Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)¶
- Credit:
- notebook created from the notebook Fine_tune_LiLT_on_a_custom_dataset_in_any_language.ipynb of Niels ROGGE
- dataset from IBM Research (DocLayNet)
- Author of this notebook: Pierre GUILLOU
- Date: 02/16/2023
- Blog posts:
- Layout XLM base
- LiLT base
- (02/16/2023) Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level
- (02/14/2023) Document AI | Inference APP for Document Understanding at line level
- (02/10/2023) Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset
- (01/31/2023) Document AI | DocLayNet image viewer APP
- (01/27/2023) Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
- Notebooks (paragraph level)
- LiLT base
- Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)
- LiLT base
- Notebooks (line level)
- Layout XLM base
- Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)
- Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- LiLT base
- Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)
- Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)
- DocLayNet image viewer APP
- Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)
- Layout XLM base
Overview¶
LiLT¶
LiLT (Language-Independent Layout Transformer) is a Document Understanding model that uses both layout and text in order to detect labels of bounding boxes. It relies on an external OCR engine like PyTesseract to get words and bboxes from the document image.
Sources:
DocLayNet¶
DocLayNet dataset¶
DocLayNet dataset (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: doclaynet_core.zip (28 GiB), doclaynet_extra.zip (7.5 GiB)
- Hugging Face dataset library: dataset DocLayNet
Paper: DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis (06/02/2022)
Processing into a format facilitating its use by HF notebooks¶
These 2 options require the downloading of all the data (approximately 30GBi), which requires downloading time (about 45 mn in Google Colab) and a large space on the hard disk. These could limit experimentation for people with low resources.
Moreover, even when using the download via HF datasets library, it is necessary to download the EXTRA zip separately (doclaynet_extra.zip, 7.5 GiB) to associate the annotated bounding boxes with the text extracted by OCR from the PDFs. This operation also requires additional code because the boundings boxes of the texts do not necessarily correspond to those annotated (a calculation of the percentage of area in common between the boundings boxes annotated and those of the texts makes it possible to make a comparison between them).
At last, in order to use Hugging Face notebooks on fine-tuning layout models like LayoutLMv3 or LiLT, DocLayNet data must be processed in a proper format.
For all these reasons, I decided to process the DocLayNet dataset:
- into 3 datasets of different sizes:
- DocLayNet small (about 1% of DocLayNet) < 1.000k document images (691 train, 64 val, 49 test)
- DocLayNet base (about 10% of DocLayNet) < 10.000k document images (6910 train, 648 val, 499 test)
- DocLayNet large (about 100% of DocLayNet) < 100.000k document images (69.103 train, 6.480 val, 4.994 test)
- with associated texts and PDFs (base64 format),
- and in a format facilitating their use by HF notebooks.
Note: the layout HF notebooks will greatly help participants of the IBM ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents!
About PDFs languages¶
Citation of the page 3 of the DocLayNet paper: "We did not control the document selection with regard to language. The vast majority of documents contained in DocLayNet (close to 95%) are published in English language. However, DocLayNet also contains a number of documents in other languages such as German (2.5%), French (1.0%) and Japanese (1.0%). While the document language has negligible impact on the performance of computer vision methods such as object detection and segmentation models, it might prove challenging for layout analysis methods which exploit textual features."
About PDFs categories distribution¶
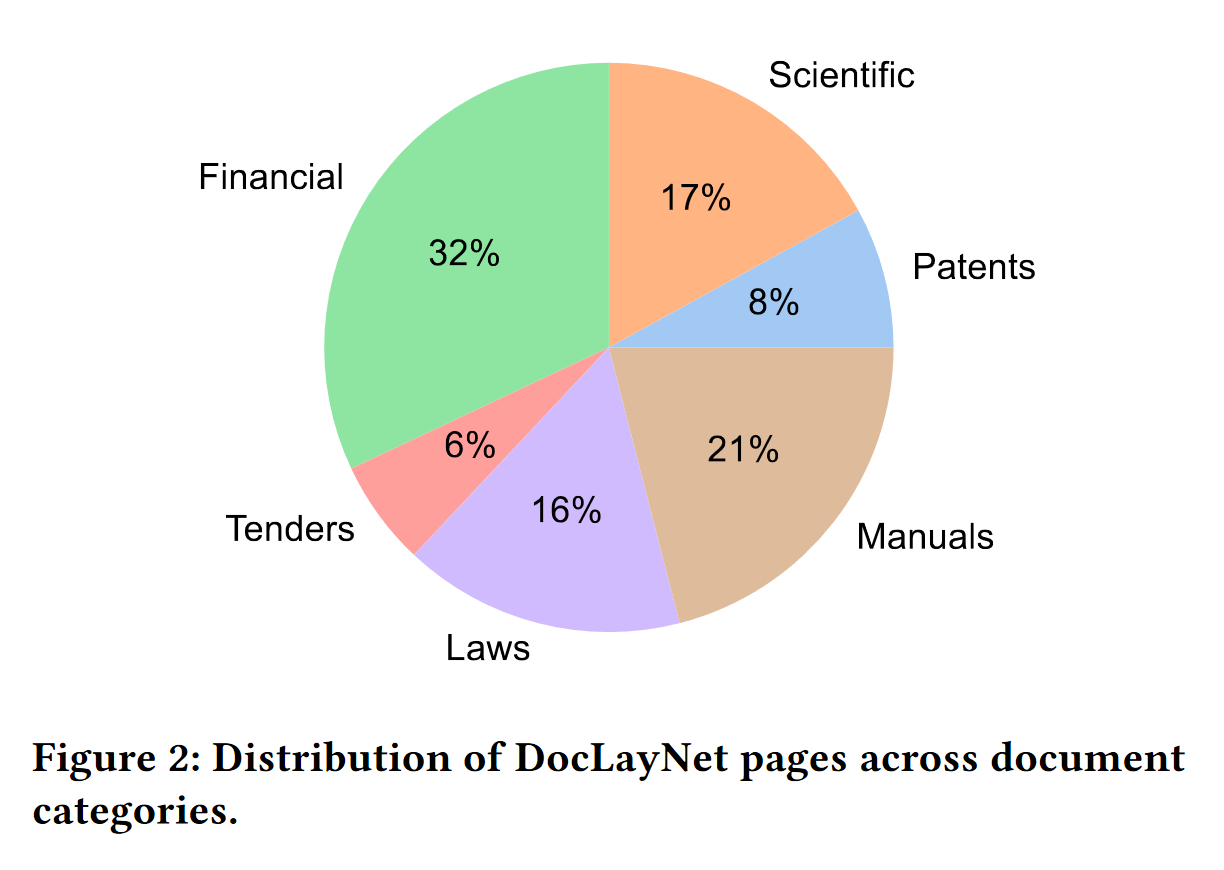
Citation of the page 3 of the DocLayNet paper: "The pages in DocLayNet can be grouped into six distinct categories, namely Financial Reports, Manuals, Scientific Articles, Laws & Regulations, Patents and Government Tenders. Each document category was sourced from various repositories. For example, Financial Reports contain both free-style format annual reports which expose company-specific, artistic layouts as well as the more formal SEC filings. The two largest categories (Financial Reports and Manuals) contain a large amount of free-style layouts in order to obtain maximum variability. In the other four categories, we boosted the variability by mixing documents from independent providers, such as different government websites or publishers. In Figure 2, we show the document categories contained in DocLayNet with their respective sizes."
DocLayNet Labels¶
The DocLayNet labels have the following meaning (source: IBM DocLayNet Labeling Guide)
- Text: Regular paragraphs.
- Picture: A graphic or photograph.
- Caption: Special text outside a picture or table that introduces this picture or table.
- Section-header: Any kind of heading in the text, except overall document title.
- Footnote: Typically small text at the bottom of a page, with a number or symbol that is referred to in the text above.
- Formula: Mathematical equation on its own line.
Further labels not shown in the example above:
- Table: Material arranged in a grid alignment with rows and columns, often with separator lines.
- List-item: One element of a list, in a hanging shape, i.e., from the second line onwards the paragraph is indented more than the first line.
- Page-header: Repeating elements like page number at the top, outside of the normal text flow.
- Page-footer: Repeating elements like page number at the bottom, outside of the normal text flow.
- Title: 1 Overall title of a document, (almost) exclusively on the first page and
- typically appearing in large font.
- None: Initial state of each cell/element. Only keep this if the element is not a text or picture or anything else of value. For instance, a smear or an invisible/empty cell should remain “None
!nvidia-smi
Wed Feb 15 07:08:31 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 510.47.03 Driver Version: 510.47.03 CUDA Version: 11.6 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 39C P0 25W / 70W | 0MiB / 15360MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Set-up environment¶
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
Mounted at /content/drive
Libraries¶
!pip install -q transformers datasets
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 6.3/6.3 MB 50.0 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 462.8/462.8 KB 46.6 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 190.3/190.3 KB 14.3 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 7.6/7.6 MB 104.4 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 132.0/132.0 KB 18.9 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 213.0/213.0 KB 27.1 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 140.6/140.6 KB 18.8 MB/s eta 0:00:00
!pip install -q evaluate
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 81.4/81.4 KB 3.4 MB/s eta 0:00:00
import numpy as np
from operator import itemgetter
import collections
import pandas as pd
import random
import matplotlib.pyplot as plt
from PIL import Image, ImageDraw, ImageFont
font = ImageFont.load_default()
import cv2
# In Colab, use cv2_imshow instead of cv2.imshow
from google.colab.patches import cv2_imshow # Colab
from ipywidgets import widgets
from IPython.display import display, HTML
from datasets import concatenate_datasets
Key parameters¶
# categories colors
label2color = {
'Caption': 'brown',
'Footnote': 'orange',
'Formula': 'gray',
'List-item': 'yellow',
'Page-footer': 'red',
'Page-header': 'red',
'Picture': 'violet',
'Section-header': 'orange',
'Table': 'green',
'Text': 'blue',
'Title': 'pink'
}
domains = ["Financial Reports", "Manuals", "Scientific Articles", "Laws & Regulations", "Patents", "Government Tenders"]
domain_names = [domain_name.lower().replace(" ", "_").replace("&", "and") for domain_name in domains]
# bounding boxes start and end of a sequence
cls_box = [0, 0, 0, 0]
sep_box = cls_box
# DocLayNet dataset
# dataset_name = "pierreguillou/DocLayNet-small"
dataset_name = "pierreguillou/DocLayNet-base"
dataset_name_suffix = dataset_name.replace("pierreguillou/DocLayNet-", "")
# parameters for tokenization and overlap
max_length = 512 # The maximum length of a feature (sequence)
doc_stride = 128 # The authorized overlap between two part of the context when splitting it is needed.
# parameters de TrainingArguments
batch_size=8 # WARNING: change this value according to your GPU RAM
num_train_epochs=1
learning_rate=2e-5
per_device_train_batch_size=batch_size
per_device_eval_batch_size=batch_size*2
gradient_accumulation_steps=1
evaluation_strategy="steps"
eval_steps=100
save_steps=100 # eval_steps
save_total_limit=2
load_best_model_at_end=True
metric_for_best_model="f1"
report_to="tensorboard"
fp16=True
push_to_hub=True # we'd like to push our model to the hub during training
hub_private_repo=True
hub_strategy="all_checkpoints"
# model name in HF
version = 1 # version number
output_dir = "DocLayNet/lilt-xlm-roberta-base-finetuned-" + dataset_name.replace("pierreguillou/", "") + "_paragraphs_ml" + str(max_length) + "-v" + str(version)
hub_model_id = "pierreguillou/lilt-xlm-roberta-base-finetuned-" + dataset_name.replace("pierreguillou/", "") + "_paragraphs_ml" + str(max_length) + "-v" + str(version)
Functions¶
General¶
# it is important that each bounding box should be in (upper left, lower right) format.
# source: https://github.com/NielsRogge/Transformers-Tutorials/issues/129
def upperleft_to_lowerright(bbox):
x0, y0, x1, y1 = tuple(bbox)
if bbox[2] < bbox[0]:
x0 = bbox[2]
x1 = bbox[0]
if bbox[3] < bbox[1]:
y0 = bbox[3]
y1 = bbox[1]
return [x0, y0, x1, y1]
# convert boundings boxes (left, top, width, height) format to (left, top, left+widght, top+height) format.
def convert_box(bbox):
x, y, w, h = tuple(bbox) # the row comes in (left, top, width, height) format
return [x, y, x+w, y+h] # we turn it into (left, top, left+widght, top+height) to get the actual box
# LiLT model gets 1000x10000 pixels images
def normalize_box(bbox, width, height):
return [
int(1000 * (bbox[0] / width)),
int(1000 * (bbox[1] / height)),
int(1000 * (bbox[2] / width)),
int(1000 * (bbox[3] / height)),
]
# LiLT model gets 1000x10000 pixels images
def denormalize_box(bbox, width, height):
return [
int(width * (bbox[0] / 1000)),
int(height * (bbox[1] / 1000)),
int(width* (bbox[2] / 1000)),
int(height * (bbox[3] / 1000)),
]
# get back original size
def original_box(box, original_width, original_height, coco_width, coco_height):
return [
int(original_width * (box[0] / coco_width)),
int(original_height * (box[1] / coco_height)),
int(original_width * (box[2] / coco_width)),
int(original_height* (box[3] / coco_height)),
]
def get_blocks(bboxes_block, categories, texts):
# get list of unique block boxes
bbox_block_dict, bboxes_block_list, bbox_block_prec = dict(), list(), list()
for count_block, bbox_block in enumerate(bboxes_block):
if bbox_block != bbox_block_prec:
bbox_block_indexes = [i for i, bbox in enumerate(bboxes_block) if bbox == bbox_block]
bbox_block_dict[count_block] = bbox_block_indexes
bboxes_block_list.append(bbox_block)
bbox_block_prec = bbox_block
# get list of categories and texts by unique block boxes
category_block_list, text_block_list = list(), list()
for bbox_block in bboxes_block_list:
count_block = bboxes_block.index(bbox_block)
bbox_block_indexes = bbox_block_dict[count_block]
category_block = np.array(categories, dtype=object)[bbox_block_indexes].tolist()[0]
category_block_list.append(category_block)
text_block = np.array(texts, dtype=object)[bbox_block_indexes].tolist()
text_block = [text.replace("\n","").strip() for text in text_block]
if id2label[category_block] == "Text" or id2label[category_block] == "Caption" or id2label[category_block] == "Footnote":
text_block = ' '.join(text_block)
else:
text_block = '\n'.join(text_block)
text_block_list.append(text_block)
return bboxes_block_list, category_block_list, text_block_list
# function to sort bounding boxes
def get_sorted_boxes(bboxes):
# sort by y from page top to bottom
sorted_bboxes = sorted(bboxes, key=itemgetter(1), reverse=False)
y_list = [bbox[1] for bbox in sorted_bboxes]
# sort by x from page left to right when boxes with same y
if len(list(set(y_list))) != len(y_list):
y_list_duplicates_indexes = dict()
y_list_duplicates = [item for item, count in collections.Counter(y_list).items() if count > 1]
for item in y_list_duplicates:
y_list_duplicates_indexes[item] = [i for i, e in enumerate(y_list) if e == item]
bbox_list_y_duplicates = sorted(np.array(sorted_bboxes, dtype=object)[y_list_duplicates_indexes[item]].tolist(), key=itemgetter(0), reverse=False)
np_array_bboxes = np.array(sorted_bboxes)
np_array_bboxes[y_list_duplicates_indexes[item]] = np.array(bbox_list_y_duplicates)
sorted_bboxes = np_array_bboxes.tolist()
return sorted_bboxes
# sort data from y = 0 to end of page (and after, x=0 to end of page when necessary)
def sort_data(bboxes, categories, texts):
sorted_bboxes = get_sorted_boxes(bboxes)
sorted_bboxes_indexes = [bboxes.index(bbox) for bbox in sorted_bboxes]
sorted_categories = np.array(categories, dtype=object)[sorted_bboxes_indexes].tolist()
sorted_texts = np.array(texts, dtype=object)[sorted_bboxes_indexes].tolist()
return sorted_bboxes, sorted_categories, sorted_texts
Dataset¶
# get PDF image and its data
def generate_annotated_image(index_image=None, split="all"):
# get dataset
example = dataset
# get split
if split == "all":
example = concatenate_datasets([example["train"], example["validation"], example["test"]])
else:
example = example[split]
# get random image & PDF data
if index_image == None: index_image = random.randint(0, len(example)-1)
example = example[index_image]
image = example["image"] # original image
coco_width, coco_height = example["coco_width"], example["coco_height"]
original_width, original_height = example["original_width"], example["original_height"]
original_filename = example["original_filename"]
page_no = example["page_no"]
num_pages = example["num_pages"]
# resize image to original
image = image.resize((original_width, original_height))
# get corresponding annotations
texts = example["texts"]
bboxes_block = example["bboxes_block"]
bboxes_line = example["bboxes_line"]
categories = example["categories"]
domain = example["doc_category"]
# get domain name
index_domain = domain_names.index(domain)
domain = domains[index_domain]
# convert boxes to original
original_bboxes_block = [original_box(convert_box(box), original_width, original_height, coco_width, coco_height) for box in bboxes_block]
original_bboxes_line = [original_box(convert_box(box), original_width, original_height, coco_width, coco_height) for box in bboxes_line]
##### block boxes #####
# get unique blocks and its data
bboxes_blocks_list, category_block_list, text_block_list = get_blocks(original_bboxes_block, categories, texts)
# sort data from y = 0 to end of page (and after, x=0 to end of page when necessary)
sorted_original_bboxes_block_list, sorted_category_block_list, sorted_text_block_list = sort_data(bboxes_blocks_list, category_block_list, text_block_list)
##### line boxes ####
# sort data from y = 0 to end of page (and after, x=0 to end of page when necessary)
sorted_original_bboxes_line_list, sorted_category_line_list, sorted_text_line_list = sort_data(original_bboxes_line, categories, texts)
# group paragraphs and lines outputs
sorted_original_bboxes = [sorted_original_bboxes_block_list, sorted_original_bboxes_line_list]
sorted_categories = [sorted_category_block_list, sorted_category_line_list]
sorted_texts = [sorted_text_block_list, sorted_text_line_list]
# get annotated boudings boxes on images
images = [image.copy(), image.copy()]
imgs, df_paragraphs, df_lines = dict(), pd.DataFrame(), pd.DataFrame()
for i, img in enumerate(images):
img = img.convert('RGB') # Convert to RGB
draw = ImageDraw.Draw(img)
for box, label_idx, text in zip(sorted_original_bboxes[i], sorted_categories[i], sorted_texts[i]):
label = id2label[label_idx]
color = label2color[label]
draw.rectangle(box, outline=color)
text = text.encode('latin-1', 'replace').decode('latin-1') # https://stackoverflow.com/questions/56761449/unicodeencodeerror-latin-1-codec-cant-encode-character-u2013-writing-to
draw.text((box[0] + 10, box[1] - 10), text=label, fill=color, font=font)
if i == 0:
imgs["paragraphs"] = img
df_paragraphs["paragraphs"] = list(range(len(sorted_original_bboxes_block_list)))
df_paragraphs["categories"] = [id2label[label_idx] for label_idx in sorted_category_block_list]
df_paragraphs["texts"] = sorted_text_block_list
df_paragraphs["bounding boxes"] = [str(bbox) for bbox in sorted_original_bboxes_block_list]
else:
imgs["lines"] = img
df_lines["lines"] = list(range(len(sorted_original_bboxes_line_list)))
df_lines["categories"] = [id2label[label_idx] for label_idx in sorted_category_line_list]
df_lines["texts"] = sorted_text_line_list
df_lines["bounding boxes"] = [str(bbox) for bbox in sorted_original_bboxes_line_list]
return imgs, original_filename, page_no, num_pages, domain, df_paragraphs, df_lines
# display PDF image and its data
def display_pdf_blocks_lines(index_image=None, split="all"):
# get image and image data
images, original_filename, page_no, num_pages, domain, df_paragraphs, df_lines = generate_annotated_image(index_image=index_image, split=split)
print(f"PDF: {original_filename} (page: {page_no+1} / {num_pages}; domain: {domain})\n")
# left widget
style1 = {'overflow': 'scroll' ,'white-space': 'nowrap', 'width':'50%'}
output1 = widgets.Output(description = "PDF image with bounding boxes of paragraphs", style=style1)
with output1:
# display image
print(">> PDF image with bounding boxes of paragraphs\n")
open_cv_image = np.array(images["paragraphs"]) # PIL to cv2
# Convert RGB to BGR
open_cv_image = open_cv_image[:, :, ::-1].copy()
cv2_imshow(open_cv_image) # Colab
cv2.waitKey(0)
# display DataFrame
print("\n>> Paragraphs dataframe\n")
display(df_paragraphs)
# right widget
style2 = style1
output2 = widgets.Output(description = "PDF image with bounding boxes of lines", style=style2)
with output2:
# display image
print(">> PDF image with bounding boxes of lines\n")
open_cv_image = np.array(images["lines"]) # PIL to cv2
# Convert RGB to BGR
open_cv_image = open_cv_image[:, :, ::-1].copy()
cv2_imshow(open_cv_image) # Colab
cv2.waitKey(0)
# display DataFrame
print("\n>> Lines dataframe\n")
display(df_lines)
## Side by side thanks to HBox widgets
sidebyside = widgets.HBox([output1,output2])
## Finally, show.
display(sidebyside)
Encoded dataset¶
# creation of encoded dataset
def prepare_features(example, cls_box = cls_box, sep_box = sep_box):
input_ids_list, attention_mask_list, bb_list, ll_list, page_hash_list = list(), list(), list(), list(), list()
# get batch
batch_page_hash = example["page_hash"]
batch_bboxes_block = example["bboxes_block"]
batch_categories = example["categories"]
batch_texts = example["texts"]
# batch_original_width, batch_original_height = example["original_width"] , example["original_height"]
batch_coco_width, batch_coco_height = example["coco_width"] , example["coco_height"]
# add a dimension if not a batch but only one image
if not isinstance(batch_page_hash, list):
batch_page_hash = [batch_page_hash]
batch_bboxes_block = [batch_bboxes_block]
batch_categories = [batch_categories]
batch_texts = [batch_texts]
batch_coco_width, batch_coco_height = [batch_coco_width], [batch_coco_height]
# process all images of the batch
for num_batch, (page_hash, boxes, labels, texts, coco_width, coco_height) in enumerate(zip(batch_page_hash, batch_bboxes_block, batch_categories, batch_texts, batch_coco_width, batch_coco_height)):
tokens_list = []
bboxes_list = []
labels_list = []
# add a dimension if only on image
if not isinstance(texts, list):
texts, boxes, labels = [texts], [boxes], [labels]
# convert boxes to original
# Check the upperleft_to_lowerright
# normalize
normalize_bboxes_block = [normalize_box(upperleft_to_lowerright(convert_box(box)), coco_width, coco_height) for box in boxes]
# sort boxes with categorizations and texts
# we want sorted lists from top to bottom of the image
boxes, labels, texts = sort_data(normalize_bboxes_block, labels, texts)
count = 0
for box, label, text in zip(boxes, labels, texts):
tokens = tokenizer.tokenize(text)
num_tokens = len(tokens) # get number of tokens
tokens_list.extend(tokens)
bboxes_list.extend([box] * num_tokens) # number of boxes must be the same as the number of tokens
labels_list.extend([label] + ([-100] * (num_tokens - 1))) # number of labels id must be the same as the number of tokens
# use of return_overflowing_tokens=True / stride=doc_stride
# to get parts of image with overlap
# source: https://huggingface.co/course/chapter6/3b?fw=tf#handling-long-contexts
encodings = tokenizer(" ".join(texts),
truncation=True,
padding="max_length",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True
)
_ = encodings.pop("overflow_to_sample_mapping")
offset_mapping = encodings.pop("offset_mapping")
# Let's label those examples and get their boxes
sequence_length_prev = 0
for i, offsets in enumerate(offset_mapping):
# truncate tokens, boxes and labels based on length of chunk - 2 (special tokens <s> and </s>)
sequence_length = len(encodings.input_ids[i]) - 2
if i == 0: start = 0
else: start += sequence_length_prev - doc_stride
end = start + sequence_length
sequence_length_prev = sequence_length
# get tokens, boxes and labels of this image chunk
bb = [cls_box] + bboxes_list[start:end] + [sep_box]
# check if the start truncation is on label -100
ll = labels_list[start:end]
flag = True
label_to_use = -100
count = 0
ll_ori = ll.copy()
while flag:
if len(ll) > 0:
if ll[0] != -100 and count == 0:
flag = False
elif ll[0] == -100 and count == 0:
ll = ll[1:]
count += 1
elif ll[0] != -100 and count > 0:
label_to_use = ll[0]
flag = False
elif ll[0] == -100 and count > 0:
ll = ll[1:]
count += 1
else:
flag = False
if label_to_use != -100:
ll = [label_to_use]*count + ll_ori[count:]
else:
ll = ll_ori
# check if the end truncation is on label -100
flag = True
label_to_use = -100
count = 0
ll_ori = ll.copy()
while flag:
if len(ll) > 0:
if ll[-1] != -100 and count == 0:
flag = False
elif ll[-1] == -100 and count == 0:
ll = ll[:-1]
count += 1
elif ll[-1] != -100 and count > 0:
label_to_use = ll[-1]
flag = False
elif ll[-1] == -100 and count > 0:
ll = ll[:-1]
count += 1
else:
flag = False
if label_to_use != -100:
ll = ll_ori[:-count] + [label_to_use]*count
else:
ll = ll_ori
# get labels for this chunck
ll = [-100] + ll + [-100]
# as the last chunk can have a length < max_length
# we must to add [tokenizer.pad_token] (tokens), [sep_box] (boxes) and [-100] (labels)
if len(bb) < max_length:
bb = bb + [sep_box] * (max_length - len(bb))
ll = ll + [-100] * (max_length - len(ll))
# append results
input_ids_list.append(encodings["input_ids"][i])
attention_mask_list.append(encodings["attention_mask"][i])
bb_list.append(bb)
ll_list.append(ll)
page_hash_list.append(page_hash)
return {
"input_ids": input_ids_list,
"attention_mask": attention_mask_list,
"normalized_bboxes": bb_list,
"labels": ll_list,
"page_hash": page_hash_list,
}
# get data of encoded chunk
def get_encoded_chunk(index_chunk=None, split="all"):
# get datasets
example = dataset
encoded_example = encoded_dataset
# get split
if split == "all":
example = concatenate_datasets([example["train"], example["validation"], example["test"]])
encoded_example = concatenate_datasets([encoded_example["train"], encoded_example["validation"], encoded_example["test"]])
else:
example = example[split]
encoded_example = encoded_example[split]
# get randomly a document in dataset
if index_chunk == None: index_chunk = random.randint(0, len(encoded_example)-1)
encoded_example = encoded_example[index_chunk]
encoded_page_hash = encoded_example["page_hash"]
# get the image
example = example.filter(lambda example: example["page_hash"] == encoded_page_hash)[0]
image = example["image"] # original image
coco_width, coco_height = example["coco_width"], example["coco_height"]
original_filename = example["original_filename"]
page_no = example["page_no"]
num_pages = example["num_pages"]
domain = example["doc_category"]
# get domain name
index_domain = domain_names.index(domain)
domain = domains[index_domain]
# get boxes, texts, categories
bboxes, labels_id, input_ids = encoded_example["normalized_bboxes"][1:-1], encoded_example["labels"][1:-1], encoded_example["input_ids"][1:-1]
bboxes = [denormalize_box(bbox, coco_width, coco_height) for bbox in bboxes]
num_tokens = len(input_ids) + 2
# get unique bboxes and corresponding labels
bboxes_list, labels_list, input_ids_list = list(), list(), list()
input_ids_dict = dict()
bbox_prev = [-100, -100, -100, -100]
for i, (bbox, label_id, input_id) in enumerate(zip(bboxes, labels_id, input_ids)):
if bbox != bbox_prev:
bboxes_list.append(bbox)
input_ids_dict[str(bbox)] = [input_id]
labels_list.append(label_id)
label_id_prev = label_id
else:
input_ids_dict[str(bbox)].append(input_id)
# start_indexes_list.append(i)
bbox_prev = bbox
# do not keep "</s><pad><pad>..."
if input_ids_dict[str(bboxes_list[-1])][0] == (tokenizer.convert_tokens_to_ids('</s>')):
del input_ids_dict[str(bboxes_list[-1])]
bboxes_list = bboxes_list[:-1]
labels_list = labels_list[:-1]
# get texts by line
input_ids_list = input_ids_dict.values()
texts_list = [tokenizer.decode(input_ids) for input_ids in input_ids_list]
# display DataFrame
df = pd.DataFrame({"texts": texts_list, "input_ids": input_ids_list, "labels_ids": labels_list, "bboxes": bboxes_list})
return image, original_filename, page_no, num_pages, domain, df, num_tokens
# display chunk of PDF image and its data
def display_chunk_lines(index_chunk=None, split="all"):
# get image and image data
image, original_filename, page_no, num_pages, domain, df, num_tokens = get_encoded_chunk(index_chunk=index_chunk, split=split)
image = image.convert('RGB') # Convert to RGB
# get data from dataframe
input_ids = df["input_ids"]
texts = df["texts"]
labels_ids = df["labels_ids"]
bboxes = df["bboxes"]
print(f'Chunk ({num_tokens} tokens) of the PDF "{original_filename}" (page: {page_no+1} / {num_pages}; domain: {domain})\n')
# display image with annotated bounding boxes
print(">> PDF image with bounding boxes of lines\n")
draw = ImageDraw.Draw(image)
labels = list()
for box, label_idx, text in zip(bboxes, labels_ids, texts):
label = id2label[label_idx]
labels.append(label)
color = label2color[label]
draw.rectangle(box, outline=color)
text = text.encode('latin-1', 'replace').decode('latin-1') # https://stackoverflow.com/questions/56761449/unicodeencodeerror-latin-1-codec-cant-encode-character-u2013-writing-to
draw.text((box[0] + 10, box[1] - 10), text=label, fill=color, font=font)
open_cv_image = np.array(image) # PIL to cv2
# Convert RGB to BGR
open_cv_image = open_cv_image[:, :, ::-1].copy()
cv2_imshow(open_cv_image) # Colab
cv2.waitKey(0)
# display image dataframe
print("\n>> Dataframe of annotated lines\n")
df["labels"] = labels
cols = ["texts", "labels", "bboxes"]
df = df[cols]
display(df)
HF login¶
!huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To login, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token:
Add token as git credential? (Y/n) Y
Token is valid.
Cannot authenticate through git-credential as no helper is defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub.
Run the following command in your terminal in case you want to set the 'store' credential helper as default.
git config --global credential.helper store
Read https://git-scm.com/book/en/v2/Git-Tools-Credential-Storage for more details.
Token has not been saved to git credential helper.
Your token has been saved to /root/.cache/huggingface/token
Login successful
Download DocLayNet¶
Download¶
local_dataset_name = "/content/drive/MyDrive/DocLayNet/datasets/" + dataset_name.replace("pierreguillou/DocLayNet-", "")
from datasets import load_dataset
dataset = load_dataset(dataset_name)
# save locally
dataset.save_to_disk(local_dataset_name)
# load
from datasets import load_from_disk
dataset = load_from_disk(local_dataset_name)
dataset
DatasetDict({
train: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 6910
})
validation: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 648
})
test: Dataset({
features: ['id', 'texts', 'bboxes_block', 'bboxes_line', 'categories', 'image', 'page_hash', 'original_filename', 'page_no', 'num_pages', 'original_width', 'original_height', 'coco_width', 'coco_height', 'collection', 'doc_category'],
num_rows: 499
})
})
dataset["train"].features
{'id': Value(dtype='string', id=None),
'texts': Sequence(feature=Value(dtype='string', id=None), length=-1, id=None),
'bboxes_block': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'bboxes_line': Sequence(feature=Sequence(feature=Value(dtype='int64', id=None), length=-1, id=None), length=-1, id=None),
'categories': Sequence(feature=ClassLabel(names=['Caption', 'Footnote', 'Formula', 'List-item', 'Page-footer', 'Page-header', 'Picture', 'Section-header', 'Table', 'Text', 'Title'], id=None), length=-1, id=None),
'image': Image(decode=True, id=None),
'page_hash': Value(dtype='string', id=None),
'original_filename': Value(dtype='string', id=None),
'page_no': Value(dtype='int32', id=None),
'num_pages': Value(dtype='int32', id=None),
'original_width': Value(dtype='int32', id=None),
'original_height': Value(dtype='int32', id=None),
'coco_width': Value(dtype='int32', id=None),
'coco_height': Value(dtype='int32', id=None),
'collection': Value(dtype='string', id=None),
'doc_category': Value(dtype='string', id=None)}
label_list = dataset["train"].features["categories"].feature.names
id2label = {id:label for id, label in enumerate(label_list)}
label2id = {label:id for id, label in enumerate(label_list)}
num_labels = len(label_list)
print(id2label)
{0: 'Caption', 1: 'Footnote', 2: 'Formula', 3: 'List-item', 4: 'Page-footer', 5: 'Page-header', 6: 'Picture', 7: 'Section-header', 8: 'Table', 9: 'Text', 10: 'Title'}
Checking of the dataset¶
Select a dataset split and display a random annotated image from it and its dataframe.
# choose your dataset
splits = ["all", "train", "validation", "test"]
index_split = 3
split = splits[index_split]
# display random PDF image and its data
display_pdf_blocks_lines(split=split)
PDF: Presidential Decree No. 1067, s. 1976 | Official Gazette of the Republic of the Philippines.pdf (page: 19 / 21; domain: Laws & Regulations)
HBox(children=(Output(), Output()))
Create PyTorch Dataset¶
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("nielsr/lilt-xlm-roberta-base")
Downloading (…)okenizer_config.json: 0%| | 0.00/451 [00:00<?, ?B/s]
Downloading (…)"tokenizer.json";: 0%| | 0.00/17.1M [00:00<?, ?B/s]
Downloading (…)cial_tokens_map.json: 0%| | 0.00/280 [00:00<?, ?B/s]
Encoded dataset (dataset divided into chunks with overlap)¶
Now one specific thing for the preprocessing in token classification is how to deal with very long documents. We usually truncate them in other tasks, when they are longer than the model maximum sentence length, but here, removing part of the the context might result in a worst model. To deal with this, we will allow one (long) example in our dataset to give several input features, each of length shorter than the maximum length of the model (or the one we set as a hyper-parameter). Also, we allow some overlap between the features we generate controlled by the hyper-parameter doc_stride in order to train the model with more contextual information.
Let's encode the dataset (ie, creation of chunks by page)!
local_encoded_dataset = "/content/drive/MyDrive/DocLayNet/datasets/" + dataset_name.replace("pierreguillou/DocLayNet-", "") + "_paragraphs_encoded" + "_ml" + str(max_length)
encoded_dataset_name_hub = dataset_name.replace("pierreguillou/","") + "_paragraphs_encoded" + "_ml" + str(max_length)
encoded_dataset = dataset.map(prepare_features, batched=True, batch_size=64, remove_columns=dataset["train"].column_names)
# save locally
encoded_dataset.save_to_disk(local_encoded_dataset)
# push to hub
encoded_dataset.push_to_hub(encoded_dataset_name_hub, private=True)
# # load from disk
# from datasets import load_from_disk
# encoded_dataset = load_from_disk(local_encoded_dataset)
# load from hb
from datasets import load_dataset
encoded_dataset = load_dataset("pierreguillou/" + encoded_dataset_name_hub)
Downloading readme: 0%| | 0.00/706 [00:00<?, ?B/s]
WARNING:datasets.builder:Using custom data configuration pierreguillou--DocLayNet-base_paragraphs_encoded_ml512-22c7035ead5dd8eb
Downloading and preparing dataset None/None to /root/.cache/huggingface/datasets/pierreguillou___parquet/pierreguillou--DocLayNet-base_paragraphs_encoded_ml512-22c7035ead5dd8eb/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec...
Downloading data files: 0%| | 0/3 [00:00<?, ?it/s]
Downloading data: 0%| | 0.00/9.44M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/1.09M [00:00<?, ?B/s]
Downloading data: 0%| | 0.00/539k [00:00<?, ?B/s]
Extracting data files: 0%| | 0/3 [00:00<?, ?it/s]
Generating train split: 0%| | 0/15009 [00:00<?, ? examples/s]
Generating validation split: 0%| | 0/1607 [00:00<?, ? examples/s]
Generating test split: 0%| | 0/1041 [00:00<?, ? examples/s]
Dataset parquet downloaded and prepared to /root/.cache/huggingface/datasets/pierreguillou___parquet/pierreguillou--DocLayNet-base_paragraphs_encoded_ml512-22c7035ead5dd8eb/0.0.0/2a3b91fbd88a2c90d1dbbb32b460cf621d31bd5b05b934492fdef7d8d6f236ec. Subsequent calls will reuse this data.
0%| | 0/3 [00:00<?, ?it/s]
encoded_dataset
DatasetDict({
train: Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels'],
num_rows: 15009
})
validation: Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels'],
num_rows: 1607
})
test: Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels'],
num_rows: 1041
})
})
# We delete an image that has data with errors
train_dataset = encoded_dataset["train"].filter(lambda example: example["page_hash"] != 'b2f15dd6946e4465db44572fbc734724a7db04e1c6b79f8ff6eb931a833e829c')
0%| | 0/16 [00:00<?, ?ba/s]
train_dataset
Dataset({
features: ['page_hash', 'input_ids', 'attention_mask', 'normalized_bboxes', 'labels'],
num_rows: 15008
})
# train_dataset = encoded_dataset["train"]
eval_dataset = encoded_dataset["validation"]
test_dataset = encoded_dataset["test"]
Checking of the encoded dataset¶
Select a encoded dataset split and display a random annotated chunk image from it and its dataframe.
Note: the image is squared because of its normalization to 1000px vs 1000px in the encoded dataset (necessary for training the model).
# choose your split
splits = ["all", "train", "validation", "test"]
index_split = 3
split = splits[index_split]
# get and image from random chunk
display_chunk_lines(split=split)
0%| | 0/1 [00:00<?, ?ba/s]
Chunk (512 tokens) of the PDF "1002.0896.pdf" (page: 16 / 28; domain: Scientific Articles) >> PDF image with bounding boxes of lines

>> Dataframe of annotated lines
| texts | labels | bboxes | |
|---|---|---|---|
| 0 | GLYPH<s49>GLYPH<s48> GLYPH<s49>GLYPH<s48> GLYP... | Picture | [290, 120, 729, 444] |
Create a custom dataset¶
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, dataset, tokenizer):
self.dataset = dataset
self.tokenizer = tokenizer
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
# get item
example = self.dataset[idx]
encoding = dict()
# encoding["page_hash"] = example["page_hash"]
encoding["input_ids"] = example["input_ids"]
encoding["attention_mask"] = example["attention_mask"]
encoding["bbox"] = example["normalized_bboxes"]
encoding["labels"] = example["labels"]
return encoding
train_dataset = CustomDataset(train_dataset, tokenizer)
eval_dataset = CustomDataset(eval_dataset, tokenizer)
test_dataset = CustomDataset(test_dataset, tokenizer)
example = train_dataset[0]
for k,v in example.items():
print(k,len(v))
input_ids 512 attention_mask 512 bbox 512 labels 512
tokenizer.decode(example["input_ids"])
'<s> Notes to the consolidated financial statements of Aegon N.V. Notes to the consolidated financial statements of Aegon N.V. Notes to the consolidated financial statements of Aegon N.V. 50 50 The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 Investments for general account The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for account of policyholders Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for Investments held for account of policyholders comprise assets that</s>'
for text, box, label in zip(dataset["train"][0]["texts"], dataset["train"][0]["bboxes_line"], dataset["train"][0]["categories"]):
print(text, box, id2label[label])
Notes to the consolidated financial statements of Aegon N.V. [119, 30, 422, 13] Page-header Note 50 [541, 30, 59, 14] Page-header 270 [71, 31, 25, 13] Page-header 50 [119, 98, 19, 14] Section-header Summary of total financial assets and financial liabilities at fair value through profit or loss [143, 98, 670, 14] Section-header Investments for general account [119, 363, 212, 13] Section-header Investments for account of policyholders [119, 564, 268, 13] Section-header Investment contracts for account of policyholders [119, 719, 326, 13] Section-header Derivatives [119, 797, 74, 13] Section-header Borrowings [119, 859, 78, 13] Section-header The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value [119, 116, 770, 11] Text through profit or loss, with appropriate distinction between those financial assets and financial liabilities held for trading and those [119, 132, 764, 11] Text that, upon initial recognition, were designated as at fair value through profit or loss. [119, 147, 485, 11] Text The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. [119, 380, 724, 11] Text This includes portfolios of investments in limited partnerships and limited liability companies (primarily hedge funds) for which [119, 395, 736, 11] Text the performance is assessed internally on a total return basis. In addition, some investments that include an embedded derivative [119, 411, 751, 11] Text that would otherwise have required bifurcation, such as convertible instruments, preferred shares and credit linked notes, have been [119, 426, 768, 11] Text designated at fair value through profit or loss. [119, 442, 270, 11] Text Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair [119, 473, 753, 11] Text value recognized in the income statement, are designated at fair value through profit or loss. The Group elected to designate these [119, 488, 761, 11] Text investments at fair value through profit or loss, as a classification of financial assets as available-for-sale would result in accumulation [119, 504, 784, 11] Text of unrealized gains and losses in a revaluation reserve within equity whilst changes to the liability would be reflected in net income [119, 519, 761, 11] Text (accounting mismatch). [119, 535, 134, 11] Text Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for [119, 581, 743, 11] Text which the financial risks are borne by the customer. Under the Group’s accounting policies these insurance and investment liabilities [119, 597, 764, 11] Text are measured at the fair value of the linked assets with changes in the fair value recognized in the income statement. To avoid an [119, 612, 751, 11] Text accounting mismatch the linked assets have been designated as at fair value through profit or loss. [119, 628, 577, 11] Text In addition, the investment for account of policyholders include with profit assets, where an insurer manages these assets together [119, 659, 762, 11] Text with related liabilities on a fair value basis in accordance with a documented policy of asset and liability management. In accordance [119, 674, 767, 11] Text with Group’s accounting policies, these assets have been designated as at fair value through profit or loss. [119, 690, 614, 11] Text With the exception of the financial liabilities with discretionary participating features that are not subject to the classification and [119, 736, 755, 11] Text measurement requirements for financial instruments, all investment contracts for account of policyholders that are carried at fair value [119, 752, 787, 11] Text or at the fair value of the linked assets are included in the table above. [119, 767, 408, 11] Text With the exception of derivatives designated as a hedging instrument, all derivatives held for general account and held for account of [119, 813, 775, 11] Text policyholders are included in the table above. [119, 829, 261, 11] Text Borrowings designated as at fair value through profit or loss includes financial instruments that are managed on a fair value basis [119, 875, 753, 11] Text together with related financial assets and financial derivatives (Refer to note 41). [119, 891, 470, 11] Text Annual Report 2013 [200, 991, 124, 12] Page-footer 2013 [631, 179, 32, 12] Table 2012 [803, 180, 30, 11] Table Trading [591, 194, 46, 12] Table Designated [653, 194, 69, 12] Table Trading [768, 195, 40, 11] Table Designated [833, 195, 61, 11] Table Investments for general account [119, 212, 165, 10] Table 121 [616, 212, 21, 10] Table 4,712 [692, 212, 30, 10] Table 754 [788, 212, 21, 10] Table 4,809 [864, 212, 30, 10] Table Investments for account of policyholders [119, 227, 209, 10] Table - [633, 227, 4, 10] Table 164,037 [678, 227, 44, 10] Table - [804, 227, 4, 10] Table 151,960 [850, 227, 44, 10] Table Derivatives with positive values not designated as hedges [119, 243, 293, 10] Table 12,651 [599, 243, 37, 10] Table - [718, 243, 4, 10] Table 19,348 [771, 243, 37, 10] Table - [890, 243, 4, 10] Table Total financial assets at fair value through profit or loss [119, 256, 346, 12] Table 12,771 [594, 257, 43, 11] Table 168,749 [672, 257, 51, 11] Table 20,102 [766, 257, 43, 11] Table 156,769 [843, 257, 51, 11] Table Investment contracts for account of policyholders [119, 281, 254, 10] Table - [633, 281, 4, 10] Table 32,628 [685, 281, 37, 10] Table - [804, 281, 4, 10] Table 29,188 [857, 281, 37, 10] Table Derivatives with negative values not designated as hedges [119, 297, 297, 10] Table 11,248 [599, 297, 37, 10] Table - [718, 297, 4, 10] Table 17,042 [771, 297, 37, 10] Table - [890, 297, 4, 10] Table Borrowings [119, 312, 57, 10] Table - [633, 312, 4, 10] Table 1,017 [692, 312, 30, 10] Table - [804, 312, 4, 10] Table 1,050 [864, 312, 30, 10] Table Total financial liabilities at fair value through profit or loss [119, 326, 365, 12] Table 11,248 [594, 327, 43, 11] Table 33,645 [680, 327, 43, 11] Table 17,042 [766, 327, 43, 11] Table 30,238 [851, 327, 43, 11] Table
len(example["input_ids"])
512
for id, box, label in zip(example["input_ids"], example["bbox"], example["labels"]):
if label != -100:
print(tokenizer.decode([id]), box, id2label[label])
else:
print(tokenizer.decode([id]), box, -100)
<s> [0, 0, 0, 0] -100 Note [69, 29, 585, 42] Page-header s [69, 29, 585, 42] -100 to [69, 29, 585, 42] -100 the [69, 29, 585, 42] -100 consolida [69, 29, 585, 42] -100 ted [69, 29, 585, 42] -100 financial [69, 29, 585, 42] -100 statement [69, 29, 585, 42] -100 s [69, 29, 585, 42] -100 of [69, 29, 585, 42] -100 A [69, 29, 585, 42] -100 ego [69, 29, 585, 42] -100 n [69, 29, 585, 42] -100 N [69, 29, 585, 42] -100 . [69, 29, 585, 42] -100 V [69, 29, 585, 42] -100 . [69, 29, 585, 42] -100 Note [69, 29, 585, 42] Page-header s [69, 29, 585, 42] -100 to [69, 29, 585, 42] -100 the [69, 29, 585, 42] -100 consolida [69, 29, 585, 42] -100 ted [69, 29, 585, 42] -100 financial [69, 29, 585, 42] -100 statement [69, 29, 585, 42] -100 s [69, 29, 585, 42] -100 of [69, 29, 585, 42] -100 A [69, 29, 585, 42] -100 ego [69, 29, 585, 42] -100 n [69, 29, 585, 42] -100 N [69, 29, 585, 42] -100 . [69, 29, 585, 42] -100 V [69, 29, 585, 42] -100 . [69, 29, 585, 42] -100 Note [69, 29, 585, 42] Page-header s [69, 29, 585, 42] -100 to [69, 29, 585, 42] -100 the [69, 29, 585, 42] -100 consolida [69, 29, 585, 42] -100 ted [69, 29, 585, 42] -100 financial [69, 29, 585, 42] -100 statement [69, 29, 585, 42] -100 s [69, 29, 585, 42] -100 of [69, 29, 585, 42] -100 A [69, 29, 585, 42] -100 ego [69, 29, 585, 42] -100 n [69, 29, 585, 42] -100 N [69, 29, 585, 42] -100 . [69, 29, 585, 42] -100 V [69, 29, 585, 42] -100 . [69, 29, 585, 42] -100 50 [116, 95, 793, 109] Section-header 50 [116, 95, 793, 109] Section-header The [116, 113, 867, 154] Text table [116, 113, 867, 154] -100 that [116, 113, 867, 154] -100 follow [116, 113, 867, 154] -100 s [116, 113, 867, 154] -100 summa [116, 113, 867, 154] -100 riz [116, 113, 867, 154] -100 es [116, 113, 867, 154] -100 the [116, 113, 867, 154] -100 carry [116, 113, 867, 154] -100 ing [116, 113, 867, 154] -100 amount [116, 113, 867, 154] -100 s [116, 113, 867, 154] -100 of [116, 113, 867, 154] -100 financial [116, 113, 867, 154] -100 assets [116, 113, 867, 154] -100 and [116, 113, 867, 154] -100 financial [116, 113, 867, 154] -100 li [116, 113, 867, 154] -100 abili [116, 113, 867, 154] -100 ties [116, 113, 867, 154] -100 that [116, 113, 867, 154] -100 are [116, 113, 867, 154] -100 class [116, 113, 867, 154] -100 ified [116, 113, 867, 154] -100 as [116, 113, 867, 154] -100 at [116, 113, 867, 154] -100 fair [116, 113, 867, 154] -100 value [116, 113, 867, 154] -100 The [116, 113, 867, 154] Text table [116, 113, 867, 154] -100 that [116, 113, 867, 154] -100 follow [116, 113, 867, 154] -100 s [116, 113, 867, 154] -100 summa [116, 113, 867, 154] -100 riz [116, 113, 867, 154] -100 es [116, 113, 867, 154] -100 the [116, 113, 867, 154] -100 carry [116, 113, 867, 154] -100 ing [116, 113, 867, 154] -100 amount [116, 113, 867, 154] -100 s [116, 113, 867, 154] -100 of [116, 113, 867, 154] -100 financial [116, 113, 867, 154] -100 assets [116, 113, 867, 154] -100 and [116, 113, 867, 154] -100 financial [116, 113, 867, 154] -100 li [116, 113, 867, 154] -100 abili [116, 113, 867, 154] -100 ties [116, 113, 867, 154] -100 that [116, 113, 867, 154] -100 are [116, 113, 867, 154] -100 class [116, 113, 867, 154] -100 ified [116, 113, 867, 154] -100 as [116, 113, 867, 154] -100 at [116, 113, 867, 154] -100 fair [116, 113, 867, 154] -100 value [116, 113, 867, 154] -100 The [116, 113, 867, 154] Text table [116, 113, 867, 154] -100 that [116, 113, 867, 154] -100 follow [116, 113, 867, 154] -100 s [116, 113, 867, 154] -100 summa [116, 113, 867, 154] -100 riz [116, 113, 867, 154] -100 es [116, 113, 867, 154] -100 the [116, 113, 867, 154] -100 carry [116, 113, 867, 154] -100 ing [116, 113, 867, 154] -100 amount [116, 113, 867, 154] -100 s [116, 113, 867, 154] -100 of [116, 113, 867, 154] -100 financial [116, 113, 867, 154] -100 assets [116, 113, 867, 154] -100 and [116, 113, 867, 154] -100 financial [116, 113, 867, 154] -100 li [116, 113, 867, 154] -100 abili [116, 113, 867, 154] -100 ties [116, 113, 867, 154] -100 that [116, 113, 867, 154] -100 are [116, 113, 867, 154] -100 class [116, 113, 867, 154] -100 ified [116, 113, 867, 154] -100 as [116, 113, 867, 154] -100 at [116, 113, 867, 154] -100 fair [116, 113, 867, 154] -100 value [116, 113, 867, 154] -100 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table 2013 [113, 173, 880, 331] Table Investment [116, 354, 322, 366] Section-header s [116, 354, 322, 366] -100 for [116, 354, 322, 366] -100 general [116, 354, 322, 366] -100 account [116, 354, 322, 366] -100 The [116, 370, 865, 441] Text Group [116, 370, 865, 441] -100 manage [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 certain [116, 370, 865, 441] -100 portfolio [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 on [116, 370, 865, 441] -100 a [116, 370, 865, 441] -100 total [116, 370, 865, 441] -100 return [116, 370, 865, 441] -100 basis [116, 370, 865, 441] -100 which [116, 370, 865, 441] -100 have [116, 370, 865, 441] -100 been [116, 370, 865, 441] -100 design [116, 370, 865, 441] -100 ated [116, 370, 865, 441] -100 at [116, 370, 865, 441] -100 fair [116, 370, 865, 441] -100 value [116, 370, 865, 441] -100 through [116, 370, 865, 441] -100 profit [116, 370, 865, 441] -100 or [116, 370, 865, 441] -100 loss [116, 370, 865, 441] -100 . [116, 370, 865, 441] -100 The [116, 370, 865, 441] Text Group [116, 370, 865, 441] -100 manage [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 certain [116, 370, 865, 441] -100 portfolio [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 on [116, 370, 865, 441] -100 a [116, 370, 865, 441] -100 total [116, 370, 865, 441] -100 return [116, 370, 865, 441] -100 basis [116, 370, 865, 441] -100 which [116, 370, 865, 441] -100 have [116, 370, 865, 441] -100 been [116, 370, 865, 441] -100 design [116, 370, 865, 441] -100 ated [116, 370, 865, 441] -100 at [116, 370, 865, 441] -100 fair [116, 370, 865, 441] -100 value [116, 370, 865, 441] -100 through [116, 370, 865, 441] -100 profit [116, 370, 865, 441] -100 or [116, 370, 865, 441] -100 loss [116, 370, 865, 441] -100 . [116, 370, 865, 441] -100 The [116, 370, 865, 441] Text Group [116, 370, 865, 441] -100 manage [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 certain [116, 370, 865, 441] -100 portfolio [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 on [116, 370, 865, 441] -100 a [116, 370, 865, 441] -100 total [116, 370, 865, 441] -100 return [116, 370, 865, 441] -100 basis [116, 370, 865, 441] -100 which [116, 370, 865, 441] -100 have [116, 370, 865, 441] -100 been [116, 370, 865, 441] -100 design [116, 370, 865, 441] -100 ated [116, 370, 865, 441] -100 at [116, 370, 865, 441] -100 fair [116, 370, 865, 441] -100 value [116, 370, 865, 441] -100 through [116, 370, 865, 441] -100 profit [116, 370, 865, 441] -100 or [116, 370, 865, 441] -100 loss [116, 370, 865, 441] -100 . [116, 370, 865, 441] -100 The [116, 370, 865, 441] Text Group [116, 370, 865, 441] -100 manage [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 certain [116, 370, 865, 441] -100 portfolio [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 on [116, 370, 865, 441] -100 a [116, 370, 865, 441] -100 total [116, 370, 865, 441] -100 return [116, 370, 865, 441] -100 basis [116, 370, 865, 441] -100 which [116, 370, 865, 441] -100 have [116, 370, 865, 441] -100 been [116, 370, 865, 441] -100 design [116, 370, 865, 441] -100 ated [116, 370, 865, 441] -100 at [116, 370, 865, 441] -100 fair [116, 370, 865, 441] -100 value [116, 370, 865, 441] -100 through [116, 370, 865, 441] -100 profit [116, 370, 865, 441] -100 or [116, 370, 865, 441] -100 loss [116, 370, 865, 441] -100 . [116, 370, 865, 441] -100 The [116, 370, 865, 441] Text Group [116, 370, 865, 441] -100 manage [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 certain [116, 370, 865, 441] -100 portfolio [116, 370, 865, 441] -100 s [116, 370, 865, 441] -100 on [116, 370, 865, 441] -100 a [116, 370, 865, 441] -100 total [116, 370, 865, 441] -100 return [116, 370, 865, 441] -100 basis [116, 370, 865, 441] -100 which [116, 370, 865, 441] -100 have [116, 370, 865, 441] -100 been [116, 370, 865, 441] -100 design [116, 370, 865, 441] -100 ated [116, 370, 865, 441] -100 at [116, 370, 865, 441] -100 fair [116, 370, 865, 441] -100 value [116, 370, 865, 441] -100 through [116, 370, 865, 441] -100 profit [116, 370, 865, 441] -100 or [116, 370, 865, 441] -100 loss [116, 370, 865, 441] -100 . [116, 370, 865, 441] -100 Investment [116, 461, 880, 532] Text s [116, 461, 880, 532] -100 for [116, 461, 880, 532] -100 general [116, 461, 880, 532] -100 account [116, 461, 880, 532] -100 back [116, 461, 880, 532] -100 ing [116, 461, 880, 532] -100 insurance [116, 461, 880, 532] -100 and [116, 461, 880, 532] -100 investment [116, 461, 880, 532] -100 li [116, 461, 880, 532] -100 abili [116, 461, 880, 532] -100 ties [116, 461, 880, 532] -100 , [116, 461, 880, 532] -100 that [116, 461, 880, 532] -100 are [116, 461, 880, 532] -100 carried [116, 461, 880, 532] -100 at [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 value [116, 461, 880, 532] -100 with [116, 461, 880, 532] -100 changes [116, 461, 880, 532] -100 in [116, 461, 880, 532] -100 the [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 Investment [116, 461, 880, 532] Text s [116, 461, 880, 532] -100 for [116, 461, 880, 532] -100 general [116, 461, 880, 532] -100 account [116, 461, 880, 532] -100 back [116, 461, 880, 532] -100 ing [116, 461, 880, 532] -100 insurance [116, 461, 880, 532] -100 and [116, 461, 880, 532] -100 investment [116, 461, 880, 532] -100 li [116, 461, 880, 532] -100 abili [116, 461, 880, 532] -100 ties [116, 461, 880, 532] -100 , [116, 461, 880, 532] -100 that [116, 461, 880, 532] -100 are [116, 461, 880, 532] -100 carried [116, 461, 880, 532] -100 at [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 value [116, 461, 880, 532] -100 with [116, 461, 880, 532] -100 changes [116, 461, 880, 532] -100 in [116, 461, 880, 532] -100 the [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 Investment [116, 461, 880, 532] Text s [116, 461, 880, 532] -100 for [116, 461, 880, 532] -100 general [116, 461, 880, 532] -100 account [116, 461, 880, 532] -100 back [116, 461, 880, 532] -100 ing [116, 461, 880, 532] -100 insurance [116, 461, 880, 532] -100 and [116, 461, 880, 532] -100 investment [116, 461, 880, 532] -100 li [116, 461, 880, 532] -100 abili [116, 461, 880, 532] -100 ties [116, 461, 880, 532] -100 , [116, 461, 880, 532] -100 that [116, 461, 880, 532] -100 are [116, 461, 880, 532] -100 carried [116, 461, 880, 532] -100 at [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 value [116, 461, 880, 532] -100 with [116, 461, 880, 532] -100 changes [116, 461, 880, 532] -100 in [116, 461, 880, 532] -100 the [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 Investment [116, 461, 880, 532] Text s [116, 461, 880, 532] -100 for [116, 461, 880, 532] -100 general [116, 461, 880, 532] -100 account [116, 461, 880, 532] -100 back [116, 461, 880, 532] -100 ing [116, 461, 880, 532] -100 insurance [116, 461, 880, 532] -100 and [116, 461, 880, 532] -100 investment [116, 461, 880, 532] -100 li [116, 461, 880, 532] -100 abili [116, 461, 880, 532] -100 ties [116, 461, 880, 532] -100 , [116, 461, 880, 532] -100 that [116, 461, 880, 532] -100 are [116, 461, 880, 532] -100 carried [116, 461, 880, 532] -100 at [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 value [116, 461, 880, 532] -100 with [116, 461, 880, 532] -100 changes [116, 461, 880, 532] -100 in [116, 461, 880, 532] -100 the [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 Investment [116, 461, 880, 532] Text s [116, 461, 880, 532] -100 for [116, 461, 880, 532] -100 general [116, 461, 880, 532] -100 account [116, 461, 880, 532] -100 back [116, 461, 880, 532] -100 ing [116, 461, 880, 532] -100 insurance [116, 461, 880, 532] -100 and [116, 461, 880, 532] -100 investment [116, 461, 880, 532] -100 li [116, 461, 880, 532] -100 abili [116, 461, 880, 532] -100 ties [116, 461, 880, 532] -100 , [116, 461, 880, 532] -100 that [116, 461, 880, 532] -100 are [116, 461, 880, 532] -100 carried [116, 461, 880, 532] -100 at [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 value [116, 461, 880, 532] -100 with [116, 461, 880, 532] -100 changes [116, 461, 880, 532] -100 in [116, 461, 880, 532] -100 the [116, 461, 880, 532] -100 fair [116, 461, 880, 532] -100 Investment [116, 550, 377, 562] Section-header s [116, 550, 377, 562] -100 for [116, 550, 377, 562] -100 account [116, 550, 377, 562] -100 of [116, 550, 377, 562] -100 policy [116, 550, 377, 562] -100 holder [116, 550, 377, 562] -100 s [116, 550, 377, 562] -100 Investment [116, 566, 861, 623] Text s [116, 566, 861, 623] -100 held [116, 566, 861, 623] -100 for [116, 566, 861, 623] -100 account [116, 566, 861, 623] -100 of [116, 566, 861, 623] -100 policy [116, 566, 861, 623] -100 holder [116, 566, 861, 623] -100 s [116, 566, 861, 623] -100 compris [116, 566, 861, 623] -100 e [116, 566, 861, 623] -100 assets [116, 566, 861, 623] -100 that [116, 566, 861, 623] -100 are [116, 566, 861, 623] -100 link [116, 566, 861, 623] -100 ed [116, 566, 861, 623] -100 to [116, 566, 861, 623] -100 various [116, 566, 861, 623] -100 insurance [116, 566, 861, 623] -100 and [116, 566, 861, 623] -100 investment [116, 566, 861, 623] -100 contract [116, 566, 861, 623] -100 s [116, 566, 861, 623] -100 for [116, 566, 861, 623] -100 Investment [116, 566, 861, 623] Text s [116, 566, 861, 623] -100 held [116, 566, 861, 623] -100 for [116, 566, 861, 623] -100 account [116, 566, 861, 623] -100 of [116, 566, 861, 623] -100 policy [116, 566, 861, 623] -100 holder [116, 566, 861, 623] -100 s [116, 566, 861, 623] -100 compris [116, 566, 861, 623] -100 e [116, 566, 861, 623] -100 assets [116, 566, 861, 623] -100 that [116, 566, 861, 623] -100 are [116, 566, 861, 623] -100 link [116, 566, 861, 623] -100 ed [116, 566, 861, 623] -100 to [116, 566, 861, 623] -100 various [116, 566, 861, 623] -100 insurance [116, 566, 861, 623] -100 and [116, 566, 861, 623] -100 investment [116, 566, 861, 623] -100 contract [116, 566, 861, 623] -100 s [116, 566, 861, 623] -100 for [116, 566, 861, 623] -100 Investment [116, 566, 861, 623] Text s [116, 566, 861, 623] Text held [116, 566, 861, 623] Text for [116, 566, 861, 623] Text account [116, 566, 861, 623] Text of [116, 566, 861, 623] Text policy [116, 566, 861, 623] Text holder [116, 566, 861, 623] Text s [116, 566, 861, 623] Text compris [116, 566, 861, 623] Text e [116, 566, 861, 623] Text assets [116, 566, 861, 623] Text that [116, 566, 861, 623] Text </s> [0, 0, 0, 0] -100
Define PyTorch DataLoader¶
import torch
from torch.utils.data import DataLoader
def collate_fn(features):
boxes = [feature["bbox"] for feature in features]
labels = [feature["labels"] for feature in features]
# use tokenizer to pad input_ids
batch = tokenizer.pad(features, padding="max_length", max_length=max_length)
sequence_length = torch.tensor(batch["input_ids"]).shape[1]
batch["labels"] = [labels_example + [-100] * (sequence_length - len(labels_example)) for labels_example in labels]
batch["bbox"] = [boxes_example + [[0, 0, 0, 0]] * (sequence_length - len(boxes_example)) for boxes_example in boxes]
# convert to PyTorch
# batch = {k: torch.tensor(v, dtype=torch.int64) if isinstance(v[0], list) else v for k, v in batch.items()}
batch = {k: torch.tensor(v) for k, v in batch.items()}
return batch
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_fn)
batch = next(iter(train_dataloader))
You're using a XLMRobertaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
for k,v in batch.items():
print(k,v.shape)
input_ids torch.Size([8, 512]) attention_mask torch.Size([8, 512]) bbox torch.Size([8, 512, 4]) labels torch.Size([8, 512])
for id, box, label in zip(batch["input_ids"][0], batch["bbox"][0], batch["labels"][0]):
if label.item() != -100:
print(tokenizer.decode([id]), box, id2label[label.item()])
else:
print(tokenizer.decode([id]), box)
<s> tensor([0, 0, 0, 0]) Note tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) to tensor([ 69, 29, 585, 42]) the tensor([ 69, 29, 585, 42]) consolida tensor([ 69, 29, 585, 42]) ted tensor([ 69, 29, 585, 42]) financial tensor([ 69, 29, 585, 42]) statement tensor([ 69, 29, 585, 42]) s tensor([ 69, 29, 585, 42]) of tensor([ 69, 29, 585, 42]) A tensor([ 69, 29, 585, 42]) ego tensor([ 69, 29, 585, 42]) n tensor([ 69, 29, 585, 42]) N tensor([ 69, 29, 585, 42]) . tensor([ 69, 29, 585, 42]) V tensor([ 69, 29, 585, 42]) . tensor([ 69, 29, 585, 42]) Note tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) to tensor([ 69, 29, 585, 42]) the tensor([ 69, 29, 585, 42]) consolida tensor([ 69, 29, 585, 42]) ted tensor([ 69, 29, 585, 42]) financial tensor([ 69, 29, 585, 42]) statement tensor([ 69, 29, 585, 42]) s tensor([ 69, 29, 585, 42]) of tensor([ 69, 29, 585, 42]) A tensor([ 69, 29, 585, 42]) ego tensor([ 69, 29, 585, 42]) n tensor([ 69, 29, 585, 42]) N tensor([ 69, 29, 585, 42]) . tensor([ 69, 29, 585, 42]) V tensor([ 69, 29, 585, 42]) . tensor([ 69, 29, 585, 42]) Note tensor([ 69, 29, 585, 42]) Page-header s tensor([ 69, 29, 585, 42]) to tensor([ 69, 29, 585, 42]) the tensor([ 69, 29, 585, 42]) consolida tensor([ 69, 29, 585, 42]) ted tensor([ 69, 29, 585, 42]) financial tensor([ 69, 29, 585, 42]) statement tensor([ 69, 29, 585, 42]) s tensor([ 69, 29, 585, 42]) of tensor([ 69, 29, 585, 42]) A tensor([ 69, 29, 585, 42]) ego tensor([ 69, 29, 585, 42]) n tensor([ 69, 29, 585, 42]) N tensor([ 69, 29, 585, 42]) . tensor([ 69, 29, 585, 42]) V tensor([ 69, 29, 585, 42]) . tensor([ 69, 29, 585, 42]) 50 tensor([116, 95, 793, 109]) Section-header 50 tensor([116, 95, 793, 109]) Section-header The tensor([116, 113, 867, 154]) Text table tensor([116, 113, 867, 154]) that tensor([116, 113, 867, 154]) follow tensor([116, 113, 867, 154]) s tensor([116, 113, 867, 154]) summa tensor([116, 113, 867, 154]) riz tensor([116, 113, 867, 154]) es tensor([116, 113, 867, 154]) the tensor([116, 113, 867, 154]) carry tensor([116, 113, 867, 154]) ing tensor([116, 113, 867, 154]) amount tensor([116, 113, 867, 154]) s tensor([116, 113, 867, 154]) of tensor([116, 113, 867, 154]) financial tensor([116, 113, 867, 154]) assets tensor([116, 113, 867, 154]) and tensor([116, 113, 867, 154]) financial tensor([116, 113, 867, 154]) li tensor([116, 113, 867, 154]) abili tensor([116, 113, 867, 154]) ties tensor([116, 113, 867, 154]) that tensor([116, 113, 867, 154]) are tensor([116, 113, 867, 154]) class tensor([116, 113, 867, 154]) ified tensor([116, 113, 867, 154]) as tensor([116, 113, 867, 154]) at tensor([116, 113, 867, 154]) fair tensor([116, 113, 867, 154]) value tensor([116, 113, 867, 154]) The tensor([116, 113, 867, 154]) Text table tensor([116, 113, 867, 154]) that tensor([116, 113, 867, 154]) follow tensor([116, 113, 867, 154]) s tensor([116, 113, 867, 154]) summa tensor([116, 113, 867, 154]) riz tensor([116, 113, 867, 154]) es tensor([116, 113, 867, 154]) the tensor([116, 113, 867, 154]) carry tensor([116, 113, 867, 154]) ing tensor([116, 113, 867, 154]) amount tensor([116, 113, 867, 154]) s tensor([116, 113, 867, 154]) of tensor([116, 113, 867, 154]) financial tensor([116, 113, 867, 154]) assets tensor([116, 113, 867, 154]) and tensor([116, 113, 867, 154]) financial tensor([116, 113, 867, 154]) li tensor([116, 113, 867, 154]) abili tensor([116, 113, 867, 154]) ties tensor([116, 113, 867, 154]) that tensor([116, 113, 867, 154]) are tensor([116, 113, 867, 154]) class tensor([116, 113, 867, 154]) ified tensor([116, 113, 867, 154]) as tensor([116, 113, 867, 154]) at tensor([116, 113, 867, 154]) fair tensor([116, 113, 867, 154]) value tensor([116, 113, 867, 154]) The tensor([116, 113, 867, 154]) Text table tensor([116, 113, 867, 154]) that tensor([116, 113, 867, 154]) follow tensor([116, 113, 867, 154]) s tensor([116, 113, 867, 154]) summa tensor([116, 113, 867, 154]) riz tensor([116, 113, 867, 154]) es tensor([116, 113, 867, 154]) the tensor([116, 113, 867, 154]) carry tensor([116, 113, 867, 154]) ing tensor([116, 113, 867, 154]) amount tensor([116, 113, 867, 154]) s tensor([116, 113, 867, 154]) of tensor([116, 113, 867, 154]) financial tensor([116, 113, 867, 154]) assets tensor([116, 113, 867, 154]) and tensor([116, 113, 867, 154]) financial tensor([116, 113, 867, 154]) li tensor([116, 113, 867, 154]) abili tensor([116, 113, 867, 154]) ties tensor([116, 113, 867, 154]) that tensor([116, 113, 867, 154]) are tensor([116, 113, 867, 154]) class tensor([116, 113, 867, 154]) ified tensor([116, 113, 867, 154]) as tensor([116, 113, 867, 154]) at tensor([116, 113, 867, 154]) fair tensor([116, 113, 867, 154]) value tensor([116, 113, 867, 154]) 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table 2013 tensor([113, 173, 880, 331]) Table Investment tensor([116, 354, 322, 366]) Section-header s tensor([116, 354, 322, 366]) for tensor([116, 354, 322, 366]) general tensor([116, 354, 322, 366]) account tensor([116, 354, 322, 366]) The tensor([116, 370, 865, 441]) Text Group tensor([116, 370, 865, 441]) manage tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) certain tensor([116, 370, 865, 441]) portfolio tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) on tensor([116, 370, 865, 441]) a tensor([116, 370, 865, 441]) total tensor([116, 370, 865, 441]) return tensor([116, 370, 865, 441]) basis tensor([116, 370, 865, 441]) which tensor([116, 370, 865, 441]) have tensor([116, 370, 865, 441]) been tensor([116, 370, 865, 441]) design tensor([116, 370, 865, 441]) ated tensor([116, 370, 865, 441]) at tensor([116, 370, 865, 441]) fair tensor([116, 370, 865, 441]) value tensor([116, 370, 865, 441]) through tensor([116, 370, 865, 441]) profit tensor([116, 370, 865, 441]) or tensor([116, 370, 865, 441]) loss tensor([116, 370, 865, 441]) . tensor([116, 370, 865, 441]) The tensor([116, 370, 865, 441]) Text Group tensor([116, 370, 865, 441]) manage tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) certain tensor([116, 370, 865, 441]) portfolio tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) on tensor([116, 370, 865, 441]) a tensor([116, 370, 865, 441]) total tensor([116, 370, 865, 441]) return tensor([116, 370, 865, 441]) basis tensor([116, 370, 865, 441]) which tensor([116, 370, 865, 441]) have tensor([116, 370, 865, 441]) been tensor([116, 370, 865, 441]) design tensor([116, 370, 865, 441]) ated tensor([116, 370, 865, 441]) at tensor([116, 370, 865, 441]) fair tensor([116, 370, 865, 441]) value tensor([116, 370, 865, 441]) through tensor([116, 370, 865, 441]) profit tensor([116, 370, 865, 441]) or tensor([116, 370, 865, 441]) loss tensor([116, 370, 865, 441]) . tensor([116, 370, 865, 441]) The tensor([116, 370, 865, 441]) Text Group tensor([116, 370, 865, 441]) manage tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) certain tensor([116, 370, 865, 441]) portfolio tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) on tensor([116, 370, 865, 441]) a tensor([116, 370, 865, 441]) total tensor([116, 370, 865, 441]) return tensor([116, 370, 865, 441]) basis tensor([116, 370, 865, 441]) which tensor([116, 370, 865, 441]) have tensor([116, 370, 865, 441]) been tensor([116, 370, 865, 441]) design tensor([116, 370, 865, 441]) ated tensor([116, 370, 865, 441]) at tensor([116, 370, 865, 441]) fair tensor([116, 370, 865, 441]) value tensor([116, 370, 865, 441]) through tensor([116, 370, 865, 441]) profit tensor([116, 370, 865, 441]) or tensor([116, 370, 865, 441]) loss tensor([116, 370, 865, 441]) . tensor([116, 370, 865, 441]) The tensor([116, 370, 865, 441]) Text Group tensor([116, 370, 865, 441]) manage tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) certain tensor([116, 370, 865, 441]) portfolio tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) on tensor([116, 370, 865, 441]) a tensor([116, 370, 865, 441]) total tensor([116, 370, 865, 441]) return tensor([116, 370, 865, 441]) basis tensor([116, 370, 865, 441]) which tensor([116, 370, 865, 441]) have tensor([116, 370, 865, 441]) been tensor([116, 370, 865, 441]) design tensor([116, 370, 865, 441]) ated tensor([116, 370, 865, 441]) at tensor([116, 370, 865, 441]) fair tensor([116, 370, 865, 441]) value tensor([116, 370, 865, 441]) through tensor([116, 370, 865, 441]) profit tensor([116, 370, 865, 441]) or tensor([116, 370, 865, 441]) loss tensor([116, 370, 865, 441]) . tensor([116, 370, 865, 441]) The tensor([116, 370, 865, 441]) Text Group tensor([116, 370, 865, 441]) manage tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) certain tensor([116, 370, 865, 441]) portfolio tensor([116, 370, 865, 441]) s tensor([116, 370, 865, 441]) on tensor([116, 370, 865, 441]) a tensor([116, 370, 865, 441]) total tensor([116, 370, 865, 441]) return tensor([116, 370, 865, 441]) basis tensor([116, 370, 865, 441]) which tensor([116, 370, 865, 441]) have tensor([116, 370, 865, 441]) been tensor([116, 370, 865, 441]) design tensor([116, 370, 865, 441]) ated tensor([116, 370, 865, 441]) at tensor([116, 370, 865, 441]) fair tensor([116, 370, 865, 441]) value tensor([116, 370, 865, 441]) through tensor([116, 370, 865, 441]) profit tensor([116, 370, 865, 441]) or tensor([116, 370, 865, 441]) loss tensor([116, 370, 865, 441]) . tensor([116, 370, 865, 441]) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) for tensor([116, 461, 880, 532]) general tensor([116, 461, 880, 532]) account tensor([116, 461, 880, 532]) back tensor([116, 461, 880, 532]) ing tensor([116, 461, 880, 532]) insurance tensor([116, 461, 880, 532]) and tensor([116, 461, 880, 532]) investment tensor([116, 461, 880, 532]) li tensor([116, 461, 880, 532]) abili tensor([116, 461, 880, 532]) ties tensor([116, 461, 880, 532]) , tensor([116, 461, 880, 532]) that tensor([116, 461, 880, 532]) are tensor([116, 461, 880, 532]) carried tensor([116, 461, 880, 532]) at tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) value tensor([116, 461, 880, 532]) with tensor([116, 461, 880, 532]) changes tensor([116, 461, 880, 532]) in tensor([116, 461, 880, 532]) the tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) for tensor([116, 461, 880, 532]) general tensor([116, 461, 880, 532]) account tensor([116, 461, 880, 532]) back tensor([116, 461, 880, 532]) ing tensor([116, 461, 880, 532]) insurance tensor([116, 461, 880, 532]) and tensor([116, 461, 880, 532]) investment tensor([116, 461, 880, 532]) li tensor([116, 461, 880, 532]) abili tensor([116, 461, 880, 532]) ties tensor([116, 461, 880, 532]) , tensor([116, 461, 880, 532]) that tensor([116, 461, 880, 532]) are tensor([116, 461, 880, 532]) carried tensor([116, 461, 880, 532]) at tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) value tensor([116, 461, 880, 532]) with tensor([116, 461, 880, 532]) changes tensor([116, 461, 880, 532]) in tensor([116, 461, 880, 532]) the tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) for tensor([116, 461, 880, 532]) general tensor([116, 461, 880, 532]) account tensor([116, 461, 880, 532]) back tensor([116, 461, 880, 532]) ing tensor([116, 461, 880, 532]) insurance tensor([116, 461, 880, 532]) and tensor([116, 461, 880, 532]) investment tensor([116, 461, 880, 532]) li tensor([116, 461, 880, 532]) abili tensor([116, 461, 880, 532]) ties tensor([116, 461, 880, 532]) , tensor([116, 461, 880, 532]) that tensor([116, 461, 880, 532]) are tensor([116, 461, 880, 532]) carried tensor([116, 461, 880, 532]) at tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) value tensor([116, 461, 880, 532]) with tensor([116, 461, 880, 532]) changes tensor([116, 461, 880, 532]) in tensor([116, 461, 880, 532]) the tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) for tensor([116, 461, 880, 532]) general tensor([116, 461, 880, 532]) account tensor([116, 461, 880, 532]) back tensor([116, 461, 880, 532]) ing tensor([116, 461, 880, 532]) insurance tensor([116, 461, 880, 532]) and tensor([116, 461, 880, 532]) investment tensor([116, 461, 880, 532]) li tensor([116, 461, 880, 532]) abili tensor([116, 461, 880, 532]) ties tensor([116, 461, 880, 532]) , tensor([116, 461, 880, 532]) that tensor([116, 461, 880, 532]) are tensor([116, 461, 880, 532]) carried tensor([116, 461, 880, 532]) at tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) value tensor([116, 461, 880, 532]) with tensor([116, 461, 880, 532]) changes tensor([116, 461, 880, 532]) in tensor([116, 461, 880, 532]) the tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) Investment tensor([116, 461, 880, 532]) Text s tensor([116, 461, 880, 532]) for tensor([116, 461, 880, 532]) general tensor([116, 461, 880, 532]) account tensor([116, 461, 880, 532]) back tensor([116, 461, 880, 532]) ing tensor([116, 461, 880, 532]) insurance tensor([116, 461, 880, 532]) and tensor([116, 461, 880, 532]) investment tensor([116, 461, 880, 532]) li tensor([116, 461, 880, 532]) abili tensor([116, 461, 880, 532]) ties tensor([116, 461, 880, 532]) , tensor([116, 461, 880, 532]) that tensor([116, 461, 880, 532]) are tensor([116, 461, 880, 532]) carried tensor([116, 461, 880, 532]) at tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) value tensor([116, 461, 880, 532]) with tensor([116, 461, 880, 532]) changes tensor([116, 461, 880, 532]) in tensor([116, 461, 880, 532]) the tensor([116, 461, 880, 532]) fair tensor([116, 461, 880, 532]) Investment tensor([116, 550, 377, 562]) Section-header s tensor([116, 550, 377, 562]) for tensor([116, 550, 377, 562]) account tensor([116, 550, 377, 562]) of tensor([116, 550, 377, 562]) policy tensor([116, 550, 377, 562]) holder tensor([116, 550, 377, 562]) s tensor([116, 550, 377, 562]) Investment tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) held tensor([116, 566, 861, 623]) for tensor([116, 566, 861, 623]) account tensor([116, 566, 861, 623]) of tensor([116, 566, 861, 623]) policy tensor([116, 566, 861, 623]) holder tensor([116, 566, 861, 623]) s tensor([116, 566, 861, 623]) compris tensor([116, 566, 861, 623]) e tensor([116, 566, 861, 623]) assets tensor([116, 566, 861, 623]) that tensor([116, 566, 861, 623]) are tensor([116, 566, 861, 623]) link tensor([116, 566, 861, 623]) ed tensor([116, 566, 861, 623]) to tensor([116, 566, 861, 623]) various tensor([116, 566, 861, 623]) insurance tensor([116, 566, 861, 623]) and tensor([116, 566, 861, 623]) investment tensor([116, 566, 861, 623]) contract tensor([116, 566, 861, 623]) s tensor([116, 566, 861, 623]) for tensor([116, 566, 861, 623]) Investment tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) held tensor([116, 566, 861, 623]) for tensor([116, 566, 861, 623]) account tensor([116, 566, 861, 623]) of tensor([116, 566, 861, 623]) policy tensor([116, 566, 861, 623]) holder tensor([116, 566, 861, 623]) s tensor([116, 566, 861, 623]) compris tensor([116, 566, 861, 623]) e tensor([116, 566, 861, 623]) assets tensor([116, 566, 861, 623]) that tensor([116, 566, 861, 623]) are tensor([116, 566, 861, 623]) link tensor([116, 566, 861, 623]) ed tensor([116, 566, 861, 623]) to tensor([116, 566, 861, 623]) various tensor([116, 566, 861, 623]) insurance tensor([116, 566, 861, 623]) and tensor([116, 566, 861, 623]) investment tensor([116, 566, 861, 623]) contract tensor([116, 566, 861, 623]) s tensor([116, 566, 861, 623]) for tensor([116, 566, 861, 623]) Investment tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) Text held tensor([116, 566, 861, 623]) Text for tensor([116, 566, 861, 623]) Text account tensor([116, 566, 861, 623]) Text of tensor([116, 566, 861, 623]) Text policy tensor([116, 566, 861, 623]) Text holder tensor([116, 566, 861, 623]) Text s tensor([116, 566, 861, 623]) Text compris tensor([116, 566, 861, 623]) Text e tensor([116, 566, 861, 623]) Text assets tensor([116, 566, 861, 623]) Text that tensor([116, 566, 861, 623]) Text </s> tensor([0, 0, 0, 0])
tokenizer.decode(batch["input_ids"][0])
'<s> Notes to the consolidated financial statements of Aegon N.V. Notes to the consolidated financial statements of Aegon N.V. Notes to the consolidated financial statements of Aegon N.V. 50 50 The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value The table that follows summarizes the carrying amounts of financial assets and financial liabilities that are classified as at fair value 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 2013 Investments for general account The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. The Group manages certain portfolios on a total return basis which have been designated at fair value through profit or loss. Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for general account backing insurance and investment liabilities, that are carried at fair value with changes in the fair Investments for account of policyholders Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for Investments held for account of policyholders comprise assets that are linked to various insurance and investment contracts for Investments held for account of policyholders comprise assets that</s>'
Define model¶
from transformers import LiltForTokenClassification
model = LiltForTokenClassification.from_pretrained("nielsr/lilt-xlm-roberta-base",
id2label=id2label, label2id=label2id, num_labels=num_labels)
Downloading (…)lve/main/config.json: 0%| | 0.00/774 [00:00<?, ?B/s]
Downloading (…)"pytorch_model.bin";: 0%| | 0.00/1.14G [00:00<?, ?B/s]
Some weights of LiltForTokenClassification were not initialized from the model checkpoint at nielsr/lilt-xlm-roberta-base and are newly initialized: ['classifier.weight', 'classifier.bias'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Train the model in native PyTorch¶
Uncomment the code below if you want to train the model just in native PyTorch.
# device = "cuda" if torch.cuda.is_available() else "cpu"
# model.to(device)
# optimizer = torch.optim.AdamW(model.parameters(), lr=5-5)
# model.train()
# for epoch in range(2):
# for batch in train_dataloader:
# # zero the parameter gradients
# optimizer.zero_grad()
# inputs = {k:v.to(device) for k,v in batch.items()}
# outputs = model(**inputs)
# loss = outputs.loss
# loss.backward()
# optimizer.step()
Train the model using 🤗 Trainer¶
We first define a compute_metrics function as well as TrainingArguments.
WARNING: we did change the function compute_metrics from the notebook Fine_tune_LiLT_on_a_custom_dataset_in_any_language.ipynb of Niels ROGGE but we recommand not to do it.
Check our notebook Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap) to get the right code (check the code of the function prepare_features(), too).
# import evaluate
# metric = evaluate.load("seqeval")
# import numpy as np
# from seqeval.metrics import classification_report
# return_entity_level_metrics = False
# def compute_metrics(p):
# predictions, labels = p
# predictions = np.argmax(predictions, axis=2)
# # Remove ignored index (special tokens)
# true_predictions = [
# [label_list[p] for (p, l) in zip(prediction, label) if l != -100]
# for prediction, label in zip(predictions, labels)
# ]
# true_labels = [
# [label_list[l] for (p, l) in zip(prediction, label) if l != -100]
# for prediction, label in zip(predictions, labels)
# ]
# results = metric.compute(predictions=true_predictions, references=true_labels)
# if return_entity_level_metrics:
# # Unpack nested dictionaries
# final_results = {}
# for key, value in results.items():
# if isinstance(value, dict):
# for n, v in value.items():
# final_results[f"{key}_{n}"] = v
# else:
# final_results[key] = value
# return final_results
# else:
# return {
# "precision": results["overall_precision"],
# "recall": results["overall_recall"],
# "f1": results["overall_f1"],
# "accuracy": results["overall_accuracy"],
# }
import evaluate
# metric = evaluate.load("seqeval")
precision_metric = evaluate.load("precision")
recall_metric = evaluate.load("recall")
f1_metric = evaluate.load("f1")
accuracy_metric = evaluate.load("accuracy")
Downloading builder script: 0%| | 0.00/7.55k [00:00<?, ?B/s]
Downloading builder script: 0%| | 0.00/7.36k [00:00<?, ?B/s]
Downloading builder script: 0%| | 0.00/6.77k [00:00<?, ?B/s]
Downloading builder script: 0%| | 0.00/4.20k [00:00<?, ?B/s]
# source: https://discuss.huggingface.co/t/combining-metrics-for-multiclass-predictions-evaluations/21792/11
import numpy as np
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label2id[label_list[p]] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label2id[label_list[l]] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
# flat list
true_predictions = [item for sublist in true_predictions for item in sublist]
true_labels = [item for sublist in true_labels for item in sublist]
results = {}
results.update(precision_metric.compute(predictions = true_predictions, references = true_labels, average="micro"))
results.update(recall_metric.compute(predictions = true_predictions, references = true_labels, average="micro"))
results.update(f1_metric.compute(predictions = true_predictions, references = true_labels, average="micro"))
results.update(accuracy_metric.compute(predictions = true_predictions, references = true_labels))
return results
# delete repo if exists
try:
from huggingface_hub import HfApi
HfApi().delete_repo(hub_model_id)
except:
print("Repository Not Found.")
else:
print(f"The following repository was deleted: https://huggingface.co/{hub_model_id}")
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(output_dir=output_dir, # name of directory to store the checkpoints
hub_model_id=hub_model_id, # name of directory to store the finetuned model in HF hub
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
evaluation_strategy=evaluation_strategy,
eval_steps=eval_steps,
save_steps=save_steps, # eval_steps
save_total_limit=save_total_limit,
load_best_model_at_end=load_best_model_at_end,
metric_for_best_model=metric_for_best_model,
report_to=report_to,
fp16=fp16,
push_to_hub=push_to_hub, # we'd like to push our model to the hub during training
hub_private_repo=hub_private_repo,
hub_strategy=hub_strategy
)
Next we define a custom Trainer which uses the DataLoaders we created above.
from transformers.data.data_collator import default_data_collator
class CustomTrainer(Trainer):
def get_train_dataloader(self):
return train_dataloader
def get_eval_dataloader(self, eval_dataset = None):
return eval_dataloader
# Initialize our Trainer
trainer = CustomTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
# callbacks=[ShuffleCallback()] if streaming else None
)
trainer.train()
# If occured an erro, train again from a checkpoint
# trainer.train(resume_from_checkpoint="parh_to_checkpoint/checkpoint-xxxx")
To compute metrics on the test set, we can run trainer.predict(). We get predictions, labels, and metrics back.
predictions, labels, metrics = trainer.predict(test_dataset)
print(metrics)
Push to HF¶
trainer.push_to_hub()