Mis notas: Machine Learning con Scikit-Learn
- 0 Intro
- 1 Estimator API
- 2 Validación del modelo
- 3 Ingeniería de características (Feature Engineering)
Disclaimer: Este notebook contiene mis notas sobre Machine Learning con Scikit-Learn, resumiendo básicamente el capítulo 5 de Python Data Science Handbook escrito por Jake VanderPlas. Recomiendo leer la fuente original e ir ejecutando todos los ejemplos (___learn by doing!___).
Intro¶
Scikit-Learn es un paquete para la implementación de Machine Learning en Python, construido sobre NumPy, Scipy y Matplotlib.
La manera más apropiada de pensar en datos dentro de Scikit-learn es usando tablas. Una tabla básica de dos dimensiones contará con las distintas muestras (samples) del dataset en filas, y los atributos (features) como columnas. Es lo que se conoce como la matriz de características X, y suele estar contenida en un array de NumPy, un DataFrame de Pandas o una matriz de SciPy.
Las muestras son observaciones de cualquier cosa que puede ser descrita por medidas cuantitativas de sus atributos o características.
Aparte de la matriz de características, generalmente trabajaremos con un array unidimensional de etiquetas y, contenido en un array de NumPy o un objeto Series de Pandas, cuya longitud equivale al número de muestras en X (una etiqueta por muestra).
Vemos un ejemplo con el dataset iris incluido con seaborn:
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()
| sepal_length | sepal_width | petal_length | petal_width | species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
Construimos la matriz de características X y el vector de etiquetas y a partir del DataFrame original:
X_iris = iris.drop('species', axis=1)
X_iris.head()
| sepal_length | sepal_width | petal_length | petal_width | |
|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
y_iris = iris['species']
y_iris.head()
0 setosa 1 setosa 2 setosa 3 setosa 4 setosa Name: species, dtype: object
Estimator API¶
La API de Scikit-Learn está diseñada siguiendo unos principios:
- Consistencia: todos los objetos comparten una interfaz común con un conjunto limitado de métodos
- Inspección: todos los valores de parámetros se exponen como atributos públicos
- Jerarquía: los algoritmos son (los únicos) representados por clases; los datasets por arrays de NumPy, dataframes de Pandas o matrices de SciPy, ....
- Composición: Muchas tareas pueden ser expresadas como una secuencia de tareas más sencillas.
Cada algoritmo de Machine Learning está implementado siguiendo estas líneas, componiendo una interfaz consistente. Para usar un algoritmo concreto seguiremos los siguientes pasos:
- Importar la clase de Scikit-Learn con el modelo más adecuado
- Instanciar la clase con los valores deseados para establecer los hiperparámetros del modelo
- Separar los datos en una matriz de características y un vector de etiquetas. Es conveniente separar también en muestras de entrenamiento y muestras de validación.
- Entrenar el modelo para que se ajuste a los datos usando el método
fit(). Si tenemos un subconjunto de validación, lo siguiente es evaluar el modelo para ver si es conveniente modificarlo. - Predecir las etiquetas aplicando el modelo a nuevas muestras:
- Para aprendizaje supervisado predecimos sus etiquetas usando el método
predict() - Para aprendizaje no supervisado normalmente transformamos o inferimos propiedades de los datos usando
transform()ypredict()
Vemos esto a través de ejemplos...
Ejemplo de aprendizaje supervisado: Regresión lineal simple¶
Usamos datos generados por nosotros mismos, que más o menos se ajustan a una recta:
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns; sns.set()
rng = np.random.RandomState(42)
x = 10 * rng.rand(50)
y = 2 * x - 1 + rng.randn(50)
plt.scatter(x, y);

Paso 1: Importamos la clase adecuada para modelar los datos.
from sklearn.linear_model import LinearRegression
Paso 2: Escogemos los hiperparámetros del modelo. Dependiendo del que hayamos elegido tendremos que responder a determinadas preguntas. En este caso vamos a fijar el parámetro fit_intercept a True para que la línea trazada por nuestro modelo no tenga que pasar necesariamente por el punto (0,0); es decir, la intersección con el eje y será determinada por la línea que mejor se ajuste a las muestras.
model = LinearRegression(fit_intercept=True)
model
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None,
normalize=False)
Paso 3: Acomodamos los datos en la matriz de características y el vector de etiquetas. En este caso el segundo ya lo tenemos (y), y para el primero simplemente tenemos que convertir el array unidimensional x en bidimensional.
X = x[:, np.newaxis]
X.shape
(50, 1)
Paso 4: Aplicamos el modelo a los datos y obtenemos la pendiente (el coeficiente lineal) y el corte con el eje (el offset).
model.fit(X, y)
print('model.coef_:', model.coef_)
print('model.intercept_:', model.intercept_)
model.coef_: [1.9776566] model.intercept_: -0.9033107255311164
Paso 5: Predecimos las etiquetas para nuevas muestras, una vez que el modelo ya ha sido entrenado. En este caso tendremos unas observaciones x, y habrá que obtener la predicción para los valores de y.
# Generamos muestras de forma arbitraria
xfit = np.linspace(-1, 11, 50)
# Ajustamos igual que hicimos con x
Xfit = xfit[:, np.newaxis]
# Obtenemos las predicciones
yfit = model.predict(Xfit)
# Visualizamos el resultado (dibujar la línea que une las predicciones es dibujar la recta de regresión)
plt.scatter(x, y)
plt.plot(xfit, yfit);

NOTA: tendríamos que evaluar la eficacia de nuestro modelo (no lo hacemos con este ejemplo puesto que los datos no son reales).
Ejemplo de aprendizaje supervisado: Clasificación¶
Usamos el dataset de iris importado previamente, usando parte de las muestras para entrenamiento y el resto para test. Esto se puede hacer de forma manual, pero usaremos el método train_test_split(). Para el modelo optaremos por aplicar el algoritmo Naive Bayes Gaussiano; muy rápido y sin hiperparámetros a escoger. Se usa para realizar una primera clasificación antes de explorar otras opciones.
Aplicamos los mismos pasos que antes:
from sklearn.model_selection import train_test_split #0
from sklearn.naive_bayes import GaussianNB #1
model = GaussianNB() #2
X_train, X_test, y_train, y_test = train_test_split(X_iris, y_iris, random_state=1) #3
model.fit(X_train, y_train) #4
y_model = model.predict(X_test) #5
Ahora sí podemos evaluar el error. Acudimos al método accuracy_score() para medir la precisión del modelo:
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_model)
0.9736842105263158
Ejemplo de aprendizaje no supervisado: Reducción de la dimensionalidad¶
Aplicaremos reducción de la dimensionalidad al dataset de iris para poder visualizar mejor los datos. En nuestro caso aplicaremos PCA, que es una técnica lineal rápida, para pasar de 4 a 2 dimensiones. Seguiremos los mismos pasos que siempre:
from sklearn.decomposition import PCA #1
model = PCA(n_components=2) #2
model.fit(X_iris) #4
X_2D = model.transform(X_iris) #5 Transformar los datos a 2 dimensiones aplicando el modelo
X_2D.shape
(150, 2)
Comparamos la visualización original con la nueva, y vemos que en la representación bidimensional las especies están bastante bien separadas, a pesar de que PCA no conoce las etiquetas. Esto indica que la clasificación será fácil.
sns.pairplot(iris, hue='species', height=1.5);

# Insertamos los resultados en el DataFrame original
iris['PCA1'] = X_2D[:, 0]
iris['PCA2'] = X_2D[:, 1]
# Visualizamos las 2 dimensiones nuevas
sns.lmplot("PCA1", "PCA2", hue='species', data=iris, fit_reg=False);

Ejemplo de aprendizaje no supervisado: Agrupamiento¶
Aplicaremos clustering al dataset de iris para intentar agrupar los datos sin usar las etiquetas. En nuestro caso usaremos GMM (Gaussian Mixture Model), que intenta modelar los datos como una colección de manchas gaussianas.
from sklearn.mixture import GaussianMixture #1
model = GaussianMixture(n_components=3, covariance_type='full') #2
model.fit(X_iris) #4
y_gmm = model.predict(X_iris) #5
iris['cluster'] = y_gmm
sns.lmplot("PCA1", "PCA2", data=iris, hue='species', col='cluster', fit_reg=False);

Ejemplo: Reconocimiento de dígitos manuscritos¶
Escogemos ahora un problema más interesante de OCR (Optical Character Recognition) para clasificar números escritos a mano. Partiremos del dataset disponible en Scikit-Learn, con datos ya preformateados (1797 muestras de 8x8 píxeles)
from sklearn.datasets import load_digits
digits = load_digits()
digits.images.shape
(1797, 8, 8)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(10, 10, figsize=(8, 8),
subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
for i, ax in enumerate(axes.flat):
ax.imshow(digits.images[i], cmap='binary', interpolation='nearest')
ax.text(0.05, 0.05, str(digits.target[i]),
transform=ax.transAxes, color='green')

Trataremos cada uno de los 64 píxeles asociados a cada caracter como un atributo distinto. Tenemos disponibles la matriz de características en digits.data, y el array de etiquetas en digits.target.
Reducción de la dimensionalidad¶
Para intentar visualizar los datos en 2 dimensiones (en lugar de usar 64), usaremos Isomap (algoritmo de Manifold Learning):
from sklearn.manifold import Isomap #1
iso = Isomap(n_components=2) #2
X = digits.data; y = digits.target #3
iso.fit(digits.data) #4
data_projected = iso.transform(digits.data) #5
data_projected.shape
(1797, 2)
plt.scatter(data_projected[:, 0], data_projected[:, 1], c=digits.target,
edgecolor='none', alpha=0.5, cmap=plt.cm.get_cmap('tab10', 10))
plt.colorbar(label='digit label', ticks=range(10))
plt.clim(-0.5, 9.5);

Podemos observar por ejemplo lo bien separados que están el 0 y el 1, y por el contrario la confusión entre el 2 y el 7, o el 3 y el 9. Pero más o menos se puede comprobar que están razonablemente separados como para poder usar un algoritmo de aprendizaje supervisado.
Clasificación¶
Usaremos de nuevo Naive Bayes Gaussiano:
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
model.fit(X_train, y_train)
y_model = model.predict(X_test)
accuracy_score(y_test, y_model)
0.8333333333333334
Obtenemos más de un 80% de efectividad, que no está nada mal. Para mejorar es interesante saber dónde se equivoca nuestro modelo; algo que podemos ver con la matriz de confusión, o volviendo a pintar el grid de caracteres con el valor estimado en rojo si no coincide con el real. Para mejorar los resultados deberíamos optar por otros algoritmos!
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(y_test, y_model)
sns.heatmap(mat, square=True, annot=True, cbar=False, cmap="YlGnBu")
plt.xlabel('predicted value')
plt.ylabel('true value');

fig, axes = plt.subplots(10, 10, figsize=(8, 8), subplot_kw={'xticks':[], 'yticks':[]},
gridspec_kw=dict(hspace=0.1, wspace=0.1))
test_images = X_test.reshape(-1, 8, 8)
for i, ax in enumerate(axes.flat):
ax.imshow(test_images[i], cmap='binary', interpolation='nearest')
ax.text(0.05, 0.05, str(y_model[i]), transform=ax.transAxes,
color='green' if (y_test[i] == y_model[i]) else 'red')

Validación del modelo¶
La precisión del modelo no sirve para validarlo correctamente. Podemos obtener un 100% de precisión con un modelo si por ejemplo lo probamos con los mismos datos que usamos para entrenarlo (¡menuda idea!).
Conjuntos de retención¶
Una forma más correcta de validar el modelo sería usando un conjunto de retención, que no es más que un subconjunto de los datos que se reserva para la fase de validación del modelo (datos de test o validación). La desventaja de usar este procedimiento es que perderemos una parte de nuestros datos que nos vendría muy bien para entrenamiento (sobre todo cuando no tenemos muchos). Para evitarlo podemos recurrir a la validación cruzada.
Validación cruzada¶
Con este método de validación, podemos dividir de varias maneras los datos disponibles en sendas iteraciones, de tal forma que creemos diferentes combinaciones de subconjuntos para entrenamiento y validación.
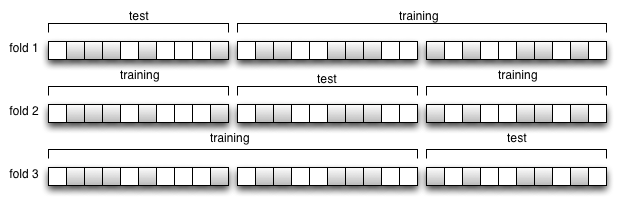
Por suerte con Scikit-Learn podemos hacer la validación cruzada directamente usando el método cross_val_score(). Eso nos dará una mejor idea del rendimiento de un algoritmo.
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
cross_val_score(model, X, y, cv=4)
array([0.94871795, 0.94871795, 0.91666667, 1. ])
Scikit-Learn implementa varios esquemas de validación cruzada que son útiles para distintos casos. Todos ellos están disponibles en el módulo model_selection. Por ejemplo podríamos querer crear el máximo de iteraciones posibles:
from sklearn.model_selection import KFold
scores = cross_val_score(model, X, y, cv=KFold(len(X)))
scores.mean()
0.9533333333333334
Seleccionando el mejor modelo¶
Este es uno de los aspectos más importantes en la práctica. Si nuestro estimador no rinde bien... ¿cómo deberíamos proceder? Existen varias posibles respuestas, aunque lo complicado es saber cuál será la adecuada en cada caso:
- Usar un modelo más complicado o más flexible
- Usar un modelo menos complicado o menos flexible xD
- Conseguir más muestras de entrenamiento
- Conseguir más datos de otras fuentes para que las muestras tengan más variables
El balance sesgo - varianza¶
Encontrar el mejor modelo es básicamente encontrar el punto dulce en el balance entre sesgo (bias) y varianza.
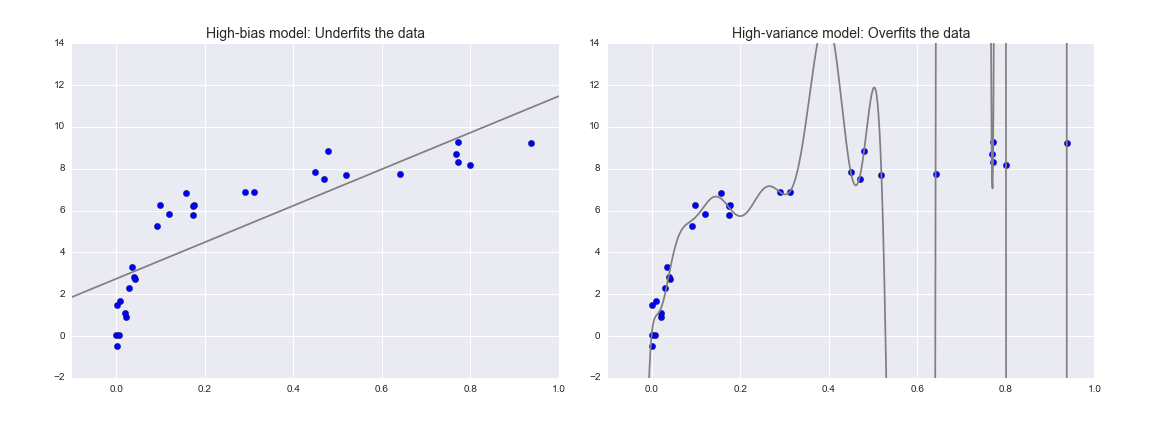
Un modelo con alto sesgo se sub-ajustará a los datos por su simplicidad y poca flexibilidad, siendo incapaz de describir o representar la información contenida en las características de los datos. El error de entrenamiento y el de validación serán similares.
Un modelo con alta varianza se estará sobre-ajustando a los datos por su complejidad, por lo que será muy sensible a errores o ruido, y no generalizará bien para nuevas muestras de entrada. El error de validación en este caso será mucho más alto que el de entrenamiento.
Curvas de validación¶
En esta gráfica vemos lo que se conoce como curva de validación:
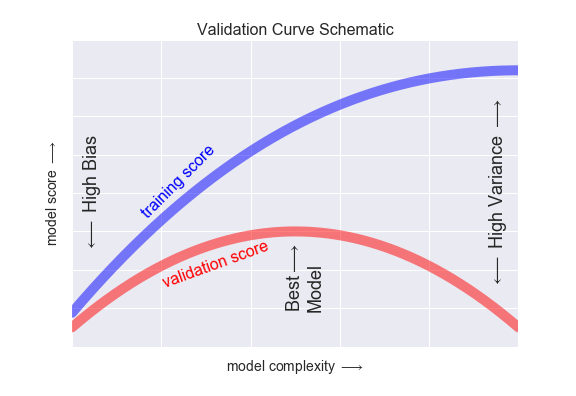
En algún punto intermedio, la curva para el score de validación tendrá un máximo. Ese punto sería nuestro punto dulce; el balance óptimo entre sesgo y varianza.
Vamos a aplicar validación cruzada con el fin de hallar la curva de validación para un modelo de regresión polinómica, que es una generalización del modelo lineal, donde la complejidad viene marcada por el grado, que está parametrizado (¡si cambia el grado no hay que cambiar el modelo!). En Scikit-Learn podemos implementar este modelo combinando la regresión polinómica lineal simple con un preprocesador polinómico, usando una tubería:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
def PolynomialRegression(degree=2, **kwargs):
return make_pipeline(PolynomialFeatures(degree), LinearRegression(**kwargs))
def make_data(N, err=1.0, rseed=1):
# randomly sample the data
rng = np.random.RandomState(rseed)
X = rng.rand(N, 1) ** 2
y = 10 - 1. / (X.ravel() + 0.1)
if err > 0:
y += err * rng.randn(N)
return X, y
X, y = make_data(40)
X_test = np.linspace(-0.1, 1.1, 500)[:, None]
plt.scatter(X.ravel(), y, color='black')
axis = plt.axis()
for degree in [1, 3, 5]:
y_test = PolynomialRegression(degree).fit(X, y).predict(X_test)
plt.plot(X_test.ravel(), y_test, label='degree={0}'.format(degree))
plt.xlim(-0.1, 1.0)
plt.ylim(-2, 12)
plt.legend(loc='best');

¿Y para qué grado del polinomio tendremos el mejor balance sesgo - varianza? Podemos averiguarlo usando directamente el método validation_curve() de Scikit-Learn para obtener la curva de validación:
from sklearn.model_selection import validation_curve
degree = np.arange(0, 21)
train_score, val_score = validation_curve(PolynomialRegression(), X, y, 'polynomialfeatures__degree', degree, cv=7)
plt.plot(degree, np.median(train_score, 1), color='blue', label='training score')
plt.plot(degree, np.median(val_score, 1), color='red', label='validation score')
plt.legend(loc='best')
plt.ylim(0, 1)
plt.xlabel('degree')
plt.ylabel('score');

Vemos claramente como el punto dulce para un balance óptimo entre sesgo y varianza se consigue usando un polinomio de grado 3.
Curvas de aprendizaje¶
El modelo óptimo dependerá generalmente del tamaño del dataset; en principio un conjunto de muestras mayor soporta un modelo más complejo. La curva de validación depende por tanto de la complejidad del modelo y del tamaño del dataset.
A veces es interesante ver cómo se comporta el modelo cuando incrementamos el número de muestras del conjunto de entrenamiento, algo que podemos hacer progresivamente.
En esta gráfica vemos lo que se conoce como curva de aprendizaje:
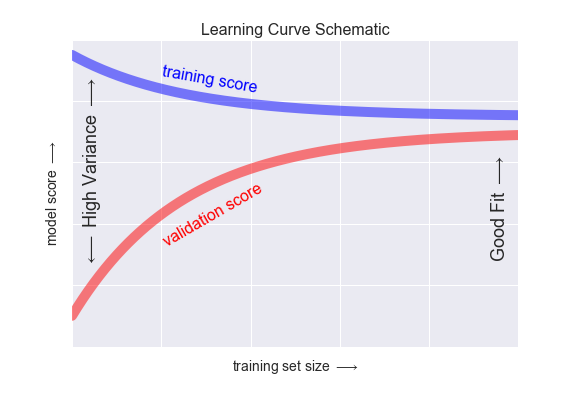 La característica más notable de esta curva es la convergencia hacia una puntuación según crece el número de muestras. Llegará un momento en que añadir más muestras no servirá de nada si no aumentamos la complejidad.
La característica más notable de esta curva es la convergencia hacia una puntuación según crece el número de muestras. Llegará un momento en que añadir más muestras no servirá de nada si no aumentamos la complejidad.
Scikit-Learn proporciona el método learning_curve() para obtener estas curvas de forma sencilla:
from sklearn.model_selection import learning_curve
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for i, degree in enumerate([2, 9]):
N, train_lc, val_lc = learning_curve(PolynomialRegression(degree), X, y, cv=7, train_sizes=np.linspace(0.3, 1, 25))
ax[i].plot(N, np.mean(train_lc, 1), color='blue', label='training score')
ax[i].plot(N, np.mean(val_lc, 1), color='red', label='validation score')
ax[i].hlines(np.mean([train_lc[-1], val_lc[-1]]), N[0], N[-1], color='gray', linestyle='dashed')
ax[i].set_ylim(0, 1)
ax[i].set_xlim(N[0], N[-1])
ax[i].set_xlabel('training size')
ax[i].set_ylabel('score')
ax[i].set_title('degree = {0}'.format(degree), size=14)
ax[i].legend(loc='best')

Vemos cómo con un modelo polinómico de grado 2 las curvas pronto convergen, por lo que aumentar el grado sería la única forma de mejorar el rendimiento; algo que vemos que se consigue (aunque también necesitamos más muestras).
Pintar la curva de aprendizaje nos puede servir en un determinado momento para tomar decisiones sobre cómo mejorar nuestro modelo.
Validación en la práctica: Cuadrícula de búsqueda¶
En la vida real los modelos no son tan sencillos como pintar una línea, por lo que estas visualizaciones son mucho más complejas, y lo que buscaremos es simplemente el modelo que maximiza la precisión en la validación.
Scikit-Learn proporciona la clase GridSearchCV para realizar este tipo de búsqueda de forma automatizada. Aplicamos esto al ejemplo de regresión polinómica, realizando la optimización para un grid de 3 dimensiones resultado de variar 3 parámetros del modelo:
from sklearn.model_selection import GridSearchCV
param_grid = {'polynomialfeatures__degree': np.arange(21),
'linearregression__fit_intercept': [True, False],
'linearregression__normalize': [True, False]}
grid = GridSearchCV(PolynomialRegression(), param_grid, cv=7, iid=False)
grid.fit(X, y)
grid.best_params_
{'linearregression__fit_intercept': False,
'linearregression__normalize': True,
'polynomialfeatures__degree': 4}
# Obtenemos el resultado
model = grid.best_estimator_
plt.scatter(X.ravel(), y)
lim = plt.axis()
y_test = model.fit(X, y).predict(X_test)
plt.plot(X_test.ravel(), y_test);
plt.axis(lim);

Scikit-Learn permite más cosas, como por ejemplo paralelizar los cálculos, hacer búsquedas aleatorias, o especificar una función de scoring propia.
Ingeniería de características (Feature Engineering)¶
En los ejemplos vistos con anterioridad los datasets contenían datos numéricos, limpios y formateados. En el mundo real difícilmente encontraremos esto. Uno de los pasos más importantes para aplicar Machine Learning es la Ingeniería de características, que consiste en tomar cualquier información de entrada y convertirla en numérica para poder construir la matriz de características.
Atributos categóricos¶
Un ejemplo habitual sería el Sexo de una persona; 'Hombre' o 'Mujer'.
Una forma de lidiar con este tipo de atributos es crear columnas extra en el dataset que indiquen si está presente o no la categoría concreta, usando como valor 0 o 1 (una columna para 'Hombre' y otra para 'Mujer' en nuestro ejemplo).
Scikit-Learn proporciona la utilidad DictVectorizer para hacer esto de forma automática. Vemos un ejemplo:
data = [
{'edad': 19, 'peso': 80, 'sexo': 'Hombre', 'estado': 'S'},
{'edad': 71, 'peso': 77, 'sexo': 'Mujer', 'estado': 'V'},
{'edad': 22, 'peso': 63, 'sexo': 'Mujer', 'estado': 'C'},
{'edad': 53, 'peso': 58, 'sexo': 'Mujer', 'estado': 'C'}
]
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer(sparse=False, dtype=int)
vec.fit_transform(data)
array([[19, 0, 1, 0, 80, 1, 0],
[71, 0, 0, 1, 77, 0, 1],
[22, 1, 0, 0, 63, 0, 1],
[53, 1, 0, 0, 58, 0, 1]], dtype=int32)
vec.get_feature_names()
['edad', 'estado=C', 'estado=S', 'estado=V', 'peso', 'sexo=Hombre', 'sexo=Mujer']
El problema de este enfoque es si el número de categorías de un atributo es grande (por ejemplo, la provincia). Pero como la mayoría de valores será igual a 0, podemos crear una salida comprimida usando el parámetro sparse=True. Muchos modelos aceptan este tipo de datasets de entrada.
Atributos textuales¶
A veces tenemos la necesidad de convertir texto en un conjunto de valores numéricos representativos. Por ejemplo para textos donde queremos analizar el sentimiento, nos gustaría saber qué palabras aparecen.
Una forma de tratar estos campos sería vectorizar el texto usando el número de apariciones de cada palabra, y crear una matriz comprimida donde cada palabra nueva es una columna extra. Para ello tenemos la utilidad CountVectorizer:
texto = ['no me ha gustado nada de nada; muy mala',
'muy buena, una obra maestra',
'ni buena ni mala']
from sklearn.feature_extraction.text import CountVectorizer
vec = CountVectorizer()
X = vec.fit_transform(texto)
X
<3x13 sparse matrix of type '<class 'numpy.int64'>' with 16 stored elements in Compressed Sparse Row format>
Este enfoque tiene alguna problemática, y es que las palabras más usadas aparecerían más veces, y quizá en nuestro caso no es lo deseado. Para ello podríamos usar TFidVectorizer
Imágenes¶
Una forma de codificar las imágenes sería usando el mismo enfoque visto para los dígitos manuscritos; usando simplemente los valores de los píxeles, pero dependiendo de la aplicación esto no será lo óptimo.
Atributos derivados¶
Un tipo interesante de atributo es aquél que deriva matemáticamente de otros. Podríamos por ejemplo convertir un dataset con dos atributos x e y en una regresión polinómica simplemente convirtiendo la columna x en varias (x^2, x^3, ...)
Valores no disponibles¶
Debemos reemplazar dichos valores con lo más adecuado para nuestro caso. Scikit-Learn proporciona el módulo impute con varias utilidades. Por ejemplo la clase SimpleImputer para un enfoque típico usando la media, la mediana o el valor más frecuente de la columna:
from numpy import nan
X = np.array([[ nan, 0, 3 ],
[ 3, 7, 9 ],
[ 3, 5, 2 ],
[ 4, nan, 6 ],
[ 8, 8, 1 ]])
from sklearn.impute import SimpleImputer
imp = SimpleImputer(strategy='mean')
X2 = imp.fit_transform(X)
X2
array([[4.5, 0. , 3. ],
[3. , 7. , 9. ],
[3. , 5. , 2. ],
[4. , 5. , 6. ],
[8. , 8. , 1. ]])
Tuberías¶
Para encadenar transformaciones podemos usar el objeto Pipeline, que aplicará los pasos especificados a los datos de entrada.
# Ejemplo
from sklearn.pipeline import make_pipeline
model = make_pipeline(SimpleImputer(strategy='mean'),
PolynomialFeatures(degree=2),
LinearRegression())