Using Cache (available since v21.06.00)¶
Need for Cache¶
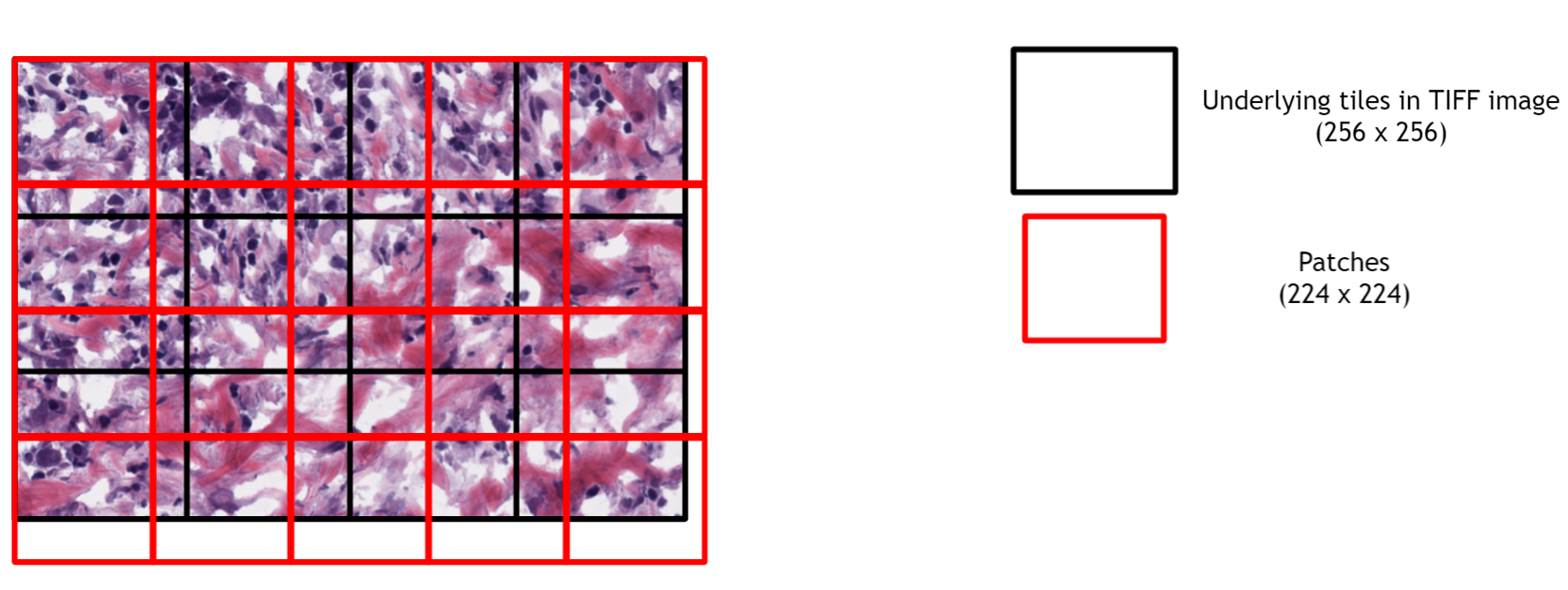
In many deep learning use cases, small image patches need to be extracted from the large image and they are fed into the neural network.
If the patch size doesn't align with the underlying tile layout of TIFF image (e.g., AI model such as ResNet may accept a particular size of the image [e.g., 224x224] that is smaller than the underlying tile size [256x256]), redundant image loadings for a tile are needed (See the following two figures)
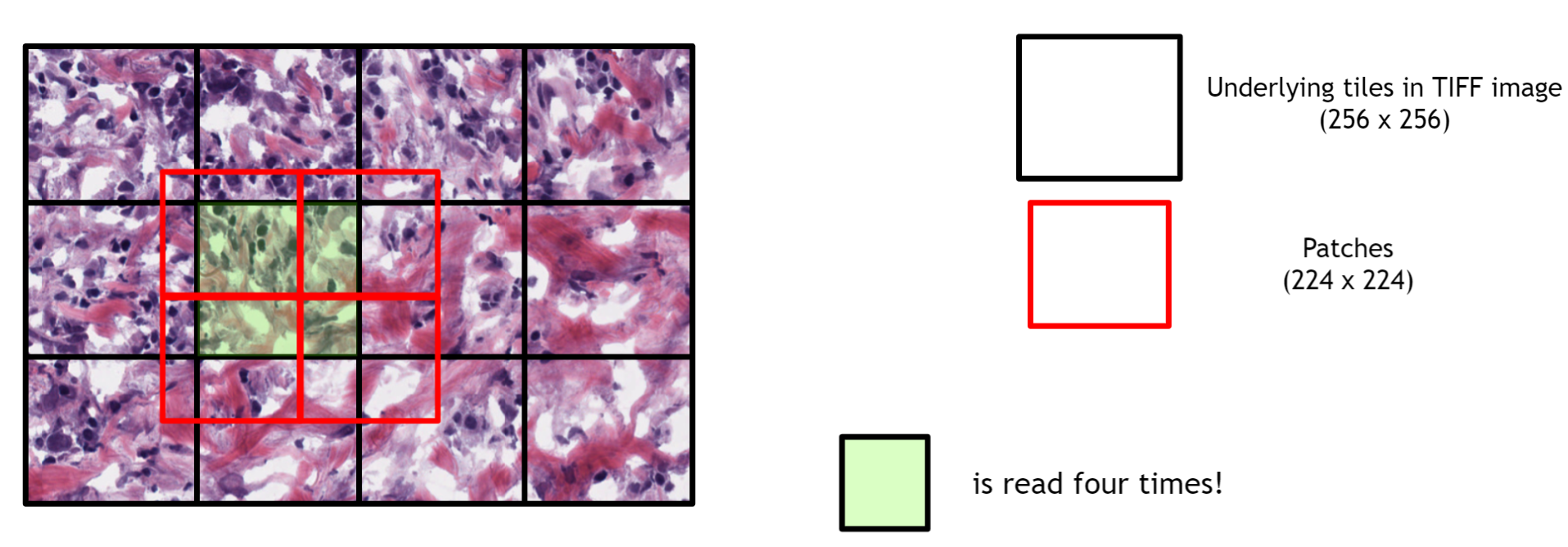
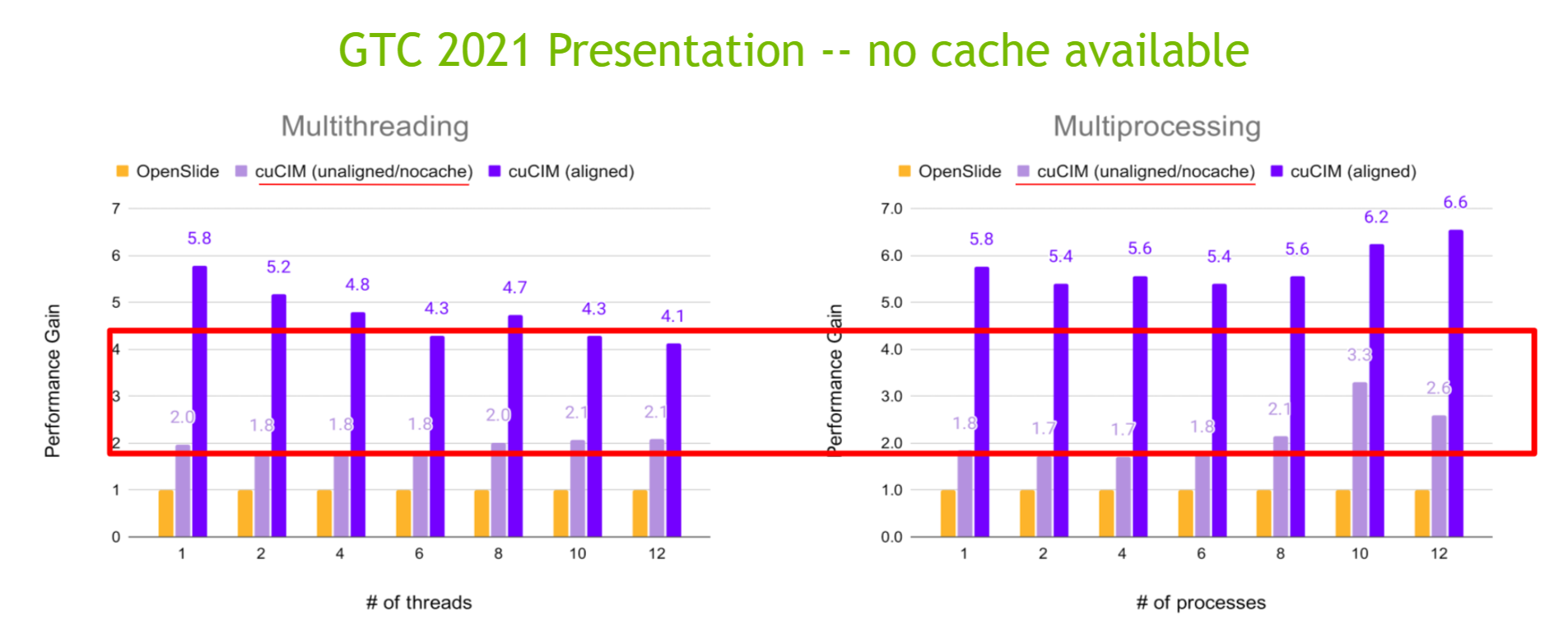
Which resulted in lower performance for unaligned cases as shown in our GTC 2021 presentation
The proper use of cache improves the loading performance greatly, especially for inference use cases and when accessing tiles sequentially (left to right, top to bottom) from one TIFF file.
On the other hand, if the application accesses partial tiles randomly from multiple TIFF files (this usually happens for training use cases), using a cache could be meaningless.
Enabling cache¶
Currently, cuCIM supports the following three strategies:
nocacheper_processshared_memory(interprocess)
1) nocache
No cache.
By default, this cache strategy is used.
With this strategy, the behavior is the same as one before v20.06.00.
2) per_process
The cache memory is shared among threads.
3) shared_memory
The cache memory is shared among processes.
Getting cache setting¶
CuImage.cache() would return an object that can control the current cache. The object has the following properties:
type: The type (strategy) namememory_size: The number of bytes used in the cache memorymemory_capacity: The maximum number of bytes that can be allocated (used) in the cache memoryfree_memory: The number of bytes available in the cache memorysize: The number of cache items usedcapacity: The maximum number of cache items that can be createdhit_count: The cache hit countmiss_count: The cache miss countconfig: A configuration dictionary that was used for configuring cache.
from cucim import CuImage
cache = CuImage.cache()
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f'free_memory: {cache.free_memory}')
print(f' size: {cache.size}/{cache.capacity}')
print(f' hit_count: {cache.hit_count}')
print(f' miss_count: {cache.miss_count}')
print(f' config: {cache.config}')
type: CacheType.NoCache(0)
memory_size: 0/0
free_memory: 0
size: 0/0
hit_count: 0
miss_count: 0
config: {'type': 'nocache', 'memory_capacity': 1024, 'capacity': 5461, 'mutex_pool_capacity': 11117, 'list_padding': 10000, 'extra_shared_memory_size': 100, 'record_stat': False}
Changing Cache Setting¶
Cache configuration can be changed by adding parameters to cache() method.
The following parameters are available:
type: The type (strategy) name. Default to 'no_cache'.memory_capacity: The maximum number of mebibytes (MiB, 2^20) that can be allocated (used) in the cache memory. Default to1024.capacity: The maximum number of cache items that can be created. Default to5461(= (<memory_capacity> x 2^20) / (256x256x3)).mutex_pool_capacity: The mutex pool size. Default to11117.list_padding: The number of additional items used for the internal circular queue. Default to10000.extra_shared_memory_size: The size of additional memory allocation (in MiB) for shared_memory allocator inshared_processstrategy. Default to100.record_stat: If the cache statistic should be recorded or not. Default toFalse.
In most cases, type(required) and memory_capacity are used.
from cucim import CuImage
cache = CuImage.cache('per_process', memory_capacity=2048)
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f'free_memory: {cache.free_memory}')
print(f' size: {cache.size}/{cache.capacity}')
print(f' hit_count: {cache.hit_count}')
print(f' miss_count: {cache.miss_count}')
print(f' config: {cache.config}')
type: CacheType.PerProcess(1)
memory_size: 0/2147483648
free_memory: 2147483648
size: 0/10922
hit_count: 0
miss_count: 0
config: {'type': 'per_process', 'memory_capacity': 2048, 'capacity': 10922, 'mutex_pool_capacity': 11117, 'list_padding': 10000, 'extra_shared_memory_size': 100, 'record_stat': False}
Choosing Proper Cache Memory Size¶
It is important to select the appropriate cache memory size (capacity). Small cache memory size results in low cache hit rates. Conversely, if the cache memory size is too large, memory is wasted.
For example, if the default tile size is 256x256 and the patch size to load is 224x224, the cache memory needs to be large enough to contain at least two rows of tiles in the image to avoid deleting the required cache entries while loading patches sequentially (left to right, top to bottom) from one TIFF file.

cuCIM provide a utility method (cucim.clara.cache.preferred_memory_capacity()) to calculate a preferred cache memory size for the given image (image size and tile size) and the patch size.
Internal logic is available at https://godbolt.org/z/jY7G84xzT
from cucim import CuImage
from cucim.clara.cache import preferred_memory_capacity
img = CuImage('input/image.tif')
image_size = img.size('XY') # same with `img.resolutions["level_dimensions"][0]`
tile_size = img.resolutions['level_tile_sizes'][0] # default: (256, 256)
patch_size = (1024, 1024) # default: (256, 256)
bytes_per_pixel = 3 # default: 3
print(f'image size: {image_size}')
print(f'tile size: {tile_size}')
# Below three statements are the same.
memory_capacity = preferred_memory_capacity(img, patch_size=patch_size)
memory_capacity2 = preferred_memory_capacity(None, image_size, tile_size, patch_size, bytes_per_pixel)
memory_capacity3 = preferred_memory_capacity(None, image_size, patch_size=patch_size)
print(f'memory_capacity : {memory_capacity} MiB')
print(f'memory_capacity2: {memory_capacity2} MiB')
print(f'memory_capacity3: {memory_capacity3} MiB')
cache = CuImage.cache('per_process', memory_capacity=memory_capacity) # You can also manually set capacity` (e.g., `capacity=500`)
print('= Cache Info =')
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f' size: {cache.size}/{cache.capacity}')
image size: [19920, 26420]
tile size: (256, 256)
memory_capacity : 74 MiB
memory_capacity2: 74 MiB
memory_capacity3: 74 MiB
= Cache Info =
type: CacheType.PerProcess(1)
memory_size: 0/77594624
size: 0/394
Reserve More Cache Memory¶
If more cache memory capacity is needed in runtime, you can use reserve() method.
from cucim import CuImage
from cucim.clara.cache import preferred_memory_capacity
img = CuImage('input/image.tif')
memory_capacity = preferred_memory_capacity(img, patch_size=(256, 256))
new_memory_capacity = preferred_memory_capacity(img, patch_size=(512, 512))
print(f'memory_capacity : {memory_capacity} MiB')
print(f'new_memory_capacity: {new_memory_capacity} MiB')
print()
cache = CuImage.cache('per_process', memory_capacity=memory_capacity)
print('= Cache Info =')
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f' size: {cache.size}/{cache.capacity}')
print()
cache.reserve(new_memory_capacity)
print('= Cache Info (update memory capacity) =')
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f' size: {cache.size}/{cache.capacity}')
print()
cache.reserve(memory_capacity, capacity=500)
print('= Cache Info (update memory capacity & capacity) =')
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity} # smaller `memory_capacity` value does not change this')
print(f' size: {cache.size}/{cache.capacity}')
print()
cache = CuImage.cache('no_cache')
print('= Cache Info (no cache) =')
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f' size: {cache.size}/{cache.capacity}')
memory_capacity : 30 MiB
new_memory_capacity: 44 MiB
= Cache Info =
type: CacheType.PerProcess(1)
memory_size: 0/31457280
size: 0/160
= Cache Info (update memory capacity) =
type: CacheType.PerProcess(1)
memory_size: 0/46137344
size: 0/234
= Cache Info (update memory capacity & capacity) =
type: CacheType.PerProcess(1)
memory_size: 0/46137344 # smaller `memory_capacity` value does not change this
size: 0/500
= Cache Info (no cache) =
type: CacheType.NoCache(0)
memory_size: 0/0
size: 0/0
Profiling Cache Hit/Miss¶
If you add an argument record_stat=True to CuImage.cache() method, cache statistics is recorded.
Cache hit/miss count is accessible through hit_count/miss_count property of the cache object.
You can get/set/unset the recording through record() method.
from cucim import CuImage
from cucim.clara.cache import preferred_memory_capacity
img = CuImage('input/image.tif')
memory_capacity = preferred_memory_capacity(img, patch_size=(256, 256))
cache = CuImage.cache('per_process', memory_capacity=memory_capacity, record_stat=True)
img.read_region((0,0), (100,100))
print(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')
region = img.read_region((0,0), (100,100))
print(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')
region = img.read_region((0,0), (100,100))
print(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')
print(f'Is recorded: {cache.record()}')
cache.record(False)
print(f'Is recorded: {cache.record()}')
region = img.read_region((0,0), (100,100))
print(f'cache hit: {cache.hit_count}, cache miss: {cache.miss_count}')
print()
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f'free_memory: {cache.free_memory}')
print(f' size: {cache.size}/{cache.capacity}')
print()
cache = CuImage.cache('no_cache')
print(f' type: {cache.type}({int(cache.type)})')
print(f'memory_size: {cache.memory_size}/{cache.memory_capacity}')
print(f'free_memory: {cache.free_memory}')
print(f' size: {cache.size}/{cache.capacity}')
cache hit: 0, cache miss: 1
cache hit: 1, cache miss: 1
cache hit: 2, cache miss: 1
Is recorded: True
Is recorded: False
cache hit: 0, cache miss: 0
type: CacheType.PerProcess(1)
memory_size: 196608/31457280
free_memory: 31260672
size: 1/160
type: CacheType.NoCache(0)
memory_size: 0/0
free_memory: 0
size: 0/0
Considerations in Multi-threading/processing Environment¶
per_process strategy¶
Cache memory¶
If used in the multi-threading environment and each thread is reading the different part of the image sequentially, please consider increasing cache memory size than the size suggested by cucim.clara.cache.preferred_memory_capacity() to avoid dropping necessary cache items.
If used in the multi-processing environment, the cache memory size allocated can be (# of processes) x (cache memory capacity).
Please be careful not to oversize the memory allocated by the cache.
Cache Statistics¶
If used in the multi-processing environment (e.g, using concurrent.futures.ProcessPoolExecutor()), cache hit count (hit_count) and miss count (miss_count) wouldn't be recorded in the main process's cache object.
shared_memory strategy¶
In general, shared_memory strategy has more overhead than per_process strategy. However, it is recommended that you select this strategy if you want to use a fixed size of cache memory regardless of the number of processes.
Note that, this strategy pre-allocates the cache memory in the shared memory and allocates more memory (as specified in extra_shared_memory_size parameter) than the requested cache memory size (capacity) for the memory allocator to handle memory segments.
Cache memory¶
Since the cache memory would be shared by multiple threads/processes, you will need to set enough cache memory to avoid dropping necessary cache items.
Setting Default Cache Configuration¶
The configuration for cuCIM can be specified in .cucim.json file and user can set a default cache settings there.
cuCIM finds .cucim.json file from the following order:
- The current folder
$HOME/.cucim.json
The configuration for the cache can be specified like below.
jsonc
{
// This is actually JSONC file so comments are available.
"cache": {
"type": "nocache",
"memory_capacity": 1024,
"capacity": 5461,
"mutex_pool_capacity": 11117,
"list_padding": 10000,
"extra_shared_memory_size": 100,
"record_stat": false
}
}
You can write the current cache configuration into the file like below:
import json
from cucim import CuImage
cache = CuImage.cache()
config_data = {'cache': cache.config}
json_text = json.dumps(config_data, indent=4)
print(json_text)
# Save into the configuration file.
with open('.cucim.json', 'w') as fp:
fp.write(json_text)
{
"cache": {
"type": "nocache",
"memory_capacity": 1024,
"capacity": 5461,
"mutex_pool_capacity": 11117,
"list_padding": 10000,
"extra_shared_memory_size": 100,
"record_stat": false
}
}
Cache Mechanism Used in Other Libraries (OpenSlide and rasterio)¶
Other libraries have the following strategies for the cache.
- OpenSlide
- 1024 x 1024 x 30 bytes (30MiB) per file handle for cache ==> 160 (RGB) or 120 (ARGB) 256x256 tiles
- Not configurable
- rasterio
- 5% of available system memory per process by default (e.g., 32 GB of free memory => 1.6 GB of cache memory allocated).
- Configurable through environment module
Results¶
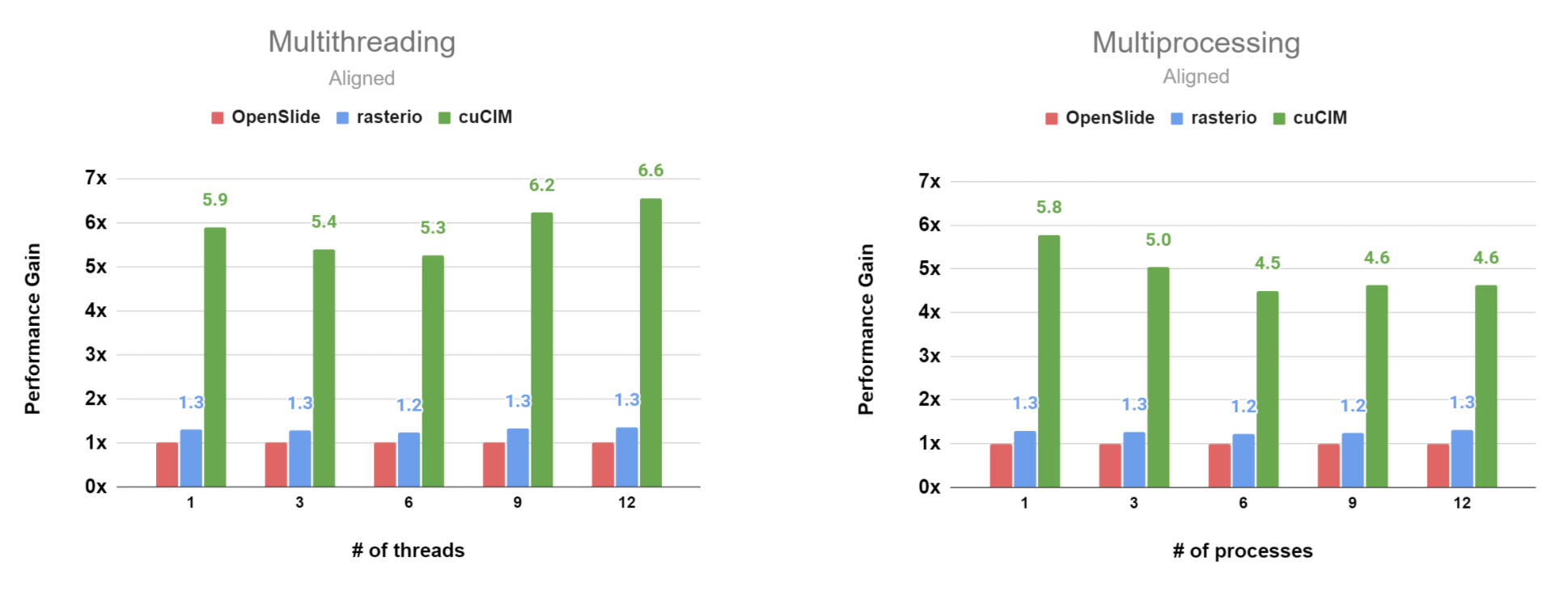
cuCIM has a similar performance gain with the aligned case when the patch and tile layout are not aligned.
We compared performance against OpenSlide and rasterio.
For the cache memory size(capacity) setting, we used a similar approach with rasterio (5% of available system memory).
System Information¶
- OS: Ubuntu 18.04
- CPU: Intel(R) Core(TM) i7-7800X CPU @ 3.50GHz
- Memory: 64GB (G-Skill DDR4 2133 16GB X 4)
- Storage
- SATA SSD: Samsung SSD 850 EVO 1TB
Experiment Setup¶
- Use read_region() APIs to read all patches (256x256 size each) of a whole slide image (.tif) at the largest resolution level (92,344 x 81,017. Internal tile size is 256 x 256 with 95% JPEG compression quality level) on multithread/multiprocess environment.
- Original whole slide image (.svs : 1.6GB) was converted into .tif file (3.2GB) using OpenSlide & tifffile library in this experiment (image2.tif).
- Original image can be downloaded from here(https://drive.google.com/drive/u/0/folders/0B--ztKW0d17XYlBqOXppQmw0M2M , TUPAC-TR-488.svs)
- Original whole slide image (.svs : 1.6GB) was converted into .tif file (3.2GB) using OpenSlide & tifffile library in this experiment (image2.tif).
- Two different job configurations
- multithreading: spread workload into multiple threads
- multiprocessing: spread workload into multiple processes
- Two different read configurations for each job configuration
- unaligned/nocache: (256x256)-patch-reads start from (1,1). e.g., read the region (1,1)-(257,257) then, read the region (257,1)-(513,257), ...
- aligned: (256x256)-patch-reads start from (0,0). OpenSlide's internal cache mechanism does not affect this case.
- Took about 10 samples due to the time to conduct the experiment so there could have some variation in the results.
- Note that this experiment doesn’t isolate the effect of system cache (page cache) that we excluded its effect on C++ API benchmark[discard_cache] so IO time itself could be short for both libraries.
Aligned Case (per_process, JPEG-compressed TIFF file)¶
Unaligned Case (per_process, JPEG-compressed TIFF file)¶
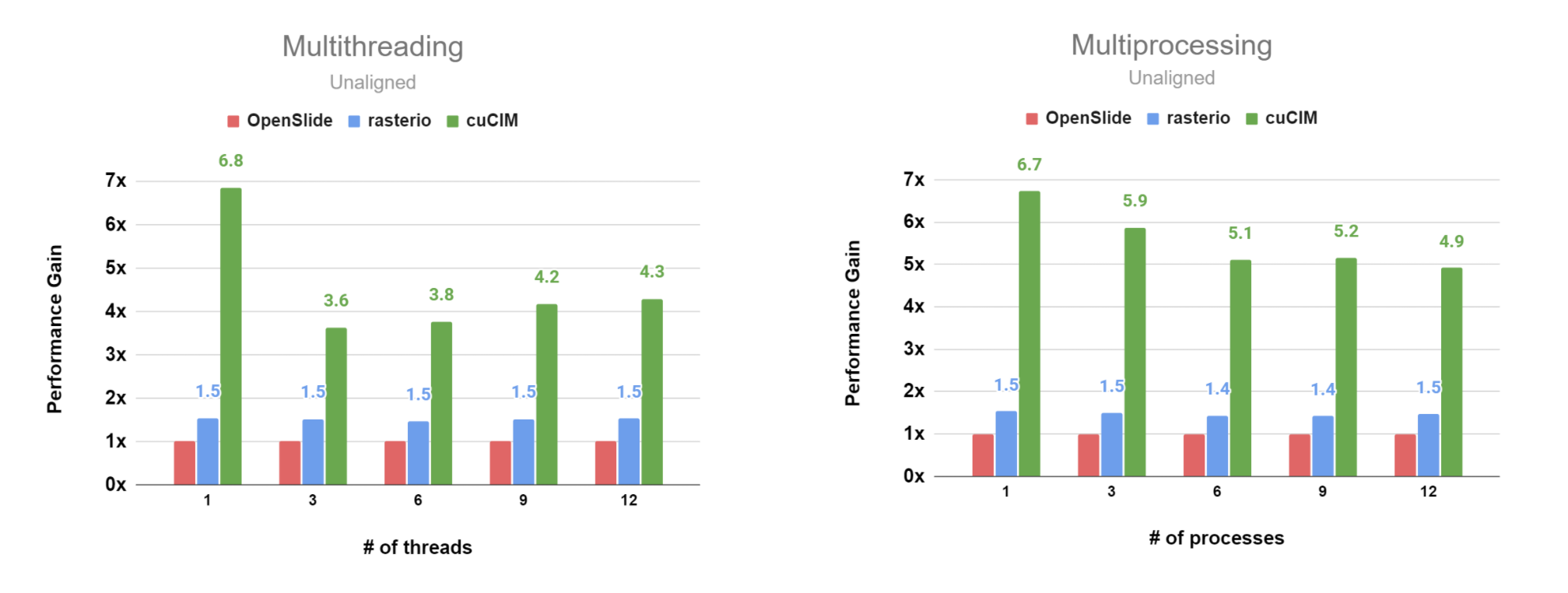
Overall Performance of per_process Compared with no_cache for Unaligned Case¶

The detailed data is available here.
Room for Improvement¶
Using of a Memory Pool¶
per_process strategy performs better than shared_memory strategy, and both strategies perform less than nocache strategy when underlying tiles and patches are aligned.
shared_memorystrategy does some additional operations compared withper_processstrategy, and both strategies have some overhead using cache (such as memory allocation for cache item/indirect function calls)
=> All three strategies (including nocache) can have benefited if we allocate CPU/GPU memory for tiles from a fixed-sized cache memory pool (using RMM and/or PMR) instead of calling malloc() to allocate memory.
Supporting Generator (iterator)¶
When patches to read in an image can be determined in advance (inference use case), we can load/prefetch entire compressed/decompressed image data to the memory and provide Python generator(iterator) to get a series of patches efficiently for inference use cases.
Appendix¶
Experiment Code¶
Please see https://github.com/rapidsai/cucim/blob/branch-21.12/experiments/Using_Cache/benchmark.py to check out the code used for the experiment.