первых двух строчек кода переменные a и b ссылаются на одну и ту же область памяти, поэтому как операция a is b, так и простое сравнение значений этих переменных a == b дает результат True. Переменная же c является ссылкой на совершенно иной участок памяти, поэтому операция a is not c, проверяющая, что a и c указывают на разные места, дает результат True. Однако, поскольку в обоих участках памяти хранится значение 500, проверка на их равенство a == c дает True.
В Python есть встроенная функция id, с помощью которой можно получить число, уникально идентифицирующее каждый объект. В качестве такого числа Python может использовать адрес объекта в памяти или некую другую информацию. Для нас важно, что если ссылки указывают на один объект, то при вызове функции id для них мы увидим одно и то же число:
id(a), id(b), id(c) # из предыдущего примера: a и b указывают на один объект, c на другой
(111805680, 111805680, 111804688)
Изменяемость типов данных¶
Все типы данных в Python можно разделить на две группы: неизменяемые (unmutable) и изменяемые (mutable).
Тип данных называется неизменяемым, если после создания и инициализации значения с таким типом в памяти оно не может быть изменено. К неизменяемым типам относятся почти все типы, рассмотренные в этой лекции (а также и некоторые другие): int, bool, float, complex, Decimal и str. Каждый раз, когда переменной с неизменяемым типом присваивается новое значение, интерпретатор выделяет участок памяти, в который записывает его, а ссылку заставляет указывать на этот участок памяти.
Очевидно, что изменяемым тип данных называется в случае, если после создания значения с таким типом оно может быть изменено. Несколько изменяемых типов данных мы встретим в лекции, посвященной коллекциям, а в этой лекции мы рассмотрели лишь один изменяемый тип данных - тип Context, хранящий данные контекста типа Decimal. Каждый раз, когда у переменной с изменяемым типом модифицируется значение, обновление происходит в том же участке памяти, где хранится предыдущее значение, то есть новый участок памяти не выделяется.
Вернемся к первому примеру в разделе Ссылки. Обратите внимание, что когда мы увеличиваем переменную a на 1 операцией a = a + 1, значение, на которое указывало a ранее, не меняется - вместо этого в памяти создается новое значение, инициализируется числом 2, и переменная a начинает ссылаться на него! Если бы тип int, который имеет переменная a, был изменяемым, то вместо создания нового значения было бы изменено существующее. Это нужно учитывать, когда несколько переменных ссылаются на один и тот же участок памяти: если они имеют изменяемый тип, то при модификации значения с помощью одной переменной, изменения станут видны при обращении через другую. Рассмотрим следующий пример:
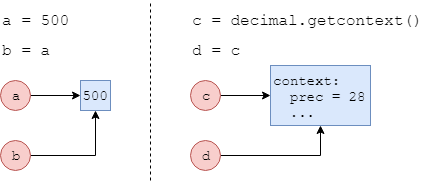
import decimal
a = 500
b = a
c = decimal.getcontext()
d = c
a, b, c.prec, d.prec, a is b, c is d
(500, 500, 2, 2, True, True)
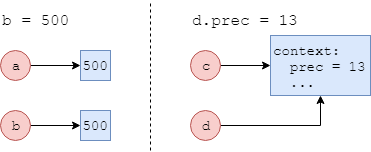
Как видите, переменные a и b ссылаются на один и тот же участок памяти, как и переменные c и d, что иллюстрирует следующий рисунок (напомним, что разделе Ссылки говорилось о том, что при присваивании одной переменной другой память для значения не выделяется, просто новая переменная начинает указывать на тот же участок, что и старая):
Продолжим нашу программу, изменив значение переменной b и атрибута d.prec:
b = 500
d.prec = 13
a, b, c.prec, d.prec, a is b, c is d
(500, 500, 13, 13, False, True)
Теперь мы видим разницу между неизменяемыми и изменяемыми типами. После того, как переменной b неизменяемого типа int была присвоена константа 500, интерпретатор выделил новый участок памяти для этого значения и заставил b ссылаться на него, поэтому a is b теперь равно False, хоть их значения по-прежнему одинаковы. Модификация же внутреннего атрибута prec изменяемого типа Context произошла в первоначально выделенном участке памяти, оставив переменные c и d ссылаться на старый адрес. При этом изменения, выполненные через переменную d, стали видны и через переменную c, что становится очевидным, если взглянуть на следующий рисунок:
Вопросы для самоконтроля¶
- Что такое переменная? Идентификатор? Ссылка?
- Что такое литерал? Приведите пример литерала для трех разных типов данных.
- Какие из представленных далее идентификаторов являются корректными в языке Python? Какие из корректных идентификаторов тем не менее не стоит использовать в программах и почему? Список идентификаторов:
for,variable1,total_sum,day_of_month,a,true,количество_элементов,1_percent - Объясните своими словами, в чем заключается польза от использования типов данных в языках программирования.
- Какие виды типизации существуют? Какие из них относятся к языку Python?
- В чем отличие между типами
floatиDecimal? - Что такое сложный тип данных?
- Перечислите встроенные в Python типы данных. Какие из них являются неизменяемыми?
- Что задает таблица кодировки?
- Можно ли сохранить строку, содержащую текст из китайских иероглифов, в переменной
strв Python? - В чем заключается работа сборщика мусора? Приведите пример. Возможны ли утечки памяти в программах на языке программирования Python?
Задание¶
- Создайте рисунок, на котором объясняется, куда ссылаются переменные после выполнения программы, представленной ниже (как сделано в разделах, посвященных ссылкам и изменяемости типов данных). На рисунке также должны присутствовать участки памяти, на которые не осталось ссылок и которые могут быть утилизированы сборщиком мусора.
import decimal
a = 1
b = 2
c = 3
a = a + b + c
b = c - 1
s1 = 'hello'
s2 = s1
s1 = 'world'
x = decimal.getcontext()
y = x
x.prec = 20