Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)¶
- Credit:
- notebook created from the notebook Fine_tuning_LayoutXLM_on_XFUND_for_token_classification_using_HuggingFace_Trainer.ipynb
- dataset from IBM Research (DocLayNet)
- Author of this notebook: Pierre GUILLOU
- Date: 31/03/2023
- Blog posts:
- Layout XLM base
- (03/31/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level with LayoutXLM base
- (03/25/2023) Document AI | APP to compare the Document Understanding LiLT and LayoutXLM (base) models at line level
- (03/05/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base
- LiLT base
- (02/16/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level
- (02/14/2023) Document AI | Inference APP for Document Understanding at line level
- (02/10/2023) Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset
- (01/31/2023) Document AI | DocLayNet image viewer APP
- (01/27/2023) Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
- Layout XLM base
- Notebooks (paragraph level)
- Layout XLM base
- Document AI | Inference at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at paragraph level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
- LiLT base
- Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
- Layout XLM base
- Notebooks (line level)
- Layout XLM base
- Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- LiLT base
- Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- DocLayNet image viewer APP
- Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
- Layout XLM base
Overview¶
LayoutXLM¶
LayoutXLM was proposed in LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Furu Wei.
It is a Document Understanding model that uses both layout and text in order to detect labels of bounding boxes. More, it’s a multilingual extension of the LayoutLMv2 model trained on 53 languages.
Sources: LayoutXLM on Hugging Face
DocLayNet¶
DocLayNet dataset¶
DocLayNet dataset (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face dataset library: dataset DocLayNet
Paper: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
Processing into a format facilitating its use by HF notebooks¶
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately (doclaynet_extra.zip, 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- DocLayNet small (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- DocLayNet base (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- DocLayNet large (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
Note: the layout HF notebooks will greatly help participants of the IBM ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents!
About PDFs languages¶
Citation of the page 3 of the DocLayNet paper: "We did not control the document selection with regard to language. The vast majority of documents contained in DocLayNet (close to 95%) are published in English language. However, DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%). While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
About PDFs categories distribution¶
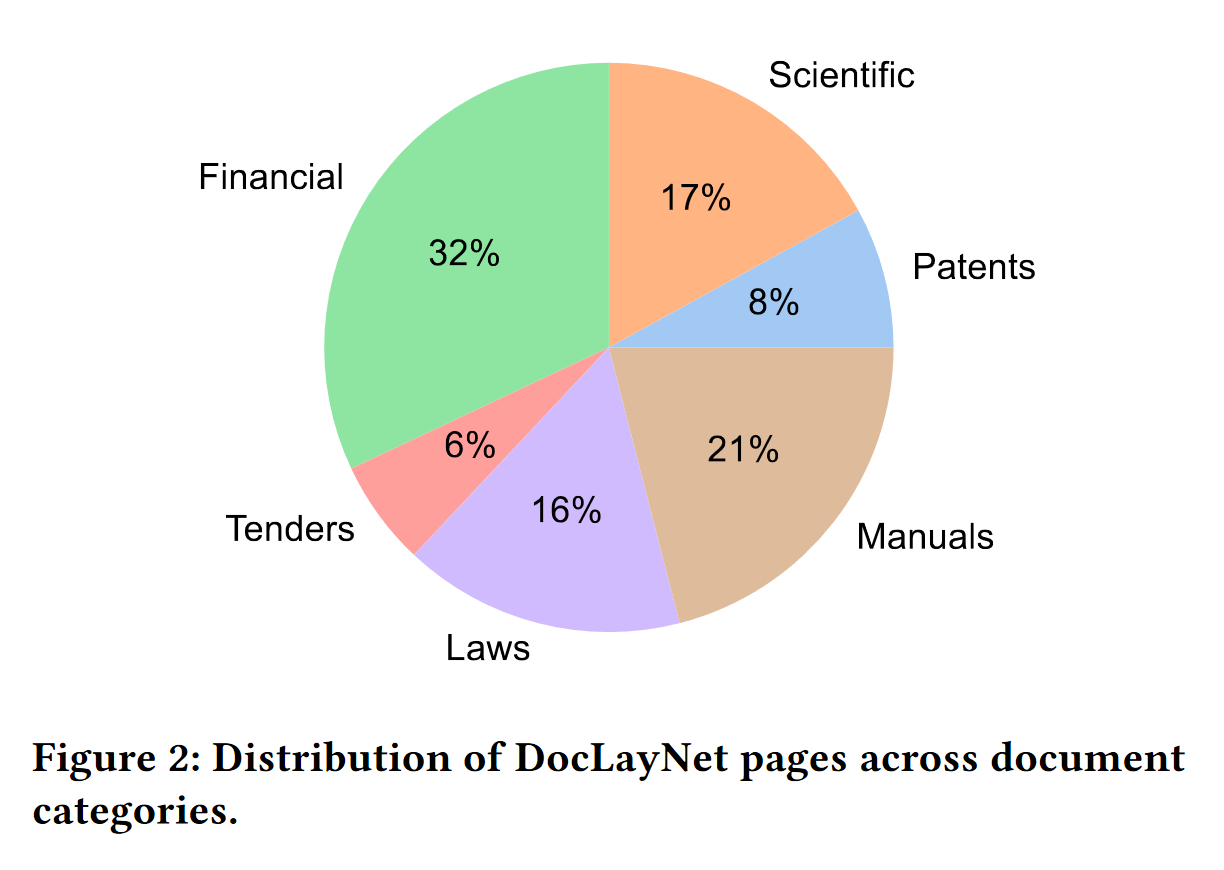
Citation of the page 3 of the DocLayNet paper: "The pages in DocLayNet can be grouped into six distinct categories, namely Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
DocLayNet Labels¶
The DocLayNet labels have the following meaning (source: IBM DocLayNet Labeling Guide)
- Text: Regular paragraphs.
- Picture: A graphic or photograph.
- Caption: Special text outside a picture or table that introduces this picture or table.
- Section-header: Any kind of heading in the text, except overall document title.
- Footnote: Typically small text at the bottom of a page, with a number or symbol that is referred to in the text above.
- Formula: Mathematical equation on its own line.
Further labels not shown in the example above:
- Table: Material arranged in a grid alignment with rows and columns, often with separator lines.
- List-item: One element of a list, in a hanging shape, i.e., from the second line onwards the paragraph is indented more than the first line.
- Page-header: Repeating elements like page number at the top, outside of the normal text flow.
- Page-footer: Repeating elements like page number at the bottom, outside of the normal text flow.
- Title: 1 Overall title of a document, (almost) exclusively on the first page and
- typically appearing in large font.
- None: Initial state of each cell/element. Only keep this if the element is not a text or picture or anything else of value. For instance, a smear or an invisible/empty cell should remain “None
!nvidia-smi
Set-up environment¶
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
Mounted at /content/drive
Libraries¶
!pip install -q transformers datasets sentencepiece seqeval
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.8/6.8 MB 84.9 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 469.0/469.0 KB 45.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 78.6 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 43.6/43.6 KB 5.7 MB/s eta 0:00:00 Preparing metadata (setup.py) ... done ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.6/7.6 MB 111.5 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 199.8/199.8 KB 22.0 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 212.2/212.2 KB 21.6 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.0/1.0 MB 62.4 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.9/132.9 KB 16.7 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 110.5/110.5 KB 15.7 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 264.6/264.6 KB 32.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 114.2/114.2 KB 16.5 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 158.8/158.8 KB 21.5 MB/s eta 0:00:00 Building wheel for seqeval (setup.py) ... done
# Detectron 2
!pip install -q torch==1.10.0+cu111 torchvision==0.11+cu111 -f https://download.pytorch.org/whl/torch_stable.html
!python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 2.1/2.1 GB 678.8 kB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 21.8/21.8 MB 68.9 MB/s eta 0:00:00 ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. torchtext 0.14.1 requires torch==1.13.1, but you have torch 1.10.0+cu111 which is incompatible. torchaudio 0.13.1+cu116 requires torch==1.13.1, but you have torch 1.10.0+cu111 which is incompatible. Looking in indexes: https://pypi.org/simple, https://us-python.pkg.dev/colab-wheels/public/simple/ Collecting git+https://github.com/facebookresearch/detectron2.git Cloning https://github.com/facebookresearch/detectron2.git to /tmp/pip-req-build-0034o1cj Running command git clone --filter=blob:none --quiet https://github.com/facebookresearch/detectron2.git /tmp/pip-req-build-0034o1cj Resolved https://github.com/facebookresearch/detectron2.git to commit e2ce8dc1ab097891395d324abaffe9cf298503d1 Preparing metadata (setup.py) ... done Requirement already satisfied: Pillow>=7.1 in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (8.4.0) Requirement already satisfied: matplotlib in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (3.7.1) Requirement already satisfied: pycocotools>=2.0.2 in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (2.0.6) Requirement already satisfied: termcolor>=1.1 in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (2.2.0) Collecting yacs>=0.1.8 Downloading yacs-0.1.8-py3-none-any.whl (14 kB) Requirement already satisfied: tabulate in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (0.8.10) Requirement already satisfied: cloudpickle in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (2.2.1) Requirement already satisfied: tqdm>4.29.0 in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (4.65.0) Requirement already satisfied: tensorboard in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (2.11.2) Collecting fvcore<0.1.6,>=0.1.5 Downloading fvcore-0.1.5.post20221221.tar.gz (50 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 50.2/50.2 KB 7.4 MB/s eta 0:00:00 Preparing metadata (setup.py) ... done Collecting iopath<0.1.10,>=0.1.7 Downloading iopath-0.1.9-py3-none-any.whl (27 kB) Collecting omegaconf>=2.1 Downloading omegaconf-2.3.0-py3-none-any.whl (79 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 79.5/79.5 KB 7.5 MB/s eta 0:00:00 Collecting hydra-core>=1.1 Downloading hydra_core-1.3.2-py3-none-any.whl (154 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 154.5/154.5 KB 19.6 MB/s eta 0:00:00 Collecting black Downloading black-23.1.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.6 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 66.6 MB/s eta 0:00:00 Requirement already satisfied: packaging in /usr/local/lib/python3.9/dist-packages (from detectron2==0.6) (23.0) Requirement already satisfied: numpy in /usr/local/lib/python3.9/dist-packages (from fvcore<0.1.6,>=0.1.5->detectron2==0.6) (1.22.4) Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.9/dist-packages (from fvcore<0.1.6,>=0.1.5->detectron2==0.6) (6.0) Collecting antlr4-python3-runtime==4.9.* Downloading antlr4-python3-runtime-4.9.3.tar.gz (117 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 117.0/117.0 KB 13.6 MB/s eta 0:00:00 Preparing metadata (setup.py) ... done Collecting portalocker Downloading portalocker-2.7.0-py2.py3-none-any.whl (15 kB) Requirement already satisfied: importlib-resources>=3.2.0 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (5.12.0) Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (2.8.2) Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (1.4.4) Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (0.11.0) Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (1.0.7) Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (4.39.2) Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.9/dist-packages (from matplotlib->detectron2==0.6) (3.0.9) Requirement already satisfied: platformdirs>=2 in /usr/local/lib/python3.9/dist-packages (from black->detectron2==0.6) (3.1.1) Collecting mypy-extensions>=0.4.3 Downloading mypy_extensions-1.0.0-py3-none-any.whl (4.7 kB) Requirement already satisfied: click>=8.0.0 in /usr/local/lib/python3.9/dist-packages (from black->detectron2==0.6) (8.1.3) Requirement already satisfied: typing-extensions>=3.10.0.0 in /usr/local/lib/python3.9/dist-packages (from black->detectron2==0.6) (4.5.0) Requirement already satisfied: tomli>=1.1.0 in /usr/local/lib/python3.9/dist-packages (from black->detectron2==0.6) (2.0.1) Collecting pathspec>=0.9.0 Downloading pathspec-0.11.1-py3-none-any.whl (29 kB) Requirement already satisfied: requests<3,>=2.21.0 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (2.27.1) Requirement already satisfied: absl-py>=0.4 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (1.4.0) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (0.40.0) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (67.6.0) Requirement already satisfied: google-auth<3,>=1.6.3 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (2.16.2) Requirement already satisfied: tensorboard-plugin-wit>=1.6.0 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (1.8.1) Requirement already satisfied: werkzeug>=1.0.1 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (2.2.3) Requirement already satisfied: tensorboard-data-server<0.7.0,>=0.6.0 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (0.6.1) Requirement already satisfied: protobuf<4,>=3.9.2 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (3.19.6) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (3.4.2) Requirement already satisfied: google-auth-oauthlib<0.5,>=0.4.1 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (0.4.6) Requirement already satisfied: grpcio>=1.24.3 in /usr/local/lib/python3.9/dist-packages (from tensorboard->detectron2==0.6) (1.51.3) Requirement already satisfied: pyasn1-modules>=0.2.1 in /usr/local/lib/python3.9/dist-packages (from google-auth<3,>=1.6.3->tensorboard->detectron2==0.6) (0.2.8) Requirement already satisfied: six>=1.9.0 in /usr/local/lib/python3.9/dist-packages (from google-auth<3,>=1.6.3->tensorboard->detectron2==0.6) (1.16.0) Requirement already satisfied: cachetools<6.0,>=2.0.0 in /usr/local/lib/python3.9/dist-packages (from google-auth<3,>=1.6.3->tensorboard->detectron2==0.6) (5.3.0) Requirement already satisfied: rsa<5,>=3.1.4 in /usr/local/lib/python3.9/dist-packages (from google-auth<3,>=1.6.3->tensorboard->detectron2==0.6) (4.9) Requirement already satisfied: requests-oauthlib>=0.7.0 in /usr/local/lib/python3.9/dist-packages (from google-auth-oauthlib<0.5,>=0.4.1->tensorboard->detectron2==0.6) (1.3.1) Requirement already satisfied: zipp>=3.1.0 in /usr/local/lib/python3.9/dist-packages (from importlib-resources>=3.2.0->matplotlib->detectron2==0.6) (3.15.0) Requirement already satisfied: importlib-metadata>=4.4 in /usr/local/lib/python3.9/dist-packages (from markdown>=2.6.8->tensorboard->detectron2==0.6) (6.1.0) Requirement already satisfied: charset-normalizer~=2.0.0 in /usr/local/lib/python3.9/dist-packages (from requests<3,>=2.21.0->tensorboard->detectron2==0.6) (2.0.12) Requirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.9/dist-packages (from requests<3,>=2.21.0->tensorboard->detectron2==0.6) (1.26.15) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.9/dist-packages (from requests<3,>=2.21.0->tensorboard->detectron2==0.6) (2022.12.7) Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.9/dist-packages (from requests<3,>=2.21.0->tensorboard->detectron2==0.6) (3.4) Requirement already satisfied: MarkupSafe>=2.1.1 in /usr/local/lib/python3.9/dist-packages (from werkzeug>=1.0.1->tensorboard->detectron2==0.6) (2.1.2) Requirement already satisfied: pyasn1<0.5.0,>=0.4.6 in /usr/local/lib/python3.9/dist-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard->detectron2==0.6) (0.4.8) Requirement already satisfied: oauthlib>=3.0.0 in /usr/local/lib/python3.9/dist-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<0.5,>=0.4.1->tensorboard->detectron2==0.6) (3.2.2) Building wheels for collected packages: detectron2, fvcore, antlr4-python3-runtime Building wheel for detectron2 (setup.py) ... done Created wheel for detectron2: filename=detectron2-0.6-cp39-cp39-linux_x86_64.whl size=6566533 sha256=30e83caa2433c80f9556e3856ce0216cb70c0d135f3db276c64ea0a668607689 Stored in directory: /tmp/pip-ephem-wheel-cache-boqzdze6/wheels/59/b4/83/84bfca751fa4dcc59998468be8688eb50e97408a83af171d42 Building wheel for fvcore (setup.py) ... done Created wheel for fvcore: filename=fvcore-0.1.5.post20221221-py3-none-any.whl size=61429 sha256=252f10e0a0e9b6e2610f8d2b93fedc5c944540dcebf4abf2d9721976978178ad Stored in directory: /root/.cache/pip/wheels/83/42/02/66178d16e5c44dc26d309931834956baeda371956e86fbd876 Building wheel for antlr4-python3-runtime (setup.py) ... done Created wheel for antlr4-python3-runtime: filename=antlr4_python3_runtime-4.9.3-py3-none-any.whl size=144573 sha256=28270633f4ecd7d5232e33afd5cdd8cce405843b0388de3d25042bbc41aae3f2 Stored in directory: /root/.cache/pip/wheels/23/cf/80/f3efa822e6ab23277902ee9165fe772eeb1dfb8014f359020a Successfully built detectron2 fvcore antlr4-python3-runtime Installing collected packages: antlr4-python3-runtime, yacs, portalocker, pathspec, omegaconf, mypy-extensions, iopath, hydra-core, black, fvcore, detectron2 Successfully installed antlr4-python3-runtime-4.9.3 black-23.1.0 detectron2-0.6 fvcore-0.1.5.post20221221 hydra-core-1.3.2 iopath-0.1.9 mypy-extensions-1.0.0 omegaconf-2.3.0 pathspec-0.11.1 portalocker-2.7.0 yacs-0.1.8
import numpy as np
from operator import itemgetter
import collections
import pandas as pd
import random
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw, ImageFont
font = ImageFont.load_default()
import cv2
# In Colab, use cv2_imshow instead of cv2.imshow
from google.colab.patches import cv2_imshow # Colab
from ipywidgets import widgets
from IPython.display import display, HTML
from datasets import concatenate_datasets
Key parameters¶
# categories colors
label2color = {
'Caption': 'brown',
'Footnote': 'orange',
'Formula': 'gray',
'List-item': 'yellow',
'Page-footer': 'red',
'Page-header': 'red',
'Picture': 'violet',
'Section-header': 'orange',
'Table': 'green',
'Text': 'blue',
'Title': 'pink'
}
domains = ["Financial Reports", "Manuals", "Scientific Articles", "Laws & Regulations", "Patents", "Government Tenders"]
domain_names = [domain_name.lower().replace(" ", "_").replace("&", "and") for domain_name in domains]
# bounding boxes start and end of a sequence
cls_box = [0, 0, 0, 0]
sep_box = [1000, 1000, 1000, 1000]
# DocLayNet dataset
# dataset_name = "pierreguillou/DocLayNet-small"
dataset_name = "pierreguillou/DocLayNet-base"
dataset_name_suffix = dataset_name.replace("pierreguillou/DocLayNet-", "")
# parameters for tokenization and overlap
max_length = 512 # The maximum length of a feature (sequence)
doc_stride = 128 # The authorized overlap between two part of the context when splitting it is needed.
# PAD token index
label_pad_token_id = -100
# parameters de TrainingArguments
batch_size=8 # WARNING: change this value according to your GPU RAM
num_train_epochs=4
learning_rate=2e-5
per_device_train_batch_size=batch_size
per_device_eval_batch_size=batch_size*2
gradient_accumulation_steps=1
warmup_ratio=0.1
evaluation_strategy="steps"
eval_steps=200
save_steps=200 # eval_steps
save_total_limit=1
load_best_model_at_end=True
metric_for_best_model="f1"
report_to="tensorboard"
fp16=True
push_to_hub=True # we'd like to push our model to the hub during training
hub_private_repo=True
hub_strategy="all_checkpoints"
# model name in HF
version = 6 # version number
output_dir = "DocLayNet/layout-xlm-base-finetuned-" + dataset_name.replace("pierreguillou/", "") + "_paragraphs_ml" + str(max_length) + "-v" + str(version)
hub_model_id = "pierreguillou/layout-xlm-base-finetuned-" + dataset_name.replace("pierreguillou/", "") + "_paragraphs_ml" + str(max_length) + "-v" + str(version)
Functions¶
General¶
# it is important that each bounding box should be in (upper left, lower right) format.
# source: https://github.com/NielsRogge/Transformers-Tutorials/issues/129
def upperleft_to_lowerright(bbox):
x0, y0, x1, y1 = tuple(bbox)
if bbox[2] < bbox[0]:
x0 = bbox[2]
x1 = bbox[0]
if bbox[3] < bbox[1]:
y0 = bbox[3]
y1 = bbox[1]
return [x0, y0, x1, y1]
# convert boundings boxes (left, top, width, height) format to (left, top, left+widght, top+height) format.
def convert_box(bbox):
x, y, w, h = tuple(bbox) # the row comes in (left, top, width, height) format
return [x, y, x+w, y+h] # we turn it into (left, top, left+widght, top+height) to get the actual box
# LiLT model gets 1000x10000 pixels images
def normalize_box(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]
# LiLT model gets 1000x10000 pixels images
def denormalize_box(bbox, width, height):
return [
int(width * (bbox[0] / 1000)),
int(height * (bbox[1] / 1000)),
int(width* (bbox[2] / 1000)),
int(height * (bbox[3] / 1000)),
]
# get back original size
def original_box(box, original_width, original_height, coco_width, coco_height):
return [
int(original_width * (box[0] / coco_width)),
int(original_height * (box[1] / coco_height)),
int(original_width * (box[2] / coco_width)),
int(original_height* (box[3] / coco_height)),
]
def get_blocks(bboxes_block, categories, texts):
# get list of unique block boxes
bbox_block_dict, bboxes_block_list, bbox_block_prec = dict(), list(), list()
for count_block, bbox_block in enumerate(bboxes_block):
if bbox_block != bbox_block_prec:
bbox_block_indexes = [i for i, bbox in enumerate(bboxes_block) if bbox == bbox_block]
bbox_block_dict[count_block] = bbox_block_indexes
bboxes_block_list.append(bbox_block)
bbox_block_prec = bbox_block
# get list of categories and texts by unique block boxes
category_block_list, text_block_list = list(), list()
for bbox_block in bboxes_block_list:
count_block = bboxes_block.index(bbox_block)
bbox_block_indexes = bbox_block_dict[count_block]
category_block = np.array(categories, dtype=object)[bbox_block_indexes].tolist()[0]
category_block_list.append(category_block)
text_block = np.array(texts, dtype=object)[bbox_block_indexes].tolist()
text_block = [text.replace("\n","").strip() for text in text_block]
if id2label[category_block] == "Text" or id2label[category_block] == "Caption" or id2label[category_block] == "Footnote":
text_block = ' '.join(text_block)
else:
text_block = '\n'.join(text_block)
text_block_list.append(text_block)
return bboxes_block_list, category_block_list, text_block_list
# function to sort bounding boxes
def get_sorted_boxes(bboxes):
# sort by y from page top to bottom
sorted_bboxes = sorted(bboxes, key=itemgetter(1), reverse=False)
y_list = [bbox[1] for bbox in sorted_bboxes]
# sort by x from page left to right when boxes with same y
if len(list(set(y_list))) != len(y_list):
y_list_duplicates_indexes = dict()
y_list_duplicates = [item for item, count in collections.Counter(y_list).items() if count > 1]
for item in y_list_duplicates:
y_list_duplicates_indexes[item] = [i for i, e in enumerate(y_list) if e == item]
bbox_list_y_duplicates = sorted(np.array(sorted_bboxes, dtype=object)[y_list_duplicates_indexes[item]].tolist(), key=itemgetter(0), reverse=False)
np_array_bboxes = np.array(sorted_bboxes)
np_array_bboxes[y_list_duplicates_indexes[item]] = np.array(bbox_list_y_duplicates)
sorted_bboxes = np_array_bboxes.tolist()
return sorted_bboxes
# sort data from y = 0 to end of page (and after, x=0 to end of page when necessary)
def sort_data(bboxes, categories, texts):
sorted_bboxes = get_sorted_boxes(bboxes)
sorted_bboxes_indexes = [bboxes.index(bbox) for bbox in sorted_bboxes]
sorted_categories = np.array(categories, dtype=object)[sorted_bboxes_indexes].tolist()
sorted_texts = np.array(texts, dtype=object)[sorted_bboxes_indexes].tolist()
return sorted_bboxes, sorted_categories, sorted_texts
Dataset¶
# get PDF image and its data
def generate_annotated_image(index_image=None, split="all"):
# get dataset
example = dataset
# get split
if split == "all":
example = concatenate_datasets([example["train"], example["validation"], example["test"]])
else:
example = example[split]
# get random image & PDF data
if index_image == None: index_image = random.randint(0, len(example)-1)
example = example[index_image]
image = example["image"] # original image
coco_width, coco_height = example["coco_width"], example["coco_height"]
original_width, original_height = example["original_width"], example["original_height"]
original_filename = example["original_filename"]
page_no = example["page_no"]
num_pages = example["num_pages"]
# resize image to original
image = image.resize((original_width, original_height))
# get corresponding annotations
texts = example["texts"]
bboxes_block = example["bboxes_block"]
bboxes_line = example["bboxes_line"]
categories = example["categories"]
domain = example["doc_category"]
# get domain name
index_domain = domain_names.index(domain)
domain = domains[index_domain]
# convert boxes to original
original_bboxes_block = [original_box(convert_box(box), original_width, original_height, coco_width, coco_height) for box in bboxes_block]
original_bboxes_line = [original_box(convert_box(box), original_width, original_height, coco_width, coco_height) for box in bboxes_line]
##### block boxes #####
# get unique blocks and its data
bboxes_blocks_list, category_block_list, text_block_list = get_blocks(original_bboxes_block, categories, texts)
# sort data from y = 0 to end of page (and after, x=0 to end of page when necessary)
sorted_original_bboxes_block_list, sorted_category_block_list, sorted_text_block_list = sort_data(bboxes_blocks_list, category_block_list, text_block_list)
##### line boxes ####
# sort data from y = 0 to end of page (and after, x=0 to end of page when necessary)
sorted_original_bboxes_line_list, sorted_category_line_list, sorted_text_line_list = sort_data(original_bboxes_line, categories, texts)
# group paragraphs and lines outputs
sorted_original_bboxes = [sorted_original_bboxes_block_list, sorted_original_bboxes_line_list]
sorted_categories = [sorted_category_block_list, sorted_category_line_list]
sorted_texts = [sorted_text_block_list, sorted_text_line_list]
# get annotated boudings boxes on images
images = [image.copy(), image.copy()]
imgs, df_paragraphs, df_lines = dict(), pd.DataFrame(), pd.DataFrame()
for i, img in enumerate(images):
img = img.convert('RGB') # Convert to RGB
draw = ImageDraw.Draw(img)
for box, label_idx, text in zip(sorted_original_bboxes[i], sorted_categories[i], sorted_texts[i]):
label = id2label[label_idx]
color = label2color[label]
draw.rectangle(box, outline=color)
text = text.encode('latin-1', 'replace').decode('latin-1') # https://stackoverflow.com/questions/56761449/unicodeencodeerror-latin-1-codec-cant-encode-character-u2013-writing-to
draw.text((box[0] + 10, box[1] - 10), text=label, fill=color, font=font)
if i == 0:
imgs["paragraphs"] = img
df_paragraphs["paragraphs"] = list(range(len(sorted_original_bboxes_block_list)))
df_paragraphs["categories"] = [id2label[label_idx] for label_idx in sorted_category_block_list]
df_paragraphs["texts"] = sorted_text_block_list
df_paragraphs["bounding boxes"] = [str(bbox) for bbox in sorted_original_bboxes_block_list]
else:
imgs["lines"] = img
df_lines["lines"] = list(range(len(sorted_original_bboxes_line_list)))
df_lines["categories"] = [id2label[label_idx] for label_idx in sorted_category_line_list]
df_lines["texts"] = sorted_text_line_list
df_lines["bounding boxes"] = [str(bbox) for bbox in sorted_original_bboxes_line_list]
return imgs, original_filename, page_no, num_pages, domain, df_paragraphs, df_lines
# display PDF image and its data
def display_pdf_blocks_lines(index_image=None, split="all"):
# get image and image data
images, original_filename, page_no, num_pages, domain, df_paragraphs, df_lines = generate_annotated_image(index_image=index_image, split=split)
print(f"PDF: {original_filename} (page: {page_no+1} / {num_pages}; domain: {domain})\n")
# left widget
style1 = {'overflow': 'scroll' ,'white-space': 'nowrap', 'width':'50%'}
output1 = widgets.Output(description = "PDF image with bounding boxes of paragraphs", style=style1)
with output1:
# display image
print(">> PDF image with bounding boxes of paragraphs\n")
open_cv_image = np.array(images["paragraphs"]) # PIL to cv2
# Convert RGB to BGR
open_cv_image = open_cv_image[:, :, ::-1].copy()
# cv2.imshow('',open_cv_image) # lambda
cv2_imshow(open_cv_image) # Colab
cv2.waitKey(0)
# display DataFrame
print("\n>> Paragraphs dataframe\n")
display(df_paragraphs)
# right widget
style2 = style1
output2 = widgets.Output(description = "PDF image with bounding boxes of lines", style=style2)
with output2:
# display image
print(">> PDF image with bounding boxes of lines\n")
open_cv_image = np.array(images["lines"]) # PIL to cv2
# Convert RGB to BGR
open_cv_image = open_cv_image[:, :, ::-1].copy()
# cv2.imshow('',open_cv_image) # lambda
cv2_imshow(open_cv_image) # Colab
cv2.waitKey(0)
# display DataFrame
print("\n>> Lines dataframe\n")
display(df_lines)
## Side by side thanks to HBox widgets
sidebyside = widgets.HBox([output1,output2])
## Finally, show.
display(sidebyside)
Encoded dataset¶
# creation of encoded dataset
def prepare_features_layoutxlm(example, cls_box = cls_box, sep_box = sep_box, label_pad_token_id = label_pad_token_id):
input_ids_list, attention_mask_list, bb_list, ll_list, page_hash_list, original_image_list= list(), list(), list(), list(), list(), list()
# get batch
batch_page_hash = example["page_hash"]
batch_bboxes_block = example["bboxes_block"]
batch_categories = example["categories"]
batch_texts = example["texts"]
batch_images = example["image"]
batch_original_width, batch_original_height = example["original_width"] , example["original_height"]
batch_coco_width, batch_coco_height = example["coco_width"] , example["coco_height"]
# add a dimension if not a batch but only one image
if not isinstance(batch_page_hash, list):
batch_page_hash = [batch_page_hash]
batch_bboxes_block = [batch_bboxes_block]
batch_categories = [batch_categories]
batch_texts = [batch_texts]
batch_images = [batch_images]
batch_original_width, batch_original_height = [batch_original_width], [batch_original_height]
batch_coco_width, batch_coco_height = [batch_coco_width], [batch_coco_height]
# process all images of the batch
for num_batch, (page_hash, boxes, labels, texts, image, coco_width, coco_height, original_width, original_height) in enumerate(zip(batch_page_hash, batch_bboxes_block, batch_categories, batch_texts, batch_images, batch_coco_width, batch_coco_height, batch_original_width, batch_original_height)):
tokens_list = []
bboxes_list = []
labels_list = []
# resize image to original + convert to RGB
original_image = image.resize((original_width, original_height)).convert("RGB")
# add a dimension if only on image
if not isinstance(texts, list):
texts, boxes, labels = [texts], [boxes], [labels]
# convert boxes to original
# Check the upperleft_to_lowerright
# normalize
normalize_bboxes_block = [normalize_box(upperleft_to_lowerright(convert_box(box)), coco_width, coco_height) for box in boxes]
# sort boxes with categorizations and texts
# we want sorted lists from top to bottom of the image
boxes, labels, texts = sort_data(normalize_bboxes_block, labels, texts)
count = 0
for box, label, text in zip(boxes, labels, texts):
tokens = tokenizer.tokenize(text)
num_tokens = len(tokens) # get number of tokens
tokens_list.extend(tokens)
bboxes_list.extend([box] * num_tokens) # number of boxes must be the same as the number of tokens
labels_list.extend([label if token.startswith('▁') else label_pad_token_id for token in tokens]) # WARNING: check the tokenizer to get the string to search
# labels_list.extend([label] + ([label_pad_token_id] * (num_tokens - 1))) # number of labels id must be the same as the number of tokens
# use of return_overflowing_tokens=True / stride=doc_stride
# to get parts of image with overlap
# source: https://huggingface.co/course/chapter6/3b?fw=tf#handling-long-contexts
encodings = tokenizer(" ".join(texts),
truncation=True,
padding="max_length",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True
)
_ = encodings.pop("overflow_to_sample_mapping")
offset_mapping = encodings.pop("offset_mapping")
# Let's label those examples and get their boxes
sequence_length_prev = 0
for i, offsets in enumerate(offset_mapping):
# truncate tokens, boxes and labels based on length of chunk - 2 (special tokens <s> and </s>)
sequence_length = len(encodings.input_ids[i]) - 2
if i == 0: start = 0
else: start += sequence_length_prev - doc_stride
end = start + sequence_length
sequence_length_prev = sequence_length
# get tokens, boxes and labels of this image chunk
bb = [cls_box] + bboxes_list[start:end] + [sep_box]
# get labels for this chunck
ll = [label_pad_token_id] + labels_list[start:end] + [label_pad_token_id]
# as the last chunk can have a length < max_length
# we must to add [tokenizer.pad_token] (tokens), [sep_box] (boxes) and [label_pad_token_id] (labels)
if len(bb) < max_length:
bb = bb + [sep_box] * (max_length - len(bb))
ll = ll + [label_pad_token_id] * (max_length - len(ll))
# append results
input_ids_list.append(encodings["input_ids"][i])
attention_mask_list.append(encodings["attention_mask"][i])
bb_list.append(bb)
ll_list.append(ll)
page_hash_list.append(page_hash)
original_image_list.append(original_image)
return {
"input_ids": input_ids_list,
"attention_mask": attention_mask_list,
"normalized_bboxes": bb_list,
"labels": ll_list,
"page_hash": page_hash_list,
"original_image": original_image_list,
}
# get data of encoded chunk
def get_encoded_chunk(index_chunk=None, split="all"):
# get datasets
example = dataset
encoded_example = encoded_dataset
# get split
if split == "all":
example = concatenate_datasets([example["train"], example["validation"], example["test"]])
encoded_example = concatenate_datasets([encoded_example["train"], encoded_example["validation"], encoded_example["test"]])
else:
example = example[split]
encoded_example = encoded_example[split]
# get randomly a document in dataset
if index_chunk == None: index_chunk = random.randint(0, len(encoded_example)-1)
encoded_example = encoded_example[index_chunk]
encoded_page_hash = encoded_example["page_hash"]
# get the image
example = example.filter(lambda example: example["page_hash"] == encoded_page_hash)[0]
image = example["image"] # original image
coco_width, coco_height = example["coco_width"], example["coco_height"]
original_filename = example["original_filename"]
page_no = example["page_no"]
num_pages = example["num_pages"]
domain = example["doc_category"]
# get domain name
index_domain = domain_names.index(domain)
domain = domains[index_domain]
# get boxes, texts, categories
bboxes, labels_id, input_ids = encoded_example["normalized_bboxes"][1:-1], encoded_example["labels"][1:-1], encoded_example["input_ids"][1:-1]
bboxes = [denormalize_box(bbox, coco_width, coco_height) for bbox in bboxes]
num_tokens = len(input_ids) + 2
# get unique bboxes and corresponding labels
bboxes_list, labels_list, input_ids_list = list(), list(), list()
input_ids_dict = dict()
bbox_prev = [-100, -100, -100, -100]
for i, (bbox, label_id, input_id) in enumerate(zip(bboxes, labels_id, input_ids)):
if bbox != bbox_prev:
bboxes_list.append(bbox)
input_ids_dict[str(bbox)] = [input_id]
labels_list.append(label_id)
label_id_prev = label_id
else:
input_ids_dict[str(bbox)].append(input_id)
# start_indexes_list.append(i)
bbox_prev = bbox
# do not keep "</s><pad><pad>..."
if input_ids_dict[str(bboxes_list[-1])][0] == (tokenizer.convert_tokens_to_ids('</s>')):
del input_ids_dict[str(bboxes_list[-1])]
bboxes_list = bboxes_list[:-1]
labels_list = labels_list[:-1]
# get texts by line
input_ids_list = input_ids_dict.values()
texts_list = [tokenizer.decode(input_ids) for input_ids in input_ids_list]
# display DataFrame
df = pd.DataFrame({"texts": texts_list, "input_ids": input_ids_list, "labels_ids": labels_list, "bboxes": bboxes_list})
return image, original_filename, page_no, num_pages, domain, df, num_tokens
# display chunk of PDF image and its data
def display_chunk_lines(index_chunk=None, split="all"):
# get image and image data
image, original_filename, page_no, num_pages, domain, df, num_tokens = get_encoded_chunk(index_chunk=index_chunk, split=split)
# image = image.convert('RGB') # Convert to RGB
# get data from dataframe
input_ids = df["input_ids"]
texts = df["texts"]
labels_ids = df["labels_ids"]
bboxes = df["bboxes"]
print(f'Chunk ({num_tokens} tokens) of the PDF "{original_filename}" (page: {page_no+1} / {num_pages}; domain: {domain})\n')
# display image with annotated bounding boxes
print(">> PDF image with bounding boxes of lines\n")
draw = ImageDraw.Draw(image)
labels = list()
for box, label_idx, text in zip(bboxes, labels_ids, texts):
if label_idx != label_pad_token_id:
label = id2label[label_idx]
labels.append(label)
color = label2color[label]
draw.rectangle(box, outline=color)
text = text.encode('latin-1', 'replace').decode('latin-1') # https://stackoverflow.com/questions/56761449/unicodeencodeerror-latin-1-codec-cant-encode-character-u2013-writing-to
draw.text((box[0] + 10, box[1] - 10), text=label, fill=color, font=font)
open_cv_image = np.array(image) # PIL to cv2
# Convert RGB to BGR
open_cv_image = open_cv_image[:, :, ::-1].copy()
# cv2.imshow('',open_cv_image) # lambda
cv2_imshow(open_cv_image) # Colab
cv2.waitKey(0)
# display image dataframe
print("\n>> Dataframe of annotated lines\n")
df["labels"] = [id2label[label_idx] if label_idx != label_pad_token_id else "-100" for label_idx in labels_ids]
cols = ["texts", "labels", "bboxes"]
df = df[cols]
display(df)
HF login¶
!huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Add token as git credential? (Y/n) Y
Token is valid.
Cannot authenticate through git-credential as no helper is defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub.
Run the following command in your terminal in case you want to set the 'store' credential helper as default.
git config --global credential.helper store
Read https://git-scm.com/book/en/v2/Git-Tools-Credential-Storage for more details.
Token has not been saved to git credential helper.
Your token has been saved to /root/.cache/huggingface/token
Login successful
Download DocLayNet¶
Download¶
local_dataset_name = "/content/drive/MyDrive/DocLayNet/datasets/" + dataset_name.replace("pierreguillou/DocLayNet-", "")
# from datasets import load_dataset
# dataset = load_dataset(dataset_name)
# # save locally
# dataset.save_to_disk(local_dataset_name)
# load
from datasets import load_from_disk
dataset = load_from_disk(local_dataset_name)
dataset
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 6910
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 648
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 499
})
})
dataset["train"].features
{'id': Value(dtype='string', id=None),
'texts': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),
'bboxes_block': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'bboxes_line': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'categories': Sequence(feature=ClassLabel(names=['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'], id=None), length=-1, id=None),
'image': Image(decode=True, id=None),
'page_hash': Value(dtype='string', id=None),
'original_filename': Value(dtype='string', id=None),
'page_no': Value(dtype='int32', id=None),
'num_pages': Value(dtype='int32', id=None),
'original_width': Value(dtype='int32', id=None),
'original_height': Value(dtype='int32', id=None),
'coco_width': Value(dtype='int32', id=None),
'coco_height': Value(dtype='int32', id=None),
'collection': Value(dtype='string', id=None),
'doc_category': Value(dtype='string', id=None)}
labels = dataset["train"].features["categories"].feature.names
id2label = {id:label for id, label in enumerate(labels)}
label2id = {label:id for id, label in enumerate(labels)}
num_labels = len(labels)
print(id2label)
{0: 'Caption', 1: 'Footnote', 2: 'Formula', 3: 'List-item', 4: 'Page-footer', 5: 'Page-header', 6: 'Picture', 7: 'Section-header', 8: 'Table', 9: 'Text', 10: 'Title'}
Checking of the dataset¶
Select a dataset split and display a random annotated image from it and its dataframe.
# choose your dataset
splits = ["all", "train", "validation", "test"]
index_split = 3
split = splits[index_split]
# display random PDF image and its data
display_pdf_blocks_lines(split=split)
PDF: NYSE_SMFG_2011.pdf (page: 200 / 230; domain: Financial Reports)
HBox(children=(Output(), Output()))
Create PyTorch Dataset¶
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-base")
Downloading (…)lve/main/config.json: 0%| | 0.00/615 [00:00<?, ?B/s]
Downloading (…)tencepiece.bpe.model: 0%| | 0.00/5.07M [00:00<?, ?B/s]
Downloading (…)/main/tokenizer.json: 0%| | 0.00/9.10M [00:00<?, ?B/s]
Encoded dataset (dataset divided into chunks with overlap)¶
Now one specific thing for the preprocessing in token classification is how to deal with very long documents. We usually truncate them in other tasks, when they are longer than the model maximum sentence length, but here, removing part of the the context might result in a worst model. To deal with this, we will allow one (long) example in our dataset to give several input features, each of length shorter than the maximum length of the model (or the one we set as a hyper-parameter). Also, we allow some overlap between the features we generate controlled by the hyper-parameter doc_stride in order to train the model with more contextual information.
Let's encode the dataset (ie, creation of chunks by page)!
local_encoded_dataset = "/content/drive/MyDrive/DocLayNet/datasets/xlmroberta/" + dataset_name.replace("pierreguillou/DocLayNet-", "") + "_paragraphs_encoded" + "_ml" + str(max_length)
encoded_dataset_name_hub = dataset_name.replace("pierreguillou/","") + "_xlmroberta" + "_paragraphs_encoded" + "_ml" + str(max_length)
# # the first time, encode your data and save it locally and/or in the HF datasets hub
# # for DocLayNet base, it can take about 40mn
# encoded_dataset = dataset.map(prepare_features_layoutxlm, batched=True, batch_size=64, remove_columns=dataset["train"].column_names)
# # save locally
# encoded_dataset.save_to_disk(local_encoded_dataset)
# # push to hub
# encoded_dataset.push_to_hub(encoded_dataset_name_hub, private=True)
# # load from disk
# from datasets import load_from_disk
# encoded_dataset = load_from_disk(local_encoded_dataset)
# load from hb
from datasets import load_dataset
encoded_dataset = load_dataset("pierreguillou/" + encoded_dataset_name_hub)
Downloading readme: 0%| | 0.00/782 [00:00<?, ?B/s]
Downloading and preparing dataset None/None to /root/.cache/huggingface/datasets/pierreguillou___parquet/pierreguillou--DocLayNet-base_xlmroberta_paragraphs_encoded_ml512-a58a0f4fca993ef2/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...
Downloading data files: 0%| | 0/3 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/183M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/166M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/162M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/161M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/168M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/170M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/170M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/167M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/170M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/140M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/106M [00:00<?, ?B/s]
Extracting data files: 0%| | 0/3 [00:00<?, ?it/s]
Generating train split: 0%| | 0/15009 [00:00<?, ? examples/s]
Generating validation split: 0%| | 0/1607 [00:00<?, ? examples/s]
Generating test split: 0%| | 0/1041 [00:00<?, ? examples/s]
Dataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/pierreguillou___parquet/pierreguillou--DocLayNet-base_xlmroberta_paragraphs_encoded_ml512-a58a0f4fca993ef2/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec. Subsequent calls will reuse this data.
0%| | 0/3 [00:00<?, ?it/s]
encoded_dataset
DatasetDict({
train: Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels', 'original_image'],
num_rows: 15009
})
validation: Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels', 'original_image'],
num_rows: 1607
})
test: Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels', 'original_image'],
num_rows: 1041
})
})
# train: we delete an image that has data with errors
train_dataset = encoded_dataset["train"].filter(lambda example: example["page_hash"] != 'b2f15dd6946e4465db44572fbc734724a7db04e1c6b79f8ff6eb931a833e829c')
train_dataset = train_dataset.remove_columns("page_hash").rename_column("normalized_bboxes", "bbox")
eval_dataset = encoded_dataset["validation"].remove_columns("page_hash").rename_column("normalized_bboxes", "bbox")
test_dataset = encoded_dataset["test"].remove_columns("page_hash").rename_column("normalized_bboxes", "bbox")
Filter: 0%| | 0/15009 [00:00<?, ? examples/s]
train_dataset.features
{'input_ids': Sequence(feature=Value(dtype='int32', id=None), length=-1, id=None),
'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'bbox': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'labels': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None),
'original_image': Image(decode=True, id=None)}
We change the features of input_ids and labels to the ones that the model wants.
from datasets import ClassLabel, Value, Sequence
new_features = train_dataset.features.copy()
new_features["input_ids"] = Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)
new_features["labels"] = Sequence(feature=ClassLabel(num_classes=11, names=labels, id=None), length=-1, id=None)
train_dataset = train_dataset.cast(new_features)
new_features = eval_dataset.features.copy()
new_features["input_ids"] = Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)
new_features["labels"] = Sequence(feature=ClassLabel(num_classes=11, names=labels, id=None), length=-1, id=None)
eval_dataset = eval_dataset.cast(new_features)
new_features = test_dataset.features.copy()
new_features["input_ids"] = Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None)
new_features["labels"] = Sequence(feature=ClassLabel(num_classes=11, names=labels, id=None), length=-1, id=None)
test_dataset = test_dataset.cast(new_features)
import torch
train_dataset.set_format(type="torch", columns=['input_ids', 'attention_mask', 'bbox', 'labels', 'original_image'])
eval_dataset.set_format(type="torch", columns=['input_ids', 'attention_mask', 'bbox', 'labels', 'original_image'])
test_dataset.set_format(type="torch", columns=['input_ids', 'attention_mask', 'bbox', 'labels', 'original_image'])
Casting the dataset: 0%| | 0/15008 [00:00<?, ? examples/s]
Casting the dataset: 0%| | 0/1607 [00:00<?, ? examples/s]
Casting the dataset: 0%| | 0/1041 [00:00<?, ? examples/s]
train_dataset.features
{'input_ids': Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None),
'attention_mask': Sequence(feature=Value(dtype='int8', id=None), length=-1, id=None),
'bbox': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'labels': Sequence(feature=ClassLabel(names=['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'], id=None), length=-1, id=None),
'original_image': Image(decode=True, id=None)}
Checking of the encoded dataset¶
Select a encoded dataset split and display a random annotated chunk image from it and its dataframe.
Note: the image is squared because of its normalization to 1000px vs 1000px in the encoded dataset (necessary for training the model).
# choose your split
splits = ["all", "train", "validation", "test"]
index_split = 3
split = splits[index_split]
# get and image from random chunk
display_chunk_lines(split=split)
Filter: 0%| | 0/499 [00:00<?, ? examples/s]
Chunk (512 tokens) of the PDF "1410.5885.pdf" (page: 50 / 80; domain: Scientific Articles) >> PDF image with bounding boxes of lines

>> Dataframe of annotated lines
| texts | labels | bboxes | |
|---|---|---|---|
| 0 | queness, and Efficiency of Equilibrium in Hedo... | -100 | [119, 740, 902, 777] |
| 1 | Ekeland, I., A. Galichon and M. Henry (2010). ... | Text | [119, 802, 902, 839] |
| 2 | Evans, W. and J. S. Ringel (1999). “Can Higher... | Text | [119, 864, 902, 902] |
| 3 | 50 | Page-footer | [503, 960, 519, 971] |
example = train_dataset[0]
for k,v in example.items():
if k != "original_image":
print(k,len(v), v.shape)
input_ids 512 torch.Size([512]) attention_mask 512 torch.Size([512]) bbox 512 torch.Size([512, 4]) labels 512 torch.Size([512])
example = train_dataset[0]
for k,v in example.items():
if k != "original_image":
print(k,v)
input_ids tensor([ 0, 18622, 7, 47, 70, 51371, 3674, 53477, 63805,
7, 111, 62, 3081, 19, 541, 5, 856, 5,
18622, 7, 47, 70, 51371, 3674, 53477, 63805, 7,
111, 62, 3081, 19, 541, 5, 856, 5, 18622,
7, 47, 70, 51371, 3674, 53477, 63805, 7, 111,
62, 3081, 19, 541, 5, 856, 5, 836, 836,
581, 23180, 450, 28960, 7, 29334, 14096, 90, 70,
85358, 214, 41170, 7, 111, 53477, 181079, 136, 53477,
400, 27519, 2449, 450, 621, 18507, 47314, 237, 99,
44075, 34292, 581, 23180, 450, 28960, 7, 29334, 14096,
90, 70, 85358, 214, 41170, 7, 111, 53477, 181079,
136, 53477, 400, 27519, 2449, 450, 621, 18507, 47314,
237, 99, 44075, 34292, 581, 23180, 450, 28960, 7,
29334, 14096, 90, 70, 85358, 214, 41170, 7, 111,
53477, 181079, 136, 53477, 400, 27519, 2449, 450, 621,
18507, 47314, 237, 99, 44075, 34292, 1210, 1210, 1210,
1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210,
1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210,
1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210,
1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210, 1210,
1210, 1210, 1210, 1210, 1210, 1210, 1210, 132274, 7,
100, 4537, 15426, 581, 10760, 111240, 7, 24233, 137251,
7, 98, 10, 3622, 30646, 18231, 3129, 765, 2809,
4331, 27686, 99, 44075, 34292, 8305, 18348, 707, 86669,
5, 581, 10760, 111240, 7, 24233, 137251, 7, 98,
10, 3622, 30646, 18231, 3129, 765, 2809, 4331, 27686,
99, 44075, 34292, 8305, 18348, 707, 86669, 5, 581,
10760, 111240, 7, 24233, 137251, 7, 98, 10, 3622,
30646, 18231, 3129, 765, 2809, 4331, 27686, 99, 44075,
34292, 8305, 18348, 707, 86669, 5, 581, 10760, 111240,
7, 24233, 137251, 7, 98, 10, 3622, 30646, 18231,
3129, 765, 2809, 4331, 27686, 99, 44075, 34292, 8305,
18348, 707, 86669, 5, 581, 10760, 111240, 7, 24233,
137251, 7, 98, 10, 3622, 30646, 18231, 3129, 765,
2809, 4331, 27686, 99, 44075, 34292, 8305, 18348, 707,
86669, 5, 132274, 7, 100, 4537, 15426, 4420, 214,
42169, 136, 77021, 400, 27519, 2449, 4, 450, 621,
175100, 99, 44075, 34292, 678, 65572, 23, 70, 44075,
132274, 7, 100, 4537, 15426, 4420, 214, 42169, 136,
77021, 400, 27519, 2449, 4, 450, 621, 175100, 99,
44075, 34292, 678, 65572, 23, 70, 44075, 132274, 7,
100, 4537, 15426, 4420, 214, 42169, 136, 77021, 400,
27519, 2449, 4, 450, 621, 175100, 99, 44075, 34292,
678, 65572, 23, 70, 44075, 132274, 7, 100, 4537,
15426, 4420, 214, 42169, 136, 77021, 400, 27519, 2449,
4, 450, 621, 175100, 99, 44075, 34292, 678, 65572,
23, 70, 44075, 132274, 7, 100, 4537, 15426, 4420,
214, 42169, 136, 77021, 400, 27519, 2449, 4, 450,
621, 175100, 99, 44075, 34292, 678, 65572, 23, 70,
44075, 132274, 7, 100, 15426, 111, 44930, 31958, 7,
132274, 7, 34658, 100, 15426, 111, 44930, 31958, 7,
48402, 13, 181079, 450, 621, 3126, 297, 47, 67842,
42169, 136, 77021, 18264, 7, 100, 132274, 7, 34658,
100, 15426, 111, 44930, 31958, 7, 48402, 13, 181079,
450, 621, 3126, 297, 47, 67842, 42169, 136, 77021,
18264, 7, 100, 132274, 7, 34658, 100, 15426, 111,
44930, 31958, 7, 48402, 13, 181079, 450, 2])
attention_mask tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1])
bbox tensor([[ 0, 0, 0, 0],
[ 69, 29, 585, 42],
[ 69, 29, 585, 42],
...,
[ 116, 566, 861, 623],
[ 116, 566, 861, 623],
[1000, 1000, 1000, 1000]])
labels tensor([-100, 5, -100, 5, 5, 5, -100, 5, 5, -100, 5, 5,
-100, -100, 5, -100, -100, -100, 5, -100, 5, 5, 5, -100,
5, 5, -100, 5, 5, -100, -100, 5, -100, -100, -100, 5,
-100, 5, 5, 5, -100, 5, 5, -100, 5, 5, -100, -100,
5, -100, -100, -100, 7, 7, 9, 9, 9, 9, -100, 9,
-100, -100, 9, 9, -100, 9, -100, 9, 9, 9, 9, 9,
9, -100, -100, 9, 9, 9, -100, 9, 9, 9, 9, 9,
9, 9, 9, -100, 9, -100, -100, 9, 9, -100, 9, -100,
9, 9, 9, 9, 9, 9, -100, -100, 9, 9, 9, -100,
9, 9, 9, 9, 9, 9, 9, 9, -100, 9, -100, -100,
9, 9, -100, 9, -100, 9, 9, 9, 9, 9, 9, -100,
-100, 9, 9, 9, -100, 9, 9, 9, 9, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8, 8,
8, 8, 8, 8, 8, 8, 8, 7, -100, 7, 7, 7,
9, 9, 9, -100, 9, 9, -100, 9, 9, 9, 9, 9,
9, 9, 9, 9, -100, 9, 9, 9, 9, 9, 9, 9,
-100, 9, 9, 9, -100, 9, 9, -100, 9, 9, 9, 9,
9, 9, 9, 9, 9, -100, 9, 9, 9, 9, 9, 9,
9, -100, 9, 9, 9, -100, 9, 9, -100, 9, 9, 9,
9, 9, 9, 9, 9, 9, -100, 9, 9, 9, 9, 9,
9, 9, -100, 9, 9, 9, -100, 9, 9, -100, 9, 9,
9, 9, 9, 9, 9, 9, 9, -100, 9, 9, 9, 9,
9, 9, 9, -100, 9, 9, 9, -100, 9, 9, -100, 9,
9, 9, 9, 9, 9, 9, 9, 9, -100, 9, 9, 9,
9, 9, 9, 9, -100, 9, -100, 9, 9, 9, 9, -100,
9, 9, 9, 9, -100, -100, -100, 9, 9, 9, 9, 9,
9, 9, 9, 9, 9, 9, 9, -100, 9, 9, 9, 9,
-100, 9, 9, 9, 9, -100, -100, -100, 9, 9, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9, -100, 9, 9, 9,
9, -100, 9, 9, 9, 9, -100, -100, -100, 9, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9, 9, -100, 9, 9,
9, 9, -100, 9, 9, 9, 9, -100, -100, -100, 9, 9,
9, 9, 9, 9, 9, 9, 9, 9, 9, 9, -100, 9,
9, 9, 9, -100, 9, 9, 9, 9, -100, -100, -100, 9,
9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 7, -100,
7, 7, 7, 7, -100, -100, 9, -100, 9, 9, 9, 9,
9, -100, -100, 9, -100, 9, 9, 9, 9, -100, 9, 9,
9, 9, 9, 9, -100, 9, 9, -100, 9, 9, 9, 9,
9, -100, -100, 9, -100, 9, 9, 9, 9, -100, 9, 9,
9, 9, 9, 9, -100, 9, 9, -100, 9, 9, 9, 9,
9, -100, -100, 9, -100, 9, 9, -100])
tokenizer.decode(example["input_ids"])
'<s> Notes to the consolidated financial statements of Aegon N.V. Notes to the consolidated financial statements of Aegon N.V. Notes to the consolidated financial statements of Aegon N.V. 50 50 The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 Investments for general account The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for account of policyholders Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for Investments held for account of policyholders comprise assets that</s>'
for id, box, label in zip(example["input_ids"], example["bbox"], example["labels"]):
if label != label_pad_token_id:
print(label)
print(tokenizer.decode([id]), box, id2label[label.item()])
else:
print(tokenizer.decode([id]), box, label_pad_token_id)
<s> tensor([0, 0, 0, 0]) -100 tensor(5) Note tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) -100 tensor(5) to tensor([ 69, 29, 585, 42]) Page-header tensor(5) the tensor([ 69, 29, 585, 42]) Page-header tensor(5) consolida tensor([ 69, 29, 585, 42]) Page-header ted tensor([ 69, 29, 585, 42]) -100 tensor(5) financial tensor([ 69, 29, 585, 42]) Page-header tensor(5) statement tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) -100 tensor(5) of tensor([ 69, 29, 585, 42]) Page-header tensor(5) A tensor([ 69, 29, 585, 42]) Page-header ego tensor([ 69, 29, 585, 42]) -100 n tensor([ 69, 29, 585, 42]) -100 tensor(5) N tensor([ 69, 29, 585, 42]) Page-header . tensor([ 69, 29, 585, 42]) -100 V tensor([ 69, 29, 585, 42]) -100 . tensor([ 69, 29, 585, 42]) -100 tensor(5) Note tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) -100 tensor(5) to tensor([ 69, 29, 585, 42]) Page-header tensor(5) the tensor([ 69, 29, 585, 42]) Page-header tensor(5) consolida tensor([ 69, 29, 585, 42]) Page-header ted tensor([ 69, 29, 585, 42]) -100 tensor(5) financial tensor([ 69, 29, 585, 42]) Page-header tensor(5) statement tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) -100 tensor(5) of tensor([ 69, 29, 585, 42]) Page-header tensor(5) A tensor([ 69, 29, 585, 42]) Page-header ego tensor([ 69, 29, 585, 42]) -100 n tensor([ 69, 29, 585, 42]) -100 tensor(5) N tensor([ 69, 29, 585, 42]) Page-header . tensor([ 69, 29, 585, 42]) -100 V tensor([ 69, 29, 585, 42]) -100 . tensor([ 69, 29, 585, 42]) -100 tensor(5) Note tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) -100 tensor(5) to tensor([ 69, 29, 585, 42]) Page-header tensor(5) the tensor([ 69, 29, 585, 42]) Page-header tensor(5) consolida tensor([ 69, 29, 585, 42]) Page-header ted tensor([ 69, 29, 585, 42]) -100 tensor(5) financial tensor([ 69, 29, 585, 42]) Page-header tensor(5) statement tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) -100 tensor(5) of tensor([ 69, 29, 585, 42]) Page-header tensor(5) A tensor([ 69, 29, 585, 42]) Page-header ego tensor([ 69, 29, 585, 42]) -100 n tensor([ 69, 29, 585, 42]) -100 tensor(5) N tensor([ 69, 29, 585, 42]) Page-header . tensor([ 69, 29, 585, 42]) -100 V tensor([ 69, 29, 585, 42]) -100 . tensor([ 69, 29, 585, 42]) -100 tensor(7) 50 tensor([116, 95, 793, 109]) Section-header tensor(7) 50 tensor([116, 95, 793, 109]) Section-header tensor(9) The tensor([116, 113, 867, 154]) Text tensor(9) table tensor([116, 113, 867, 154]) Text tensor(9) that tensor([116, 113, 867, 154]) Text tensor(9) follow tensor([116, 113, 867, 154]) Text s tensor([116, 113, 867, 154]) -100 tensor(9) summa tensor([116, 113, 867, 154]) Text riz tensor([116, 113, 867, 154]) -100 es tensor([116, 113, 867, 154]) -100 tensor(9) the tensor([116, 113, 867, 154]) Text tensor(9) carry tensor([116, 113, 867, 154]) Text ing tensor([116, 113, 867, 154]) -100 tensor(9) amount tensor([116, 113, 867, 154]) Text s tensor([116, 113, 867, 154]) -100 tensor(9) of tensor([116, 113, 867, 154]) Text tensor(9) financial tensor([116, 113, 867, 154]) Text tensor(9) assets tensor([116, 113, 867, 154]) Text tensor(9) and tensor([116, 113, 867, 154]) Text tensor(9) financial tensor([116, 113, 867, 154]) Text tensor(9) li tensor([116, 113, 867, 154]) Text abili tensor([116, 113, 867, 154]) -100 ties tensor([116, 113, 867, 154]) -100 tensor(9) that tensor([116, 113, 867, 154]) Text tensor(9) are tensor([116, 113, 867, 154]) Text tensor(9) class tensor([116, 113, 867, 154]) Text ified tensor([116, 113, 867, 154]) -100 tensor(9) as tensor([116, 113, 867, 154]) Text tensor(9) at tensor([116, 113, 867, 154]) Text tensor(9) fair tensor([116, 113, 867, 154]) Text tensor(9) value tensor([116, 113, 867, 154]) Text tensor(9) The tensor([116, 113, 867, 154]) Text tensor(9) table tensor([116, 113, 867, 154]) Text tensor(9) that tensor([116, 113, 867, 154]) Text tensor(9) follow tensor([116, 113, 867, 154]) Text s tensor([116, 113, 867, 154]) -100 tensor(9) summa tensor([116, 113, 867, 154]) Text riz tensor([116, 113, 867, 154]) -100 es tensor([116, 113, 867, 154]) -100 tensor(9) the tensor([116, 113, 867, 154]) Text tensor(9) carry tensor([116, 113, 867, 154]) Text ing tensor([116, 113, 867, 154]) -100 tensor(9) amount tensor([116, 113, 867, 154]) Text s tensor([116, 113, 867, 154]) -100 tensor(9) of tensor([116, 113, 867, 154]) Text tensor(9) financial tensor([116, 113, 867, 154]) Text tensor(9) assets tensor([116, 113, 867, 154]) Text tensor(9) and tensor([116, 113, 867, 154]) Text tensor(9) financial tensor([116, 113, 867, 154]) Text tensor(9) li tensor([116, 113, 867, 154]) Text abili tensor([116, 113, 867, 154]) -100 ties tensor([116, 113, 867, 154]) -100 tensor(9) that tensor([116, 113, 867, 154]) Text tensor(9) are tensor([116, 113, 867, 154]) Text tensor(9) class tensor([116, 113, 867, 154]) Text ified tensor([116, 113, 867, 154]) -100 tensor(9) as tensor([116, 113, 867, 154]) Text tensor(9) at tensor([116, 113, 867, 154]) Text tensor(9) fair tensor([116, 113, 867, 154]) Text tensor(9) value tensor([116, 113, 867, 154]) Text tensor(9) The tensor([116, 113, 867, 154]) Text tensor(9) table tensor([116, 113, 867, 154]) Text tensor(9) that tensor([116, 113, 867, 154]) Text tensor(9) follow tensor([116, 113, 867, 154]) Text s tensor([116, 113, 867, 154]) -100 tensor(9) summa tensor([116, 113, 867, 154]) Text riz tensor([116, 113, 867, 154]) -100 es tensor([116, 113, 867, 154]) -100 tensor(9) the tensor([116, 113, 867, 154]) Text tensor(9) carry tensor([116, 113, 867, 154]) Text ing tensor([116, 113, 867, 154]) -100 tensor(9) amount tensor([116, 113, 867, 154]) Text s tensor([116, 113, 867, 154]) -100 tensor(9) of tensor([116, 113, 867, 154]) Text tensor(9) financial tensor([116, 113, 867, 154]) Text tensor(9) assets tensor([116, 113, 867, 154]) Text tensor(9) and tensor([116, 113, 867, 154]) Text tensor(9) financial tensor([116, 113, 867, 154]) Text tensor(9) li tensor([116, 113, 867, 154]) Text abili tensor([116, 113, 867, 154]) -100 ties tensor([116, 113, 867, 154]) -100 tensor(9) that tensor([116, 113, 867, 154]) Text tensor(9) are tensor([116, 113, 867, 154]) Text tensor(9) class tensor([116, 113, 867, 154]) Text ified tensor([116, 113, 867, 154]) -100 tensor(9) as tensor([116, 113, 867, 154]) Text tensor(9) at tensor([116, 113, 867, 154]) Text tensor(9) fair tensor([116, 113, 867, 154]) Text tensor(9) value tensor([116, 113, 867, 154]) Text tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(8) 2013 tensor([113, 173, 880, 331]) Table tensor(7) Investment tensor([116, 354, 322, 366]) Section-header s tensor([116, 354, 322, 366]) -100 tensor(7) for tensor([116, 354, 322, 366]) Section-header tensor(7) general tensor([116, 354, 322, 366]) Section-header tensor(7) account tensor([116, 354, 322, 366]) Section-header tensor(9) The tensor([116, 370, 865, 441]) Text tensor(9) Group tensor([116, 370, 865, 441]) Text tensor(9) manage tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) certain tensor([116, 370, 865, 441]) Text tensor(9) portfolio tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) on tensor([116, 370, 865, 441]) Text tensor(9) a tensor([116, 370, 865, 441]) Text tensor(9) total tensor([116, 370, 865, 441]) Text tensor(9) return tensor([116, 370, 865, 441]) Text tensor(9) basis tensor([116, 370, 865, 441]) Text tensor(9) which tensor([116, 370, 865, 441]) Text tensor(9) have tensor([116, 370, 865, 441]) Text tensor(9) been tensor([116, 370, 865, 441]) Text tensor(9) design tensor([116, 370, 865, 441]) Text ated tensor([116, 370, 865, 441]) -100 tensor(9) at tensor([116, 370, 865, 441]) Text tensor(9) fair tensor([116, 370, 865, 441]) Text tensor(9) value tensor([116, 370, 865, 441]) Text tensor(9) through tensor([116, 370, 865, 441]) Text tensor(9) profit tensor([116, 370, 865, 441]) Text tensor(9) or tensor([116, 370, 865, 441]) Text tensor(9) loss tensor([116, 370, 865, 441]) Text . tensor([116, 370, 865, 441]) -100 tensor(9) The tensor([116, 370, 865, 441]) Text tensor(9) Group tensor([116, 370, 865, 441]) Text tensor(9) manage tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) certain tensor([116, 370, 865, 441]) Text tensor(9) portfolio tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) on tensor([116, 370, 865, 441]) Text tensor(9) a tensor([116, 370, 865, 441]) Text tensor(9) total tensor([116, 370, 865, 441]) Text tensor(9) return tensor([116, 370, 865, 441]) Text tensor(9) basis tensor([116, 370, 865, 441]) Text tensor(9) which tensor([116, 370, 865, 441]) Text tensor(9) have tensor([116, 370, 865, 441]) Text tensor(9) been tensor([116, 370, 865, 441]) Text tensor(9) design tensor([116, 370, 865, 441]) Text ated tensor([116, 370, 865, 441]) -100 tensor(9) at tensor([116, 370, 865, 441]) Text tensor(9) fair tensor([116, 370, 865, 441]) Text tensor(9) value tensor([116, 370, 865, 441]) Text tensor(9) through tensor([116, 370, 865, 441]) Text tensor(9) profit tensor([116, 370, 865, 441]) Text tensor(9) or tensor([116, 370, 865, 441]) Text tensor(9) loss tensor([116, 370, 865, 441]) Text . tensor([116, 370, 865, 441]) -100 tensor(9) The tensor([116, 370, 865, 441]) Text tensor(9) Group tensor([116, 370, 865, 441]) Text tensor(9) manage tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) certain tensor([116, 370, 865, 441]) Text tensor(9) portfolio tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) on tensor([116, 370, 865, 441]) Text tensor(9) a tensor([116, 370, 865, 441]) Text tensor(9) total tensor([116, 370, 865, 441]) Text tensor(9) return tensor([116, 370, 865, 441]) Text tensor(9) basis tensor([116, 370, 865, 441]) Text tensor(9) which tensor([116, 370, 865, 441]) Text tensor(9) have tensor([116, 370, 865, 441]) Text tensor(9) been tensor([116, 370, 865, 441]) Text tensor(9) design tensor([116, 370, 865, 441]) Text ated tensor([116, 370, 865, 441]) -100 tensor(9) at tensor([116, 370, 865, 441]) Text tensor(9) fair tensor([116, 370, 865, 441]) Text tensor(9) value tensor([116, 370, 865, 441]) Text tensor(9) through tensor([116, 370, 865, 441]) Text tensor(9) profit tensor([116, 370, 865, 441]) Text tensor(9) or tensor([116, 370, 865, 441]) Text tensor(9) loss tensor([116, 370, 865, 441]) Text . tensor([116, 370, 865, 441]) -100 tensor(9) The tensor([116, 370, 865, 441]) Text tensor(9) Group tensor([116, 370, 865, 441]) Text tensor(9) manage tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) certain tensor([116, 370, 865, 441]) Text tensor(9) portfolio tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) on tensor([116, 370, 865, 441]) Text tensor(9) a tensor([116, 370, 865, 441]) Text tensor(9) total tensor([116, 370, 865, 441]) Text tensor(9) return tensor([116, 370, 865, 441]) Text tensor(9) basis tensor([116, 370, 865, 441]) Text tensor(9) which tensor([116, 370, 865, 441]) Text tensor(9) have tensor([116, 370, 865, 441]) Text tensor(9) been tensor([116, 370, 865, 441]) Text tensor(9) design tensor([116, 370, 865, 441]) Text ated tensor([116, 370, 865, 441]) -100 tensor(9) at tensor([116, 370, 865, 441]) Text tensor(9) fair tensor([116, 370, 865, 441]) Text tensor(9) value tensor([116, 370, 865, 441]) Text tensor(9) through tensor([116, 370, 865, 441]) Text tensor(9) profit tensor([116, 370, 865, 441]) Text tensor(9) or tensor([116, 370, 865, 441]) Text tensor(9) loss tensor([116, 370, 865, 441]) Text . tensor([116, 370, 865, 441]) -100 tensor(9) The tensor([116, 370, 865, 441]) Text tensor(9) Group tensor([116, 370, 865, 441]) Text tensor(9) manage tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) certain tensor([116, 370, 865, 441]) Text tensor(9) portfolio tensor([116, 370, 865, 441]) Text s tensor([116, 370, 865, 441]) -100 tensor(9) on tensor([116, 370, 865, 441]) Text tensor(9) a tensor([116, 370, 865, 441]) Text tensor(9) total tensor([116, 370, 865, 441]) Text tensor(9) return tensor([116, 370, 865, 441]) Text tensor(9) basis tensor([116, 370, 865, 441]) Text tensor(9) which tensor([116, 370, 865, 441]) Text tensor(9) have tensor([116, 370, 865, 441]) Text tensor(9) been tensor([116, 370, 865, 441]) Text tensor(9) design tensor([116, 370, 865, 441]) Text ated tensor([116, 370, 865, 441]) -100 tensor(9) at tensor([116, 370, 865, 441]) Text tensor(9) fair tensor([116, 370, 865, 441]) Text tensor(9) value tensor([116, 370, 865, 441]) Text tensor(9) through tensor([116, 370, 865, 441]) Text tensor(9) profit tensor([116, 370, 865, 441]) Text tensor(9) or tensor([116, 370, 865, 441]) Text tensor(9) loss tensor([116, 370, 865, 441]) Text . tensor([116, 370, 865, 441]) -100 tensor(9) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) -100 tensor(9) for tensor([116, 461, 880, 532]) Text tensor(9) general tensor([116, 461, 880, 532]) Text tensor(9) account tensor([116, 461, 880, 532]) Text tensor(9) back tensor([116, 461, 880, 532]) Text ing tensor([116, 461, 880, 532]) -100 tensor(9) insurance tensor([116, 461, 880, 532]) Text tensor(9) and tensor([116, 461, 880, 532]) Text tensor(9) investment tensor([116, 461, 880, 532]) Text tensor(9) li tensor([116, 461, 880, 532]) Text abili tensor([116, 461, 880, 532]) -100 ties tensor([116, 461, 880, 532]) -100 , tensor([116, 461, 880, 532]) -100 tensor(9) that tensor([116, 461, 880, 532]) Text tensor(9) are tensor([116, 461, 880, 532]) Text tensor(9) carried tensor([116, 461, 880, 532]) Text tensor(9) at tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) value tensor([116, 461, 880, 532]) Text tensor(9) with tensor([116, 461, 880, 532]) Text tensor(9) changes tensor([116, 461, 880, 532]) Text tensor(9) in tensor([116, 461, 880, 532]) Text tensor(9) the tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) -100 tensor(9) for tensor([116, 461, 880, 532]) Text tensor(9) general tensor([116, 461, 880, 532]) Text tensor(9) account tensor([116, 461, 880, 532]) Text tensor(9) back tensor([116, 461, 880, 532]) Text ing tensor([116, 461, 880, 532]) -100 tensor(9) insurance tensor([116, 461, 880, 532]) Text tensor(9) and tensor([116, 461, 880, 532]) Text tensor(9) investment tensor([116, 461, 880, 532]) Text tensor(9) li tensor([116, 461, 880, 532]) Text abili tensor([116, 461, 880, 532]) -100 ties tensor([116, 461, 880, 532]) -100 , tensor([116, 461, 880, 532]) -100 tensor(9) that tensor([116, 461, 880, 532]) Text tensor(9) are tensor([116, 461, 880, 532]) Text tensor(9) carried tensor([116, 461, 880, 532]) Text tensor(9) at tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) value tensor([116, 461, 880, 532]) Text tensor(9) with tensor([116, 461, 880, 532]) Text tensor(9) changes tensor([116, 461, 880, 532]) Text tensor(9) in tensor([116, 461, 880, 532]) Text tensor(9) the tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) -100 tensor(9) for tensor([116, 461, 880, 532]) Text tensor(9) general tensor([116, 461, 880, 532]) Text tensor(9) account tensor([116, 461, 880, 532]) Text tensor(9) back tensor([116, 461, 880, 532]) Text ing tensor([116, 461, 880, 532]) -100 tensor(9) insurance tensor([116, 461, 880, 532]) Text tensor(9) and tensor([116, 461, 880, 532]) Text tensor(9) investment tensor([116, 461, 880, 532]) Text tensor(9) li tensor([116, 461, 880, 532]) Text abili tensor([116, 461, 880, 532]) -100 ties tensor([116, 461, 880, 532]) -100 , tensor([116, 461, 880, 532]) -100 tensor(9) that tensor([116, 461, 880, 532]) Text tensor(9) are tensor([116, 461, 880, 532]) Text tensor(9) carried tensor([116, 461, 880, 532]) Text tensor(9) at tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) value tensor([116, 461, 880, 532]) Text tensor(9) with tensor([116, 461, 880, 532]) Text tensor(9) changes tensor([116, 461, 880, 532]) Text tensor(9) in tensor([116, 461, 880, 532]) Text tensor(9) the tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) -100 tensor(9) for tensor([116, 461, 880, 532]) Text tensor(9) general tensor([116, 461, 880, 532]) Text tensor(9) account tensor([116, 461, 880, 532]) Text tensor(9) back tensor([116, 461, 880, 532]) Text ing tensor([116, 461, 880, 532]) -100 tensor(9) insurance tensor([116, 461, 880, 532]) Text tensor(9) and tensor([116, 461, 880, 532]) Text tensor(9) investment tensor([116, 461, 880, 532]) Text tensor(9) li tensor([116, 461, 880, 532]) Text abili tensor([116, 461, 880, 532]) -100 ties tensor([116, 461, 880, 532]) -100 , tensor([116, 461, 880, 532]) -100 tensor(9) that tensor([116, 461, 880, 532]) Text tensor(9) are tensor([116, 461, 880, 532]) Text tensor(9) carried tensor([116, 461, 880, 532]) Text tensor(9) at tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) value tensor([116, 461, 880, 532]) Text tensor(9) with tensor([116, 461, 880, 532]) Text tensor(9) changes tensor([116, 461, 880, 532]) Text tensor(9) in tensor([116, 461, 880, 532]) Text tensor(9) the tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) -100 tensor(9) for tensor([116, 461, 880, 532]) Text tensor(9) general tensor([116, 461, 880, 532]) Text tensor(9) account tensor([116, 461, 880, 532]) Text tensor(9) back tensor([116, 461, 880, 532]) Text ing tensor([116, 461, 880, 532]) -100 tensor(9) insurance tensor([116, 461, 880, 532]) Text tensor(9) and tensor([116, 461, 880, 532]) Text tensor(9) investment tensor([116, 461, 880, 532]) Text tensor(9) li tensor([116, 461, 880, 532]) Text abili tensor([116, 461, 880, 532]) -100 ties tensor([116, 461, 880, 532]) -100 , tensor([116, 461, 880, 532]) -100 tensor(9) that tensor([116, 461, 880, 532]) Text tensor(9) are tensor([116, 461, 880, 532]) Text tensor(9) carried tensor([116, 461, 880, 532]) Text tensor(9) at tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(9) value tensor([116, 461, 880, 532]) Text tensor(9) with tensor([116, 461, 880, 532]) Text tensor(9) changes tensor([116, 461, 880, 532]) Text tensor(9) in tensor([116, 461, 880, 532]) Text tensor(9) the tensor([116, 461, 880, 532]) Text tensor(9) fair tensor([116, 461, 880, 532]) Text tensor(7) Investment tensor([116, 550, 377, 562]) Section-header s tensor([116, 550, 377, 562]) -100 tensor(7) for tensor([116, 550, 377, 562]) Section-header tensor(7) account tensor([116, 550, 377, 562]) Section-header tensor(7) of tensor([116, 550, 377, 562]) Section-header tensor(7) policy tensor([116, 550, 377, 562]) Section-header holder tensor([116, 550, 377, 562]) -100 s tensor([116, 550, 377, 562]) -100 tensor(9) Investment tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) -100 tensor(9) held tensor([116, 566, 861, 623]) Text tensor(9) for tensor([116, 566, 861, 623]) Text tensor(9) account tensor([116, 566, 861, 623]) Text tensor(9) of tensor([116, 566, 861, 623]) Text tensor(9) policy tensor([116, 566, 861, 623]) Text holder tensor([116, 566, 861, 623]) -100 s tensor([116, 566, 861, 623]) -100 tensor(9) compris tensor([116, 566, 861, 623]) Text e tensor([116, 566, 861, 623]) -100 tensor(9) assets tensor([116, 566, 861, 623]) Text tensor(9) that tensor([116, 566, 861, 623]) Text tensor(9) are tensor([116, 566, 861, 623]) Text tensor(9) link tensor([116, 566, 861, 623]) Text ed tensor([116, 566, 861, 623]) -100 tensor(9) to tensor([116, 566, 861, 623]) Text tensor(9) various tensor([116, 566, 861, 623]) Text tensor(9) insurance tensor([116, 566, 861, 623]) Text tensor(9) and tensor([116, 566, 861, 623]) Text tensor(9) investment tensor([116, 566, 861, 623]) Text tensor(9) contract tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) -100 tensor(9) for tensor([116, 566, 861, 623]) Text tensor(9) Investment tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) -100 tensor(9) held tensor([116, 566, 861, 623]) Text tensor(9) for tensor([116, 566, 861, 623]) Text tensor(9) account tensor([116, 566, 861, 623]) Text tensor(9) of tensor([116, 566, 861, 623]) Text tensor(9) policy tensor([116, 566, 861, 623]) Text holder tensor([116, 566, 861, 623]) -100 s tensor([116, 566, 861, 623]) -100 tensor(9) compris tensor([116, 566, 861, 623]) Text e tensor([116, 566, 861, 623]) -100 tensor(9) assets tensor([116, 566, 861, 623]) Text tensor(9) that tensor([116, 566, 861, 623]) Text tensor(9) are tensor([116, 566, 861, 623]) Text tensor(9) link tensor([116, 566, 861, 623]) Text ed tensor([116, 566, 861, 623]) -100 tensor(9) to tensor([116, 566, 861, 623]) Text tensor(9) various tensor([116, 566, 861, 623]) Text tensor(9) insurance tensor([116, 566, 861, 623]) Text tensor(9) and tensor([116, 566, 861, 623]) Text tensor(9) investment tensor([116, 566, 861, 623]) Text tensor(9) contract tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) -100 tensor(9) for tensor([116, 566, 861, 623]) Text tensor(9) Investment tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) -100 tensor(9) held tensor([116, 566, 861, 623]) Text tensor(9) for tensor([116, 566, 861, 623]) Text tensor(9) account tensor([116, 566, 861, 623]) Text tensor(9) of tensor([116, 566, 861, 623]) Text tensor(9) policy tensor([116, 566, 861, 623]) Text holder tensor([116, 566, 861, 623]) -100 s tensor([116, 566, 861, 623]) -100 tensor(9) compris tensor([116, 566, 861, 623]) Text e tensor([116, 566, 861, 623]) -100 tensor(9) assets tensor([116, 566, 861, 623]) Text tensor(9) that tensor([116, 566, 861, 623]) Text </s> tensor([1000, 1000, 1000, 1000]) -100
Define Data Collator¶
Below, we define this data collator. For that, we'll use LayoutLMv2FeatureExtractor for preparing the image inputs, and LayoutXLMTokenizer to pad the text inputs.
from transformers import LayoutLMv2FeatureExtractor, LayoutXLMTokenizer
feature_extractor = LayoutLMv2FeatureExtractor(apply_ocr=False)
tokenizer = LayoutXLMTokenizer.from_pretrained("microsoft/layoutxlm-base")
/usr/local/lib/python3.9/dist-packages/transformers/models/layoutlmv2/feature_extraction_layoutlmv2.py:30: FutureWarning: The class LayoutLMv2FeatureExtractor is deprecated and will be removed in version 5 of Transformers. Please use LayoutLMv2ImageProcessor instead. warnings.warn(
Downloading (…)tencepiece.bpe.model: 0%| | 0.00/5.07M [00:00<?, ?B/s]
Downloading (…)lve/main/config.json: 0%| | 0.00/1.02k [00:00<?, ?B/s]
Downloading (…)n/config.4.13.0.json: 0%| | 0.00/947 [00:00<?, ?B/s]
from transformers import PreTrainedTokenizerBase
from transformers.file_utils import PaddingStrategy
from torch.utils.data import DataLoader
from dataclasses import dataclass
import torch
from typing import Optional, Union
@dataclass
class DataCollatorForTokenClassification:
"""
Data collator that will dynamically pad the inputs received, as well as the labels.
Args:
tokenizer (:class:`~transformers.PreTrainedTokenizer` or :class:`~transformers.PreTrainedTokenizerFast`):
The tokenizer used for encoding the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.file_utils.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
label_pad_token_id (:obj:`int`, `optional`, defaults to -100):
The id to use when padding the labels (-100 will be automatically ignore by PyTorch loss functions).
"""
feature_extractor: LayoutLMv2FeatureExtractor
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
label_pad_token_id: int = -100
def __call__(self, features):
# prepare image input
image = self.feature_extractor([feature["original_image"] for feature in features], return_tensors="pt").pixel_values
# prepare text input
for feature in features:
del feature["original_image"]
batch = self.tokenizer.pad(
features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt"
)
batch["image"] = image
return batch
data_collator = DataCollatorForTokenClassification(
feature_extractor,
tokenizer,
pad_to_multiple_of=None,
padding="max_length",
max_length=max_length,
)
Create PyTorch DataLoader¶
Next, we create PyTorch DataLoaders and train the model in native PyTorch.
However, we'll use the HuggingFace Trainer in this notebook, as you can see further. We'll just need to provide our collate function defined above, and it will create dataloaders behind the scenes.
Below, we create a PyTorch DataLoader with our collate function.
from torch.utils.data import DataLoader
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, collate_fn=data_collator, shuffle=True)
eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size, collate_fn=data_collator, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, collate_fn=data_collator, shuffle=True)
Let's verify a batch:
batch = next(iter(train_dataloader))
print(batch.keys())
print()
for k,v in batch.items():
print(k, v.shape)
dict_keys(['input_ids', 'attention_mask', 'bbox', 'labels', 'image']) input_ids torch.Size([8, 512]) attention_mask torch.Size([8, 512]) bbox torch.Size([8, 512, 4]) labels torch.Size([8, 512]) image torch.Size([8, 3, 224, 224])
tokenizer.decode(batch['input_ids'][0])
'<s> construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new We began construction on four new Consolidated Revenues ($ — billions) We We We We We We We We We We We We We We We We We We We We We We We We We We We We We We 0 0 0 0 0 0 0 0 0 GENERATE SUPPLEMENTAL REVENUES We have two initiatives that generate We have two initiatives that generate We have two initiatives that generate We have two initiatives that generate We We We We We We We We We We We We We We We We We Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Our Dividends Per Dividends Per ACQUIRE HIGH QUALITY RETAIL ACQUIRE HIGH QUALITY RETAIL 0 0 0 0 0 0 0 0 0 The The The The The The The The The The The The The The The The The The The The The The The The The The The The The The We We We We We We We We We We We We We We We We We We We We We We We We We We SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business SBN provides programs and business Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding Regarding The The The The The The The The The The The The The The The The The The The The simon property group, inc. 4</s><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad><pad>'
for id, label in zip(batch['input_ids'][0][:30], batch['labels'][0][:30]):
if label != -100:
print(tokenizer.decode([id.item()]), id2label[label.item()])
else:
print(tokenizer.decode([id.item()]), label.item())
<s> -100 construction Text on Text four Text new Text We Text began Text construction Text on Text four Text new Text We Text began Text construction Text on Text four Text new Text We Text began Text construction Text on Text four Text new Text We Text began Text construction Text on Text four Text new Text We Text
It's always important to also verify that the resized image and normalized bounding boxes are set up properly.
import numpy as np
from PIL import Image
image_to_verify = batch['image'][0].numpy()
image_to_verify = np.moveaxis(image_to_verify, source=0, destination=-1)
image_to_verify = Image.fromarray(image_to_verify)
image_to_verify

from PIL import ImageDraw
def unnormalize_box(bbox, width, height):
return [
width * (bbox[0] / 1000),
height * (bbox[1] / 1000),
width * (bbox[2] / 1000),
height * (bbox[3] / 1000),
]
draw = ImageDraw.Draw(image_to_verify)
for bbox in batch['bbox'][0]:
draw.rectangle(unnormalize_box(bbox, width=224, height=224), outline='red', width=1)
image_to_verify

Define model¶
from transformers import LayoutLMv2ForTokenClassification
model = LayoutLMv2ForTokenClassification.from_pretrained('microsoft/layoutxlm-base',
id2label=id2label,
label2id=label2id)
Downloading pytorch_model.bin: 0%| | 0.00/1.48G [00:00<?, ?B/s]
Some weights of the model checkpoint at microsoft/layoutxlm-base were not used when initializing LayoutLMv2ForTokenClassification: ['layoutlmv2.visual.backbone.bottom_up.res4.2.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.1.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.6.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.21.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.5.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.3.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.4.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.8.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.22.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.11.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.3.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.13.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.14.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.0.shortcut.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.15.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.1.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.2.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.0.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.18.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.0.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.0.shortcut.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.21.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.7.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.6.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.16.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.1.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.0.shortcut.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.22.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.20.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.1.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.2.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.2.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.0.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.1.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.17.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.14.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.12.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.20.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.15.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.0.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.17.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.7.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.9.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.0.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.21.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.10.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.0.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.18.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.8.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.10.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.4.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.3.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.1.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.5.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.0.shortcut.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.0.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.12.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.2.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.1.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.0.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.19.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.0.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.13.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.5.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.12.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.0.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.9.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.1.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.11.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.3.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.0.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.1.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.8.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.10.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.1.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.11.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.3.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.17.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.2.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.6.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.18.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.7.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.stem.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.19.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.1.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.3.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.2.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.2.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.2.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.2.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.15.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res3.2.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.9.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.22.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res2.0.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.14.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.13.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.4.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.20.conv2.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.19.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.16.conv3.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.1.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res4.16.conv1.norm.num_batches_tracked', 'layoutlmv2.visual.backbone.bottom_up.res5.2.conv1.norm.num_batches_tracked'] - This IS expected if you are initializing LayoutLMv2ForTokenClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing LayoutLMv2ForTokenClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model). Some weights of LayoutLMv2ForTokenClassification were not initialized from the model checkpoint at microsoft/layoutxlm-base and are newly initialized: ['classifier.bias', 'classifier.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Train the model using 🤗 Trainer¶
We first define a compute_metrics function as well as TrainingArguments.
from datasets import load_metric
import numpy as np
# Metrics
metric = load_metric("seqeval")
return_entity_level_metrics = False
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[id2label[p] for (p, l) in zip(prediction, label) if l != label_pad_token_id]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[id2label[l] for (p, l) in zip(prediction, label) if l != label_pad_token_id]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
if return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
<ipython-input-43-602a686f53e2>:5: FutureWarning: load_metric is deprecated and will be removed in the next major version of datasets. Use 'evaluate.load' instead, from the new library 🤗 Evaluate: https://huggingface.co/docs/evaluate
metric = load_metric("seqeval")
Downloading builder script: 0%| | 0.00/2.47k [00:00<?, ?B/s]
# # delete repo if exists
# try:
# from huggingface_hub import HfApi
# HfApi().delete_repo(hub_model_id)
# except:
# print("Repository Not Found.")
# else:
# print(f"The following repository was deleted: https://huggingface.co/{hub_model_id}")
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir=output_dir, # name of directory to store the checkpoints
overwrite_output_dir=True,
hub_model_id=hub_model_id, # name of directory to store the finetuned model in HF hub
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
warmup_ratio=warmup_ratio, # we warmup a bit
evaluation_strategy=evaluation_strategy,
eval_steps=eval_steps,
save_steps=save_steps, # eval_steps
save_total_limit=save_total_limit,
load_best_model_at_end=load_best_model_at_end,
metric_for_best_model=metric_for_best_model,
report_to=report_to,
fp16=fp16,
push_to_hub=push_to_hub, # we'd like to push our model to the hub during training
hub_private_repo=hub_private_repo,
hub_strategy=hub_strategy,
remove_unused_columns=False,
)
Next we define a custom Trainer which uses the DataLoaders we created above.
from transformers.data.data_collator import default_data_collator
from transformers import TrainingArguments, Trainer
class CustomTrainer(Trainer):
def get_train_dataloader(self):
return train_dataloader
def get_eval_dataloader(self, eval_dataset = None):
return eval_dataloader
# Initialize our Trainer
trainer = CustomTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
Evaluate¶
trainer.evaluate()
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Text seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Section-header seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: List-item seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Page-footer seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Page-header seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Picture seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Caption seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Table seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Formula seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Title seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
/usr/local/lib/python3.9/dist-packages/seqeval/metrics/sequence_labeling.py:171: UserWarning: Footnote seems not to be NE tag.
warnings.warn('{} seems not to be NE tag.'.format(chunk))
{'eval_loss': 0.16871610283851624,
'eval_precision': 0.8183318056828598,
'eval_recall': 0.7624252775405637,
'eval_f1': 0.7893899204244033,
'eval_accuracy': 0.9730095001280235,
'eval_runtime': 330.9537,
'eval_samples_per_second': 4.856,
'eval_steps_per_second': 0.305,
'epoch': 4.0}
To compute metrics on the test set, we can run trainer.predict(). We get predictions, labels, and metrics back.
# predictions, labels, metrics = trainer.predict(test_dataset)
#print(metrics)
Push to HF¶
trainer.push_to_hub()